|
Oracle Enterprise Manager Cloud Control 12c: Reversibles Data Masking (encrypt/decrypt)
von Ulrike Schwinn, Oracle Deutschland B.V. & Co. KG
|

|
Oracle Enterprise Manager Cloud Control 12c ist in vielen Bereichen der Testfunktionalitäten erweitert worden. Die Tipps zu
Application Data Model (ADM),
Sensible Daten
und Data Subsetting geben
eine gute Einführung. Auch im Data Masking Umfeld gibt es einige Neuerungen wie zum Beispiel das reversible Data Masking (encrypt/decrypt).
Mit anderen Worten: Nach einer Maskierung (Anonymisierung) kann offensichtlich eine De-Maskierung durchgeführt werden.
Zur Erinnerung: Data Masking ist der Vorgang, mit dem Daten zum Beispiel zum Testen unter Beibehaltung realistischer Eigenschaften anonymisiert werden.
Verwendet wird dabei das Package DBMS_CRYPTO. Normalerweise wird DBMS_CRYPTO zum Erstellen von Prüfsummen und zur Verschlüsselung von sensiblen Daten wie Passwörtern usw. verwendet. Da die Nutzung des Package DBMS_CRYPTO nicht Format
erhaltend ist, eignet es sich nicht zur alleinigen Nutzung im Testdatenumfeld. Um dies zu erreichen, muss das Format der Daten zusätzlich mit einem
regulären Ausdruck beschrieben werden; somit bleibt das Quell- bzw Zielformat erhalten. Welche Anwendungen sich dafür eignen und wie dieses Feature funktioniert, zeigt dieser Tipp an einem Beispiel.
Zuerst allerdings wird das allgemeine Vorgehen beim Data Masking in 12c erklärt.
Der Inhalt des Tipp unterteilt sich in folgende Abschnitte:
Data Masking: Das Vorgehen
Die Hauptkomponenten des Data Masking Workflows haben sich in Cloud Control 12c nicht verändert. Folgende Graphik zeigt dies im Überblick.
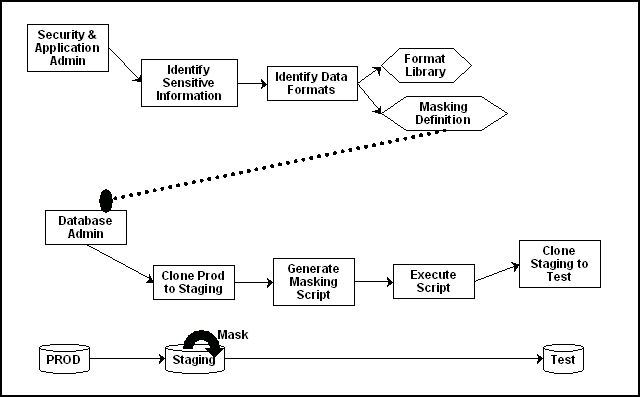
Wie im Vorgänger-Release werden beim Data Masking hauptsächlich folgende Schritte durchgeführt:
- Definition von Masking Formaten
- Generieren einer Masking Definition, die festlegt, wie die einzelnen Spalten anonymisiert werden sollen
- Erzeugen des zugehörigen Masking Skripts
- Anwenden des Masking Skripts in einer Staging Datenbank
Da ab Cloud Control 12c eine neue Technik zum Auffinden und Definieren von sensiblen Spalten zur Verfügung steht (siehe auch Tipp zu
Sensible Daten),
wird diese Information zusätzlich für Schritt 1 und 2 benötigt. Somit muss ein Application Data Model (ADM) mit den zugehörigen sensiblen
Spalten in einem vorgelagerten Schritt erzeugt werden.
Bevor Sie beginnen, überprüfen Sie die Privilegien. Erforderlich sind:
- EM_ALL_OPERATOR für Enterprise Manager Cloud Control User
- SELECT_CATALOG_ROLE für das DB Login
- Select Any Dictionary Privileg für DB Login
- EXECUTE Privilege auf DBMS_CRYPTO Package speziell für das ENCRYPT/DECRYPT Masking Feature
Je nachdem ob Sie ein Masking Format zur Verfügung stellen oder gleich eine Definition erzeugen wollen, navigieren Sie im ersten Schritt
zu "Enterprise->Quality Management->Data Masking Formats" bzw. zu "Data Masking Definitions".

Wir werden in unserem Beispiel eine Data Masking Definition erzeugen und navigieren daher zu "Data Masking Definitions". Die Beispieltabelle heisst CUSTOMERS_PART,
besteht nur aus folgenden 5 Zeilen und stellt eine Teilmenge der Tabelle CUSTOMERS dar.
Eine besondere Rolle spielen dabei die Spalten CUST_MAIN_PHONE_NUMBER und CUST_LAST_NAME, die als sensible Spalten identifiziert wurden.
Dieser Tatsache wurde in dem entsprechendem ADM ATS_SH_PART und den zugehörigen sensiblen Spalten Rechnung getragen. Dieses ADM wird im Folgenden genutzt.
Die Format erhaltende Maskierung (encrypt)
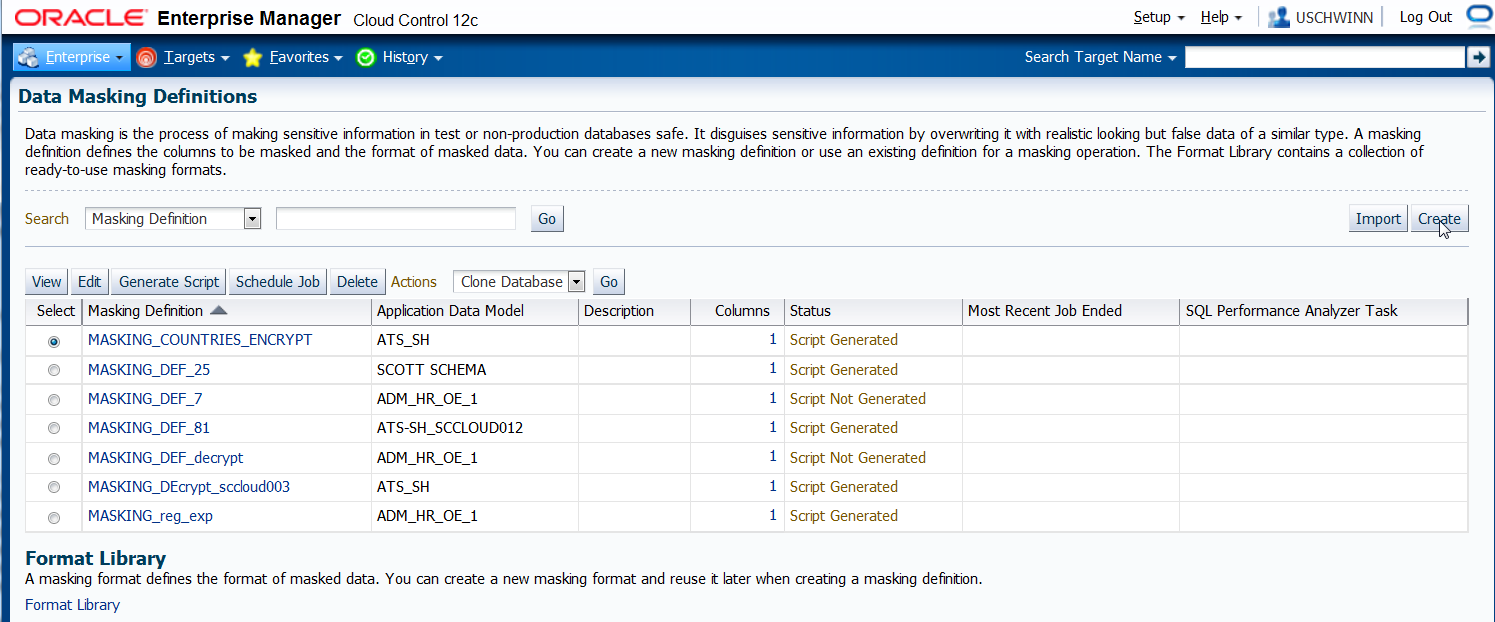
Man gelangt zu einer Masking Startseite, die entweder alle vorhanden Definitionen oder alle Formate anzeigt.
Folgendes Beispiel zeigt alle Data Masking Definitionen an. In der Spalte 3 mit Überschrift "Application Data Model" ist zu erkennen, dass jeder Definition ein
ADM zugrunde liegt.
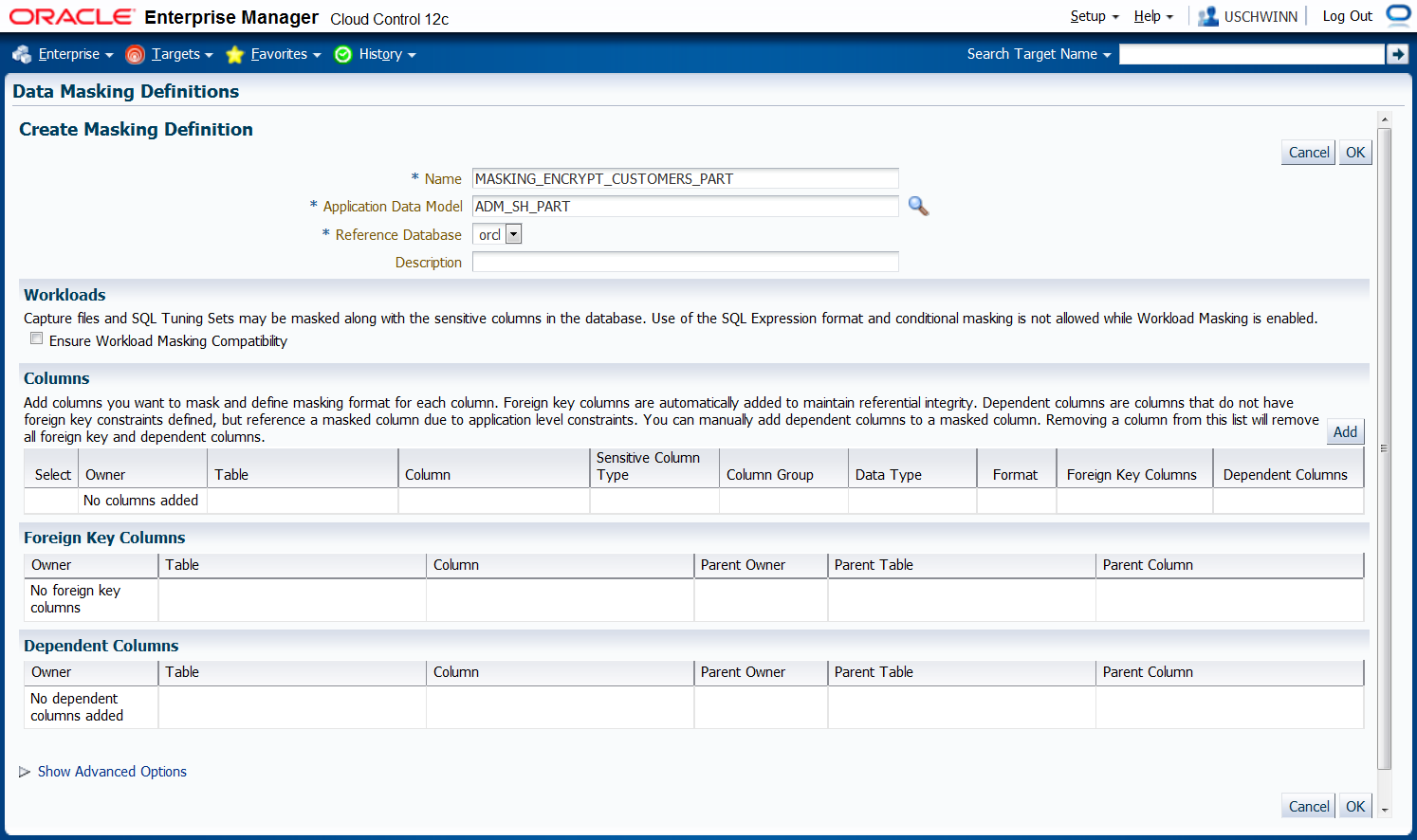
Im nächsten Schritt bereiten wir die Masking Definition vor. Die Eingabe eines Namens und eines Application Data Models bzw. der zugehörigen Datenbank ist notwendig.
Danach wird der "Add" Button betätigt, um die Spalten hinzuzufügen.
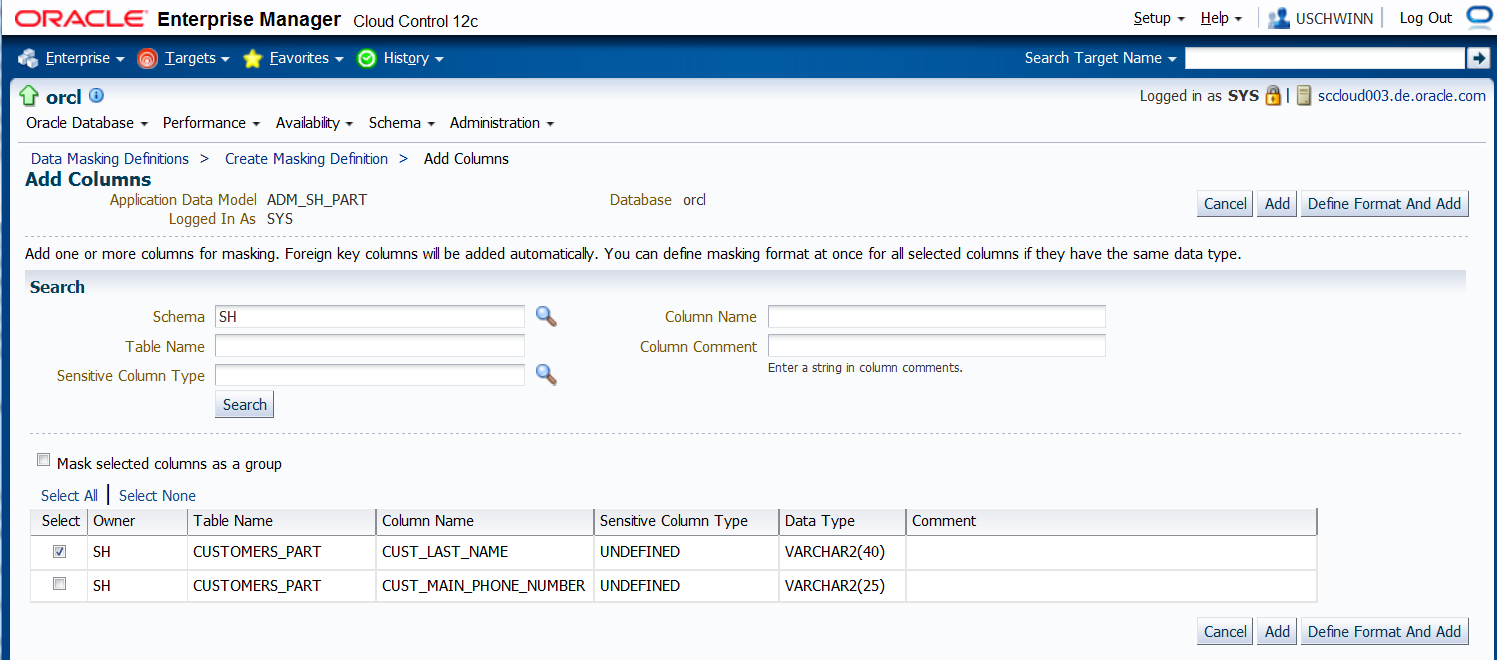
Auf der folgenden Seite reicht es aus, das Feld "Schema" zu befüllen (hier mit SH). Nach Betätigen des "Search" Buttons, werden die zuvor im ADM definierten
sensitiven Spalten "CUST_LAST_NAME" und "CUST_MAIN_PHONE_NUMBER" angezeigt. Selektieren Sie nun die Spalte "CUST_LAST_NAME" und betätigen Sie dann den "Define Format And Add" Button.
Sie gelangen zur Seite "Define Column Mask". Hier wählen Sie als Format Entry "Encrypt" und fahren fort mit "Add".
Ein zusätzliches Feld mit dem Property Feld "Regular Expression" erscheint und muss ausgefüllt werden. Da die Eigenschaft Format erhaltend (format preserved)
Voraussetzung für das Funktionieren der Maskierung und De-Maskierung ist, wird eine Beschreibung des Spalteninhalts über eine regulären Ausdruck "Regular Expression"
benötigt. Die Bezeichnung "Regular Expression" ist etwas irreführend, da nur eine Teilmenge der allgemein bekannten Syntax der regulären Ausdrücke
unterstützt wird.
Im Handbuch ist zu diesem Thema folgender Eintrag zu finden:
Encrypts column data by specifying a regular expression. The column values in all the rows must match the regular expression. This format can be used
to mask data consistently across databases. That is, for a given value it always generates the same masked value.
For example, the regular expression [(][1-9][0-9]{2}[)][_][0-9]{3}[-][0-9]{4} generates U.S. phone numbers such as (123) 456-7890.
This format supports a subset of the regular expression language. It supports encrypting strings of fixed widths. However, it does not support * or + syntax
of regular expressions. If a value does not match the format specified, the encrypted value may no longer produce one-to-one mappings.
All non-confirming values are mapped to a single encrypted value, thereby producing a many-to-one mapping."
Mit anderen Worten: Diese Art von Maskierung funktioniert nur über eine Abbildung auf vordefinierten Formaten mit fester Länge.
Daher sind Wildcards und Bedingungen usw. verboten.
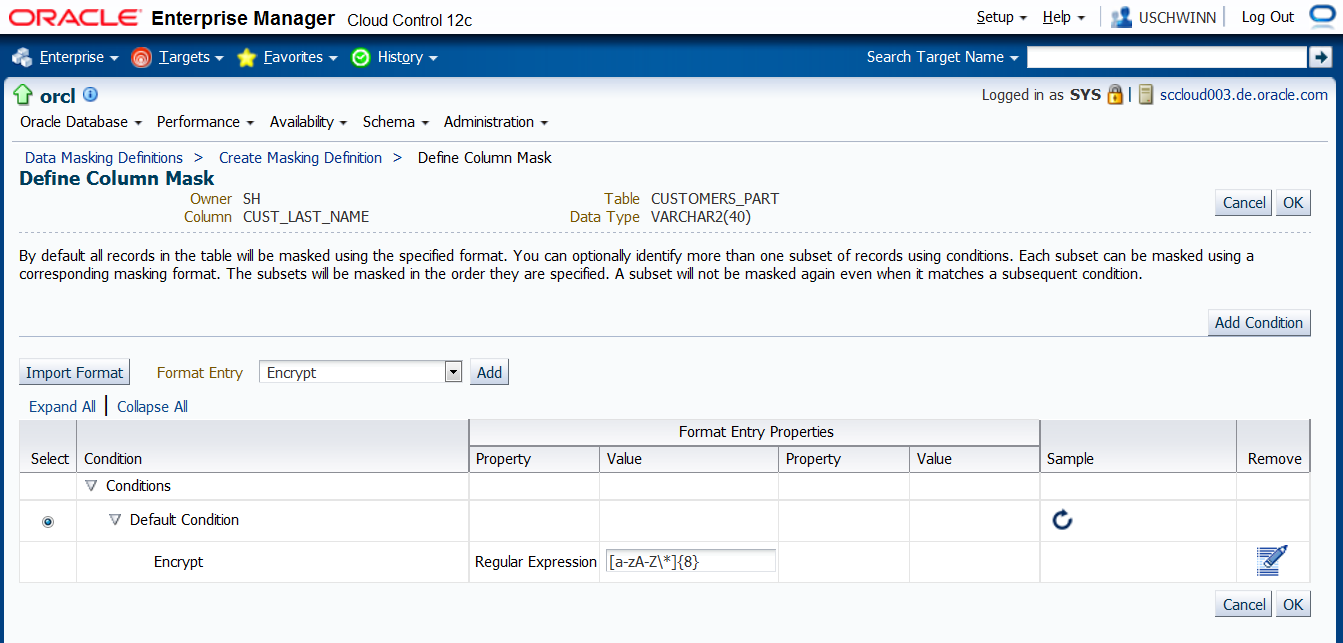
Für die Spalte CUST_LAST_NAME bedeutet dies, dass wir die maximale Länge der Spalteinhalte als festes Format vorgeben müssen - in unserem Fall 8.
Nach dem Verschlüsseln sind alle Namen 8 Zeichen lang. Dies bedeutet natürlich, dass die Spalteninhalte mit geringerer Länge verlängert werden.
Nach der De-Maskierung wird das ursprüngliche Wort wiederhergestellt. Da die Länge 8 Zeichen beträgt, werden die kürzeren Worte mit
einem Zusatzzeichen von links aufgefüllt. Gibt man bei der Formatbeschreibung ein Zeichen an, das nicht in den urspünglichen Worten vorkommt (z.B. '*') wird
dieses automatisch als Zusatzzeichen verwendet. Gibt man kein Zusatzzeichen an, wird ein Zeichen aus dem regulären Ausdruck verwendet - in meinem Tests der Buchstabe 'A'.
Die Beschreibung lässt sich dann folgendermassen ausdrücken.
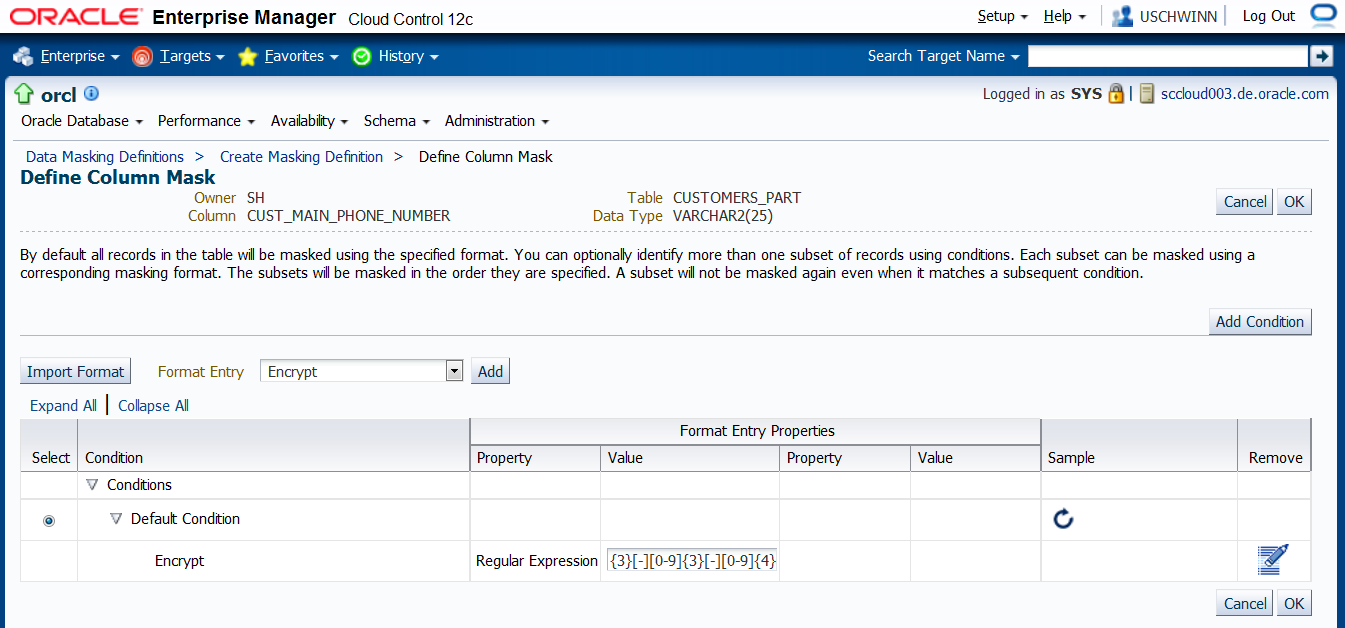
Im nächsten Schritt muss die Telefonnummer CUST_MAIN_PHONE_NUMBER mit einem regulären Ausdruck beschrieben werden. Die Telefonnummer hat eine feste Länge und
ein festes Format, das sich mit einem einfachen regulären Ausdruck beschreiben lässt.
Um die Formatbeschreibung für die Spalte CUST_MAIN_PHONE_NUMBER zu überprüfen, machen wir vorab noch einen Test auf SQL Ebene.
Danach tragen wir auch diesen regulären Ausdruck in das Feld "Regular Expression" ein.
Nun können wir die Definition mit den verbleibenden Schritten "Generate Script" und "Schedule Job" abschliessen.
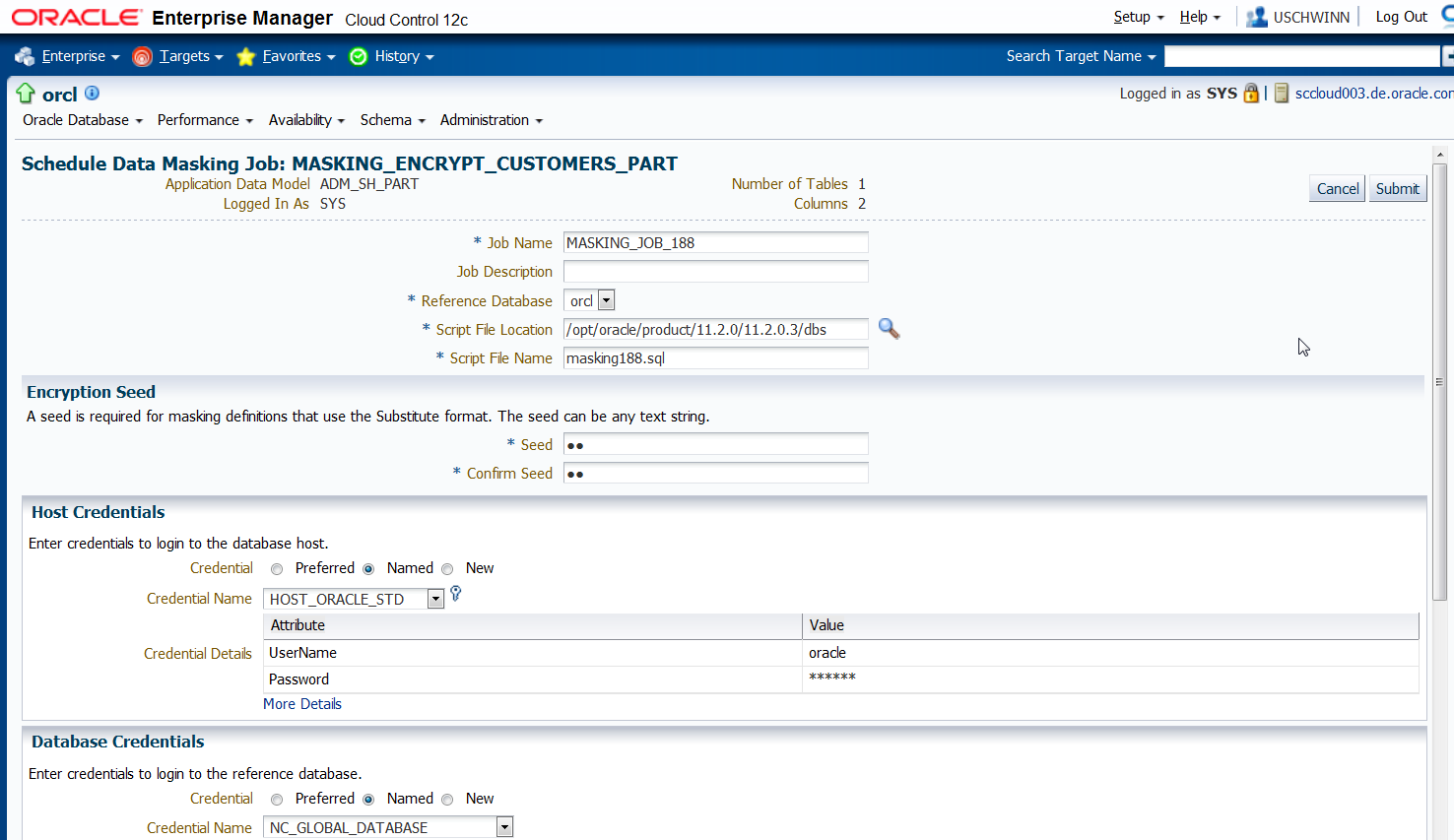
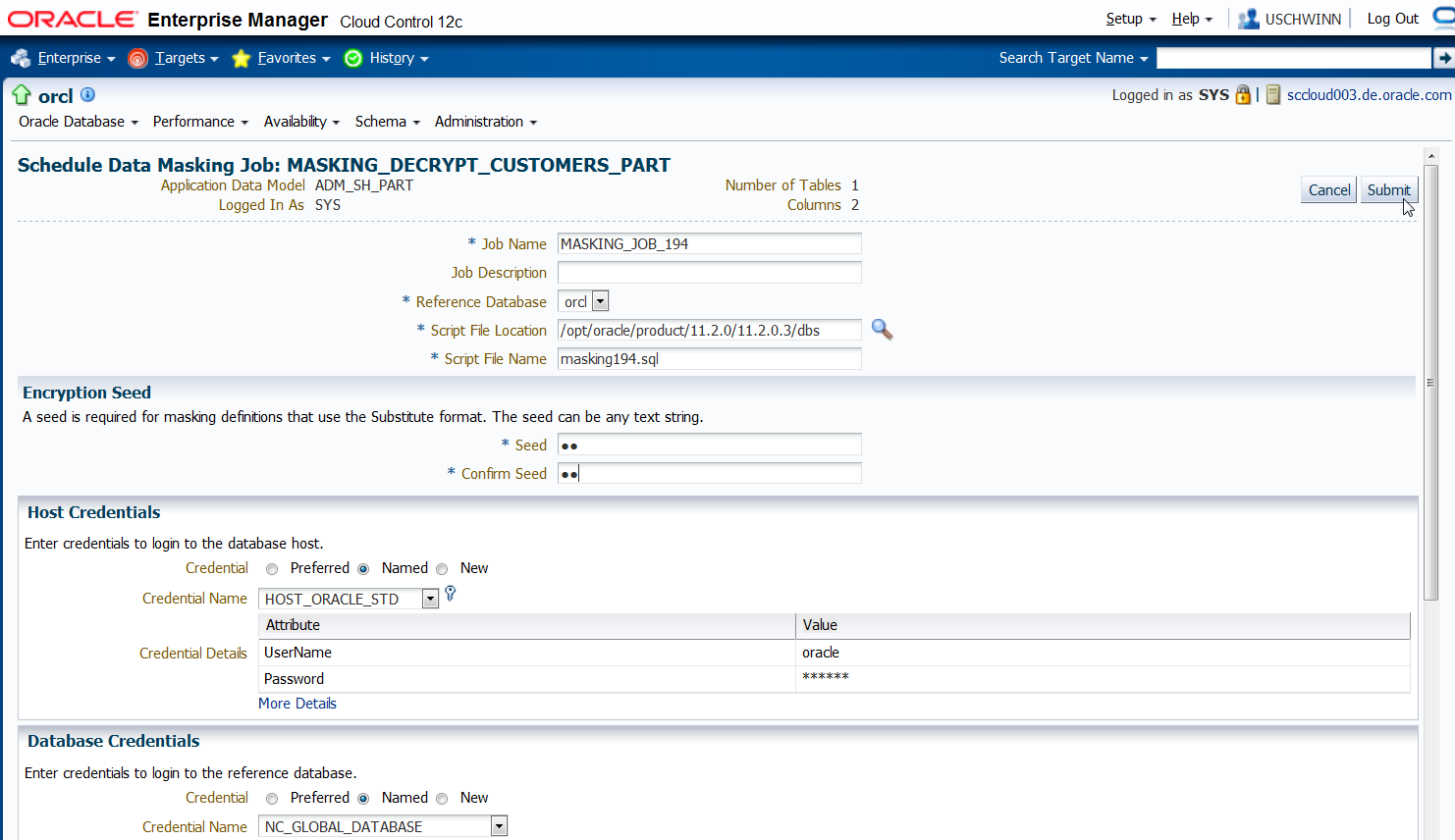
Auf der Seite "Schedule Data Masking Job" sind die Credential Felder für Datenbank und Host Login auszufüllen und ein Eintrag für das Feld "Encryption Seed" vorzunehmen.
Die Information aus dem Feld "Encryption Seed" sollte man sich merken, wenn später eine De-Maskierung der Spalten erfolgen soll.
Nun müssen wir nur noch abwarten bis der Job beendet ist. Die Spalten CUST_MAIN_PHONE_NUMER und CUST_LAST_NAME liegen maskiert vor.
Dabei beträgt die Länge aller Namen nun 8 Zeichen; das Format der Telefonnummern ist, wie zu erwarten, gleich geblieben.
Die De-Maskierung (decrypt)
Nun kommt der "große Augenblick" der De-Maskierung. Für den De-Maskierungsjob wird Folgendes benötigt:
- die regulären Ausdrücke, die zur Format-Erhaltung notwendig waren
- die Information aus dem Feld "Encryption Seed"
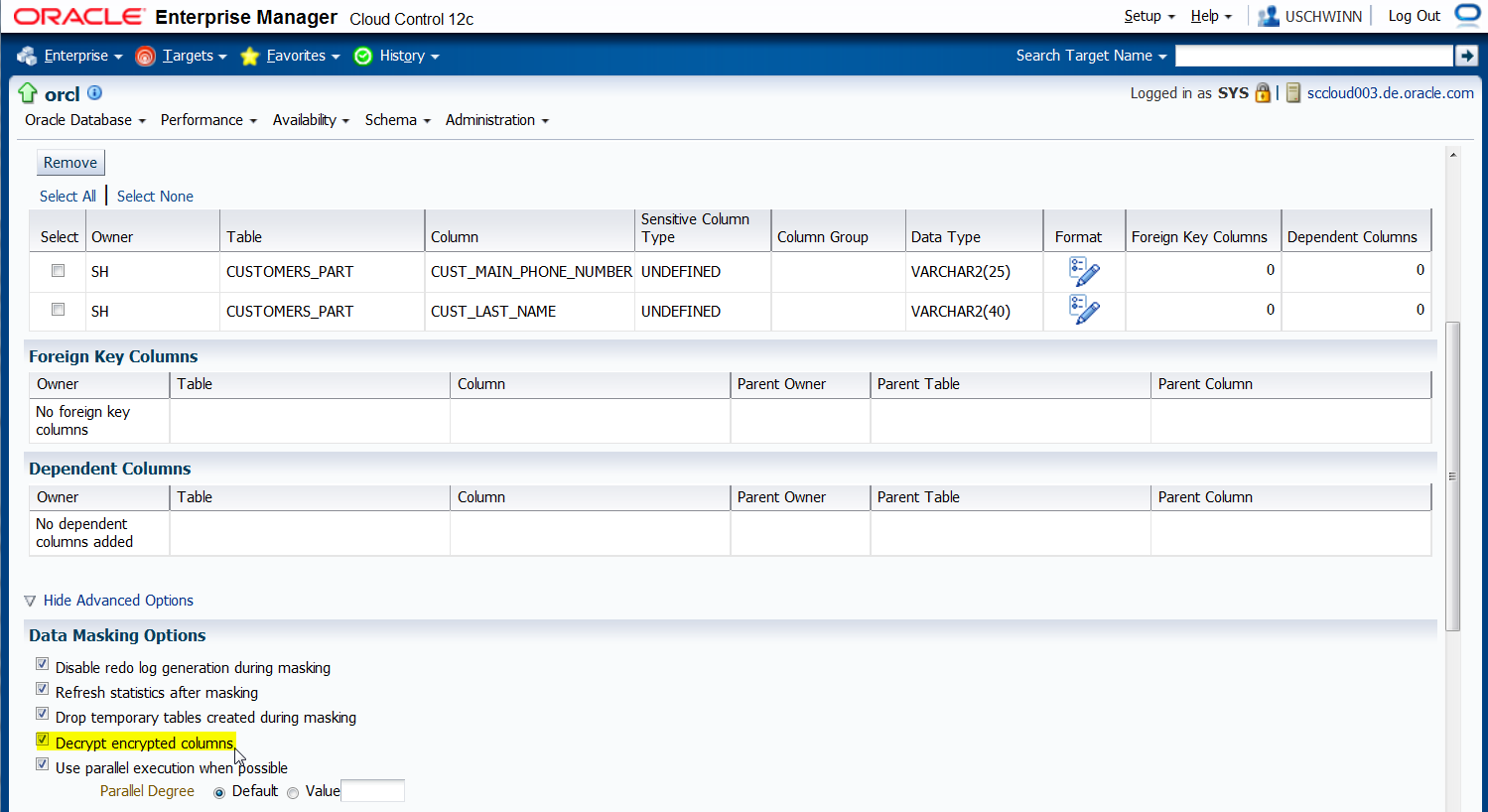
- die Checkbock "Decrypt encrypted columns" unter Advanced Options
Der Job sieht dann folgendermassen aus. Im Unterschied zum Maskierungsjob muss nun die Checkbox "Decrypt encrypted columns" markiert sein.
Nach der Skript-Generierung wird der Job mit "Schedule Job" aufgesetzt. Hier ist wie beim Maskierungsjob der Eintrag zu den Credential Informationen und die
Information aus dem Feld "Encryption Seed" erforderlich.
Nun kommt der Moment der Überprüfung. Die Verifizierung erfolgt über eine Abfrage auf SQL Ebene.
Die Spalte CUST_MAIN_PHONE_NUMBER und die Spalte CUST_LAST_NAME enthalten wieder die ursprünglichen Werte. Da die Länge bei CUST_LAST_NAME auf
8 Zeichen festgelegt war, sind die ungenutzten Felder mit dem Zeichen '*' aufgefüllt worden, d.h. statt "Kessel" haben wir nun "**Kessel".
Eine Bereiniging ist zum Beispiel über folgendes UPDATE Statement möglich:
Lizenzhinweis
Die in diesem Tipp beschriebene Funktionalität ist Teil des Oracle Data Masking Pack for Oracle and non-Oracle Databases.
Informationen und hilfreiche Links
Weitere Informationen finden Sie unter:
Zurück zur Community-Seite
|
 DBA Community - Februar 2012
DBA Community - Februar 2012