Oracle Data Miner 4.0の使用
概要
- 個人の行動の予測。たとえば、プロモーションの申し出に応答する可能性の高い顧客や特定の製品を購入する可能性のある顧客の抽出 (分類)
- 対象となる人々やアイテムのプロファイルの検索 (Decision Treeによる分類)
- 集合からセグメントまたはクラスタの発見 (クラスタリング)
- より多くのターゲット属性に関連する要因の特定 (属性重要度)
- 同時発生するイベントや購買の発見 (相関、マーケットバスケット分析)
- 異常値やレアなイベントの検出 (異常検出)
- データマイニングおよびビジネス目標の観点での課題定義
- データ収集および準備
- モデルの構築と検証
- 展開
目的
このチュートリアルでは、Oracle Database 12c Release 1上でデータマイニング・アクティビティを実行するためのOracle Data Miner 4.0の使用をカバーします。 Oracle Data Miner 4.0 は、Oracle SQL Developer バージョン4.0のエクステンションとして提供されます。このレッスンでは、ビジネス上の課題を解決するために、分類モデルを作成することでData Minerを使い方を学びます
Oracle SQL Developerは、データベース開発者のためのフリーのグラフィカルツールです。SQL Developerでは、データベース・オブジェクトを参照し、SQL文やSQLスクリプトの実行、およびPL/SQL文の編集・デバッグができます。 SQL Developer 4.0に含まれるData MinerはOracle Database 11g Release 2とOracle Database 12cに対応しています
所要時間
約45分間
導入
データマイニングは、データからパターンや傾向を抽出することにより、データのかたまりから有益な情報を抽出するプロセスです。データマイニングは以下のような多様なビジネス上の課題解決のために利用できます:
Oracle Data Miningを利用して、ビジネス上の課題を解決するフェーズは以下の通りです:
課題の定義とビジネス目標
データマイニングの実施時に、ビジネス上の課題をデータマイニングの機能の観点で明確に定義する必要があります。 たとえば小売業,電話会社、金融機関および他のエンタープライズ企業では、古くからの忠実な顧客のライバル社への切り替えという行為である顧客の「解約」に注視しています。「顧客の解約を解決するためにデータマイニングを使いたい」というのは、あまりにも漠然としています。ビジネス上の観点から、不満を持つ顧客の流出をくいとめることより、離れてしまった顧客を呼びもどすことのほうが、現実的に遙かに困難で費用がかかることです。さらに、企業にとっての価値が低い顧客には興味がないかもしれません。このようにデータマイニングによって、解約する可能性の高い顧客を予測し、潜在的に価値の高い顧客が解約するかどうかを予測することがビジネス上の課題となります
データ収集と準備
データマイニングにおける一般的な経験則は、個々のデータについてできるだけ多くの情報を収集し、有益である可能性のデータを任意にフィルタリングできるようにすることです。 具体的には、いくつかの属性は重要ではないかもしれないと考えるかもしれませんが、容易に削除するべきではありません。ODMのアルゴリズムによって削除するかどうかを決定できます。目標は任意の個人に対して適用できる行動のプロファイルを構築することですので、あなたは、名前、住所、電話番号等の特定の識別子を削除するべきです(ただし、郵便番号のような特定の個人を識別することなく一般的な場所を示す属性は役に立つかもしれません)。 一般的には、データ収集および準備のフェーズで、データマイニング・プロジェクトの時間と労力の50%以上を費やすと言われています
モデルの構築と検証
Oracle Data Minerでは、ワークフローの作成プロセスは、モデルの構築およびテスト中の困難なタスクの多くを自動化します。これは、ビジネス上の課題を解決するのに最も良いアルゴリズムがなんであるかを事前にすることはとても困難なので、通常、いくつかのモデルを作成しテストします。完全なモデルというものは存在せず、最良な予測モデルを検索するということは、必然的に最も制度の高いモデルを決定するということではなく、ビジネス上の目標という観点から許容されるエラーの種類を決定するということになります
展開
Oracle Data Miningは、実用的な結果を生成しますが、正しいものを素早く届けなければその結果は有用ではありません。Oracle Data Minerのユーザ・インタフェースは、結果を出力するためのオプションがいくつか用意されています
- 次のソフトウェアにアクセス可能もしくはインストール済み:
- Oracle Database:
- 必要最低バージョン: Oracle Database 11g Enterprise Edition, Release 2 (11.2.0.1) と Data Mining Option
- 推奨バージョン: Oracle Database 12c Enterprise Edition, Release 12.1 と Advanced Analytics Option
- SQL Developer 4.0
- Oracle Database:
シナリオ
これのレッスンは、分類モデルによって解決できるビジネス上の課題に焦点を当てています。このシナリオでは、ABC社は、保険を購入する可能性が最も高い顧客を識別したいと考えています
注: このチュートリアルでは、「データの準備および収集」というフェーズは既に完了しており、サンプルのデータセットにはすべての必要なデータフィールドが含まれています。よって、このレッスンでは「モデルの構築と評価」フェーズに主に焦点を当てています
ソフトウェア要件
次のソフトウェアが必要になります:
前提条件
チュートリアルを開始する前に、Oracle Data Minerを含めたOracle SQL Developer 4.0をインストールしてください
注: もしまだOracle Data Minerのセットアップをしていない場合、次のレッスンを実施してください: Oracle Data Miner 4.0のセットアップ
Data Minerプロジェクトの作成
Data Minerプロジェクトを作成し、Data Minerワークフローを構築する前に、必要なData Minerの機能に簡単にアクセスできるために、SQL Developer内のData Minerインタフェース・コンポーネントを整理しておくと便利です
開始するには、SQL Developerインタフェースのエレメンツ([接続]タブや[レポート]タブなどが含まれる)をすべて閉じ、以下のように、Data Minerタブのみを開きます:
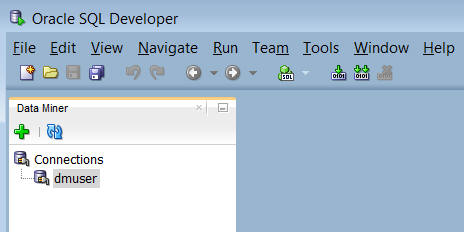
上に示したように、Data Minerユーザ(dmuser)が作成されており、SQL Developerの接続が確立されています。「Oracle Data Miner 4.0のセットアップ」チュートリアルで、DMUSERというデータベース・アカウントとSQL Developerの接続を作成する方法を学びます。このユーザは、マイニングに用いるサンプルデータへのアクセス権を持っています
注: もし、Data Minerタブが開いていない場合、SQL Developerのメニューから、表示> Data Miner > Data Minerの接続 を選択します
Data Minerプロジェクトの作成
Data Miner ワークフローの作業を開始する前に、1つ以上のワークフローのコンテナとしてData Minerプロジェクトを作成する必要があります
Data Miner プロジェクトを作成するには、次の手順を実行します:
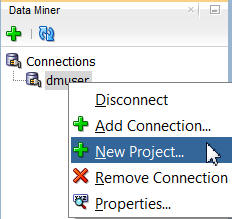
以下のように、Data Miner タブで、dmuserを右クリックし新規プロジェクトを選択します:
プロジェクトの作成ウィンドウで、プロジェクト名(この例ではABC Insurance)を入力し、OKをクリックします
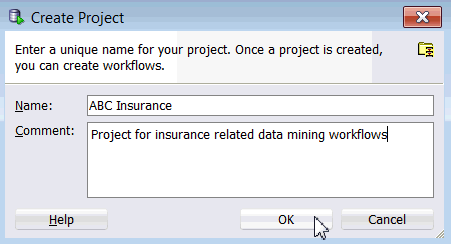
注: オプションでこのプロジェクトの意図を説明するコメントを入力することができます。この説明は、いつでも変更できます
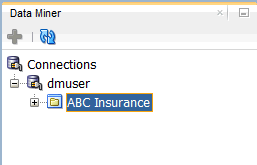
結果: 新規プロジェクトがデータマイニングのユーザ接続ノードの下に表示されます
Data Minerワークフローの構築
- データマイニングサーバのための指示を提供します。たとえば、「これらの特性を持つモデルを構築します」というワークフローを定義すると、ワークフローに返す結果とともにデータマイニングサーバでモデルが構築されます
- グラフィカル環境からデータマイニング・プロセスの作成、分析およびテストを対話的に実施できます
- より大きなプロセスの1サイクルのみをテストし、分析するために使う、もしくは特定のビジネス上の課題を解決するためにデザインされたプロセスのすべてのフェーズをカプセル化することができます
- プロセスの各要素は、ノードと呼ばれるグラフィカルなアイコンで表示されます
- 各ノードは、特定の指示を含む明確な目的を持ち、多くの方法で個々の定義を設定・修正します
- 一緒にリンクされる場合には、ワークフローノードは特定のデータマイニングの課題を解決されたことにより、モデリングプロセスを構築します
- ソースデータを特定し、検討する
- いくつかの分類モデルを構築し、比較する
- 最も実用的な結果を生成するモデルを選択し,実行する
- SQL Developerウィンドウの中央:
- 指定した名前のタブ名のついた空のワークフローウィンドウが表示されます
- また、[プロパティ]タブが、初回は同じエリアにあります
- インタフェースの右側上部に、ワークフローエディタの[コンポーネント]タブが表示されます
- また、他の3つのOracle Data Minerインタフェース要素が左側下部に開いています:
- ワークフローの名前を持つ[構造]タブ
- [サムネイル]タブ
- [ワークフロー・ジョブ]タブ
- Oracle Data Minerによって、 ワークスペースノード名とモデル名は自動で作成されます。この例では、「データソース」という名前が生成されました。 このレッスンで示したものと全く同じノード、モデル名を取得できない場合があります
- プロパティ・インスペクタを使用して、ワークスペースとモデルを変更することができます
- ズームオプションで別の値を入力するか選択することで、ワークフローキャンバス内のノードのサイズを変更できます。上図では既にズームプルダウンリストより75%が選択されています
- [サムネイル]タブでは、より大きなワークフローウィンドウの小さなディスプレイが用意されています。ワークフローウィンドウの周囲のノードをドラッグすると、サムネイル表示が自動的に調整されます
- SQL Developer内の別の場所に任意のData Minerのタブを移動することができます。デフォルトでワークフローペインの右下に配置される[プロパティ]タブを、単に目的の場所にドラッグすることで移動しています
- [プロパティ]タブでは:
- データセクションを使用して、表またはビューの列に関する情報を表示します
- データキャッシュセクションを使用して、結果表示を最適化するために出力データのキャッシュを生成します
- 上図のように詳細セクションを使用して、ノード名の変更や各ノードに関するコメントを追記します
- ノードの周囲の境界線にある黄色い情報アイコン(!)は、ノードが完全ではないことを示しています。よって、データ参照ノードを使う前に、少なくとも1つの追加ステップが必要です
- この場合、ソースデータを参照するためにデータ参照ノードにデータソースノードから接続する必要があります
- Data Minerはワークフロー文書を保存し、ステータス情報をノードの処理中にワークフローペインの上部にあるステータスバーに表示します
- 各ノードの処理中には、ノードの境界線上に緑の歯車アイコンが表示されます
- 更新が完了すると、データソースおよびデータの参照ノードの境界線には、以下のように緑のチェックマークが表示されます:
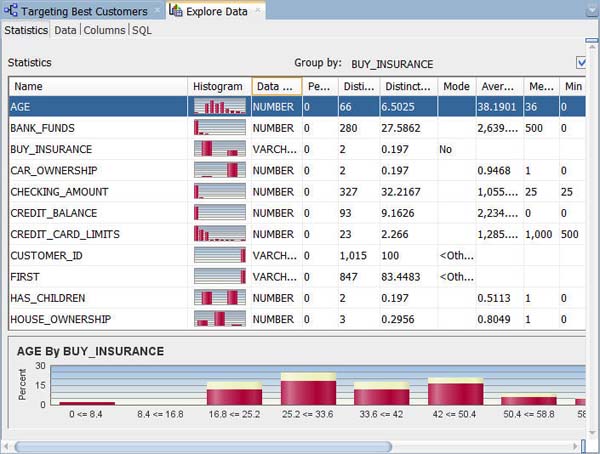
- Data Minerは、定義したデータセット内の各属性に関するさまざまな統計を、「グループ化基準」属性に定義した属性(BUY_INSURANCE)について算出します。次の列が出力されます:ヒストグラムのサムネイル、データ型、個別値、個別値パーセント、モード値、平均値、中間値、最小値、最大値、標準偏差、分散
- この表示によって可視化され、データを検証でき、また手動でデータのパタンや構造を調査できます
- 先に述べたように、境界線上の黄色い感嘆符は、ノードが完全になる前により多くの情報の設定が必要なことを示しています
- この場合、2つのアクションが必要です:
- ソースデータノードと分類構築ノードの間に接続を作成する必要があります
- 2つの属性を分類構築プロセス用に指定する必要があります
- 黄色い"!"マークが表示されているターゲットフィールドに注意してください。これは、この項目のために属性を選択しなければならないことを意味します
- 各モデルの名前が自動で生成されますが、この例とは異なる場合があります
- 必須ではありませんが、各レコードを一意にするためにケースIDを定義することをおすすめします。これはモデルの再現性を支援し、優れたデータマイニングの取り組みと一致するものです
- 先の述べたように、分類モデルのためのすべての4つのアルゴリズムがデフォルトで選択されています。特に指定しない限り、これらは自動的に実行されます。
- 詳細モデル設定ウィンドウでは、4つの分類アルゴリズムのそれぞれについて、データの使用方法、アルゴリズム設定、パフォーマンス設定について変更できます
- このウィンドウから赤い"x"もしくは緑の"+"アイコンを用いて、任意のアルゴリズムを選択解除(再選択)できます
- 構築プロセス中にテストを実行するかしないか
- どのテスト結果を生成するか
- テストデータの管理をどうするか
- ノードを実行すると、ノードに定義されたすべてのモデルが構築、テストされます
- 前と同様、サーバプロセスが実行中はノードの境界線上に緑のギアアイコンが表示され、ワークフローウィンドウの上部にステータスが表示されます
- 4つのモデルすべてが構築に成功している
- モデルはすべて同じターゲット(BUY_INSURANCE)を持つが異なるアルゴリズムを使っている
- ソースデータが自動でテストデータと構築データに分割される
- 比較結果には5つのタブが含まれます: パフォーマンス、パフォーマンス・マトリックス、ROC、リフト、利益
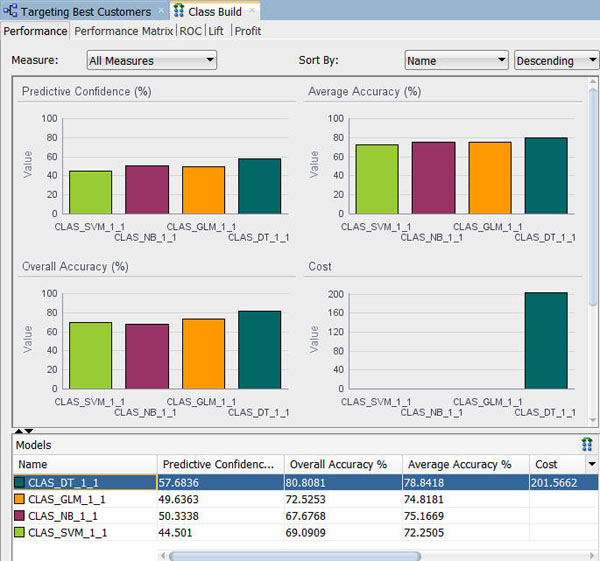
- パフォーマンスタブでは、各モデルについての、予測信頼度、平均精度および全体精度という情報を数値およびグラフィカルな情報として提供します
- パフォーマンスタブによると、ディシジョンツリー(DT)モデルが最も高い予測信頼度、全体精度、および平均精度を出しているように見えます。ほかのモデルの結果はまちまちです
- リフトタブでは、各モデルのリフト値をグラフィカルに表示します。ランダムケースの場合の赤いラインおよびしきい値のための縦の青いラインがあります
- リフトはモデルテストの一種です。実際に正のターゲット値になるものを「高速に」見つけるための評価基準です
- リフトビューアは、各モデル内の指定されたターゲット値のリフト値を比較します
- リフトビューアでは、累積陽性例と累積リフトの値を表示します
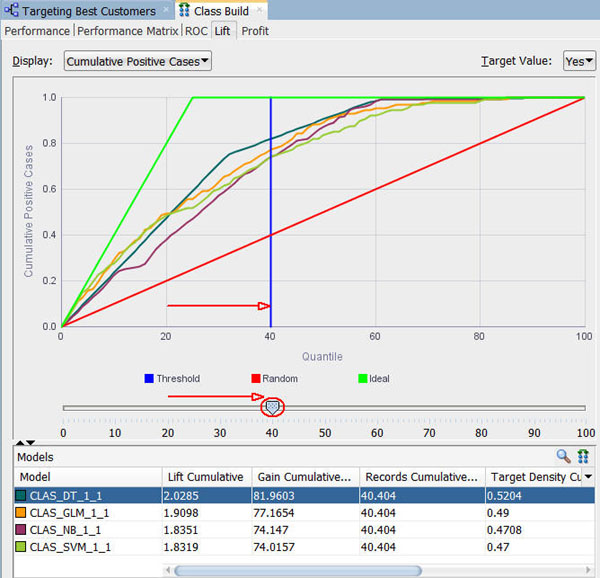
- 分位単位で移動させると、DTモデルの累積リフトおよび累積利益%は以下のように40分位で他のモデルを追い越します
- 50分位以上になると、SVMモデルが停滞しているのに比べ、NBモデルのリフトと利益が増加しているように見えます。しかし、DTモデルは継続的によいリフトと利益の値を出してきています
- サムネイルタブでは、ツリー全体の高レベルなビューを提供しています。たとえば、プライマリ表示ウィンドウ内ではノードをいくつかのみ表示していますが、サムネイルタブでは、このツリーには5つのレベルが含まれることを確認できます
- サムネイルタブのボックスを動かすことでプライマリウィンドウ内のビューを動的に動かすことができます。また、 ディシジョンツリー表示内の別の場所を表示するには、プライマリ表示ウィンドウ内のスクロールバーを使用することができます
- 最後に、表示可能なコンテンツのサイズを増加もしくは減少させるためにプライマリ表示ウィンドウのズーム率を変更できます
- ディシジョンツリーの各レベルには、IF/THEN文で定義されるルールが表示されます。ツリーにレベルが追加されるには、新たな条件がIF/THEN文で追加されることです
- ツリーの各ノードに対して、ボックスに個々のノードについての要約情報が表示されます
- また、以下のように個々のノードを選択すると、IF/THEN文ルールがルールタブに表示されます
- 一般的に、ディシジョンツリー・モデルは非常に大きなレベルのセットを表示し、また、各レベルのノードにさらにツリーが含まれています。しかし、このレッスンのデータセットは通常のデータマイニング のセットよりもとても小さいのでこのディシジョンツリーもとても小さいです
- このレベルは、まずBANK_FUNDS属性で分割し、2番目にCHECKING_AMOUNT属性で分割しています
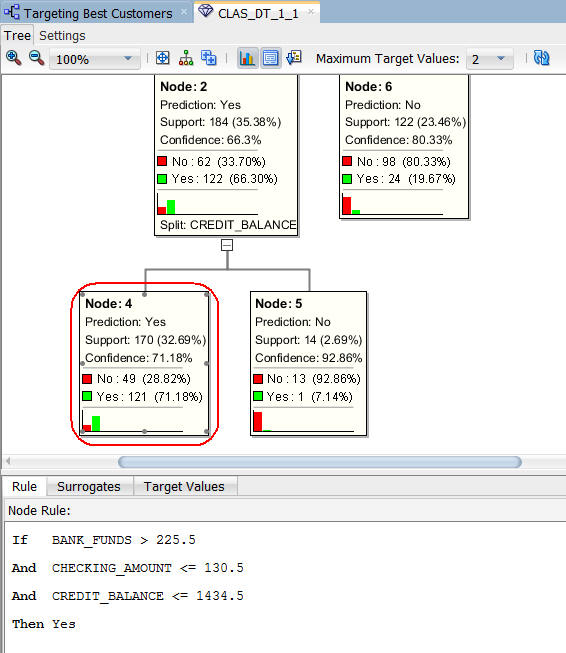
- ノード2は、BANK_FUNDSの値が225.5より大きく、CHECKING_AMOUNTの値が130.5より小さい場合に、66.3%の確率でこの条件の顧客が保険を購入するであろうと予測しています
- Data Miner 4.0を用いると、UIの画像からチャートイメージをコピーして貼り付けることができます。そして、この画像を別の文書にも貼り付けることができます。たとえば、今回はディシジョンツリーのノード2を選択し、クリップボードにコピーします。
- このツリーの下位レベルでは、最終的にはCREDIT_BALANCE属性で分割されます
- このノーd-は、BANK_FUNDSの値が225.5より大きく、CHECKING_AMOUNTの値が130.5に等しく、CREDIT_BALANCEの値が1434.5に等しい場合、71%の確率で顧客が保険を購入することを予測しています
- まず、分類構築ノード内から必要なモデル(複数でも可能)を指定します
- 第二に、ワークフローに新規データソースノードを追加します。(このノードは「適用」するためのデータとします)
- 第三に、ワークフローに「適用」ノードを追加します
- 次に、分類構築ノードと新規データソースノードをそれぞれ適用ノードに接続します
- 最後に、モデルから予測結果を得るために適用ノードを実行します
- 2つめのリンクが完了すると、Apply Modelノードの境界線上の黄色い感嘆符の表示が消えます
- これはノードが実行する準備が出てきていることを示しています
- 予測値(YesまたはNo)
- 予測の確率
- 使用可能な属性リストからCUSTOMER_IDを選択します
- シャトルコントロールを使用して、選択した属性リストに移動します
- 最後にOKをクリックします
- 表には、3つの予測データと顧客ID列の4つの列が含まれます
- 次に示すように、ソートボタンを使用して任意の列を元に表を並べ替えることができます
- ここでは、以下のようにソートされます:
- まず、予測結果値(CLAS_DT_1_1_PRED)を降順で選択します (保険を購入するという予測結果が"Yes"の列が最初にくることを意味します)
- 次に、予測確率(CLAS_DT_1_1_PROB)を降順で選択します(表表示の一番上は予測確率の高いものになることを意味します)
- 適用ノードを実行するたびに、Oracle Data Minerは異なるサンプルをとります。データおよび表の並びは実行のたびに変わる可能性があります。よって、表のサンプルはここで表示しているものと異なる場合があります。データ量が少ないこのレッスンのスキーマの場合、特にこれは明らかです
- フィルタボックスにWHERE句を入力することでデータをフィルタリングできます
- 表の内容は、Oracle Application ExpressやOracle BI Answers、Oracle BI DashboardsなどのOracleの提供するアプリケーションを使用して表示できます
Data Minerワークフローは、データマイニング・プロセスをあらわす接続ノードの集合です
ワークフロー:
Data Minerワークフローには何が含まれる?
視覚的には、以下のようにワークフローウィンドウが表示され、作成使用としているデータマイニング・プロセス・フローのグラフィカルな表現を提供します:
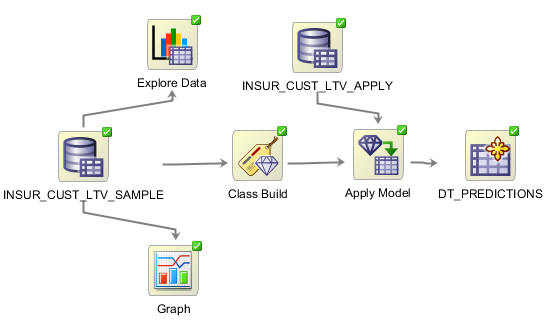
注:
これから学ぶように、任意のノードをワークフローエリアに単にドラッグ&ドロップすることでワークフローに追加できます。各ノードには、デフォルトのプロパティが含まれています。必要に応じてプロパティを変更し、次のステップに進むための準備をします
データマイニングシナリオのサンプル
このトピックでは、保険を購入する可能性が最も高い既存顧客を予測するデータマイニング・プロセスを作成します。
この目標を達成するために、以下を実施してワークフローを構築します:
このプロセスのためのワークフローを作成するには、次の手順を実行します
ワークフローの作成とデータソースの追加
プロジェクト(ABC Insurance)を右クリックし,メニューから、新規ワークフロー を選択します
結果: ワークフローの作成ウィンドウが表示されます
ワークフローの作成ウィンドウで、名前にTargeting Best Customersを入力し、OKをクリックします
結果:
後で見やすいように、ニーズに合わせてSQL Developerウィンドウ内のData Minerタブペインを、開く、閉じる、サイズ変更、および移動することができます
ワークフローの最初の要素はソースデータです。ここでは、ワークフローにデータソースノードを追加し、データソースとして INSUR_CUST_LTV_SAMPLE 表を選択します
A. [コンポーネント]タブで、データ カテゴリをドリルします。. 以下のように、6つのデータノードグループが表示されます:
B. ワークフローペインにデータソース ノードをドラッグ&ドロップします
結果: ワークフローペインにデータソースノードが表示され、データソースの定義ウィザードが開きます
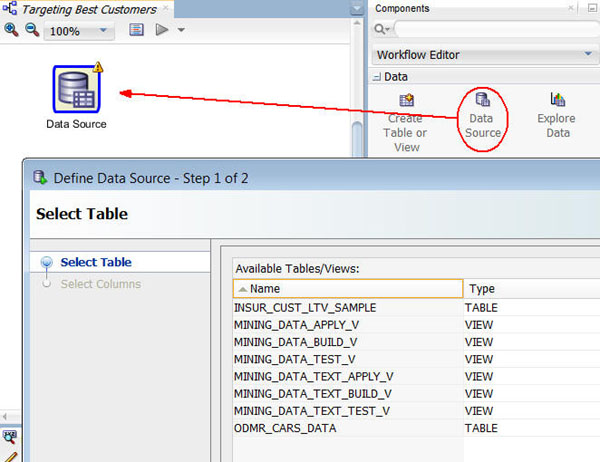
Notes:
ウィザードのステップ1:
A. 以下のように、使用可能な表/ビューリストからINSUR_CUST_LTV_SAMPLE を選択します:
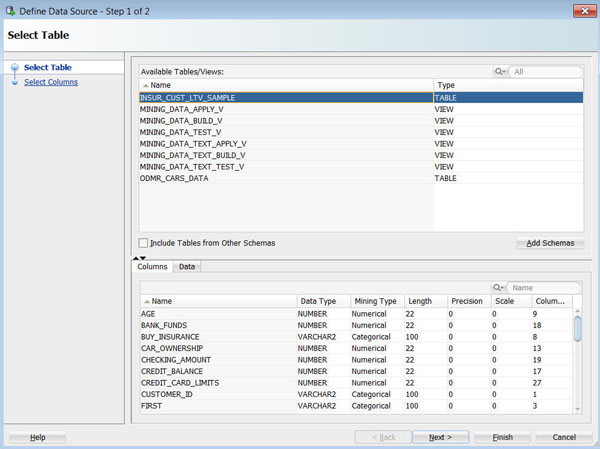
注: ウィザード内の下のペインで選択した表を表示し内容を確認できます。[列]タブには、表構造についての情報が表示され、[データ]タブには、選択した表もしくはビューからデータのサブセットが表示されます。
B. 次をクリックします
ウィザードのステップ2では、データソース内の不必要な列を削除できます。 今回は、表に定義されたすべての属性を残しておきます
ウィザードの下部にある終了をクリックします
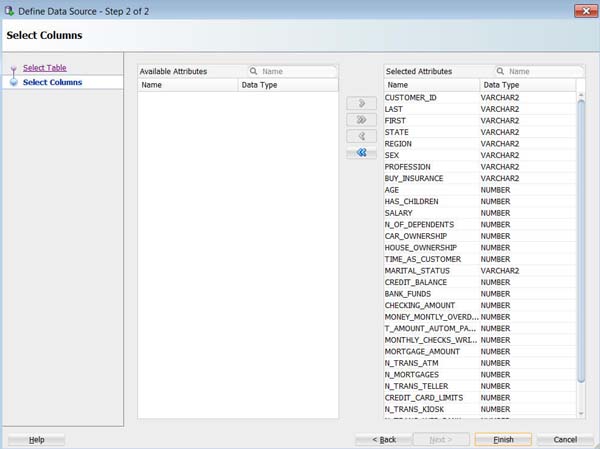
結果: 下に示すように、データソースノード名が選択した表名に更新され、ノードに関連づけられるプロパティが[プロパティ]タブに表示されます
Notes:
ソースデータの分析
ソースデータの分析のためにデータの参照ノードを使います。グラフノードでもデータの可視化は可能です。これらはオプションのステップですが、Oracle Data Minerでは、このツールによって、選択したデータにより定義したビジネス上の課題を解決する基準を満たしているかどうかを確認できます
次の手順に従ってください:
以下のようにデータグループからデータの参照をワークフローにドラッグ&ドロップします:
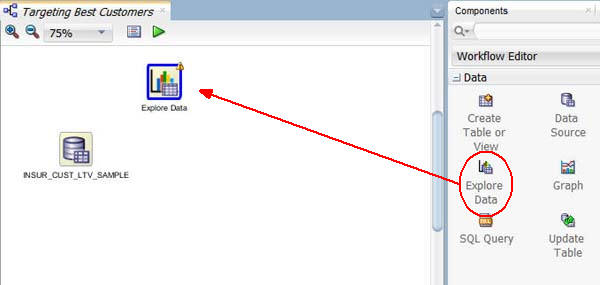
結果: 新たにワークフローペインにデータの参照ノードが表示されます
注:
データソースとデータ参照ノードを接続するために以下の手順を行います:
A. データソースノード(INSUR_CUST_LTV_SAMPLE)を右クリックし、ポップアップメニューから接続を選択し、ポインタをデータの参照ノードにドラッグします:
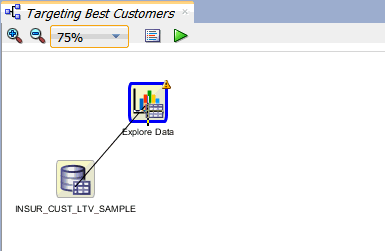
B. 次に、データの参照 ノードをクリックし2つのノードを接続します。結果、表示はこのようになります:
次に、データソースの「グループ化基準」を選択します
A. データの参照ノードをダブルクリックし、データの参照ノードの編集ウィンドウを表示します
B. グループ化基準リストから、以下のようにBUY_INSURANCE 属性を選択します:
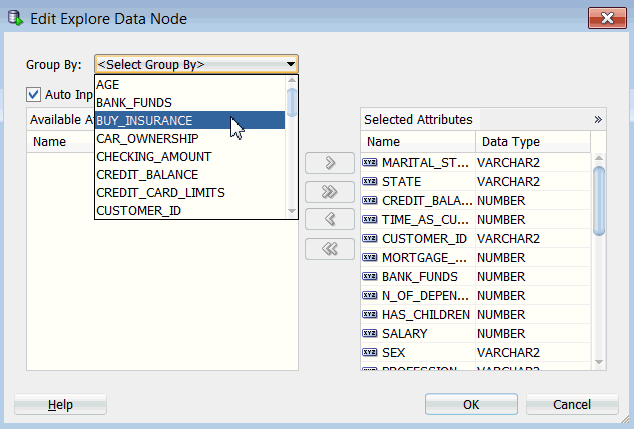
C. 次にOKをクリックします
注: 選択した属性ウィンドウでは、ソースデータから任意の属性を削除(または再追加)することができます
次にデータ参照ノードを右クリックし[実行]を選択します
結果:
注: ワークフローキャンパスから任意の処理を実行すると、指定した手順はOracle Daya Minerサーバによって実行されています
データの参照ノードの結果を確認するには、次の手順を実行します:
A.データの参照ノードを右クリックし、メニューからデータの表示を選択します
結果: 以下のようにデータの参照ノードのための新たなタブが開きます
注:
B. [名前]リストから属性を選択すると、下のウィンドウに関連するヒストグラムが表示されます
C. ソースデータの分析を実施したら、クローズアイコン(X)をクリックしてデータの参照タブを閉じます
次に、グラフノードを使用してさらにデータを可視化します
以下のように、データグループからグラフノードをワークフローにドラッグ&ドロップします:
結果: ワークフローペインに新たにグラフノードが表示されます。前に見たように、黄色い情報アイコン(!)が表示され設定が完全ではないことを示しています
データソースノードにグラフノードを接続するには、以下の手順を使用します:
A. データソースノード(INSUR_CUST_LTV_SAMPLE)を右クリックし、ポップアップメニューから接続 を選択し、グラフノードにポインタをドラッグします
B. 次に、2つのノードを接続するためにグラフノードをクリックします。以下のように結果が表示されます:
次に、グラフノードを右クリックし、メニューから編集をクリックします
結果: 次の情報ダイアログが表示されます
はい をクリックし、ノードを実行しサンプルを生成します
結果:処理が終了すると、ワークフローは以下のようになります:
ここで、新規グラフウィンドウを表示するためにグラフノードをダブルクリックします。以下の属性を設定します:
A. 上部のHistogram ボタンをクリックし、グラフタイプを選択します
B. Titleボックスで、 Histogram of AGE Grouped by LTVと入力します
C. ヒストグラムの設定エリアで属性の値にAGE を選択します
D. 次に、グループ化基準オプションを有効にします
E. グループ化基準オプションの属性に、LTV_BINを選択します
新たなグラフウィンドウは以下のように設定します:
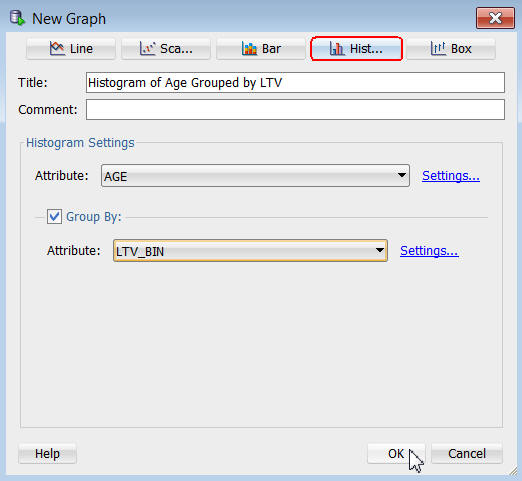
F. OKをクリックします
結果: 以下のようなグラフが表示されます:
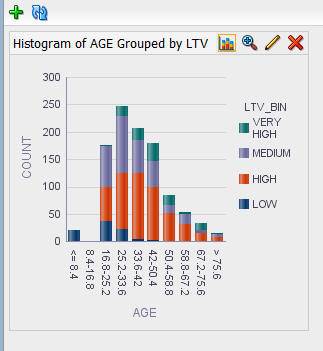
G. オプションで、以下のようにグラフをフルウィンドウで表示するにはズームインツールを選択します:
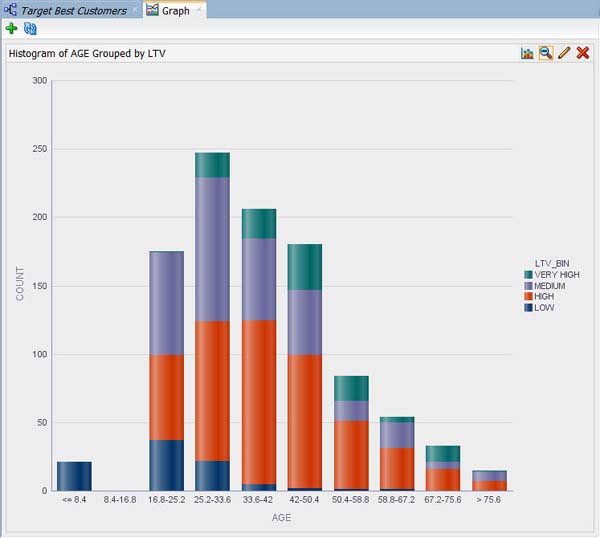
注: 単にズームアウトツール(ズームインツールを切替)をクリックするとオリジナルサイズに戻ります
以下のように、新規グラフツール(緑の"+"アイコン)をクリックするだけで、1つのノード内に追加のグラフを作成できます:
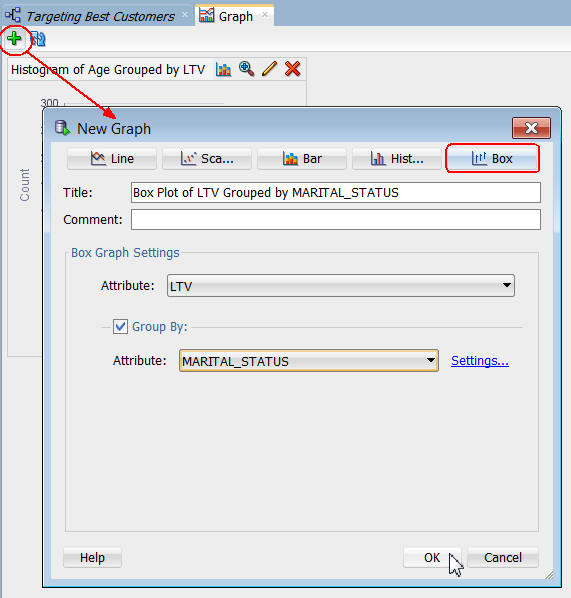
注: MARITAL_STATUSでグループ化したLTV(ライフタイムバリュー)のボックスグラフを作成します。以下のような結果が表示されます:
グラフノードで分析を実施したら、以下のようにクローズアイコン(X)をクリックしてグラフタブを閉じます:
次に、データベースのデータマイニングのパワーを使用して、高レベル分析の演習を実施します
分類モデルの作成
このチュートリアルの概要セクションで、個人の行動の予測には分類モデルを使うことを紹介しています。このシナリオでは、あなたは保険を購入してくれそうな顧客を予測したいとします。したがって、今回は分類モデルを用います。
Oracle Data Minerでは、分類モデルを作成するとアルゴリズムの異なる4つのモデルが作成されます。分類ノード内のもでるはすべて同じターゲットとケースIDを持ちます。このデフォルトの構成は、最良の予測をするアルゴリズムの発見が容易にできます。ここでは、すべてのアルゴリズムを使用して分類ノードを定義します。
では、次のトピックでは各モデルを実行し検証します。
デフォルトの分類モデルを作成するには、次の手順を実行します:
A. はじめに[コンポーネント]で、データカテゴリを折りたたみ、モデル カテゴリを展開します:
B. 次に、[コンポーネントタブから]分類ノードをワークフローペインにドラッグ&ドロップします:
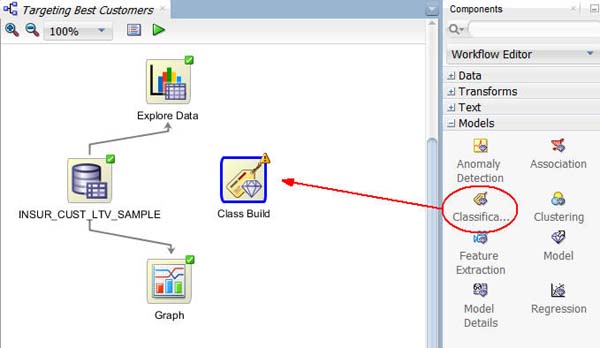
結果: 「分類構築」という名前のノードがワークフローに表示されます:
注:
まず、先に説明したのと同じように、分類構築ノードにデータソースノードを接続します
結果: 分類ビルド・ノードの編集ウィンドウが表示されます
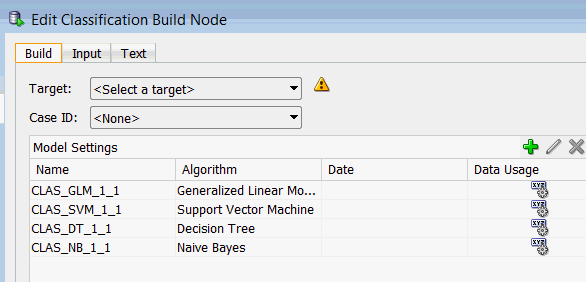
注:
分類ビルド・ノードの編集ウィンドウでは:
A. ターゲット属性としてBUY_INSURANCEを選択します
B. ケースID属性としてCUSTOMER_ID を選択します
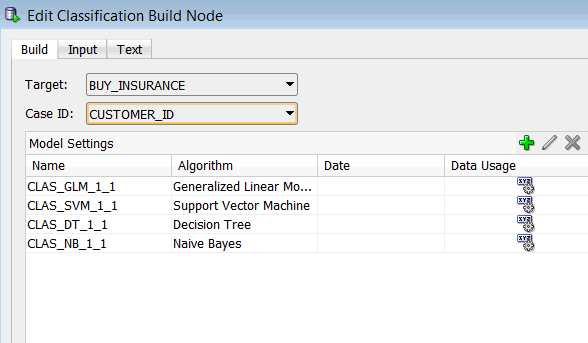
注:
オプションで、任意のアルゴリズムをダブルクリックして、リストされているアルゴリズムの特定の設定を変更できます
A. 例えば以下のように、最初のアルゴリズムをダブルクリックして、詳細モデル設定ウィンドウを表示します:
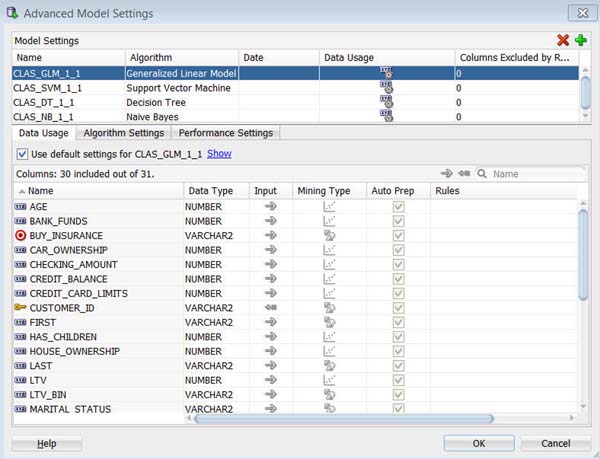
注:
B. Support Vector Machineアルゴリズムを選択し、アルゴリズム設定タブをクリックします
C. 次に、以下のように、カーネル・ファンクションオプションで線形を選択します:
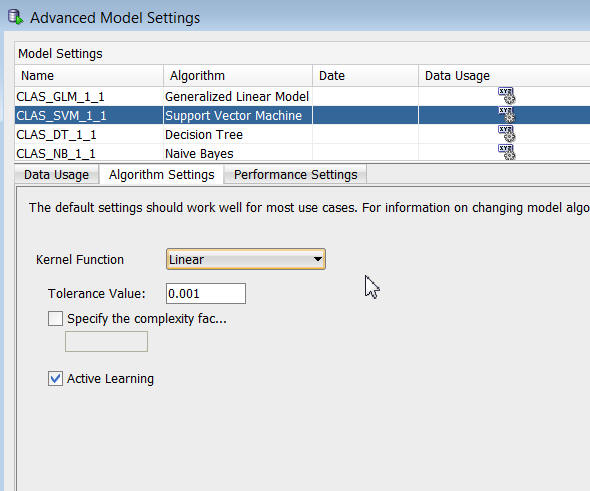
注: モデルの結果をわかりやすく解釈するために、Support Vector Machine (SVM)アルゴリズムのデフォルトの設定であるシステム決定から線形に値を変更しています
D. 各アルゴリズムのほかのタブも気軽に確認してください。しかし、ほかの設定はデフォルトから変更しないでください
E. 確認し終わったら、OKをクリックしSVMアルゴリズムの設定を保存し、詳細モデル設定ウィンドウを閉じます
最後に、分類ビルド・ノードの編集ウィンドウでOKをクリックし、変更を保存します
結果: 分類構築ノードを実行する準備が整いました
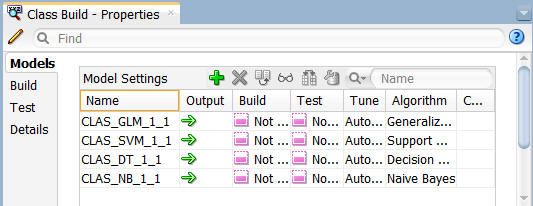
注: プロパティタブのモデルセクションでは、以下のように各線託したアルゴリズムの現在のステータスを参照できます:
メインツールバーですべて保存をクリックしワークフローを保存します

モデルの構築
このトピックでは、ソースデータを元に選択したモデルを構築します。この操作は「トレーニング」と呼ばれ、このモデルはトレーニングデータから実行するときには「学習」と呼ばれます。
一般的なデータマイニングの実践構築(トレーニング)はソースデータの一部に対して行われ、その後、データの残りの部分に対してモデルをテストします。デフォルトでOracle Data Minerは、40/60に分割したデータを用いたアプローチを用います
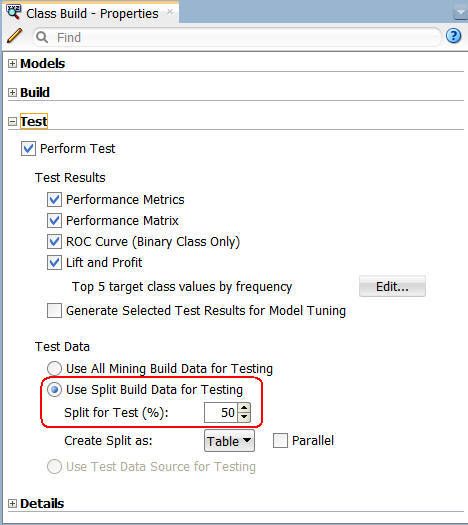
モデルを構築する前に、分類構築ノードを選択し、プロパティタブからテストセクションを選択します。テストセクションでは以下を指定することができます:
テストデータエリアでは以下のように値を50に変更してテストデータの分割を50/50に指定します
次に、モデルを構築します
分類構築ノードを右クリックし、ポップアップメニューから実行を選択します
注:
構築が完了すると、すべてのノードの境界線に緑のチェックが表示されます
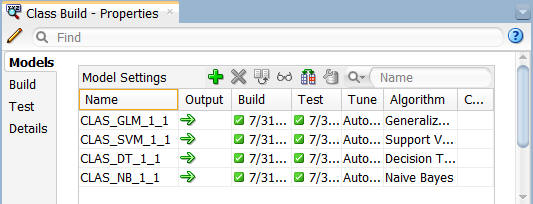
また、プロパティ・インスペクタを使用して構築についての情報を確認することができます
ワークフローで分類構築ノードを選択し、プロパティタブでモデルセクションを選択します
注:
モデルの比較
選択したモデルを構築・トレーニングした後、比較フォーマットで表示してすべてのモデル結果を評価できます。ここでは、4つのすべての分類モデル結果を相対的に比較します。
次の手順に従います:
分類構築ノードを右クリックし、メニューからテスト結果の比較を選択します
結果: 分類構築タブが新たに開き、パフォーマンスタブでは、以下のように4つのモデルの比較情報が表示されます:
注:
サンプルデータが非常に小さいので、ここで得られる数値はチュートリアルで示すものとは多少異なる場合があります。また、ヒストグラムの色はこの例に示したものと異なっていてもかまいません
リフトタブを選択します。そして、グラフ上部右のターゲット値をYesに変更します
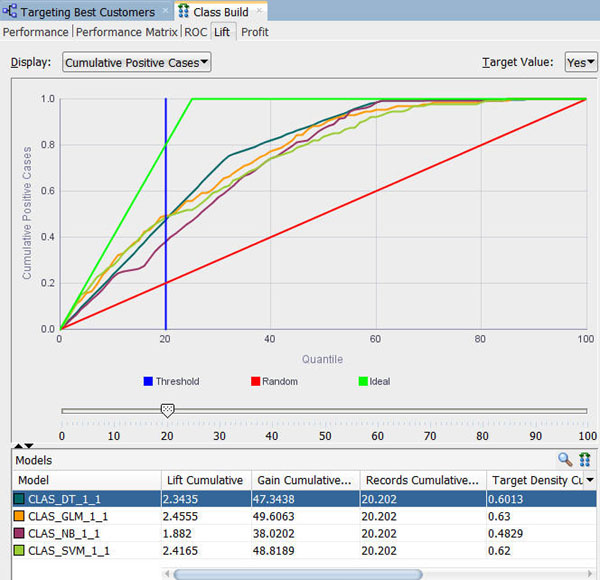
注:
上記の例では、20分位でDT、一般化線形モデル(GLM)、およびSupport Vector Machine (SVM)のモデルは、累積リフトと累積利益%の値はとても近いものを示しています
リフトタブで、以下のようにスライダツールを用いて、グラフのX軸に沿って分位の測定ラインを移動させることができます。左右に移動させるとモデル内のデータは自動的に更新されます。以下のイメージを参考にしてください
次に、パフォーマンス・マトリックスタブを選択します
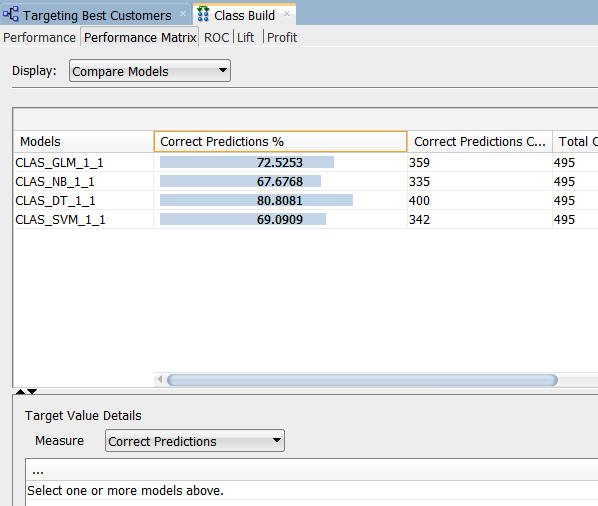
注: パフォーマンス・マトリックスでは、DTモデルの正しい予測%の値がほぼ81%に達していて、最も高い値をだしています。次点のGLMは72.5%です
GLMとDTモデルの詳細を比較しましょう
まず、モデルのターゲット値の詳細を表示するためにをGLMモデルを選択します。各モデルの「ターゲット値」はBUY_INSURANCE属性であることを思い出してください
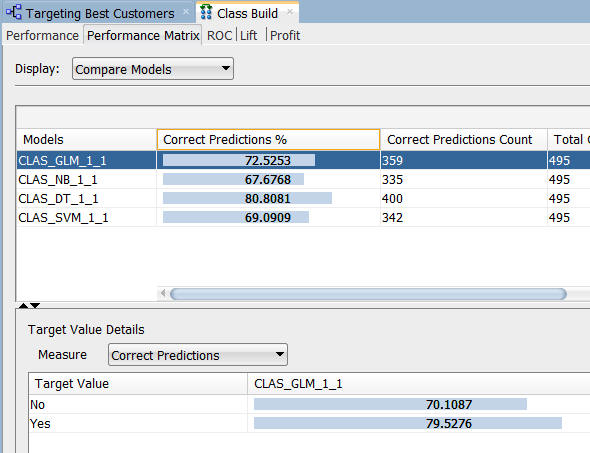
注: GLMモデルは、保険を購入するという顧客に関して70%の正しい予測を返し、買わないという顧客については79.5%の正しい予測をしています
次に、DTモデルを選択します
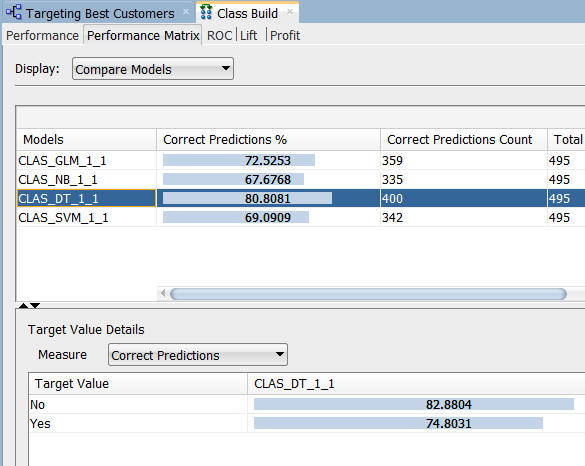
注: DTモデルでは、保険を購入する顧客についての予測は82.9%、購入しない顧客に関しては74.8%の正しい予測をしています
初回の分析をした結果、より深くディシジョンツリー・モデルを検証することにします。分類構築タブウィンドウを閉じます
特定のモデルの選択と検証
前野トピックで実行された分析により、ディシジョンツリー・モデルを以降の分析で用いることにします
ディシジョンツリー・モデルを検証するために次の手順を実行します
ワークフローペインに戻り、再び分類構築ノードを右クリックし、モデルの表示> CLAS_DT_1_1 を選択します。(注: ディシジョンツリー・モデルの名前が異なることがあります)
結果: ウィンドウが開き、ディシジョンツリーがグラフィカルに表示されます
このインタフェースは、いくつかのナビゲーション表示機能が提供されています:
たとえば、ディシジョンツリー表示ウィンドウで100%ズームに設定します
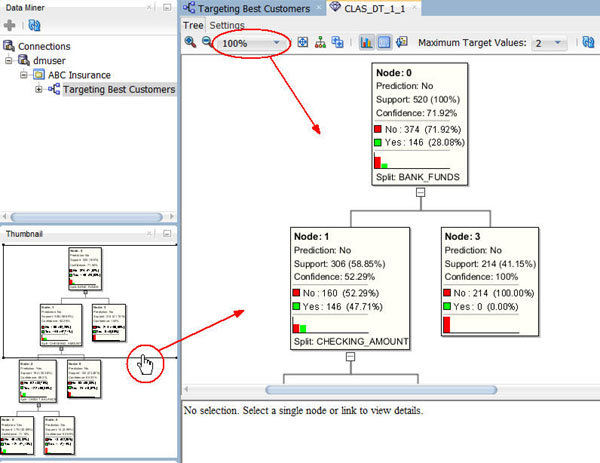
まず、移動してノード 2を選択します
注:
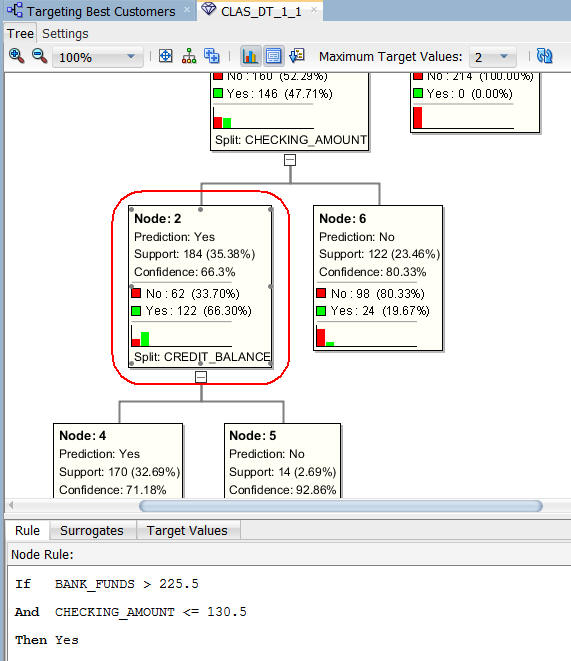
注:
次に、ツリーのレベルの下方のノード4を選択します
注:
以下にあるように、ディシジョンツリーの表示タブを閉じます:
モデルの適用
このトピックでは、ディシジョンツリー・モデルを適用し、結果表示用の表を作成します。モデルを「適用」し、保険を購入する可能性がある顧客を予測します。.
モデルを適用するには,次の手順を実行します:
モデルを適用し、結果を表示するには、以下の手順を実行します:
ワークフロー上で、分類構築ノードを選択します。次に、[プロパティ]タブからモデルセクションを表示し、DTモデル以外のモデルの選択を解除します.
モデルの選択を解除するには、各モデルの出力列にある大きな緑色の矢印をクリックします。この動作により列に小さな赤い"x"が追加され、次に構築では使用されないことを示します
作業が終了したら、プロパティタブのモデルタブは以下のように表示されます:
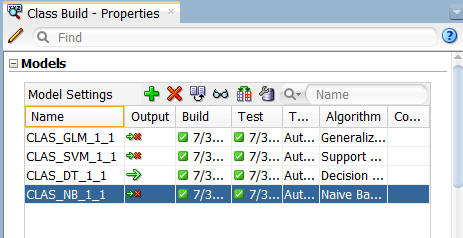
注: この場合、DTモデルだけが後続のノードに処理が渡されます
次に、ワークフローに新たなデータソースノードを追加します。 注: 「適用」用のデータソースとして同じ表を使う場合であっても、ワークフローに2番目のデータソースノードを追加する必要があります
A. 以下のように、[コンポーネント]タブの[データ]カテゴリからワークフローキャンバスに、データソースノードをドラッグ&ドロップします。自動的にデータ・ソースの定義ウィザードが開きます
B. データ・ソースの定義ウィザードで、NSUR_CUST_LTV_SAMPLE 表を選択し終了をクリックします
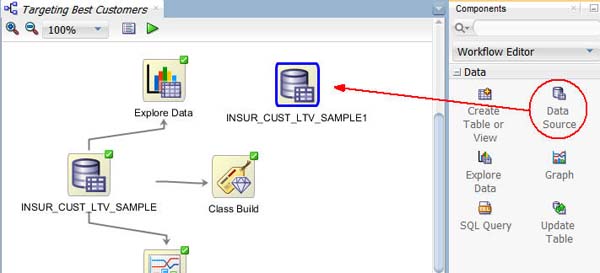
結果: INSUR_CUST_LTV_SAMPLE1という名前の新規データソースノードが、ワークフローキャンバスに表示されます
新しいデータソースノードを選択し、プロパティタブの詳細セクションを使って,以下のようにノード名をINSUR_CUST_LTV_APPLYに変更します:
結果: 新規表名がワークフロー上にも反映されます
次に、コンポーネントタブ内の評価と適用カテゴリを展開します
以下のように、適用ノードをワークフローキャンバスにドラッグ&ドロップします:
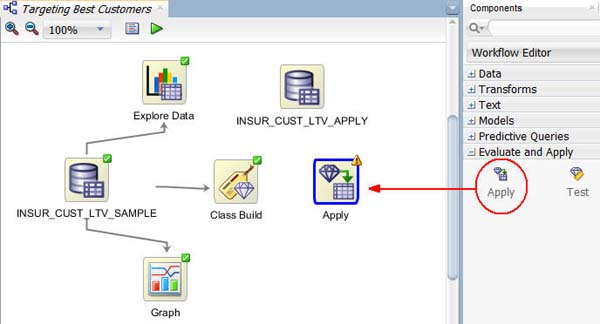
注: ノードの境界線上の感嘆符は、適用ノードが実行される前に多くの情報が必要であることを示します
プロパティ・インスペクタの詳細タブを用いて、適用ノードの名前をApply Modelに変更します
以下に記載されている方法で、分類構築ノードをApply Modelノードに接続します
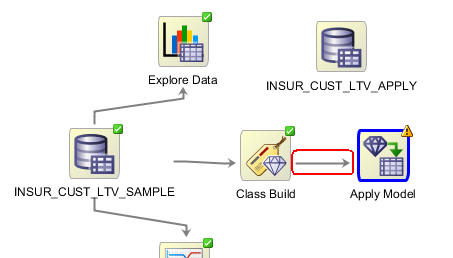
次に、INSUR_CUST_LTV_APPLY ノードをApply Modelノードに接続します:
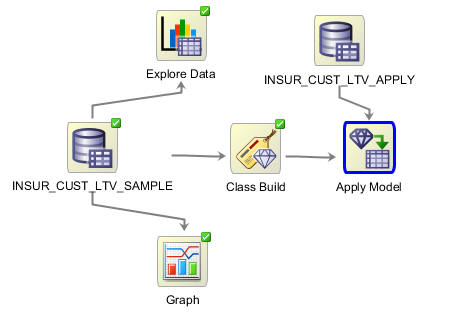
注:
適用するモデルノードを実行する前に、結果のアウトプットについて検討します。デフォルトでは、各顧客のための情報のための2つの列を作詞します:
しかし、本当に特定の顧客と予測された情報を関連づけることができるように、各顧客の情報を理解してください
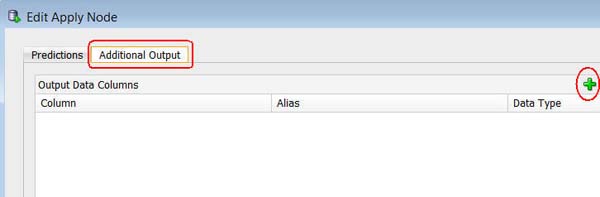
この情報を取得するには、適用されたアウトプットに3つめの列:CUSTOMER_IDを追加する必要があります。アウトプットに顧客IDを追加するには次の手順に従います:
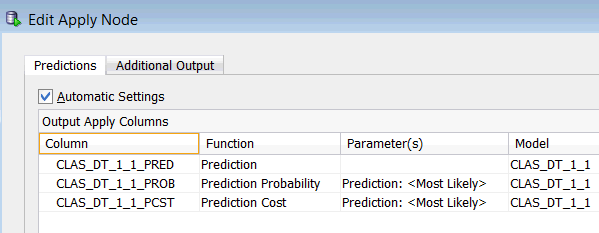
A. Apply Modelノードを右クリックし、編集をクリックします
結果: 適用ノードの編集ウィンドウが表示されます。予測、予測確率および予測コストの列が予測タブに自動的に追加定義されています。
B. 追加出力タブを選択し、以下のように緑の"+"ボタンをクリックします:
C. 出力データ列の編集ダイアログが表示されます:
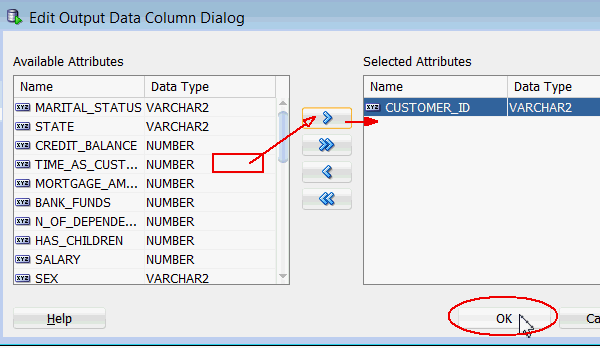
結果: 以下に表示されているように、CUSTOMER_ID列が追加出力タブに追加されています:
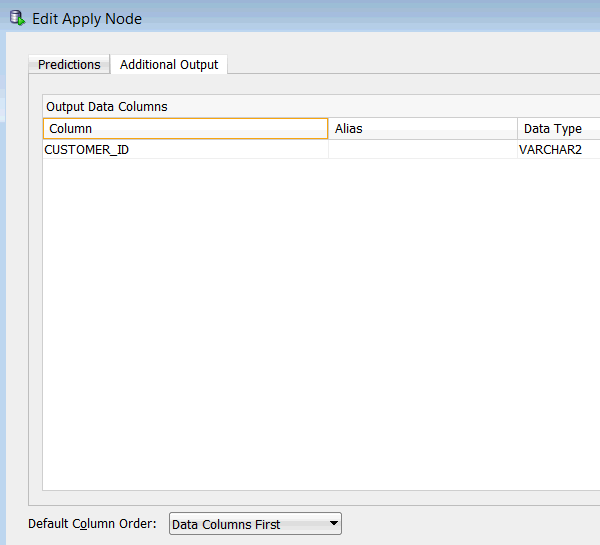
また、デフォルト列順序がデータ列が先に設定されており、適用列が後に配置されます。希望する場合、この順序を切り替えることができます
D. 最後に、変更を適用するために適用ノードの編集ウィンドウでOKをクリックします
これで、モデルを適用する準備ができました。Apply Modelノードを右クリックしメニューから実行を選択します
結果:前と同様、ワークフロードキュメントが自動的に保存され、実行中は小さな歯車アイコンがそれぞれのノードに表示されます。また、実行ステータスはワークフローペインの上部に表示されています
処理が完了すると、サーバプロセスが正常に完了したことを示すために、すべてのワークフローノードに緑のチェックマークアイコンが表示されます
必要に応じて、モデルの予測結果(「適用」の結果)を格納するデータベース表に作成することができます
この表は任意の目的に利用できます。たとえば、アプリケーションにこの表から予測値を組み込むことができ、顧客への割引レター等やその他の適切なアクションのための示唆を与えてくれます
モデルの予測結果の表を作成するには、次の手順を実行視します:
A. 以下のようにコンポーネントペインのデータカテゴリから、表またはビューの作成をワークフローウィンドウにドロップします:
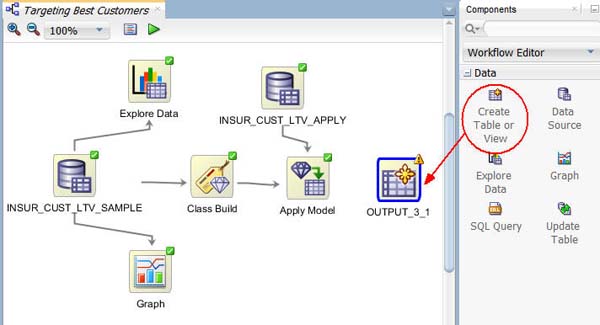
結果: OUTPUTノードが作成されます (OUTPUTノードの名前は以下の例とは異なる場合があります)
B. Apply Model ノードをOUTPUTノードに接続します
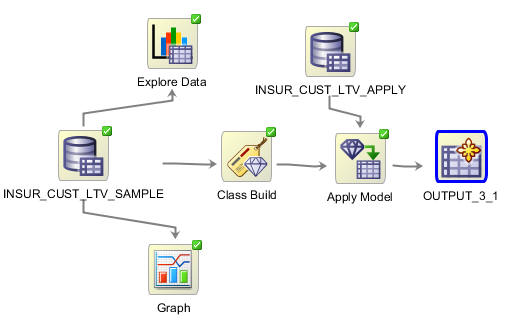
C. 作成される表の名前を指定するには以下の手順を実行します (そうしないと、Data Minerはデフォルトの名前で表を作成します:
1. OUTPUTノードを右クリックし、メニューから編集を選択します
2. 表またはビュー作成ノードの編集ウィンドウで、以下のようにデフォルトの表名からDT_PREDICTIONSに名前を変更します:
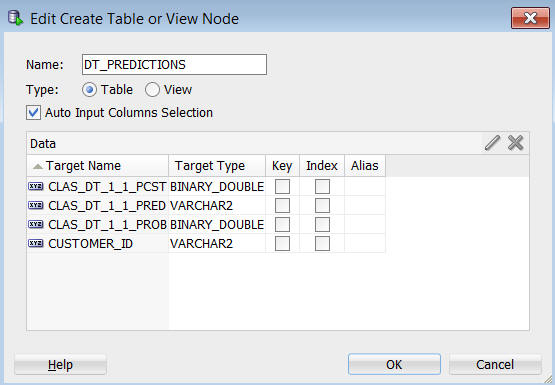
3. 次にOKをクリックします
D. 最後に、DT_PREDICTIONSノードを右クリックし、メニューから実行を選択します
結果: プロセスが実行されると、ワークフロードキュメントが自動的に保存されます。完了すると、すべてのノードに以下のように緑のチェックマークがつきます:
注: アウトプットノード(DT_PREDICTIONS)を実行すると、スキーマ内に表が作成されます
結果を表示するには:
A. DT_PREDICTIONS表ノードを右クリックし、メニューからデータの表示を選択します
結果: 新しいタブに表の内容が表示されます:
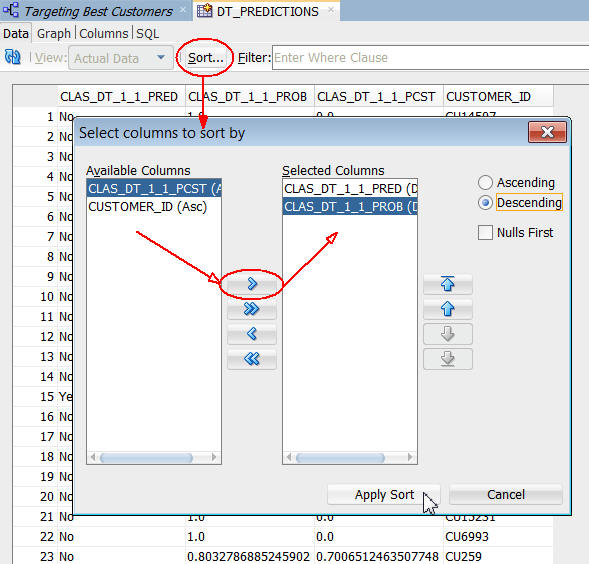
B. ソートの適用をクリックし、結果を表示します:
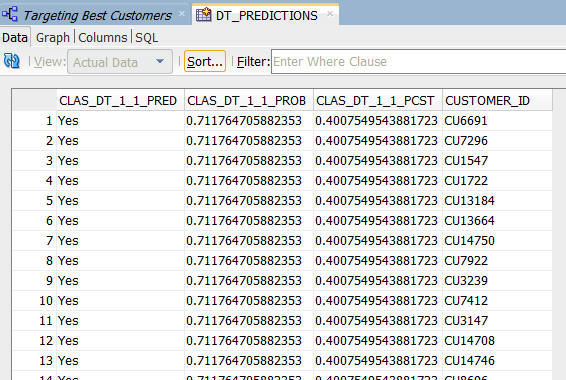
注:
C. 結果表示を確認し、DT_PREDICTIONS表のタブを閉じ、すべて保存をクリックします
まとめ
- Data Minerインタフェースコンポーネントについて
- Data Minerプロジェクトの作成
- 顧客の行動を予測するために分類モデルを使ったワークフロードキュメントの構築
- OTNのOracle Data MiningおよびOracle Advanced Analyticsのページ
- Oracle Learning Libraryにある他のOBE
- Data Mining概要マニュアル:
このレッスンでは、SQL Developer 4.0に含まれるグラフィカルユーザインタフェースOracle Data Minerを使って、「分類」予測データマイニングをIを作成しビジネス課題を検証・解決しました
このチュートリアルでは、以下のことを学びました:
リソース
Oracle Data Miningについて詳しくは:
謝辞
主なカリキュラム開発者: Brian Pottle
他の貢献者: Charlie Berger, Mark Kelly, Margaret Taft, Kathy Talyor
To help navigate this Oracle by Example, note the following:
- Hiding Header Buttons:
- Click the Title to hide the buttons in the header. To show the buttons again, simply click the Title again.
- Topic List Button:
- A list of all the topics. Click one of the topics to navigate to that section.
- Expand/Collapse All Topics:
- To show/hide all the detail for all the sections. By default, all topics are collapsed
- Show/Hide All Images:
- To show/hide all the screenshots. By default, all images are displayed.
- Print:
- To print the content. The content currently displayed or hidden will be printed.
To navigate to a particular section in this tutorial, select the topic from the list.