作業を開始する前に
目的
このチュートリアルでは、ローカル・コンピュータから入力したデータを使用してOracle Big Data Cloud Serviceインスタンス上でMapReduceプログラムを実行する方法を学習します。所要時間
約90分予備知識
Oracle Big Data Cloud Serviceは、ビジネス分析機能を強化するためのハイパワーな環境を提供する自動化サービスです。自動ライフサイクル管理機能やワンクリックのセキュリティ機能を搭載するOracle Big Data Cloud Serviceは、簡単な操作でビッグ・データの多様なワークロードやテクノロジーを最適かつ安全に実行できるように設計されています。Oracle Big Data Cloud ServiceとOracle Big Data SQL Cloud Serviceを併用すれば、Hadoop、NoSQL、およびOracle Database Service – Exadata Editionのデータを、既存のSQLスキルを活用して分析することができます。詳しくはhttps://cloud.oracle.com/ja_JP/bigdataを参照してください。Oracle Storage Cloud Serviceは、スケーラブルで信頼できるセキュアなオンデマンド・パブリック・クラウド・ストレージ・ソリューションです。ハードウェアに1円も投資することなく、数分で追加のストレージ容量を利用できます。いつでもどこからでもOracle Storage Cloud Serviceにアクセスでき、インターネットに接続するデバイスの種類も問いません。詳しくはhttps://cloud.oracle.com/ja_JP/storageを参照してください。
コンテナとは、Oracle Storage Cloud Serviceに格納されているデータの整理に使用できるストレージ区画です。コンテナはディレクトリに似ていますが、大きな相違点があります。それは、ディレクトリとは異なりコンテナはネストできないという点です。Service Administratorロールを持つユーザーは誰でもコンテナを作成できます。
Oracle Storage Cloud ServiceインスタンスはOracle Storage Cloud ServiceのREST APIを使用して作成および管理ができます。Webベースのユーザー・インタフェースの代わりにこのAPIを使用すると、変更や再利用が簡単にできるクライアント・アプリケーションを生成できます。
REST APIにはさまざまな方法でアクセスできます。このチュートリアルでは、cURLコマンドライン・ツールを使用してOracle Storage Cloud ServiceのREST APIにアクセスする方法を説明します。
前提条件
このチュートリアルを始める前に、以下のことを確認してください。- RESTインタフェースにアクセスできるツールを持っていること。このチュートリアルではcURLを使用します。これは、さまざまなオペレーティング・システムで動作する無料のオープン・ソフトウェアです。Windows 64ビット・マシンにcURLをインストールする手順は、installing_curl_command_line_tool_on_windowsを参照してください。
- cURLのSSL対応バージョンを持っていること。cURLのダウンロードおよび使用について詳しくは、http://curl.haxx.seを参照してください。
- SSL証明書ファイルまたはバンドルを持っていること。Oracle Cloudでは、Verisignの証明書を使用してクライアントからサーバーへのセキュアな接続を許可します。cURLを使用してSSL証明書を検証する方法について詳しくは、http://curl.haxx.se/docs/sslcerts.htmlを参照してください。
- WindowsにPuTTYをインストールしてあること。PuTTYはさまざまなサイトから入手できますが、サイトhttp://www.putty.orgからインストールすることをお勧めします。
ローカル・コンピュータからOracle Storage Cloud Serviceへのファイルのアップロード
ローカル・コンピュータにあるファイルをOracle Big Data Cloud Serviceにアップロードしてさらに処理できるようにするには、そのファイルをOracle Storage Cloud Serviceにアップロードする必要があります。ローカル・コンピュータにあるファイルをOracle Storage Cloud Serviceにアップロードするには、次の手順を実行します。
認証トークンのリクエスト
Oracle Storage Cloud Serviceのサービス・インスタンスで操作を行う場合は、必ず認証を受ける必要があります。認証トークンをリクエストするには資格証明を入力する必要があります。Oracle Storage Cloud Serviceへの接続にはcURLを使用します。
-
コマンド・プロンプトを開きます。次のcURLコマンドを実行して認証トークンを取得します。

この画像の説明
注:認証トークンの取得に使用する構文は次のとおりです。curl -v -X GET -H "X-Storage-User: myService-myIdentityDomain:username@example.com" -H "X-Storage-Pass:Password" https://storage.us2.oraclecloud.com/auth/v1.0 -k
上の構文の'username@example.com'、'Password'、および'myIdentityDomain'には、各自の値を入力してください。 -
出力内容を確認します。出力内の'X-Auth-Token'という値が現行の認証トークンです。Oracle Storage Cloud Serviceへの以降の接続には、この認証トークンを使用する必要があります。

この画像の説明
既存のコンテナのリスティング
Oracle Storage Cloud Serviceに接続してcURLの各種コマンドを使用するには、認証トークンを使用する必要があります。自分のOracle Storage Cloud Serviceアカウントの既存のコンテナは、すべてリストすることができます。
-
次のcURLコマンドを使用して、アカウントの既存のコンテナをすべてリストします。

この画像の説明
注:コンテナをリストする構文は次のとおりです。curl -v -X GET -H "X-Auth-Token:GeneratedAuthenticationToken" https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。アカウントの既存のコンテナがすべてリストされます。

この画像の説明
新しいコンテナの作成
Oracle Storage Cloud Serviceにオブジェクトを格納するには、コンテナを作成する必要があります。コンテナは、次のcURLコマンドを使用して作成できます。
-
次のcURLコマンドを使用して、Chicago_Airlinesという名前の新しいコンテナを作成します。

この画像の説明
注:新しいコンテナの作成に使用する構文は次のとおりです。curl -v -X PUT -H "X-Auth-Token:GeneratedAuthenticationToken" https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain/Chicago_Airlines -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。コンテナの作成が成功した場合は、出力メッセージに'HTTP/1.1 201 Created'と表示されます。

この画像の説明
ローカル・コンピュータからOracle Storage Cloud Serviceコンテナへのファイルの書込み
Big Data Cloud Serviceのコンテナにファイルを書き込んで格納することができます。ファイルはオブジェクトとしてコンテナに格納されます。ローカル・コンピュータからコンテナにファイルを書き込むことができます。
-
ローカル・コンピュータからChicago_Airlinesコンテナにファイル'D:\flight_data'を書き込みます。

この画像の説明
注:ファイルの書込みに使用する構文は次のとおりです。curl -v -X PUT -H "X-Auth-Token:GeneratedAuthenticationToken" -T D:\flight_data https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain/Chicago_Airlines/flightdetails -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。オブジェクトの作成と書込みが成功した場合は、出力メッセージに'HTTP/1.1 201 Created'と表示されます。

この画像の説明
コンテナに含まれるオブジェクトのリスティング
コンテナに含まれるオブジェクトのうち、アクセス権があるものはすべてリストできます。
-
Chicago_Airlinesコンテナに含まれるすべてのオブジェクトをリストします。

この画像の説明
注:コンテナに含まれるオブジェクトをリストするときに使用する構文は次のとおりです。curl -v -X GET -H "X-Auth-Token:GeneratedAuthenticationToken" https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain/Chicago_Airlines -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。上の手順で書き込んだflight_detailsオブジェクトがリストされます。

この画像の説明
Oracle Storage Cloud ServiceからBig Data Cloud Serviceへのデータの移動
前の項で、ローカル・コンピュータからOracle Storage Cloud Serviceにファイルを移動しました。次は、Oracle Storage Cloud ServiceからBig Data Cloud Serviceにファイルを移動します。Big Data Cloud Serviceにファイルを移動したら、HadoopとMapReduceを使用してファイルを処理できます。Big Data Cloud Serviceでは、Big Data Cloud ServiceとOracle Storage Cloud Serviceとの間のデータ移動にSwift APIを使用します。
Big Data Cloud Serviceへのログイン
Big Data Cloud Serviceのサービス・インスタンスで操作を行う場合は、必ず認証を受ける必要があります。Big Data Cloud Serviceでは、ユーザー名とパスワードでユーザーを認証します。Big Data Cloud Serviceインスタンスへのログインには、PuTTYを使用できます。要求された場合は必ず、Big Data Cloud Serviceのユーザー名とパスワードを入力する必要があります。
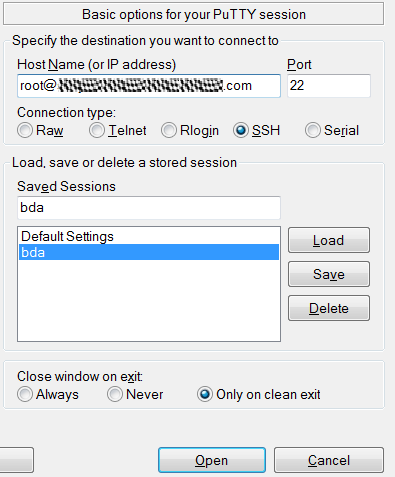


Oracle Storage Cloud Service用の新しいSwift API資格証明の作成
Big Data Cloud Serviceインスタンスへのログインに成功したら、Oracle Storage Cloud Serviceにアクセスして、Oracle Storage Cloud ServiceコンテナからBig Data Cloud Serviceにデータを移動する必要があります。Big Data Cloud ServiceインスタンスからOracle Storage Cloud Serviceにアクセスする場合は、新しいSwift API資格証明を作成する必要があります。Big Data Cloud ServiceインスタンスからOracle Storage Cloud Serviceに接続する必要がある場合は、いつでもその資格証明を再利用できます。Oracle Storage Cloud ServiceとBig Data Cloud Serviceとの間の接続には、Swift APIが使用されます。
-
次のbdcs-admin add_swift_credコマンドを使用して、BDCSProvider1という名前の新しいswift資格証明を作成します。

この画像の説明
注:新しいswift資格証明の作成に使用する構文は次のとおりです。bdcs-admin add_swift_cred --swift-username Storage-myIdentityDomain:userName@example.com --swift-password Password --swift-storageurl https://storage.us2.oraclecloud.com/auth/v1.0 --swift-provider BDCSProvider1
'GeneratedAuthenticationToken'、'myIdentityDomain'、'userName@example.com'、および'Password'は、実際の値に置き換えてください。 -
出力内容を確認します。新しい資格証明の作成と書込みが成功すると、プロバイダ名が表示されます。

この画像の説明
Oracle Storage Cloud ServiceのオブジェクトのSwift APIによるリスティング


Cloudera Managerの資格証明の構成
Big Data Cloud Serviceインスタンスへのログインに成功したら、構成ファイルを使用してCloudera Managerの資格証明を構成できます。この構成ファイルは、以降、Cloudera Managerに接続するときに再利用できます。
-
bdcs_variables.shという名前の新しいファイルを作成します。Cloudera Managerの資格証明を入力します。CM_ADMIN、CM_PASSWORD、CM_URLに適切な値を指定してください。bdcs_variables.shファイルを保存します。

この画像の説明
注:Cloudera Managerの資格証明の構成に使用する構文は次のとおりです。#!/bin/bash
export CM_ADMIN="Cloudera Manager Administrator username"
export CM_PASSWORD="Cloudera Manager Administrator password"
export CM_URL="Cloudera Manager web address:portnumber" -
bdcs_variables.shを表示し、正しい値が入力されているかどうか確認します。次のcatコマンドを使用します。

この画像の説明 -
Cloudera Managerの構成ファイルを実行します。これにより、環境に構成が適用されます。

この画像の説明
Big Data Cloud Serviceのファイル/ディレクトリのリスティング


Oracle Storage Cloud ServiceからHDFSへのファイルのコピー
Oracle Storage Cloud Service コンテナからBig Data Cloud ServiceのHDFSに、オブジェクトをコピーできます。
-
Oracle Storage Cloud ServiceのChicago_Airlinesコンテナにあるflightdetailsオブジェクトを、Big Data Cloud ServiceのHDFSの/user/bdcstest/ディレクトリにコピーします。'bdcs dm copy'コマンドを使用します。

この画像の説明
注:HDFSディレクトリの名前は、Big Data Cloud Serviceのユーザー名に応じて異なる場合があります。コピーが完了するまで操作を待機させる必要がある場合は、--waitパラメータをオプションで指定します。 -
出力内容を確認します。コピー操作が成功すると、'data movement succeeded with status: succeeded'と表示されます。

この画像の説明
Big Data Cloud ServiceでのMapReduceプログラムの実行
Oracle Storage Cloud ServiceからBig Data Cloud Service内のHDFSにファイルを移動しました。次は、Big Data Cloud ServiceでMapReduceプログラムを実行します。HadoopとMapReduceで単語をカウントする簡単な例を、先ほどHDFSにアップロードしたファイルを使用して実行します。単語をカウントするJavaプログラムを記述し、これをJarファイルにパッケージし、このJarファイルをHadoop MapReduceで実行する必要があります。
ディレクトリの作成と入力ファイルの格納
HDFSにコピーしたファイルを移動して格納するための入力ディレクトリを作成する必要があります。このファイルがMapReduceプログラムの入力になります。
-
wordcount/inputという名前の新しいディレクトリをHDFSに作成します。これは、入力ファイルを格納するために必要なディレクトリです。次の'hadoop fs -mkdir'コマンドを使用します。

この画像の説明

この画像の説明
注:wordcountディレクトリを先に作成する必要があります。その後、wordcountディレクトリ内にinputディレクトリを作成します。 -
HDFS内のディレクトリをリストします。これにより、ディレクトリの作成が成功したかどうかを確認します。'hadoop fs -ls'コマンドを使用します。

この画像の説明 -
/user/bdcstest/から/user/bdcstest/wordcount/inputディレクトリにflightdetailsファイルをコピーします。'hadoop fs -mv'コマンドを使用します。

この画像の説明
-
/user/bdcstest/wordcount/inputディレクトリのファイルをリストして、flightdetailsファイルがコピーされているかどうか確認します。

この画像の説明
WordCount.javaプログラムの作成
flightdetailsファイルに含まれる単語の出現回数を個別にカウントするJavaプログラムを作成する必要があります。このJavaファイルをjarファイルとしてパッケージしてから、MapReduceを使用して実行します。
-
WordCount.javaファイルを格納する、wordcount_classesという名前の新しいディレクトリを作成します。

この画像の説明 -
wordcount_classesディレクトリにナビゲートします。

この画像の説明 -
ファイル名としてWordCount.javaを指定して、viエディタを開きます。

この画像の説明 -
指定された入力ファイルに含まれる単語の数をカウントするMapReduce Javaプログラムを記述します。プログラムを保存します。

この画像の説明

この画像の説明

この画像の説明

この画像の説明
完成したプログラムをダウンロードするには、「program example」を右クリックしてブラウザのオプションを選択し、ファイルをWordCount.javaファイルとして保存してください。
注:MapReduceで実行できるように、JavaプログラムにはMapクラスとReduceクラスの両方が含まれている必要があります。
WordCount.javaファイルのコンパイルとWordCount.jarファイルの作成
クラス・ファイルを生成するには、WordCount.javaファイルをコンパイルする必要があります。クラス・ファイルを生成したら、すべてのクラス・ファイルをjarにパッケージし、MapReduceプログラムとして実行できるようにする必要があります。
-
buildという名前の新しいディレクトリを作成します。WordCount.javaファイルのコンパイルにより生成されるクラス・ファイルは、すべてここに格納されます。

この画像の説明 -
WordCount.javaファイルをコンパイルします。'-cp'パラメータを使用して、MapReduce jarファイルのクラス・パスを指定します。

この画像の説明 -
buildディレクトリのファイルをリストします。これにより、クラス・ファイルが正しく生成されているかどうかを確認します。WordCount.classファイルが存在することを確認します。

この画像の説明 -
buildディレクトリのすべてのクラス・ファイルを使用して、wordcount.jarを生成します。'jar -cvf'コマンドを使用します。

この画像の説明 -
出力内容を確認します。コマンドの実行が成功していることを確認します。

この画像の説明 -
wordcount_classesディレクトリをリストして、wordcount.jarが生成されていることを確認します。

この画像の説明
単語をカウントするMapReduceプログラムの実行
wordcount.jarファイルの作成に成功したら、MapReduceを使用してこのwordcount.jarファイルを実行できます。
-
Hadoopでwordcount.jarファイルを実行します。'hadoop jar'コマンドを使用します。出力ディレクトリとして/user/bdcstest/wordcount/outputを指定します。

この画像の説明
注:/user/bdcstest/wordcount/outputディレクトリがコマンドにより生成されます。このようなディレクトリがすでに存在する場合は、プログラムの実行が失敗します。 -
出力内容を確認します。DFSClientによってwordcount.jarが実行されています。また、MapReduceプログラムの進行と完了の状況が表示されています。

この画像の説明

この画像の説明
注:プログラムの実行が成功すると、wordcountディレクトリ内のoutputディレクトリに出力が格納されます。 -
/user/bdcstest/wordcount/outputディレクトリをリストします。

この画像の説明 -
出力内容を確認します。生成されたファイルがリストされています。MapReduceプログラムの出力内容は、part-r-xxxxxファイルに存在します。

この画像の説明
注:part-r-xxxxxの数字は入力データの量によって異なります。
Big Data Cloud ServiceからOracle Storage Cloud Serviceへのデータの移動
MapReduceプログラムの実行が成功し、単語をカウントするプログラムの出力が生成されたら、このファイルをローカル・コンピュータに移動して詳しく分析することもできますが、Big Data Cloud Serviceには多数の分析ツールが揃っているため、そこで詳しく分析することもできます。
HDFSからOracle Storage Cloud ServiceへのSwift APIによる出力のコピー
Big Data Cloud ServiceのHDFSからOracle Storage Cloud Serviceのコンテナにファイルをコピーできます。他のさまざまなOracleエンジニアド・ソリューションを使用して詳しい分析を実行したり、手元のローカル・コンピュータに格納したりするには、この処理が必要です。
-
出力ファイルpart-r-00000を、HDFSの/user/bdcstest/wordcount/outputディレクトリからOracle Storage Cloud ServiceのChicago_Airlinesコンテナにコピーします。'bdcs dm copy'コマンドを使用します。

この画像の説明
注:--userパラメータには、実際に指定されているBig Data Cloud Serviceユーザー名を入力してください。 -
出力内容を確認します。コピー操作が成功すると、'data movement succeeded with status: succeeded'と表示されます。

この画像の説明
Oracle Storage Cloud Serviceに存在するオブジェクトのSwift APIによるリスティング


Oracle Storage Cloud Serviceからローカル・コンピュータへのオブジェクトのダウンロード
Oracle Storage Cloud Serviceに出力ファイルを移動したら、この出力ファイルをローカル・コンピュータにダウンロードできます。これは、cURLコマンドを使用して実行できます。
コンテナに含まれるオブジェクトのリスティング
コンテナに含まれるすべてオブジェクトをリストできます。Big Data Cloud ServiceからOracle Storage Cloud Serviceに移動したオブジェクトもすべてリストされます。
-
Chicago_Airlinesコンテナに含まれるすべてのオブジェクトをリストします。

この画像の説明
注:コンテナに含まれるオブジェクトをリストするときに使用する構文は次のとおりです。curl -v -X GET -H "X-Auth-Token:GeneratedAuthenticationToken" https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain/Chicago_Airlines -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。flight_detailsオブジェクトとflightoutputオブジェクトの両方がリストされます。

この画像の説明
Oracle Storage Cloud Serviceコンテナからローカル・コンピュータへのファイルの書込み
Oracle Storage Cloud Serviceコンテナのオブジェクトをローカル・コンピュータに書き込むことができます。
-
Chicago_Airlinesコンテナのオブジェクトflightoutputを、ローカル・コンピュータのD:\にあるflightoutputという名前の新しいファイルに書き込みます。

この画像の説明
注:ファイルの書込みに使用する構文は次のとおりです。curl -v -X GET -H "X-Auth-Token:GeneratedAuthenticationToken" -o flightoutput https://storage.us2.oraclecloud.com/v1/Storage-myIdentityDomain/ChicagoAirlines/flightoutput -k
'GeneratedAuthenticationToken'および'myIdentityDomain'は実際の値に置き換えてください。 -
出力内容を確認します。ファイルの作成と書込みが成功すると、出力メッセージに'HTTP/1.1 200 OK'と表示されます。

この画像の説明