Series: Project Lockdown
A phased approach to securing your database infrastructure
Updated August 2010
Phase 3
Duration: One Month
It’s Phase 3 of your security and compliance project. Let’s see what you can do within about a month to lock down your database infrastructure..
DOWNLOAD
- Phase 3 Checklist (PDF)
Covered in this Installment:
- 3.1 Remove Passwords from Scripts
- 3.2 Remove Password from Oracle RMAN
- 3.3 Move DBA Scripts to Scheduler
- 3.4 Lock Down Objects
- 3.5 Create Profiles of Database Users
- 3.6 Create and Analyze Object Access Profiles
- 3.7 Enable Auditing for Future Objects
- 3.8 Restrict Access from Specific Nodes Only
- 3.9 Institute Periodic Cleanup of Audit Trails
3.1 Remove Passwords from Scripts
Background
Some of your most serious potential threats arise from the use of hard-coded passwords in applications, programs, and scripts. In many cases, eliminating those passwords is a trivial exercise that will have an immediate impact.
For example, in many installations I have audited, a STATSPACK job runs as a shell script such as this:
export ORACLE_HOME=/u01/app/oracle/10.1/db
export ORACLE_SID=MYSID
cd $ORACLE_HOME/bin
$ORACLE_HOME/bin/sqlplus -s perfstat/perfstat @statspack.sqlThe shell script is then scheduled through cron or Windows Scheduler. There are two major risks to this approach:
- An intruder may find the file statspack.sh and see the password of the user PERFSTAT
- When the shell script is running, someone on the *nix server can issue a ps -aef command and see the command running—with the password clearly visible.
When I ask the reason for this approach, the answer is almost universally the same: because the previous DBA did it that way. Whatever the reason, the threat is clear and present and must be eliminated.
Strategy
You have several options for eliminating the exposure of passwords. Don’t be fooled into believing that the following will hide one:
sqlplus -s scott/$SCOTTPASSWORD @script.sql
where SCOTTPASSWORD is an environmental variable defined prior to the execution of the script. When a user issues the command /usr/ucb/ps uxgaeww, he can see all the environmental variables used in the process that will expose the password. Therefore, you have to literally hide the password in some manner. Let’s explore the options.
Option 1. One simple option is to use the nolog parameter in SQL*Plus. In this option, the previous script would change to the following:
export ORACLE_HOME=/u01/app/oracle/10.1/db
export ORACLE_SID=MYSID
cd $ORACLE_HOME/bin
$ORACLE_HOME/bin/sqlplus /nolog @statspack.sqlThis script allows a SQL*Plus session to be established but not yet connected to the database. Inside the script statspack.sql, you should place the userid and password:
connect perfstat/perfstat
... the rest of the script comes here ... Thus, if someone issues ps -aef, he will not see the userid or the password. (By the way, this is also best practice for initiating SQL*Plus sessions interactively.)
Option 2. This small variation of the above approach is useful in cases where SQL statements are not in a SQL script but rather embedded in the shell script directly, as in this example:
$ORACLE_HOME/bin/sqlplus user/pass << EOF
... SQL statements come here ...
EOFYou can change the shell script to the following:
$ORACLE_HOME/bin/sqlplus /nolog << EOF
connect user/pass
... SQL statements come here ...
EOFAgain, this is a good practice for building quick-and-dirty shell scripts that process SQL.
Option 3. In this option, you can create a password file containing userids and passwords and read them at runtime. First, create a file named .passwords (note the period before the filename) containing all userids and passwords. Because the filename starts with a period, it will be invisible when someone uses the ls -l command (but it will be visible with ls -la). Then change the permissions to 0600 so that only the owner can read it.
The file should contain the userids and passwords (one per line) separated by a space:
scott tiger
jane tarzan
... and so on ... Now create another file, a shell script named .getpass.sh (note the period again), with the following lines:
fgrep $1 $HOME/.passwords | cut -d " " -f2
Make the permissions of this script 0700 so that no one else can see and execute it. Subsequently, when you need to run a script as SCOTT all you have to do is code the lines like this:
.getpass.sh scott | sqlplus -s scott @script.sql
This will get the password of scott from the file and pass it to the sqlplus command. If someone issues the ps command, he will not be able to see the password.
As a fringe benefit, you have now enabled a flexible password management system. Whenever scott’s password changes (and it should change periodically as a good practice), all you have to do is edit the password file.
Option 4. This is where the OS-authenticated users come into the picture. (You learned about them in Phase 2.) As a recap, if you have a *nix user named ananda you can create an Oracle user as
create user ops$ananda identified externally;
Here the user can log in to the database as
sqlplus /
Note that there is no userid and password. The database does not actually authenticate the user; it assumes that user ananda has been properly authenticated at the OS level. Although this is not a great practice, it can be an attractive one—for shell scripts, for example. Your script could look like this:
sqlplus -s / @script.sql
Because neither the username nor the password is passed, there is no risk of their exposure via the ps command.
Implications
None. Replacing hard-coded passwords with a password management system does not affect the functionality of scripts, just how the password is supplied. You do however have to make sure to back up the password file or keep copies of it, as well as keep them up to date.
Action Items
- Identify scripts with hard-coded passwords.
- Pick an option for implementation:
- Use the Connect command inside the SQL script
- Use the Connect command inside the shell script (no SQL script).
- Use a password file.
- Use OS-authenticated accounts.
- Modify the scripts to remove the passwords.
3.2 Remove Password from Oracle RMAN
Background
Hard-coded passwords are not limited to scripts. Oracle Recovery Manager (RMAN) scripts are susceptible to the same bad habits.
Here is a typical Oracle RMAN command inside a script for making a backup:
rman target=/ rcvcat=catowner/catpass@catalog_connect_string
Here the catalog database is referenced in the connect string catalog_connect_string and the userid and password of the catalog are catowner and catpass, respectively. The userid and password are clearly visible if someone issues a ps command, just as previously described.
You have a couple of options for removing these hard-coded passwords:
Option 1. In this option, use the connect string inside the RMAN script like this:
connect target /
connect catalog catowner/catpass@catalog_connect_string
run {
allocate channel ...
... and so on ... This is clearly the preferred method—not only because it hides the password from the process listing, but also because it makes it easier to examine mistakes in the catalog connect strings.
Option 2. The other option is to use OS authentication for the catalog connection. You need to make a few additional changes, though. First, the catalog is probably on a different database than the one being backed up. To enable OS authentication in that case, you need to enable remote OS authentication on the catalog database.
On the catalog database, add the following initialization parameter and then restart:
remote_os_authent=TRUE
Now create a userid OPS$ORACLE as follows (on the catalog database):
create user ops$oracle identified externally;
Now your RMAN connection will look like this:
rman target=/ rcvcat=/@catalog_connect_string
This will not reveal the catalog user or password.
As you now connect as OPS$ORACLE and not catowner, you must rebuild the repository. After connecting, use the command
RMAN> register database;
to rebuild the catalog. You are now ready to use this script in RMAN backups.
Implications
There are a few implications here. First, the change in the catalog database exposes it to access from an outside server by anyone with login “oracle.” This is a serious security hole in itself; because you can’t control the clients, someone could infiltrate a client server—possibly via an inherently insecure operating system—create an id called “oracle,” and log into the catalog database.
You can prevent such an infiltration in several ways. The simplest method is to enable node filtering (discussed in section 3.8) to prevent any random server from connecting to this node.
Also be aware of the possibility of a different name for the Oracle software owner on the source database server. If you use “orasoft” on database server A and “oracle” on database server B, the users you need to create on the catalog database are OPS$ORASOFT and OPS$ORACLE, respectively—thus there will be two repositories, not one. This is not necessarily a bad thing, but if you want to report on backups from the catalog, you will have to know all the repositories in the database.
Action Plan
- Pick a method for hiding the RMAN catalog owner password:
- Connect command inside the script
- Connect as OS-authenticated user
- IF b., then
- Enable remote OS authentication on the catalog database (requires restart).
- Enable node validation in the catalog database to reject all nodes except the known few.
- Create users in the name OPS$ORACLE.
- Modify RMAN catalog connect string to use OPS$ORACLE.
- Rebuild catalog.
3.3 Move DBA Scripts to Scheduler
Background
What about those rather common DBA scripts that require a database login—for statistics collection, index rebuilding, and so on? Traditionally, DBAs use the cron (or AT, in Windows) job approach to run jobs, but there are two risks here:
- If this script needs to log in to the database—and most DBA scripts do—the userid and passwords must be placed in the script or somehow passed to the script. So, anyone with access to this script will be able to learn the password.
- Worse, anyone with access to the server can issue a ps -aef command and see the password from the process name.
You need to protect the password from being exposed.
Strategy
You can follow the same strategy as previously described, by passing the password in the SQL script or letting the shell script read it from a text file. That approach will prevent someone from learning the password in the ps -aef output; however, it will not address the problem of someone accessing the scripts.
In Oracle Database 10g Release 1 and later, you have an elegant way to manage this process via database jobs. Note that prior to Oracle Database 10g, database jobs were managed via the dbms_job supplied package, which could execute a PL/SQL package, code segment, or just plain SQL but not OS executables. In Oracle Database 10g, the new job management system is the supplied package dbms_scheduler (“Scheduler,” for short). In addition to offering a significantly improved user interface, this tool has a great advantage: It can execute even OS executables—all from within Oracle Database. This capability makes it super-easy to implement a one-stop job management system.
Here’s an example. Suppose you have a cron job that collects optimizer statistics, as shown below:
00 22 * * 6 /proprd/oracle/dbawork/utils/bin/DbAnalyze
-d PROPRD1 -f DbAnalyze_PROPRD1_1.cfg 2>&1 1> /tmp/DbAnalyze1.log As you can see, this job:
- Runs a program named /proprd/oracle/dbawork/utils/bin/DbAnalyze -d PROPRD1 -f DbAnalyze_PROPRD1_1.cfg
- Runs at 22 minutes past midnight, every Saturday
- Writes output to the file /tmp/DbAnalyze1.log
Now, to convert this to a Scheduler job, you would use the following code segment:
1 BEGIN
2 DBMS_SCHEDULER.create_job
3 (job_name => 'Dbanalyze',
4 repeat_interval => 'FREQ=WEEKLY; BYDAY=SAT BYHOUR=0 BYMINUTE=22',
5 job_type => 'EXECUTABLE',
6 job_action => '/proprd/oracle/dbawork/utils/bin/DbAnalyze -d
PROPRD1 -f DbAnalyze_PROPRD1_1.cfg',
7 enabled => TRUE,
8 comments => 'Analyze'
9 );
10 END;The arguments of the procedure are self-explanatory; the calendaring syntax is almost English-like. (For more details about Scheduler, read this OTN article or my book Oracle PL/SQL for DBAs (O’Reilly Media, 2005)
Why bother with Scheduler when good old cron is available? For several reasons, actually:
- Scheduler runs jobs only when the database is available, which is a great feature for supporting database-centric jobs. You don’t need to worry about checking if the database is up.
- Scheduler syntax is consistent across OSs. If migrating, all you need to do is move your code to the new server and a very simple export-import will enable your scheduled jobs.
- Like objects, Scheduler jobs are owned by users, which allows you to enable finer levels of privilege such as execution of a job by a separate user—unlike cron, which is generally used by a single Oracle software owner account.
- Best of all, because you don’t have to place a password anywhere, there is no risk of accidentally exposing one. Even the SYS user will not be able to know the password of the user, because it’s not stored anywhere. This ability makes Scheduler an attractive tool for managing DBA (or even regular users’) jobs very securely.
- As a fringe benefit of the above, you don’t need to worry about changes, such as when user passwords change.
Implications
There are none, as long as the jobs are database dependent. Of course, certain jobs must run even when the database is unavailable—such as jobs to move the alert log to a different location or to check if the database is up and running. These jobs should stay outside the database and within cron.
Action Plan
- Identify database jobs in cron.
- Decide which jobs should run even when the database is down (example: jobs that move the listener logs to a different location every day).
- For the rest of the jobs, create Scheduler jobs that are initially disabled by stating ENABLED=FALSE in the CREATE_JOB procedure.
- Test the execution of the jobs using the dbms_scheduler.run_job() procedure.
- If successful, turn off the cron job and enable the Scheduler job using the dbms_scheduler.enable() procedure.
3.4 Lock Down Objects
Background
Programmatic objects such as packages, procedures, functions, type bodies, and object methods embody the business logic of your organization. Any change to them may affect processing logic overall, and depending on how it is configured, the impact on a production system may be catastrophic.
Many organizations address this issue by implementing a secure change-control process where a change is discussed and approved—ideally, between at least two people—before it is implemented. The challenge is to make the system work automatically—which is actually a requirement in many jurisdictions and industries.
Strategy
This secure change-control process could work like this:
- An application super-owner (this could be the DBA, if needed) “unlocks” the program to be altered.
- The application owner alters the program body.
- The super-owner locks the program.
Considering that Oracle Database does not contain a native locking mechanism for data definition language (DDL), how would you implement this process?
One option is to revoke create session system privileges from the schema owner so that the schema owner can never log in to make a change. Instead, the changes are made by human application owners with privileges to alter the objects of the specified schema. This is a very good method for securing critical database objects by making it possible to create audit trails of changes made to objects, where the trails are traced back to real human users, not generic schema names.
For instance, suppose that the schema is BANK and the table name is ACCOUNTS. By revoking create session privileges from BANK, you prevent it from ever logging in to the database. Instead, you allow SCOTT, who has create session privilege, to modify ACCOUNTS. The Oracle user SCOTT is actually owned by the real human user Scott, and no one else has access to this userid. Any changes made to ACCOUNTS by SCOTT can be directly attributed to the user Scott, making accountability a key component of your security infrastructure feasible.
Generally, to lock the program in this approach, you should revoke the privilege from SCOTT. When the need arises to alter the program, you can grant it again—allowing SCOTT to change the program—and then revoke the grant.
Needless to say, this is not an elegant way to handle security. You will quickly run into issues where privilege management is not as simple as “one user per object.” In a typical database infrastructure, hundreds of users will be granted several types of privileges to perhaps thousands of objects. Revoking privileges will erase complex dependencies and cause big management headaches.
A more manageable solution is to use DDL triggers. Using this approach, you can establish the grants as necessary but control changes via DDL triggers.
For example, suppose you want to secure a package called SECURE_PKG in the schema ARUP. You would create a DDL schema trigger as follows:
1 create or replace trigger no_pkg_alter
2 before ddl
3 on arup.schema
4 begin
5 if (
6 ora_dict_obj_name = 'SECURE_PKG'
7 and
8 ora_sysevent = 'CREATE'
9 )
10 then
11 raise_application_error (-20001,'Can''t Alter SECURE_PKG');
12 end if;
13 end;
14 /In lines 6 and 8, you are checking if a change is made to the package. Remember, changes to packages are made by the create or replace package statement; hence the event checked for is create. If you want to secure a table from alterations, you can use alter in this value. In line 11, an error is raised when the package is altered.
Once this trigger is in place, when a user with privileges tries to alter this package, or even the owner of the object (ARUP) tries to recreate the package by running the package creation script
create or replace package secure_pkg
he will get this error:
ERROR at line 1:
ORA-00604: error occurred at recursive SQL level 1
ORA-20001: Can't Alter SECURE_PKG
ORA-06512: at line 8If you definitely want to modify this package, you can ask the DBA to unlock it by disabling the trigger:
alter trigger no_pkg_alter disable
/ Now the package creation script will go through. When done, lock it by asking the DBA to enable the trigger. The underlying privileges remain intact. Even when you allow the schema owner to log in and modify objects they own, this method will protect the objects as well. This strategy enables a two-person approach to change management.
Implications
There are none, provided that everyone is aware that the DBA must unlock the object when it’s ready for a change. If you make this step part of the formal change-control process, it will affect reliability in the most positive manner.
Action Plan
- Make a list of all objects that should be locked down. Note that not all objects need to be under such strict control (temporary tables created by the application owner to hold intermediate values, for example).
- Create the trigger with all these object names in the list. Make the trigger initially disabled. Do not add this functionality to an existing trigger. You should be able to control this trigger independently.
- Identify a person who should unlock objects. It could also be you.
- Document when objects should locked and unlocked, workflow, and so on.
- Enable the trigger.
3.5 Create Profiles of Database Users
Background
The design of any security system should start with a thorough and accurate understanding of the users accessing it as well as their modes of access—otherwise, you have no comparative baseline. As a DBA, you should have knowledge about your users and their applications and mechanism of access (such as the origin of the access, the DDL involved, and so on) anyway.
Strategy
This is where Oracle auditing comes in extremely handy. You don’t need to write extensive logon/logoff triggers or complex pieces of PL/SQL code. Rather, simply enable auditing by placing the following parameter in the database initialization parameter file:
audit_trail = db
and recycle the database. Once set, issue the following command as a DBA user:
audit session;
This statement enables auditing for all session-level activities such logons and logoffs. At the bare minimum, it shows who logged in, when, from which terminal, IP address, host machine, and so on.
After turning auditing on, you can monitor activity by issuing the following SQL statement
select to_char(timestamp,'mm/dd/yy hh24:mi:ss') logon_ts,
username,
os_username,
userhost,
terminal,
to_char(logoff_time,'mm/dd/yy hh24:mi:ss') logoff_ts
from dba_audit_trail
where logoff_time is not null;
Here is sample output:
LOGON_TS USERNAME OS_USERNAM USERHOST TERMINAL LOGOFF_TS
------------------------- --------------- ---------- --------------- --------------- ------------------
01/11/06 20:47:06 DELPHI sgoper stcdelpas01 unknown 01/11/06 20:48:46
01/11/06 20:48:21 DELPHI sgoper stcdelpas01 unknown 01/11/06 20:48:38
01/11/06 20:48:41 DELPHI sgoper stcdelpas01 unknown 01/11/06 20:49:19
01/11/06 20:36:03 STMT crmapps prodwpdb pts/3 01/11/06 20:36:03
01/11/06 20:36:04 STMT crmapps prodwpdb pts/3 01/11/06 20:37:40Here you can clearly see the userids that connect to the database, their OS userids (OS_USERNAME), and the time they logged off. If they connected from the same server as the database server, their terminal id is shown in the TERMINAL column (pts/3). If they connect from a different server, it shows up in the USERHOST column (stcdelpas01) .
Once you understand how the information is presented, you can construct queries to get more useful information. For instance, one typical question is, “Which machines do users usually connect from?” The following SQL statement gets the answer quickly:
select userhost, count(1)
from dba_audit_trail
group by userhost
order by 2
/Sidebar: Auditing Best Practices
Here you have learned how to use auditing to enforce some rudimentary levels of accountability. This approach has one serious limitation, however: You have to enable auditing by setting the initialization parameter AUDIT_TRAIL. This parameter is not dynamic; so to enable it, you must recycle the database. But if scheduling the required outage is difficult—and for many DBAs, it is—what are your options?
When I create a database, I always set the parameter to DB (for Oracle9i and earlier), DB_EXTENDED (for Oracle Database 10g and 11g Release 1) and DB, EXTENDED (for Oracle Database 11g Release 2). But wait—doesn’t that enable auditing and fill up the AUD$ table in the SYSTEM tablespace, eventually causing the database to halt?
No. Setting the AUDIT_TRAIL to a value does not enable auditing. It merely prepares the database for auditing—by specifying a location where the trails are written, such as to the OS or the database, the amount and type of auditing done, and whether the format is XML (introduced in Oracle Database 10g Release 2).
To enable auditing, you have to use the AUDIT command on an object. For example, use the following command to start auditing on the table credit_cards:
audit select, insert, update, delete on ccmaster.credit_cards;
Setting the parameter AUDIT_TRAIL while creating the database also allows you to capture auditing for reasons other than security—such as collecting information on CPU and IO used by sessions that will be an input to the Resource Manager. So, next time you bounce the database, place the AUDIT_TRAIL parameter first.
Oracle Database 11g Release 2 introduced the audit trail purge, which allows you to maintain a sizeable audit trail.
A sample output may look like this (toward the end of the output):
USERHOST COUNT(1)
--------------- ----------
stccampas01 736
prodwpdb 1235stcdelpas01 2498
This is revealing—as you can see, most of the connections come from the client machine stcdelpas01, but the next maximum number of connections comes from prodwpdb, which is the name of the database server itself. This could be a surprise, because you may have assumed that the connections originate externally.
Well, the next question could be, “Who is accessing the database from the server directly?” Another piece of SQL gets you that information:
select os_username, username, count(1)
from dba_audit_trail
where userhost = 'prodwpdb'
group by os_username, username
order by 3
/
Here is sample output:
OS_USERNAME USERNAME COUNT(1)
----------- -------- --------
oracle SYS 100
oracle DBSNMP 123
oracle PERFSTAT 234
infrap DW_ETL 1986This output clearly reveals that OS user infrap runs something on the server itself and connects as DW_ETL. Is this normal? Ask the user. If you don’t get a reasonable response, it’s time to dig around some more. The point is to know everything about your users: who they are, where they are coming from, and what they do.
Another crucial piece of information you can obtain from audit trails is evidence of potential past attacks. When an adversary mounts an attack, he may not get the password right every time—so he may resort to a brute-force approach wherein he tries to repeatedly guess the password and then log in.
You can detect such an attack by identifying patterns of username/password combinations from the audit trail. The clue is the column RETURNCODE, which stores the Oracle error code the user raised when the connection attempt was made. If a wrong password were supplied, the user would raise the following:
ORA-1017: invalid username/password; logon denied
So, you should look for ORA-1017, as in the following SQL statement:
select username, os_username, terminal, userhost,
to_char(timestamp,'mm/dd/yy hh24:mi:ss') logon_ts
from dba_audit_trail
where returncode = 1017; Here is sample output:
USERNAME OS_USERNAM TERMINAL USERHOST LOGON_TS
--------------- ---------- --------------- --------------- ------------------
WXYZ_APP pwatson STPWATSONT40 STPWATSONT40 01/11/06 10:42:19
WXYZ_APP pwatson STPWATSONT40 STPWATSONT40 01/11/06 10:42:28
WXYZ_APP pwatson STPWATSONT40 STPWATSONT40 01/11/06 10:43:11
PERFSTAT oracle pts/5 prodwpdb 01/11/06 12:05:26
ARUP pwatson STANANDAT42 STPWATSONT40 01/11/06 14:09:20
ARUP pwatson STANANDAT42 STPWATSONT40 01/11/06 14:23:41Here you can clearly see who has attempted to connect with a wrong password. Many of the attempts could be honest mistakes, but others may require investigation. For instance, the OS user pwatson has repeatedly tried (and failed) to log in as WXYZ_APP from the same client machine in a short span of time. Immediately thereafter, pwatson attempted to log in as the user ARUP. Now, this is suspicious. Remember, most attacks come from legitimate users within the organization, so no pattern is worth glossing over.
Along the same lines, you can monitor attempted logins with presumably “guessed” userids.
select username from dba_audit_trail where returncode = 1017
minus
select username from dba_users;The output:
USERNAME
---------------
A
SCOTT
HRHere someone has attempted to log in as a user that does not exist (SCOTT, which you have judiciously dropped from the database). Who could that be? Is it an innocent user expecting erroneously to connect to the development database, or is it a malicious user probing to see if SCOTT exists? Again, look for a pattern and identify the human user who made this attempt. Don’t be satisfied until you get a satisfactory explanation.
Implications
Turning on auditing definitely affects performance. But the rudimentary level of auditing you have enabled in this step will have negligible performance impact, with benefits far outweighing the costs.
The other impact you should consider carefully is the storage of audit trails. The audit trail entries are stored in the SYSTEM tablespace, which grows in size as the audit trails lengthen. If the SYSTEM tablespace fills up and there is no more space for audit records, all database interactions fail. Therefore, you have to be vigilant about free space.
Action Plan
- Set the initialization parameter audit_trail to DB in the database and recycle it.
- Enable auditing for sessions.
- Extract information from audit trails and analyze it for patterns of attacks.
3.6 Create and Analyze Object Access Profiles
Background
Merely knowing usernames and associated properties such as OS usernames, the terminals they connect from, and so on is not sufficient, however. To properly lock down the database, you also have to know what users are accessing. This information allows you to create an object “access profile”—any deviation from which may indicate attack or intrusion.
Strategy
Again, the power of auditing is useful here. In the previous step, you enabled session-level auditing, which allows you to see session details. Now you have to enable object access auditing.
You may choose, for example, to audit access to objects that are very sensitive—such as tables where credit card numbers are stored, or procedures that return clear text credit-card numbers from encrypted values.
Suppose you want to audit anyone accessing the table credit_cards, owned by ccmaster. You could issue
audit select on ccmaster.credit_cards by access;
Subsequently, anyone who selects from that table will leave an audit trail.
You can record the information in two ways. In the first approach, demonstrated above in the keyword by “access,” a record goes into the audit trail whenever someone selects from the table. If the same user selects from the table twice in the same session, two records go into the trail.
If that volume of information is too much to handle, the other option is to record only once per session:
audit select on ccmaster.credit_cards by session;
In this case, when a user selects from the table more than once in a session, only one record goes into the audit trail.
Once auditing is enabled, you can analyze the trail for access patterns.
The trail looks different in each of the approaches. If auditing is enabled by session, you will see one record per session per object. The column action_name in this case will show SESSION REC, and the actions will be recorded in the column ses_actions.
select username, timestamp, ses_actions
from dba_audit_trail
where obj_name = 'CREDIT_CARDS'
and action_name = 'SESSION REC'
/
The output:
USERNAME TIMESTAMP SES_ACTIONS
------------------------------ --------- -------------------
ARUP 16-JAN-06 ---------S------Of course, you can also use other columns, such as os_username, terminal, and so on.
Note how the column ses_actions shows a series of hyphens and a letter S. This indicates that the user ARUP has performed certain actions that are recorded in the single record of the audit trail. The value follows a pattern, where each position indicates a specific action:
| Position | Action |
|---|---|
| 1 | Alter |
| 2 | Audit |
| 3 | Comment |
| 4 | Delete |
| 5 | Grant |
| 6 | Index |
| 7 | Insert |
| 8 | Lock |
| 9 | Rename |
| 10 | Select |
| 11 | Update |
| 12 | References |
| 13 | Execute |
| 14 | Not used |
| 15 | Not used |
| 16 | Not used |
In the above example, ses_actions shows the following:
---------S------
The S is in the 10th position, meaning that the user ARUP selected from the table credit_cards. However, it does not show how often the user selected from this table in this session, because you enabled for session only, not for access. If the user had also inserted and updated in the query, the column value would be this:
------S--SS-----
Note there are Ss in the 7th (Insert), 10th (Select), and 11th (Update) positions.
Why the letter S? It means that action by the user was successful. When you enable auditing, you can specify if the trail is to be recorded when the access was successful or unsuccessful. For instance, to record an audit trail only when the access failed for some reason (such as insufficient privileges), you can enable auditing as follows:
audit select on ccmaster.credit_cards by session whenever not successful;
Subsequently, when user ARUP successfully selects from the table, there will be no records in the audit trail. If the access is unsuccessful, there will be a record. The letter in the column ses_actions in that case would be F (for failure).
Similarly, if you want to audit only when the access is successful, you would substitute the clause “whenever not successful” to “whenever successful.” By default, both successful and unsuccessful accesses are logged if you do not specify the clause. So what happens if in a single session some accesses were successful but others were not? The letter in that case would be B (for both).
For example, here’s how the value would change along a time line for user ARUP, who does not have select privileges on the table credit_cards:
-
ARUP issues select * from CCMASTER.CREDIT_CARDS. - It fails, raising ORA-00942: table or view does not exist.
- A record goes into audit trail with the ses_actions value as ---------F------. Note the F in the 10th position, indicating a failure.
- ARUP is not disconnected from the session. The owner of the table credit_cards, CCMASTER, grants the select privilege to ARUP.
- ARUP now successfully selects from the table.
- The ses_action column value will now change to ---------B------. Note that the 10th position has changed from F to B (both success and failure).
After you have audited that object for a while and developed its access profile, you can turn off auditing for successful attempts and enable it for failed ones only. It’s usually the failed ones that reveal potential attacks. Auditing for failed ones only will also reduce the overall length of the audit trails.
In Oracle Database 11g Release 2, the behavior is different. Instead of just one record per session, several records are generated once per action. In the above example where the user performed three actions—insert, select, and update—there will be three records in the audit trail with action_name = SESSION REC.
Had you enabled auditing by access, you would have used a different query, because there would be one record per access. The column ses_actions would not be populated, and the column action_name would show the actual action (such as select or insert) instead of the value SESSION REC. So you would use the following:
col ts format a15
col username format a15
col userhost format a15
col action_name format a10
select to_char(timestamp,’mm/dd/yy hh24:mi:ss’) ts,
username, userhost, action_name
from dba_audit_trail
where owner = 'CCMASTER'
and obj_name = 'CREDIT_CARDS';
TS USERNAME USERHOST ACTION_NAM
----------------- ---------- --------------- ------
01/16/06 00:27:44 ARUP prodwpdb SELECT
01/16/06 11:03:24 ARUP prodwpdb UPDATE
01/16/06 12:34:00 ARUP prodwpdb SELECTNote that there is one record per access (select, update, and so on), which gives you much finer granularity for establishing a pattern of access—as opposed to session-level auditing, which merely shows that ARUP selected and updated from the table credit_cards but not how many times or when.
So, which type of auditing should you use—session level or access level? Remember, access-level auditing writes one record per access, so the amount of audit information written is significantly larger than when only one record per session is written. If you are just trying to establish who accesses the tables and how, you should turn on session-level auditing first. That should give you an idea about how each object is accessed by users. To track down abuse from a specific user, you can turn on access-level auditing.
Implications
As described previously, auditing does affect performance. However, the benefits of auditing may far outweigh the cost, especially if you enable it strategically. Moreover, you don’t need to keep it turned on forever; you can turn auditing on or off on objects dynamically if necessary.
Action Plan
- Identify key objects (tables, packages, views, etc.) that you want to audit (if not all of them).
- Turn on session-level auditing for those objects.
- After some time that you believe is representative of a typical work cycle, analyze the audit trails. The time you wait for the records to be gathered usually depends on your particular case. For instance, in the retail industry, you may want to wait for a month, which will generally capture all the processes—such as month-end processing, tallying of books, and so on.
- Once you develop the profile, track down unsuccessful attempts. Note the users and the objects they were attempting to access.
- Turn off session-level auditing and turn on access-level auditing for those objects only.
- Analyze the access pattern by highlighting the failed attempts, the time, the terminal it came from, and so on, and determine the reason behind the failed attempts. If there is no justifiable excuse, pursue the matter as a potential security breach.
3.7 Enable Auditing for Future Objects
Background
By now you’ve learned how to use auditing on specific, sensitive objects. You may also have decided to enable auditing for all objects, not a subset of them—perhaps you don’t know which ones are sensitive, or perhaps all of them are. In that case, there is a problem: Objects are created in the database continuously, and when they materialize, you have to remember to enable auditing on them.
Strategy
Default auditing is very useful here. To enable auditing on any object not yet created, you issue the following:
audit select on default by session;
Afterward, when you create a table in any schema, the auditing options are automatically enabled for select on that table. To check for the default auditing options set in the database currently, use the following:
SQL> select * from all_def_audit_opts;
ALT AUD COM DEL GRA IND INS LOC REN SEL UPD REF EXE FBK REA
--- --- --- --- --- --- ----- --- --- ---- -- - -- -- -
-/- -/- -/- -/- -/- -/- -/- -/- -/- S/S -/- -/- -/- -/- -/-Note under the column SEL that you have a value S/S. The left-hand value indicates the auditing option when the action is successful. Here it’s S, indicating “session level.” The right-hand part indicates when it’s not successful, which also shows S—indicating “session level” as well. As you didn’t specify when the auditing should be done, the option was set for both success and failure—hence the value S/S.
Suppose you want to enable default auditing on select at session level when successful and at access level when not successful? You would issue the following:
SQL> audit select on default by session whenever successful;
Audit succeeded.
SQL> audit select on default by access whenever not successful
Audit succeeded.Now if you see the default option, you will see this:
SQL> select * from all_def_audit_opts;
ALT AUD COM DEL GRA IND INS LOC REN SEL UPD REF EXE FBK REA
--- --- --- --- --- -- -- -- --- --- --- --- --- --- ---
-/- -/- -/- -/- -/- -/- -/- -/- -/- S/A -/- -/- -/- -/- -/-Here note the column SEL, which shows S/A—indicating session level (S) in success and access level (A) in failure.
This arrangement is common when you want to limit the number of audit entries under successful access, hence the session-level auditing for successful access. You would want, however, to track each occurrence of failed access; hence you have enabled access-level auditing for failures.
To disable default auditing, you would issue this:
noaudit select on default;
Later, you should check in all_def_audit_opts view to make sure the default audit options are indeed turned off.
Implications
With any auditing, there is always a performance concern, but the price may be small for the information obtained from it.
However, there is a potential hazard. As the default auditing is enabled for all objects created subsequently, without regard to who creates them and who selects from them, you as the DBA have no control over the audit options on a table. This situation may be exploited by an adversary, who can create objects indiscriminately, insert into them, select from them, and then finally drop them—all well within the quota imposed at the tablespace level.
However, the auditing is turned on for each created object, so the records keep building up in the audit trail, inflating the AUD$ table. Because that table is in the SYSTEM tablespace (unless you have moved it to a different tablespace in 11gR2), it will eventually fill up and kill the database, essentially creating a denial-of-service attack!
This situation may be rare, but it’s definitely possible. Fortunately, the prevention is simple: Just keep a close eye on the SYSTEM tablespace. If space runs out fast, explore why the audit records are being created so quickly. If you see a large number of objects created or selected that are not parts of the profile you built using auditing, you should definitely investigate.
As an immediate measure, you could turn off default auditing and then turn off auditing on those objects that crowd the audit trail entries (which can be done online). Then you should delete the records from the audit trail after storing them on a table in a different tablespace for future analysis.
Action Plan
- Decide what actions on which you want to enable default auditing.
- Decide what level—session or access—you want the default auditing to be.
- Enable default auditing.
3.8 Restrict Access from Specific Nodes Only
Background
In many cases, only a specified set of client machines will connect to your database servers. Here is a typical architecture:
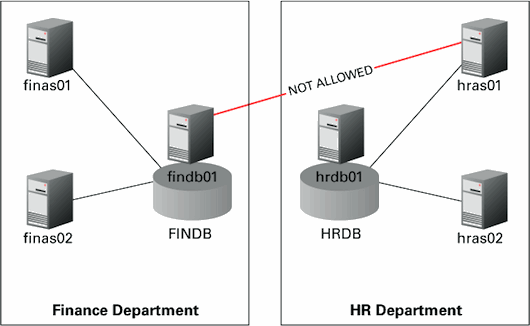
Here, the database servers are findb01 and hrdb01, with databases named FINDB (financial database) and HRDB (HR database). The clients in the HR department connect to HRDB only; if they need some data from FINDB, they connect to the applications running on the finance department servers and get the data. Similarly, the application servers in the finance department never connect to HRDB directly.
What happens if a client in the finance department, finas01, tries to connect to HRDB? It will be able to successfully connect, provided that it knows a valid userid and password. As always, you should protect user passwords, but sometimes there are generic users with well-known passwords. Some examples are application users such as HRAPP with a ridiculously insecure password such as hrapp, password, or even abc123. Even with password management policies (described in Phase 4) in place, the password could be well known.
So, you have to build a wall around your servers so that no client machine outside the authorized list of machines can connect to them.
Strategy
How can you ensure that only client connections from the HR department are allowed into the database HRDB? You have two options: login triggers and listener node validation.
Login triggers. In this option, you create a trigger that fires at login, checks the IP address, and fails if the IP address is not in a list of approved ones. Here is the trigger:
1 create or replace trigger valid_ip
2 after logon on database
3 begin
4 if sys_context('USERENV','IP_ADDRESS') not in (
5 '100.14.32.9'
6 ) then
7 raise_application_error (-20001,'Login not allowed from this IP');
8 end if;
9* end;In line 5, you can place all the IP addresses that are valid client machines enclosed in quotes and separated by commas. After this trigger is in effect, when SCOTT tries to connect from an IP address not in the list in the trigger, here’s what occurs:
$ sqlplus scott/tiger@hrdb
ERROR:
ORA-00604: error occurred at recursive SQL level 1
ORA-20001: Login not allowed from this IP
ORA-06512: at line 5Note the error “ORA-20001: Login not allowed from this IP,” which was placed in the trigger. You can make this message as descriptive as you like. You can also make the trigger more robust to collect useful information such as recording such attempts in a table.
Note a very important point, however: Because login triggers do not fire for a DBA user, they do not prevent someone from logging in as a user with the DBA role enabled. This risk is not as bad as it sounds; you may, in fact, want to let DBAs log in from any client machine.
Listener node validation. The other option is to disable the login attempt at the listener itself. The connection attempt to the database server is disallowed by the listener, so there is no need for a trigger. To enable node validation, simply place the following lines in the file $ORACLE_HOME/network/admin/sqlnet.ora on server hrdb01:
tcp.validnode_checking = yes
tcp.invited_nodes = (hrdb01, hras01, hras02)Here you have specified the client machines (hras01 and hras02) that are allowed to connect to the listener. You can also specify the hostnames as IP addresses. Place all the node names on a single unbroken line (very important) separated by commas. Don’t forget to add the database server name (hrdb01).
After restart, if a client attempts to log in from a machine other than hras01 or hras02, he gets this error:
$ sqlplus scott/tiger@hrdb
ERROR:
ORA-12537: TNS:connection closedThis rather nonintuitive error is raised because of the filtering that occurs at the listener level. As the listener itself terminates the connection attempt, you get a “connection closed” error. This error occurs even if the user has the DBA role, because the attempt has not yet reached the database. Node validation is a very powerful feature. (For more information, read my blog article “Building a Simple Firewall Using Oracle Net.”)
So, which option should you choose to prevent unwanted clients from connecting? Let’s examine the pros and cons:
- Node validation works at the listener level, so all users are stopped from connecting—even the ones with DBA roles. This may or may not be desirable. For instance, if you have a DBA tool installed on your laptop and your laptop has DHCP enabled—which assigns a new IP each time it connects to the network—you can’t place the IP address in the list of valid nodes; hence, you will not be able to connect.
- Node validation requires the listener to be restarted. For the brief moment that the listener is down, clients will not be able to connect. Although this may not be an issue, you should be aware of it. Every time you change the list of valid nodes, you will have to restart the listener.
- If you want to disable node validation temporarily, you should put tcp.valid_node_checking=no in the file sqlnet.ora and restart the listener. In the case of a login trigger, all you have to do is disable the trigger. You can re-enable it later when required.
- In node validation, you can place all the allowed clients on one line, but on one unbroken line only. If the list is too long to fit on one line, then you can’t use this approach. Conversely, the trigger approach has virtually no limitations. Or, you can use another feature called Connection Manager to limit IP addresses more than one line long.
- You have to use specific IP addresses or hostnames in node validation—no wild cards such as “10.20.%.%”, indicating all clients in the subnet 10.20. To accomplish this, you can use either wild cards in the trigger approach or Connection Manager.
- The trigger approach lets you build a sophisticated tracking system wherein you can write to some tracking table for all attempts, successful or denied. In node validation, there is no such facility.
- In the trigger approach, you can control access based on parameters other than IP—such as the time of day, the user connecting, and so on. Node validation reads only the IP address.
- Remember, node validation stops attempts at the listener level; the database connections are as yet not attempted. Hence, if you have enabled auditing on failed login attempts, they would not be registered.
- Because node validation works at the listener level, the potential adversary does not even get into the database, making denial-of-service attacks more difficult. This is a huge advantage for node validation over the trigger approach.
You should decide on your approach after considering the above differences. In general, if the only objective is to stop connections from IP addresses without any other functionality such as tracking those unsuccessful attempts, node validation is a quick and simple method. If you want more-sophisticated functionality, then you should look into login triggers.
How do you know which IP addresses to block and which ones to allow? Perhaps this assumption is too simplistic; in reality, the list of client machines will be long and difficult to track. Here is where your previous research comes in handy. Remember, in Phase 2, that you captured the IP addresses from which the users connect by mining the listener log. In that step, you must have generated a list of valid client IP addresses or hostnames. That list is what you need now.
Implications
The implications can be quite serious; if you haven’t done your homework, you may block a legitimate client.
Action Plan
- From Phase 2 Step 1, get the list of valid IP addresses or hostnames of client machines.
- Decide on the approach to use—trigger based or node validation.
- Implement the plan.
- Monitor closely for several days, preferably a full cycle such as a week or a month, as appropriate in your organization.
- Fine-tune the approach by adding or removing nodes from being filtered.
3.9 Institute Periodic Cleanup of Audit Trails
Background
Over a period of time, the audit trail grows quickly in size depending on the extent of the auditing. Like all things that grow rapidly, it needs frequent trimming, especially after you have examined the records and have no need for them.
There are several types of audit trails—the database audit trail (in the table AUD$), the fine-grained audit (FGA) trail (in the table FGA_LOG$), the OS audit trail (which are regular files in the file system), and the XML audit trail (which are just XML files in the file system)
Strategy
You can delete the audit trails based on the source. The database and fine-grained audit trails can be deleted by connecting as SYS and issuing the following:
SQL> delete aud$;
SQL> delete fga_log$;Don’t forget to commit after the statements. Because these are regular delete operations, they generate a large amount of redo and undo
To avoid the generation of redo and undo, you may truncate the tables rather than deleting. Bear in mind that the only Oracle-recommended method for truncation is making sure the audit trails are not being written while truncating the tables.
So, you should shut down the database, change the audit_trail parameter to none, and restart the database. After that, issue the following (as SYS):
SQL> truncate table AUD$;
Remember, truncate is a DDL operation; you can’t undo it. After that, reset the audit_trail parameter to DB and restart the database for normal operation.
For fine grained audit trails, you can truncate the table FGA_LOG$ at the same time as AUD$, if desired. For FGA, however, there is a slightly more flexible way. You can simply disable the FGA policies and then truncate the trail, without shutting down the database. Beware of the fact that while the policies are disabled, the fine-grained auditing is disabled too, and actions during that stage are not audited.
To remove the OS files and XML files, you can simply use the rm command. To remove files older than seven days, you could write a script like this:
DAYS=7
AUDIT_FILE_LOC=/u01/oracle/admin/PRODB/audit
find ${AUDIT_FILE_LOC} -name "*.log" -ctime ${DAYS} -exec rm {} \;Set the location of audit trail files and days after which to remove them in the variables.
Technically, you can remove the trail records by issuing the truncate command against AUD$ and FGA_LOG$ tables even when the database is under normal operation; but you risk losing records that may not have been examined. While the database is not being accessed, the trail contents remain static, making sure the truncate command performs a consistent operation.
Oracle Database 11g Release 2 offers a new way of managing the audit trail cleanup, via a package dbms_audit_mgmt. First, you have to initialize the cleanup operation as shown below:
begin
dbms_audit_mgmt.init_cleanup(
audit_trail_type => dbms_audit_mgmt.audit_trail_all,
default_cleanup_interval => 7*24 );
end;
/
This is done only once. This tells that the cleanup will occur in 7*24 hours—in other words, at weekly intervals. The trail type is set to ALL types—in other words, database audit logs, FGA logs, OS files and XML files
Now you can create a Scheduler Job that will purge the trail in weekly intervals
begin
dbms_audit_mgmt.create_purge_job (
audit_trail_type => dbms_audit_mgmt.audit_trail_all,
audit_trail_purge_interval => 7*24,
audit_trail_purge_name => 'all_audit_trails_job'
);
end;
/
If the audit trails are too large, you can set a property called delete batch size, which sets the number of records the job will delete in one shot. Here is how you set the batch size to 10,000.
begin
dbms_audit_mgmt.set_audit_trail_property(
audit_trail_type => dbms_audit_mgmt.audit_trail_aud_std,
audit_trail_property => dbms_audit_mgmt.db_delete_batch_size,
audit_trail_property_value => 10000);
end;
/
If you have enabled FGA you can set the delete size of those logs as well:
begin
dbms_audit_mgmt.set_audit_trail_property(
audit_trail_type => dbms_audit_mgmt.audit_trail_fga_std,
audit_trail_property => dbms_audit_mgmt.db_delete_batch_size,
audit_trail_property_value => 10000);
end;
/ In the beginning, you can choose to manually delete the audit trails as a one-time effort. This will leave less amount of trail for the purge job. Here is how you can purge the available trails manually:
begin
dbms_audit_mgmt.clean_audit_trail(
audit_trail_type => dbms_audit_mgmt.audit_trail_all
);
end;
/Implications
Because under the covers this is a normal delete operation, redo and undo will be generated, which could be substantial based on the amount of records deleted. Needless to say, you should perform this purge operation in a time period when the stress on the database is low.
Once the purge is completed, the audit trails will be gone. So, you should have created all the reports or archived these to a different place.
Action Plan
- Archive the audit trails to a different place if needed.
- Perform a one-time manual delete.
- Institute a purge process, which varies depending on the version of the database.
- Make sure you handle both database audit records (regular and FGA) and OS files (regular and XML)
- Set the delete batch size for the purge process.
The content provided here is for instructional purposes only and is not validated by Oracle; use it at your own risk! Under no circumstances should you consider it to be part of a consulting or services offering.