|
Oracle Database 11g Release 2 verfügbar: 11 neue Features für DBAs
von DBA Community, ORACLE Deutschland GmbH
Seit dem 1. September steht 11g Release 2 zum Download auf OTN
für die Plattform Linux zur Verfügung. Um einen Vorgeschmack auf einige der neuen Features zu geben,
haben wir im Folgenden eine Auswahl von 11 interessanten Neuerungen zusammengestellt. Bei den
Beschreibungen handelt es sich um eine kurze Zusammenfassung der einzelnen Neuerungen, die nicht nach Prioritäten geordnet ist.
Mehr Informationen dazu mit ausführlichen Code-Beispielen finden Sie wie immer in unseren
2 wöchentlichen Ausgaben.
11g Oracle Database 11g Release 2: 11 neue Features
- RAC One
- Einfachere Installation und Konfiguration
- Online Application Upgrade
- Oracle Database Filesystem
- Speicherplatz bei Bedarf
- Parallelisierung: einfacher und effizienter
- ASM für alle Daten
- Segmentlose UNUSABLE Indizes und Index Partitionen
- External Tables mit Pre-processor-Klausel
- Erweiterungen im Datenbank Scheduler
- Neue und erweiterte Packages
Oracle RAC One Node
Oracle RAC One Node ist die kostengünstige "ein" Knotenversion des Oracle Real Application Clusters.
Moment! EIN Knoten? Nein, Sie haben sich nicht verlesen.
Sinn und Zweck von RAC One ist es, auch Single Instanz Datenbanken in einen
Cluster mit aufzunehmen und somit das Rollout von Datenbanken zu
standardisieren - egal ob Single Instanz (SI) oder RAC Datenbank. Ziel ist es,
immer dieselbe Infrastruktur zu verwenden und in diesen großen Clustern mehrere -
wenn nicht sogar alle - Datenbanken bereitzustellen.
Hierbei kommt die Single Instanz in den Genuss aller Clusterware Funktionalitäten:
- Automatisches Umschalten im Falle des Knotenausfalls:
In diesem Fall wird die SI auf einem anderen Rechnerknoten gestartet.
Dies entspricht der Funktionalität eines Cold Failover Cluster.
Durch eine veränderte Technologie beim Verbinden mit den Listenern eines Clusters (über den sogenannten
SCAN Listener - einer weiteren 11gR2 Funktion) werden die Clients
automatisch auf den neuen Knoten umgeleitet, ohne dass dies im Vorfeld
in der Client Konfiguration festgehalten werden muss.
- Online Migration der Datenbank Instanz im Falle von geplanten Wartungsarbeiten am Knoten
Für eine kurze Zeit läuft die Datenbank Instanz dann auf 2 Knoten. Neue Client Connections
werden auf den neuen Knoten umgeleitet, während bestehende Verbindungen davon
unangetastet bleiben und ihre Arbeiten beenden können.
Nach einiger Zeit werden die restlichen Verbindungen dann hart beendet,
um den Knoten für Wartungsarbeiten frei zu geben.
- Unterstützung von Online Rolling Upgrades der Datenbank und Grid Infrastruktur
Bei der Grid Infrastruktur handelt es sich um ein gemeinsames Home-Verzeichnis der Oracle Clusterware
und der ASM Datenbank. Beide wurden mit 11gR2 in ein gemeinsames Home integriert.
Da die Clusterware seit 10.1.0.2 und ASM seit 11.1.0.6 komplett Rolling Upgrade fähig
sind, kann also jedes Betriebsystem- und Grid Infrastruktur-Upgrade online
durchgeführt werden. Die Benutzer der Datenbanken im Cluster (egal ob SI oder RAC)
bemerken das Upgrade nicht (siehe Online Migration). Dasselbe gilt
für die meisten One Off Patches und Critical Patch Updates der Datenbank,
die als RAC Rolling Upgrade fähig gekennzeichnet sind.
- Verwendung der neuen regelbasierten Server Pools
Anstatt wie bisher eine Datenbank auf dedizierten Knoten zu definieren,
überlässt man die Verwaltung der Instanzen und Datenbanken komplett dem Cluster.
Der Cluster sucht dann die entsprechend freien Ressourcen (Knoten) heraus, auf denen die
Datenbank Instanz (RAC One) bzw. Instanzen (RAC) gestartet werden.
- ASM Cluster Filesystem und Snapshot Funktionalität
Informationen hierzu finden Sie im ASM Teil
Sollte eine Single Instanz mehr Ressourcen benötigen, ist das Upgrade auf eine
normale RAC Lizenz spielend möglich. Die Skalierung über mehrere Server erfordert
lediglich die passende Lizenz, da technisch alle Vorraussetzungen gegeben sind.
Zurück zum Anfang des Artikels
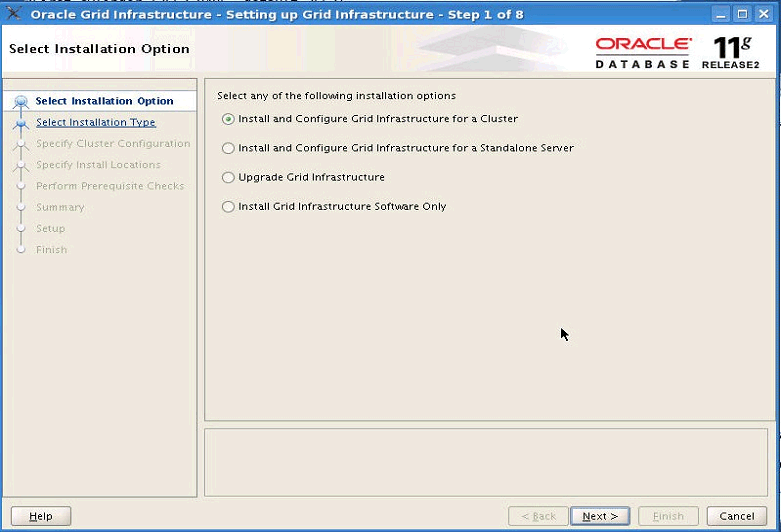
Einfachere Installation und Konfiguration
Der Oracle Universal Installer (OUI) hat sich in fast jedem Release verändert.
In 11g R2 sind die Veränderungen jedoch massiv, und sie führen zu wesentlichen Verbesserungen.
Die wichtigste (nicht nur im RAC Umfeld) ist die Integration des Cluster Verification Utility (CVU bzw. CLUVFY).
Es überprüft vor der Installation alle wichtigen Parameter einer SI oder RAC Installation.
Der Installer gibt aber nicht nur die Ergebnisse aus, sondern erlaubt es ebenfalls, gleich ein Fix Script zu erzeugen,
das der Administrator aufrufen kann, um die Probleme falls möglich zu beheben.
Vergessen sind auch die Zeiten, in denen Sie SSH manuell konfigurieren mußten. Auch dies kann
der OUI während der Installation für Sie erledigen bzw. für eine bereits aufgesetztes SSH überprüfen.
Neu ist auch, dass nun über den OUI eine saubere Deinstallation eines Clusterknoten, einer fehlgeschlagenen
Clusterinstallation, eines defekten Knoten oder des kompletten Clusters möglich ist.
Besonders hilfreich ist das, wenn man fehlgeschlagene Installationen neu starten möchte,
da dies vom Installer erkannt und vorher sauber bereinigt wird.
Als kleineres Update gibt es nun auch für die Clusterware ein Out-of-Place Upgrade, d.h. die neue Clusterware
kann in ein neues Home installiert werden. Diejenigen, die mit 10g /opt/oracle/product/10.1.0/crs
als Clusterverzeichnis gewählt haben, wird es nun freuen, endlich den Pfad ohne Neuinstallation ändern zu können.
Für eine größere Ansicht auf das Bild klicken.
Eine weitere große Neuerung ist die Einführung von Grid Plug and Play (GPnP).
Dahinter verbirgt sich die Entfernung von knotenabhängigen Konfigurationsdaten innerhalb des Clusters.
Das ermöglicht nun sowohl ein einfaches Klonen der Grid Infrastruktur als auch eine "Software only" Installation.
Die Konfiguration kann dann in einem zweiten Schritt zu einem späteren Zeitpunkt passieren. Das
erlaubt den einfachen Austausch der Konfigurationsdaten. Das "Verschieben" eines Clusterknotens
zu einem anderen Cluster ist damit kein Hexenwerk mehr.
Ebenfalls viel hat sich im Bereich der Integration der Cluster Infrastruktur in die Konfigurationswerkzeuge
getan. Nicht nur, dass die Enterprise Manager Datenbank Console (DB Console) nun eine graphische
Benutzeroberfläche zur Verwaltung der Clusterressourcen bietet. Zur Konfiguration eines Clusters gehört nun auch
der sogenannte Cluster Time Service: Fehleranalysen im Clusterumfeld erweisen sich als besonders schwierig, wenn die Knoten
unterschiedliche Zeitstempel haben, deswegen war bis 11gR2 ein NTP Server dringend empfohlen.
Ist dieser bei 11gR2 nicht vorhanden, übernimmt der Cluster Time Service die Zeitsynchronisation der Knoten.
Der Database Configuration Assistant (DBCA) erzeugt nun vollständige Skripte
beim Anlegen einer Datenbank - in der Vergangenheit fehlten häufig die Befehle zum Anlegen von DB Control
und zur Registrierung mit der Clusterware. Wer allerdings das Management vom Automatic Storage Management (ASM)
innerhalb des DBCAs sucht, sucht vergeblich. Hierfür gibt es nun ein eigenes Konfigurationswerkzeug:
den ASM Configuration Assistant, kurz ASMCA.
|
Zurück zum Anfang des Artikels
Online Application Upgrade
Mit dem neuen Edition-Based Redefinition-Feature wird ein Interface zur Verfügung gestellt, das
ununterbrochene Verfügbarkeit von Applikationen gewährleistet. Bisher war es möglich, Operationen
wie Tabellenänderungen oder einen Indexneuaufbau online zu gestalten. Sogar unterschiedliche Versionen von
Tabellen können in einem eigenen Workspace verwaltet werden. Diese Funktionen sind nun um eine neue Technik erweitert worden,
die es es ermöglicht, online Änderungen von Applikationen wie z.B. von PL/SQL Programmen zu erlauben.
Die Idee dahinter ist, Veränderungen in Ruhe in einem eigenen Bereich, der sogenannten Edition
durchzuführen. So können Applikationen auf die jeweiligen Editionen vor und nach der Änderung
(Upgrade) ununterbrochen zugreifen, auch wenn sich beispielsweise Programme ändern. Spezielle Objekte
wie Editioning Views und Editioning Trigger helfen dabei, die unterschiedlichen Sichtweisen auf
Tabellen der einzelnen Editionen aufrechtzuerhalten und die Veränderungen an den Tabellen in den jeweiligen Editionen durchzuführen.
Zurück zum Anfang des Artikels
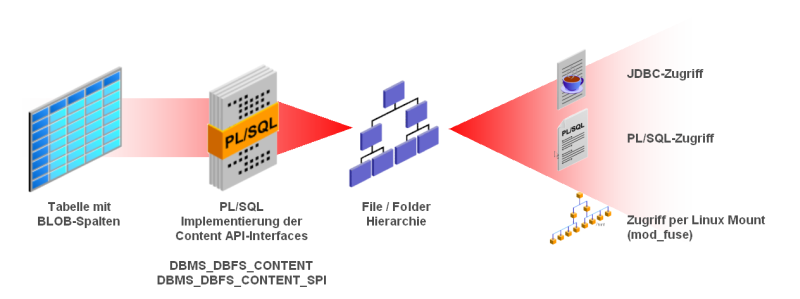
Das Oracle Database Filesystem
Das neue Oracle Database Filesystem erlaubt es, eine Dateisystem-Sicht über eine
Tabelle mit einer LOB-Spalte zu legen. Dazu stellt Oracle eine PL/SQL-Schnittstelle
bereit, die implementiert werden muss, so dass Dateisystem-Operationen auf entsprechende
SQL-DML oder SELECT-Anweisungen abgebildet werden.
Auf Linux-Systemen kann ein solches Database Filesystem mit Hilfe des quelloffenen
Kernelmoduls "mod_fuse" (filesystem in user space) in den Server-Verzeichnisbaum eingehängt
werden. Die folgende Abbildung zeigt die Architektur.
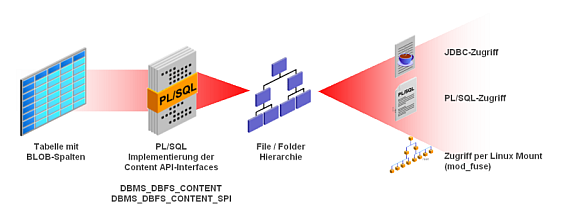
Für eine größere Ansicht auf das Bild klicken.
Eine fertige Implementierung, den Oracle Securefile Store, bringt
die Datenbank bereits mit. Die PL/SQL-Implementierung ist bereits vorhanden; mit einem SQL-Skript
werden die nötigen Tabellen in einem frei wählbaren Datenbankschema erstellt. Auf die Dokumente kann
anschließend beliebig entweder über die Dateisystem-Sicht oder über die SQL-Sicht zugegriffen werden.
Das Database Filesystem bietet also eine neue Schnittstelle für LOB-Daten: Die Dateisystem-Sicht.
Zurück zum Anfang des Artikels
Speicherplatz bei Bedarf
Häufig benötigen Applikationen beim Installieren viele Schemaobjekte, die zu Beginn der Nutzung noch gar
nicht verwendet werden und somit leer sind. Die Objekte benötigen allerdings trotzdem Speicherplatz beim Erzeugen.
Oracle 11g Release 2 schafft hier Abhilfe.
Das Erzeugen von Objekten wie nicht partitionierten Tabellen kann nun ab Release 2
verzögert werden. Erst nach dem ersten Einfügen von Daten werden automatisch die entsprechenden
Segmente angelegt. Zugehörige LOB-Segmente und Indexsegmente profitieren ebenfalls automatisch von
dieser Technik. Folgender Code-Ausschnitt zeigt eine Verwendung:
Leere Datenbankobjekte benötigen somit keinen Platz und reduzieren den Aufwand bei der Installation
von Applikationen mit leeren Tabellen.
Zurück zum Anfang des Artikels
Parallelisierung: einfacher und effizienter
Parallele Operationen können nun automatisiert und sogar im Memory ablaufen. Was bedeutet das?
Damit wird verhindert, dass parallele Operationen bei falscher Einstellung dem Gesamtsystem zu viele Ressourcen
wie I/O oder CPU abverlangen und somit gar zu einer Verlangsamung der Applikationen führen.
Über einen Initialisierungsparameter wird automatisch gesteuert, ob ein
Statement überhaupt parallel ausgeführt werden soll und welcher DOP (kurz für degree of parallelism)
genutzt werden soll. Zusätzlich wird entschieden, ob das Statement sofort ausgeführt werden kann
oder ob es in eine Warteschlange eingereiht wird, bis die entsprechenden Systemressourcen zur
Verfügung stehen. So wird gewährleistet, dass parallelisierte Applikationen
insgesamt effizienter und schneller abgearbeitet werden.
Schließlich können die abgefragten Objekte sogar automatisch im Memory gehalten werden, um ungenutztes Memory
für die Ausführung zu verwenden. Das kann besonders in Data Warehouse Umgebungen sinnvoll sein,
in denen große Mengen an ungenutztem Memory vorhanden sind.
Zurück zum Anfang des Artikels
ASM für alle Daten
Mit 11gR2 wird das Automatic Storage Management zu einem vollwertigen Volume Manager.
Die Volumes können für alle Filesysteme verwendet werden - von NTFS bis zu ext3.
Dabei bleiben alle Funktionalitäten, wie das Striping und Mirroring von ASM, erhalten und werden automatisch
unterhalb der Filesysteme verwendet. Schaut man in ASM hinein, erscheint das Volume wie ein Tablespace
- ein einfacher Container.
Allerdings werden herkömmliche Filesysteme allein durch die Verwendung
von ASM nicht clusterfähig!
Denn hierfür wird nicht nur ein clusterfähiger Volume Manager benötigt,
sondern auch ein clusterfähiges Filesystem.
Das clusterfähige Filesystem ist das ASM Cluster File System (ACFS), dem gerade im RAC Cluster eine hohe Bedeutung zukommt.
Das ACFS bietet alle Funktionalitäten eines modernen journaling Filesystems, soll aber im jetzigen Release
nur Linux und Windows zur Verfügung stehen (andere Betriebssysteme sollen die Funktionalität mit einem Patch Set
nachgereicht bekommen).
ACFS ist der ideale Speicherort für externe Tabellen und shared Oracle Homes, wie sie z.B. im SAP Umfeld benötigt werden.
ACFS unterstützt dabei auch die Erstellung von File System Snapshots.
Die zeitpunktgenauen Kopien werden mit Hilfe der "Copy On Write Technology" erstellt und
erlauben bis zu 64 Snapshots. Persistente Read-Only Snapshots können automatisch in bestimmten
Intervallen erzeugt werden. Die Snapshot Technology eignet sich optimal für ein schnelles
Filesystem Backup oder das Spiegeln von Daten für Reporting Applikationen.
Ebenfalls finden nun die OCR und die Voting Disk direkt in ASM Platz. Hierfür werden
einige Blöcke an einer festen Stelle auf den ASM Platten reserviert.
Gespiegelt wird abhängig von der Redundancy der ASM Diskgroup. Sollte eine der Platten ausfallen,
die die Voting Disk enthält, wird die Disk automatisch auf einer anderen Platte wiederhergestellt.
Zurück zum Anfang des Artikels
Segmentlose UNUSABLE Indizes und Index Partitionen
Neu in Oracle Database 11g Release 2 ist die Nutzung des Speicherplatzes für UNUSABLE Indizes oder
Indexpartitionen. Diese können den gesamten Speicherplatz wieder freigeben. Vor allem für partitionierte
Indizes kann man dieses Feature sehr gut einsetzen: Zum Beispiel wird für eine
Buchungstabelle die Partitionierung empfohlen, wenn
- z.B. nur die Daten der letzten 60 Tage oft benutzt werden
- eingetragene Daten irgendwann nicht mehr verändert werden dürfen
- die Daten aber lange gespeichert werden müssen
In diesen Fällen empfiehlt sich eine Partitionierung nach der Zeit, zum Beispiel pro Monat eine Partition.
Indizes auf diese Tabelle werden in aller Regel nach dem gleichen Partitionierungskriterium partitioniert,
es entsteht pro Tabellenpartition jeweils eine Indexpartition. Da auf ältere Daten nur selten zugegriffen wird,
können die Indexpartitionen auf alte Daten nun gezielt UNUSABLE gemacht werden. Diese Indexpartitionen
verbrauchen dann keinen Speicherplatz mehr. Ein Zugriff auf alte Daten erfolgt über einen Partition-Scan,
ein Zugriff auf neue Daten über einen Index-Scan, und das auch gemischt in einem Zugriff, wenn sowohl auf
neue als auch auf alte Daten zugegriffen wird. Damit kann enorm viel Speicherplatz für nicht genutzte Indexstrukturen
eingespart werden.
Zurück zum Anfang des Artikels
External Tables mit Pre-processor-Klausel
Seit 11g Release 2 können die Flat Dateien für die External
Tables Nutzung vorab einem Pre-processing unterzogen werden.
Das eröffnet zusätzliche Möglichkeiten des Einsatzes von External Tables, die bisher an
ein festes Format bei Angabe des Access Treibers gebunden waren. So ist der ORACLE_LOADER Access Treiber,
der bisher nur die beiden Werte ORACLE_LOADER und ORACLE_DATAPUMP kannte, um die Möglichkeit eines
benutzerdefinierten Pre-processor-Programms erweitert worden.
Nun können auch Daten, die nicht im vordefinierten Oracle Treiber Format vorliegen - also zum Beispiel
im ZIP-Format - als Eingabe für die External Table Nutzung verwendet werden. Folgendes Beispiel zeigt die
Verwendung.
Zurück zum Anfang des Artikels
Erweiterungen im Datenbank Scheduler
Im Bereich Datenbank Scheduler sind einige Erweiterungen bzgl. entfernter und verteilter Umgebungen eingeführt
worden.
So können Datenbank Scheduler Jobs auch als Remote Database Jobs erzeugt werden. Das bedeutet,
dass ein Job erzeugt werden kann, der auf einer anderen Datenbank Instanz auf dem gleichen oder
einem entfernten Rechner läuft.
Zusätzlich können mehrere Bestimmungsziele - multiple destinations - für einen einzelnen Job angegeben
werden, wobei das Monitoring zentral von einer Instance aus erfolgt. Ein Ziel kann dabei ein lokaler oder entfernter
Rechner oder eine lokale oder entfernte Datenbank sein.
Zurück zum Anfang des Artikels
Neue und erweiterte Packages
Wie in jedem neuen Datenbank-Release sind auch in 11g Release 2 einige interessante neue Packages bzw.
Package-Erweiterungen hinzugefügt worden.
Folgende Liste führt einige Package-Beispiele auf:
- DBMS_COMPRESSION ist ein neues Package, um die Komprimierungsrate einer Tabelle zu
analysieren und Informationen über die Komprimierbarkeit einer Tabelle auszugeben.
- DBMS_AUDIT_MGMT ist ein neues Package, um Audit Trail Einträge zu verwalten. Ein interessantes Beispiel
der Nutzung wäre das unterstützte Verschieben von AUD$ in einen anderen Tablespace.
- DBMS_SPM ist in 11g Release 1 als Package-Interface für SQL Plan Management eingeführt
worden und nun auch für die Migration von Stored Outlines zu SQL PLAN Baselines einsetzbar.
- DBMS_UTILITY wartet auf alle Transaktionen, die Locks auf den aufgelisteten Tabellen haben,
bis diese mit COMMIT oder ROLLBACK abgeschlossen sind oder ein Timeout eingetreten ist.
Zurück zum Anfang des Artikels
Zurück zur Community-Seite
|