应对大数据的挑战
为了提高流程效率、盈利能力和产能,企业和政府机构无不面临着前所未有的庞大信息量。鉴于此,各组织开始考虑采用强大的数据存储解决方案来满足其信息存储和检索需求,而这其中不乏超大型数据库 (VLDB) 的身影。最近几年数据的指数级增长催生了全新的存储技术。与此同时,在大数据存储和管理领域,企业数据库和相关的补充性技术都受到了人们的广泛关注。
大数据是由四个关键特性来定义的:数据量、速度、多样性和价值。对于 IT 经理来说,数据量和速度并不是新出现的问题;它们现在只是被放大了。而多样性和价值密度过低才是导致大数据引发新问题的显著特性。不同于传统的交易数据,大数据可采用许多不同的格式。它通常具有极低的密度;对其进行单次观察无法获取大量价值。但是,聚合和分析这类数据却可以得到意义重大的趋势。

全球性数据爆炸在一定程度上是由技术驱动的,数字视频、音乐、智能手机以及互联网的发展都使这一问题得到进一步加剧。举例来说,当浏览器成为通用客户端之后,出现了数以亿计的互联网用户的点击流数据。随着社交网络规模的显著增长,数据挖掘对象的数量已达到上亿级别。可为基于位置的服务提供相关信息的智能手机发展迅猛,其用户数量即将超过十亿。从 Web 服务器日志、仪器仪表数据流、实时交易数据、博客以及 Twitter 和 Facebook 等社交媒体中,我们都能提取出有价值的信息。
如今,得益于 CPU 和存储成本的不断降低,许多组织都有足够的预算来处理 TB 级甚至 PB 级的数据集,因而能够从大数据中获益。
1“大数据,大影响:国际发展新机遇”,世界经济论坛
利用大数据,组织能够更加深入地理解自己的用户、客户群、业务运营、供应链,甚至所处的竞争环境或监管环境。如果处理得当,大数据将对收入和盈利产生积极的影响,使组织能在改进的商务智能的基础上提供更好的服务、制定更好的决策。通过分析大数据,组织可以建立和完善先进的预测分析解决方案,从而降低成本并获得可持续的竞争优势。
如果组织能通过大数据增强对客户和用户的了解,政府和相关行业也将从中获益。举例来说,零售行业生成的数据集可用于点击流监测和消费舆情分析,以及为在线客户提供相关建议。在金融服务业,加强对客户的认知可实现欺诈检测和预测,还能通过分析消费习惯提高单位客户利润率。此外,在公共和私人医疗保健领域,大数据有望帮助组织降低成本、提高效率,从而为病人提供更加优质的护理服务。
或许是考虑到大数据的优势和实用性,许多业内分析人士都预测大数据技术和服务市场将保持快速增长的势头。

2 IDC“Worldwide Big Data Technology and Services 2012-2015 Forecast”,文档编号 #233485,2012 年 3 月
在大数据的影响下,决策制定技术将发生翻天覆地的变化。组织需要分析不同的数据源,如社交媒体、视频、智能移动设备等,并对其中的数据进行整合以补充到企业数据库中。为涵盖大数据而产生的信息架构的演变很可能会成为新一代企业基础设施的基础。
要利用这些不同的数据来源制定决策,组织必须建立起一个有效的大数据策略,做好大数据的获取、组织和分析工作,并由此产生新的业务洞察,制定更加明智的决策。
大数据完善过程中的每一步都要求使用与当前任务相匹配的、合适的硬件和软件。为满足大数据的规模需求和各种不同的分析需求,组织可以扩容现有的数据仓库基础设施。但是,在获取和组织新数据类型的初始阶段,一些新的软件必不可少。在这类软件中,Apache Hadoop 是最引人注目的一款产品。
Hadoop 包含两个重要的组件:用于数据存储的 Hadoop 分布式文件系统 (HDFS) 和用于管理数据处理的 MapReduce 编程框架。借助 Hadoop 工具套件,企业可以组织原始(通常为非结构化的)数据并对其进行转换,以便将它们加载到数据仓库和数据集市中进行综合分析。
Hadoop 支持并行处理大数据集,因此可以让计算机集群或网格来处理大数据负载。它主要在 HDFS 上运行,HDFS 具有容错性,可扩展至带有数千个节点的多个集群上。而 Hadoop MapReduce 提供了使用大量处理器分析大型数据集的能力。举例来说,雅虎的研究人员曾在一个由 3800 个节点构成的集群上运行 Hadoop MapReduce,用 16.25 个小时完成了对 1 PB 数据的排序。尽管 Hadoop MapReduce 非常适合解决键/值数据集的问题,但是却难以应对需要复杂数据或事务的操作。

大数据的来源多种多样,其中包括人类活动产生的数据和机器生成的数据。从线上活动、RFID、仪器仪表、社交媒体、点击流和交易系统等数据源中获取数据时需面对事务量巨大、数据流速度极快、数据格式种类繁多等挑战。从各种不同的系统获取数据所需的延迟也各不相同,交互式系统在提供服务时要求响应速度达到亚秒级,而采用批处理方式的系统则会存储数据,便于以后进行离线分析。
内容的多样性往往要求软件能够在高吞吐量的情况下同时处理结构化和非结构化数据。一个有效的大数据解决方案必须具有足够的存储和处理能力,确保能够收集、组织和提炼大量数据,甚至是 PB 级的数据。
组织需要理清计划存储的数据类型和今后使用数据的方式,以便为新数据选出正确的存储技术。虽然市场上存在许多针对特定场景进行了优化的专业存储技术,但是最主要的用例有两种。
倾向于批处理且对响应速度、更新和查询需求较低的系统通常使用 Hadoop 分布式文件系统 (HDFS)。而当时间限制更严格,应用程序要求查询响应时间达到亚秒级,或者需要频繁更新现有数据时,通常使用某种形式的 NoSQL 数据库。
Amazon、Google、LinkedIn 和 Twitter 等公司在严格的延迟限制下还要努力应对空前的数据量和操作量,在此情形下,NoSQL 技术应运而生。通过利用结构化和半结构化数据源来开发新的业务分析模型,分析诸如网站点击流的大量实时数据能获得重要的业务优势。因此,这些企业便以十年的分布式散列表 (DHT) 研究为基础,利用传统关系数据库系统或嵌入式键/值存储数据库(如 Oracle Berkeley 数据库),开发出高可用的分布式键值存储技术。

从大数据中发掘价值的过程是一个将原始数据提炼为有价值信息的多阶段过程。数据获取,例如从点击流和社交媒体信源中提取数据,是对数据进行转换和组织以发掘商业价值的前提。之后的预处理过程将剔除价值较低的数据,并对余下的数据进行结构化处理以用于分析。由于大数据形态多样、大小不一且格式各异,因此这一转换过程是将数据移入分析环境的重要先决条件。

提炼过的大数据可与您的企业数据一同进行分析。在得到原始数据之后,企业可以使用 Hadoop 分布式文件系统 (HDFS) 或 NoSQL 数据库等平台将数据存储起来,并在进行预处理后将其加载到分析环境中,例如在 Oracle Exadata 数据库云服务器上运行的数据仓库。通常情况下,此类负载由 Apache Hadoop 处理。
组织已经通过建立数学模型和长时间筛选海量数据获取了实用的信息。完成提炼过程后,大数据会扩展现有的模型,并极有可能为使用数据仓库的商务智能应用程序提供全新的、丰富的洞察。

数据仓库是大数据分析的关键。尽管数据的来源多种多样,但针对所有数据的综合分析可提供全新的洞察。因此,现代数据仓库已经成为一个综合性的信息库,其中不仅要存储传统的企业数据,还要存储由 Hadoop 创建的汇总数据。
新的数据源是全然不同的 — 数据的可理解性较低,精确性先天不足,或者仅与问题间接相关。因此,为了发掘大数据的价值,我们必须转向一种迭代的、不断完善的分析过程。每一次迭代或者揭示新的洞察,或者仅仅让分析人员解决特定的疑问。大数据分析不仅关乎充分理解数据集并就此做出报告,还需要揭示新的关系。
尽管传统分析工具的重要性毋庸置疑,但涉及统计分析和数据挖掘的高级分析是充分发挥大数据价值的必不可少的工具。开源的 R 统计编程语言自 1997 年发展至今吸引了大量用户。这种语言不仅在分析人员和数据科学家中广受欢迎,而且还广泛应用于学术领域,因此训练有素的开发人员大有人在。
一项称为预测分析的统计技术已在多个行业中获得了长足的发展,这些行业包括金融、零售、保险、医疗保健、制药和电信。这种技术可以利用客户数据来构建和优化预测模型。举例来说,组织可以使用预测工具来指导营销活动和提高工作效率。预测分析的兴起得益于计算能力的不断提升。借助如今的工具,预测分析可以创建复杂的模型并在大量数据集上执行各种场景。
在如今数据泛滥的环境下,我们可以使用强大的工具来提取数据和展现信息,从而制定更加明智的决策。借助自动化分析,我们可以制定由数据驱动的决策。此外,我们还可以将大数据转换为切实可行的洞察并通过合适的技术实现实时转换。
可视化和商务智能信息板是功能强大的决策辅助工具,它们在处理大量数据时的表现尤为突出。统计软件是数据分析、商务智能和决策支持的关键要素。运行 R 统计分析语言脚本的 Web 界面可以集成到信息板中,为决策过程提供分析和数据流图形。
大数据的信息量和速度对数据分析和商务智能工具的可伸缩性和性能提出了新的要求。服务器容量、高速互联能力和网络带宽的提升促成了新一代软件的兴起,使它们可以实现内存中、数据库中的实时分析。
举例来说,内存数据库可支持实时决策。现代系统的 64 位寻址能力意味着我们可以配置搭载 1 TB 内存的服务器。同时,这种能力也意味着可以将数据库(甚至一些包含十亿行以上数据记录的数据库)加载到内存中,从而维持快速决策所需的高性能和低延迟处理。
1 Brynjolfsson、Hitt 和 Kim,“Strength in Numbers:How Does Data-Driven Decision Making Affect Firm Performance?”(2011 年 4 月 22 日)。
Oracle 提供了一个功能强大的软件体系,其中包含的一些新功能是专为应对大数据带来的新挑战而设计的。所有组件既可以在 Oracle 集成式系统上运行,也可以在客户集成的硬件上运行。
架构和性能需求不同的应用程序对数据存储和检索功能的需求也各不相同。许多大数据应用程序都需要快速、精简并且能对大量数据进行交互式查询和更新操作的数据存储。
Oracle NoSQL 数据库可以快速获取和组织无模式、非结构化或半结构化数据。它是一个“始终可用”的分布式键值数据存储库,具有查询延迟可预测、查询响应快速的特点,能支持多种交互式用例。此外,它还提供了一个简单的编程模型,可轻松集成到新的大数据应用程序中。
Oracle Endeca Information Discovery 是一个企业数据发现平台,可对复杂和多样化的数据执行高级挖掘和分析操作。该解决方案从多个不同的源系统中加载信息,并将信息存储在一个可对变化的数据提供动态支持的分面数据模型中。用户可通过交互式和可配置的应用程序对这些经过集成的丰富数据进行搜索、挖掘和分析。Oracle Endeca 提供了一个直观的界面,可帮助业务用户轻松地挖掘大数据,以确定其潜在价值。

Oracle Data Integrator 可对 Oracle 数据库、Oracle 管理软件和其他第三方应用程序源进行数据提取、加载和转换 (E-LT)。Oracle GoldenGate 支持实时转换大量数据,并可将数据加载到数据仓库或数据集市中。这些产品与 Oracle Big Data Connectors 一起提供了一种 Oracle 独有的大数据集成解决方案。在大数据爆炸的时代,这些产品越来越凸显出自身的重要性,因为孤立的大数据是毫无使用价值的。
Oracle 开发出了一套可轻松集成 Oracle 数据库与 Hadoop 的软件。Oracle Big Data Connectors 随 Oracle 大数据机一同提供,同时,也可作为独立的软件产品供用户使用。借助这套软件,用户能够更加方便地从 Oracle 数据库访问 Hadoop 分布式文件系统 (HDFS),也能轻松地从 Hadoop 向 Oracle 数据库加载数据。此外,这套软件还为 HDFS 与 MapReduce 框架提供了本机 R 接口,可支持 Oracle Data Integrator 生成 Hadoop MapReduce 程序。
大数据和分析经常相伴而行,这是因为随着技术的发展进步,我们已经能够分析越来越大的数据集。在这些技术进步中值得一提的是,Oracle 数据库能够将分析功能嵌入到数据库中,从而通过一个架构解决方案来提供可伸缩性、性能和安全性。这一架构可减轻 RAM 有限的计算机处理分析工作的负载,并使分析处理更加贴近数据。这将减少不必要的网络往返、有助于充分利用企业级数据库,并能降低硬件成本。
Oracle Advanced Analytics 将 Oracle 数据库转变为一个先进的、支持大数据分析的分析平台。该产品集 Oracle Data Mining 与 Oracle R Enterprise(开源 R 统计编程语言的增强版)两者的功能于一体。使用 Oracle Advanced Analytics 时,系统无需在数据库与执行分析处理的外部客户端之间编组数据,因而消除了网络延迟。与在数据库外部进行处理相比,这可以实现 10 倍到 100 倍的性能提升。通过将分析逻辑封装在数据库中,数据库的多级安全模型将发挥出重要的作用,并且数据库也因此能够管理实时预测模型和相关的结果。
Oracle 的软件体系是强大的集成式系统产品线的基础,可帮助您快速获取新洞察并发挥大数据的价值。

1 “Oracle 通过 Cloudera [Oracle Enterprise Manager] 协议主流化其 Hadoop 平台”,Tony Baer,Ovum,2012 年 1 月。
借助 Oracle 的集成式系统,组织可以将大数据解决方案作为对操作系统、数据仓库、分析和商务智能处理的补充。集成式系统经过预先集成,更易于部署和支持,并且可提供优化的性能。它们既可以单独部署,也可以部署到现有的基础设施中。
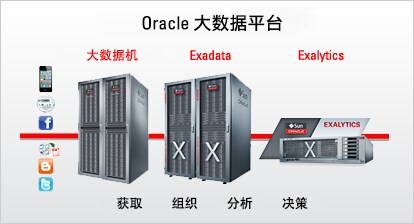
Oracle 大数据机是一个全面的、支持企业环境的软硬一体式系统,可让企业轻松开始部署大数据解决方案。该产品通过 Hadoop 和 Oracle NoSQL 数据库获取数据,使用 Hadoop MapReduce 算法组织数据,并将数据加载到数据仓库中进行综合分析。
Oracle 与 Cloudera 联手在 Oracle 大数据机中融入了 Cloudera Distribution。这将确保客户能够访问经过全面集成且广受支持的 Hadoop 发行版,该版本可在拥有数万个节点的生产环境中部署,能加快部署速度并降低拥有成本。
Oracle Exadata 数据库云服务器是先进的软硬件一体式系统,不仅易于部署、极具可伸缩性,而且具备安全性和冗余性。借助 Exadata 智能扫描、Exadata 智能闪存缓存和混合列压缩等创新技术,Exadata 可为数据仓库、联机事务处理和混合负载提供极限性能。Oracle Exadata 采用大规模并行架构和高速 InfiniBand 网络,可维持数据库服务器、存储服务器以及其他集成式系统(例如 Oracle 大数据机和 Oracle Exalytics)之间的高带宽链路。

Oracle Exadata 支持巨型数据仓库的部署,以及揭示新关系、获取新洞察所需的迭代式分析。实施这种全新的分析方法后,决策者可据此采取措施,实现商业价值。

Oracle Exalytics 商务智能云服务器是一个集成的硬件和软件解决方案,可通过内存中分析实现快速决策,且能维持较低的预算。该产品在部署后可支持需求预测、收入和收益管理、定价、库存管理以及大量其他应用程序。此处,还可以通过高速 InfiniBand 链路将其连接至 Oracle Exadata 上的数据仓库,为访问大型数据仓库的商务智能应用程序提供实时分析。
Oracle Exalytics 商务智能云服务器可提供“快如闪念的分析”。这将从根本上改变企业与 BI 软件之间的交互方式,让企业能够更加充分地利用数据并创造出更多商业价值。
为了从大数据中获得真正的商业价值,企业需要适当的工具来从不同的数据源中捕获和组织多种类型的数据,并且要能轻松地将这些数据融入到现有的企业数据中,将这些数据与企业数据一同进行分析。Oracle 的集成式系统和补充性软件提供了一个端到端的价值链,可帮助您充分发挥大数据的价值。















Oracle Exadata 数据库云服务器 X2-2 全机架配置提供了一个由 8 个双处理器数据库服务器构成的数据库网格,共有 96 个处理器内核和多达 1152 GB 的 RAM。它还提供了一个由 14 个 Exadata 存储服务器构成的网格,搭载 504 TB 的磁盘存储空间和 5.3 TB PCI 闪存缓存。Oracle Exadata 数据库云服务器 X2-8 全机架配置提供两个 8 处理器数据库服务器、160 个处理器内核和 4 TB 的 RAM。它还配备了 14 个存储服务器,搭载 504 TB 的磁盘存储和 5.3 TB 的智能闪存缓存。
大数据应用程序使 I/O 性能变得越发重要 — I/O 带宽越高,数据密集型应用程序的执行速度就越快。Oracle Exadata 数据库云服务器可搭载高性能或高容量磁盘驱动器。闪存与高性能磁盘相结合可实现出众的 I/O 性能。智能 PCI 闪存缓存可将随机 I/O 的速度提升 30 倍。在全机架配置中,高性能磁盘的带宽可达到 25 GB/秒,闪存缓存对非压缩数据执行 SQL 操作时的带宽可达到 75 GB/秒。此外,高性能磁盘的处理能力可达每秒 50000 次 I/O 操作 (IOPS),而 Exadata 的闪存缓存可达 150 万次 SQL IOPS。
当服务器处理大型数据库时,数据压缩可同时提供存储和性能优势。Oracle Exadata 提供了混合列压缩技术,可为数据仓库提供 10 倍的压缩率,并能为归档提供 15 至 50 倍的压缩率。数据将以压缩形式接受扫描,并以压缩形式保存在闪存缓存中。
Oracle Exalytics 商务智能云服务器是一个集成的硬件和软件解决方案,可支持低延迟、高性能的建模和分析。该系统可通过 40 Gb/秒的高速 InfiniBand 链路连接至 Oracle Exadata 机架和 Oracle 大数据机,从而为大数据应用程序提供实时分析。
它提供了一个机架安装式服务器,搭载 1 TB RAM、3.6 TB 硬盘驱动器、40 个 Intel 处理内核,并采用高速互联技术。通过私有 InfiniBand 链路与 Oracle Exadata 数据库云服务器相连,Oracle Exalytics 即可高速访问数据仓库或运营数据库。InfiniBand 结构还可以实现高性能互联,从而打造 Oracle Exalytics 商务智能云服务器集群。
Oracle Exalytics 的主要功能包括内存中列压缩、内存中分析、优化的存储块访问和自适应的内存缓存。Oracle Exalytics 会通过试探来让缓存适应分析负载的变化以及确定内存中存储的内容。
Oracle Exalytics 商务智能云服务器包括 Oracle TimesTen In-Memory Database for Exalytics 和 Oracle Business Intelligence Foundation Suite。Oracle Business Intelligence Foundation Suite 是 Oracle 丰富的分析解决方案(包括 ERP 分析、CRM 分析、行业分析和 EPM 分析)中的重要的一支。
Oracle Exalytics 还提供了另一种数据库解决方案,即内存优化版本的 Oracle Essbase OLAP 服务器。Exalytics 的两种内存数据库都支持并行查询操作,可通过分布式负载获得优化的性能。它们的数据管理引擎都支持一些执行高性能分析的技术。
采用 Exalytics 分析解决方案的另一个优势在于它能够利用成熟、符合标准的接口来访问和操作多维数据。Oracle Exalytics 商务智能云服务器支持 SQL 数据访问、ODBC 和 JDBC 的实际行业标准。它还支持多维查询表达式,允许用户操作 OLAP 多维数据集中的多维数据。
商务智能是一项数据密集型活动,需要解决问题的工具和报告工具。Oracle Exalytics 为各种 Oracle BI 及 EPM 管理软件提供了先进的建模、分析和可视化功能。Oracle BI 管理软件的 8000 个预置资产中包括信息板、报告工具和指标功能。
Exalytics 软件(例如 Oracle Business Intelligence Foundation Suite)内置增强特性,可利用内存计算功能提升响应能力和交互性。为了确保易用性,Oracle Exalytics 还提供了一个演示建议引擎,可为数据集提供可视化建议。
此外,Oracle Exalytics 还可以使用移动设备实现身临其境的体验。Oracle Business Intelligence Foundation Suite 为 Apple iOS 设备(包括 iPad 和 iPhone)提供了移动商务智能支持。同时,Oracle Business Intelligence Enterprise Edition 中的所有可用功能都适用于移动用户,无需用户编写任何自定义的代码。
Oracle NoSQL 数据库的用例包括具有以下特点的场景:高速数据捕获、大量简单查询、大量的随机读取和超大型半结构化或非结构化数据信息库。Oracle NoSQL 数据库可出色地完成传感器数据捕获、针对 Web 应用程序的点击捕获、以及用于移动设备监视及备份的统计分析和网络捕获。此外,Oracle NoSQL 数据库还能为可伸缩的身份验证、实时通信、社交媒体和个性化功能提供数据服务。
Oracle Data Integrator 可从原有数据源中提取数据,这些数据源包括联机事务处理、联机分析处理、运营数据库和应用程序数据源。它可以将数据推入数据仓库、规划系统或其他应用程序。Oracle Data Integrator 公开了一些开放的 API 和开放的 XML 知识模型。它支持集成 SAP、Oracle 管理软件和 Oracle Golden Gate CDC(针对实时捕获改变的数据)管理软件。该产品采用 100% 的 Java 代码编写,可嵌入式 Java 代理的内存占用非常小,并且可直接在数据仓库硬件或预备服务器上运行。Oracle Data Integrator 采用针对 DBMS 进行过优化的原生 SQL,并且它的图形界面可简化集成处理过程。
对于需要大数据处理功能的处理场景,Oracle Data Integrator 可使用 Oracle Loader for Hadoop 优化数据加载。通过使用知识模型来控制流程,Oracle Data Integrator 可以将数据加载到 Hadoop 分布式文件系统 (HDFS) 中、转换 HDFS 数据、将其附加到现有 HDFS 数据中,并将 HDFS 数据集成到 Oracle 数据库中。
开发 Hadoop MapReduce 作业需要高级编程技巧。但是,Oracle Data Integrator 和 Oracle Data Integrator Application Adapter for Hadoop 可在 Oracle Data Integrator 内提供原生 Hadoop 集成,从而减少开发自定义 MapReduce 作业的需求。它采用可驱动 Hadoop 的知识模块创建和发起 Hadoop 作业,以执行数据验证和数据转换,并将数据加载到 Oracle 数据库中。
Oracle Data Mining
Oracle Data Mining 提供了一些可作为原生 SQL 函数运行的算法,能在构建和执行模型时实现更高的性能。它提供了一个丰富的开发环境,专用于创建预测分析应用程序。此外,您还可以使用它的图形界面实现工作流的自动化。作为对 Oracle SQL Developer 的扩展,Oracle Data Mining 可帮助数据分析人员创建专用于解决问题的分析工作流。它可以生成相应的 SQL 代码来部署和自动执行分析方法 — 一切都在 Oracle 数据库内部完成。Oracle Data Mining 模型采用了 Oracle Exadata 的智能扫描技术。它还可以将 SQL 谓词和大量 Oracle Data Mining 模型推送至存储服务器,从而减轻数据库服务器的负载。
Oracle Data Mining 提供了 12 种强大、高性能的数据库中数据挖掘算法,并且支持挖掘星型模式、事务数据和文本等非结构化数据。
 |
 |
 |
 |
 |
 |
 |
| 问题 | 算法 | 适用性 |
|---|---|---|
| 分类 | Logistic 回归 (GLM) 决策树 贝氏 支持向量机 |
传统统计技术 流行/规则/透明度 嵌入式应用 宽泛/狭窄的数据/文本 |
| 回归 | 多重回归 (GLM) 支持向量机 |
传统统计技术 宽泛/狭窄的数据/文本 |
| 异常检测 | 一类 SVM | 缺少目标领域的示例 |
| 属性重要性 | 最短描述长度 (MDL) | 属性精简 识别有用的数据 减少数据噪声 |
| 关联规则 | Apriori | 市场组合分析 链接分析 |
| 集群化 | 分层 K 均值 分层 O 集群 |
产品分组 文本挖掘 基因和蛋白质分析 |
| 特性提取 | 非负矩阵因式分解 | 文本分析 特性精简 |
此外,每一个 Oracle 数据库都提供了 50 多个内置的 SQL 统计函数。这些 SQL 函数支持汇总和比较分析,例如平均值、中值、偏度、峰度、t 测试、F 测试、皮尔逊相关性、分布拟合、方差分析等。Oracle R Enterprise 还另外新增了对超过 70 个统计函数的支持。
Oracle Data Mining 提供了 12 种强大、高性能的数据库中数据挖掘算法,并且支持挖掘星型模式、事务数据和文本等非结构化数据。
Oracle 大数据机提供预先安装并经过优化的软件,可提供卓越的性能。这些软件包括
Oracle 大数据机中包含企业版 Cloudera Manager,这是一种针对 Hadoop 集群的端到端的管理软件。
客户可以采用单独许可组件的形式在 Oracle 大数据机上预先安装和预先 Oracle NoSQL 数据库企业版及 Oracle Big Data Connectors。Oracle Big Data Connectors 支持通过 Oracle 数据库无缝集成存储在 Hadoop 中的数据。
Oracle R Enterprise 将用于统计计算和统计绘图的开源 R 语言与 Oracle 数据库集成在一起。这种集成支持在数据库中执行与数据紧密靠近的 R 语言结构。通过使用 R 库的统计功能以及将计算推送至数据库中,Oracle R Enterprise 对数据库的分析功能进行了扩展。凭借这种数据库中架构,开源的 R 程序包可从支持数据库的数据并行机制中获益。当在数据库内部执行时,对十亿行数据的数据集进行数字分析已经成为可能。
Oracle R Enterprise 在数据库的 R 处理与 SQL 处理之间进行了紧密的集成,可以使用 SQL 函数,并能进行从 R 到 SQL 的函数映射。因此,R 处理在数据库中完成并且可透明地利用 SQL。由于 R 提供了广泛的统计函数库,因此 Oracle R Enterprise 处理可通过将 R 函数推送至 SQL 而获益。
Oracle R Enterprise 还可以通过 Oracle R Connector for Hadoop 与 Oracle 大数据机上的 Hadoop 相集成。这样便可在 Hadoop 分布式文件系统 (HDFS) 驻留数据上建立基于 R 的分析,并在 Hadoop 基础架构上执行此分析。R 用户不需要学习新的并行技巧或 Hadoop 编程语言。他们可以在本地环境中使用 HDFS 文件中的示例数据来开发 R 代码。Oracle R Connector for Hadoop 可以将 R 代码部署在 Hadoop 上执行并将结果透明地提取到用户桌面。
当 Oracle R Enterprise 与 Oracle R Connector for Hadoop 结合在一起使用时,R 用户将面临多种选择 — 在 Hadoop 基础架构上执行的 R 计算既可引用数据库,又可引用 HDFS 驻留数据。结果可传输至用户桌面、用户在交互模式下的 R 环境或 Oracle 数据库(也同时保留在 HDFS 中)。
Oracle R Enterprise 提供了三种不同的计算引擎,可在 R 引擎与 Oracle 数据库之间提供多个接口。
R 中已经扩充了一个由开源扩展(CRAN 程序包)构成的大型库,这些程序包无需修改即可由 Oracle R Enterprise ORE 访问。
在 Oracle Loader for Hadoop 中,您可以使用 Hadoop MapReduce 创建数据集,这些数据集经过了优化处理,可以加载到 Oracle 数据库中。该工具提供了一个 Java 文件 (OraLoader.jar),这是 Hadoop 用户的 MapReduce 管道中的最后一个阶段,可准备相应格式的数据,以便将其高效地加载到 Oracle 数据库中。Oracle Loader for Hadoop 提供了在线和离线两种操作模式。
为了执行映射,Oracle Loader for Hadoop 可从 Oracle 数据库中获取目标表上的元数据。OraLoader 映射器流程包括分区、分类和数据转换。在完成映射流程后,OraLoader 分区器会识别要加载的 Oracle 数据库分区并为这些分区选择化简器节点。
OraLoader 化简器流程可以执行 Java Database Connectivity 或 Oracle Call Interface 代码并将其从化简器流程插入到分区或未分区的数据库表中。或者,在离线模式中,化简器流程还可以创建 CSV 或 Oracle 数据泵格式的文件,并创建相应的 SQL 代码来加载适当的数据库表。随后,用户可以将脚本和文件复制到数据库节点中,并通过执行脚本来加载数据。
该适配器在 Oracle Data Integrator 内部提供了原生 Hadoop 集成,可允许开发人员使用 Oracle Data Integrator 图形界面生成和编排 MapReduce 作业。它提供了一些 Oracle Data Integrator 知识模型,用于将数据加载至 Apache Hadoop、转换 Apache Hadoop 中的数据以及编排 Oracle Loader for Hadoop。此外,该适配器还可直接将数据加载至异构系统中,无论数据是存放在 Hadoop 集群上的大数据沙盒中还是其他异构环境中。
R 是一个用于统计分析和统计绘图的编程环境,可通过专用程序包进行扩展(开源社区中提供了超过 3500 个程序包)。Oracle R Connector for Hadoop 可让 R 用户访问和操作 Hadoop 分布式文件系统 (HDFS) 中的数据,并将数据链接到 Oracle 数据库。此外,Oracle R Connector for Hadoop 还允许 R 用户以交互的方式将 MapReduce 作业从 R 环境提交至 Hadoop 集群。Oracle R Connector for Hadoop 支持在本地 R 环境和 Hadoop 集群上执行相同的 R 代码,并且可以直接访问 HDFS 数据,而不需要对 R 映射器和化简器函数进行任何修改。
Oracle R Connector for Hadoop 还可以与 Oracle R Enterprise 一起使用,后者是 Oracle Advanced Analytics 的一个组件并且支持在数据库中执行分析。Oracle R Enterprise 和开源 R 程序包都可以利用映射器和化简器函数在 Hadoop 内提供一个强大的分析环境。
Oracle Direct Connector for Hadoop Distributed File System 为 Oracle 数据库提供了高速访问 Hadoop 分布式文件系统 (HDFS) 内数据的方法。它采用 Oracle 数据库外部表机制对 HDFS 数据执行 SQL 查询。这让用户能够在熟悉的 SQL 范例中操作,同时
HDFS 可采用分隔数据或 Oracle 数据泵格式的数据。该连接器还可以通过自动负载平衡来组织数据,从而实现高效的并行处理。











