|
Erstellung von OLAP Cubes leicht gemacht mit dem Analytic Workspace Manager 11g
von Frank Schneede, ORACLE Deutschland GmbH
Die Technologie des Online Analytical Processing (OLAP) wird im Datawarehouseumfeld dazu verwendet, das in Standardberichten vorliegende Zahlenmaterial einer tiefergehenden
Analyse zu unterziehen. Während Standardberichte häufig durch den Einsatz einzelner, spezialisierter Materialized Views optimiert worden sind, ist dieses bei einer
ad-hoc durchgeführten drill-down-Analyse nicht möglich, da die zugrundeliegenden Abfragen und Berechnungen nicht im Vorfeld klar sind. Aus diesem Grunde lässt die Antwortzeit
für ad-hoc Abfragen leider meistens zu wünschen übrig. Um die Antwortzeiten für ad-hoc Abfragen zu reduzieren, werden daher OLAP-Cubes eingesetzt, die die Daten
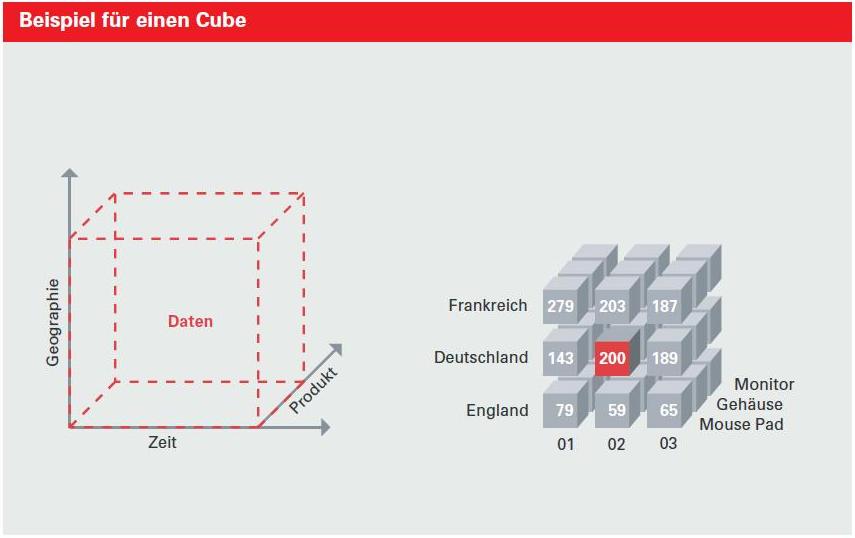
logisch in Form eines mehrdimensionalen Würfels darstellen. Die Dimensionen des OLAP-Cubes beschreiben die Daten und erlauben auf einfache Weise den Zugriff.
Dabei können Daten über eine oder mehrere Achsen des Würfels ausgewählt werden.
 |
| Für eine größere Ansicht auf das Bild klicken |
Bereits seit der Datenbankversion 9i ist die Oracle Datenbank in der Lage, multidimensionale Objekte abzubilden. Im Laufe der Zeit sind die Möglichkeiten dieser Technologie
immer mehr erweitert worden. Der vorerst letzte Evolutionsschritt ist in der aktuellen Version Oracle 11g erfolgt. In dieser Version sind cube-organized Materialized Views
eingeführt worden, die durch den mehrdimensionalen Aufbau eine Vielzahl relationaler Materialized Views ersetzen können und auf diese Weise die Abfrageperformance in Datawarehouses
verbessern helfen. Die Wartung bzw. die Aktualisierung dieser Daten ist durch ein inkrementelles Refresh schnell und leicht durchführbar.
Für den Datenbankadministrator, der bisher vorwiegend mit relational organisierten Daten gearbeitet hat, stellt die multidimensionale OLAP-Welt leider noch häufig ein "Buch mit sieben
Siegeln" dar, das aus diesem Grunde oftmals verschlossen bleibt. Dieser Tipp soll dazu dienen, durch das Aufzeigen von Parallelen zur relationalen Datenbank-Welt
die fremd anmutende OLAP-Welt zu erklären und dem DBA näherzubringen. Gleichzeitig wird mit dem Analytic Workspace Manager 11g ein Werkzeug vorgestellt, das
die Erzeugung multidimensionaler Datenbankobjekte signifikant erleichtert.
Dieser Tipp führt schrittweise durch den Prozeß der Erstellung eines OLAP-Cubes und sollte - im Gegensatz zu den sonst in der DBA-Community erscheinenden Artikeln - zum besseren
Verständnis in einer eigenen Demoumgebung nachvollzogen werden. Zu diesem Zweck müssen als erstes ein paar Vorbereitungen getroffen werden:
- Installation der Oracle Datenbank 11g mit OLAP Option
- Installation des Analytic Workspace Manager 11g
- Installation des Beispiel-Schemas
Installation der Oracle Datenbank 11g mit OLAP Option
Installieren Sie sich eine Oracle Datenbank (Patch Level 11.1.0.7 oder höher).
Installation des Analytic Workspace Manager 11g
Laden Sie den Analytic Workspace Manager 11g, im Folgenden verkürzt AWM 11g genannt, vom
OTN (in der Version 11.1.0.7A oder größer) herunter und folgen den Installationsanweisungen in der
readme-Datei . Eine standalone-Installation ist im Zweifelsfall
ausreichend.
Der AWM 11g ist ebenfalls auf dem Installationsmedium für den Oracle 11g Client enthalten, wenn Sie also über eine Client-Installation verfügen, so können Sie
auch den dort installierten AWM 11g nutzen. Gegebenenfalls muss das aktuelle Patch-Release 11.1.0.7 nachinstalliert werden.
Installation des Beispiel-Schemas
Um Demoszenarien im Datawarehouse-Umfeld sinnvoll durchspielen zu können und einigermaßen aussagekräftige Daten zur Verfügung zu haben, hat sich bewährt, das OLAPTRAIN Schema
zu verwenden, das Sie ebenfalls im OTN bekommen. Folgen Sie den
Installationshinweisen , aber führen Sie nur die Installation des
Schemas, nicht jedoch des Analytic Workspaces SALESTRACK aus. Dieser wird im Laufe dieses Tipps erstellt.
Überblick über das Beispiel-Schema
Nachdem nun die Vorbereitungen getroffen worden sind, können wir uns dem Demo-Schema OLAPTRAIN widmen. Das Schema OLAPTRAIN ist als Star-Schema aufgebaut und besteht aus 5 Tabellen:
- CHANNELS - (Dimensions-)Tabelle mit Vertriebskanälen (Shops, Web-Shops)
- CUSTOMERS - (Dimensions-)Tabelle mit Kundeninformationen
- PRODUCTS - (Dimensions-)Tabelle für Produktinformationen (Lieferant, Abteilung, ...)
- TIMES - (Dimensions-)Tabelle mit Zuordnung der Kalendertage zu unterschiedlichen Zeitabschnitten (Kalenderjahr, Quartal, ...)
- SALES_FACT - (Fakten-)Tabelle aller Verkäufe mit Menge, Stückpreis, Gesamtpreis und Dimensionsinformationen (Datum, Produkt, Kunde, Vertriebskanal)
Das Schema enthält darüberhinaus einige weitere Tabellen, die aber hier keine Rolle spielen sollen. Es sind für alle oben genannten Tabellen, die die Grundlage des OLAP Cubes bilden werden,
Materialized View Logs vorhanden, die später genutzt werden können, um einen inkrementellen Refresh für die Cube-organized Materialized View durchführen zu können.
Die Arbeitsschritte, die zur Erstellung des OLAP Cubes ausgeführt werden müssen, sind:
- Einrichten des Analytic Workspace
- Anlegen von Dimensionen und Ebenen (Level)
- Anlegen der Hierarchie für die Dimension
- Anlegen der Attribute
- Zuordnung (Mapping) der Dimensionen zu relationalen Tabellen
- Verwendung von Templates
- Anlegen des Cubes
- Anlegen von Kennzahlen
- Zuordnung (Mapping) des Cubes zu relationalen Tabellen
- Einrichtung von Query Rewrite für die Cube-organized Materialized View
- Laden der Daten
- Einfache Berichterstellung mit dem Analytic Workspace Manager 11g
Einrichten des Analytic Workspace
Zu einem OLAP Cube gehören eine Vielzahl von Datenbankobjekten, so zum Beispiel Views, Materialized Views, Cubes usw.. Diese Objekte können mit einem intuitiv bedienbaren Tool,
dem AWM 11g in einem sogenannten Analytic Workspace angelegt und verwaltet werden. Nach dem Start des AWM 11g,
wird die Datenbankverbindung, wie bereits aus ähnlichen graphischen Tools (z. B. SQL Developer) bekannt, hinzugefügt. Anschließend wird der Analytic Workspace SALESTRACK
angelegt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Dieses ist die Arbeitsumgebung, die in diesem Tipp verwendet wird. Sie kann in der Praxis dazu verwendet werden, Daten zu analysieren oder auch Berichte in grafischer Darstellung
anzufertigen. Die Durchführung von Wartungsarbeiten wie das Laden von Daten oder das Aktualisieren von Materialized Views findet ebenfalls aus dem AWM 11g heraus statt.
Anlegen von Dimensionen und Ebenen (Level)
Der nächte Schritt befasst sich dann mit dem Anlegen der Dimensionen und der zugehörigen Ebenen (Level). Als Dimensionen haben wir bereits die oben genannten Tabellen identifiziert. Aus diesen
Dimensionen leiten sich schließlich die Ebenen (Level) ab, d. h. die Aggregationsebenen, auf denen die Vertriebsdaten zusammengefaßt werden sollen. Wichtig bei der Festlegung der Ebenen ist, dass
die gewünschte höchstmögliche Granularität die niedrigste Ebene darstellt. Somit ergibt sich folgendes Bild:
- CHANNEL - Der Vertrieb gliedert sich in zwei Vertriebsklassen, den direkten und den indirekten Vertrieb. Diesen Klassen sind die einzelnen Vertriebskanäle (z. B. Katalog, Internet, Shop Paris, ...)
zugeordnet. Damit gibt es drei Aggregationsebenen: Gesamt - alle Vertriebskanäle, Vertriebsklasse und Vertriebskanal.
- GEOGRAPHY - Die Kunden bieten sich für eine Aggregation nach geographischen Kriterien an. Hier gibt es also die Aggragationsebenen: Gesamt - alle Regionen, Region, Land
und Staat/Provinz
- PRODUCT - Die verschiedenen Produkte sind zu Untergruppen (z. B. Kamera Linsen, HD Camcorder, ...) zusammengefaßt, die wiederum unterschiedliche Gruppen (z. B. Kamera Zubehör,
Camcorder, ...) bilden. Die Gruppen sind Kategorien (z. B. Kameras und Zubehör, Camcorder und Zubehör, Personal Computer, ...) und Abteilungen (z. B. Kameras und Camcorder, Computer, ...)
zugeordnet. Damit ergeben sich also sechs Ebenen: Gesamt - alle Produkte, Abteilung, Kategorie, Typ, Untergruppe und Artikel.
- TIME - Die Zeit-Dimension gliedert sich nach den üblichen Kriterien: Gesamt - alle Jahre, Kalenderjahr, Quartal und Monat.
Wie man schon an diesem kleinen Beispiel erkennt, folgt die Aufteilung in Aggregationsebenen nicht zwingend einer Baumstruktur, in der eine Ebene einer höheren Verdichtungsebene ausschließlich aus der
Zusammenfassung der nächstniedrigen Ebene besteht. Die Aggregationsebenen ergeben sich im Allgemeinen aus den Anforderungen des Business, für das dieser OLAP Cube verwendet werden soll.
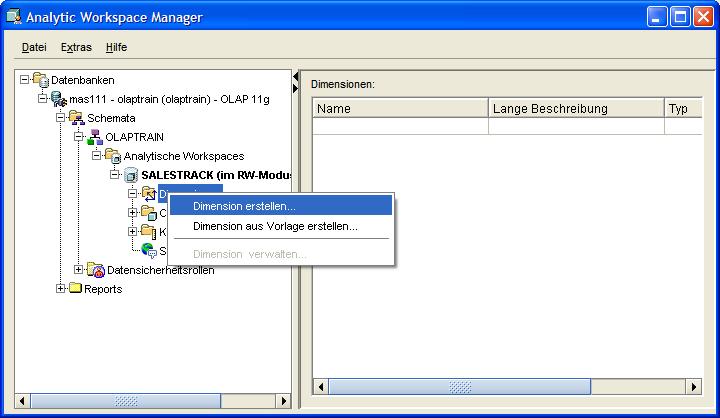
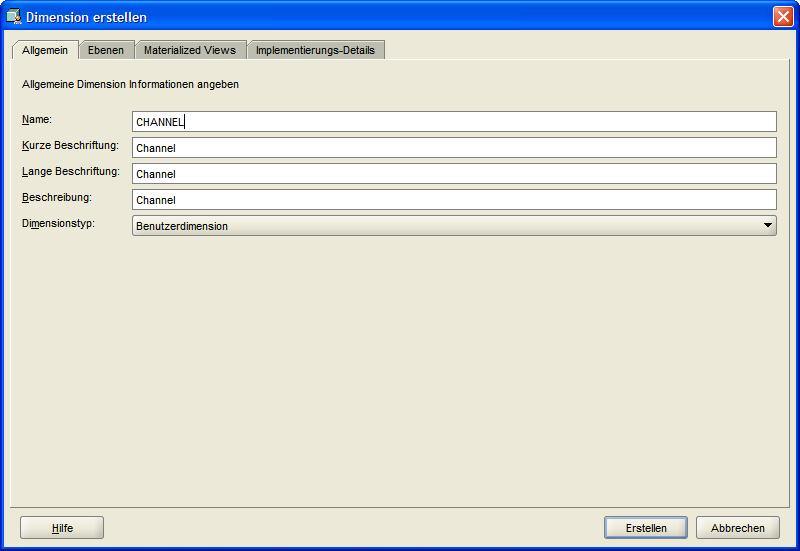
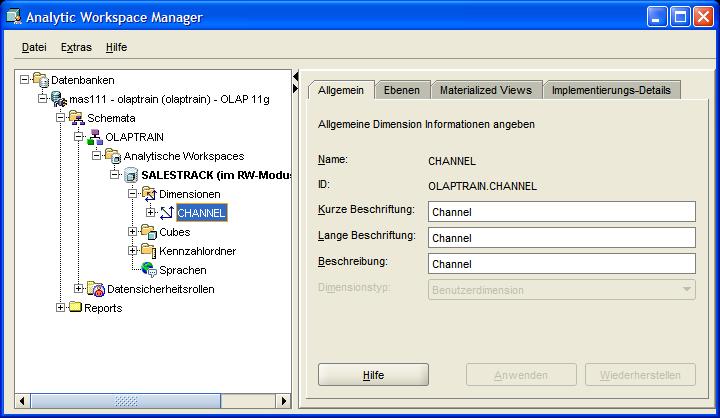
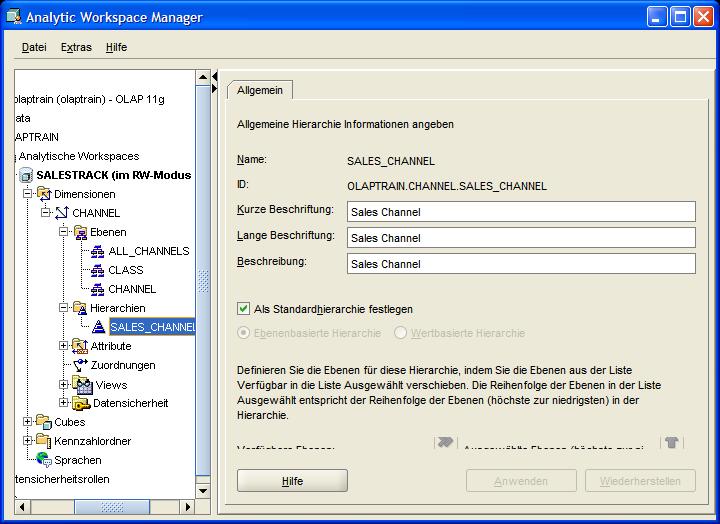
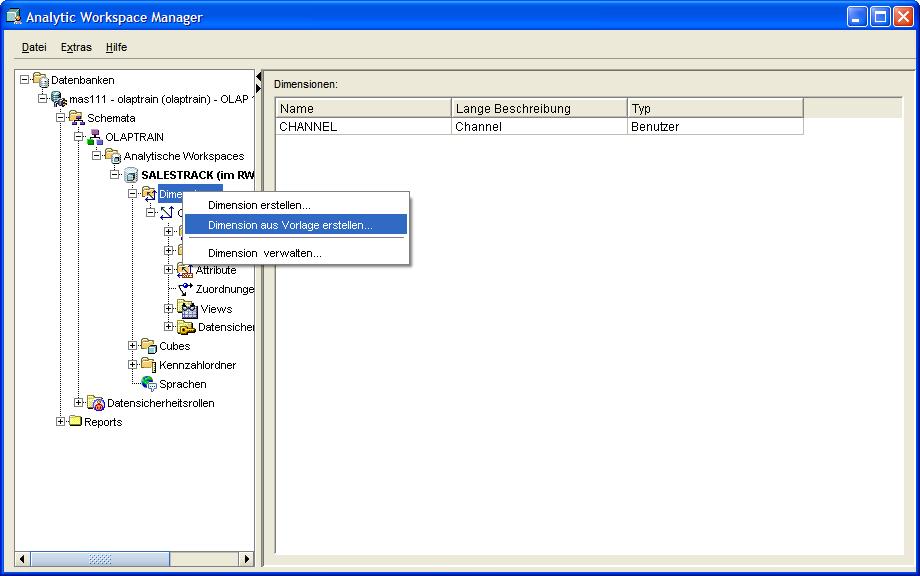
Eine neue Dimension wird jetzt im AWR 11g über das Kontextmenü im Navigationsbaum angelegt. In dem erscheinenden Fenster wird im Reiter Allgemein (General) als
erstes der Name der Dimension (hier: CHANNEL) angegeben, dieser wird automatisch in die anderen Beschreibungsfelder übernommen:
| Für eine größere Ansicht auf das betreffende Bild klicken |
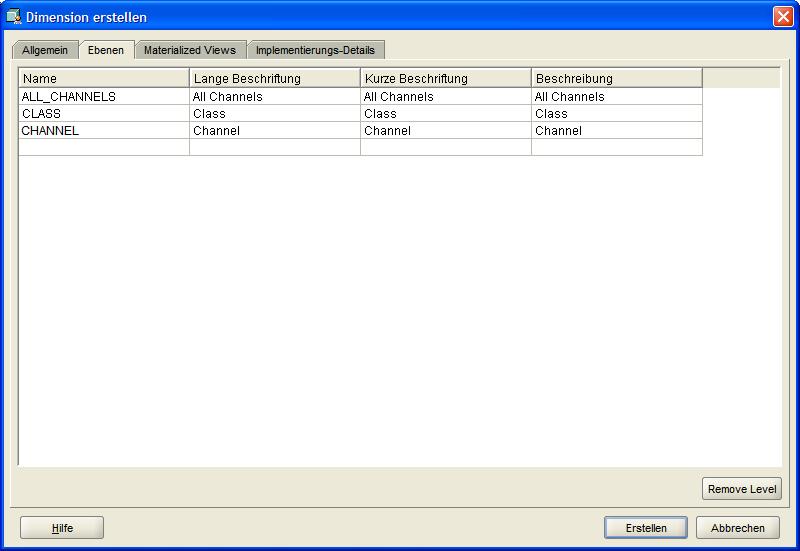
Im nächsten Reiter Ebenen (Level) werden die zu der Dimension gehörigen Ebenen (Level) spezifiziert, auch hier braucht nur der Name eingegeben werden.
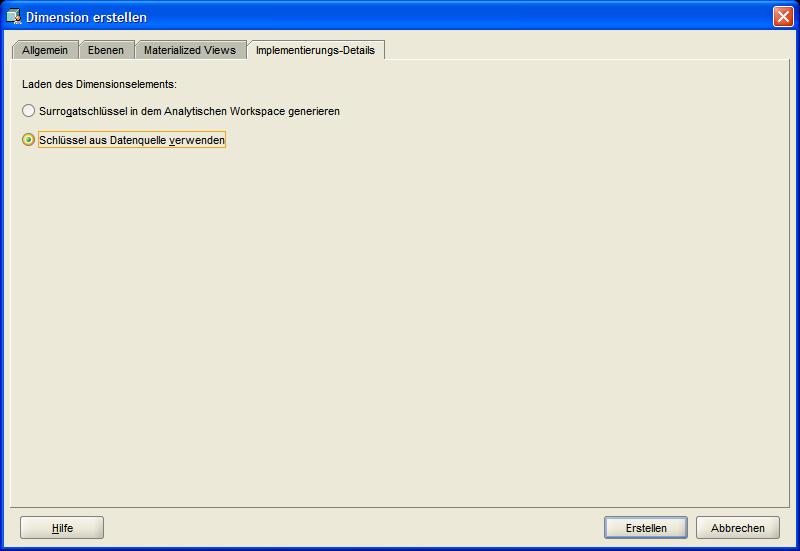
Schließlich wird noch im Reiter Implementierungs-Details (Implementation Details) festgelegt, ob die Aggregationsebene durch einen Primärschlüssel eindeutig ermittelt werden können.
Dieses ist in dem vorliegenden Beispiel der Fall, jedoch kann es in der Praxis durchaus vorkommen, dass ein Ersatz-Schlüsselbegriff (Surrogate Key) angelegt werden muss.
Nachdem der Button zum Erstellen (Create) der Dimension betätigt worden ist, ist nun die Dimension in ihrer Grundstruktur angelegt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
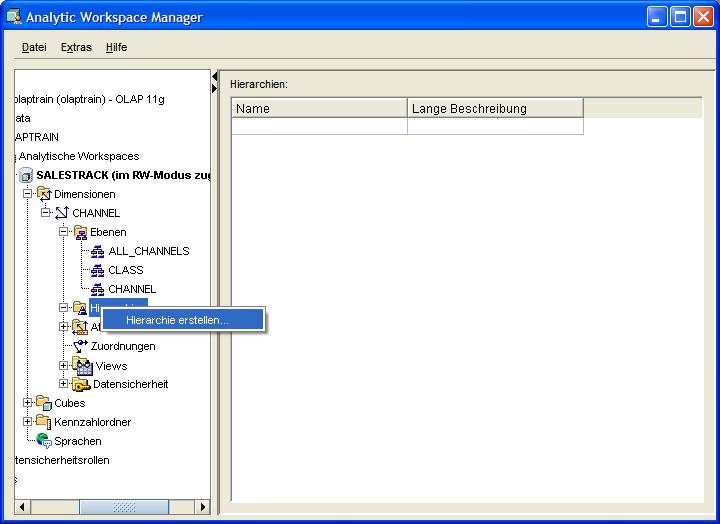
Anlegen der Hierarchie für die Dimension
Für die Durchführung von Geschäftsanalysen müssen nun die mit der Dimension korrespondierenden Hierarchien angelegt werden, für die dann jeweils Aggregationen vorausberechnet werden.
Die hier anzulegende Hierarchie kann dann im Analyseprozeß als "Drill-Down-Pfad" verwendet werden - das ist unabhängig davon, ob die in der Hierarchie berechneten Aggregationsebenen vollständig
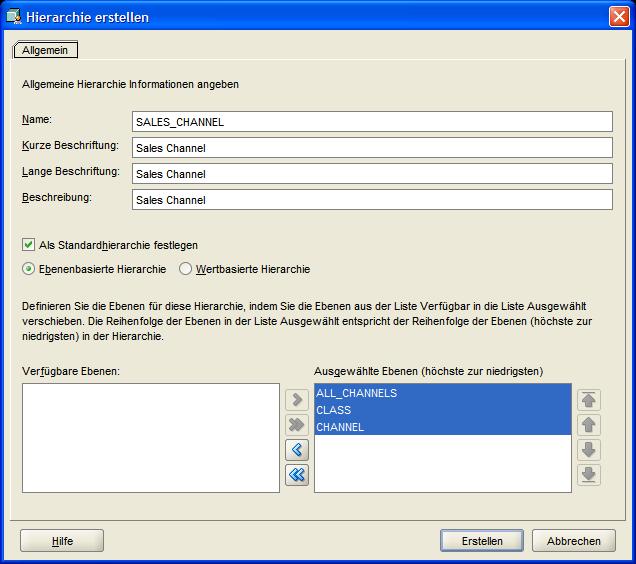
aggregierte Gesamtsummen darstellen. Dimensionen können durchaus mehrere Hierarchien besitzen, wovon jedoch eine als Default-Hierarchie festgelegt werden muss. Der Ablauf der
Anlage ist ziemlich selbsterklärend, es werden alle oben definierten Ebenen in die neu angelegte Hierarchie übernommen, die nach der Anlage im Menübaum erscheint:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Anlegen der Attribute
Für die Bestandteile der Dimensionsdefinition werden im nun folgenden Arbeitsschritt zusätzliche Attribute angelegt, die zur Datenauswahl und Beschriftung der Daten in Berichten
verwendet werden. Hierbei werden für jede Dimension zunächst Lang- und Kurzbeschreibungen festgelegt. Zeit-Dimensionen haben zusätzlich Attribute, die die Zeitspanne und das Enddatum
einer Periode beschreiben. Es ist natürlich darüberhinaus möglich, eigene Attribute zu definieren.
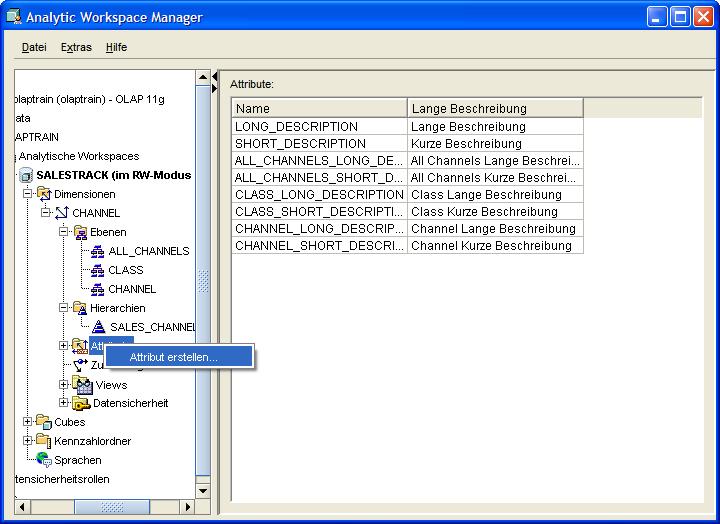
In diesem Beispiel wird nun das Attribut CHANNEL_TYPE über das Kontextmenü erstellt und die standardmäßig vorgegebenen Attribute werden kontrolliert:
 |
| Für eine größere Ansicht auf das Bild klicken |
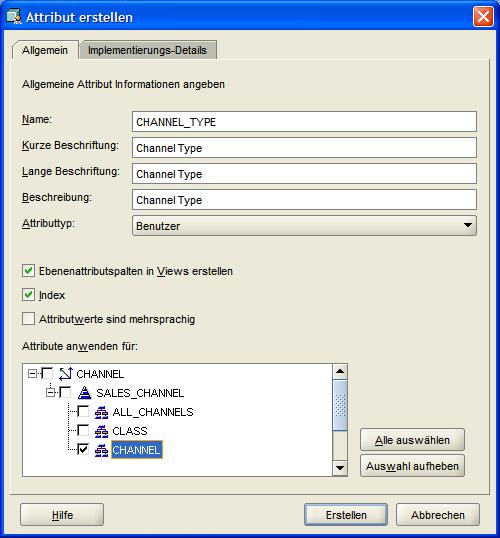
Der Name CHANNEL_TYPE wird vergeben, wobei die verschiedenen Beschriftungen automatisch ergänzt werden. Dieses benutzerdefinierte Attribut soll nur für die Hierarchie CHANNEL gelten:
 |
| Für eine größere Ansicht auf das Bild klicken |
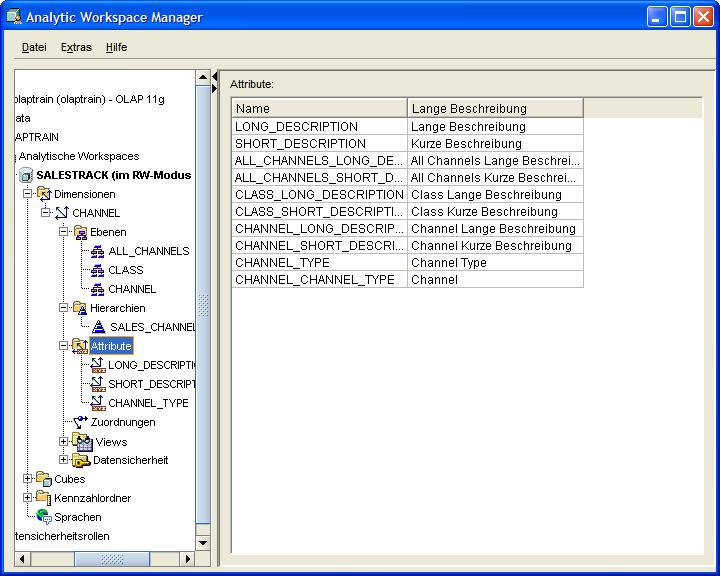
Nachdem der Button zur Erstellung des Attributes betätigt worden ist, erscheint das neue Attribut im Menübaum:
 |
| Für eine größere Ansicht auf das Bild klicken |
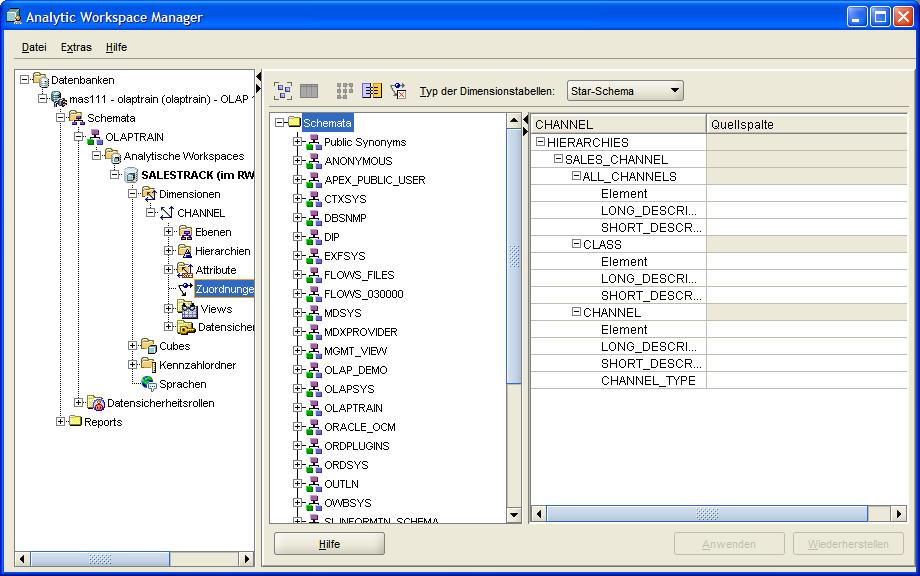
Zuordnung (Mapping) der Dimensionen zu relationalen Tabellen
Zu diesem Zeitpunkt sind die OLAP Datenobjekte erstellt und es muss nun eine Zuordnung (Mapping) zu den relationalen (Quell-) Tabellen erfolgen. Hierbei werden die Schlüsselspalten
dem Element-Attribut der OLAP-Dimension per drag-and-drop zugeordnet und schließlich die Beschreibungsfelder auf die gleiche Weise versorgt.
Nach dem Navigieren im Menübaum des AWM 11g zu dem Punkt Zuordnungen (Mappings) erscheint die Übersicht der zu versorgenden Attribute und der Menübaum zum navigieren in den Schemas,
die für die Zuordnungen herangezogen werden:
 |
| Für eine größere Ansicht auf das Bild klicken |
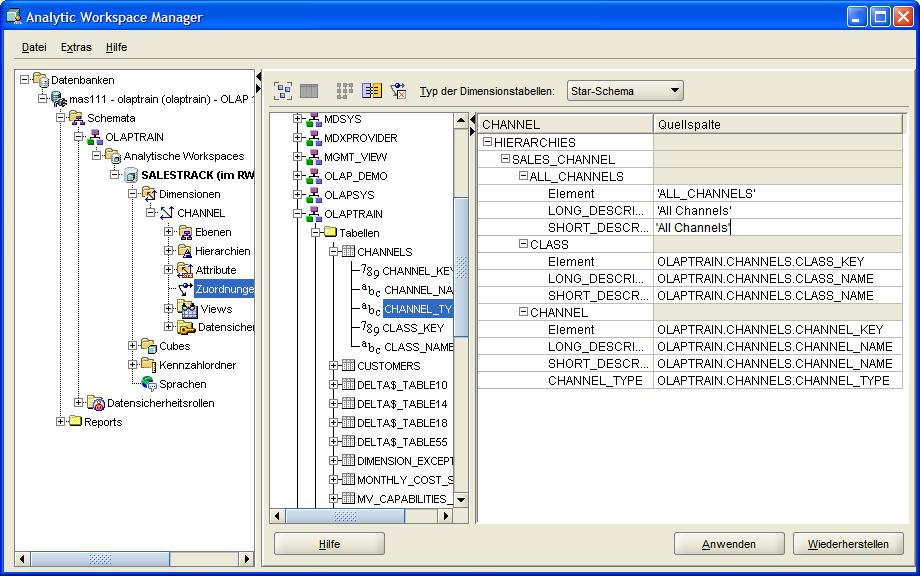
Der Menübaum im Schemanavigator wird aufgeklappt, bis die Spalten der Dimensionstabelle CHANNELS erscheint. Aus dieser werden dann die Quellspalten (Source Columns) per drag-and-drop gefüllt, lediglich
der Text für die oberste Hierachieebene (ALL_CHANNELS) muss manuell ausgefüllt werden. Somit ergibt sich folgendes Bild, welches durch Betätigen des Buttons Anwenden (Apply) nur noch
in die Datenbank übernommen wird:
 |
| Für eine größere Ansicht auf das Bild klicken |
An dieser Stelle wäre die Dimension CHANNEL fertiggestellt und könnte mit Daten versorgt werden, diese geschieht in diesem Beispiel jedoch erst in einem späteren Schritt.
Verwendung von Templates
Es ist bereits zu diesem Zeitpunkt ersichtlich, dass das Anlegen eines OLAP Cubes mit einigen Arbeitsschritten verbunden ist. Da eine solche Struktur möglicherweise auf unterschiedlichen
Systemen, z. B. Entwicklungs-, Integrations- und Produktionsumgebung abgebildet werden soll, ist es sinnvoll, eine Möglichkeit der Übertragung der Strukturen zu schaffen. Diese Möglichkeit
bilden sogenannte Templates, das sind XML-Dateien, die die Definition der Objekte (Workspace, Dimension, Cube oder Kennzahlen) im AWM 11g, nicht jedoch die Daten, enhalten. Mit diesen
Templates ist es möglich,
- Analytic Workspaces zwischen Benutzern auszutauschen
- Objektdefinitionen zu anderen Schemas oder Instanzen zu übertragen
- Objektdefinitionen außerhalb der Datenbank zu sichern
- Objektdefinitionen in einem Konfigurationsmanagement zu verwalten
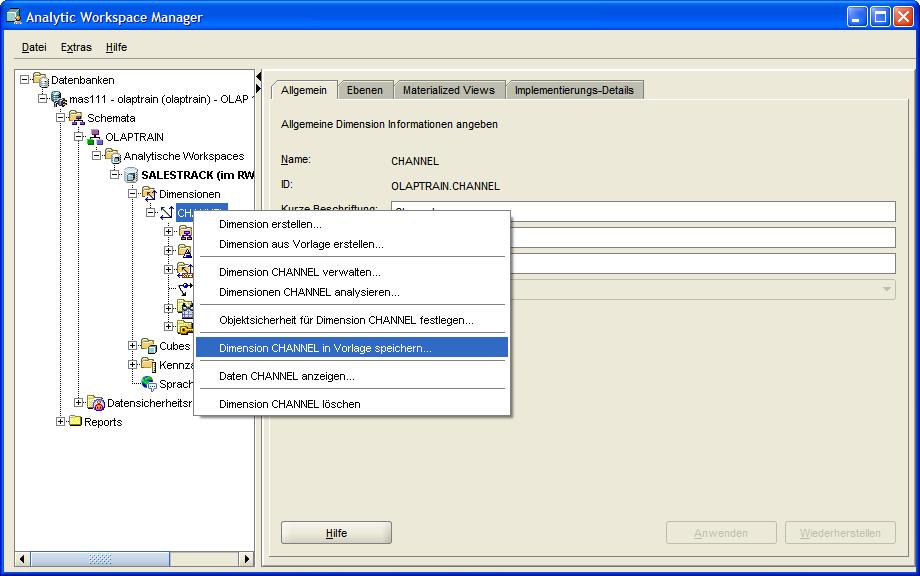
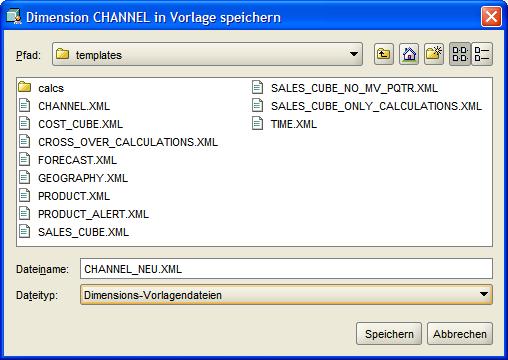
Das Speichern der Dimensionsdefinition erfolgt denkbar einfach über das Kontextmenü, das erscheint, wenn die rechte Maustaste im Menübaum des AWM 11g auf der Dimension CHANNEL
betätigt wird:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Ebenso einfach ist es, weitere Dimensionen in den Analytic Workspace SALESTRACK einzuspielen. Die Definitionen, die in diesem Beispiel verwendet werden, liegen ebenfalls im
OTN zum Download bereit. Das entpackte Verzeichnis enthält alle in den
folgenden Abschnitten benötigten Definitionen.
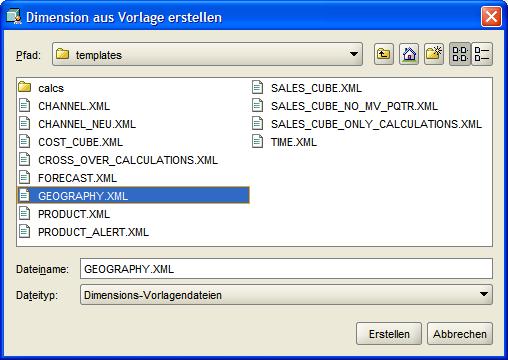
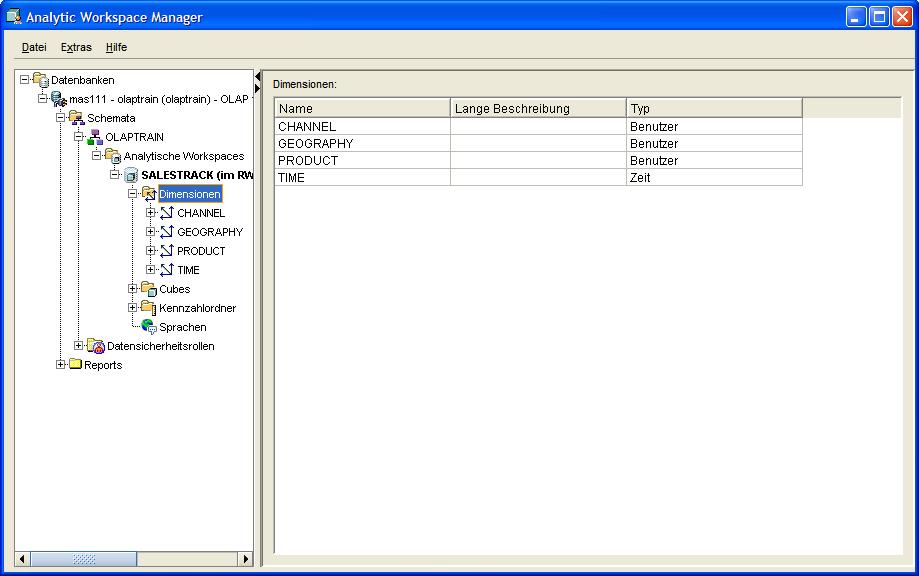
Das Erstellen der fehlenden Dimensionen GEOGRAPHY, PRODUCT und TIME erfolgt intuitiv mittels Kontextmenü im Navigationsfenster und Auswahl der entsprechenden XML Datei. Nachdem das
Fortschrittsfenster geschlossen worden ist, erscheinen alle angelegten Dimensionen im rechten Fenster des AWM 11g:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Anlegen des Cubes
Nach den vorbereitenden Arbeiten ist es nun soweit, dass der OLAP Cube angelegt werden kann. Ein OLAP Cube ist im Grunde nichts anderes als eine Sammlung von Kennzahlen, die durch
die gleichen Dimensionen beschrieben werden. OLAP Cubes unterstützen die Definition von Kennzahlen unter anderem durch folgende Eigenschaften:
- Die Kanten eines OLAP Cubes werden durch die Dimensionen, hier also durch CHANNEL, GEOGRAPHY, PRODUCT und TIME beschrieben. Kennzahlen, die die gleiche Dimensionalität
besitzen, werden üblicherweise in einem OLAP Cube gespeichert.
- Kennzahlen mit einer ähnlichen Verteilung bzw. Aggregationsregeln werden ebenfalls in einem OLAP Cube gespeichert.
- Kennzahlen eines OLAP Cubes stehen zu anderen logischen Objekten in der gleichen Beziehung und können auf leichte Weise analysiert und zusammen angezeigt werden.
- Ein Analytic Workspace kann durchaus mehrere OLAP Cubes enthalten, wobei die unterschiedlichen Cubes sich dann in ihrer Dimensionalität unterscheiden.
- Dimensionen in einem Analytic Workspace können von mehreren OLAP Cubes verwendet werden.
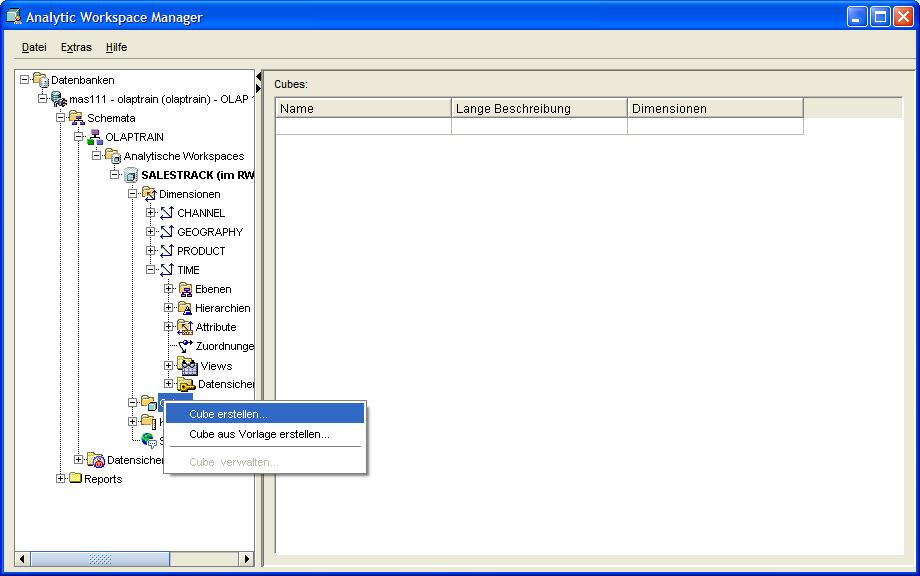
Wir werden nun in diesem Beispiel einen OLAP Cube anlegen, der Verkaufsdaten enthält. Die Kanten enthalten dann die Werte der Dimensionen für Zeit (TIME),
Gebiet (GEOGRAPHY), Vertriebskanal (CHANNEL) und Produkt (PRODUCT). Im Cube selbst werden nicht nur Kennzahlen für Umsatzzahlen und verkaufte Einheiten liegen,
sondern darüberhinaus einige berechnete Kennzahlen, die sich aus Umsatz und verkauften Einheiten ableiten lassen. Über die rechte Maustaste und die entsprechende
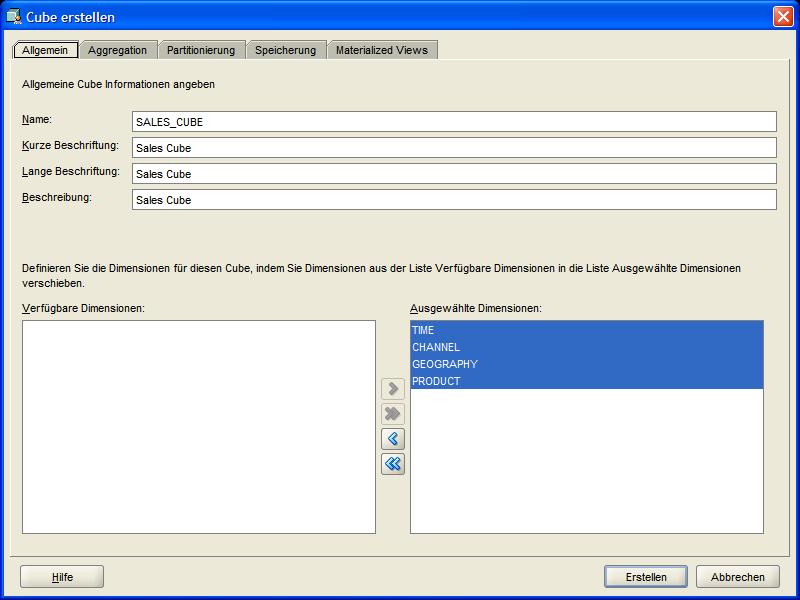
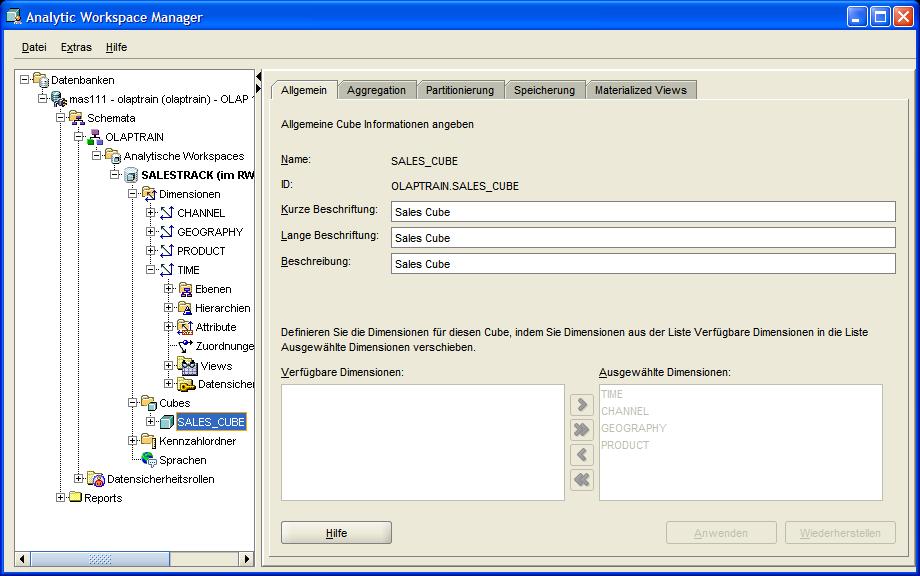
Auswahl im Kontextmenü öffnet sich ein Wizard, der durch alle Schritte der Definition des OLAP Cubes durchführt. Im ersten Reiter Allgemein (General) wird ein
Name für den OLAP Cube festgelegt und die Auswahl der Dimensionen durchgeführt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
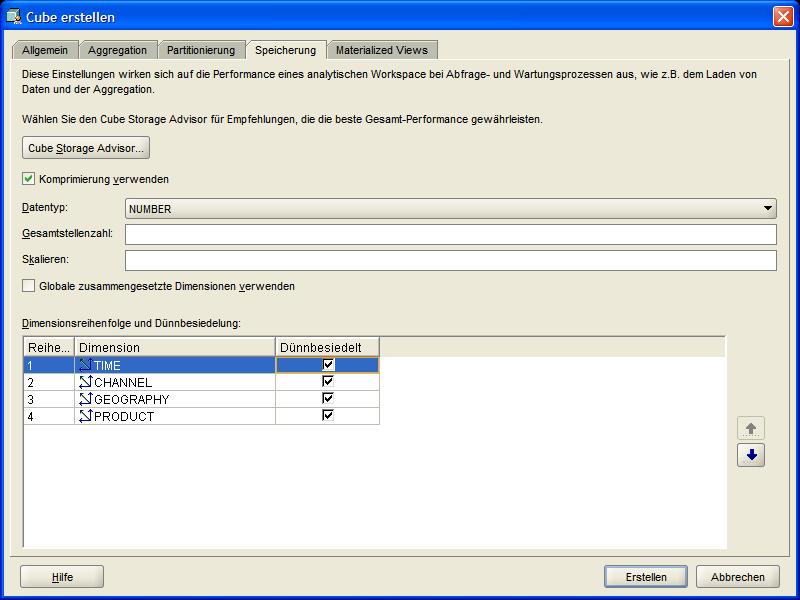
Im Reiter Speicherung (Storage) wird festgelegt, wie der Speicher für den OLAP Cube beschaffen sein soll. Hierbei spielt es eine Rolle, wie die Verteilung der Daten
(Sparsity) ist. Eine "dünnbesiedelte" (sparse) Verteilung bedeutet, dass bei einer Komprimierung, die standardmäßig aktiviert ist, eine große Ersparnis an Speicherplatz
zu erwarten ist. Für jede der Dimensionen ist anzugeben, ob diese "dünnbesiedelt" (sparse) ist, also viele leere Zellen im OLAP Cube enthalten sind. Dieses sollte
grundsätzlich eingeschaltet werden, denn dann wird ein Index angelegt, der den Zugriff auf die betreffenden Dimensionsinformationen beschleunigt:
 |
| Für eine größere Ansicht auf das Bild klicken |
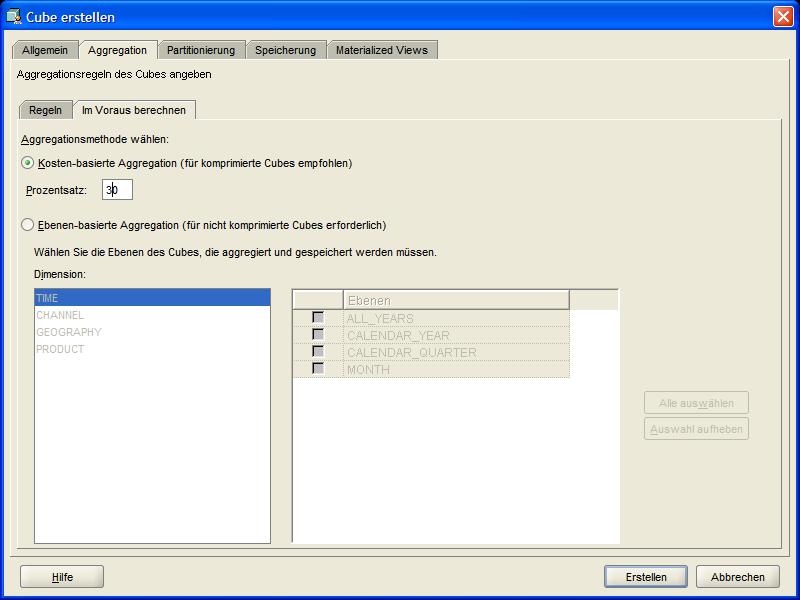
Der folgende Schritt im Reiter Aggregation dient dazu, bereits bei der Erstellung des OLAP Cubes eine Vorausberechnung der kostenintensivsten Aggregate
bilden zu lassen. Der in diesem Beispiel gewählte Aggregationsfaktor von 30% bewirkt, dass ein größerer Teil des OLAP Cubes vorausberechnet wird, als durch den
standardmäßig vorgegebenen Wert von 20%. In OLAP Cubes besteht in der Version 11g die Möglichkeit, die kostenbasierte Vorausberechnung durchzuführen -
dieses setzt jedoch voraus, dass der OLAP Cube im vorausgegangenen Schritt komprimiert angelegt wurde:
 |
| Für eine größere Ansicht auf das Bild klicken |
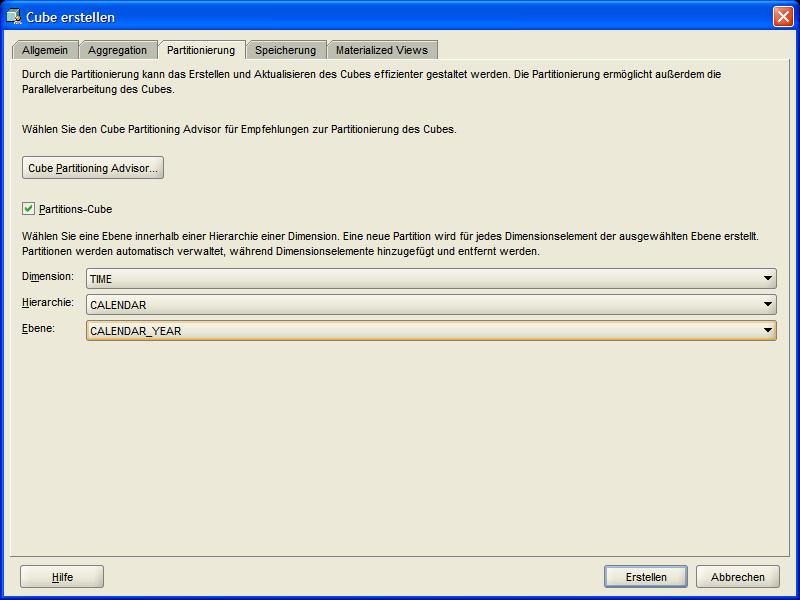
Im letzten Reiter Partitionierung (Partitioning) dieses Wizards wird festgelegt, ob der vorliegende OLAP Cube partitioniert erstellt werden soll. Dieses macht häufig
durchaus Sinn, denn bei einer mehrdimensionalen Betrachtung kommen sehr schnell erhebliche Datenmengen zusammen. In diesem Beispiel wird die Dimension TIME
auf Jahresebene partitioniert. Nach der Betätigung des Buttons Erstellen (Create) erscheint der OLAP Cube im Navigationsbaum:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Anlegen von Kennzahlen
Das Anlegen von Kennzahlen füllt nun den OLAP Cube mit analytischem Inhalt. Man unterscheidet hierbei zwei Arten von Kennzahlen:
- Gespeicherte oder Basis-Kennzahlen - Diese bilden die zahlenmäßige Grundlage des Geschäftes und sind direkt in den Faktentabellen enthalten. Es werden
im folgenden Schritt nur noch die Mappings zu den Quelldaten hergestellt - so, wie es bereits bei den Dimensionen geschehen ist.
- Berechnete Kennzahlen - Die berechneten Kennzahlen zeigen auf eindrucksvolle Weise die Mächtigkeit multidimensionaler Auswertungen, indem
geschäftliche Berechnungen leicht und effizient in der Datenbank erstellt und abgelegt werden können. Üblicherweise ist die Anzahl der berechneten
Kennzahlen in einem OLAP Cube erheblich größer als die der Basis-Kennzahlen.
Berechnete Kennzahlen leiten sich entweder aus Basis-Kennzahlen ab oder werden aus anderen berechneten Kennzahlen gebildet. Die definierten Berechnungen
werden dynamisch ausgeführt, sobald der Benutzer eine berechnete Kennzahl abfragt. Die berechneten Kennzahlen erscheinen als zusätzliche Spalten in der
Cube-View, die mit dem OLAP Cube zusammen erzeugt wird.
Der AWM 11g bietet ein graphisches User Interface, mit Hilfe dessen berechnete Kennzahlen sehr intuitiv angelegt werden können. Vordefinierte
Berechnungsregeln für sehr viele Geschäftsvorfälle sind bereits enthalten, die dann ausgewählt und auf die individuellen Bedürfnisse angepaßt werden können.
Natürlich können berechnete Kennzahlen - auch das wird in diesem Abschnitt beschrieben - wie bereits die oben angelegten Dimensionen über Templates
erstellt werden.
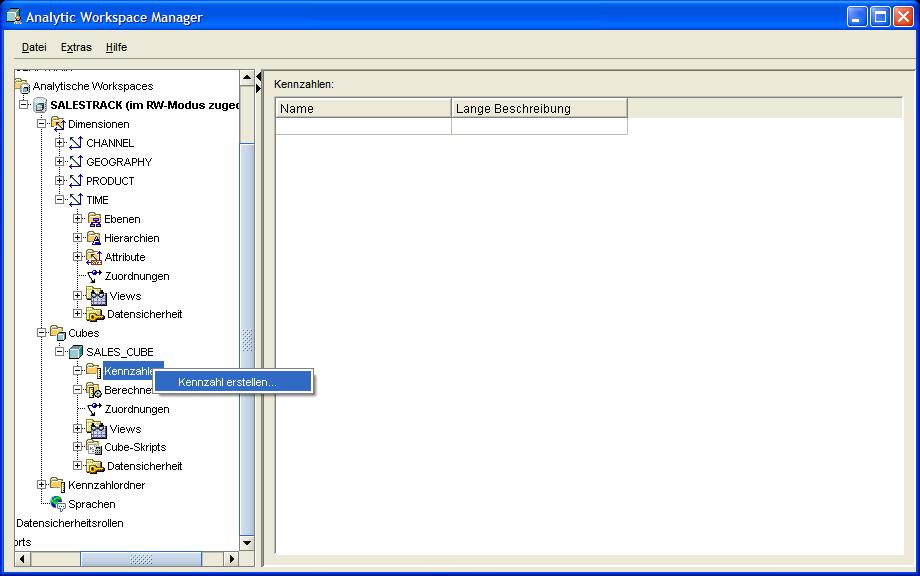
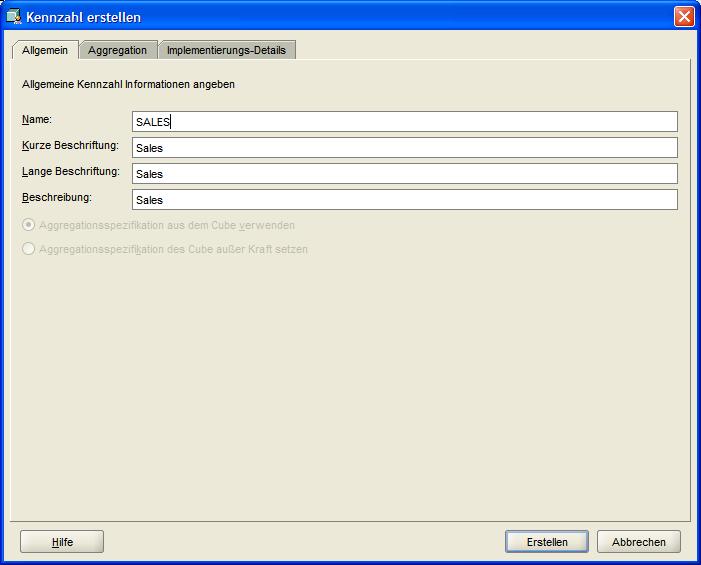
Zum Erstellen einer Basis-Kennzahl sind nur zwei Schritte notwendig. Über die rechte Maustaste im Navigationsbaum und die entsprechende Menüauswahl
erscheint ein Fenster, in dem lediglich der Name der Basis-Kennzahl (in diesem Beispiel SALES) eingegeben werden muß. Der Erstellen-Button
schließt den Vorgang ab:
 |
 |
| Für eine größere Ansicht auf das betreffende Bild klicken |
Die zweite in diesem Beispiel verwendete Basis-Kennzahl QUANTITY wird auf gleiche Weise erstellt.
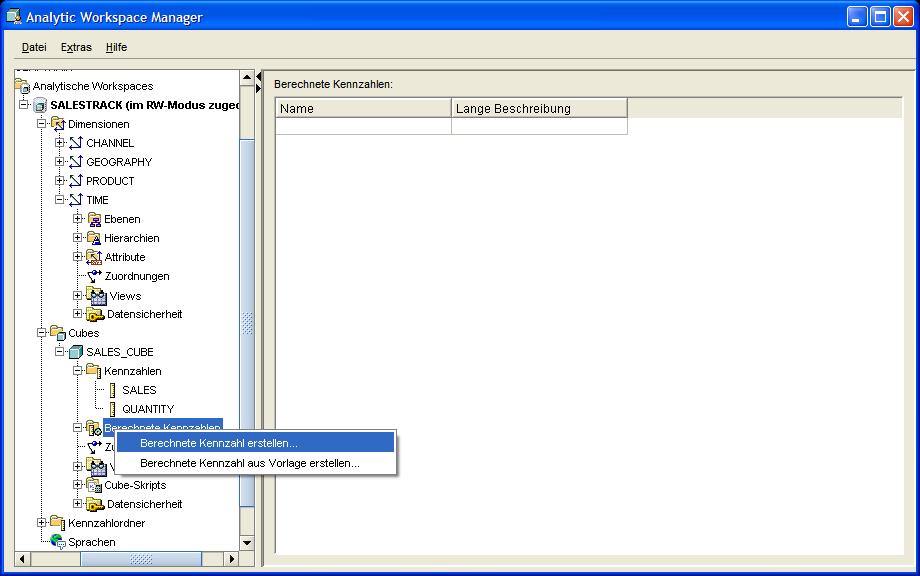
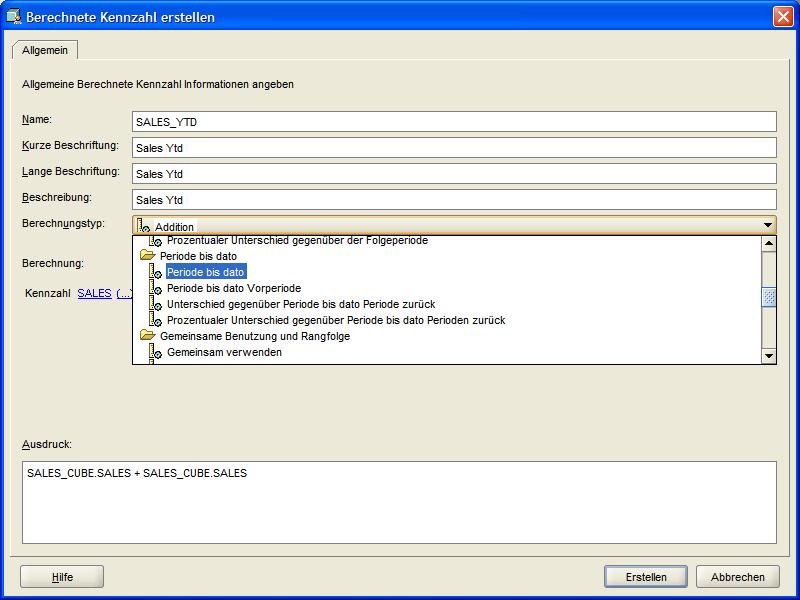
Nun kommt der wesentlich aufwändigere und für die spätere Durchführung analytischer Betrachtungen wichtigere Schritt der Anlage von berechneten Kennzahlen.
Auch hier wird über das Kontextmenü und die entsprechende Menüauswahl ein Fenster geöffnet, in dem als erstes der Name der neuen berechneten Kennzahl (in
diesem Beispiel SALES_YTD, also die kumulierten Verkäufe) eingetragen wird. Anschließend wird die Berechnung definiert, in der Auswahlliste in diesem
Fall also "Periode bis dato" (Period To Date) ausgewählt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
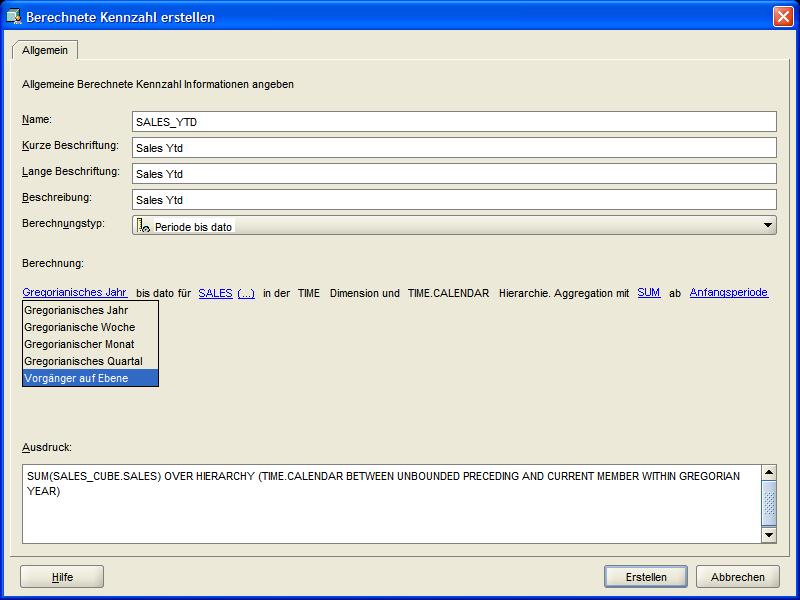
Durch diesen Vorgang erscheint ein freier Text mit Hyperlinks als Beschreibung. In diesem Bereich können dann die Vorgaben der berechneten Kennzahl an die
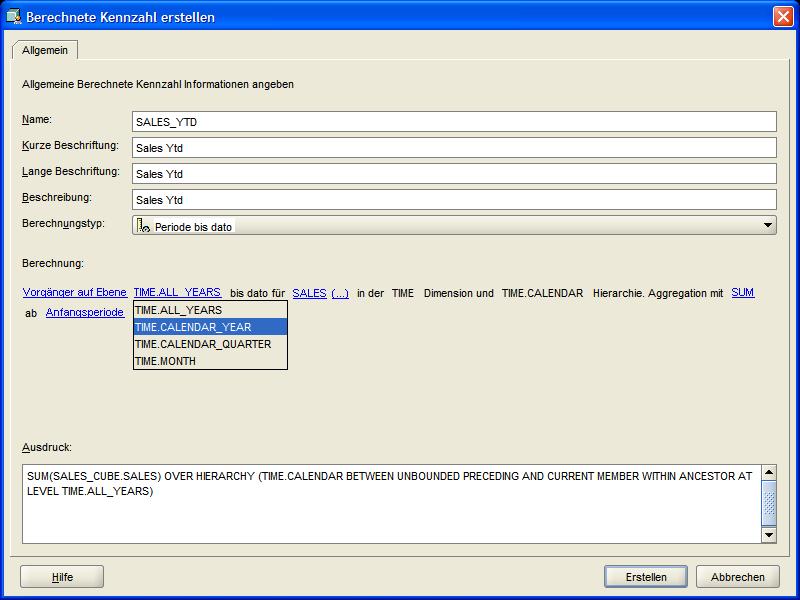
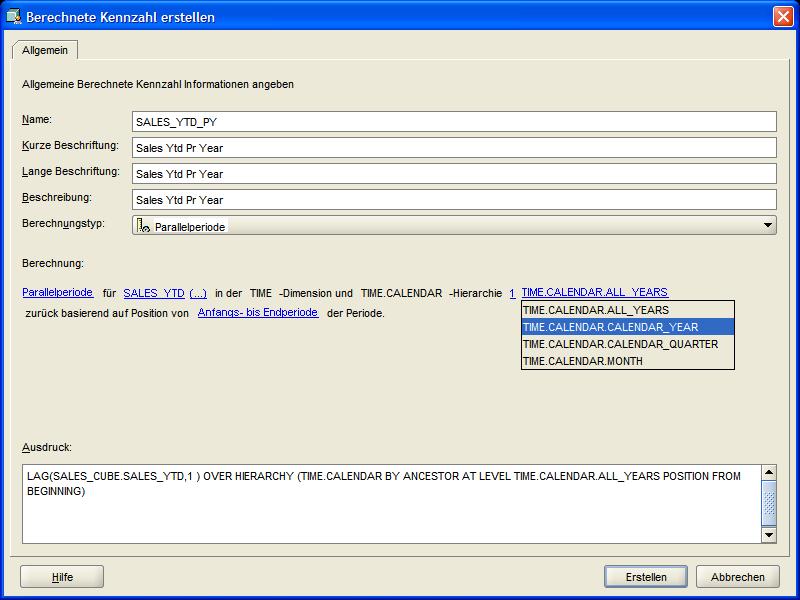
eigenen Erfordernisse angepaßt werden. Das bedeutet für die vorliegende berechnete Kennzahl, dass im ersten Hyperlink "Vorgänger auf Ebene" (Ancestor At Level) ausgewählt wird,
worauf ein neuer Hyperlink in der Beschreibung erscheint. Über diesen Hyperlink wird schließlich als Hierarchieebene der Dimension TIME das Kalenderjahr
ausgewählt und der Vorgang über den Erstellen-Button zum Abschluß gebracht:
| Für eine größere Ansicht auf das betreffende Bild klicken |
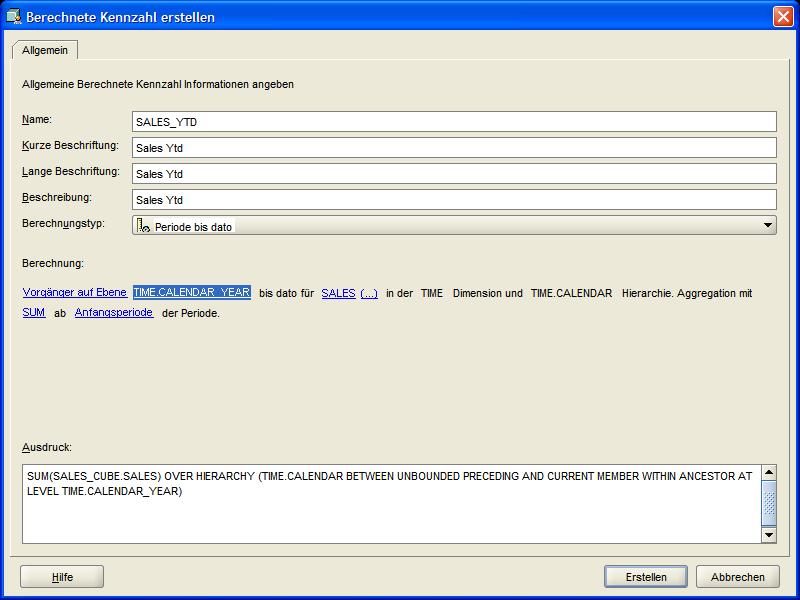
Bereits mit der Anlage dieser ersten berechneten Kennzahl sieht man an dem im Fenster dargestellten Ausdruck, wie komplex die SQL-Darstellung der
berechneten Kennzahl ist und wie einfach sich im Gegensatz dazu die Arbeit mit dem AWM 11g gestaltet.
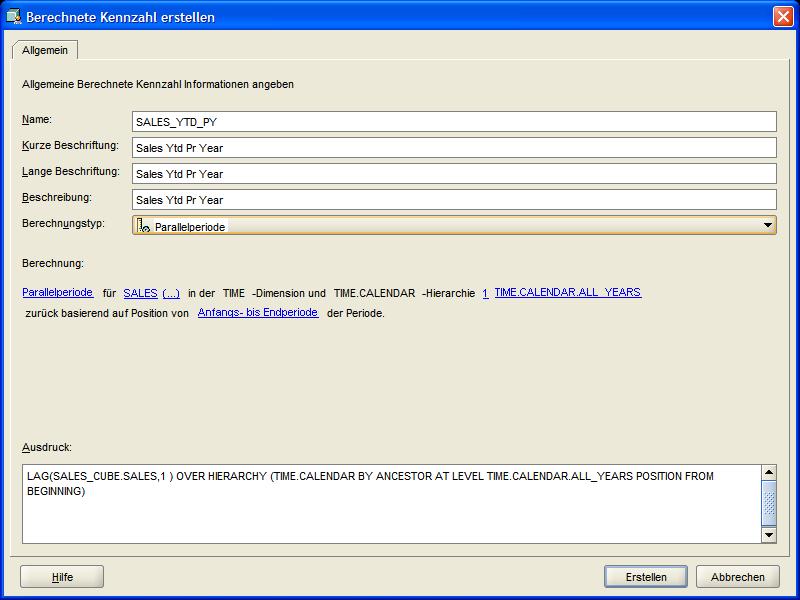
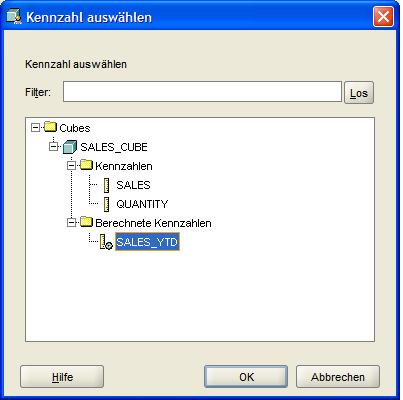
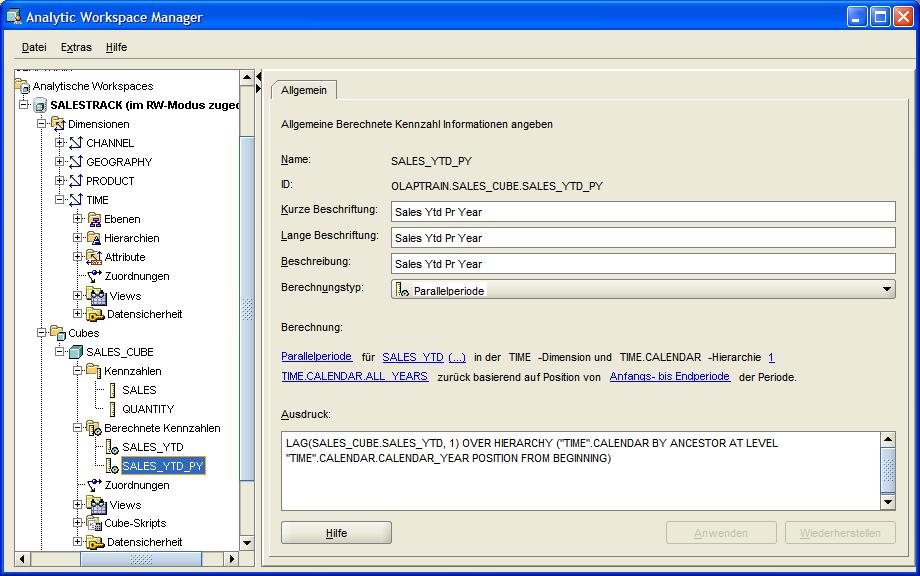
Die zweite berechnete Kennzahl SALES_YTD_PY zeigt die Verkäufe des gleichen Zeitraumes im Vorjahr. Hierzu wird als Berechnungstyp "Parallelperiode" (Parallel Period) gewählt, über
den Hyperlink öffnet sich ein Fenster, in dem die Kennzahl (hier: SALES_YTD) ausgewählt wird, auf die in dieser Kennzahl Bezug genommen wird. Auch hier wird wieder das Kalenderjahr
als Hierarchieebene der Dimension TIME ausgewählt. Nach der Fertigstellung erscheinen die angelegten Kennzahlen im Navigationsbaum:
| Für eine größere Ansicht auf das betreffende Bild klicken |
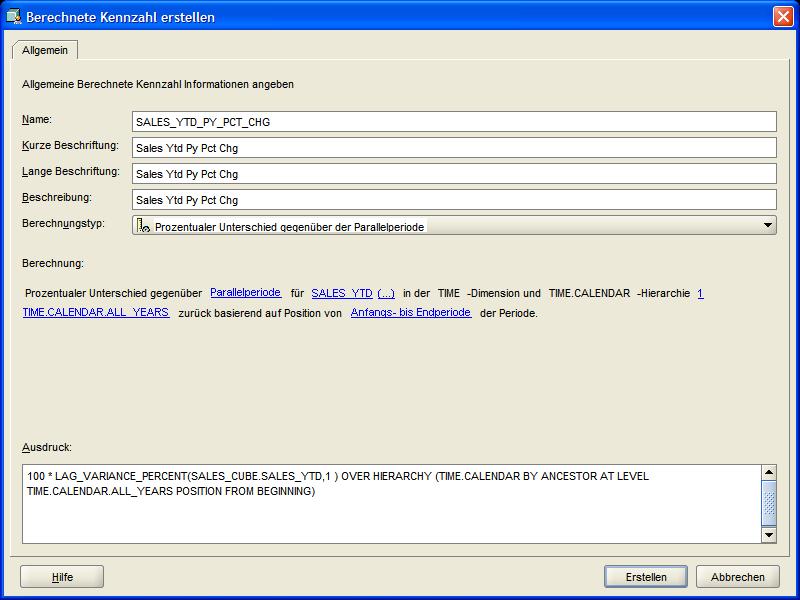
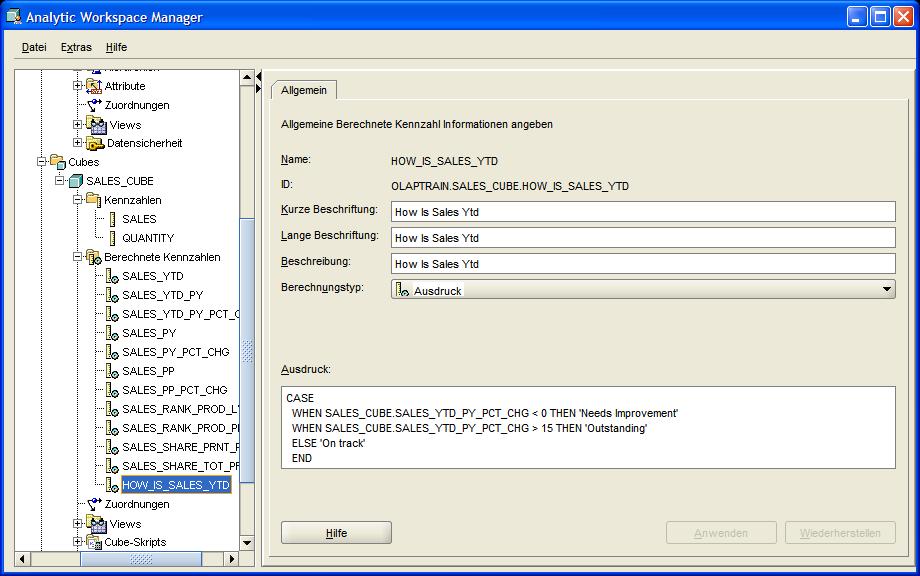
Das letzte Beispiel einer berechneten Kennzahl (SALES_YTD_PY_PCT_CHG) zeigt die Berechnung der prozentualen Entwicklung im Vergleich zum Vorjahr. Hier ist
wichtig, dass die zugrundeliegenden Formeln im Bereich "Ausdruck" des Erstellungsfensters manuell modifiziert werden können. Hier ist der Faktor 100 dazu
vorgesehen, dass die Prozentwerte in Zahlen < 0 vorliegen.
 |
| Für eine größere Ansicht auf das Bild klicken |
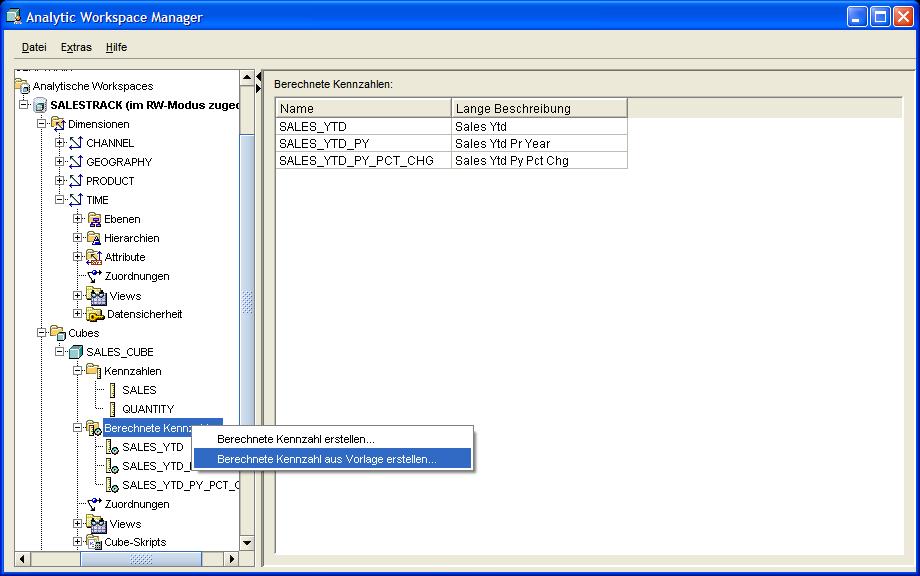
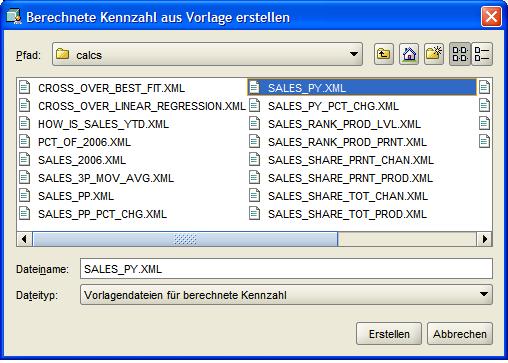
Die restlichen Kennzahlen werden wie bereits bei den Dimensionen vorgestellt, über Templates angelegt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
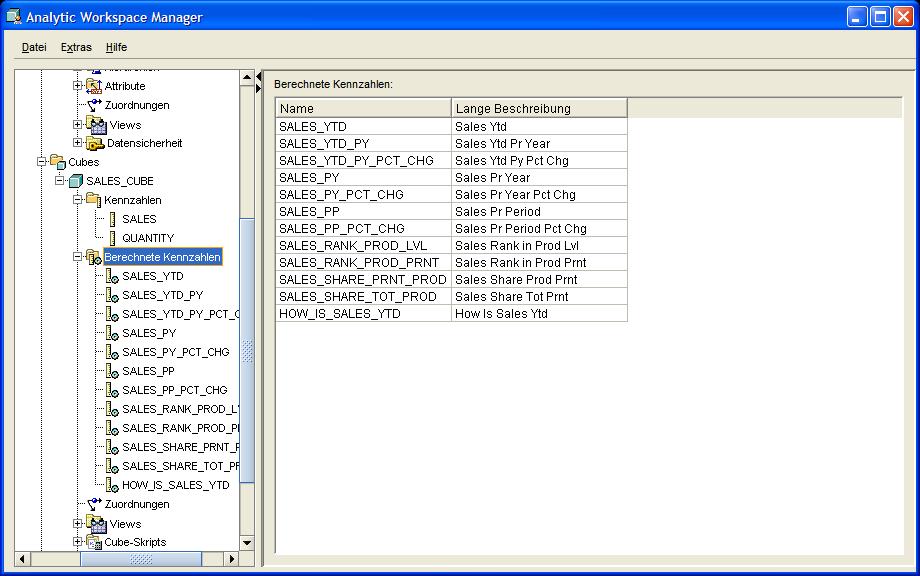
In der Übersicht kann man nun alle 12 angelegten Kennzahlen des OLAP Cubes erkennen. Die letzte berechnete Kennzahl HOW_IS_SALES zeigt eine Kennzahl,
der ein Ausdruck als
Berechnungsvorschrift, in diesem Fall also eine Fallunterscheidung mittels CASE, zugrunde liegt. Sie simuliert eine Art Ampel, die die Entwicklung der
Verkäufe bewertet:
| Für eine größere Ansicht auf das betreffende Bild klicken |
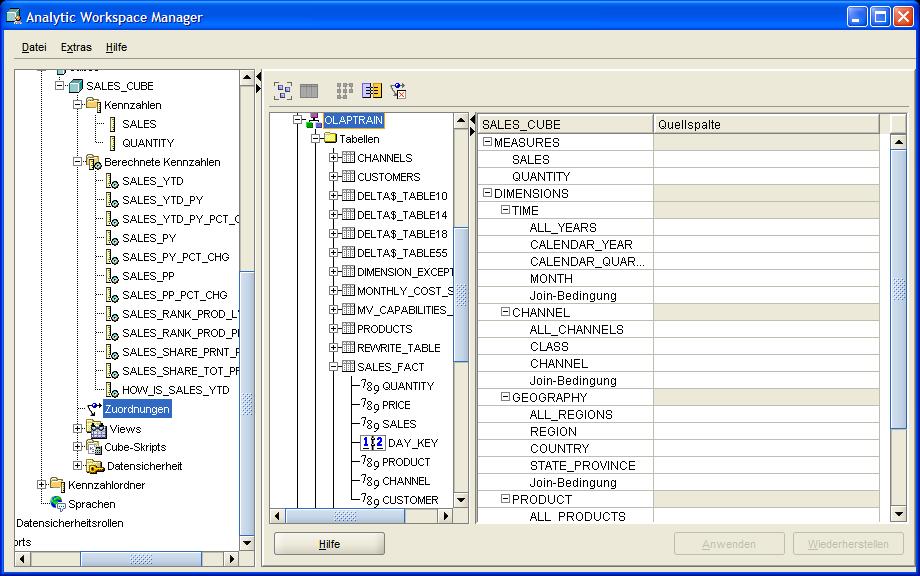
Zuordnung (Mapping) des Cubes zu relationalen Tabellen
Nachdem nun der OLAP Cube mit allen Basis-Kennzahlen und berechneten Kennzahlen in seiner Struktur angelegt worden ist, müssen jetzt die Zuordnungen (Mappings) definiert werden. Hier wird also
festgelegt, aus welchen Quelldaten die Zellen des OLAP Cubes ihre Informationen beziehen. Dieses geschieht, wie bereits bei den Mappings für die Dimensionen, mittels drag-and-drop.
Durch Positionierung auf dem Knoten Zuordnungen (Mappings) im Navigationsbaum wird ein Fenster
 |
| Für eine größere Ansicht auf das Bild klicken |
geöffnet, in dem die noch fehlenden Quellspalten dem SALES_CUBE zugeordnet werden müssen:
- Basis-Kennzahlen, die im OLAP Cube gespeichert werden sollen
- Niedrigster Detaillierungsgrad jeder Dimensionshierarchie
- Join-Bedingung für die Verknüpfung des Foreign Key (FK) der Faktentabelle mit dem Primary Key (PK) der Dimensionstabelle.
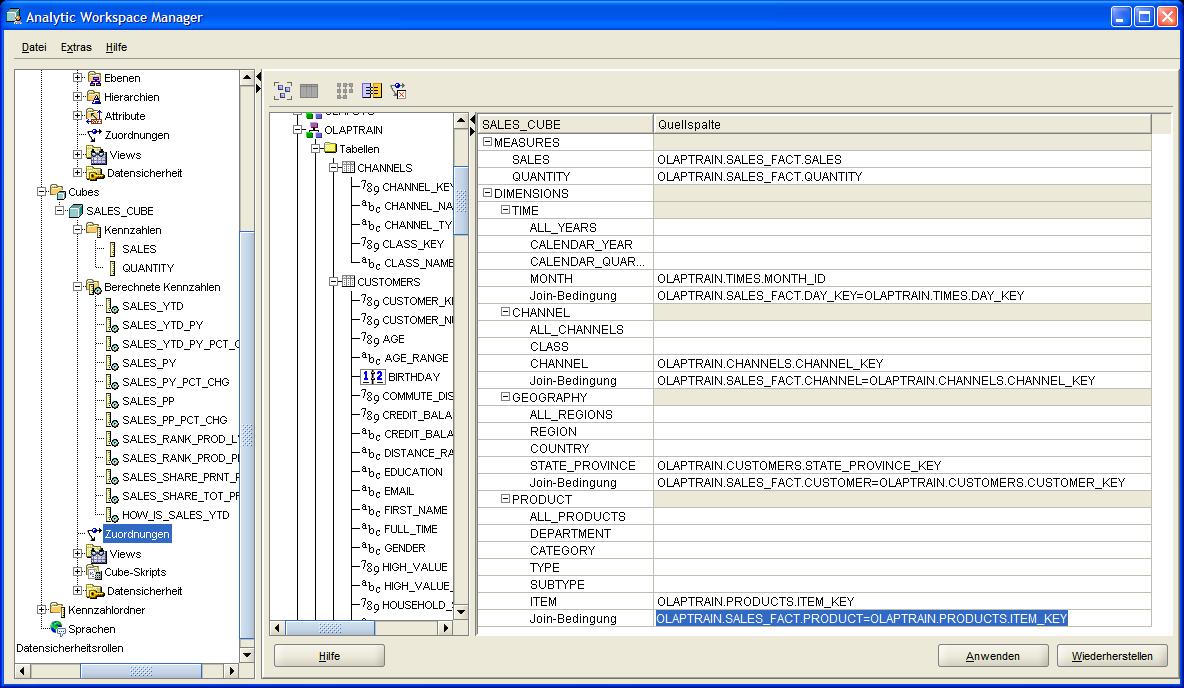
Aus dem Navigationsbaum der Schema-Übersicht werden nun einfach die gewünschten Spalten in die Quellspalte gezogen. Dieses geschieht in der Reihenfolge (a) FK der Faktentabelle und (b)
PK der Dimensionstabelle; das Gleichheitszeichen wird automatisch eingefügt. Am Ende entsteht dann folgendes Bild, in dem nur noch der Button Anwenden (Apply) gedrückt werden muss:
 |
| Für eine größere Ansicht auf das Bild klicken |
Einrichtung von Query Rewrite für die Cube-organized Materialized View
Die Oracle Datenbank 11g bietet die Möglichkeit, OLAP Cubes als cube-organized Materialized Views darzustellen. Auf diese Weise können u. U. mehrere relationale Materialized
Views in einer cube-organized Materialized View zusammengefaßt werden. Durch die Zusammenfassung wird einerseits Platz gespart, auf der anderen Seite wird die Verwaltung der Aggregationen
dadurch stark vereinfacht, dass eben nur eine Materialized View gewartet werden muss. Durch das Einrichten des Query Rewrite für den OLAP Cube werden automatisch alle MAV-Objekte
angelegt und innerhalb der Oracle Datenbank verwaltet. Bevor das Query Rewrite eingestellt werden kann, muss der vorige Schritt, also das Durchführen der Mappings, abgeschlossen worden sein.
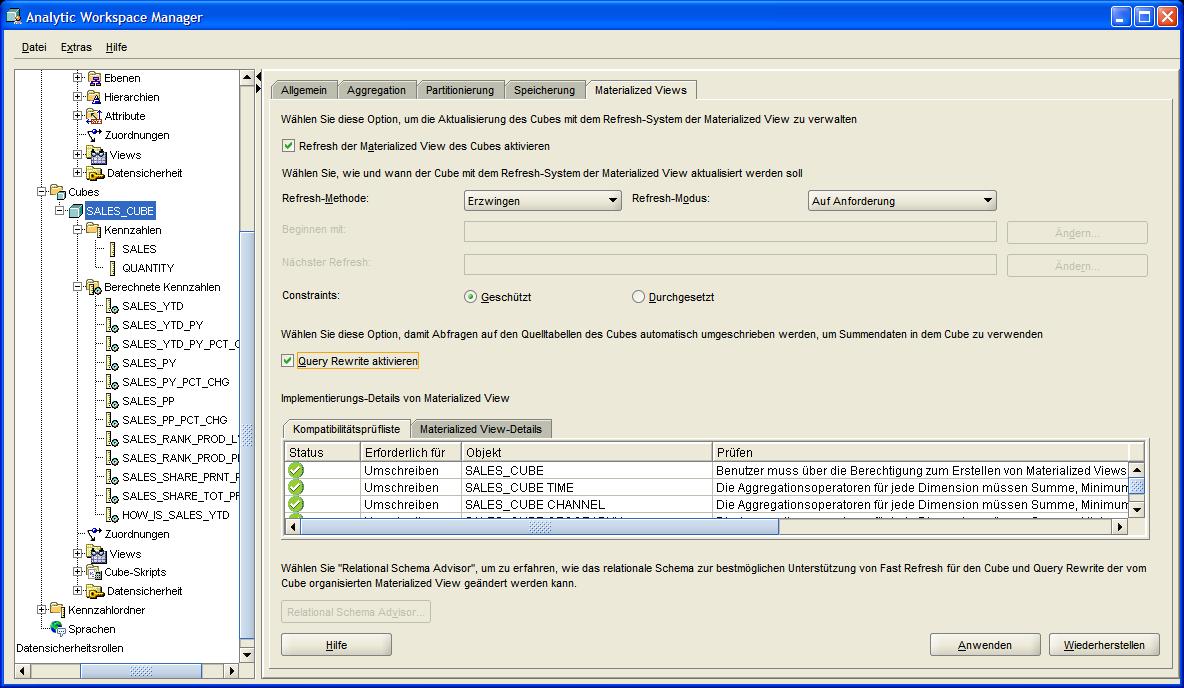
Durch Klicken auf den obersten Knoten (SALES_CUBE) im Navigationsbaum, öffnet sich im rechten Fensterteil das Optionsfenster für den OLAP Cube. Im letzten Reiter (Materialized Views)
werden nun die Einstellungen vorgenommen, und zwar durch Setzen der Checkboxes für "Refresh der Materialized View des Cubes aktivieren"
(Enable Materialized View Refresh of the Cube) und "Query Rewrite aktivieren" (Enable Query Rewrite).
Bei der Einstellung des MV Refresh muss noch festgelegt werden, wie (FAST, FORCE, COMPLETE) und zu welchem Zeitpunkt (ON COMMIT, ON DEMAND, START_WITH/NEXT) der Refresh der
Materialized View erfolgen soll. Diese Einstellungen und das entsprechende Verhalten sind jedoch bereits aus der Arbeit mit relationalen Materialized Views bekannt und können
eins zu eins auf die OLAP-Welt übertragen werden. Durch die Aktivierung des Query Rewrite für den gesamten OLAP Cube wird für die zugehörigen Dimensionen ebenfalls
automatisch das MV Refresh aktiviert.
Anschließend werden die Einstellungen durch Betätigen des Buttons Anwenden (Apply) in der Datenbank festgeschrieben:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Laden der Daten
Das Laden der Daten in den OLAP Cube schließt den gesamten Vorgang der Erstellung eines OLAP Cubes ab. Das Laden selber ist unter Umständen ein sehr zeitaufwändiger Prozeß, der - bei kleinen
Cubes - interaktiv und sofort gestartet werden kann, anderenfalls ist es angeraten, einen Scheduler-Job für den Ladevorgang zu starten, der dann sinnvollerweise in eine betriebsarme Zeit gelegt werden sollte.
Es können darüberhinaus alle im analytic Workspace befindlichen Objekte zugleich geladen werden oder alternativ auch nur bestimmte Dimensionen und Kennzahlen. Der Einfachheit halber
wird in diesem Beispiel der gesamte OLAP Cube auf einmal interaktiv mit Daten versorgt.
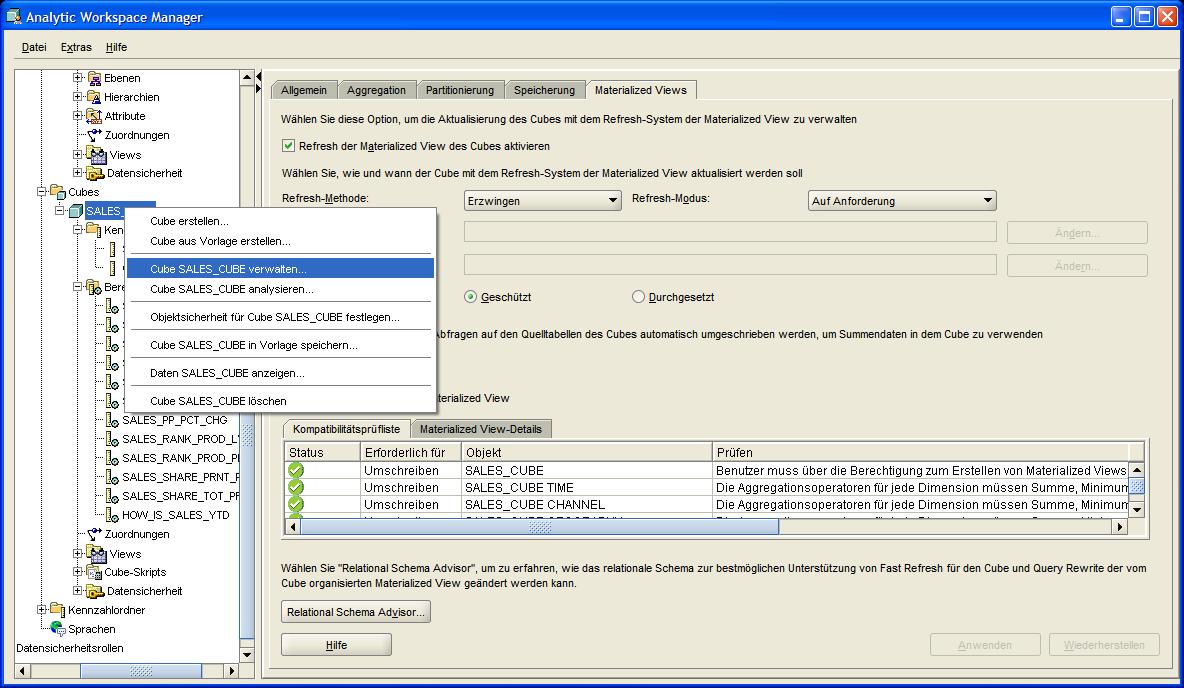
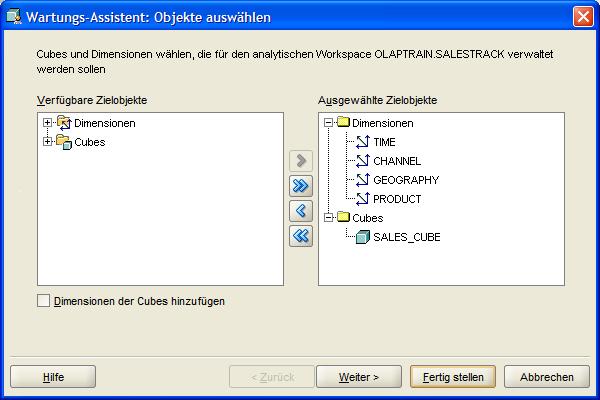
Durch einen Klick auf "Cube SALES_CUBE verwalten" (Maintain Cube SALES_CUBE) im Kontextmenü des Navigationsbaumes öffnet sich ein Wizard-Fenster, in dem die Auswahl der zu ladenden
Objekte durchgeführt werden kann. Wie bereits ausgeführt, wird an dieser Stelle einfach die Default-Einstellung übernommen und auf den Button "Fertig stellen" (Finsh) geklickt. Es erscheint
ein Fenster, das den Fortschritt der Operation anzeigt:
| Für eine größere Ansicht auf das betreffende Bild klicken |
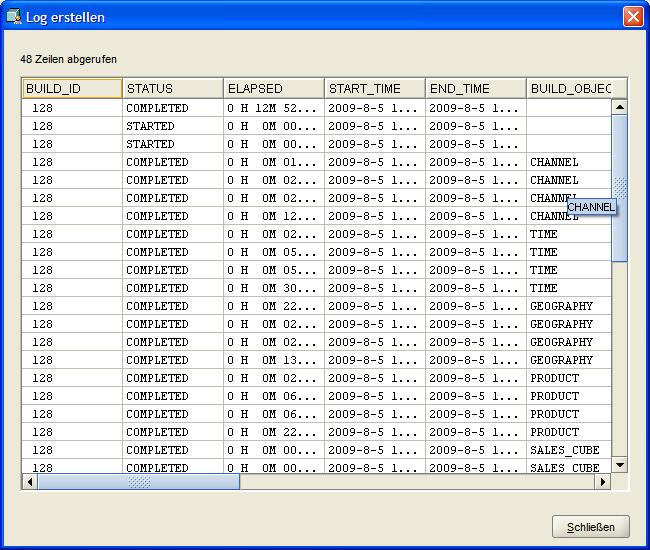
Am Ende erscheint schließlich ein Protokoll mit allen Meldungen, aus denen man entnehmen kann, das das Laden der Daten in diesem Fall fast 13 Minuten gedauert hat:
 |
| Für eine größere Ansicht auf das Bild klicken |
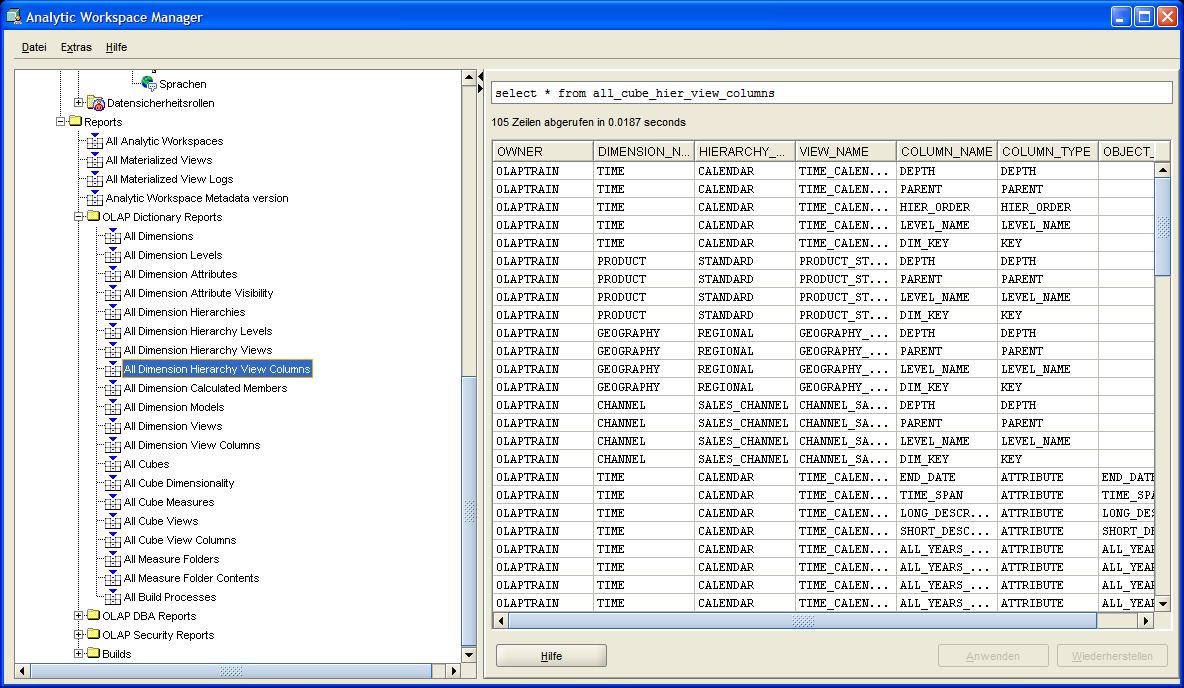
Im unteren Bereich des Navigationsbaumes finden sich zahlreiche vordefinierte Berichte, mit denen der Anwender sich einen Überblick über die in der Datenbank befindlichen
mehrdimensionalen Objekte verschaffen kann. Zum besseren Verständnis erscheint das ausgewählte SELECT-Statement in der obersten Zeile des Berichtes. In diesem Beispiel
werden alle Spalten aller Hierarchien angezeigt:
 |
| Für eine größere Ansicht auf das Bild klicken |
Einfache Berichterstellung mit dem Analytic Workspace Manager 11g
Im letzten Abschnitt dieses Tipps soll nun noch kurz dargestellt werden, wie einfach kleine Abfragen mit dem AWM 11g erstellt werden können. Das Fenster zur Erstellung der
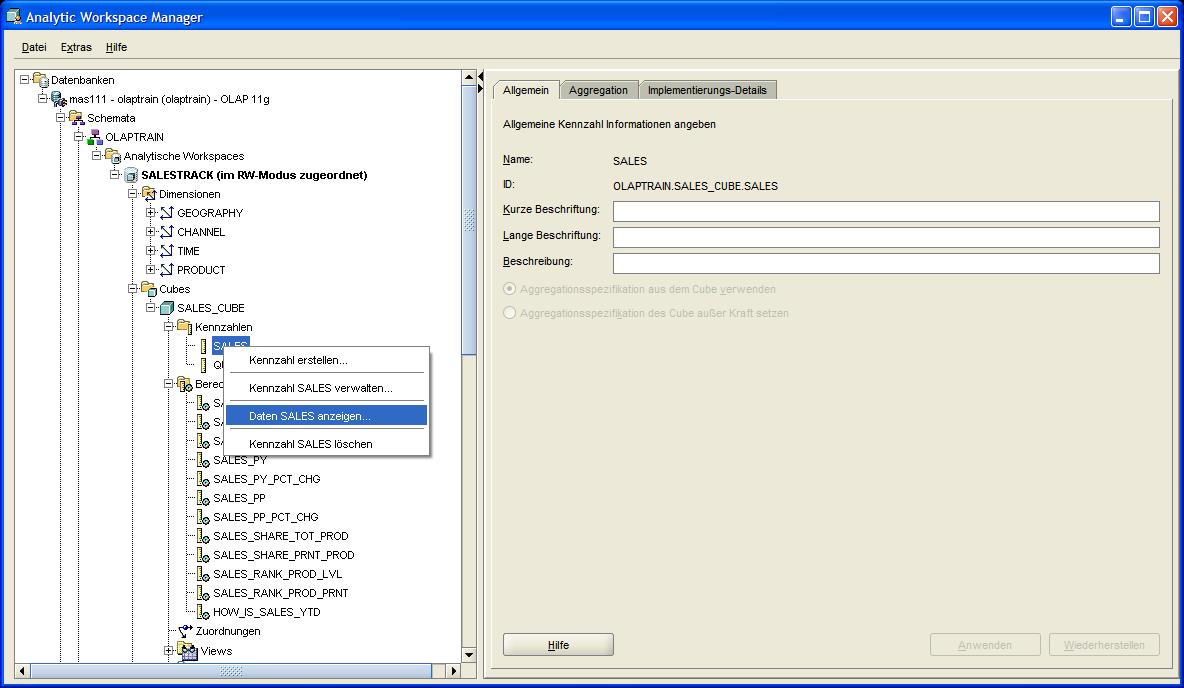
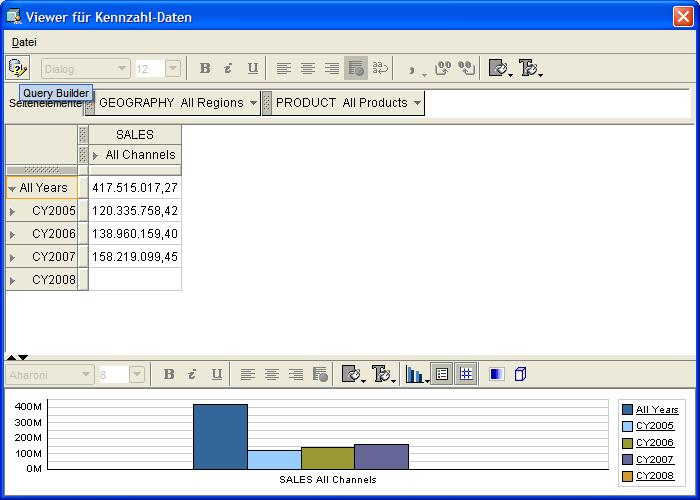
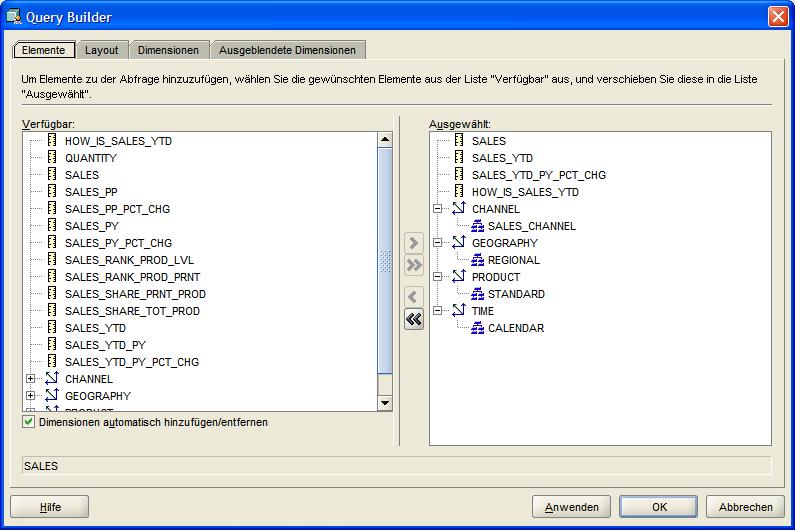
Abfrage erscheint über das Kontextmenü im Navigationsbaum, indem die Kennzahl SALES ausgewählt wird. Durch Klick auf "Daten SALES anzeigen" (View Data SALES) öffnet sich der Viewer
für Kennzahlen und zeigt eine Kreuztabelle an. Über das Starten des Query-Builders in der linken oberen Ecke des Fensters erscheint ein Dialogfenster, in dem der gewünschte Bericht
parametrisiert werden kann.
| Für eine größere Ansicht auf das betreffende Bild klicken |
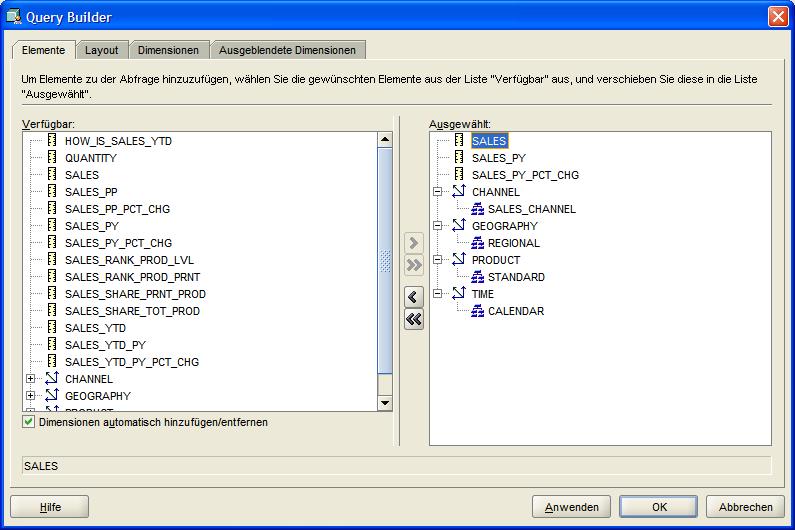
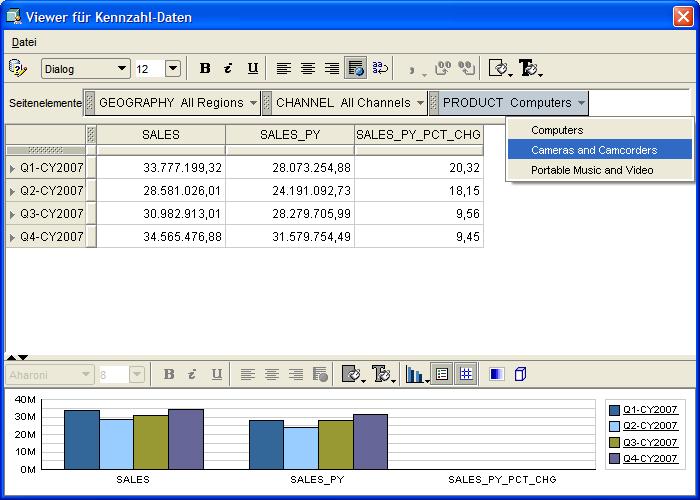
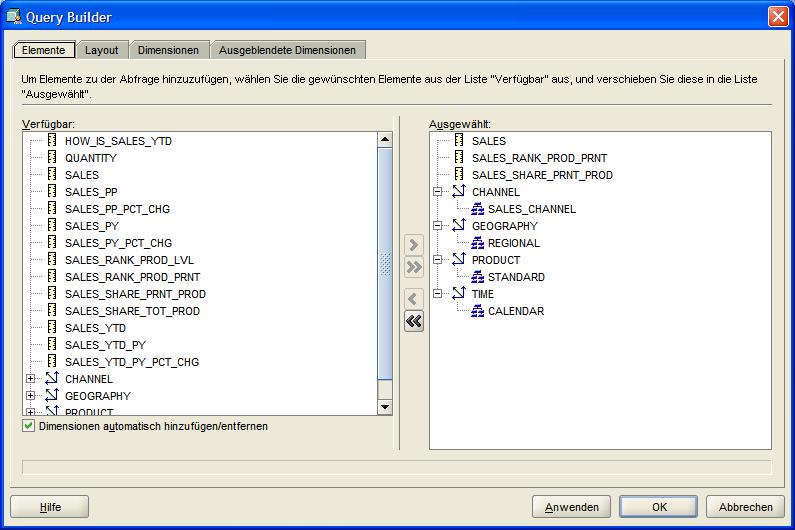
In diesem ersten Beipiel sollen die aktuellen Verkäufe mit dem Vorjahr verglichen wetrden. Zuerst müssen die gewünschten Kennzahlen SALES (aktuelle Verkäufe), SALES_PY (Vorjahresverkäufe)
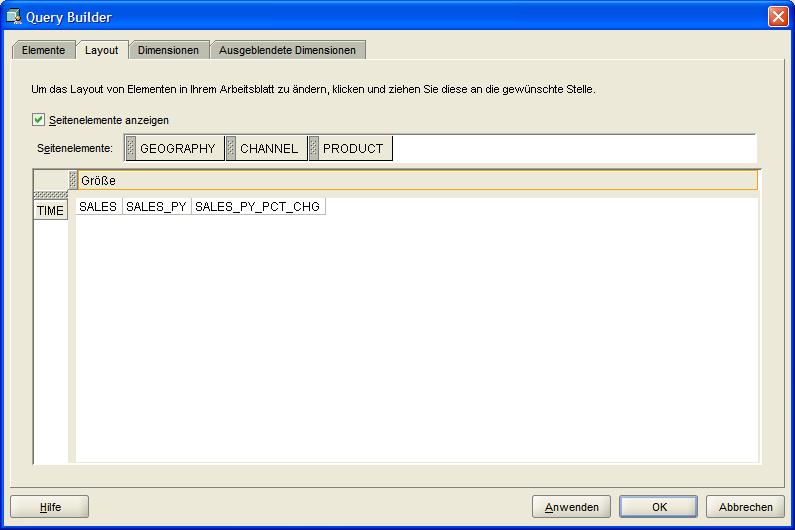
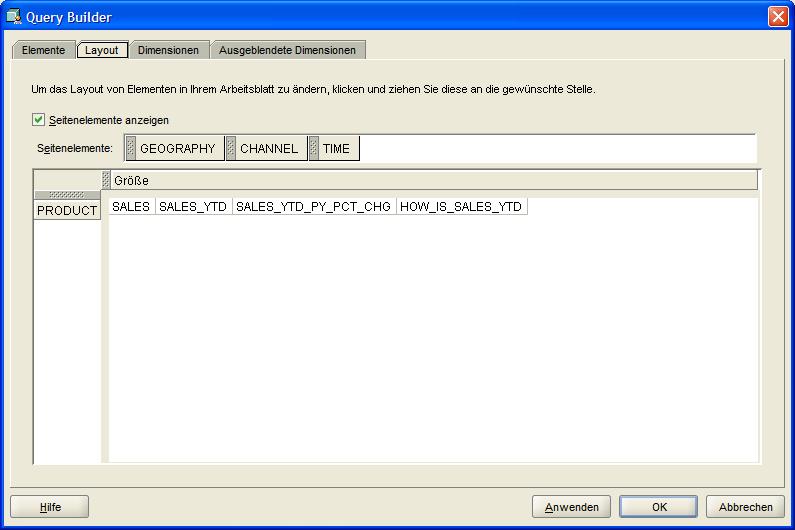
und SALES_PY_PCT_CHG (Veränderung Verkäufe zum Vorjahr) als Elemente (Items) ausgewählt werden. Im Reiter Layout wird der Tabellenaufbau so geändert, dass nur die Verkäufe selbst betrachtet werden.
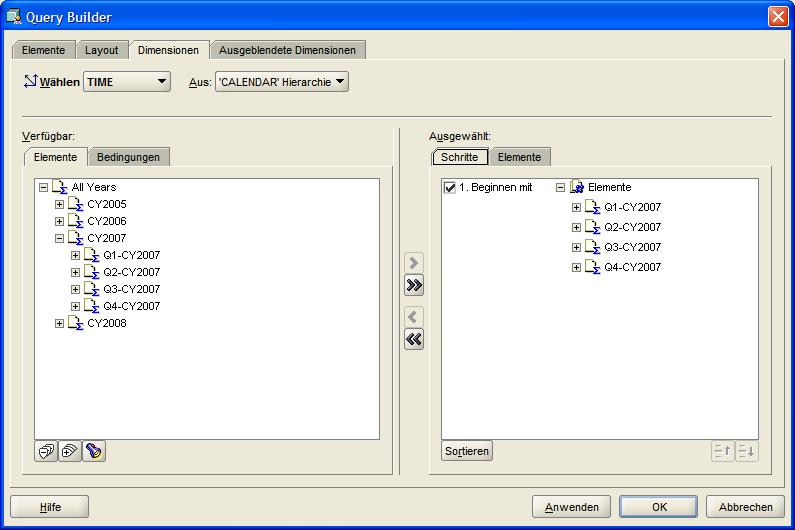
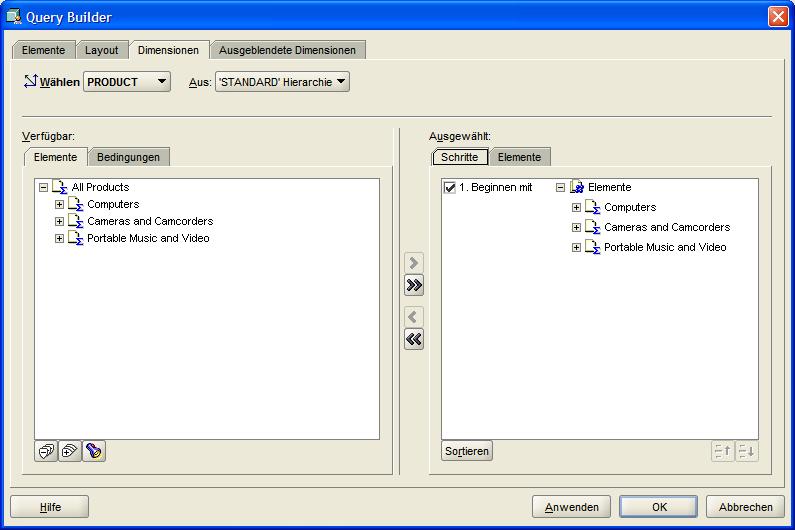
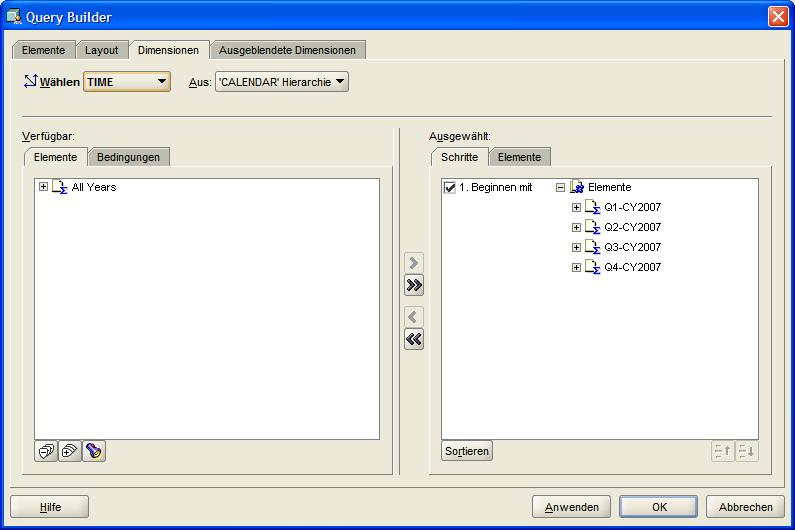
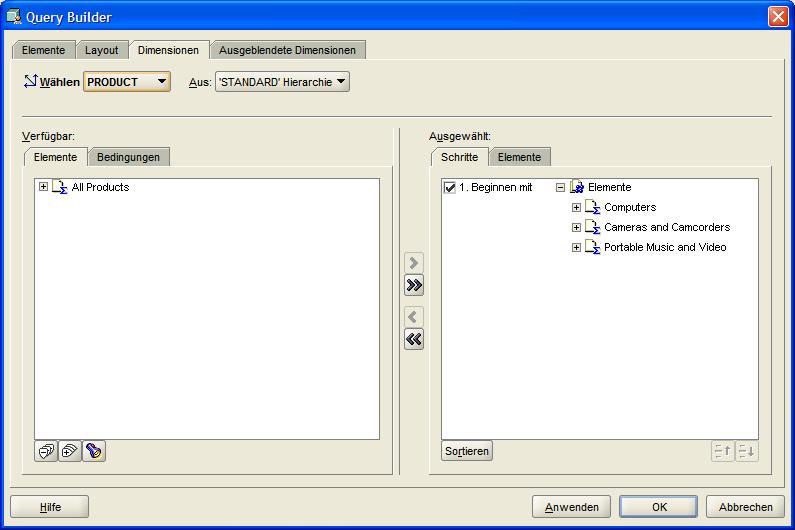
Im nächten Reiter Dimensionen (Dimensions) werden dann die zu betrachtenden Dimensionen bzw. Hierarchien ausgewählt. Dieses sind hier die Quartale des Jahres 2007 und die oberste
Produkthierarchie Abteilung (Computers, Cameras and Camcorders, Portable Music and Video). Nach Fertigstellung des Berichtes kann man in der Produktdimension eine drill-down-Analyse
durch die Hierarchien durchführen, deren Ergebnis immer sofort im Berichtsfenster angezeigt wird:
| Für eine größere Ansicht auf das betreffende Bild klicken |
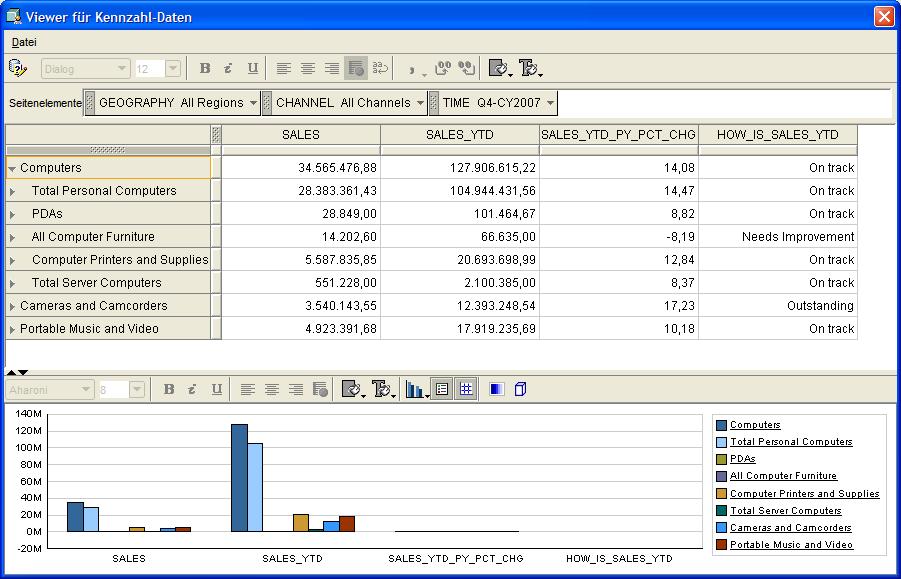
Im zweiten Beispiel wird ein Vergleich der aktuellen Verkäufe (SALES) und aufgelaufenen Verkäufe (SALES_YTD) mit prozentualer Veränderung zum Vorjahr (SALES_YTD_PY_PCT_CHG)
dargestellt. Die Entwicklung wird in einer Art Ampel (HOW_IS_SALES) textlich ausgewiesen. Betrachtet werden die drei obersten Produkthierarchien (Abteilung), in denen eine drill-down-Analyse
stattfinden soll:
| Für eine größere Ansicht auf das betreffende Bild klicken |
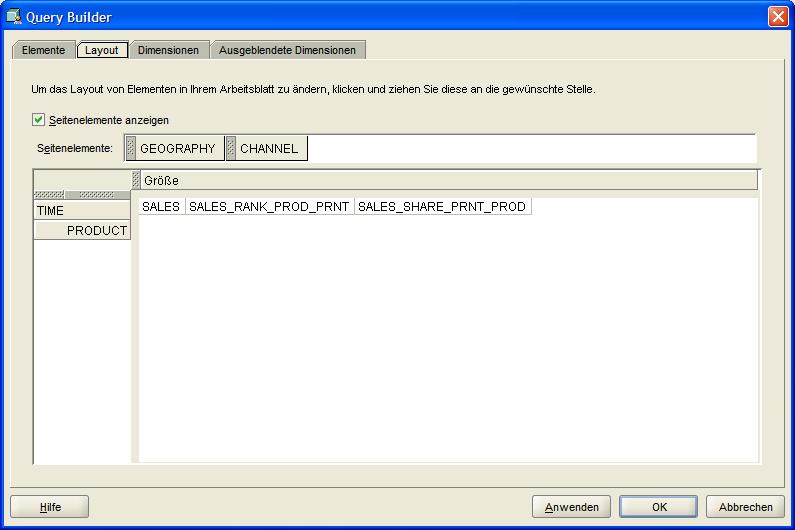
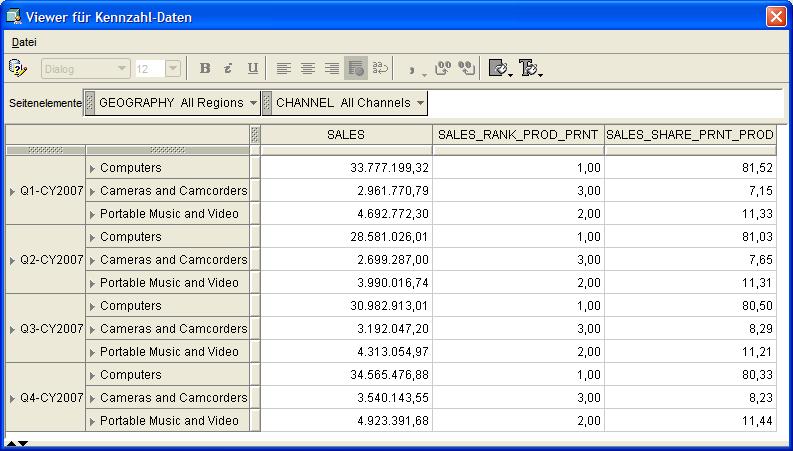
Das dritte und letzte Beispiel zeigt einen Bericht der drei oberen Produkthierarchien (Abteilung) inklusive Rangfolge und prozentualem Anteil am Gesamtverkauf für alle Quartale 2007. Nach dem Start
des Query Builders werden die gewünschten Kennzahlen (SALES, SALES_TANK_PROD_PRNT, SALES_SHARE_PRNT_PROD) ausgewählt, das Layout festgelegt und schließlich die auszuwertenden
Hierarchien selektiert. Das Ergebnis wird als Tabelle ausgegeben:
| Für eine größere Ansicht auf das betreffende Bild klicken |
Natürlich kann man das angezeigte Ergebnis auch über eine SQL-Abfrage erzeugen. Dieses ist jedoch - zumindest für einen Anwender ohne fundierte SQL-Kenntnisse - erheblich
aufwändiger, wie diese Ausgabe aus einer SQL*Developer Sitzung illustriert:
 |
| Für eine größere Ansicht auf das Bild klicken |
Die Erstellung eines OLAP Cubes mit Hilfe des Analytic Workspace Manager 11g ist nach Durcharbeiten dieses sehr ausführlichen Community-Tipps sicher kein Hexenwerk mehr!
Einige Bemerkungen noch zum Abschluß:
Wichtige Basis für die Arbeit mit mehrdimensionalen Daten ist, dass dem DBA ein sauber definiertes Star-Schema als Aufsetzpunkt zur Verfügung steht und auch das
Regelwerk für die Berechnung aussagekräftiger Kennzahlen bekannt ist. Ein graphisches Werkzeug wie der AWM 11g bietet dann alle Hilfsmittel, die der DBA zum Einstieg in
die OLAP-Welt benötigt. Auswertungen der OLAP-Daten können
- für Anwender und DBAs mit entsprechender Berechtigungsstufe mit dem Viewer innerhalb des AWM 11g
- für kundige DBAs auf SQL-Ebene mit z. B. dem SQL*Developer
- für Analysten sogar mit Zugriff auf die Oracle OLAP-Daten aus MS Excel heraus
erfolgen.
Im einem weiteren Community-Tipp, der demnächst zu diesem Themenkreis erscheinen wird, können Sie lesen, wie man einen OLAP Cube mit SQL-Bordmitteln abfragt und
wie sich Query Rewrite bei Abfragen auf eine Cube-organized Materialized View auswirkt.
Zurück zur Community-Seite
|