|
Performantes DML: Hints, paralleles DML und DBMS_EXECUTE_PARALLEL
von Ulrike Schwinn, ORACLE Deutschland GmbH
Effizientes und schnelles Einfügen oder Verändern von Daten ist mittlerweile eine unverzichtbares Ziel von Datenbankanwendungen.
Die entsprechende Performance kann beispielsweise durch zusätzliche Parallelisierung, Reduzierung von Table Scans oder durch Umgehung des
Buffer Caches mit Direct Writes gewonnen werden. Im folgenden Beitrag werden einige interessante Aspekte zum Thema DML-Operationen erläutert,
neue Features in 11g Release 2 aufgezeigt und speziell das Thema Umgang mit Parallel DML erläutert.
DML Operationen: einige Aspekte
Ob DML Operationen effizient durchgeführt werden, kann von einigen Faktoren abhängen. So hat der Umgang mit
den zur Verfügung stehenden Ressourcen wichtige Auswirkungen. Folgende Faktoren können dabei eine Rolle spielen:
Database Buffer Cache Nutzung, Parallelisierung von Operationen und Prozessen, Anzahl von Tabellenscans, die Menge an
erzeugten Redo-Informationen wie auch der Einsatz von COMMIT Operationen.
Ein Blick in das Oracle SQL Language Reference Handbuch gibt einen ersten Eindruck über die Vielfalt der Möglichkeiten,
DML- Statements abzusetzen. Sollen Daten über SQL geladen werden und ist man an keinen SQL Standard (z.B. SQL:2008)
gebunden, lohnt sich auf jeden Fall der Einsatz von entsprechenden Erweiterungen. Mehr Performance, höhere Effizienz
oder größere Funktionalität können dann das Ergebnis sein.
Kenntnisse über folgende Syntax und Techniken sind auf jeden Fall hilfreich.
- Multi Table INSERT
- Direktes (DIRECT LOAD) oder konventionelles Ladeverfahren
- DML Error Logging
- Bulk Load bei PL/SQL Nutzung
- Einsatz von asynchronem COMMIT
- Parallelisierung
Neue Hints mit 11g Release 2
Mit 11g Release 2 gibt es einige neue Hints und Packages, die auch im Bereich DML-Operationen Wirkung zeigen.
So kann beispielsweise der neue semantische Hint IGNORE_ROW_ON_DUPKEY_INDEX einen
UNIQUE KEY Verstoß ignorieren. Damit treten gewisse Fehlermeldungen (z.B. ORA-00001: unique constraint...) nicht mehr
auf und müssen nicht mehr abgefangen werden. Dies kann ein ERROR LOGGING überflüssig machen oder aufwändige PL/SQL Exception
Handling-Programmierungen einsparen. Alle Syntax-Optionen und Einschränkungen können im Oracle SQL Language Reference Handbuch
nachgeschlagen werden. Folgendes einfache Beispiel zeigt eine Anwendung.
Auch im Bereich Direct-Path INSERT Funktionalität gibt es Erweiterungen, die beispielsweise bei Einfügeoperationen in
PL/SQL-Umgebungen zum Einsatz kommen können. Direct-Path INSERT ist jetzt auch mit seriellen INSERT Statements mit VALUES-Klausel möglich. Notwendig ist dabei der
Einsatz des neuen Hints APPEND_VALUES. Folgendes Beispiel zeigt die Nutzung bei einem Massen-Ladevorgang.
Parallelisierung von DML-Operationen: einige Grundlagen
Beim Einsatz von Parallel DML stellen sich häufig folgende Fragen: Wie schaltet man parallel DML ein? Ist eine
Partitionierung der Tabelle notwendig? Wann soll man überhaupt parallel DML einsetzen? Wie kann ich den gesamten Prozessablauf
parallelisieren? Die folgenden Abschnitte geben Antwort auf diese Fragen.
DML Operationen wie INSERT ... SELECT, UPDATE, MERGE und DELETE können über folgende Massnahmen parallelisiert werden:
- Einschalten der Parallelisierung mit ALTER SESSION FORCE PARALLEL DML und
- Anzeigen der Parallelisierung - durch den PARALLEL Hint oder durch die Tabelleneigenschaft PARALLEL.
Folgender Ausschnitt zeigt eine Anwendung.
Wie zu erkennen ist, ist keine Partitionierung des Segments notwendig, um Parallelisierung zu erreichen. Möchte man die parallele Verarbeitung
monitoren, stehen die Views V$PQ_SESSTAT oder der Performance- bzw SQL Monitoring Bereich im 11g Enterprise Manager Konsole zur Verfügung.
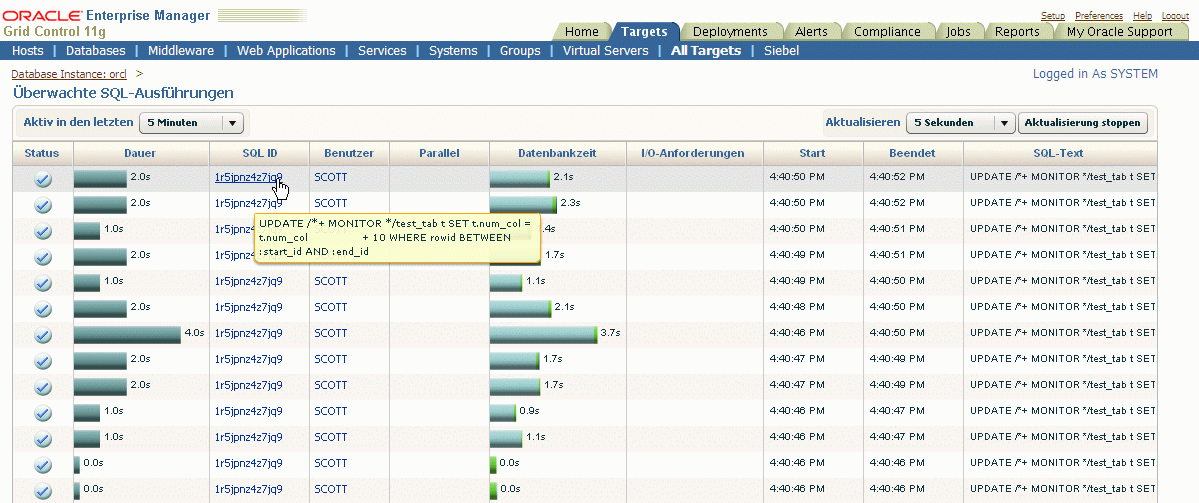
Folgender Screenshot zeigt die Ausführung im SQL Monitoring-Bereich an.

Für eine größere Ansicht auf das Bild klicken
Wann setzt man Parallel DML ein? Parallel DML kann beispielsweise Batch Jobs auf große Tabellen enorm beschleunigen. So können große Menge
an Daten mit einer UPDATE-Operation angepasst werden, monatliche Datenrefreshs mit einer MERGE-Operation durchgeführt werden
oder beispielsweise historische Tabellen mit DELETE und INSERT SELECT angepasst werden.
Folgende Regeln bzw. Konsquenzen bringt der Einsatz von Parallel DML mit sich:
- Keine weiteren seriellen oder parallelen Operationen können in der gleichen Transaktion auf der Tabelle durchgeführt werden. Die Transaktion muss
vorher abgeschlossen werden.
- Einschränkungen: Keine Unterstützung von Integritätsconstraints, von Triggern, Clustertabellen usw..
- INSERT VALUES Operationen können nicht parallelisiert werden.
- Parallele Operationen auf Tabellen mit LOBs können nur auf partitionierten Tabellen erfolgen.
Wird gegen die Einschränkungen (in Bullet 2) verstossen, wird automatisch ohne Fehlermeldung in den konventionellen Modus umgeschaltet.
Detaillierte Informationen zu den Einschränkungen finden sich im Handbuch Oracle Database VLDB and Partitioning Guide 11g Release 2 (11.2)
Bei parallelen INSERT Operationen werden dabei sogenannte DIRECT Write Ladeverfahren durchgeführt. Diese haben folgende
Eigenschaften:
- Das Ausschalten der Redo Generierung wird möglich: Dazu muss die Tabelle mit der Eigenschaft NOLOGGING erzeugt werden.
- Daten können komprimiert eingefügt werden: Hierfür muss die Tabelle mit der Eigenschaft COMPRESS BASIC erzeugt werden.
- Der Platzbedarf erhöht sich.
Möchte man die Einschränkungen und Konsequenzen, die Parallel DML mit sich bringt, nicht in Kauf nehmen, müssen Alternativen überlegt werden.
Eine Alternative dazu ist, die manuelle Aufteilung der Tabelle in mehrere "Chunks" - zum Beispiel über feste ROWID-Bereiche - und eine anschliessende Verarbeitung in parallelen Sessions durchzuführen.
Neues zur Prozess-Parallelisierung mit 11g Release 2
In 11g Release 2 gibt es eine weitere Alternative mit dem neuen Package DBMS_PARALLEL_EXECUTE. Die Idee dahinter ist,
dass ein spezieller Scheduler-Prozess die Tabelle automatisch in Teilbereiche aufteilt,
parallel abarbeitet und eine COMMIT-Operation nach jedem abgearbeiteten Teilbereich durchführt. Auf diese Weise wird die oben
beschriebene Alternative - das manuelle Vorgehen - überflüssig.
Folgende drei Aufrufe sind dafür notwendig:
- Das Anlegen einer Aufgabe (auch Task) mit CREATE_TASK.
- Die Aufteilung der Tabelle in Teilbereiche (auch Chunks) durch eine definierte Methode. Zur Verfügung steht die ROWID-, die Spaltenwert- oder die SELECT- Methode.
- Der Ablauf des Statements mit RUN_TASK in den definierten Chunk-Bereichen.
Um im Fehlerfall die Operation automatisch wieder anzustarten, steht die Prozedur RESUME_TASK zur Verfügung,
die zusätzlich verwendet werden kann.
Folgendes Beispiel zeigt eine einfache Anwendung eines parallelisierten UPDATE- Statements. Die Tabelle besteht aus 500 000 Zeilen und soll mit einem Parallelisierungsgrad von 10 bearbeitet werden. Die definierten Chunks haben dabei jeweils die Größe von 10 000 Zeilen.
Während der Ausführung kann man beobachten, dass zusätzliche Job-Prozesse mit Namen "ora_j00x_orcl" angestartet werden. Detailliert überwachen lässt sich der Ablauf der Verarbeitung mit neuen Data Dictionary Views.
Mit der View DBA_PARALLEL_EXECUTE_CHUNKS lässt sich zum Beispiel der aktuelle Stand der Ausführung wie folgt überprüfen.
Wie man leicht erkennen kann, werden die ROWID-Teilbereiche von den einzelnen Job-Prozessen abgearbeitet und befinden sich jeweils in einem unterschiedlichen Prozess-Status. Durch die Verwendung des Hints MONITOR
lässt sich zusätzlich die Abarbeitung im Enterprise Manager im Bereich "SQL Monitoring" überwachen.
Folgender Screenshot zeigt die Ausführung.

Für eine größere Ansicht auf das Bild klicken
Die Vorteile der Nutzung sind offensichtlich. Durch die parallele Abarbeitung der Scheduler Job-Slaves kann eine schnelle Durchführung
gewährleistet werden. Außerdem wird durch die zusätzliche Möglichkeit, den Status der Abarbeitung abzufragen und einen Wiederanlauf
im Fehlerfall zu starten, eine erfolgreiche Abarbeitung sichergestellt. Möchte man eine parallele und skalierbare DML-Verarbeitung von
großen Tabellen ohne die Restriktionen von Parallel DML durchführen, stellt die Verwendung von DBMS_PARALLEL_EXECUTE somit eine gute
Alternative dar.
Mehr zu weiteren Themen rund um die Oracle Datenbank demnächst.
Zurück zur Community-Seite
|