
When you define a new data store that connects to a fixed width text file, the New Data Store wizard will prompt you to define the names and sizes of the data fields in the file.
Data in a fixed-width text file is arranged in rows and columns, with one entry per row. Each column has a fixed width, specified in characters, which determines the maximum amount of data it can contain. No delimiters are used to separate the fields in the file. Instead, smaller quantities of data are padded with spaces to fill the allotted space, such that the start of a given column can always be specified as an offset from the beginning of a line. The following file snippet illustrates characteristics common to many flat files. It contains information about cars and their owners, but there are no headings to the columns in the file and no information about the meaning of the data. In addition, the data has been laid out with a single space between each column, for readability:
In order to parse the data in a fixed width text file correctly, OEDQ needs to be informed of the column sizes implicit in that file. This is done in the New Data Store wizard, and can be edited as part of the data store settings later, if required.
When you first enter the data store configuration screen for a fixed width text file, the columns table is empty. In the following screenshot, it has been populated with the mapping information for some of the columns in our sample file:
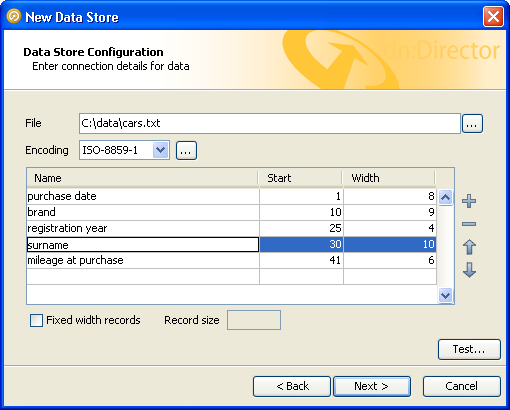
Each column is described to OEDQ by its starting position and width, in characters. Each column is also assigned a name, which is used in data snapshots and downstream processing so that the data can be identified. Names are defined by the user at the time the data store is defined and should be descriptive, for maximum downstream usability.
Notice that the positions of the data columns are defined in terms of start point and width. Note also that the first character on a line is at position 1, not zero. Providing a width and a starting point for each column means that OEDQ does not assume that one column continues right up until the start of the next, with the result that:
The buttons to the right of the columns table can be used to add or remove records, or move the selected record up or down in the list.
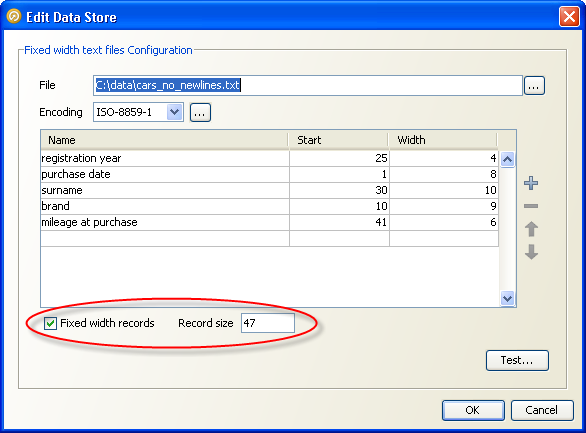
By default, it is assumed that fixed width files will be formatted as already described, with a new line separating one row from the next. However, some files do not use new line characters to separate rows. Data will then appear like this in a text editor:

In this case, the width of the whole record must also be specified as part of the data store configuration, so that OEDQ can correctly subdivide the data into rows. To do this,
Oracle ® Enterprise Data Quality Help version 9.0
Copyright ©
2006,2011 Oracle and/or its affiliates. All rights reserved.