Meeting the Challenge
of Big Data
Business and government can never have too much information for making the organization more efficient, profitable, or productive. For that reason organizations turned to powerful data stores, including very large databases (VLDBs), to meet their information storage and retrieval needs. Due to exponential data growth in recent years, we have embraced new storage technologies and the enterprise database now shares the spotlight with complementary technologies for storing and managing big data.
There are four key characteristics that define big data: Volume, Velocity, Variety and Value. Volume and velocity aren't necessarily new problems for IT managers; these issues are just amplified today. The distinguishing characteristics of big data that do create new problems are the variety and low density value of the data. Big data comes in many different formats that go beyond the traditional transactional data formats. It is also typically very low density; one single observation on its own doesn't have a lot of value. However, when this data is aggregated and analyzed, meaningful trends can be identified.

The global data explosion is driven in part by technology such as digital video and music, smartphones, and growth of the internet. For example, clickstream data became available for hundreds of millions of internet users after the browser became a universal client. Social networks have grown so large that the scope of data mining activity now encompasses hundreds of millions. Smartphones that can provide information for location-based services will soon be in the hands of 1 billion users. There is useful information to be derived from these disparate sources such as Web server logs, data streams from instruments, real-time trading data, blogs, and social media such as Twitter and Facebook.
Today the processing of terabyte-size, and even petabyte-size, data sets is within the budget of many organizations due to inexpensive CPU cycles and low-cost storage. That puts many organizations in a position to benefit from big data.
1"Big Data, Big Impact: New Possibilities for International Development", World Economic Forum
Big data enables an organization to gain a much greater understanding of their user and customer base, their operations and supply chain, even their competitive or regulatory environment. When handled correctly, big data will have a positive impact on the top line and bottom line, enabling better services and better decisions based on improved business intelligence. Organizations can analyze big data to develop and refine sophisticated predictive analytics that can reduce costs and deliver sustainable competitive advantage.
When organizations use big data to develop a better understanding of customers and users it generates benefits that are seen across both industry and government. The retail industry, for example, generates data sets for clickstream monitoring, consumer sentiment analysis, and making recommendations when a customer is online. In financial services, enhanced knowledge of the customer enables fraud detection and prediction, as well as analysis of spending habits to increase profitability per customer. And in both public and private healthcare, big data is expected to deliver cost reductions and efficiencies that will also result in better patient care.
Perhaps because of the benefits and the useful applications for big data, industry analysts have forecast rapid growth in the market for big data technology and services.

2 IDC Worldwide Big Data Technology and Services 2012-2015 Forecast, doc #233485, March 2012
Big data represents a sea change in the technology we draw upon for making decisions. Organizations will integrate and analyze data from diverse sources, complementing enterprise databases with data from social media, video, smart mobile devices, and other sources. The evolution of information architectures to include big data will likely provide the foundation for a new generation of enterprise infrastructure.
To exploit these diverse sources of data for decision-making, an organization must develop an effective strategy for acquiring, organizing, and analyzing big data, using it to generate new insights about the business and make better decisions.
Each step in the process of refining big data has requirements that are best served by matching the right hardware and software to the job at hand. Existing data warehouse infrastructure can grow to meet both the scale of big data and the different analytics needs. But handling the initial acquisition and organization of the new data types will require new software, most notably Apache Hadoop.
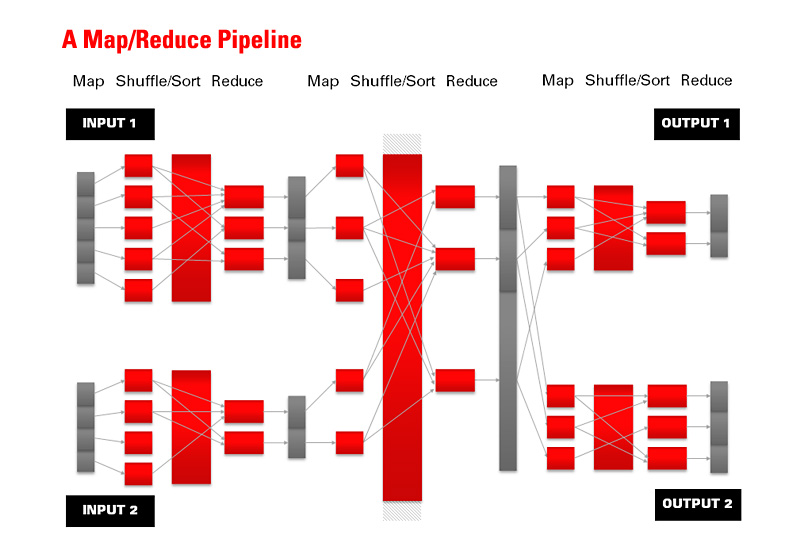
Hadoop contains two main components: the Hadoop Distributed File System (HDFS) for data storage, and the MapReduce programming framework that manages the processing of the data. The Hadoop tool suite enables organizations to organize raw (often unstructured) data and transform it so it can be loaded into data warehouses and data marts for integrated analysis.
Hadoop lets a cluster or grid of computers tackle big data workloads by enabling parallel processing of large data sets. It operates primarily with HDFS, which is fault-tolerant and can scale out to many clusters with thousands of nodes. Hadoop MapReduce also provides capabilities for analysis operations on massive data sets using a large number of processors. For example, researchers at Yahoo sorted a petabyte of data in 16.25 hours running Hadoop MapReduce on a cluster of 3,800 nodes. Although Hadoop MapReduce is well suited to problems with key/value data sets, it's not intended for operations that require complex data or transactions.

The sources of big data are numerous including both human- and machine-generated data feeds. Acquisition of data from sources like online activity, RFID, instrumentation, social media, clickstreams, and trading systems is characterized by a large volume of transactions, high velocity of data flow, and greater variety of data formats. Required latency varies, from interactive systems that deliver a service and need subsecond responses, to more batch-oriented systems that store data for offline analysis later.
The diversity of content requires software to operate on structured and unstructured data, often in high-throughput scenarios. An effective big-data solution must provide storage and processing capacity to collect, organize, and refine large volumes of data, even petabyte-size data sets.
Organizations need to choose the right storage technology for new data with a clear understanding of both the kind of data they plan to store as well as how they will use it. While there are many specialist storage technologies tuned for particular scenarios, there are two primary use cases to be aware of.
Systems that are more batch-oriented with less stringent requirements for response time, updates, and queries often use the Hadoop Distributed File System (HDFS). Where time constraints are more stringent, with applications needing subsecond query response times, or frequent updates to existing data, some form of NoSQL database is usually required.
NoSQL emerged as companies, such as Amazon, Google, LinkedIn and Twitter struggled to deal with unprecedented data and operation volumes under tight latency constraints. Analyzing high-volume, real time data, such as web-site click streams can provide significant business advantage by harnessing unstructured and semi-structured data sources to develop new business analysis models. Consequently, enterprises built upon a decade of research on distributed hash tables (DHTs) and utilized either conventional relational database systems or embedded key/value stores, such as Oracle's Berkeley DB, to develop highly available, distributed key-value stores.

Deriving value from big data is a multiphase process that takes raw data and refines it into useful information. Data acquisition, such as taking data from streams and social media feeds, is a precursor to transforming and organizing data to derive business value. Pre-processing is used to weed out less useful data and structure what is left for analysis. Because big data comes in many shapes, sizes, and formats, this transformation is an important prerequisite to moving the data into the analytics environment.

The refining of big data enables it to be analyzed alongside your enterprise data. After raw data has been acquired, using data stores such as Hadoop Distributed File System (HDFS) or a NoSQL database, it can be preprocessed for loading into an analytics environment, such as a data warehouse running on Oracle Exadata Database Machine. This type of workload is often handled using Apache Hadoop.
Developers today typically create custom-written Java code that, in conjunction with the MapReduce programming framework, processes and transforms the data on the node where it is stored. Overall, data movement is therefore minimized since only final results of preprocessing are uploaded to the data warehouse.
By prepping data to load into Oracle Exadata Database Machine, we set the stage for integrated analysis with traditional enterprise data.
Organizations have been deriving useful information through the combination of building mathematical models and sifting through large volumes of data for a long time. Once refined, big data expands existing models and is a potential rich new source of insight for business intelligence applications that use the data warehouse.

The data warehouse is key to big data analysis. While data comes from many sources, new insight comes from an integrated analysis of all data together. Hence, the modern data warehouse now becomes a repository for the data summaries created by Hadoop as well as more traditional enterprise data.
New data sources are different—the data itself is often less well understood, but may also be inherently less precise or only indirectly relevant to the problem. So, to derive value from big data, we must turn to an analysis process of iteration and refinement. Each iteration can either reveal new insight, or simply enable an analyst to rule out a particular line of inquiry. Big data analysis is about uncovering new relationships rather than reporting on a well-understood data set.
While traditional analysis tools are still important, advanced analytics involving both statistical analysis and data mining are required to get the most out of big data. A large user community has turned to the open source R statistical programming language that has been evolving since 1997. Very popular among analysts and data scientists, R is also widely used in the academic world, so there's a ready pool of trained R developers coming along.
One use of statistical techniques called predictive analytics has gained traction across multiple industries including finance, retail, insurance, healthcare, pharmaceuticals, and telecommunications. Predictive analytics can exploit and use customer data to build and optimize predictive models. Organizations are using predictors, for example, to guide marketing campaigns and make them more effective. The surge of interest in predictive analytics has been made possible by gains in computing horsepower. With today's tools, predictive analytics can create sophisticated models and execute a variety of scenarios across large sets of data.
When we make decisions in today's world awash in data, we can use powerful tools to distill data and present information, making for a more intelligent decision-making process. Using automated analysis, we can make decisions that are data driven. We can turn big data into actionable insight and, with the right technology, do it in real time.
Visualizations and business intelligence dashboards are a powerful assist to decision-making, particularly when dealing with massive amounts of data. Statistical software is a key element of analytics, business intelligence, and decision support. The Web interface for running scripts of the R statistical analysis language can be integrated into dashboards, providing analysis and streaming graphics for the decision-making process.
The volume and velocity of big data have put new emphasis on scalability and performance of analytics and business intelligence tools. Improvements in server capacity, high-speed interconnects, and network bandwidth have contributed to the emergence of a new generation of software that provides in-memory, in-database, and real-time analytics.
In-memory databases, for example, give us the capacity for real-time decision-making. The 64-bit addressing capability of modern systems means we can configure servers with a terabyte (TB) of memory. That capacity means databases, some in excess of a billion rows, can be loaded into memory to sustain high-performance, low-latency processing, which results in faster decision-making.
1 Brynjolfsson, Hitt, and Kim, "Strength in Numbers: How Does Data-Driven Decision Making Affect Firm Performance?" (April 22, 2011).
Oracle offers a powerful stack of software, including new functionality specifically designed to handle the new challenges of big data. All components can run both on Oracle engineered systems as well as customer-integrated hardware.
Applications, having diverse architectures and performance requirements, also have diverse requirements for data storage and retrieval capabilities. Many big data applications require a fast, stripped-down data store that supports interactive queries and updates with a large volume of data.
Oracle NoSQL Database can quickly acquire and organize schema-less, unstructured, or semistructured data. It is an "always available," distributed key-value data store with predictable latency and fast response to queries, supporting a wide range of interactive use cases. And it has a simple programming model, making it easy to integrate into new big data applications.
Oracle Endeca Information Discovery is an enterprise data discovery platform for advanced exploration and analysis of complex and varied data. Information is loaded from disparate source systems and stored in a faceted data model that dynamically supports changing data. This integrated and enriched data is made available for search, discovery and analysis via interactive and configurable applications. Oracle Endeca's intuitive interface empowers business users to easily explore big data to determine its potential value.

Oracle Data Integrator provides data extraction, loading, and transformation (E-LT) for Oracle Database, Oracle Applications, and other 3rd party application sources. Oracle GoldenGate provides high-volume, real-time transformation and loading of data into a data warehouse or data mart. Together these products work with Oracle Big Data Connectors to provide a gateway to integrating big data. The big-data explosion has added to the importance of those products because big data is not useful if it's siloed.
Oracle has developed a suite of software for easily integrating Oracle Database with Hadoop. Oracle Big Data Connectors are available with Oracle Big Data Appliance or as individual software products. They facilitate access to the Hadoop Distributed File Systems (HDFS) from the Oracle Database and data loading to Oracle Database from Hadoop. They also provide native R interface to HDFS and the MapReduce framework and enable Oracle Data Integrator to generate Hadoop MapReduce programs.
We often see big data and analytics used in the same sentence because technology gains have enabled us to analyze increasingly large data sets. Not the least of those gains is the capacity for Oracle Database to embed analytics in the database, an architectural solution that provides scalability, performance, and security. This architecture offloads analytics work from RAM-limited computers and puts analytics processing closer to the data. This eliminates unnecessary network round trips, leverages an enterprise-class database, and lowers hardware costs.
Oracle Advanced Analytics turns Oracle Database into a sophisticated analytics platform ready for big data analytics. It combines the capabilities of Oracle Data Mining with Oracle R Enterprise, an enhanced version of the open source R statistical programming language. Oracle Advanced Analytics eliminates network latency that results from marshalling data between a database and external clients doing analytics processing. This can produce a 10x to 100x improvement in performance compared to processing outside the database. Encapsulating analytics logic in the database also exploits the database's multilevel security model and enables the database to manage real-time predictive models and results.
Oracle's software stack is the foundation for a powerful line of engineered systems that will help you quickly find new insights and unlock the value in big data.

1 "Oracle mainstreams its Hadoop platform with Cloudera [Oracle Enterprise Manager] deal," Tony Baer, Ovum, January 2012.
Oracle's engineered systems enable organizations to deploy big data solutions as a complement to operational systems, data warehousing, analytics, and business intelligence processing. Engineered systems are preintegrated, so easier to deploy and support, and they deliver optimized performance. They can be deployed alone or alongside existing infrastructure.
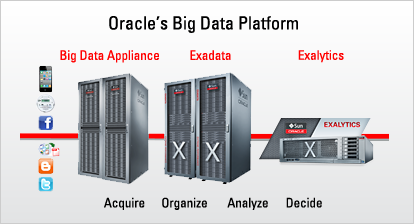
Oracle Big Data Appliance is a comprehensive, enterprise-ready combination of hardware and software that makes getting started with big data easy and fast. It is designed to run both Hadoop and Oracle NoSQL Database for data acquisition, and to run Hadoop MapReduce algorithms to organize the data and load it into a data warehouse for integrated analysis.
Oracle has partnered with Cloudera to include the Cloudera Distribution as part of Oracle Big Data Appliance. This ensures that customers have access to a fully integrated and supported distribution of Hadoop, which has tens of thousands of nodes in production, speeding deployment and reducing ownership costs.
Oracle Exadata Database Machine represents a leading-edge combination of hardware and software that is easy-to-deploy, completely scalable, secure and redundant. Innovative technologies such as Exadata Smart Scan, Exadata Smart Flash Cache, and Hybrid Columnar Compression enable Exadata to deliver extreme performance for everything from data warehousing to online transaction processing to mixed workloads. Oracle Exadata uses a massively parallel architecture and a high-speed InfiniBand network to sustain high-bandwidth links between the database servers and storage servers and also to other engineered systems like Oracle Big Data Appliance and Oracle Exalytics.

Oracle Exadata supports deployment of massive data warehouses and the iterative analysis needed to uncover new relationships and develop new insight. Once this new analysis is operationalized, it becomes available to decision-makers who can act upon it and realize the business value.

Oracle Exalytics In-Memory Machine is an integrated hardware and software solution that provides in-memory analytics for rapid decision-making without breaking the budget. It can be deployed to support demand forecasting, revenue and yield management, pricing, inventory management, and a myriad of other applications. Plus, it can be linked by a high-speed InfiniBand connection to data warehouse on Oracle Exadata providing real-time analytics for business intelligence applications accessing large data warehouses.
Oracle Exalytics In-Memory Machine delivers "speed of thought analysis." And this fundamentally changes how you interact with your BI software, enabling you to get more out of your data and to generate more business value.
To derive real business value from Big Data, you need the right tools to capture and organize a wide variety of data types from different sources, and to be able to easily analyze it within the context of all your enterprise data. Oracle's engineered systems and complementary software provide an end-to-end value chain to help you unlock the value of big data.













The Oracle Exadata Database Machine X2-2 full rack includes a database grid of eight dual-processor database servers for a total of 96 processor cores and up to 1,152 gigabytes (GB) of RAM. It also features a grid of 14 Exadata storage servers, with 504 terabytes (TB) of disk storage and a 5.3 TB PCI flash cache memory. The Oracle Exadata Database Machine X2-8 full rack has two 8-processor database servers, 160 processor cores, and 4 TB of RAM. It also includes a pool of 14 storage servers with 504 TB of disk storage and a 5.3 TB smart flash cache.
Big data applications put a premium on I/O performance—the greater the I/O bandwidth, the faster a data-intensive application can execute. Oracle Exadata Database Machine is configurable with high-performance or high-capacity disk drives. Combining flash with high-performance disk produces impressive I/O performance. The smart PCI flash cache accelerates random I/O by as much as a factor of 30. In the full-rack configuration, high-performance disks deliver 25 GB/sec bandwidth, with flash cache delivering 75 GB/sec for SQL operations with uncompressed data. A high-performance disk can sustain 50,000 I/O operations per second (IOPS), and Exadata's flash cache can sustain 1.5 million SQL IOPS.
When servers operate with large databases, compressing the data provides both storage and performance advantages. Oracle Exadata provides hybrid columnar compression, which provides up to 10-to-1 compression for data warehouses, and up to 15 to 50 times compression for archives. The data remains compressed for scans and in flash memory.
Oracle Exalytics In-Memory Machine is an integrated hardware and software solution for low-latency, high-performance modeling and analytics. It can be linked by a high-speed 40 (Gb/s) InfiniBand connection to Oracle Exadata racks and Oracle Big Data Appliance to provide real-time analytics for big data applications.
The in-memory analytics hardware includes a single rack-mounted server with 1 terabyte (TB) of RAM, a 3.6 TB hard drive, high-speed interconnect technology, and 40 Intel processing cores. By using the private InfiniBand connection to an Oracle Exadata Database Machine, Oracle Exalytics can take advantage of high-speed access to a data warehouse or operational database. The InfiniBand fabric can also serve as a high-performance interconnection for clusters of Oracle Exalytics machines.
Key Oracle Exalytics capabilities include in-memory columnar compression, in-memory analytics, optimized access to storage blocks, and an adaptive, in-memory cache. Oracle Exalytics applies heuristics to enable the cache to adapt to changes in the analytic workload and determine what is stored in memory.
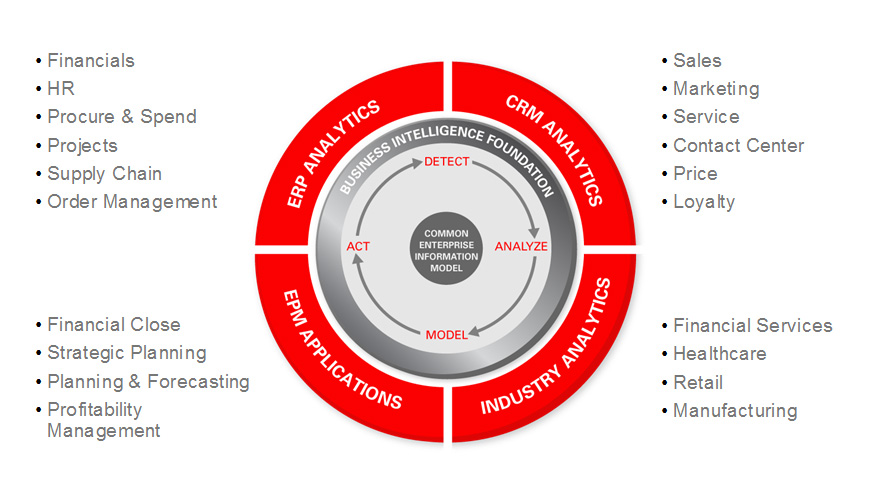
Oracle Exalytics In-Memory Machine includes Oracle TimesTen In-Memory Database for Exalytics and Oracle Business Intelligence Foundation Suite. Oracle Business Intelligence Foundation Suite is a key component of Oracle's broad-spectrum analytic solutions that include ERP analytics, CRM analytics, industry analytics, and EPM analytics.
Oracle Exalytics also includes a second database solution, a memory-optimized version of the Oracle Essbase OLAP server. Both of Exalytics' in-memory databases support parallel query operations for optimal performance with distributed workloads. The two data management engines support several techniques for the execution of high-performance analytics.
Another advantage of adopting the Exalytics approach to analytics is the ability to exploit mature, standards-compliant interfaces for data access and operations with multidimensional data. Oracle Exalytics In-Memory Machine supports the de facto industry standards for SQL data access, ODBC and JDBC. It also supports multidimensional expressions for query, and manipulation of multidimensional data in OLAP cubes.
Business intelligence is a data-intensive activity that requires problem-solving and reporting tools. Oracle Exalytics provides a leading-edge modeling, analytics, and visualization capability for a broad range of Oracle BI and EPM applications. There are dashboards, reporting tools, and metrics capabilities among the 8,000 prebuilt assets of Oracle BI applications.
Exalytics software, such as Oracle Business Intelligence Foundation Suite, includes enhancements to exploit the in-memory capabilities for improved responsiveness and interactivity. To provide ease of use, Oracle Exalytics includes a presentation suggestion engine that recommends visualizations for a data set.
Oracle Exalytics users can also benefit from an immersive experience using mobile devices. Oracle Business Intelligence Foundation Suite provides mobile business intelligence support for Apple iOS devices, including iPad and iPhone. All content available in Oracle Business Intelligence Enterprise Edition is available to mobile users without requiring any custom programming.
The use cases for Oracle NoSQL Database include scenarios with characteristics such as a high rate of data capture, a high volume of simple queries, high-volume random reads, and very large repositories of semi-structured or unstructured data. Oracle NoSQL Database performs well enough for sensor data capture, click-through capture from a Web application, and statistics and network capture for monitoring and backup for mobile devices. Oracle NoSQL Database can also be used for data services for scalable authentication, real-time communication, social media, and personalization.
Oracle Data Integrator can extract data from legacy data sources including online transaction processing, online analytical processing, and operational databases, as well as application data sources. It can pipe data into a data warehouse, planning system, or other application. Oracle Data Integrator exposes open APIs and open XML knowledge modules. It supports integration with SAP and, Oracle applications, and Oracle Golden Gate CDC (for real-time changed data capture) applications. Oracle Data Integrator is 100 percent Java code, and the embeddable Java agents have a small memory footprint. Oracle Data Integrator agents can run directly on data warehouse hardware or on staging servers. Oracle Data Integrator uses native SQL optimized for the DBMS, and its graphical interface simplifies integration processing.
For processing scenarios that require big-data-handling capabilities, Oracle Data Integrator can leverage Oracle Loader for Hadoop to optimize data loading. Letting a knowledge model control the process, Oracle Data Integrator can load data into Hadoop Distributed File System (HDFS), transform HDFS data, append to data within HDFS, and integrate HDFS data with Oracle Database.
Developing Hadoop MapReduce jobs requires advanced programming skills. But Oracle Data Integrator and Oracle Data Integrator Application Adapter for Hadoop reduce the requirement to develop custom MapReduce jobs by providing native Hadoop integration within Oracle Data Integrator. It uses knowledge modules that can drive Hadoop, creating and launching Hadoop jobs for data validation, transformation, and loading into Oracle Databases.
Oracle Data Mining
Oracle Data Mining provides algorithms that run as native SQL functions to provide better performance when building and executing models. Oracle Data Mining includes a rich development environment for creating predictive analytics applications. You can also automate workflows using graphical interfaces. An extension to Oracle SQL Developer, Oracle Data Mining helps data analysts create analytical workflows to solve problems. It can then generate SQL code to automate and deploy the analytical methodology—all from inside Oracle Database. Oracle Data Mining models leverage Oracle Exadata's smart scan technology. It also lightens the database server workload by pushing SQL predicates and scoring of Oracle Data Mining models down to storage servers.
Oracle Data Mining delivers 12 powerful, high-performance in-database data mining algorithms, as well as the ability to mine star schemas, transactional data, and unstructured data, such as text.
 |
 |
 |
 |
 |
 |
 |
| Problem | Algorithm | Applicability |
|---|---|---|
| Classification | Logistic Regression (GLM) Decision Trees Naive Bayes Support Vector Machine |
Classical statistical technique Popular / Rules / transparency Embedded app Wide / narrow data / text |
| Regression | Multiple Regression (GLM) Support Vector Machine |
Classical statistical technique Wide / narrow data / text |
| Anomaly Detection | One Class SVM | Lack examples of target field |
| Attribute Importance | Minimum Description Length (MDL) | Attribute reduction Identify useful data Reduce data noise |
| Association Rules | Apriori | Market basket analysis Link analysis |
| Clustering | Hierarchical K-Means Hierarchical O-Cluster |
Product grouping Text mining Gene and protein analysis |
| Feature Extraction | Nonnegative Matrix Factorization | Text analysis Feature reduction |
Additionally, every Oracle Database includes more than 50 built-in SQL statistical functions. These SQL functions support summary and comparative statistics such as mean, median, skewness, kurtosis, t-tests, F-test, Pearson correlations, distribution fits, ANOVA, and so on. Oracle R Enterprise adds support for another more than 70 statistical functions.
Oracle Data Mining delivers 12 powerful, high-performance in-database data mining algorithms, as well as the ability to mine star schemas, transactional data, and unstructured data, such as text.
Oracle Big Data Appliance includes software that is preinstalled and optimized for superior performance. The software includes
Oracle Big Data Appliance includes the enterprise version of Cloudera Manager, an end-to-end management application for Hadoop clusters.
Oracle NoSQL Database, Enterprise Edition and Oracle Big Data Connectors can be installed and preconfigured on each Oracle Big Data Appliance as a separately licensed component. Oracle Big Data Connectors provide seamless integration of data stored in Hadoop with Oracle Database.
Oracle R Enterprise integrates the open source R language for statistical computing and graphics with Oracle Database. This integration enables R language constructs to execute in the database, in close proximity to data. Oracle R Enterprise extends the database's analytical capabilities by leveraging the R library's statistical functionality and pushing computations down to the database. With this in-database architecture, open source R packages benefit from database-enabled data parallelism. When executing within the database, numerical analysis of billion-row data sets becomes practical.
Oracle R Enterprise provides tight integration between R and SQL processing of the database, including the use of SQL functions and function mapping from R to SQL. Thus the R processing happens in the database and transparently leverages SQL. Because of R's extensive library of statistical functions, Oracle R Enterprise processing benefits from pushing R functions down to SQL.
Oracle R Enterprise can also integrate with Hadoop on Oracle Big Data Appliance via Oracle R Connector for Hadoop. This allows R-based analytics to be developed on Hadoop Distributed File System (HDFS) resident data and to execute on Hadoop infrastructure. R users do not need to learn new parallel techniques or Hadoop programming. They simply develop R code in their local environments using a sample of data from HDFS files. Oracle R Connector for Hadoop can deploy the R code to execute on Hadoop and fetch results transparently to the user's desktop.
When Oracle R Enterprise and Oracle R Connector for Hadoop are used together, R users have a multitude of choices—their R computations executing on Hadoop infrastructure can reference both database and HDFS resident data. The results can be delivered to the user's desktop, the user's R environment in interactive mode, or to an Oracle Database (in addition to existing on HDFS).
Oracle R Enterprise includes three different computation engines, providing multiple interfaces between the R engine and Oracle Database.
R has been augmented with a large library of open source extensions (CRAN packages) that are accessible to Oracle R Enterprise ORE without modification.
Oracle Loader for Hadoop enables you to create data sets with Hadoop MapReduce that are optimized for loading into Oracle Database. Oracle Loader for Hadoop includes a Java file (OraLoader.jar) that is the last stage in a Hadoop user's MapReduce pipeline and prepares the data in a format that makes for efficient loading into Oracle Database. Oracle Loader for Hadoop provides both online and offline modes of operation.
To do the mapping, Oracle Loader for Hadoop obtains metadata for the target table from Oracle Database. The OraLoader mapper process includes partitioning, sorting, and data conversion. After the mapping process, the OraLoader partitioner identifies the Oracle Database partitions to be loaded and selects reducer nodes for those partitions.
The OraLoader reducer processes can execute Java Database Connectivity or Oracle Call Interface code and insert it from reducer processes into a partitioned or nonpartitioned database table. Alternatively, in offline mode, the reducer processes can create files in comma-separated value or Oracle Data Pump format, and create SQL scripts to load the appropriate database table. The user can then copy the scripts and files to the database node and execute the script to load the data.
This adapter provides native Hadoop integration within Oracle Data Integrator and enables developers to use the Oracle Data Integrator graphical interface to generate and orchestrate MapReduce jobs. It includes Oracle Data Integrator knowledge modules for loading data to Apache Hadoop, transforming data within Apache Hadoop, and orchestrating Oracle Loader for Hadoop. This adapter loads data easily and directly into heterogeneous systems, whether the data stays in the big data sandbox on a Hadoop cluster or whether it is brought into other heterogeneous environments.
R is a programming environment for statistical analysis and graphing that is extensible through special-purpose packages (there are more than 3,500 available in the open source community). Oracle R Connector for Hadoop enables R users to access and manipulate data in the Hadoop Distributed File System (HDFS) and link it with Oracle Database. Oracle R Connector for Hadoop also allows R users to submit MapReduce jobs interactively from the R environment to the Hadoop cluster. Oracle R Connector for Hadoop supports execution of the same R code in both the local R environment and on a Hadoop cluster, and can access HDFS data without any change to the R mapper and reducer functions.
Oracle R Connector for Hadoop can also be used in combination with Oracle R Enterprise, a component of Oracle Advanced Analytics that supports in-database execution of analytics. Both Oracle R Enterprise and open source R packages can be used with mapper and reducer functions to provide a powerful analytical environment within Hadoop.
Oracle Direct Connector for Hadoop Distributed File System provides Oracle Database with high-speed access to data in the Hadoop Distributed File System (HDFS). It uses the Oracle Database External Table mechanism to execute SQL queries against HDFS data. This permits users to operate within the familiar SQL paradigm while
The HDFS format can use delimited data or data in Oracle Data Pump format. This connector also organizes the data for efficient parallel processing with automatic load balancing.