Develop C and C++ Applications with Oracle Database 11g Using Pro*C
Purpose
In this tutorial, you analyze and execute C programs in several stages to learn about the features and functionality of Pro*C.
You learn how to create and use reports (ADDM reports - Automatic Database Diagnostic Monitor and AWR reports - Automatic Workload Repository) to analyze the performance and bottleneck of a sample application. As the reports are run, you analyze and refine the sample in several stages. The end result is an efficient application.
Time to Complete
Approximately 60 minutes.
Prerequisites
Before you perform this tutorial, you should:
| 1. | Install Oracle Database 11g Release 2 (if not already present) |
|
| 2. | Install the Pro*C precompiler. |
|
| 3. | Download and unzip the proclab.zip file into your working directory (i.e./home/oci/proclab ) |
|
Overview
In this tutorial you use a step by step approach to run and tune the application in several stages. Starting with non-optimized code, each stage adds up to this non-optimized stage showing the performance improvement by using features like statement caching, client side result set caching, etc. A few stages show specific features like LOB handling, and fetching through a ref-cursor.
The AWR and ADDM Reports
Automatic Workload Repository (AWR) is a built-in repository in every Oracle Database. At regular intervals, the Oracle Database makes a snapshot of all its important statistics and workload information and stores in AWR.
The Automatic Database Diagnostic Monitor (ADDM) enables the Oracle Database to diagnose its own performance and determine how identified problems could be resolved. It runs automatically after each AWR statistics capture, making the performance diagnostic data readily available.
To run the reports, you can use the reports.sql script provided with this tutorial. For each of the stages that you want to examine, the executable generated from corresponding pc file is provided to the script (reports.sql) with a few additional parameters.
Developing C Application with the Pro*C Drivers
Pro*C Overview
For the Pro*C analysis, the source code files are as named stage1.pc, stage2.pc, stage3.pc, stage4.pc, stage5.pc, stage6.pc, and stage7.pc, with a common library file named helper.pc that is used for all of the stages shown. These files are stored in the /home/oci/proclab location.
In this section of the tutorial, you examine seven stages of a Pro*C application. Some of the stages (stage3, stage4, stage5) focus on performance tuning, while others focus on illustrating a specific feature (stage2, stage6, stage7). By generating the ADDM and AWR reports on the sample applications, you analyze performance and bottlenecks.
The Sample Pro*C Application
The following objects are defined within the prochol schema:
The MYEMP table is defined as:
CREATE TABLE myemp ( empno number(4) primary key, ename varchar2(10), job varchar2(9), mgr number(4), hiredate date, sal number(7,2), comm number(7,2), deptno number(2)) ;
To demonstrate the LOB features, the following table is defined:
CREATE TABLE lob_table(
article_no number(5),
article_nm varchar2(50),
article_text clob,
comments clob)
LOB(article_text) STORE AS SECUREFILE (TABLESPACE SYSAUX
COMPRESS low CACHE),
LOB(comments) STORE AS SECUREFILE (TABLESPACE SYSAUX
COMPRESS low CACHE)
;
The following three procedures are used in the Pro*C application:
- update_salary() is used to perform DML
- query_salary() is used for single row queries
- multirow_fetch() is used for multiple row fetches
The main C functions are:
- For multithreaded demos: main()=>thread_function()=>do_workload()
- Random Input to simulate input: random_input()
To compile and link all of the stages of the source code, you can use the make utility.
Stage 1: Setting Up
In this section, no optimizations are performed. The main thread performs the following initializations:
- Parses the command line options and setting the global flags (variables) accordingly
- Notes the time counts to calculate the total time taken by the process/application
- Creates the default run time context and connection
After initialization is complete the main thread spawns a configurable (-t option) number of child threads. The function thread_function() serves as the starting point for each child thread. Each child thread does the following:
- Allocates its own run time context.
- Creates its own connection using its run time context.
- Calls the workload function named do_workload(), a configurable (-i option) number of times. The workload function calls the following functions:
- query_salary(): Fetches a single row from a cursor.
- multirow_fetch(): Fetches multiple rows from a cursor.
- update_salary(): Updates the sal column in a loop.
After each child thread complete its workload, the main thread joins the child threads, then calculates and prints the performance statistics for each query and the total time take by the application.
|
. |
Open a terminal window. Change to your /home/oci/proclab directory and start SQL*Plus. Logon as system. Use the password "manager".
Examine the contents for the stage1.pc file. You can use a text editor to view the contents.
Note: If you are working in a Linux environment, you may need to change the permission to execute the stagen files. To do so, execute the following at the command prompt: chmod 777 stage* exit |
|---|---|
| . |
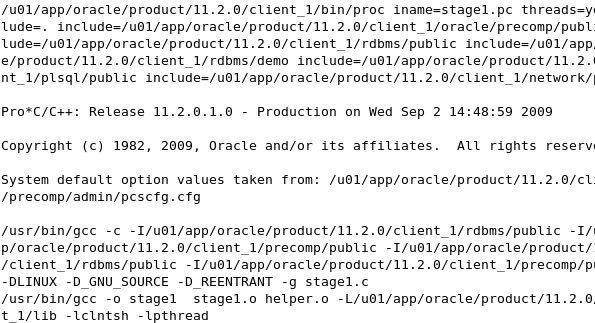
Use the gmake utility to build the executable C programs and library for the source code for stage1. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage1
|
| . |
The reports.sql script is stored in the $HOME/oci/proclab/sql directory. In a new terminal session, change to the $HOME/oci/proclab/sql directory. cd $HOME/oci/proclab/sql Start SQL*Plus. In your SQL*Plus session, run the reports.sql script. Pass to it the stage1 file. Add the parameter to iterate 10 times to increase the workload and generate findings, set the number of threads to 30. (Note: we have purposefully set the number of iterations to a low value of 10 to save time in this exercise. For the pre-canned reports generated for this stage, the number of iterations was set to 500.) @reports.sql "../stage1 -i 10 -t 30"
As the report runs, you are shown the percentage completed.
|
| . |
When prompted for the report name, enter:
stage1_proc
This generates two reports which are saved in the current directory:
Generated sample results are provided to you for each stage. These files are located in the /home/oci/proclab/doc sub-folder. . The names of the sample results files are:
Note: Your results may differ from the sample results provided due to environment differences. For consistency in this tutorial, the generated sample results are examined.
|
| . |
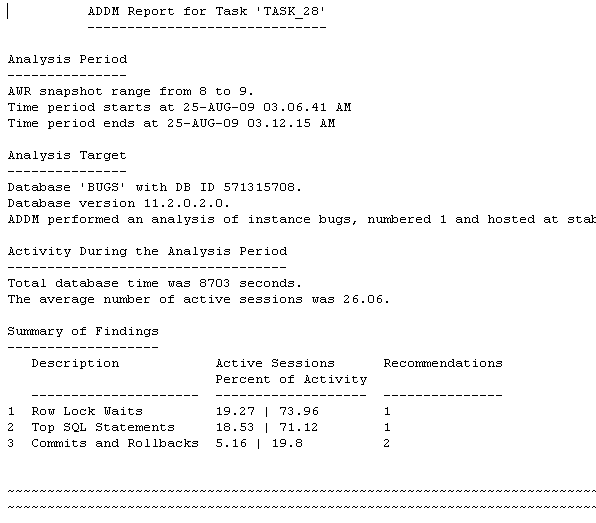
Examine the contents in the stage1_results.txt report. (You can either open the file in a text editor, or you can scroll up in your SQL*Plus session.)
Note the summary of findings.
|
| . |
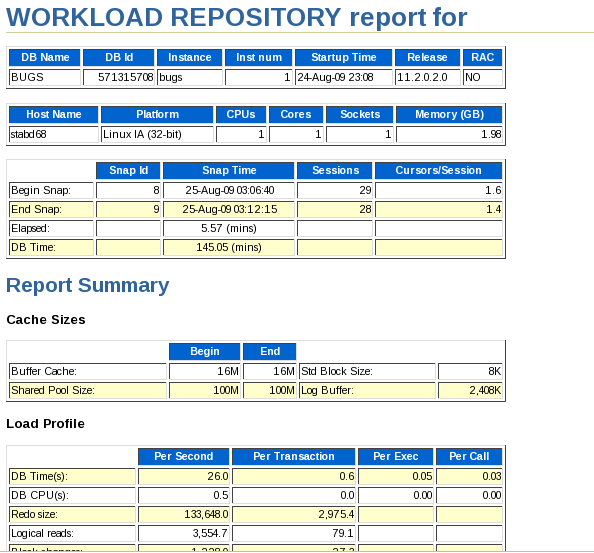
Examine the contents in the stage1_results_awr.htm report. Find the file stage1_results_awr.htm. Double-click the file name to open the file in a browser (or right-click and select the Open with "Web-Browser" option).
Review the report .
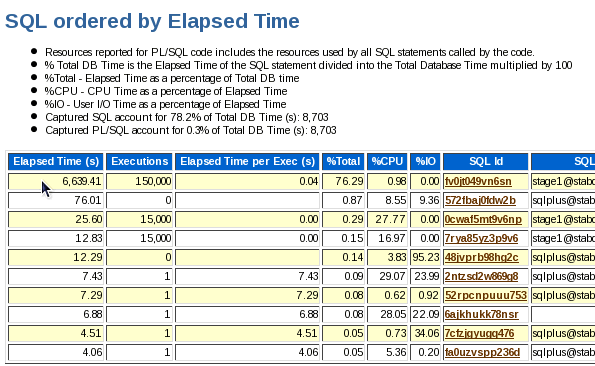
Scroll down to the Main Report. Click the SQL Statistics link.
Note the Elapsed time statistics. As you go through each of the stages and apply different tuning methods, these numbers will change (and improve).
|




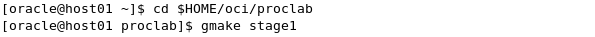
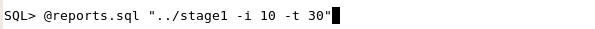





Stage 2: Using Array-DML Fetch
In this section, the C code is optimized for array fetch It also demonstrates the usage of scrollable cursors. In this stage the multi-row fetch is performed using an array, which can hold ARRAY_LENGTH number of rows for each fetch. Except for the multirow_fetch() function, the rest of the code is the same as stage1 code.
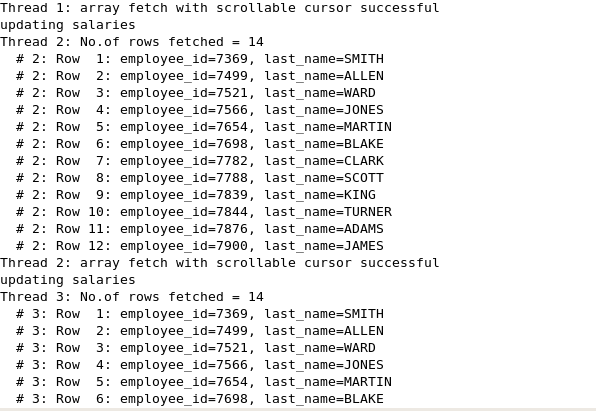
The multirow_fetch() function fetches chunks of ARRAY_LENGTH (defined in this function itself) number of rows in a loop of FETCH_LOOP count. In the program ARRAY_LENGTH, it is set to 3, meaning that program fetches 3 rows at a time. For the first loop it would fetch first 3 rows, for the second loop next 3 rows are fetched, and so on until the FETCH_LOOP count is hit.
We fetch chunks of ARRAY_LENGTH number of rows from an absolute row number. For completeness, we fetch all the rows in sequence in this demonstration. But in general, a scrollable cursor is capable of fetching any number of rows starting from any particular row number within the result set.
|
. |
Examine the contents for the stage2.pc
file.
Locate the stage2.pc file in the /home/oci/proclab directory.
Right click on the stage2.pc file and select the Open with "Text Editor" option.
In stage2.pc array DML fetch and usage of scrollable cursor options is used.
|
|---|---|
. |
Use the gmake utility to build the executable C programs and library for the source code for stage2. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage2
|
. |
In a terminal window, execute the stage2 file. Include the switches of iterate for 5, threads 5 and specify verbose to print the detailed information. ./stage2 -i 5 -t 5 -v
|







Stage 3: Connection Pooling Enabled
In this section, you enable connection pooling. This is achieved by using these precompile time options:
- cpool=yes
- cmin=5 is the minimum number of physical connection to be created at the time of connection pooling creation
- cmax=10 is the maximum number of physical connection that are allowed in a pool
- cincr=1 is the umber of physical connections that to be increased by
|
. |
Examine the contents of the stage3.pc file located in the cd $HOME/oci/proclab directory. You can use a text editor to view the contents.
|
|---|---|
|
. |
Use the gmake utility to build the executable C programs and library for the source code for stage3. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage3
|
|
. |
In your SQL*Plus session, run the reports.sql script. Pass to it the stage3 file. Add the parameters to iterate 500 times to increase the workload and generate findings, set the number of threads to 30. @reports.sql "../stage3 -i 500 -t 30"
As the report runs, you are shown the percentage completed.
|
|
. |
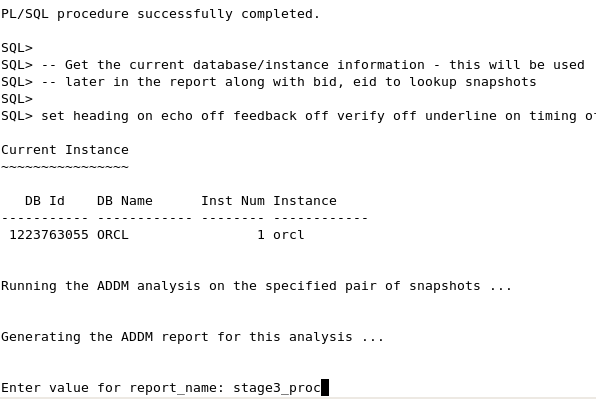
When prompted for the report name, enter: stage3_proc
This generates two reports which are saved in the current directory:
Generated sample results are provided to you for each stage. These files are located in the /home/oci/proclab/doc sub-folder. The names of the sample results files are:
Note: Your results may differ from the sample results provided due to environment differences. For consistency in this tutorial, the generated sample results are examined.
|
|
. |
Examine the contents in the stage3_results_addm.txt report. (You can either open the file in a text editor, or you can scroll up in your SQL*Plus session.) Note the summary of findings.
|
|
. |
Examine the contents in the stage3_results_awr.htm report. Find the file stage3_results_awr.htm. Double-click the file name to open the file in a browser (or right-click and select the Open with "Web-Browser" option).
Review the report.
Scroll down to the Main Report. Click the SQL Statistics link.
Note that the Elapsed Time(s) has decreased significantly when compared with stage1.
|



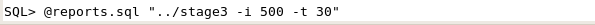







Stage 4: Using Statement Caching
In this section you use statement caching. This stage is same as stage1, but with statement caching enabled. This is achieved by precompiling with the following precompiler option:
- stmt_cache=20 which enables statement caching with a cache size of 20.
|
. |
Examine the contents of the stage4.pc file located in the /home/oci/proclab directory. You can use a text editor to view the contents.
|
|---|---|
|
. |
Use the gmake utility to build the executable C programs and library for the source code for stage4. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage4
|
|
. |
in your SQL*Plus session, run the reports.sql
script. Pass to it the stage4
file. Add the parameters to iterate 500 times to increase the workload
and generate findings, set the number of threads to 30. @reports.sql "../stage4 -i 500 -t 30"
As the report runs, you are shown the percentage completed.
|
|
. |
When prompted for the report name, enter: stage4_proc
This generates two reports which are saved in the current directory:
Generated sample results are provided to you for each stage. These files are located in the /home/oci/proclab/doc sub-folder. The names of the sample results files are:
Note: Your results may differ from the sample results provided due to environment differences. For consistency in this tutorial, the generated sample results are examined.
|
|
. |
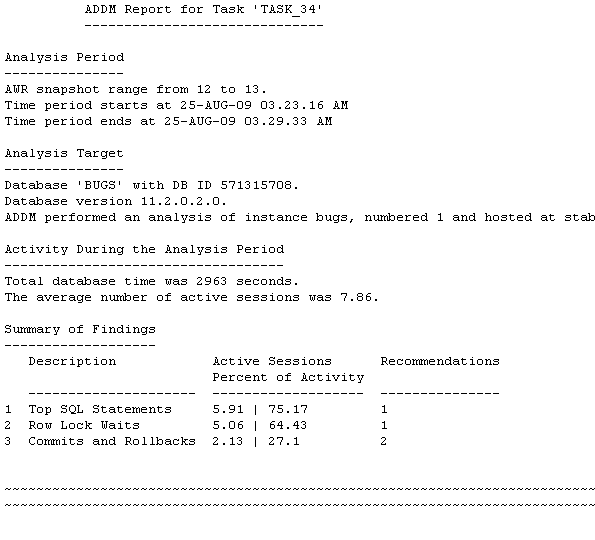
Examine the contents in the stage4_results_addm.txt report. (You can either open the file in a text editor, or you can scroll up in your SQL*Plus session.) Note the summary of findings.
|
|
. |
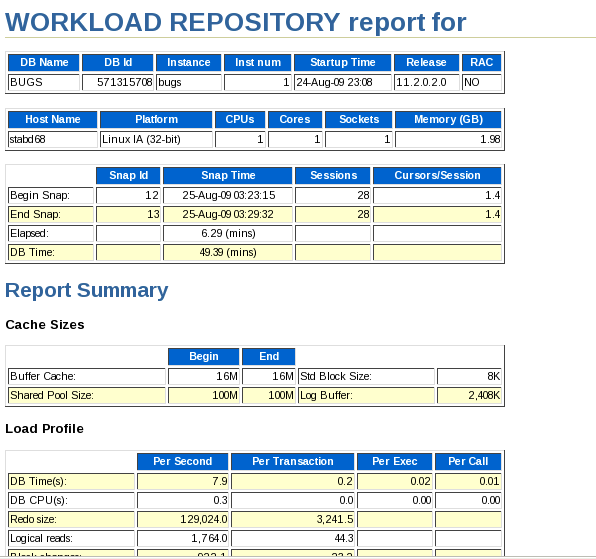
Examine the contents in the stage4_results_awr.htm report. Find the file stage4_results_awr.htm. Double-click the file name to open the file in a browser (or right-click and select the Open with "Web-Browser" option).
Review the report.
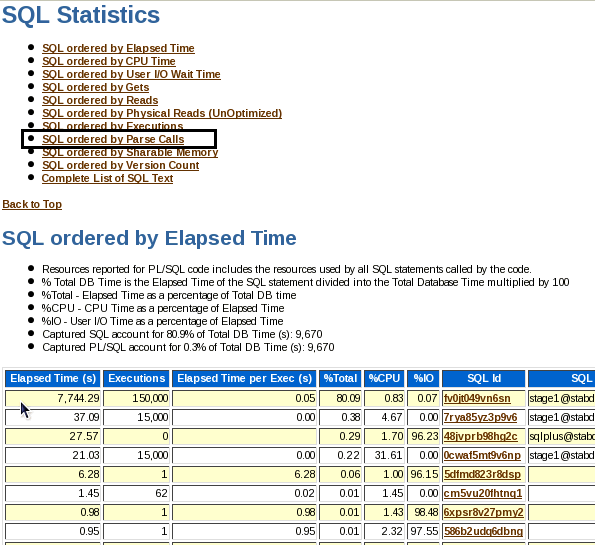
Scroll down to the Main Report. Click the SQL Statistics link.
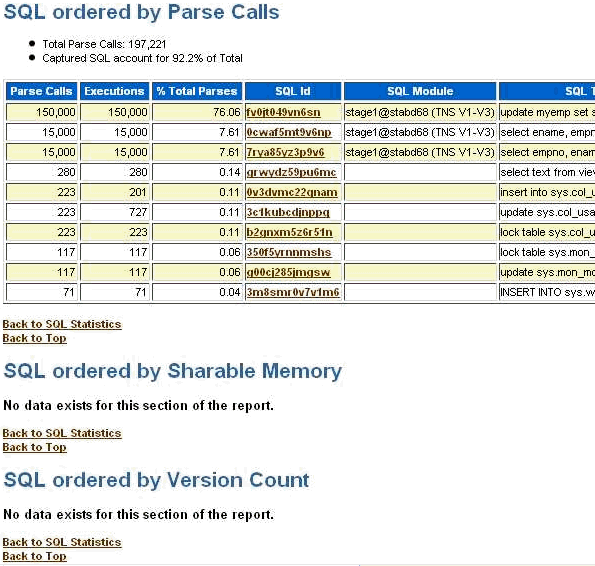
Note the difference in number of parse calls between Stage1 and Stage4.
|











Stage 5: Using Client Resultset Caching
In this section, you enabling result-set caching and then examine the results. This stage is same as stage1, but with client result set caching enabled. This is achieved by adding SQL hints to the SELECT statements. Only the SELECT statements are modified in this section, all else stands same as stage1. The client result cache statistics are printed at the end of this stage.
|
. |
You will need to enable client results set caching. In your init.ora file, the following statements are set for you:. client_result_cache_size=65536 client_result_cache_lag=1000000 compatible=11.0.00.0 If it were not present, you would need to:
|
|---|---|
|
. |
Examine the contents for the stage5.pc file. You can use a text editor to view the contents.
|
|
. |
Use the gmake utility to build the executable C programs and library for the source code for stage5. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage5
|
|
. |
In your SQL*Plus session, run the reports.sql script. Pass to it the stage5 file. Add the parameter to iterate 500 times to increase the workload and generate findings, set the number of threads to 30. @reports.sql "../stage5 -i 500 -t 30"
As the report runs, you are shown the percentage completed.
|
|
. |
When prompted for the report name, enter: stage5_proc
This generates two reports which are saved in the current directory:
Generated sample results are provided to you for each stage. These files are located in the /home/oci/proclab/doc sub-folder. The names of the sample results files are:
Note: Your results may differ from the sample results provided due to environment differences. For consistency in this tutorial, the generated sample results are examined.
|
|
. |
Examine the contents in the stage5_results_addm.txt report. (You can either open the file in a text editor, or you can scroll up in your SQL*Plus session.) Note the summary of findings.
|
|
. |
Examine the contents in the stage5_results_awr.htm report. Find the file stage5_results_awr.htm. Double-click the file name to open the file in a browser (or right-click and select the Open with "Web-Browser" option).
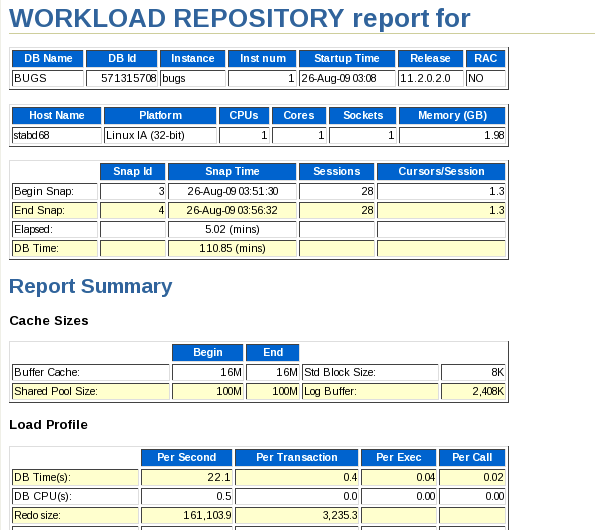
Review the report.
Scroll down to the Main Report. Click the SQL Statistics link.
Review the report. Click on the SQL ordered by Executions link.
|













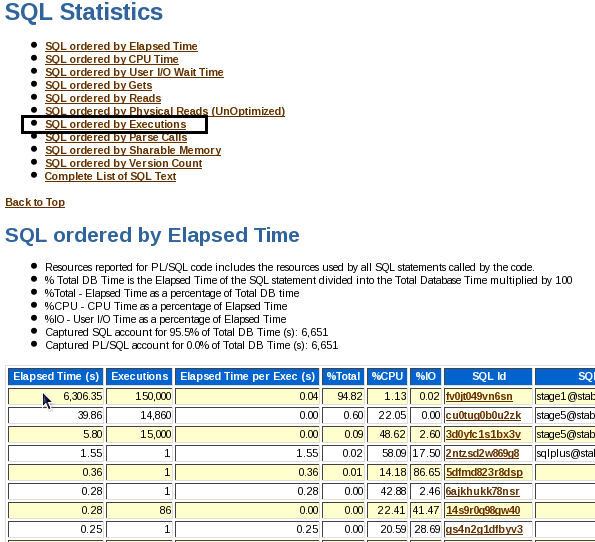

Stage 6: PL/SQL Procedure Invocation
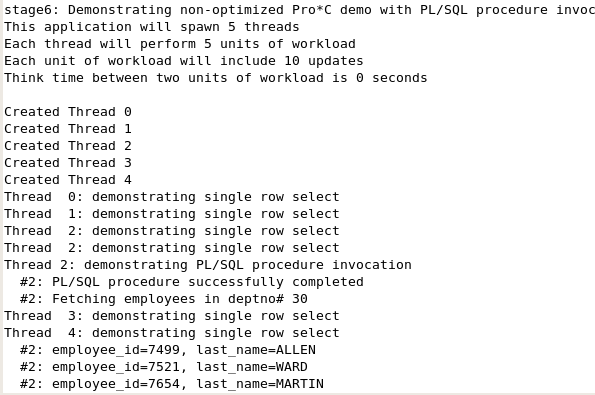
In this section, the multirow_fetch() function is modified so that it invokes a PL/SQL stored procedure that is defined in the createtables.sql script. (This script is available to you and was executed to set up your session). The multirow_fetch() function declares a ref cursor using the sql_cursor pseudotype, allocates the ref cursor, and calls a PL/SQL stored procedure to populate the ref cursor. Once returned by the PL/SQL stored procedure, the ref cursor behaves similarly to cursors that are statically declared in the Pro*C application. The multirow_fetch() function:
- Randomly selects one of the 3 departments (10, 20, 30) from which to fetch the employees data.
- Declares a ref-cursor and passes it on to the PL/SQL stored procedure along with the above generated department number (deptno).
- The PL/SQL procedure emp_demo_pkg.open_cur opens a cursor for the SQL statement, which retrieves all of the employees in the department with the passed deptno value and returns the REF cursor back. It also returns the number of rows matched (meaning, the number of rows in the cursor returned). The parameters are defined as:
ref-curosr IN/OUT
dept no IN
rowcount - OUT - Fetches all the rows in the returned ref-cursor.
|
. |
Examine the contents for the stage6.pc
file.
Locate the stage6.pc file in the /home/oci/proclab directory.
Right click on the stage6.pc file and select the Open with "Text Editor" option.
In stage6.pc, the threads are joined and the performance statistics are calculated and printed for each query.
|
|---|---|
. |
Use the gmake utility to build the executable C programs and library for the source code for stage6. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. gmake cd $HOME/oci/proclab stage6
|
. |
In a terminal window, execute the stage6 file. Include the switches of iterate for 5, threads 5 and specify verbose to print the detailed information. ./stage6 -i 5 -t 5 -v
|







Stage 7: LOB Handling
In this section, you examine LOB handling in Pro*C. The multirow_fetch() function is modified in this stage so that it retrieves LOB data and updates the LOB columns in lob_table created for this tutorial. Neither the query_salary() nor update_salary() functions are called here as only the lob_table is utilized this stage.
- lob_table: This tables stores a set of articles and several comments from the readers on the articles. The following columns are defined:
- article_no: a unique id for a article.
- article_nm: title of the article
- article_text: the body of the article
- comments: comments received on this article.
-
do_workload(): The calls to the query_salary and update_salary functions are not used. Only the call to the multirow_fetch function is used in this stage.
- multirow_fetch():
- Randomly selects an article to read from the lob_table
- Reads the article
- Appends a comment with timestamp in the comments column of the article. It also reports the number of characters read.
|
. |
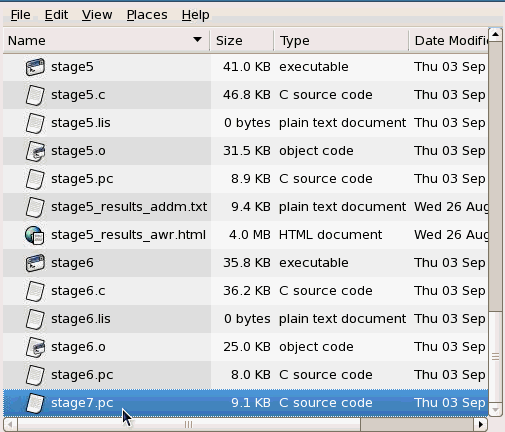
Examine the contents for the stage7.pc
file.
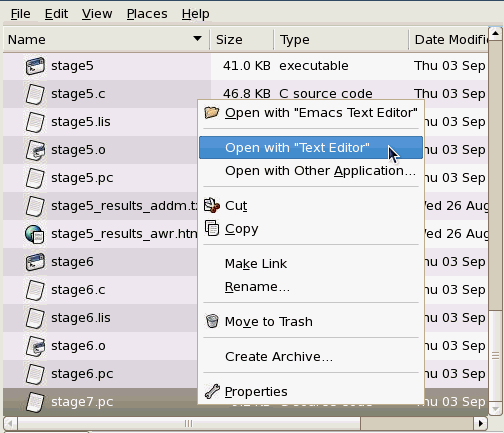
Locate the stage7.pc file in the /home/oci/proclab directory.
Right click on the stage7.pc file and select the Open with "Text Editor" option.
In stage7.pc, LOB handling is demonstrated.
|
|---|---|
. |
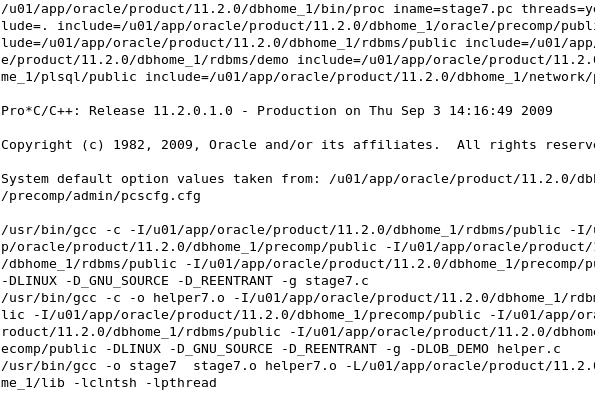
Use the gmake utility to build the executable C programs and library for the source code for stage7. Start a terminal window, navigate (by using the 'cd' command) to the location where the stage files are (/home/oci/proclab) and execute the gmake utility. cd $HOME/oci/proclab gmake stage7
|
. |
In a terminal window, execute the stage7 file. Include the switches of iterate for 10, threads 5 and specify verbose to print the detailed information. ./stage7 -i 10 -t 5 -v
|
| . | >
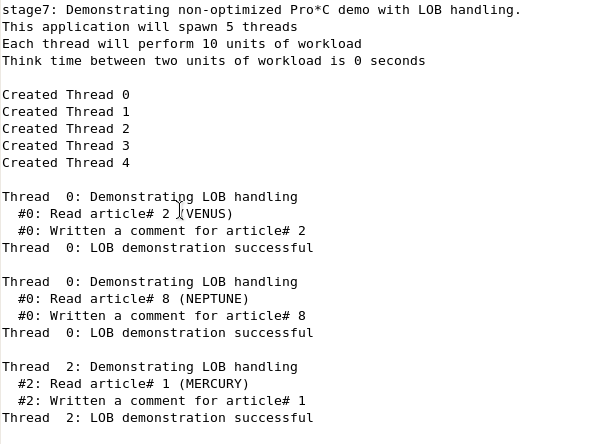
In a SQL*Plus session, examine the contents of the lob_table: DESCRIBE lob_table
select count(*) from lob_table;
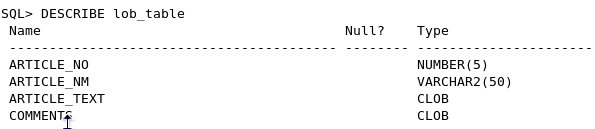
Retrieve the article_text and comments from the lob_table. Issue the following SQL*Plus commands to format the output. set linesize 120 column article_text forma a40 column comments format a40 Then issue this SELECT statement: select article_text, comments from lob_table;
|





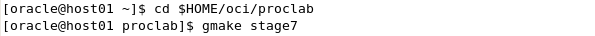
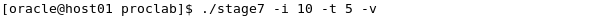







Summary
In this tutorial, you learned how to:
- Setup and Review of no Optimization with Pro*C (stage1)
- Optimize by Using Array-DML and the use of scrollable cursor
- Optimize by Enabling Connection Pooling
- Optimize by Using Statement Caching
- Optimize by Enabling Client Result-Set Caching
- Invoke a PL/SQL stored procedure
- Handle LOBs
![]()

|
About
Oracle |Oracle and Sun | |