高速データ・ロードおよびOracle Partitioningによるローリング・ウィンドウ操作
このチュートリアルでは、Oracle Databaseを使用した高速データ・ロードとOracle Partitioningを使用したローリング・ウィンドウ操作について学習します。
約2時間
このチュートリアルでは、以下のトピックについて説明します。
| 概要 | |
| シナリオ | |
| 前提条件 | |
| 売上履歴スキーマのスキーマ変更の実装 | |
| 外部表を使用したデータ・ロード | |
| 表圧縮を活用したディスク領域の節約とTCOの削減 | |
| Oracle Partitioningによるローリング・ウィンドウ操作の実行 | |
| まとめ |
![]() このアイコンの上にカーソルを置くと、すべてのスクリーンショットがロードし、表示されます。 (警告:すべてのスクリーンショットが同時にロードされるため、ご使用のインターネット接続によってはレスポンス・タイムが遅くなる場合があります。)
このアイコンの上にカーソルを置くと、すべてのスクリーンショットがロードし、表示されます。 (警告:すべてのスクリーンショットが同時にロードされるため、ご使用のインターネット接続によってはレスポンス・タイムが遅くなる場合があります。)
注:各手順に関連したスクリーンショットのみを表示する場合は、それぞれの手順にあるアイコンの上にカーソルを置いてください。 スクリーンショットをクリックすると、非表示になります。
データウェアハウスにデータを提供するオンライン・トランザクション処理(OLTP)ソース・システムは、多くの場合、データウェアハウス・システムに直接接続して新しいデータを抽出することはありません。 OLTPシステムは一般的に、外部ファイルの形式でデータ・フィードを送信します。 このデータをデータウェアハウスにロードする必要があります(なるべくパラレル処理にします)。このように、既存のリソースが活用されます。
たとえば、このチュートリアルで使用されるサンプルの企業(MyCompany)のビジネス・ニーズとディスク領域の制約によって、過去3年分のデータのみが分析に関連するとします。 つまり、新しいデータを挿入する場合、古いデータを消去するか、またはOracle Databaseの表圧縮を使用して、ディスク領域を解放する必要があります。 ローリング・ウィンドウと呼ばれるこのメンテナンス処理は、Oracle Partitioningによって実行されます。
このチュートリアルを始める前に次のことを確認してください。
| 1. |
Oracle Database、SQL、PL/SQLに関する実用的な知識を有していること。 |
| 2. |
データウェアハウスに精通していること。 |
| 3. | Oracle Database 11gがインストールされていること。 |
| 4. | wkdirという名前のディレクトリを作成し、このディレクトリにetl.zipをダウンロードして解凍していること。 |
外部ファイルをデータウェアハウスにロードする際、MyCompanyではOracle Database外部表機能が使用されます。この機能を使用すると、フラット・ファイルなどの外部データを、通常のデータベース表と同じようにデータベース内に公開できます。 外部表には、SQLを使用してアクセスできます。したがって、SQL、PL/SQL、およびJavaのすべての機能を使用して、外部ファイルに対する直接問合せをパラレルで実行できます。 一般的に、外部表は、抽出、変換、およびロード(ETL)プロセスで使用され、SQLを使用したデータ変換とデータ・ロードを単一の手順に統合します。 外部表は、ETLで使用される多数のアプリケーションや、フラット・ファイルを処理できるその他のデータベース環境において、非常に強力な機能です。 また、SQL*Loaderの代替機能としても使用できます。
パラレル実行を利用すると、意思決定支援システム(DSS)やデータウェアハウスで一般的に使用されている大規模データベースのデータ集約型処理にかかる応答時間が大幅に短縮されます。 パラレル実行は、特定のOLTPシステムやハイブリッド・システムでも実装できます。 簡潔に説明すると、パラレル処理とは、問合せのすべての作業を1つのプロセスで実行する代わりに、タスクを分割して、作業の各部分を多数のプロセスで同時に実行するという概念です。 たとえば、パラレル実行を使用すると、1つのプロセスで4つの四半期を処理する代わりに、4つのプロセスで1つずつの四半期を処理できます。
データウェアハウスに対する非常に重要なバックオフィス・タスクの1つに、OLTP(ソース)システムで行われる各種の変更に対するデータの同期があります。 また、分析の観点から見たデータの使用期間は、一般的に非常に制限されています。このため、新しいデータをロードするには、古いデータをターゲット・システムから消去する必要があります。この操作は、一般的にローリング・ウィンドウ操作と呼ばれます。 理想的には、データウェアハウス・システムの同時オンライン・アクセスに影響を与えることなく、この操作をできるだけ迅速に実行する必要があります。
このOracle by Example(OBE)のタスクを開始する前に、既存の売上履歴(SH)スキーマに変更を実装する必要があります。 SHスキーマに追加のオブジェクトを作成します。 また、追加のシステム権限をSHユーザーに付与する必要があります。 これらの変更を行うSQLファイルは、modifySH_11g.sqlです。 次の手順を実行してください。
| 1. |
ターミナル・ウィンドウを開きます。 ターミナル・セッションから次のコマンドを実行して、作業ディレクトリを/home/oracle/wkdir/etlに変更します。 cd wkdir/etl (注: このチュートリアルでは、/home/oracle/wkdir/etlフォルダが作成されていることを前提とします。 このフォルダが作成されていない場合は、フォルダを作成し、etl.zipの内容をこのフォルダに解凍する必要があります。)
|
| 2. |
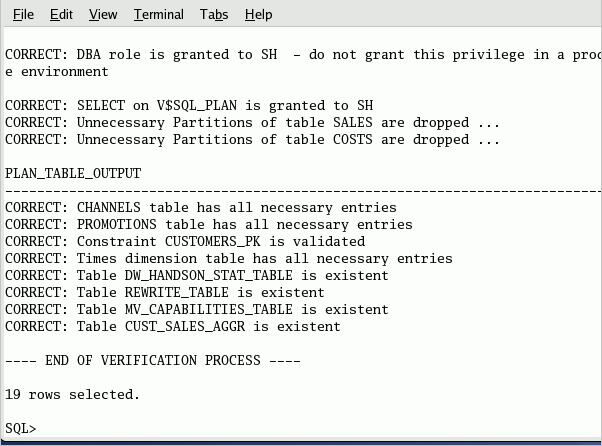
SQL*Plusセッションを開始し、SHユーザーとしてログインします(パスワードにSHを使用します)。 次のmodifySH_11g.sqlスクリプトをSQL*Plusセッションで実行します。 @modifySH_11g.sql 出力結果の末尾が、下に示すイメージと一致している必要があります。
|
ここでは、外部表を使用してデータウェアハウスにデータをロードします。
外部表を構築して使用するには、以下の手順を実行します。
| 1. | |
| 2. | 外部表の作成 |
| 3. | 外部表からの選択 |
| 4. | 外部表への透過的な高速パラレル・アクセスの提供 |
| 5. | Oracleのパラレル挿入機能の確認 |
| 6. |
外部表を作成する前に、データファイルが存在するファイル・システムのディレクトリを示すデータベースのディレクトリ・オブジェクトを作成する必要があります。 任意で、データファイルのロケーションと、log、bad、およびdiscardファイルのロケーションを分離できます。 ディレクトリを作成するには、以下の手順を実行します。
|
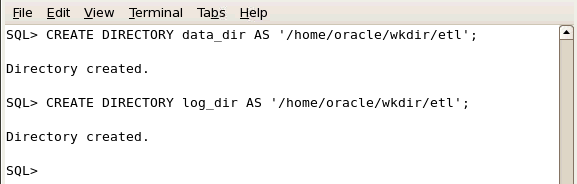
SHユーザーとしてログオンしたSQL*Plusセッションで、create_directory.sqlスクリプトを実行するか、以下のSQL文をSQL*Plusセッションにコピーします。 DROP DIRECTORY data_dir; DROP DIRECTORY log_dir; CREATE DIRECTORY data_dir AS '/home/oracle/wkdir/etl';
スクリプトはLinuxシステム用に設定されており、ファイルが/home/oracle/wkdir/etlに抽出されたと仮定します。 セキュリティ上の理由から、シンボリック・リンクはデータベース内のDIRECTORYオブジェクトとしてサポートされていません。
|
外部表を作成すると、次の情報が定義されます。
| 1. |
データベース内の表を表現するメタデータ情報 |
| 2. | 外部ファイルからデータを抽出するHOWアクセス・パラメータ定義 |
このメタ情報を作成すると、初期ロードを実行しなくても、外部データにデータベース内からアクセスできるようになります。
外部表を構築するには、以下の手順を実行します。
|
SHユーザーとしてログインしたSQL*Plusセッションで、create_external_table.sqlスクリプトを実行するか、以下のコマンドをコピーします。 DROP TABLE sales_delta_XT; CREATE TABLE sales_delta_XT
(
PROD_ID NUMBER,
CUST_ID NUMBER,
TIME_ID DATE,
CHANNEL_ID CHAR(2),
PROMO_ID NUMBER,
QUANTITY_SOLD NUMBER(3),
AMOUNT_SOLD NUMBER(10,2)
)
ORGANIZATION external
(
TYPE oracle_loader
DEFAULT DIRECTORY data_dir
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII
BADFILE log_dir:'sh_sales.bad'
LOGFILE log_dir:'sh_sales.log_xt'
FIELDS TERMINATED BY "|" LDRTRIM
(prod_id, cust_id,
time_id CHAR(11) DATE_FORMAT DATE MASK "DD-MON-YYYY",
channel_id, promo_id, quantity_sold, amount_sold
)
)
location
(
'salesDec01.dat'
)
)REJECT LIMIT UNLIMITED NOPARALLEL;
以下のデータ・ディクショナリ・ビューを通じて外部表の情報を参照できます。 - [USER | ALL| DBA]_EXTERNAL_TABLES
- [ALL| DBA]_DIRECTORIES
- [USER | ALL| DBA]_EXTERNAL_LOCATIONS
|
以下のSQLコマンドに示されているとおり、追加アクションを実行せずに外部ファイルのデータにアクセスできます。
|
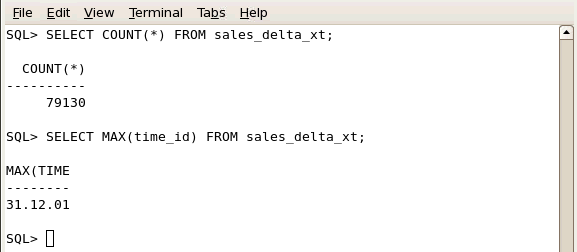
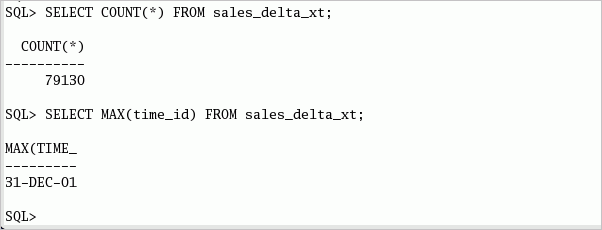
SHユーザーとしてログインしたSQL*Plusセッションで、以下の問合せまたはselect_et.sqlファイルを実行します。 SELECT COUNT(*) FROM sales_delta_xt; SELECT MAX(time_id) FROM sales_delta_xt; ファイルを正しくコピーした場合、TIME_IDの最大値は2001年12月の末日になります。
|
SQL*Loaderとは異なり、外部表へのアクセスは外部ファイルの数に関係なくパラレル実行できます。 SQL*Loaderが実行できるのは、ファイル単位の操作だけです。 つまりパラレル処理を実行するには、大規模なソース・ファイルを手動で分割する必要があります。 外部表を使用すると、通常の表と同じように並列度が正確に制御されます。 この場合、デフォルトでNOPARALLEL外部表を定義します。 次の項では、ヒントを使用した文レベルの並列度を制御する方法について説明します。
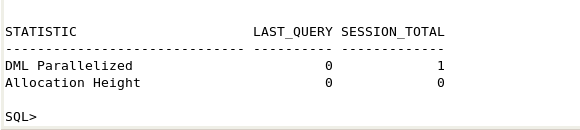
| 1. |
parallel_select_from_ET.sqlスクリプトには、次の3つの手順に対するSQL文が含まれます。 SHユーザーとしてログオンしたSQL*Plusセッションで、次の問合せまたはparallel_select_from_ET.sqlファイルを実行して、現在のパラレル・セッションの統計情報を確認します。
SELECT *
FROM v$pq_sesstat
WHERE statistic in ('Queries Parallelized',
'Allocation Height');
|
| 2. |
以前に使用した問合せをそのまま実行して、ヒントで制御される並列度4の外部表にアクセスします。 以下のコマンドまたはparallel_select_from_ET_2.sqlスクリプトを使用できます。 SELECT /*+ parallel(a,4) */ COUNT(*) FROM sales_delta_XT a;
外部表は1つの入力ソース・ファイルだけを指しますが、実際は外部表に対してパラレルでSELECTが実行されています。 または、次のALTER TABLEコマンドを使用して、外部表のPARALLELプロパティを変更できます。 ALTER TABLE sales_delta_XT PARALLEL 4;
|
| 3. |
セッションの統計情報を再表示して、違いを確認します。 以下のコマンドまたはparallel_select_from_ET.sqlスクリプトを実行します。 パラレル・セッションの統計情報が変更されています。 最後の問合せがパラレル処理され、その並列度が表示されます。
SELECT *
FROM v$pq_sesstat
WHERE statistic in
('Queries Parallelized', 'Allocation Height');
|
Oracle Databaseは、各パーティション内に無制限のパラレル・ダイレクト・パスのINSERT機能を提供します。 実行計画を使用すると、INSERTのパラレル処理を実行するかどうかを決定できます。 または、EXPLAIN PLANコマンドを実行せずに、SQLキャッシュで操作の実行計画を確認することもできます。
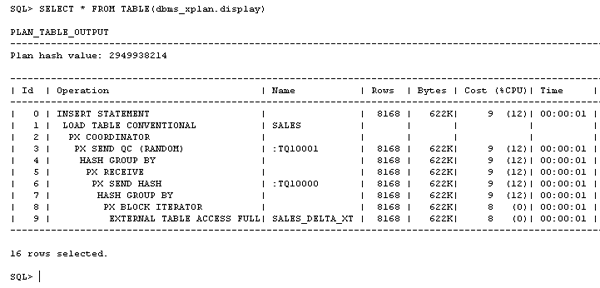
次のシリアル計画を検証します。 パラレルで定義されたオブジェクトがないため、オブジェクトのデフォルト並列度が変更されている場合とヒントが使用されている場合を除いて、自動的にシリアル実行になります。
| 1. |
SERIAL INSERT処理の実行計画を表示するには、show_serial_exec_plan.sqlを実行するか、以下のSQL文をSQL*Plusセッションにコピーします。 EXPLAIN PLAN FOR INSERT /*+ APPEND */ INTO sales
(
PROD_ID,
CUST_ID,
TIME_ID,
CHANNEL_ID,
PROMO_ID,
QUANTITY_SOLD,
AMOUNT_SOLD
)
SELECT
PROD_ID,
CUST_ID,
TIME_ID,
case CHANNEL_ID
when 'S' then 3
when 'T' then 9
when 'C' then 5
when 'I' then 4
when 'P' then 2
else 99
end,
PROMO_ID,
sum(QUANTITY_SOLD),
sum(AMOUNT_SOLD)
FROM SALES_DELTA_XT
GROUP BY 1, prod_id,time_id,cust_id,channel_id,promo_id;
set linesize 140 set pagesize 40 SELECT * FROM TABLE(dbms_xplan.display); |
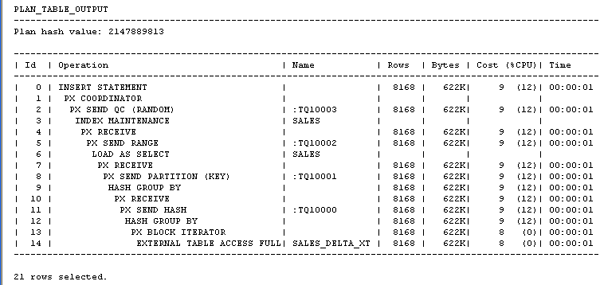
| 2. |
PARALLEL INSERT実行計画を表示するには、SHユーザーとしてログインし、以下のコマンドまたはshow_parallel_exec_plan.sqlスクリプトを実行します。 パラレルDMLコマンドは、常にトランザクションの最初の文に配置する必要があります。 また、主キーおよび外部キーの制約がある場合、DML操作は実行できません。 このため、パラレルDML操作の前に制約を無効にする必要があります。 ALTER TABLE sales DISABLE CONSTRAINT sales_product_fk;
|
ここでは、前述したパラレルINSERT(挿入)を実行します。 挿入を実行する前に、外部表からデータをSELECT(選択)するだけではなく、SELECTの一部として集計を行うことに注意してください。 ここで、変換と実際のロード・プロセスが統合されます。 この操作は、SQL*Loaderユーティリティだけでは実行できません。
| 1. |
以下のSQL文またはparallel_insert_file.sqlファイルを実行して、パラレルINSERT(挿入)を実行します。 set timing on この文の実行時間を記録しておき、SQL*Loaderおよび後続の挿入の処理にかかる合計時間と比較します。 ここでは1つのディスクを使用した単一CPUマシン上で、非常に少量のデータにパラレル・アクセスしているため、外部表へのアクセスを並列化し、変換とロードを統合したことによるメリットは十分には分かりません。
|
| 2. |
ROLLBACKを実行して、データを以前の状態に戻します (次の例で、SQL*Loaderを使用して同じデータを挿入します)。 ROLLBACK; 
|
| 3. |
ROLLBACKを発行した後、制約を再度有効にする必要があります。 以下のコマンドまたはenable_cons.sqlスクリプトを実行します。 ALTER TABLE sales MODIFY CONSTRAINT sales_product_fk ENABLE NOVALIDATE; ALTER TABLE sales MODIFY CONSTRAINT sales_customer_fk ENABLE NOVALIDATE; ALTER TABLE sales MODIFY CONSTRAINT sales_time_fk ENABLE NOVALIDATE; ALTER TABLE sales MODIFY CONSTRAINT sales_channel_fk ENABLE NOVALIDATE; ALTER TABLE sales MODIFY CONSTRAINT sales_promo_fk ENABLE NOVALIDATE;  1つの手順で、データのロードと変換の両方が実行されました。 SQL*Loaderを使用してデータをロードおよび変換するには、2つのプロセスが必要です。つまり、より多くの作業が必要になり、プロセス完了までのパフォーマンスが低下します。 |
上で実行した外部表の手順は、データのロードおよび変換に適した手順です。 外部表を使用した場合の利点を示すため、SQL*Loaderを使用してデータをロードおよび変換するために必要なタスクと比較します。
SQL*Loaderを使用してデータをロードおよび変換するには、以下の手順を実行します。
| 1. | |
| 2. | |
| 3. | ターゲット・データベースへのステージング表のロード |
| 4. | ステージング表の削除 |
2つ目の手順でデータベース内の変換を実行するには、データをロードするステージング表が必要になります。
|
SHユーザーとして接続したSQL*Plusセッションで、以下のコマンドまたはcreate_stage.sqlスクリプトを実行して、ステージング表を作成します。 CREATE TABLE sales_dec01 AS 
|
注: スクリプトはLinuxシステム用に設定されており、ファイルが/home/oracle/wkdir/etlに抽出されたと仮定しています。
以下の手順を実行して、sales_dec01.ctlファイルからステージング表にデータファイルをロードします。
| 1. |
OSコマンドラインから以下のコマンドを実行します。 cd /home/oracle/wkdir/etl 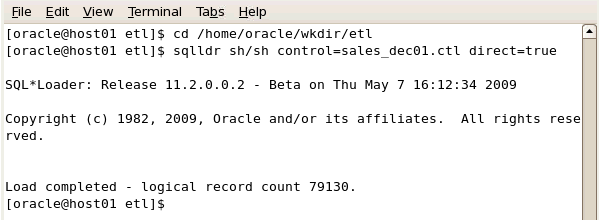
注: SQL*Loaderを使用して接続する場合、データベース・エイリアスの指定が必要な場合があります。 以下の文を使用して、SQL*Loaderを起動します。 sqlldr sh/sh@<database alias> control=sales_dec01.ctl direct=true |
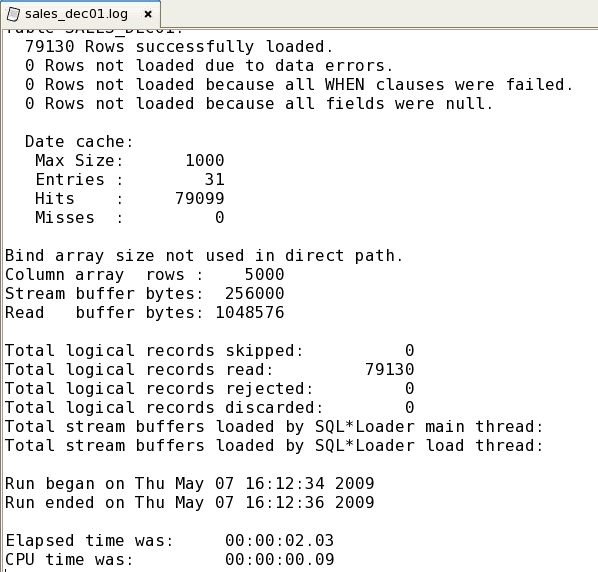
| 2. |
このタスクをパラレル実行することはできません。 SQL*Loaderのsales_dec01.logログ・ファイルを確認し、ロード・プロセスの実行時間を記録します。 任意のエディタを使用して、sales_dec01.logファイルを確認します。 ファイルは、/home/oracle/wkdir/etlディレクトリにあります。
外部表とは異なり、データベース内からデータにアクセスできるようにするために、データベースで一定の領域が使用されています。 ステージング表によって使用される領域は、追加の変換用にロードされるデータ量に比例します。 また、SQL*Loaderのロード処理をパラレル化するには、複数の外部ファイルを使用する必要があります。 複数のSQL*LoaderプロセスにSKIPオプションを使用すると、同じファイルにアクセスできます。 ただしこの場合、すべてのSQL*Loaderプロセスが外部ファイル全体をスキャンするため、 全面的なパフォーマンスに弊害をもたらします。 オブジェクトの領域使用量に関する情報には、以下のデータ・ディクショナリ・ビューを通じてアクセスできます。[USER | ALL| DBA]_SEGMENTS [USER | ALL| DBA]_EXTENTS |
外部データをロードしてデータベースからアクセスできるようにした後、変換を実行できます。
|
SHユーザーとしてSQL*Plusにログインします。 以下のコマンドまたはload_stage_table.sqlスクリプトを実行して、外部データ(データベース内にステージングされているもの)を変換しSALESファクト表に挿入するSQL文を実行します。 set timing on
|
ステージング表の削除または切捨てを実行すると、使用されている領域が解放されます。
以下のコマンドまたはdrop_sales_dec01.sqlスクリプトを使用して、ステージング表の情報を削除します。 DROP TABLE sales_dec01; 
|
このシンプルなロードおよび変換プロセスに外部表を使用することで、ロード処理と変換処理が統合されます。これによって、プロセスが簡素化され、高速化されます。 また外部表を使用した場合、データベース内にデータをステージングする必要はありません。 外部データの量が多くなればなるほど、SQL*Loaderの代わりに外部表を使用することで、ステージング領域と処理時間がいっそう節約されます。
12月のデータをSALESファクト表の第4四半期パーティションに正しくロードすると、今後このパーティションには最小限のDML操作以外何も発生しません。 したがって、このパーティションは、Oracleの表圧縮機能を使用するストレージとして最大の候補になります。 ビジネスで必要とされる情報が増えるにつれ、リレーショナル・データベースに格納されるデータも増加します。 大量データを保持するコストの大部分は、ディスク・システムとデータを管理するために使用されるリソースのコストです。 このコストに対処するため、Oracle Databaseは独自の方法を使用して、データの問合せ時間にマイナスの影響をほとんど与えることなく、リレーショナル表に格納されたデータを圧縮することで、大幅なコスト削減を実現します。
市販のリレーショナル・データベース・システムは、リレーショナル表に格納されたデータに対して圧縮技術をあまり利用しません。 この理由の1つとして、圧縮に必要な時間と領域のトレードオフがリレーショナル・データベースでは必ずしも魅力的ではない点があります。 通常の圧縮技術を使用した場合、領域は節約できるかもしれませんが、データの問合せ時間が大幅に増加します。 また、多くの標準的な技術では、圧縮後にデータ・サイズが増加しないことが保証されていません。
Oracle Databaseは、大規模なデータウェアハウスに非常に有効な、独自の圧縮技術を提供します。 この圧縮技術は、多くの面でその独自性を発揮します。 まず、リレーショナル・データ用に最適化されているため、ディスク領域の削減量が標準的な圧縮アルゴリズムよりも大幅に多くなります。 また圧縮データの問合せパフォーマンスに悪影響が及ぶことはほとんどありません。実際、バックアップおよびリカバリなどのデータ管理操作や大量データにアクセスする問合せに、大きなプラスの影響を与える場合があります。 さらに、圧縮データが非圧縮データより大きくならないことが保証されています。
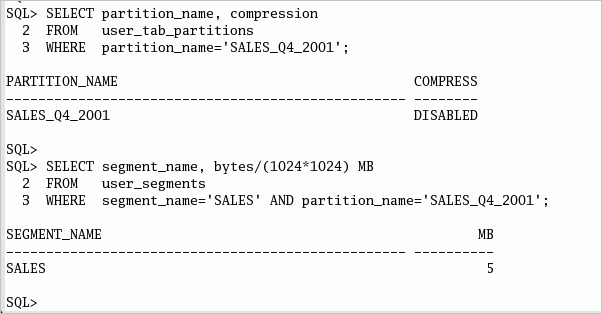
表圧縮による利点を評価するため、最新のパーティションで圧縮が有効化されていないことを確認します。 また、パーティションの大きさを調べます。
| 1. | part_before_compression.sqlスクリプトを実行するか、次のSQL文をSQL*Plusセッションにコピーします。 COLUMN partition_name FORMAT a50
|
| 2. |
パーティションを圧縮し、すべての既存索引を透過的にメンテナンスします。 すべてのローカル索引およびグローバル索引は、このSQL文の一部としてメンテナンスされます。 パーティションのメンテナンス処理に対するオンライン索引のメンテナンスは、このチュートリアルの後半で取り上げます。 パーティションの圧縮は、インプレース圧縮ではありません。 新しく圧縮したセグメントを作成し、操作の最後に古い非圧縮のセグメントを削除します。 SHユーザーとしてログインしたSQL*Plusセッションで、compress_salesQ4_2001.sqlスクリプトまたは次のSQL文を実行します。 ALTER TABLE sales MOVE PARTITION sales_q4_2001 COMPRESS UPDATE INDEXES; 
|
| 3. | 以下のコマンドまたはpart_after_compression.sqlスクリプトを実行して、新しく圧縮したパーティションが割り当てられる領域を確認し、非圧縮のパーティション・サイズと比較します。 SELECT partition_name, compression FROM user_tab_partitions 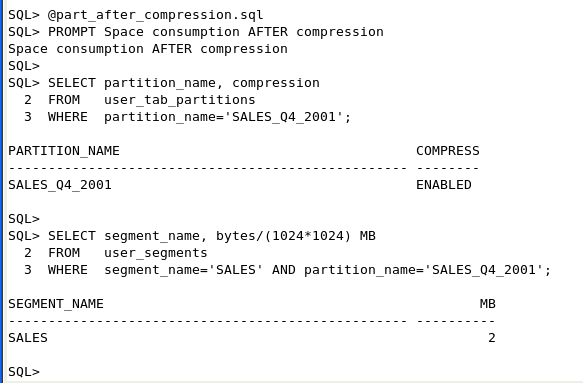
通常、実際のデータの圧縮比率は、売上履歴スキーマの圧縮比率よりも高くなります。 SALESファクト表のデータは人工的に生成されたものであるため、INSERTの前にデータがクレンジング、統合、または集計されるデータウェアハウス環境で見られる通常の"自然なソート"にはなりません。 |
多くのデータウェアハウスでは、データのローリング・ウィンドウが維持されます。 たとえば、あるデータウェアハウスには最近12カ月の売上データが保存されます。 新しいパーティションをSALES表に追加できるのと同様に、古いパーティションをSALES表から素早く(かつ1つずつ)削除できます。 Oracle Partitioningは、このような処理に理想的なフレームワークを提供します。 2つの利点(リソース使用量の削減とエンドユーザーへの影響の最小化)は、パーティションの追加と同様にパーティションの削除にも当てはまります。
ローリング・ウィンドウ操作の実行手順
| 1. | |
| 2. | |
| 3. | ファクト表からの古いデータの削除 |
ローリング・ウィンドウ操作を実行するには、以下の手順を実行して、新しいデータを使用したスタンドアロン表の作成およびロードを実行する必要があります。 上で定義した外部表を使用しますが、異なる外部ファイルに対してこの外部表を指定します。
| 1.1 | |
| 1.2 | |
| 1.3 | この表のロード |
| 1.4 | |
| 1.5 |
この項では、すでに定義した外部表を使用します。 ただし、今回は異なる外部ファイルのsales_Q1_dataを使用します。 このため、外部表の位置属性を変更して、新しいデータファイルを指定する必要があります。
| 1. |
最初に、select_et.sqlスクリプト・ファイルまたは以下のSQL文を実行して、現在の外部表の行数を確認します。 SELECT COUNT(*) FROM sales_delta_xt; SELECT MAX(time_id) FROM sales_delta_xt;
2001年12月のすべての売上トランザクションを含むファイルは、2001年12月の末日の値を示します。OSレベルで外部ファイルを変更した後、行数とMAX(time_id)の値が異なることを確認します。
|
| 2. |
LOCATION属性を変更します。 以下のコマンドまたはalter_loc_attrib.sqlスクリプトを実行して、LOCATION属性を変更します。 ALTER TABLE sales_delta_xt location ( 'salesQ1.dat' ); 
新しいデータを確認するには、以下のコマンドまたはselect_et.sqlスクリプトを実行します。 SELECT COUNT(*) FROM sales_delta_xt; SELECT MAX(time_id) FROM sales_delta_xt; 行数とTIME_IDの最大値が変わっています。 外部表ファイルが正しい場合、TIME_IDの最大値は2002年3月の末日になります。
|
ここでは、新しい第1四半期の売上データを格納するために空の表を作成します。 この表は、パーティション化された既存のSALES表に後で追加されます。
以下のコマンドまたはcreate_stage_table.sqlスクリプトを実行して表を作成します。 DROP TABLE sales_delta; |
この表をロードするには、以下の手順を実行します。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはload_stage_table2.sqlスクリプトを実行して表をロードします。 INSERT /*+ APPEND */ INTO sales_delta
|
| 2. |
SALES_DELTA表をロードした後、新しく作成したこの表の統計情報を収集します。 SHユーザーとしてログインしたSQL*Plusセッションで、以下のコマンドまたはgather_stat_stage_table.sqlスクリプトを実行して、表の統計情報を収集します。 exec dbms_stats.gather_table_stats('SH','sales_delta',estimate_percent=>20);
|
このスタンドアロン表と空のパーティションのSALES表を後で交換するため、交換した後に使用できるように、既存のSALES表とまったく同じ索引構造を構築して、この表のローカル索引構造を保存する必要があります。
| 1. |
ビットマップ索引を作成する前に、実際にデータを圧縮することなく、新しく作成した表を圧縮表に変更する必要があります。 この操作は、作成するビットマップ索引を、圧縮パーティションがすでに含まれるパーティション化表の索引と交換できるようにするために必要です。 以下のコマンドまたはalter_sales_delta.sqlスクリプトを実行して表を変更します。 ALTER TABLE sales_delta COMPRESS; ALTER TABLE sales_delta NOCOMPRESS; 
|
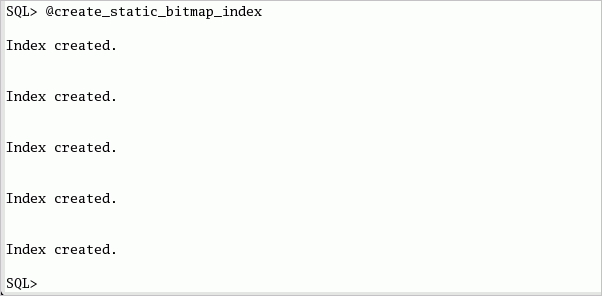
| 2. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_static_bitmap_index.sqlスクリプトを実行して、SALES_DELTA表のビットマップ索引を作成します。 CREATE BITMAP INDEX sales_prod_local_bix ON sales_delta (prod_id) NOLOGGING COMPUTE STATISTICS ; CREATE BITMAP INDEX sales_cust_local_bix ON sales_delta (cust_id) NOLOGGING COMPUTE STATISTICS ; CREATE BITMAP INDEX sales_time_local_bix ON sales_delta (time_id) NOLOGGING COMPUTE STATISTICS ; CREATE BITMAP INDEX sales_channel_local_bix ON sales_delta (channel_id) NOLOGGING COMPUTE STATISTICS ; CREATE BITMAP INDEX sales_promo_local_bix ON sales_delta (promo_id) NOLOGGING COMPUTE STATISTICS ; 索引作成の一部として、これらの索引の統計情報が作成されます。
|
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_constraints.sqlスクリプトを実行して、SALES表の制約を変更します。 ALTER TABLE channels MODIFY CONSTRAINT CHANNELS_PK RELY;
|
ローリング・ウィンドウ操作の次のタスクでは、新しくロードおよび索引付けされたデータをファクト表に追加します。 作成するには、以下の手順に従います。
| 2.1 | |
| 2.2 | |
| 2.3 | パーティションからの選択による妥当性の管理 |
| 2.4 | 最新のパーティションの分割による(ビジネス)データ整合性の確保 |
新しい空のパーティションを作成する必要があります。 明確な上限を持つ新しいパーティションを作成するか、またはMAXVALUEキーワードを使用できます。 キーワードを使用すると、潜在的な上限に違反するレコードが拒否されずにINSERT処理が正しく実行されます。
このビジネス・シナリオでは、ロード操作の完了後にSPLIT PARTITIONを発行して、潜在的な違反を識別します。 上限に違反するすべてのレコードが追加のパーティションに"分離"されます。
新しい空のパーティションを作成する必要があります。 実行するには、以下の手順に従います。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_partition_for_sales_etl.sqlスクリプトを実行して、パーティションをSALES表に追加します。 COLUMN partition_name FORMAT a20
select partition_name, high_value
from user_tab_partitions
where table_name='SALES'
order by partition_position;
ALTER TABLE sales
ADD PARTITION sales_q1_2002
VALUES LESS THAN (MAXVALUE);
SELECT COUNT(*)
FROM sales PARTITION (sales_q1_2002);
|
PARTITION EXCHANGEコマンドを実行して、新しくロードおよび索引付けしたデータを実際のSALESファクト表に追加します。 これはDDLコマンドだけで、実際のデータは操作しません。 追加するには、以下の手順に従います。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはexchange_partition_wo_gim.sqlスクリプトを実行して、SALES表をALTER(変更)します。これによって、パーティションが交換されます。 ALTER TABLE sales EXCHANGE PARTITION sales_q1_2002
|
次に、新しく追加および交換したパーティションに対して選択処理を実行します。
パーティション化されたファクト表に追加するデータが多ければ多いほど、このメタデータのみの操作によって節約される時間も多くなります。
レンジ・パーティション化などの論理パーティション操作を実施する必要があります。 ハッシュ・パーティション化は、一般的なローリング・ウィンドウ操作には使用できません。
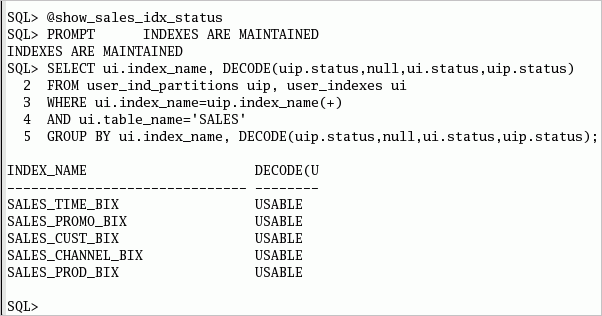
SALES表のすべての索引が維持されており、使用できる状態になっています。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下の問合せまたはselect_count.sqlスクリプトを実行します。 交換したパーティションの行数とスタンドアロン表(現在は空になっている)が表示されます。 SELECT COUNT(*) 
|
| 2. |
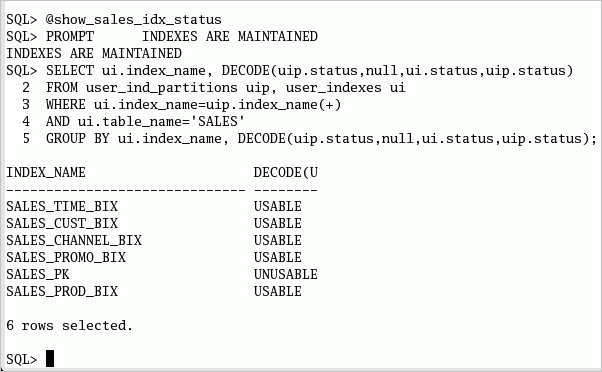
SALES表のすべてのローカル索引は有効になっています。 以下のコマンドまたはshow_sales_idx_status.sqlスクリプトを実行して、索引の状態を参照します。 SELECT ui.index_name, DECODE(uip.status,null,ui.status,uip.status)
また、PARTITION EXCHANGEコマンドの一部として、WITHOUT VALIDATION句も使用できます。 この句を使用すると、交換される表の妥当性の確認がOracle Databaseサーバーで実行されません。 それ以外の場合、Oracle Databaseサーバーは、パーティション化キーのすべての値がパーティション境界内で一致することを保証します。 |
すでに説明したとおり、潜在的なエラーを回避するため、上限が固定されていないパーティションへのデータ・ロードを選択しました。 潜在的な違反を識別するには、最新のパーティションを分割して2つのパーティションを作成します。この際、1つのパーティションは上限を固定したものにします。
Oracle Databaseは高度な高速分割処理を使用して、SPLIT操作後の2つの新しいパーティションのうちの1つが空であるかどうかを検出します。 いずれかが空である場合、Oracle Databaseサーバーは新しいセグメントを2つ作成しません。 その代わり、DBMS_STATSを使用して空の新しいパーティションに1つのセグメントだけを作成します。また、すべてのデータを含む新しいパーティションとして既存のセグメントを使用します。
この最適化は、完全に透過的に実行されます。 SPLIT操作の実行時間が向上し、システム・リソースが節約されます。また、索引のメンテナンスは必要ありません。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはfast_split_sales.sqlスクリプトを実行して、SALES表の変更と索引状態の参照を実行します。 ALTER TABLE sales SPLIT PARTITION sales_q1_2002
|
| 2. |
SALES表のすべてのローカル索引が依然として有効になっていることに注目します。 show_sales_idx_status.sqlスクリプトを実行して、SALES表のローカル索引の状態を参照します。 @show_sales_idx_status.sql
|
ローリング・ウィンドウ操作の次のタスクでは、ファクト表から古いデータを削除します。 ここでは、過去3年の最新データだけを分析するとします。 2002年の第1四半期を追加したため、1998年の第1四半期のデータを削除する必要があります。
レンジ・パーティション化を使用しないで、表のDML操作を実行する必要があります。 パーティション化を使用する場合、PARTITION EXCHANGEコマンドを再度利用して、ファクト表からデータを削除できます。 ここでも、新規データの追加と同様に、ハッシュ・パーティション化は有効ではありません。
データを削除するわけではないことに注意します。 代わりに、SALESファクト表のこのデータを含むパーティションを、同じ論理構造を持つ空のスタンドアロン表と交換(論理的に置換)します。 ビジネス・ニーズに応じて、このデータをアーカイブするか、交換したパーティションを削除できます。
| 3.1 | |
| 3.2 | |
| 3.3 | この表の制約の作成 |
| 3.4 | 交換前のパーティションのデータ表示 |
| 3.5 | 空の新しい表と既存の1998年第1四半期のパーティションの交換 |
| 3.6 | 交換後のパーティションのデータ表示 |
1998年の古いデータを保存する空の表を作成する必要があります。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_empty_sat.sqlスクリプトを実行して、1998年の古いデータを保存する空の表を作成します。 DROP TABLE sales_old_q1_1998; CREATE TABLE sales_old_q1_1998 NOLOGGING COMPRESS
|
ローカル索引を作成します。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_ndx.sqlスクリプトを実行して、ローカル索引を作成します。 CREATE BITMAP INDEX sales_prod_old_bix
ON sales_old_q1_1998 (prod_id)
NOLOGGING COMPUTE STATISTICS ;
|
制約を作成します。
|
SHスキーマでログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_constraints_old.sqlスクリプトを実行して、制約を変更および作成します。 ALTER TABLE channels MODIFY CONSTRAINT CHANNELS_PK RELY;
|
交換を実行する前に、パーティションの古い1998年第1四半期のデータを参照します。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはshow_partition.sqlスクリプトを実行して、パーティションの古いデータを参照します。 SELECT COUNT(*) FROM sales PARTITION (sales_q1_1998);
|
空の表と既存の1998年第1四半期のパーティションを交換します。 交換するには、以下の手順に従います。
|
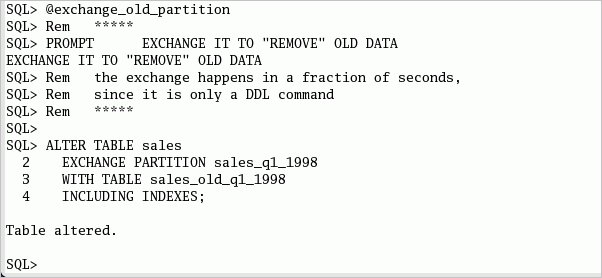
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはexchange_old_partition.sqlスクリプトを実行して、パーティションを交換します。 ALTER TABLE sales EXCHANGE PARTITION sales_q1_1998 WITH TABLE sales_old_q1_1998 INCLUDING INDEXES;
上記の方法の代わりに、DROP PARTITION文を使用することもできます。 SALES_OLD_Q1_1998表に1998年第1四半期のデータがすべて格納されます。この表を削除すると、データがシステムから完全に削除されます。 |
交換を実行した後に、パーティションのデータを参照します。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcount_sales.sqlスクリプトを実行して、パーティションのデータを参照します。 SELECT COUNT(*) FROM sales PARTITION (sales_q1_1998); SELECT COUNT(*) FROM sales_old_q1_1998;
EXCHANGEコマンドの実行前とは異なり、スタンドアロン表に数千行が格納されているのに対し、SALES表の該当パーティションは空になっています。
|
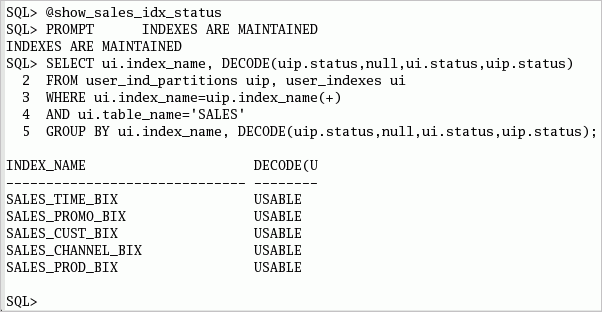
| 2. |
ローカル索引は、交換の影響を受けません。 以下のコマンドまたはshow_sales_idx_status.sqlスクリプトを実行して、索引の情報を参照します。 SELECT ui.index_name, DECODE(uip.status,null,ui.status,uip.status) FROM user_ind_partitions uip, user_indexes ui WHERE ui.index_name=uip.index_name(+) AND ui.table_name='SALES' GROUP BY ui.index_name, DECODE(uip.status,null,ui.status,uip.status);
|
Oracle Database 10gのローカル索引メンテナンス拡張機能について学習するため、オンラインのローカル索引メンテナンスを使用して、最新の四半期パーティションを月次パーティションに分割します。 これは、Oracle Database 10gの新機能です。 またここでは、Oracle9iで導入されたグローバル索引メンテナンス機能も使用します。
| 1. | |
| 2. |
Oracle Database 10g以降では、可用性に影響を与えることなく、すべてのパーティション・メンテナンス操作を実行できます。 ローカル索引メンテナンスによって、アトミックなパーティション・メンテナンス操作の一部として、パーティション化された表のローカル索引が最新の状態に維持されます。
索引配置などの、影響を受けるすべてのローカル索引構造に対する物理属性を制御するため、パーティション・メンテナンス操作のSQL構文が拡張されています。
手順
| 1.1 | |
| 1.2 | |
| 1.3 | クリーンアップ |
次のシナリオを検証します。 2002年の第1四半期のデータを正常にロードした後、ビジネス要件の変化によって問合せパターンが変更されたことに気づいたとします。 四半期ごとの分析に焦点を当てる代わりに、多くのビジネス・ユーザーは月ごとのレポートや分析を使用し始めています。 変更されたこのビジネス要件に対処して問合せのパフォーマンスを最適化するため、Oracle Partitioningを使用して、最新の四半期を月ごとのパーティションに分割します。
ローカル索引メンテナンスのオンラインの可用性は、この例では取り上げません。 オンラインの可用性は、グローバル索引メンテナンスで示されており、ローカル索引においてもまったく同じように機能します。
新しい空のパーティションを作成する必要があります。 明確な上限を設定するか、またはMAXVALUEキーワードを指定して、新しいパーティションを作成します。 キーワードを使用すると、潜在的な上限に違反するレコードが拒否されずにINSERT処理が正しく実行されます。
このビジネス・シナリオでは、ロード操作の完了後にSPLIT PARTITIONコマンドを発行して、潜在的な違反を識別します。 上限に違反するすべてのレコードが追加のパーティションに"分離"されます。
以下の手順を実行して、空の新しいパーティションを作成します。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のSQL文を実行して、四半期パーティションから最新の月(2002年3月)を分離します(ローカル索引メンテナンスを含む)。 このタスクを実行するには、以下のコマンドまたはsplit1_10g.sqlスクリプトを実行します。 ALTER TABLE sales SPLIT PARTITION sales_q1_2002
AT (TO_DATE('01-MAR-2002','DD-MON-YYYY'))
INTO (PARTITION sales_1_2_2002 TABLESPACE example,
PARTITION sales_MAR_2002 TABLESPACE example NOCOMPRESS)
UPDATE INDEXES;
|
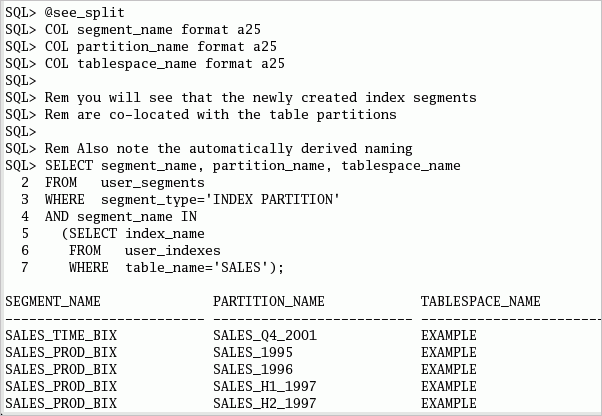
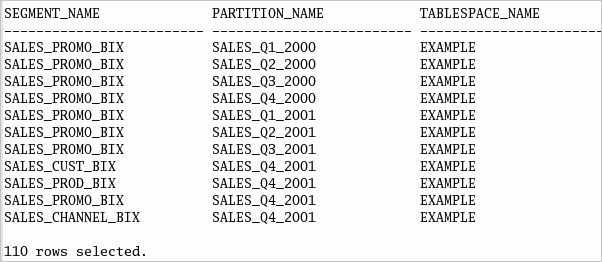
| 2. |
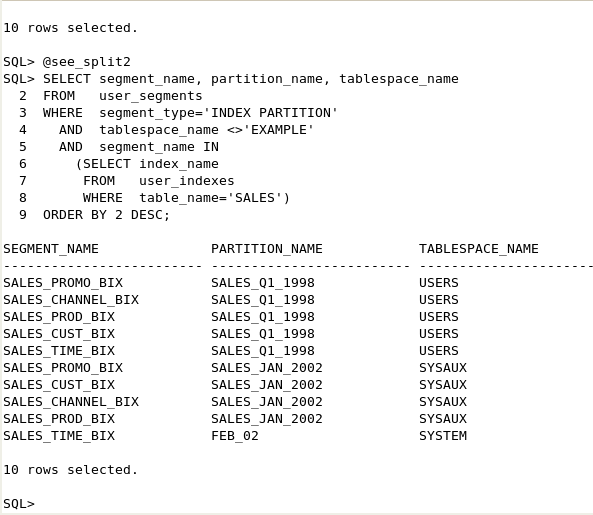
新しい索引パーティションと表パーティションが同じロケーションに配置され、索引パーティションにパーティションのネーミングが継承されていることを確認できます。 以下のコマンドまたはsee_split.sqlスクリプトを実行して、パーティションの情報を参照します。
COL segment_name format a25
COL partition_name format a25
COL tablespace_name format a25
SELECT segment_name, partition_name, tablespace_name
FROM user_segments
WHERE segment_type='INDEX PARTITION'
AND segment_name IN
(SELECT index_name
FROM user_indexes
WHERE table_name='SALES');
...
|
前の四半期パーティションの残りを1月および2月のパーティションに分割します。 デモ用に、SYSAUX表領域に新しいパーティションを作成して、一部の索引に明示的に名前を付けます。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のSQL文を実行して、残りのパーティションを分割します(ローカル索引メンテナンスを含む)。 以下のコマンドまたはsplit2_10g.sqlスクリプトを実行します。
ALTER TABLE sales SPLIT PARTITION sales_1_2_2002
AT (TO_DATE('01-FEB-2002','DD-MON-YYYY'))
INTO
(PARTITION sales_JAN_2002 TABLESPACE sysaux COMPRESS,
PARTITION sales_FEB_2002 TABLESPACE example NOCOMPRESS)
UPDATE INDEXES (sales_time_bix
(PARTITION jan_02 TABLESPACE example,
PARTITION feb_02 TABLESPACE system));
|
| 2. |
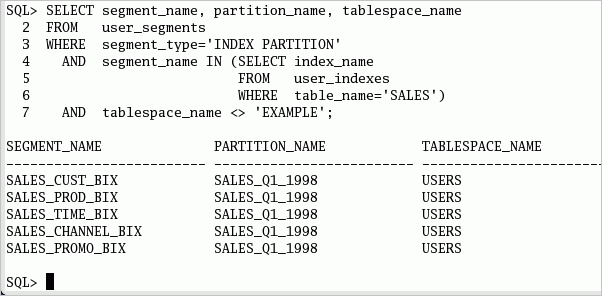
新しい索引パーティションと表パーティションが同じロケーションに配置され、索引パーティションの名前がパーティションから継承されていることを確認できます。 以下のコマンドまたはsee_split2.sqlスクリプトを実行して、パーティションとセグメントの情報を参照します。
SELECT segment_name, partition_name, tablespace_name
FROM user_segments
WHERE segment_type='INDEX PARTITION'
AND tablespace_name <>'EXAMPLE'
AND segment_name IN (SELECT index_name
FROM user_indexes
WHERE table_name='SALES')
ORDER BY 2 DESC;
|
SYSAUX表領域からEXAMPLE表領域にパーティションを移動して、クリーンアップ操作を実行します。 標準的なネーミング規則を使用します。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcleanup_split_10g.sqlスクリプトを実行して、パーティションの移動および索引の更新を実行します。 ALTER TABLE sales MOVE PARTITION sales_JAN_2002 TABLESPACE example COMPRESS
UPDATE INDEXES (sales_time_bix (PARTITION sales_jan_2002 TABLESPACE example),
sales_cust_bix (PARTITION sales_jan_2002 TABLESPACE example),
sales_channel_bix (PARTITION sales_jan_2002 TABLESPACE example),
sales_prod_bix (PARTITION sales_jan_2002 TABLESPACE example),
sales_promo_bix (PARTITION sales_jan_2002 TABLESPACE example))
;
ALTER INDEX sales_time_bix
REBUILD PARTITION feb_02 TABLESPACE example;
SELECT segment_name, partition_name, tablespace_name
FROM user_segments
WHERE segment_type='INDEX PARTITION'
AND segment_name IN (SELECT index_name
FROM user_indexes
WHERE table_name='SALES')
AND tablespace_name <> 'EXAMPLE';
|
グローバル索引メンテナンスによって、アトミックなパーティション・メンテナンス操作の一部として、パーティション化された表のグローバル索引が最新の状態に維持されます。 これにより、グローバル索引が使用不可にならないよう維持されるため、メンテナンス操作が実行される場合のグローバル索引の使用に影響が及ばなくなります。
手順
| 2.1 | |
| 2.2 | |
| 2.3 | グローバル索引メンテナンスを使用したパーティションの交換とグローバル索引への影響 |
| 2.4 | グローバル索引メンテナンスを使用しないパーティションの交換とグローバル索引への影響 |
| 2.5 | グローバル索引の削除と交換(クリーンアップ) |
グローバル索引が存在する状態で、3月のデータとパーティション化された表を交換します。 最初に、必要なインフラストラクチャを構築する必要があります。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはprep4_global_index.sqlスクリプトを実行して、グローバル索引メンテナンスの準備をします。 CREATE TABLE sales_mar_2002_temp
|
グローバル索引メンテナンス機能を実証するには、最初にグローバル索引を作成する必要があります。 作成するには、以下の手順に従います。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはcreate_global_index.sqlスクリプトを実行して、SALES表に連結された一意な索引を作成します。 CREATE UNIQUE INDEX sales_pk ON sales (prod_id, cust_id, promo_id, channel_id, time_id) NOLOGGING COMPUTE STATISTICS; これには最大で1分ほどかかります。
|
| 2. |
以下のコマンドまたはadd_sales_pk.sqlスクリプトを実行して、この索引を利用する制約を作成します。 ALTER TABLE sales ADD CONSTRAINT sales_pk PRIMARY KEY (prod_id, cust_id, promo_id, channel_id, time_id) USING INDEX; 
|
| 3. |
グローバル索引を使用して制約が定義される場合、交換される表にも同じ制約が定義される必要があります。 以下のコマンドまたはadd_salestemp_pk.sqlスクリプトを実行して、このタスクを実行します。 ALTER TABLE sales_mar_2002_temp ADD CONSTRAINT sales_mar_2002_temp_pk PRIMARY KEY (prod_id, cust_id, promo_id, channel_id, time_id) DISABLE VALIDATE;  |
同時オンライン・アクセスのパーティション・メンテナンス操作の影響を示すには、2つのセッション(ひいては2つのウィンドウ)が必要になります。 先に進む前に、次の項を注意深く読んでください。
1つ目のウィンドウで、以下の手順を実行します。
|
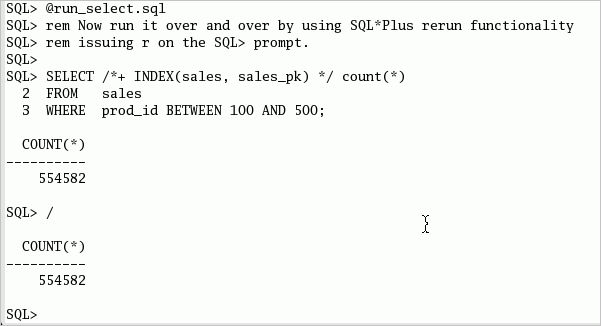
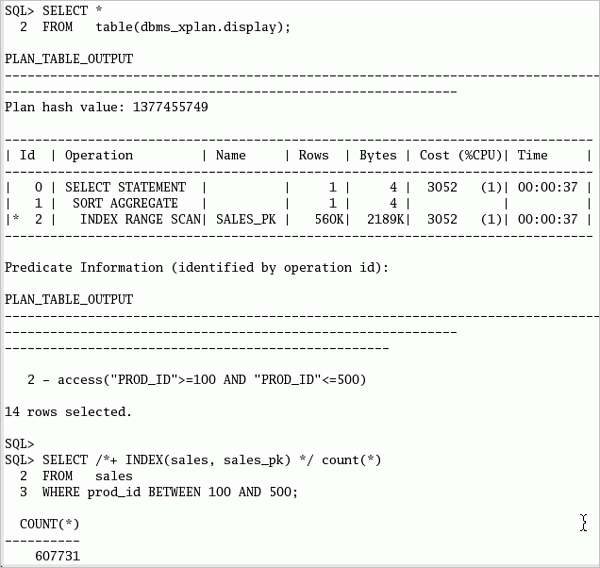
SHユーザーとしてログオンしたSQL*Plusセッションで、以下のコマンドまたはuse_global_index.sqlスクリプトを実行して、EXPLAIN PLANの作成と情報の参照を実行します。 EXPLAIN PLAN FOR SELECT /*+ INDEX(sales, sales_pk) */ count(*) FROM sales WHERE prod_id BETWEEN 100 AND 500; set linesize 140 SELECT * FROM TABLE(dbms_xplan.display); 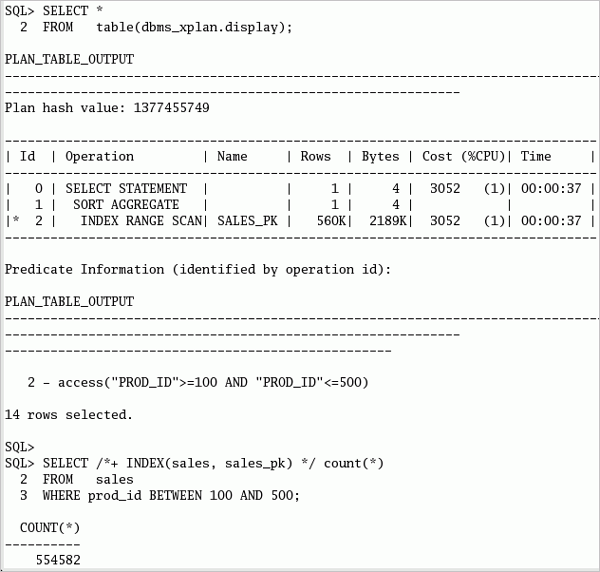
計画とグローバル索引の使用を検証した後で、以下の文またはrun_select.sqlファイルを繰り返し実行します。 最後に実行された文を再実行する場合、SQL*Plus機能の"r"または"/"を使用できます。 SELECT /*+ INDEX(sales, sales_pk) */ count(*) FROM sales WHERE prod_id BETWEEN 100 AND 500;
問合せを実行している間、2つ目のウィンドウで以下の手順を実行します。 パーティション・メンテナンス操作が実行されている間、グローバル索引を使用した同時問合せアクセスには影響が及ばないことが分かります。 問合せは失敗しません。 パーティション交換コマンドが成功すると、すぐに問合せの結果が変更されることを確認します。 Oracle Databaseサーバーは、この状況でのREAD CONSISTENCY(読取り一貫性)を保証します。また、オンライン使用を制限することなく、もっとも効率的なパーティション表と索引のメンテナンス操作を実現します。 |
2つ目のウィンドウで、以下の手順を実行します。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下の問合せまたはexchange_partition_w_gim.sqlスクリプトを実行します。 ALTER TABLE sales EXCHANGE PARTITION sales_mar_2002 WITH TABLE sales_mar_2002_temp INCLUDING INDEXES UPDATE GLOBAL INDEXES;
これはDDLコマンドですが、PARTITION EXCHANGEアトミック・コマンドの一部としてグローバル索引がメンテナンスされるため、時間がかかる場合があります。
|
| 2. | パーティション・メンテナンス操作の後もすべての索引が有効であることが分かります。 以下のコマンドまたはshow_sales_idx_status.sqlスクリプトを実行します。 SELECT ui.index_name,
DECODE(uip.status,null,ui.status,uip.status) status,
count(*) num_of_part
FROM user_ind_partitions uip, user_indexes ui
WHERE ui.index_name=uip.index_name(+)
AND ui.table_name='SALES'
GROUP BY ui.index_name, DECODE(uip.status,null,ui.status,uip.status);
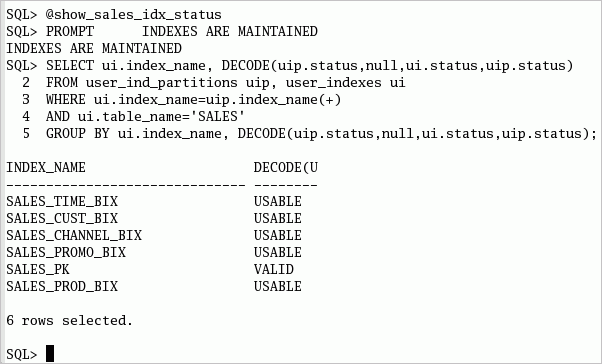
|
| 3. | 交換されたパーティションとスタンドアロン表の情報を参照します。 以下のコマンドまたはcount_mar_sales.sqlスクリプトを実行します。 SELECT COUNT(*) FROM sales PARTITION (sales_mar_2002); SELECT COUNT(*) FROM sales_mar_2002_temp;
このコマンドによって、数千行がパーティション化された表に追加されたため、スタンドアロン表は空になっています。 |
2001年の第1四半期の新しい売上データが再交換されます。 オンラインの使用に影響を与えることなく、PARTITION EXCHANGEコマンドの一部としてグローバル索引がメンテナンスされました。
次に、グローバル索引メンテナンスが存在しない場合の動作を検証します。
この機能を示すには、2つのウィンドウが必要です。 先に進む前に、次の項を注意深く読んでください。
1つ目のウィンドウで、以下の手順を実行します。
SHユーザーとしてログオンしたSQL*Plusセッションで、以下の問合せまたはuse_global_index.sqlスクリプトを実行します。 explain plan for SELECT /*+ INDEX(sales, sales_pk) */ count(*) FROM sales WHERE prod_id BETWEEN 100 AND 500; set linesize 140 SELECT * FROM table(dbms_xplan.display); SELECT /*+ INDEX(sales, sales_pk) */ count(*) FROM sales WHERE prod_id BETWEEN 100 AND 500; 2つ目のウィンドウで以下の手順を実行してから、上記の問合せを実行して違いを確認します。 この問合せは、パーティション・メンテナンス・コマンドが処理されるとすぐに失敗します。
|
2つ目のウィンドウで、以下の手順を実行します。
| 1. |
SHユーザーとしてログオンしたSQL*Plusセッションで、以下の問合せまたはexchange_partition_wo_gim2.sqlスクリプトを実行します。 ALTER TABLE sales
EXCHANGE PARTITION sales_mar_2002
WITH TABLE sales_mar_2002_temp
|
| 2. | ここでは、グローバル索引に使用不可のマークが付けられています。 以下のコマンドまたはshow_sales_idx_status.sqlスクリプトを実行して、この情報を参照します。 SELECT ui.index_name,
DECODE(uip.status,null,ui.status,uip.status) status,
count(*) num_of_part
FROM user_ind_partitions uip, user_indexes ui
WHERE ui.index_name=uip.index_name(+)
AND ui.table_name='SALES'
GROUP BY ui.index_name, DECODE(uip.status,null,ui.status,uip.status);
|
環境をクリーンアップするには、以下の手順に従います。
|
SHユーザーとしてログオンしたSQL*Plusセッションで、以下の文またはcleanup_mod1.sqlスクリプトを実行して、このOBEで実施した変更をクリーンアップします。 ALTER TABLE sales DROP CONSTRAINT sales_pk;
DROP INDEX sales_pk;
ALTER TABLE sales
EXCHANGE PARTITION sales_q1_1998
WITH TABLE sales_old_q1_1998 INCLUDING INDEXES;
ALTER TABLE sales DROP PARTITION sales_jan_2002;
ALTER TABLE sales DROP PARTITION sales_feb_2002;
ALTER TABLE sales DROP PARTITION sales_mar_2002;
DROP TABLE sales_mar_2002_temp;
DROP TABLE sales_delta;
DROP TABLE sales_old_q1_1998;
set serveroutput on
exec dw_handsOn.cleanup_modules
SELECT * FROM TABLE(dw_handsOn.verify_env)
|
このチュートリアルで学習した内容は、次のとおりです。
| 外部表を使用したデータ・ロード | ||
| SQL*Loaderの使用と外部表との比較 | ||
| 表圧縮によるディスク領域の節約 | ||
| Oracle Partitioningによるローリング・ウィンドウ操作の実行 | ||
![]() このアイコンの上にカーソルを置くと、すべてのスクリーンショットが非表示になります。
このアイコンの上にカーソルを置くと、すべてのスクリーンショットが非表示になります。