|
Parallel Query ganz automatisch mit Oracle 11g
von Frank Schneede, ORACLE Deutschland GmbH
Datenbanken enthalten heutzutage eine riesige Menge an Daten, unabhängig davon, ob es sich um OLTP Systeme, Datawarehouses oder Operational Data Stores handelt. Die performante Ausführung von
SQL-Abfragen kann daher durchaus eine Herausforderung darstellen, denn die Antwortzeit hängt in einem solchen Fall wesentlich von der Menge der abgefragten Daten ab. Ein gutes Mittel,
Abfragen auf großen Datenmengen performant abzuarbeiten, ist die Nutzung von Parallel Query, die es bereits seit der Oracle Version 7.3 in der Enterprise Edition gibt. Die Grundidee
von Parallel Query ist es, mehrere Unterprozesse zu starten, die jeder für sich eine Teilmenge der Daten bearbeiten und das Zwischenresultat dann zur Ermittlung des
Endergebnisses an den zentralen Benutzerprozess zurückmelden. Durch dieses Prinzip werden die zur Verfügung stehenden Rechnerressourcen besser ausgenutzt und eine zum Teil
erhebliche Verbesserung der SQL Antwortzeiten bei Abfragen großer Tabellen erreicht. Das Beispiel wird dies belegen.
Die parallele Ausführung von Abfragen war lange Zeit sehr restriktiv implementiert, so konnte parallel Query zuerst nur mit partitionierten
Tabellen verwendet werden, wobei der Parallelitätsgrad (DoP = Degree of Parallelism) mit der Anzahl der Partitionen und den zur Verfügung stehenden Prozessoren korrespondieren musste.
Diese Einschränkungen haben glücklicherweise für die aktuell im Einsatz befindlichen Releases keine Relevanz mehr, eine parallele Ausführung ist auch bei nicht partitionierten
Objekten völlig unproblematisch.
Bis zur Version Oracle 11g musste der DBA allerdings noch für alle in einer Abfrage verwendeten Tabellen und die dazugehörenden Indizes den DoP manuell ermitteln, einstellen und pflegen.
Nur auf diese Weise war es überhaupt möglich, gleichbleibend gute Antwortzeiten zu erzielen. Man kann sich leicht vorstellen, dass es nicht immer ganz einfach war, den
Parallelitätsgrad zu ermitteln, der für die bestmögliche Antwortzeit sorgte. Der optimale DoP hängt nämlich von vielen Faktoren ab, neben der reinen Datenmenge
sind unter anderem auch die zur Verfügung stehenden CPU-Ressourcen (Prozessoren oder Kerne) oder die Art der Benutzerlast entscheidend.
In der aktuellen Datenbankversion Oracle 11g hat es rund um das Thema Parallel Query Verbesserungen gegeben, die den DBA mit sehr mächtigen Automatismen unterstützen. Dieser Artikel
führt kurz in das Thema Parallel Query ein, zeigt die Möglichkeiten in Oracle 11g Release 2 und gibt Hinweise darauf, wie die parallele Ausführung überwacht und
gesteuert werden kann:
- Einführung Funktionsweise Parallel Query
- Das Parallel Query Handwerkzeug für den DBA
- Parallel Query Überwachung
- Fazit
Einführung Funktionsweise Parallel Query
In den folgenden Beispielen wird das Schema SH verwendet, mit dessen Hilfe die gezeigten Statements leicht auf jeder Oracle Datenbank nachvollzogen werden können. Dieser erste Abschnitt
soll dazu dienen, das Konzept und die Vorteile der parallelen Abarbeitung zu verstehen und Ausführungspläne lesen zu können. Im folgenden ersten Statement ist ein Join der
Tabellen CUSTOMERS und SALES zu sehen, das Informationen über getätigte Verkäufe anzeigt.
Ohne weitere Einstellungen an den Objekten vorzunehmen, erfolgt also eine serielle Abarbeitung des Statements. Sobald zum Beipiel in Oracle 11g durch den Befehl
ALTER SYSTEM SET PARALLEL_DEGREE_POLICY=AUTO auf parallele Abarbeitung umgestellt wird, versucht die
Oracle Datenbank, soviel Arbeitsschritte wie möglich parallel auszuführen. In dem folgenden Ausführungsplan kann man die Vorteile zur seriellen Ausführung gut erkennen.
Insbesondere in den Spalten Cost (%CPU) und Time des Ausführungsplans sieht man die zu erwartende Verbesserung (1:38 zu 0:34) in der Abfrageperformance.
Der Ausführungsplan unterscheidet sich in erster Linie durch zusätzliche Schritte, die die Arbeit der verschiedenen parallelen Prozesse koordinieren und die einzelnen Zwischenergebnisse
zusammenführen.
Um einen parallelen Ausführungsplan und die sich dahinter verbergenden Prinzipien zu verstehen und letztlich auch steuern zu können, möchte ich an dieser Stelle einige
Erklärungen zur parallelen Ausführung geben. Prinzipiell basiert die parallele Ausführung eines SQL Statements auf zwei verschiedenen Komponenten, dem Query Coordinator
(abgekürzt QC, grün dargestellt) und den Parallel Execution (abgekürzt PX, blau dargestellt) Serverprozessen. Der Query Coordinator ist im obigen Beispiel im Schritt Id 1 leicht auszumachen. Er heißt PX COORDINATOR
und dient dazu, die Einzelergebnisse der unabhängig arbeitenden PX Server Prozesse zusammenzuführen. In komplexeren SQL Statements kann der QC Prozess auch Arbeiten übernehmen,
die nicht parallel ausgeführt werden können, zum Beispiel bei einer Abfrage eines Aggregates SUM() die Summation aller Zwischenergebnisse.
Die PX Server Prozesse werden aus einem Pool verfügbarer Prozesse bedient. Die Anzahl der möglichen PX Server Prozesse wird durch den init.ora Parameter PARALLEL_MAX_SERVERS limitiert, der Standardwert
wird aus anderen init.ora Parametern (CPU_COUNT, PARALLEL_THREADS_PER_CPU, PGA_AGGREGATE_TARGET) abgeleitet. Die PX Server Prozesse sind auf Betriebssystemebene mit dem Befehl ps zu sehen:
Anhand des nächsten Beipiels möchte ich das Producer/Consumer Modell erläutern und gleichzeitig auf ein Problem aufmerksam machen, das sich ergibt, wenn nicht alle von
einer SQL Abfrage verwendeten Objekte auf parallele Abarbeitung eingerichtet sind. In der Abfrage werden die Umsätze je Bundesstaat der USA ermittelt. Um diese Informationen berechnen
zu können, wird der JOIN um die Tabelle COUNTRIES erweitert, die jedoch nicht parallelisiert ist.
Die Prozesse dieses Beispiels sind drei Komponenten zuzuordnen. Die erste Komponente ist wieder der Query Coordinator (QC, grün dargestellt). Die anderen PX Server Prozesse
sind Consumer (rot dargestellt) und Producer (blau dargestellt). Die Bearbeitung fängt mit der Verarbeitung der Tabelle CUSTOMERS
(seriell!) an, hierbei muss von serieller auf parallele Arbeitsweise umgestellt werden (S->P in Spalte IN-OUT des Ausführungsplanes). Eine solche Umstellung sollte grundsätzlich
vermieden werden, da bei größeren Tabellen mit Performanceeinbußen durch die Umstellung seriell/parallel gerechnet werden muss!
Das Ergebnis der Producer für die Tabellen COUNTRIES (Id 14) und CUSTOMERS (Id 16) wird durch den Consumer (Id 13) in einem Hash-Join (Id 11) verarbeitet und durch den Producer (Id 10) an
den nächsten Consumer (Id 9) weitergereicht, der das Ergebnis des Joins mit der Tabelle SALES (Producer, Id 18) wiederum über einen Hash-Join verknüpft, filtert (Id 7) und gruppiert
(Id 6). Am Ende der Verarbeitung werden die Zwischenergebnisse weitergereicht (Producer Id 5) und durch den obersten Consumer (Id 4) zusammengefasst. Dieses Ergebnis schließlich wird
durch den Query Coordinator (Id 1) an den Benutzerprozess zurückgegeben.
Aus der Art des Zusammenspiels Producer/Consumer ergibt sich die Konsequenz, dass immer eine Kombination paralleler Prozesse (Producer/Consumer) vorhanden sein muss. Eine parallele JOIN Operation
zweier Tabellen mit Parallelitätsgrad 4 bräuchte demnach die zweifache Anzahl des Parallelitätsgrades als PX Server Prozesse, also insgesamt 8 PX Server Prozesse, 4 Producer und 4 Consumer.
Die Daten, die ein PX Server Prozess bearbeitet, werden als Granules bezeichnet. Die Festlegung, wie die Granules gebildet werden, hängt vom SQL Statement und dem eingestellten DoP ab und wird
ausschließlich durch die Datenbank selbst festgelegt.
Ein weiterer Punkt, der zu dem oben gezeigten Ausführungsplan anzumerken ist, betrifft die Daten-Umverteilung (Spalte PQ Redistrib im Ausführungsplan). Diese Umverteilung ist nötig,
um für die unabhängig voneinander arbeitenden PX Server Prozesse sicherzustellen, dass jeder PX Prozess die für die Ausführung einer Join-Operation notwendigen
Schlüsselattribute erhält. Dieses geschieht in dem oben gezeigten Beispiel auf zweierlei Weise:
- BROADCAST - dieses Verfahren wird angewendet, wenn die Ergebnismengen einer Join-Operation unterschiedlich groß sind. Die kleinere von beiden wird hierbei als Ganzes an alle anderen
PX Server Prozesse geschickt.
- HASH - mit diesem Verfahren wird eine mengenmäßige Gleichverteilung der Ergebnismengen einer Join-Operation erreicht.
Nachdem nun die grundsätzliche Arbeitsweise von Parallel Query beschrieben worden ist, sollen im folgenden Abschnitt die Möglichkeiten vorgestellt werden, mit denen der DBA
die Parallel Query Funktionalität beeinflussen kann.
Das Parallel Query Handwerkzeug für den DBA
Der DBA muss eine ganze Menge an Randbedingungen beachten, um mit Parallel Query tatsächlich eine nachhaltig gute Systemperformance zu erzielen.
Dieses wird auch im Alltag deutlich, wenn gut eingerichtete Systeme im Laufe ihres Lebenszyklus an Performance zu wünschen übrig lassen. Um das zu vermeiden, sind in Oracle 11g
Automatismen eingeführt worden, die nach der initialen Einrichtung dafür sorgen, dass eine gute Systemperformance in Bezug auf Parallel Query auch langfristig erhalten bleibt.
Die Oracle Datenbank ist standardmäßig so eingerichtet, dass Parallel Query genutzt werden kann. Wenn der DBA nun die Steuerung der Parallelität selbst in der Hand
behalten möchte, anstelle auf datenbankinterne Automatismen zu vertrauen, so kann er das tun, in dem die Default-Parallelität für jedes gewünschte Objekt separat eingerichtet
wird. Das Ergebnis sieht man anschließend im Data Dictionary.
Innerhalb eines Statements kann der gewünschte Parallelitätsgrad auch für jede Tabelle separat in einem Hint angegeben werden. Dieses Vorgehen ist nur sinnvoll, wenn
man das System- bzw. Antwortzeitverhalten testen möchte. Eine grundsätzliche Festlegung des DoP zum Beispiel im Code eines Programms ist hingegen nicht sinnvoll, denn
dann müssten bei Änderungen Anpassungen im Programmcode erfolgen.
Soll innerhalb einer Sitzung Parallel Query genutzt werden, so kann das auch über die Änderung eines Session-Parameters geschehen.
Die bis hierher geschilderten Steuerungsmöglichkeiten sind auch bereits vor Oracle 11g nutzbar, erfordern nur eine stetige Überwachung und gegebenenfalls Anpassung
der Systemparameter. Zudem kann es bei einer ungünstigen Dimensionierung des Parallelitätsgrades dazu kommen, dass das System überlastet wird und somit genau das
Gegenteil dessen passiert, was der DBA bzw. Anwendungsentwickler beabsichtigt hat, nämlich ein massiver Performanceeinbruch. Um diesem möglichen Problem vorzubeugen,
wurden Parametrisierungsparameter eingeführt, mit deren Hilfe Grenzen für das Starten von parallelen Prozessen gesetzt werden können. Der Parameter
PARALLEL_MAX_SERVERS definiert diesen Grenzwert. Der Wert stellt sicher, dass nicht mehr PX Server Prozesse gestartet werden, als vom DBA gewünscht. Standardmäßig wird der Wert
von PARALLEL_MAX_SERVERS aus der Anzahl der CPUs, der Anzahl der Threads pro CPU (auf den meisten Systemen vom Betriebssystem her auf 2 festgelegt) und der Größe
der SGA berechnet, kann aber auch jederzeit dynamisch angepasst werden.
In den unterschiedlichen Beispielen dieses Artikels wurden bereits viele der Möglichkeiten genutzt, den DoP zu setzen. Die Angabe DEFAULT bewirkt, dass durch die Datenbank
der DoP auf 2*CPU_COUNT gesetzt wird, bei Cluster-Umgebungen wird dieser Wert nochmals mit dem ACTIVE_INSTANCE_COUNT multipliziert. Eine solche Festlegung kann in Mehrprozessorsystemen
bzw. solchen mit vielen Prozessorkernen dazu führen, dass der Parallelitätsgrad sehr hoch ist. Ein System mit vielen gleichzeitig aktiven Benutzern kommt dann schnell an
seine Grenze, ein einzelner Batchjob nutzt die zur Verfügung stehenden Ressourcen hingegen optimal aus.
Um dieses Problem zu umgehen, kann ein fester Parallelitätsgrad im Data Dictionary eingetragen werden. Es hat sich hierbei in vielen Fällen bewährt, einen Grad von
höchstens 4 zu wählen und diesen bei allen korrespondierenden Objekten (d. h. den zugehörigen Indizes) identisch zu halten. Bei einem laufenden System hat es
der DBA hier oftmals schwer, diese Regel einzuhalten, was in letzter Konsequenz dann wieder zur Performanceproblemen führen kann.
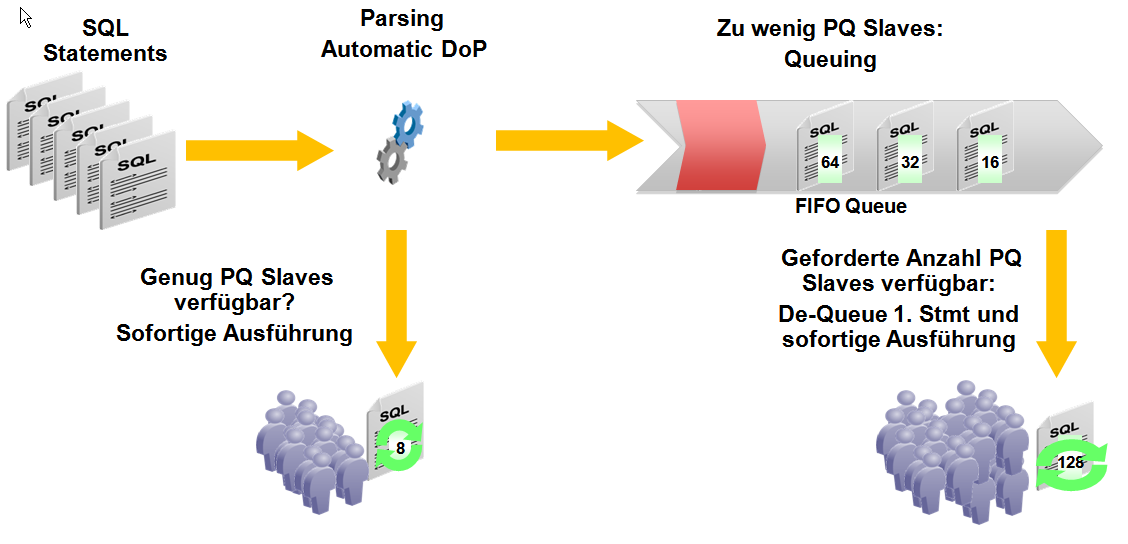
In Oracle 11g steht dem DBA nun eine sehr elegante Lösung für den Einsatz von Parallel Query zur Verfügung, dieses ist der Automatic Degree of Parallelism.
Die Funktion wird über den init.ora Parameter PARALLEL_DEGREE_POLICY gesteuert. Der Oracle Optimizer berechnet die benötigte Zeit für die serielle Abarbeitung
des Statements und prüft das ermittelte Ergebnis gegen den Schwellenwert PARALLEL_MIN_TIME_THRESHOLD. Wenn die berechnete Zeit diese Schwelle nicht übersteigt, dann
wird seriell gearbeitet, anderenfalls erfolgt die Berechnung des optimalen DoP. Die folgende Grafik illustriert die Implementierung.
| Für eine größere Ansicht auf das Bild klicken |
Das oben dargestellte Problem der möglichen Systemüberlastung wird bei dem geschilderten Automatismus dadurch vermieden, dass der ideale DoP, der unmittelbar von der Objektgröße
abhängt, und ein weiterer Schwellenwert, PARALLEL_DEGREE_LIMIT, in Relation gesetzt werden. PARALLEL_DEGREE_LIMIT berechnet sich hierbei nach der Regel
PARALLEL_THREADS_PER_CPU * CPU_COUNT * ACTIVE_INSTANCE_COUNT. Das Minimum aus dem idealen DoP und dem PARALLEL_DEGREE_LIMIT wird dann für die Ausführung des Statements
verwendet. Da PARALLEL_DEGREE_LIMIT manuell modifiziert werden kann, hat der DBA jederzeit direkten Einfluss auf das Systemverhalten und kann basierend auf seinen eigenen
Erfahrungen Grenzwerte festlegen. Im Ausführungsplan wird die durch den Optimizer getroffene Entscheidung im Bereich NOTES festgehalten.
Der Parameter PARALLEL_DEGREE_POLICY kann auf Session- oder Systemebene geändert werden. Es gibt auch die Möglichkeit, die Auto DoP-Funktion durch
den Hint PARALLEL(AUTO) zu nutzen. Mit den beschriebenen Alternativen hat der DBA für nahezu jede Lebenslage eine gute Lösungsmöglichkeit. Der Auto DoP
sollte Vorrang vor dem bisherigen Algorithmus mittels PARALLEL_ADAPTIVE_MULTI_USER haben, da mit dem neuen Algorithmus mehr Statements parallel abgearbeitet werden
können.
Die Einstellung PARALLEL_DEGREE_POLICY=AUTO ignoriert jede andere manuelle Festlegung. Sollen weiterhin bestimmte benutzerdefinierte Ausführungen von Statements stattfinden,
so muss PARALLEL_DEGREE_POLICY=MANUAL gesetzt werden. Die dritte Einstellungsmöglichkeit, PARALLEL_DEGREE_POLICY=LIMITED, bedeutet, dass der Auto DoP nur für
Tabellen oder Indizes, die über die PARALLEL Klausel ohne expliziten Parallelitätsgrad definiert worden sind, berechnet wird. Alle weiteren PQ Funktionen, wie das
Parallel Statement Queueing, werden nicht genutzt.
Bei einem Multiuser Betrieb und lang laufenden Parallel Query Statements kann es natürlich vorkommen, dass die Datenbank an die Grenzen der zur Verfügung
stehenden Ressourcen stößt. Bislang war es so, dass ein Statement in diesem Fall üblicherweise serialisiert abgearbeitet oder - bei Verwendung
des init.ora Parameters PARALLEL_MIN_PERCENT - eine Fehlermeldung erzeugt wurde. Mit Oracle 11g gibt es die Möglichkeit des parallel Statement Queueing.
In diesem Fall wird ein Statement, für dessen optimale Ausführung die Ressourcen fehlen, solange in einer internen Queue geparkt, bis genügend PX Server
Prozesse zur Verfügung stehen, und anschließend quasi mit voller Kraft ausgeführt. Das Abwarten ist erfahrungsgemäß besser, als das
Statement möglicherweise extrem langwierig seriell auszuführen. Das folgende Schaubild zeigt den Algorithmus.
| Für eine größere Ansicht auf das Bild klicken |
Parallel Statement Queueing arbeitet strikt nach dem Prinzip "first in - first out", dieses ist für die Einhaltung der Datenkonsistenz sehr wichtig. Im Einzelfall
kann es wünschenswert sein, Statement Queueing explizit auszuschalten. Das geschieht durch Einsatz des Hints /*+ NO_STMT_QUEUING */ .
Der DBA kann über eine Abfrage des Data Dictionaries prüfen, ob gerade ein Parallel Statement Queuing stattfindet, wie die folgende Abfrage zeigt.
Parallel Query Überwachung
Für die Überwachung von Parallel Query Prozessen können natürlich die Data Dictionary Views
- v$pq_slave
- v$pq_sysstat
- v$pq_sesstat
- v$pq_tqstat
genutzt werden. Wesentlich einfacher ist allerdings die Verwendung des Oracle Enterprise Manager Grid Control, der eine intuitive grafische Oberfläche bietet.
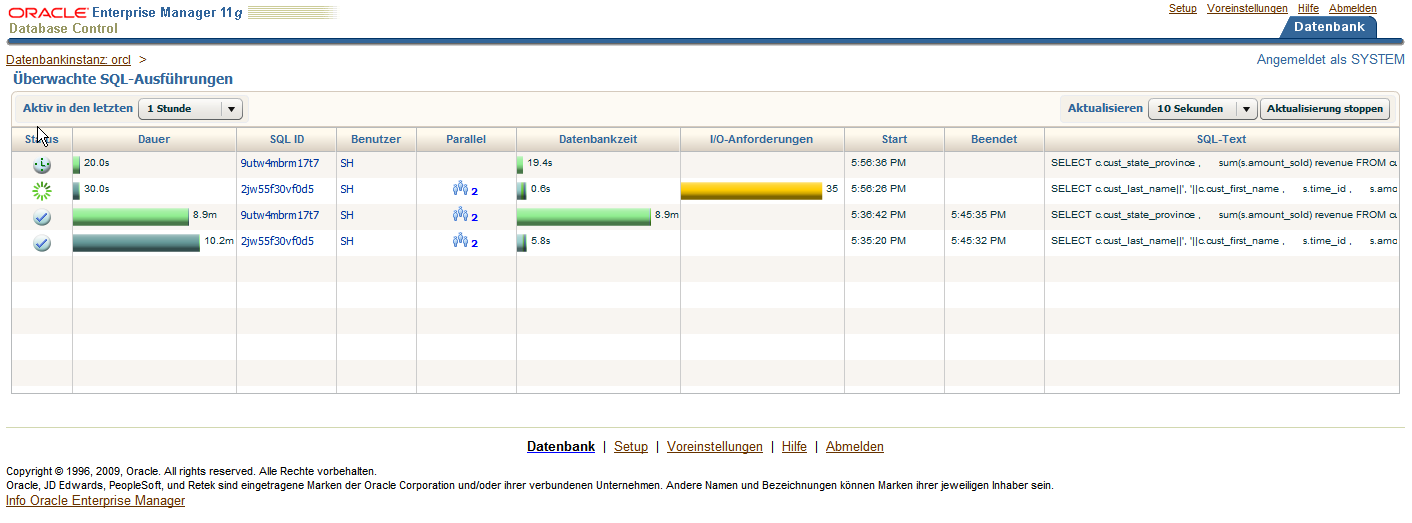
Im Abschnitt Performance bekommt man über den Link SQL Überwachung die im letzten Auswertungsintervall überwachten SQL Statements angezeigt. Mit dieser Anzeige hat
der Anwender sofort einen Überblick über die aktuell im System befindlichen SQL Statements. In dem unten dargestellten Screenshot sieht man zum Beispiel,
dass zwei Statements beendet worden sind, eines wird aktuell ausgeführt und eines befindet sich in der Warteschlange.
| Für eine größere Ansicht auf das Bild klicken |
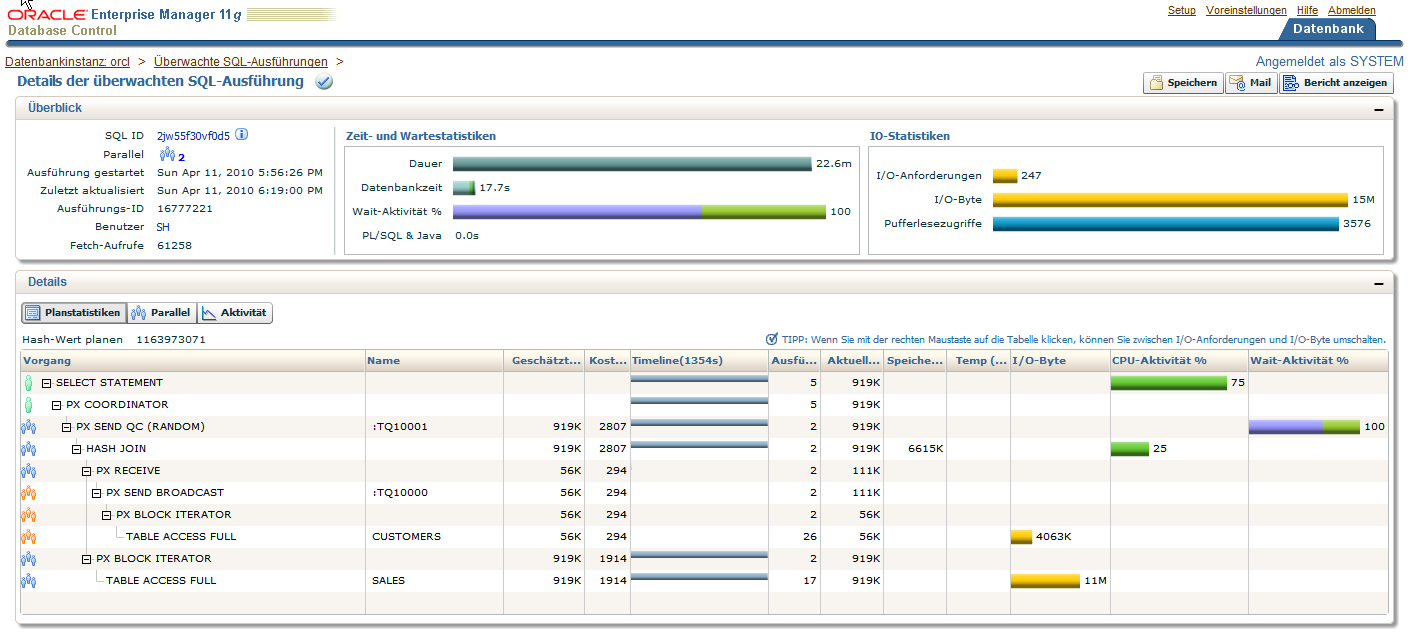
Durch einen Klick auf die SQL Id erhält man eine genaue Übersicht zu dem ausgewählten Statement. Hier ist insbesondere der Blick auf den Ausführungsplan
interessant. Die verschiedenen Schritte des Ausführungsplans sind detailliert aufgeschlüsselt und farblich markiert, dass gut erkennbar ist, welche einzelnen
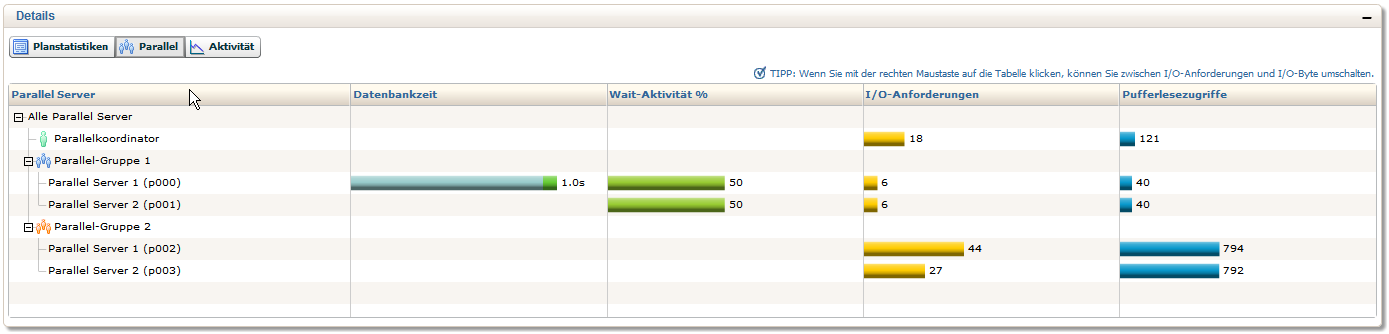
Schritte in Gruppen zusammengefasst werden. Durch Auswahl des Reiters Parallel im Detail-Fenster erhält man eine Aufstellung über die Aktivitäten
der unterschiedlichen PX Server Prozesse.
| Für eine größere Ansicht auf das entsprechende Bild klicken |
Fazit
Der Bereich Parallel Query ist in Oracle 11g erheblich einfacher geworden. Von den vorhandenen 14 init.ora Parametern, die es im Umfeld von Parallel Query gibt,
sind im Grunde nur 3 wirklich interessant:
- PARALLEL_MAX_SERVERS: Mit diesem Parameter wird festgelegt, wie viele PX Server maximal vorhanden sein können.
- PARALLEL_MIN_SERVERS: Dieser Parameter legt fest, wie viele PX Server minimal gestartet sein müssen. Dieses dient dazu, das zeitkritische Starten von PX Server
Prozessen zu minimieren.
- PARALLEL_DEGREE_POLICY: Mit diesem Parameter kann in der Einstellung AUTO Parallel Query nahezu vollständig automatisiert werden. Dieses ist ganz eindeutig
die empfohlene Methode. Die Einstellung MANUAL sollte nur aus Gründen der Rückwärtskompatibilität genutzt werden.
Mit dem neuen, effizienten Algorithmus zur Steuerung der Parallel Query Funktionalität hat der DBA das Werkzeug, die eingesetzten Systeme optimal auszunutzen.
Mehr zu diesem Thema bzw. zu weiteren Themen rund um die Datenbank lesen Sie in den nächsten Ausgaben ...
Zurück zur Community-Seite
|