Text Mining Using Oracle Data Miner
Purpose
This tutorial covers the use of Oracle Data Miner to perform text mining against Oracle Database 11g Release 2.
Much of today's enterprise information includes both structured and unstructured content related to a given item of interest. For example:
- Customer account data may include text fields that describe support calls and other interactions with the customer.
- Insurance claim data may include a claim status description, supporting documents, email correspondence, and other information.
- Patient data may include comments by doctors and nurses.
It is often essential that analytic applications evaluate the structured information together with the related text.
In this tutorial, you use Oracle Data Miner to include customer comments collected during a survey to better identify good customers.
Time to Complete
Approximately 30 mins.
Overview
Data mining is the process of extracting useful information from masses of data by extracting patterns and trends from the data. Data Mining allows you to mine data sets that contain regular relational information (numeric and character columns), as well as one or more text columns.
Oracle Data Miner uses the facilities of Oracle Text to preprocess text columns.
Transforming Text
Text must undergo a transformation process before it can be mined. The text transformation extracts meaning from the text. Once the data has been properly transformed, it can be used for building, testing, or scoring data mining models.
Data Miner provides Text nodes that enable transformation of text data. The resulting transformed data can then be used as input to build and apply models.
Building Models
To build models that use text columns, you follow these steps:
- Create a workflow in an existing project.
- Create a data source node using data than has one or more columns of text data.
- Prepare the text columns for mining.
- Create training models against test data.
- Apply selected models against new data.
Note: Most Oracle Data Mining algorithms support text. However, O-Cluster and Decision Tree models don't support text.
Prerequisites
Before starting this tutorial, you should:
. |
Have access to or have Installed Oracle Database 11g Enterprise Edition, Release 2 (11.2.0.1) with Data Mining Option. In addition, you must install the Oracle Database Sample Schemas, including the Sales History (SH) schema.
|
|---|---|
. |
Have access to or have installed Oracle SQL Developer, version 3.0, or later. Note: SQL Developer does not have an installer. To install SQL Developer, just unzip the free SQL Developer download to any directory on your PC.
|
. |
|
Create a New Data Miner Workflow
In the Setting Up Oracle Data Miner 11g Release 2 tutorial, you learned how to create a database connection to a Data Miner user and install the Oracle Data Miner Repository, all from within SQL Developer.
In the Using Oracle Data Miner 11g Release 2 tutorial, you learned how to create Data Miner Project and Workflow.
Here, you will create a new Data Miner project using the existing Data Miner user connection.
To create the new workflow, and then perform the following steps:
. |
First, select the Data Miner tab. Result: the dmuser connection that you created previously appears.
Note: If you have not yet created the dmuser connection, follow the instructions in Setting Up Oracle Data Miner 11g Release 2 to create the connection.
|
|---|---|
. |
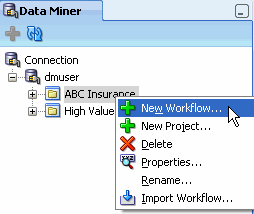
A. Drill on the dmuser connection and right-click the ABC Insurance project to display the pop-up menu:
B. Select New Workflow from the menu. Result: The Create Workflow window appears. Note: If you have not yet created the ABC Insurance project, follow the instructions in Using Oracle Data Miner 11g Release 2 to create the project.
|
. |
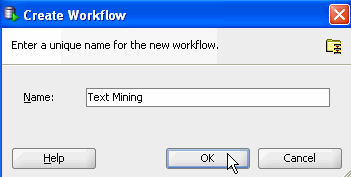
In the Create Worflow window, enter Text Mining as the name and click OK.
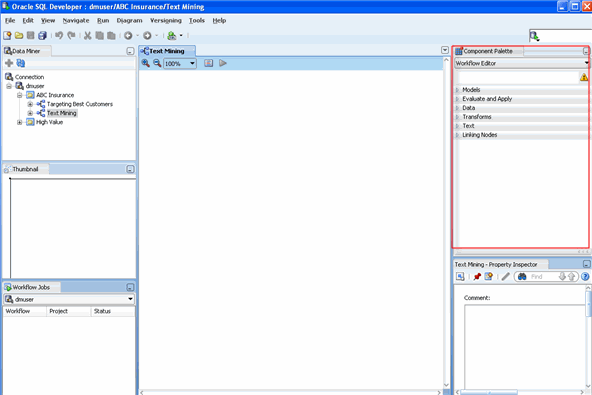
Result:
Note: The Targeting Best Customers workflow may be created by completing the Using Oracle Data Miner 11g Release 2 tutorial.
|

Perform Text Mining Tasks
In this topic, you will perform the following tasks:
- Create a Data Source that contains text
- Transform the text column to prepare it for data mining use
- Build Classification models with the text
- Examine model results
- Apply models to new data
Create a Data Source Containing Text
You first learned how to create data sources in the Using Oracle Data Miner 11g Release 2 tutorial.
In this topic, you create a data source in a similar fashion. However, in this scenario the data column of intrest does not contain regular relational information, but rather text descriptive information.
Note: Although in this example only one text column is used, input data can have several text columns.
To the appropriate data source, perform the following steps.
. |
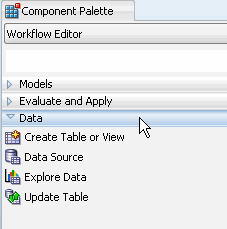
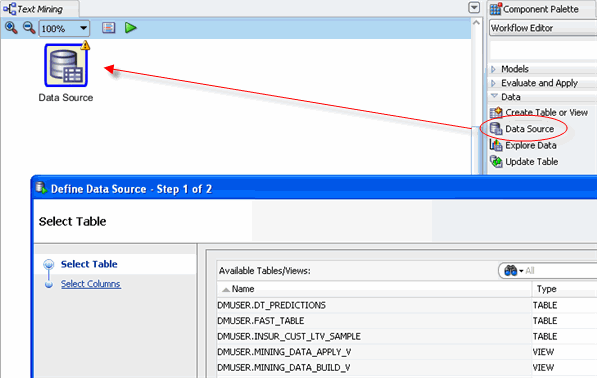
First, add a Data Source node to the workflow. A. In the Workflow Editor of the Component Palette, click the Data category. A list of data nodes appear, as shown here:
B. Drag and drop the Data Source node onto the Workflow pane. Result: A Data Source node appears in the Workflow pane and the Define Data Source wizard opens.
Notes:
|
|---|---|
. |
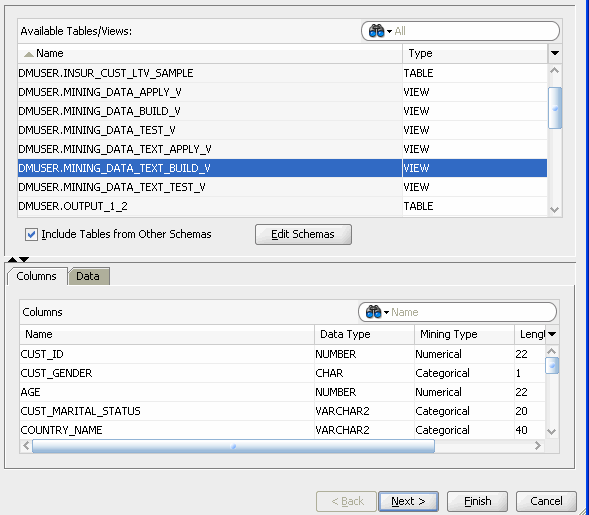
In Step 1 of the wizard, scroll down in the Available Tables/Views list and select the MINING_DATA_TEXT_BUILD_V View, like this:
Note: You may use the two tabs in the bottom pane in the wizard to view and examine the selected table.
|
. |
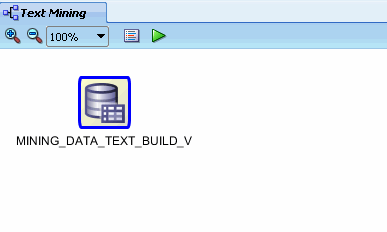
In Step 2 of the wizard, you may remove individual columns that you don't need in your data source. For the time being, we'll keep all of the attributes that are defined in the table. Therefore, click Finish at the bottom of the wizard window. Result: As shown below, the data source node name is updated with the selected view name, and the properties associated with the node are displayed in the Property Inspector.
Notes:
|
. |
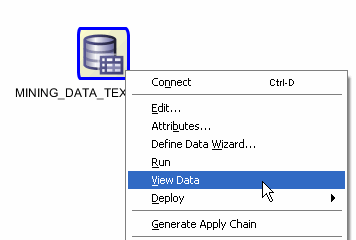
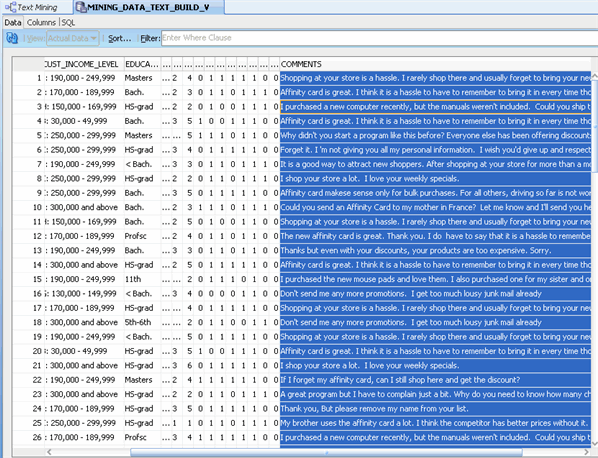
MINING_DATA_TEXT_BUILD_V contains the column COMMENTS, which contains customer comments. To view some of the comments: A. Right-click the data source node and select View Data.
Result: The actual data is displayed in a new tab MINING_DATA_TEXT_BUILD_V.
Note: You can resize any of the column headers to increase or reduce the data display, as shown above. B. When you are done viewing the data, close the tab by clicking the (X) icon.
|
. |
Click the Save All tool in the SQL Developer toolbar. Result: The workflow document is saved, and the workflow name changes in appearance from itatic to a normal font display.
|
Transform the Text Column
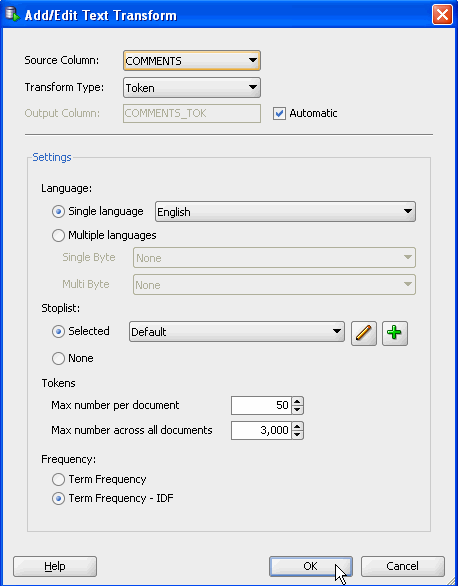
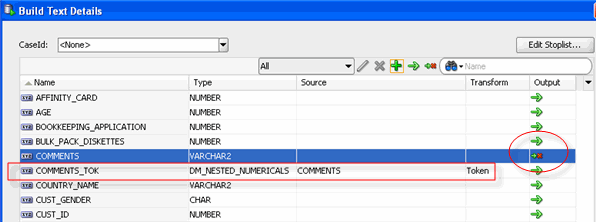
Since the COMMENTS attribute consists of unstructured data, it must be prepared before it is used for model building and mining.
To transform the text column, you will:
- Add a Build Text node
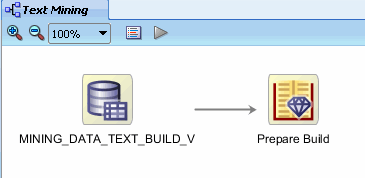
- Connect the data source node to the build text node
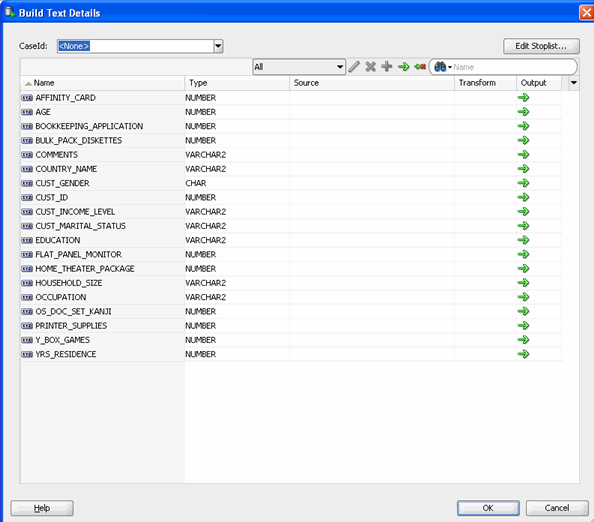
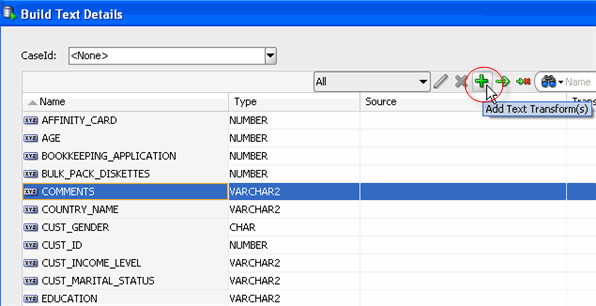
- Specify transformation rules in the build text node for the COMMENTS attribute
- Run the transformation process
Follow these steps:
|

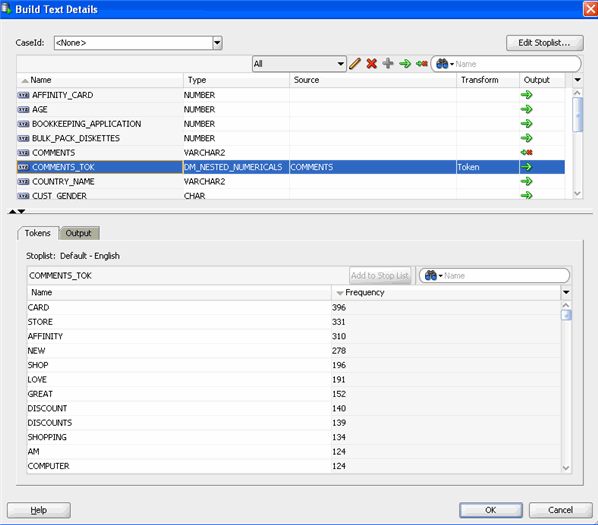
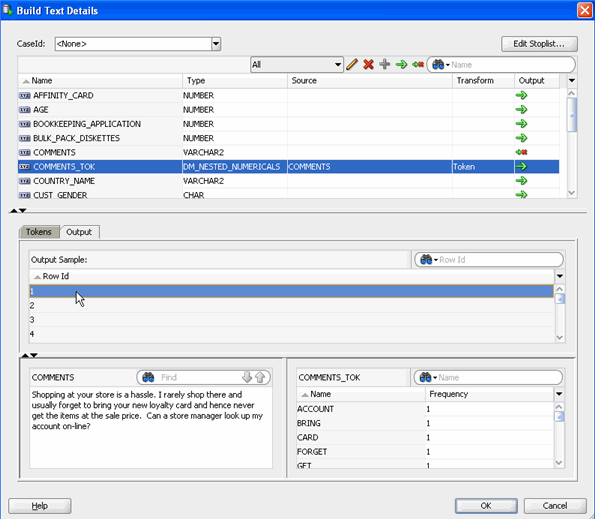
Build Classification Models With Text
At this stage in the process, the text column is prepared so that you can use the data source to build models. The transformed attribute -- COMMENTS_TOK -- will be passed to the model build node, and COMMENTS will not be passed on.
In this topic, you build Classification models that use the transformed customer comments data to better identify good customers. Then, you run the models.
. |
To begin, add a classification node to the workflow. A. First, click on Models in the Component Palette to display the available list:
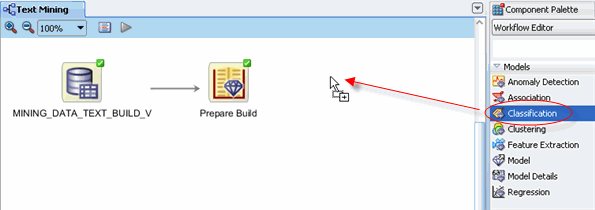
B. Then, drag the Classification node from the paleltte to the Workflow pane, like this:
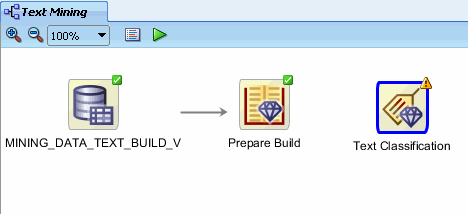
C. Drop the node onto the workflow. After a moment, a "Class Build" node appears in the workflow. D. Using the Details section of the Property Inspector, rename the class build node to Text Classification. The workflow should now look like this:
Notes: As stated previously, a yellow exclamation mark on the border indicates that more information needs to be specified before the node is complete. In this case, two actions are required:
|
|---|---|
. |
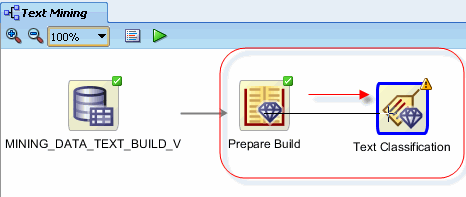
Next, connect the Prepare Build node to the Text Classification node using the same technique described previously.
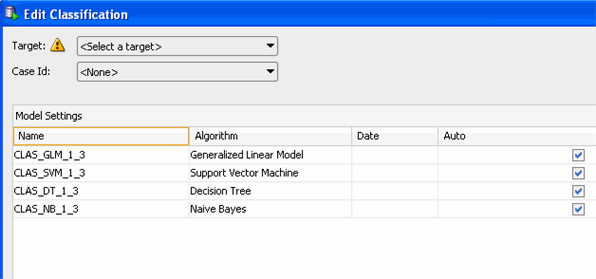
Result: the Edit Classification window appears.
Note: Notice that a yellow "!" indicator is displayed next to the Target field. This means that an attribute must be selected for this item.
|
. |
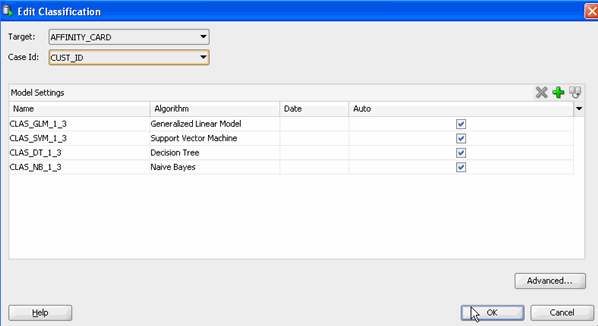
In the Edit Classification window, select AFFINITY_CARD as the Target attribute and CUST_ID as the Case Id attribute. Then, click OK.
. |
. |
Right-click the Text Classification node and select Run from the pop-up menu. Note: As before, green gear icons appear on the node borders to indicate a server process is running, and the Workflow Jobs tab shows the status of the build. When the build is complete, the status column displays a green check mark.
In the workflow pane, the border of the build node changes from a green gear turning to a green check mark, like this:
|
. |
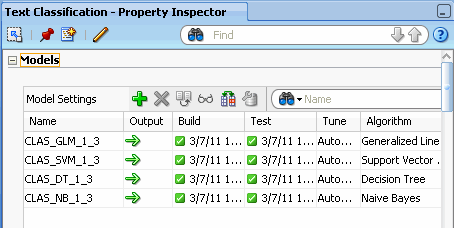
You can view the status of the classification models by viewing the Models tab in the Property Inspector:
Notes:
|
Examine Model Results
Once the build process is complete, you can examine the models that were built and see how the text features appear by viewing the models.
In this topic, you view some of the test model (also known as training model) results.
Follow these steps:
. |
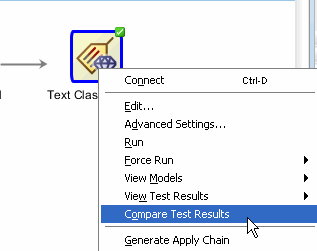
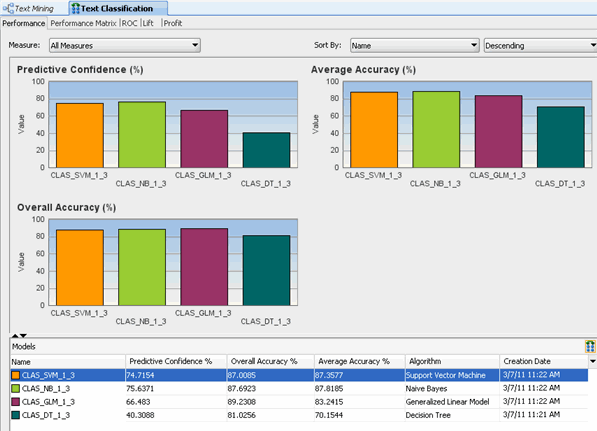
To compare all of the models: A. Right-click the Text Classification node and select Compare Test Results from the menu.
Results:
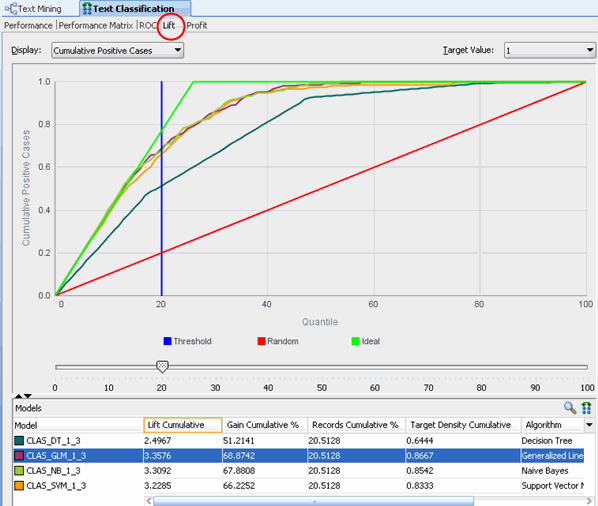
B. Select the Lift tab.
Notes:
C. Feel free to examine any of the comparison results tabs. When you are done, Close the Text Classification display tab, like this:
|
|---|---|
. |
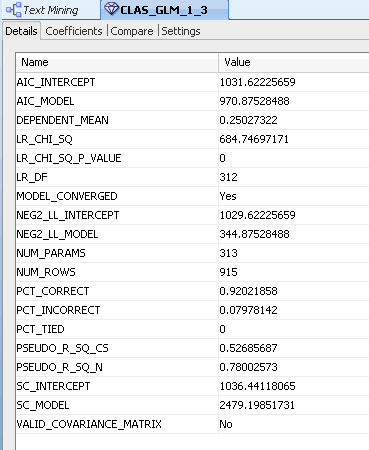
Next, examine individual models. A. For example, right-click the Text Classification node and select View Models > CLAS_GLM from the menu. Result: The Details tab for the GLM model is displayed by default.
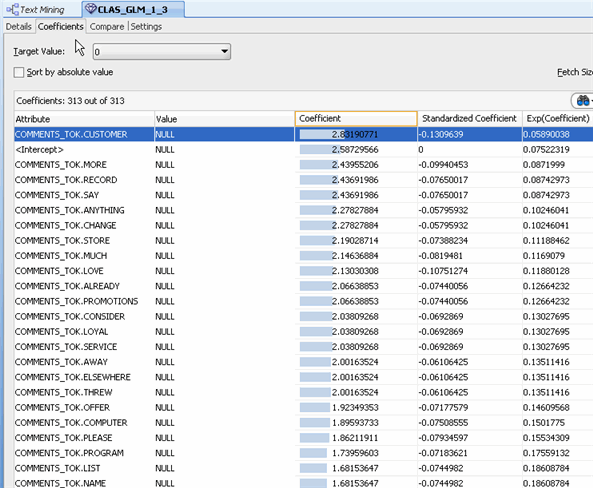
B. Select the Coefficients tab to show coefficients for the tokens in the COMMENTS_TOK attribute.
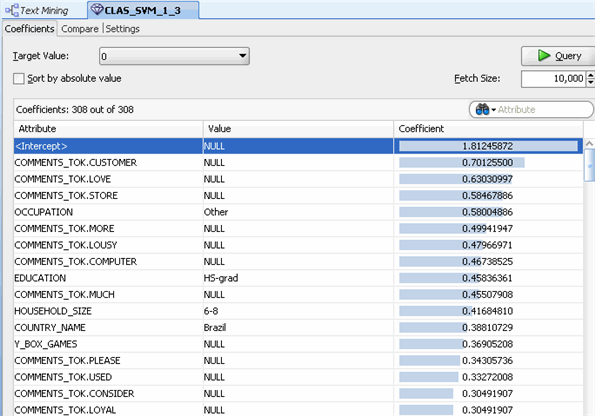
C. Close the the CLAS_GLM display tab. D. To view the Coefficient data for the SVM model, right-click the Text Classification node and select View Models > CLAS_SVM from the menu.
E. When you are done examining the models, close the display tabs for the selected models.
|
Apply Models to New Data
After examining the test models, you can apply all of the models to new data, or you can select a model and apply just that model to new data.
In either case, the text column in the new data must be prepared in the same way as the text column was prepared in the data used to build the models.
Here, you prepare the new data, and then apply all four models to the new data.
Follow these steps:
. |
First, add a Data Source node to the workflow for the new "apply" data, just as you did for the "build" data. A. Using the Workflow Editor of the Component Palette, drag and drop a Data Source node to the workflow window. Result: As before, a Data Source node appears on the workflow, and the Define Data Source wizard opens.
B. In Step 1 of the wizard, select MINING_DATA_TEXT_APPLY_V from the Available Tables/Views list, and then click FINISH. Result: The MINING_DATA_TEXT-APPLY_V node is added to the workflow.
|
|---|---|
. |
Next, create an "Apply Text" node for the new data. A. Using the Workflow Editor of the Component Palette, drag and drop an Apply Text node from the Text category to the workflow window. Result: As before, a Data Source node appears on the workflow, and the Define Data Source wizard opens.
B. Using the same technique as described for the "build" data:
Result: The display should now look like this:
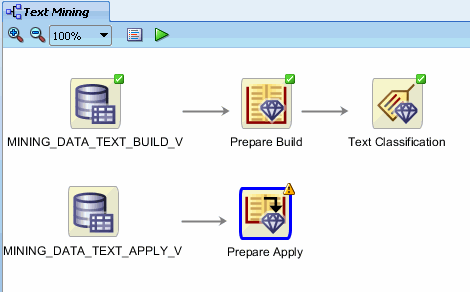
C. In addition, connect the Prepare Build node to the the Prepare Apply node.
Notes:
|
. |
Now, right-click Prepare Apply and select Run from the menu.
Notes:
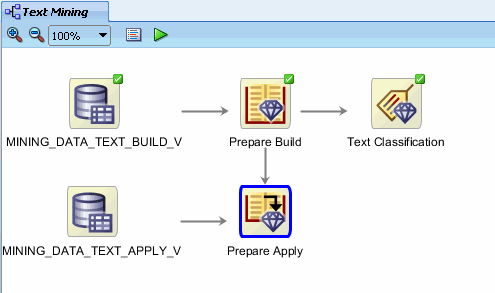
After execution completes, you can apply the models to the prepared new data. The display should now look like this:
|
. |
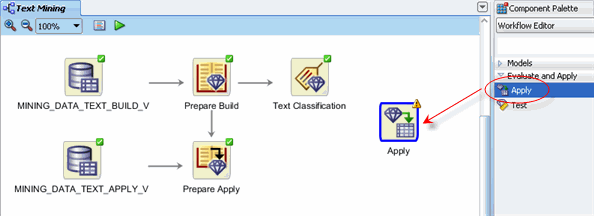
Add a final node to the workflow. A. Open the Evaluate and Apply section of the Components Palette, and then drag and drop an Apply node to the workflow, like this:
B. Rename the Apply node to Predict. C. Create two links the Predict node:
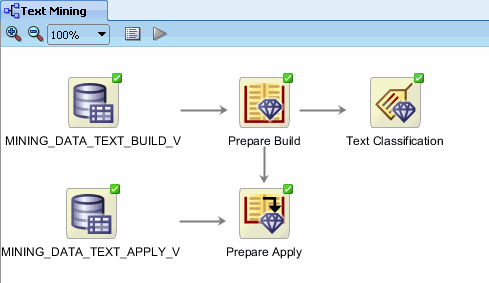
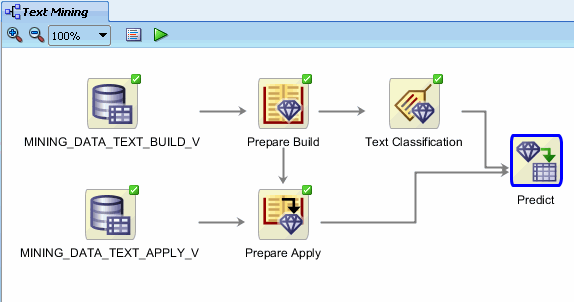
Result: The display should now look like this:
|
. |
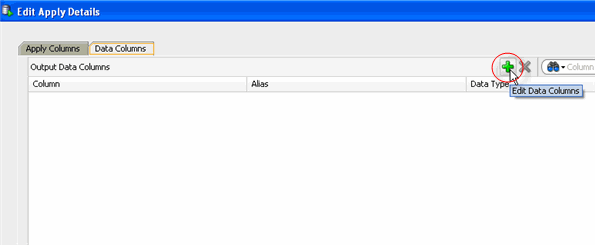
Before running the prediction models, you will add the CUST_ID attribute to the Predict node. This additional data allows you identify predictions. A. Right-click Predict and select Edit from the pop-up menu to display the Edit Apply Details window. B. In the Edit Apply Details window, select the Data Columns tab, and then click the Edit Data Columns (+) tool, as shown here:
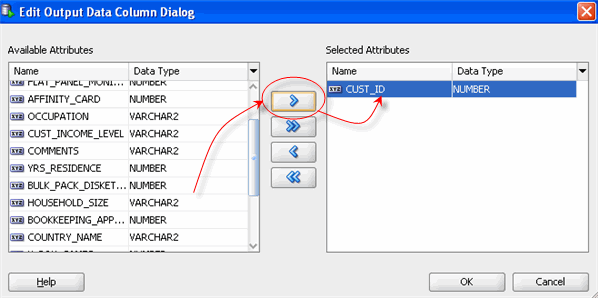
C. In the Edit Output Data Column Dialog, move CUST_ID from the Available Attribute list to the Selected Attribute list, like this:
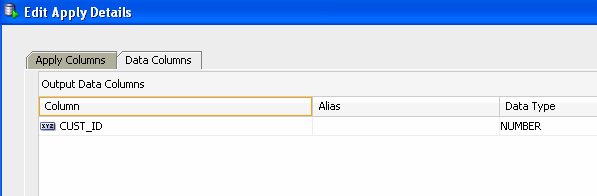
D. Click OK to close the dialog and return to the Apply Edit Details window. Results: the Data Columns tab of the Apply Edit window now looks like this:
E. Click OK to close the the Apply Edit Details window.
|
. |
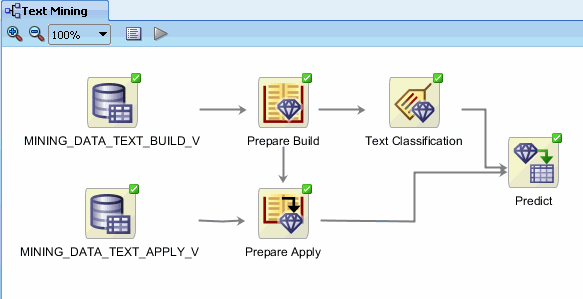
Finally, to apply all four models to the new data, right-click Predict and select Run from the menu. Monitor the run process as before. When complete, the display should look like this:
|
. |
After execution completes, you can examine the predictions of the models. To view the results, right-click the Predict node and select View Data from the Menu. Result: A new tab opens with the prediction results for all four mdels. For each customer (CUST_ID), the predicted outcome and probability for that outcome is shown for each model.
Note: Oracle Data Mining's Naive Bayes model is able to leverage all of the available structured and unstructured data to build a predictive model that produces:
|
. |
Close the Predict tab, and then close the Text Mining workflow. |



Summary
In this lesson, you examined tasks associated with performing Text Mining with the Oracle Data Miner graphical user interface, which is included as an extension to SQL Developer, version 3.0.
In this tutorial, you have learned how to:
- Create a Data Miner project
- Build a Workflow document
- Create data sources from unstructured text data
- Transform unstructured text into a format that can be mined
- Build and apply Classification models for text mining purposes
Resources
To learn more about Oracle Data Mining:
- See the Oracle Data Mining home page on OTN.
Curriculum Developer: Brian Pottle
Technical Contributors: Charlie Berger, Mark Kelly, Margaret Taft, Kathy Taylor
![]()
 |
About
Oracle |Oracle and Sun | |