Creating and Running Imports
Purpose
This tutorial covers how to create and run imports in Data Relationship Management (DRM) Web Client.
Time to Complete
Approximately 30 min.
Overview
You create imports in the Import task group in DRM Web Client. An import wizard, which consists of the following tabs, guides you through the process of defining the import source, style, columns, filters, and target:
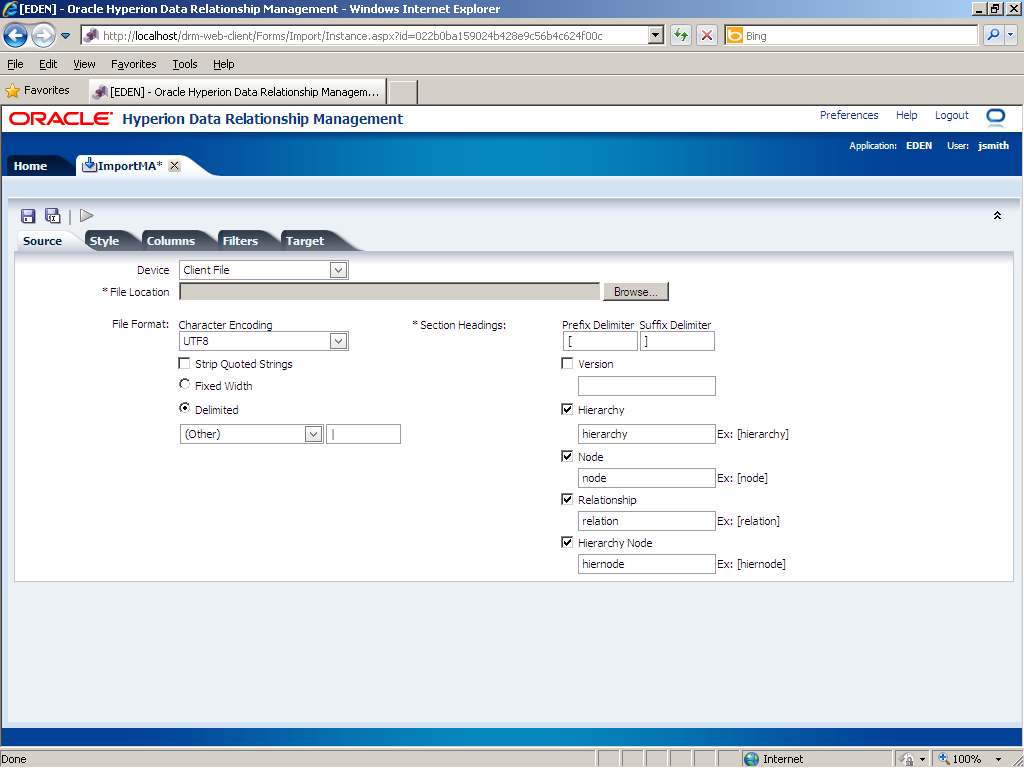
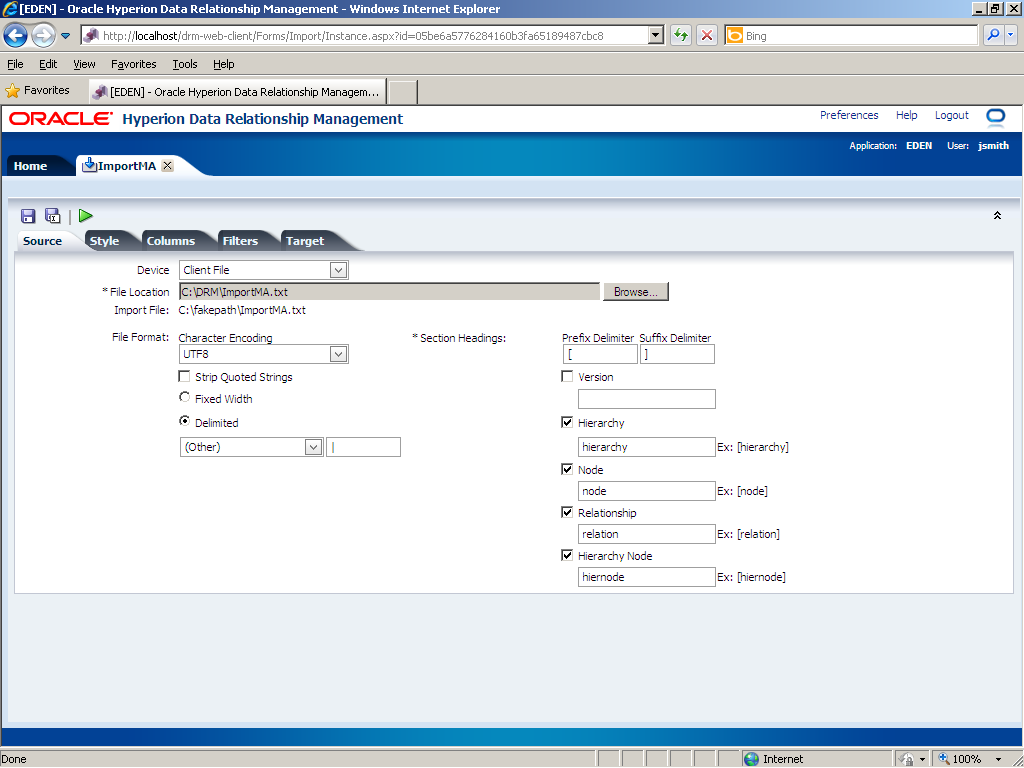
- Source—Select an import source, specify file formats, and configure section headings. For the source file, you select either a client file on your local machine or a server file on a network file system or FTP directory.
- Style—Enable the import to sort nodes based on the order in which they are displayed in the Relation section of the source file, configure childless nodes as leaf nodes, and enforce invalid node name characters. You can also append unique names to duplicate nodes to enable them to be imported rather than rejected; for example, <node name>:Shared-000. A duplicate node is any node that appears under multiple parents within the same hierarchy.
- Columns—Map properties (such as Name or Description) to columns in the input file, and map columns to hierarchies. Create separate mappings for each section that is specified in the file.
- Filter—Make selections to skip blank property types and use default values for certain property types. This action is recommended to minimize the size of the imported version.
- Target—Specify a name and description for the new version, as well as the maximum number of errors that can occur during the processing before the import stops.
You must first open an import to run it. If you import a file from your client machine, you must also select a client file before you can run the import. After running an import, you can view summary information and detailed messages in the import results.
The import results identify the completion status of the process, the statistics for errors, and the statistics for hierarchies, nodes, and orphans. Warning and error messages are displayed below the summary information. You can download import results to an external CSV, PDF, RTF, or XLS file.
The import process creates a new version of data in the application and loads it in a detached (unsaved) state. The version includes the hierarchies, nodes, and property values that were successfully imported. You can permanently save the version for future use or blend it into another version. If the version is incorrect, you can discard it and import it again.
In this tutorial, you create and run an import.
Prerequisites
Before starting this tutorial, you should have access to or have installed Oracle Hyperion Enterprise Performance Management 11.1.2.1.0 and Oracle Hyperion Data Relationship Management, Fusion Edition 11.1.2.1.0.
Creating an Import
In this topic, you create an import.
. |
Begin by navigating to the Import task group. Use the Import task group to create and manage imports.
|
|---|---|
. |
Click the New Import (
Use the import wizard to define the source, style, columns, filters, and target for the import. You begin on the Source tab.
|
. |
Perform the following actions on the Source tab:
|
. |
Click the Style tab.
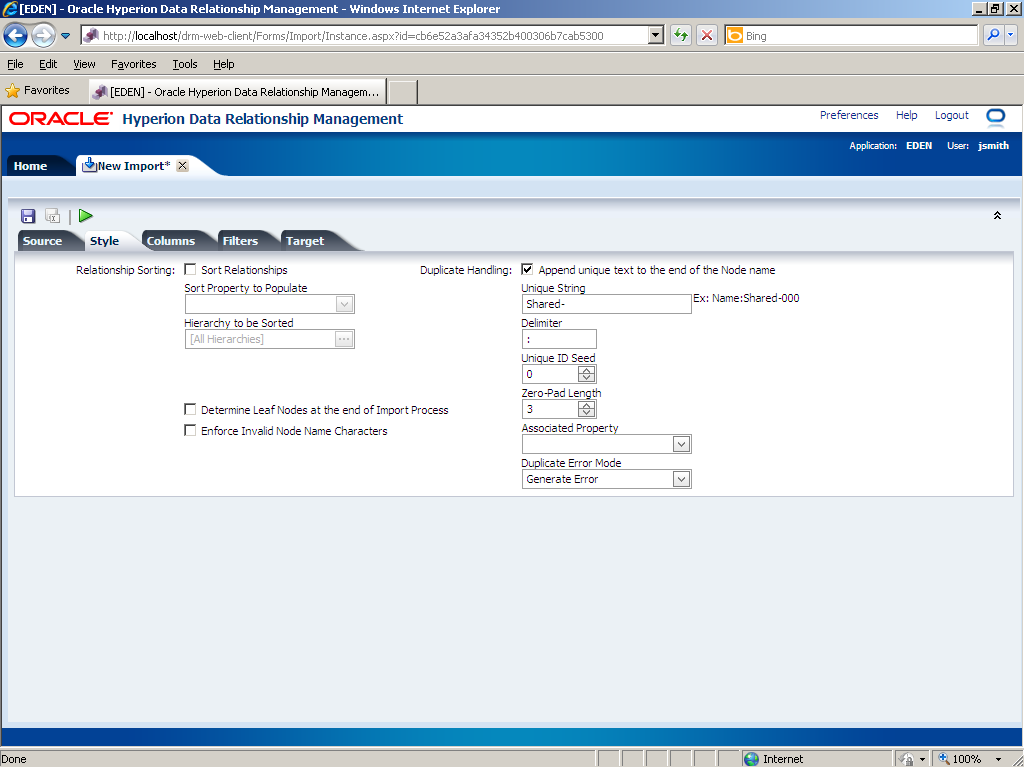
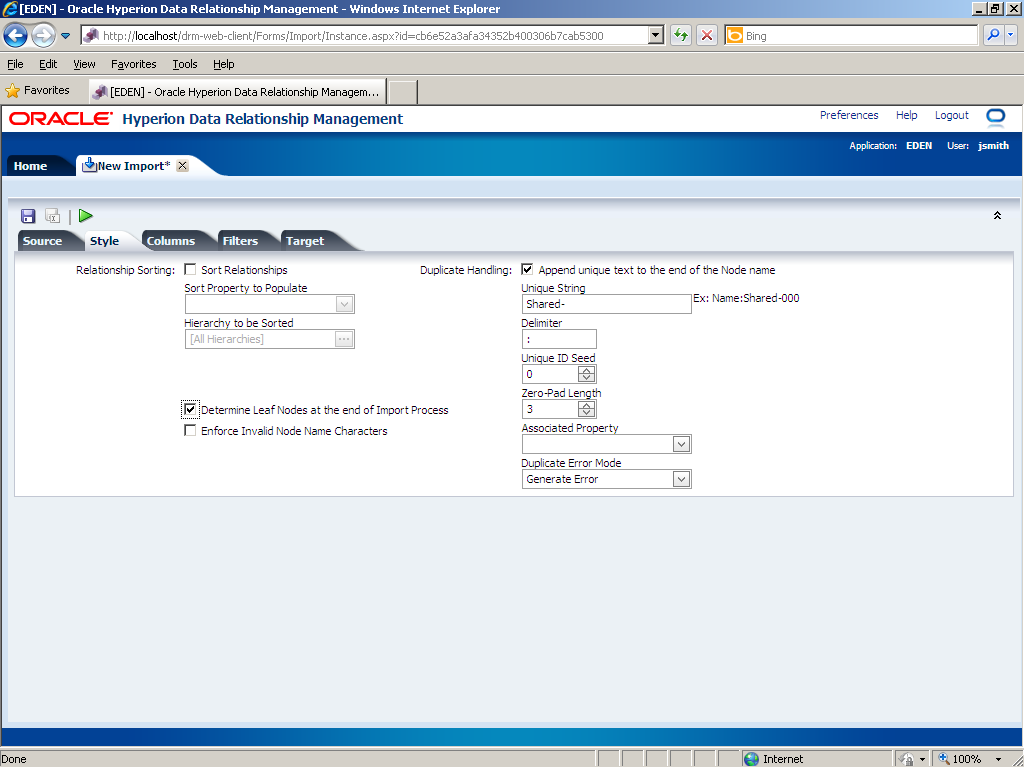
Use the Style tab to define relationship sorting, determine leaf nodes, enforce invalid node name characters, and specify duplicate handling options.
|
. |
Perform the following actions on the Style tab:
|
. |
Click the Columns tab.
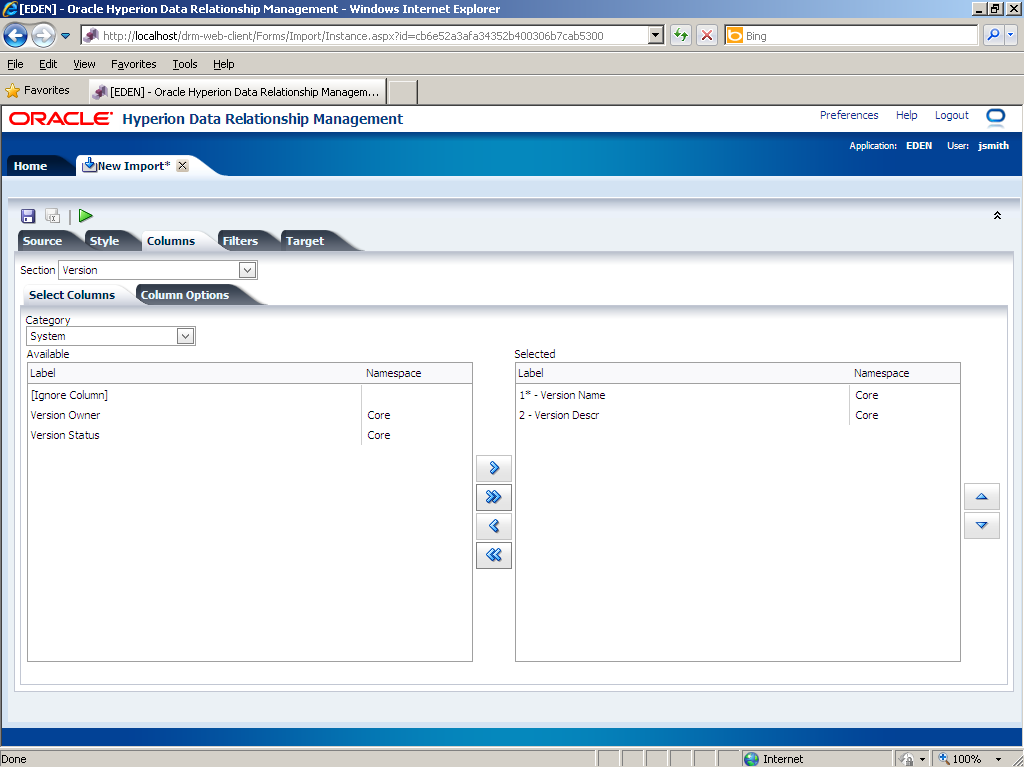
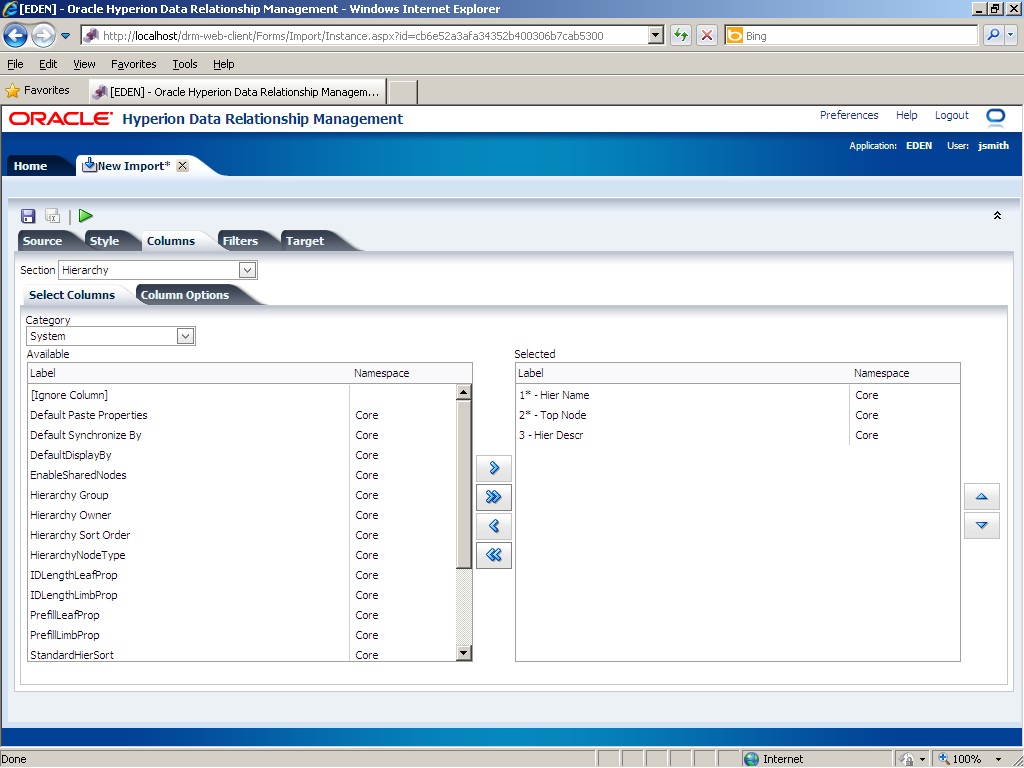
Use the Columns tab to map properties to columns in the import file and map columns to hierarchies. In the Selected list, columns that are marked with an asterisk (*) are mandatory.
|
. |
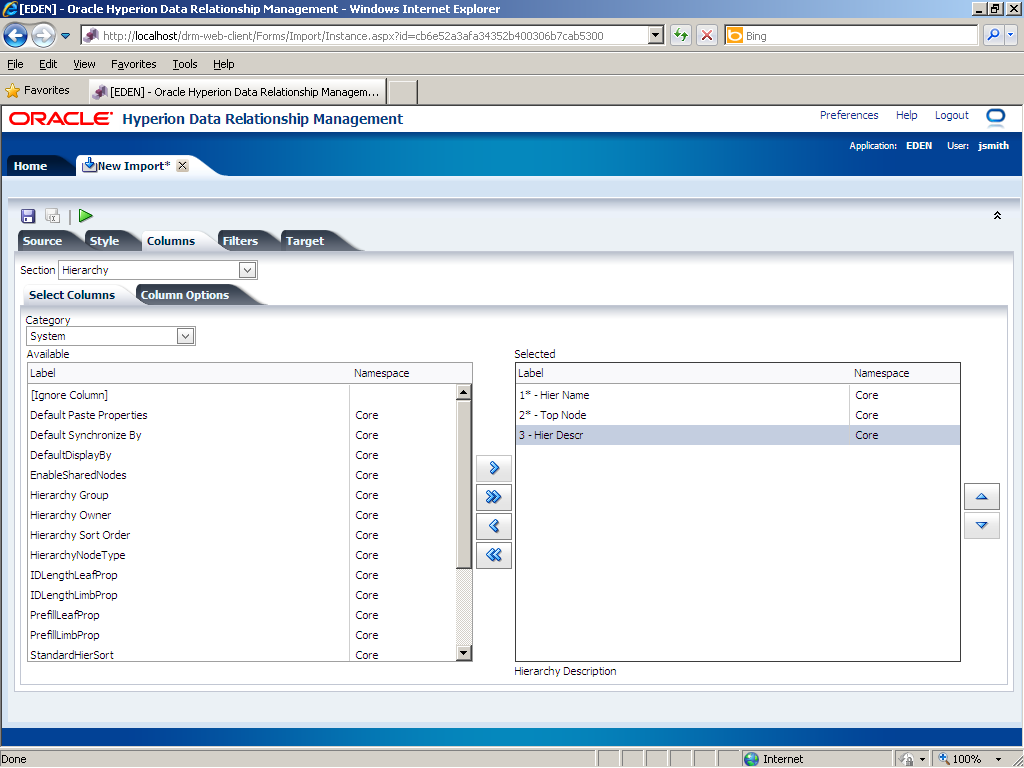
In the Section drop-down list, select Hierarchy.
|
. |
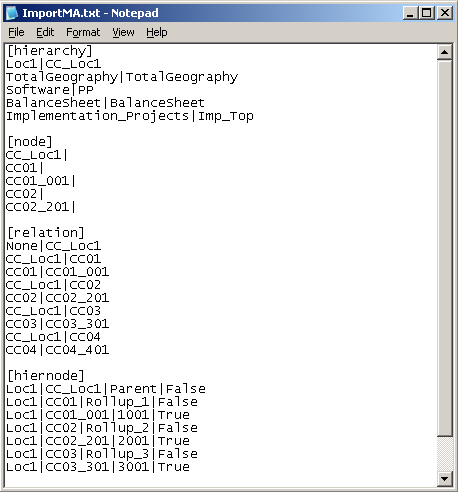
In this example, the Hierarchy section in the import file has two properties: hierarchy name and top node; therefore, you need to remove the Hier Desc property from the Selected list. In the Selected list, click 3 - Hier Descr.
|
. |
Click the Remove (
The Hier Descr property is removed from the Selected list.
|
. |
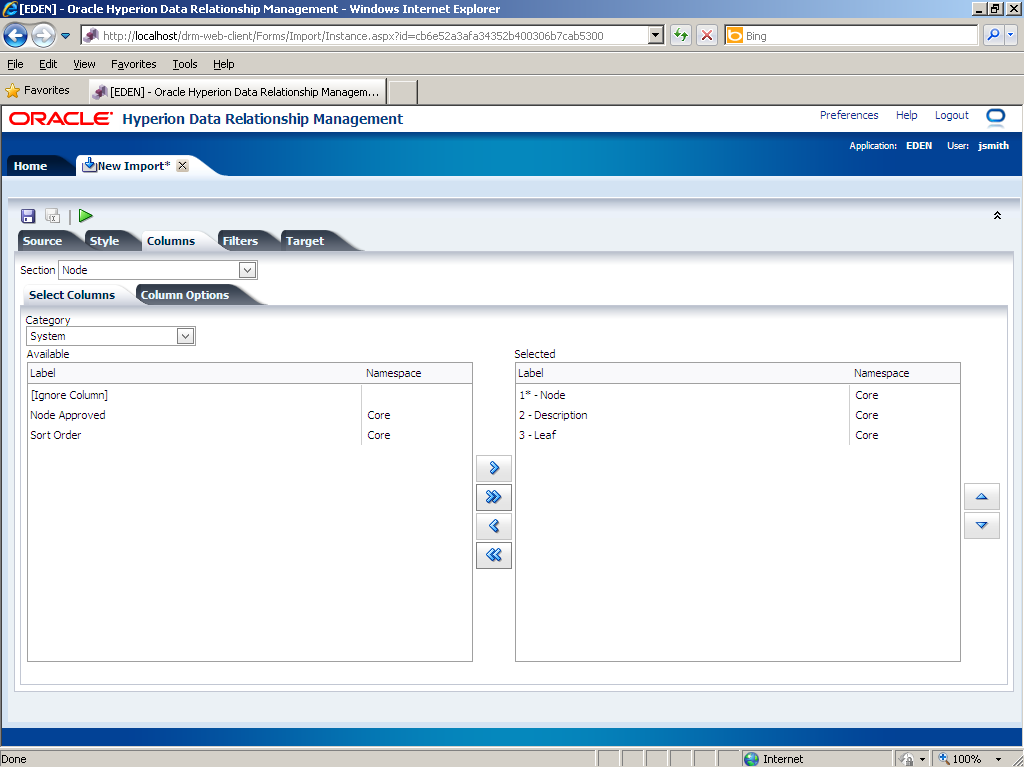
In the Section drop-down list, select Node.
|
. |
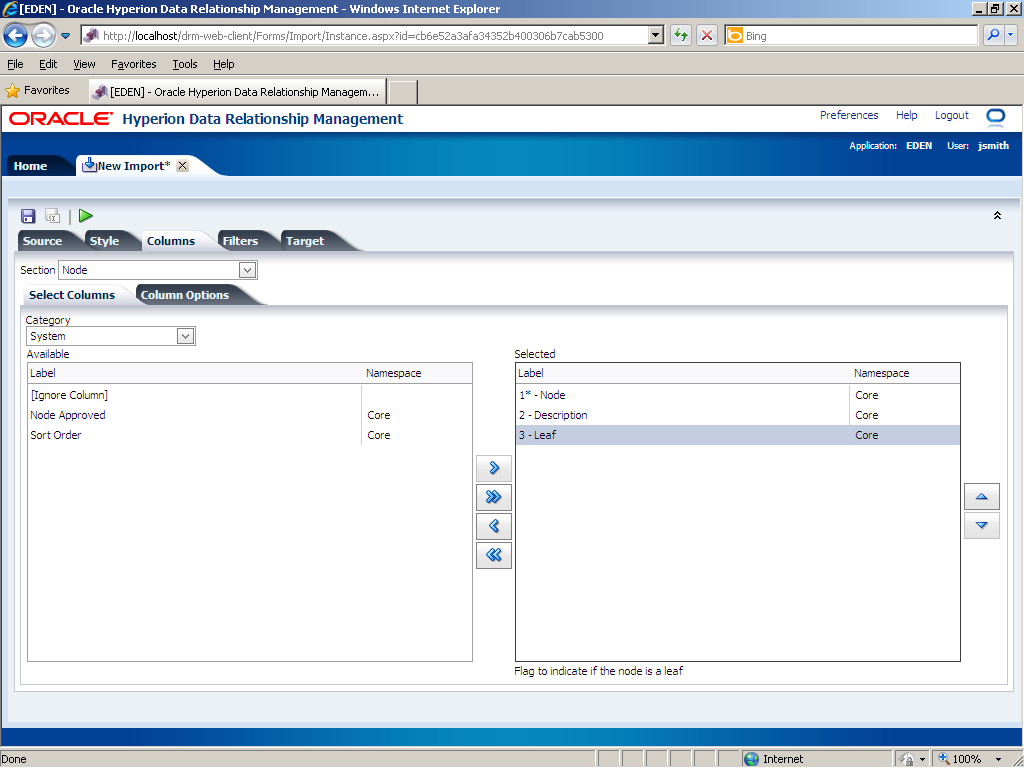
In this example, the Node section in the import file has two properties: node name and node description; therefore, you need to remove the Leaf property from the Selected list. In the Selected list, click 3 - Leaf.
|
. |
Click the Remove (
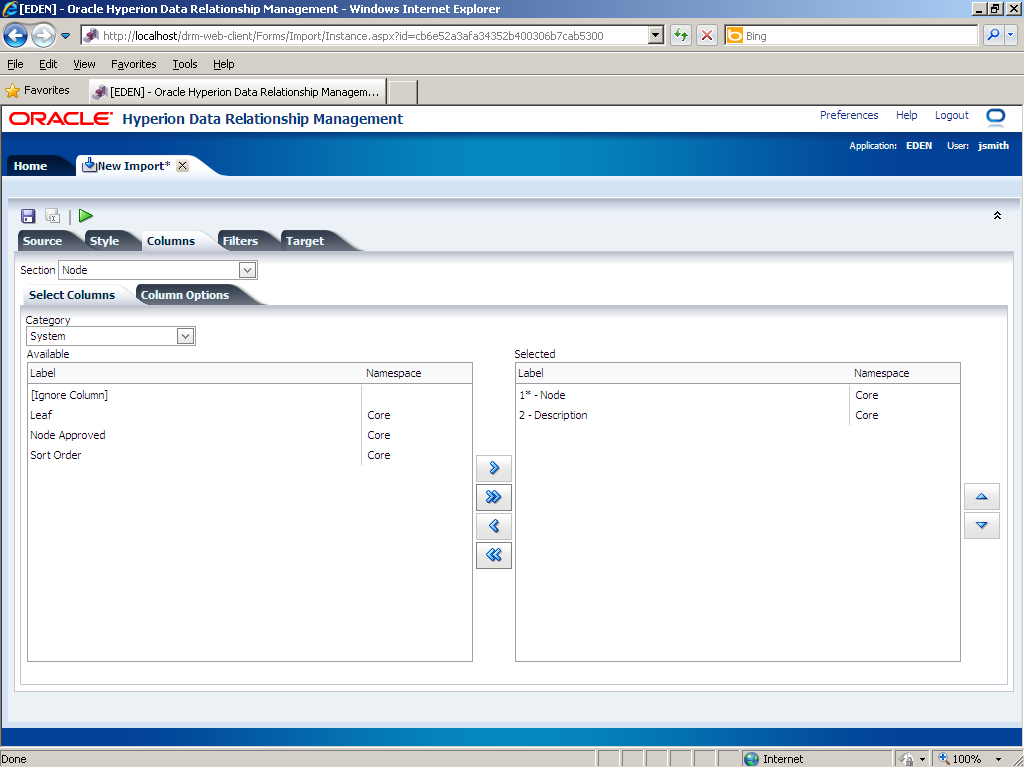
The Leaf property is removed from the Selected list.
|
. |
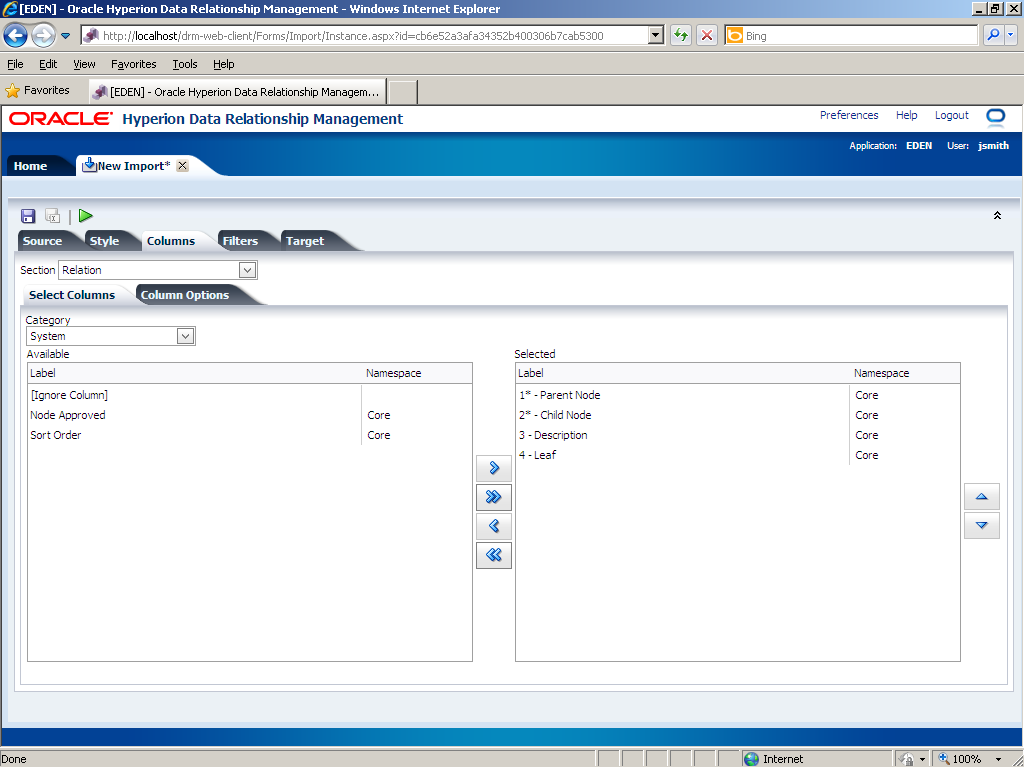
In the Section drop-down list, select Relation.
|
. |
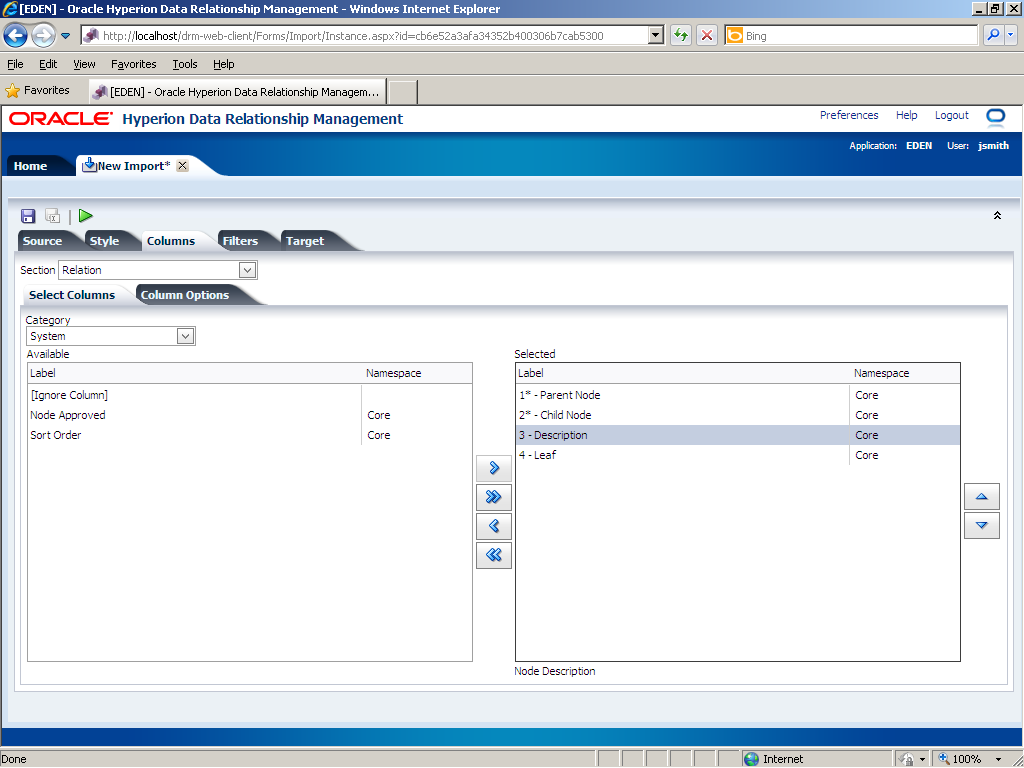
In this example, the Relation section in the import file has two properties: parent node and child node; therefore, you need to remove the Description and Leaf properties from the Selected list. In the Selected list, click 3 - Description.
|
. |
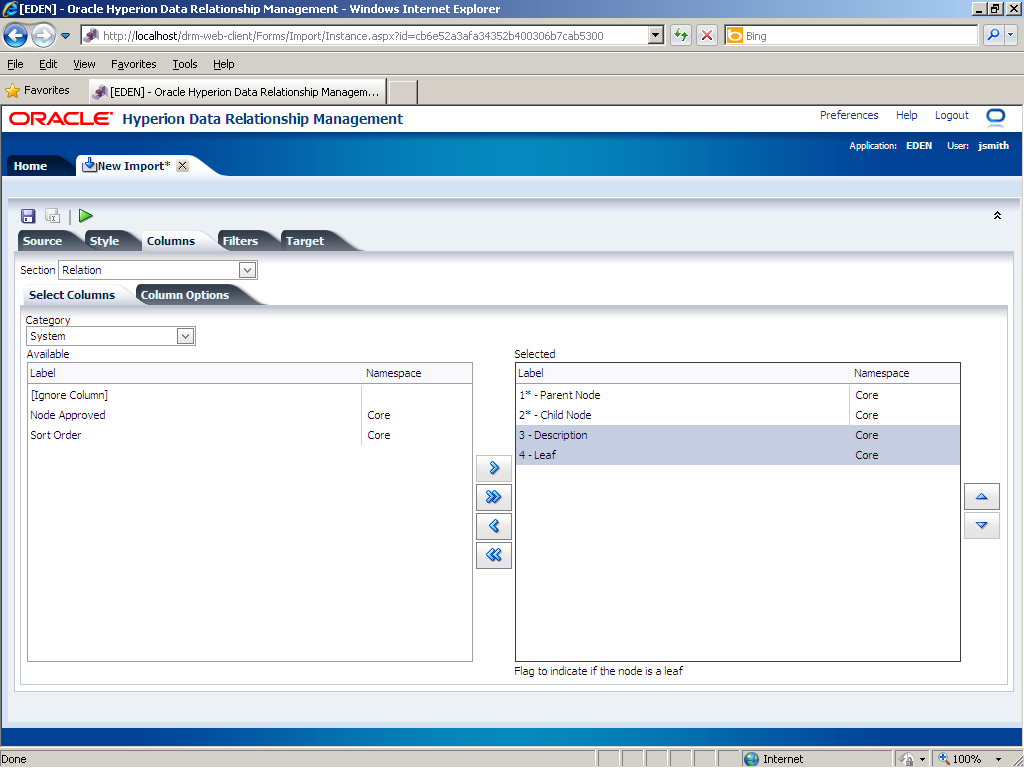
Press the [Ctrl] key and click 4 - Leaf.
|
. |
Click the Remove (
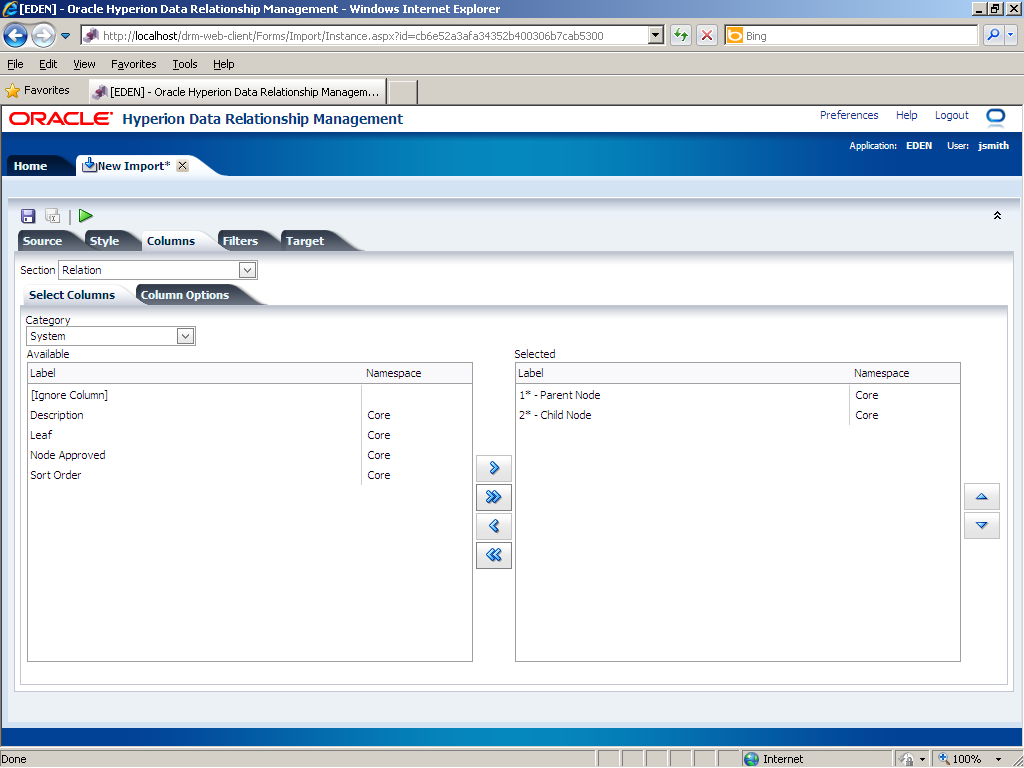
The Description and Leaf properties are removed from the Selected list.
|
. |
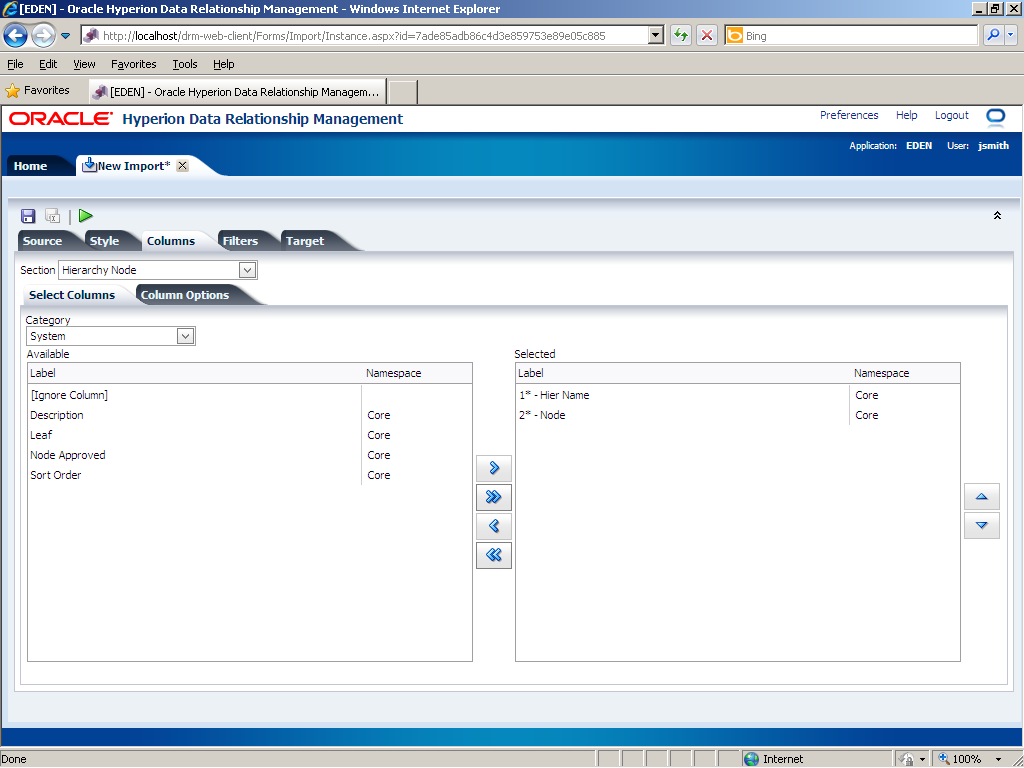
In the Section drop-down list, select Hierarchy Node.
|
. |
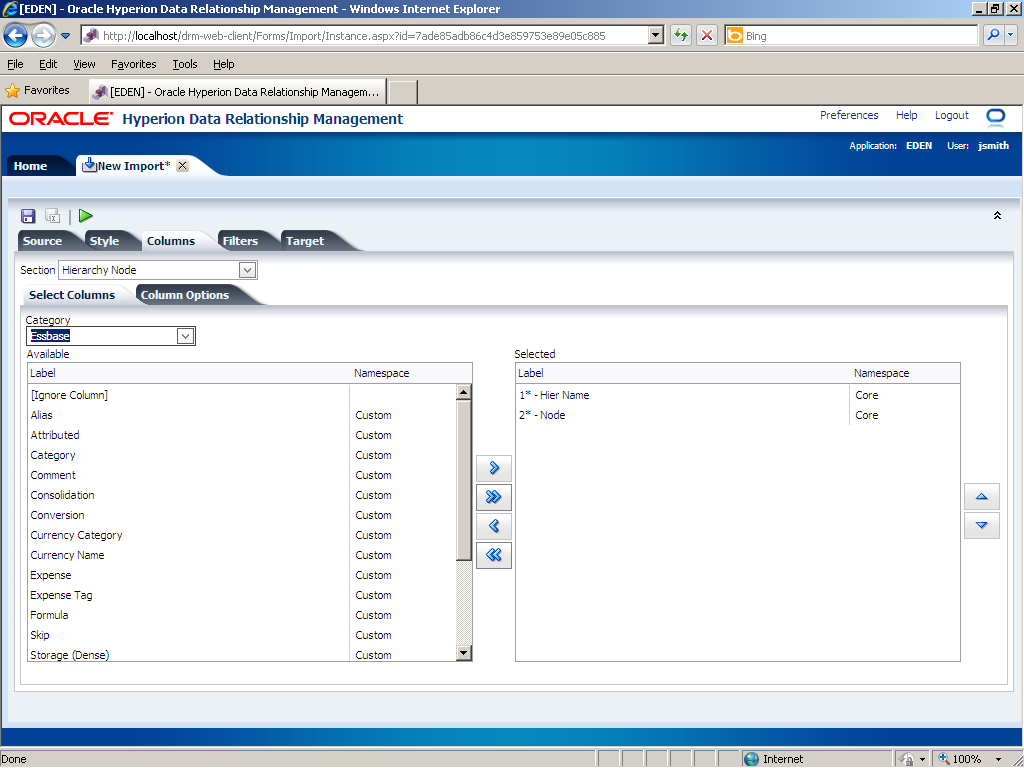
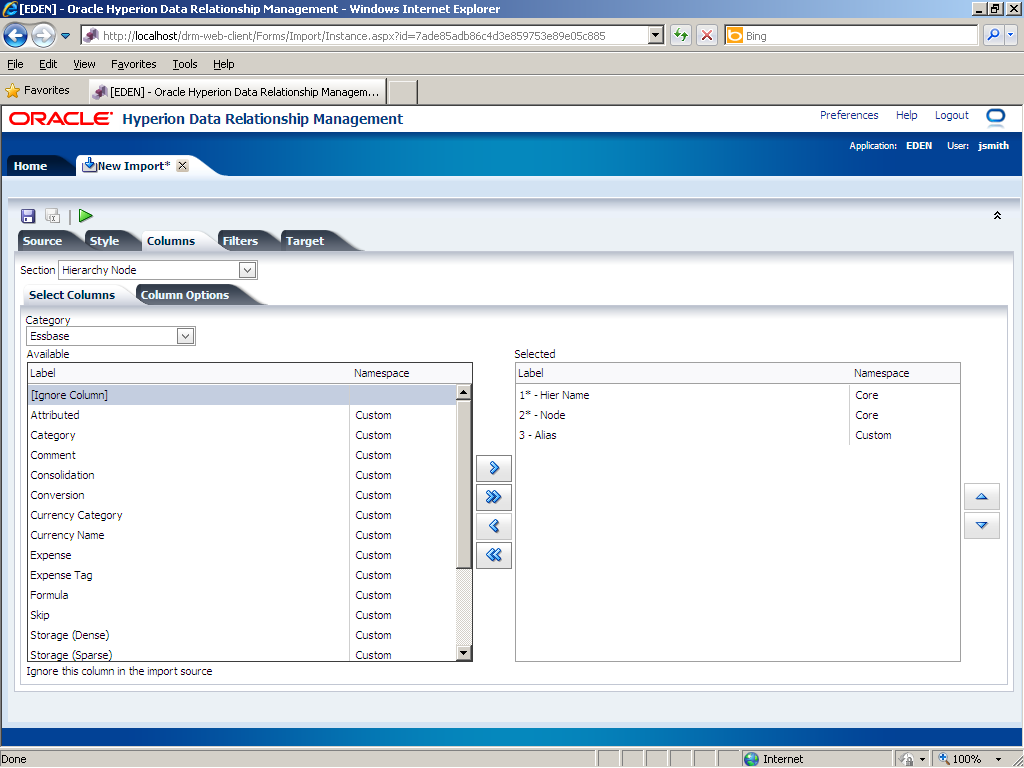
In this example, the Hierarchy Node section in the import file has four columns: hierarchy name, node name, alias, and a column that should not be imported; therefore, you need to add two columns to the Available list. In the Category drop-down list, select Essbase.
|
. |
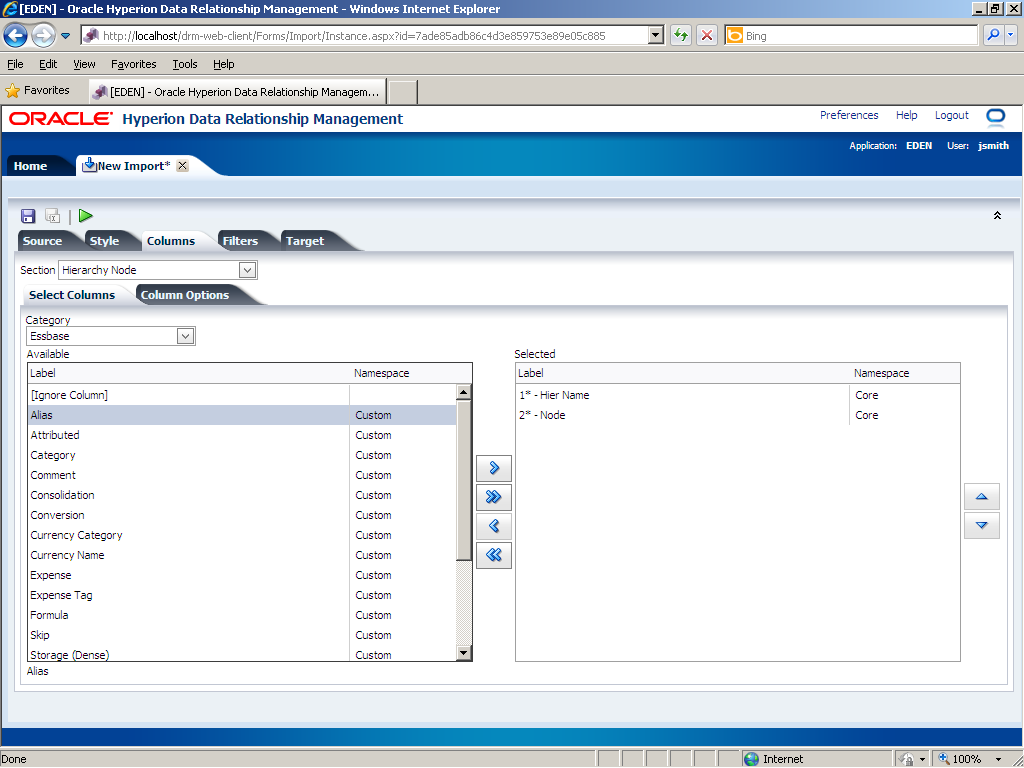
In the Available list, click Alias.
|
. |
Click the Select (
The Alias property is displayed in the Selected list.
|
. |
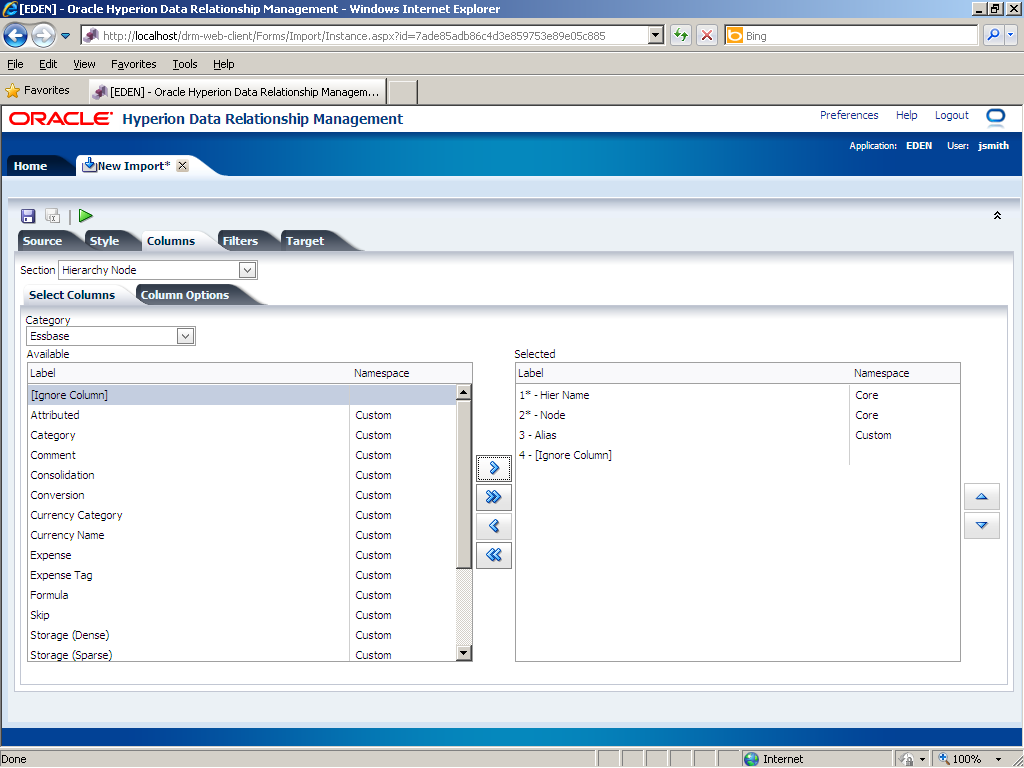
In the Available list, click [Ignore Column].
|
. |
Click the Select (
The [Ignore Column] property is displayed in the Selected list.
|
. |
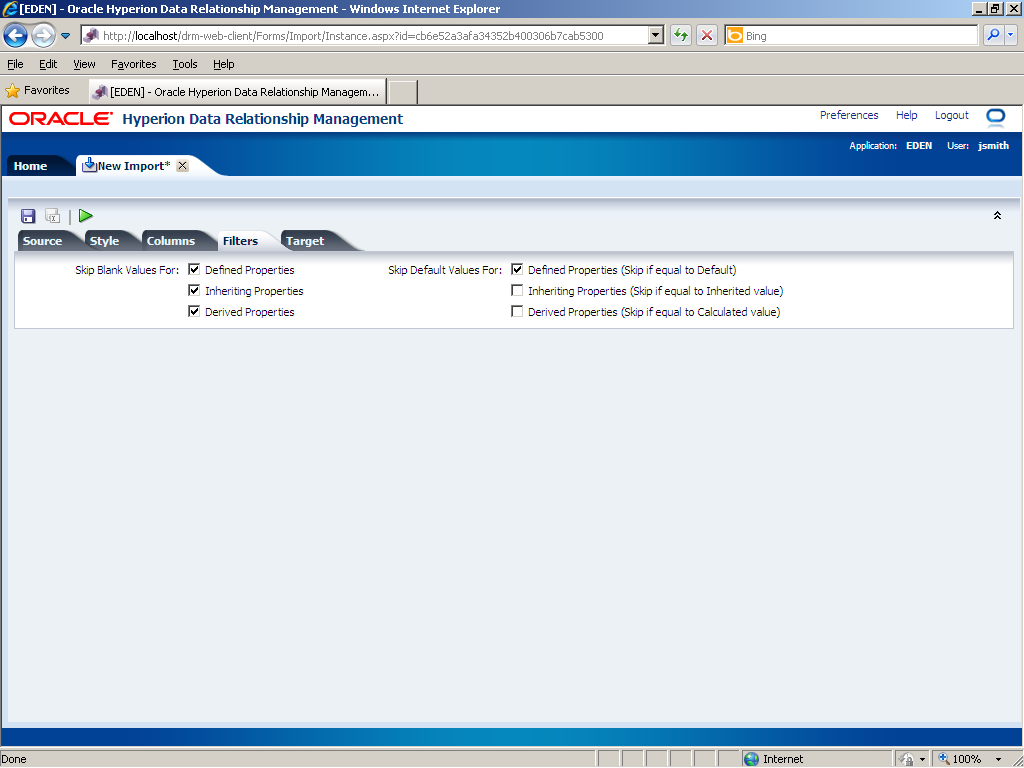
Click the Filters tab.
Use the Filters tab to skip blank values and default values for defined, inheriting, and derived properties during the import process. In this example, you accept the default selections.
|
. |
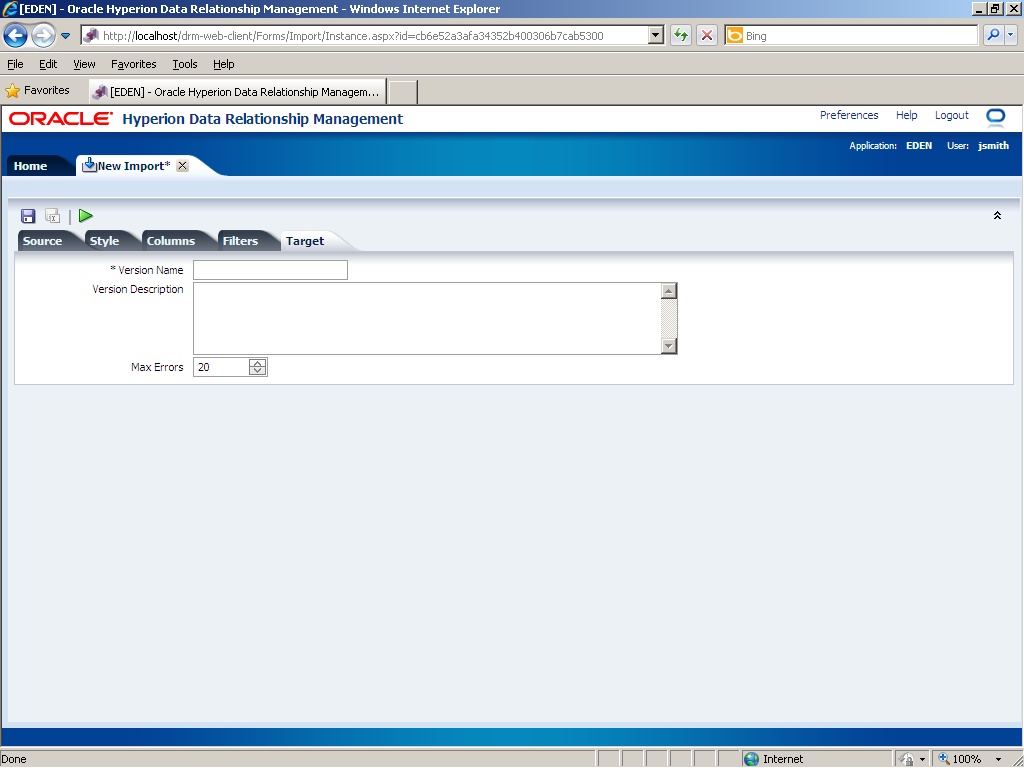
Click the Target tab.
Use the Target tab to specify a name and description for the new version and to specify the maximum number of errors that can occur during the processing before the import stops. Note: You specify a version name and description only if your import file does not have a Version section to define those values.
|
. |
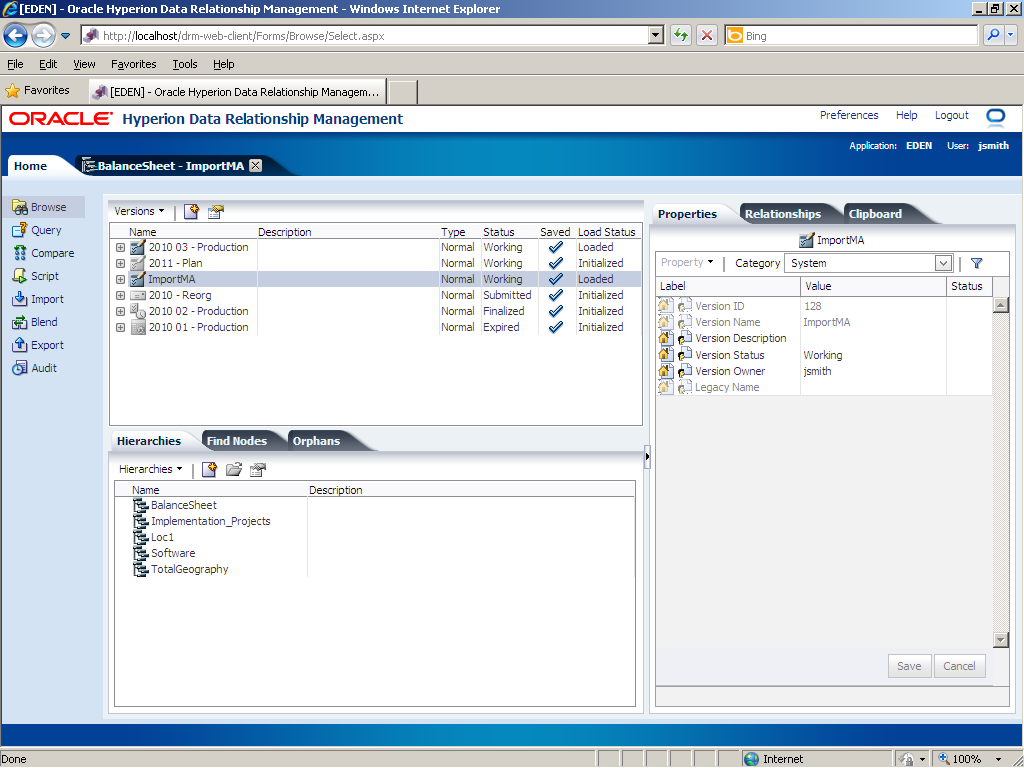
In the Version Name field, enter ImportMA.
|
. |
Click the Save (
Use the Save Import dialog box to specify a name and description for the import, and select an object access level.
|
. |
In the Save Import dialog box, perform the following actions:
|
. |
Click OK.
The tab name is displayed as ImportMA. |
. |
Close the ImportMA tab.
Your import is listed in the Import task group under Standard Imports.
|
 ) button.
) button.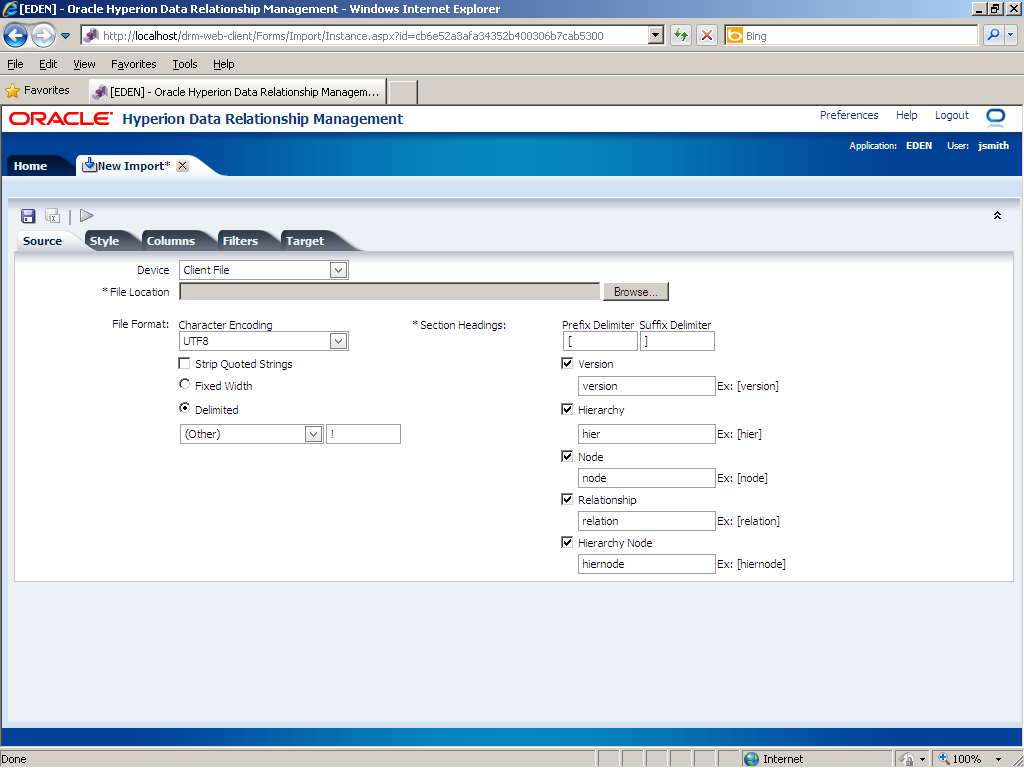
 ) button.
) button.
 ) button.
) button.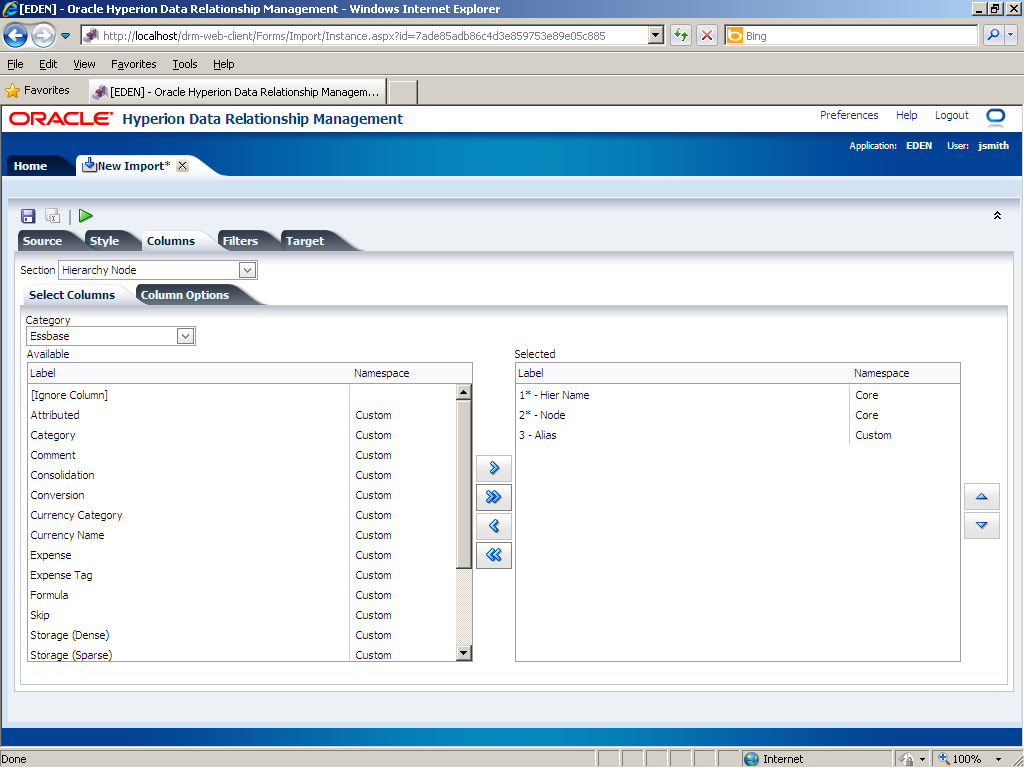
 ) button.
) button.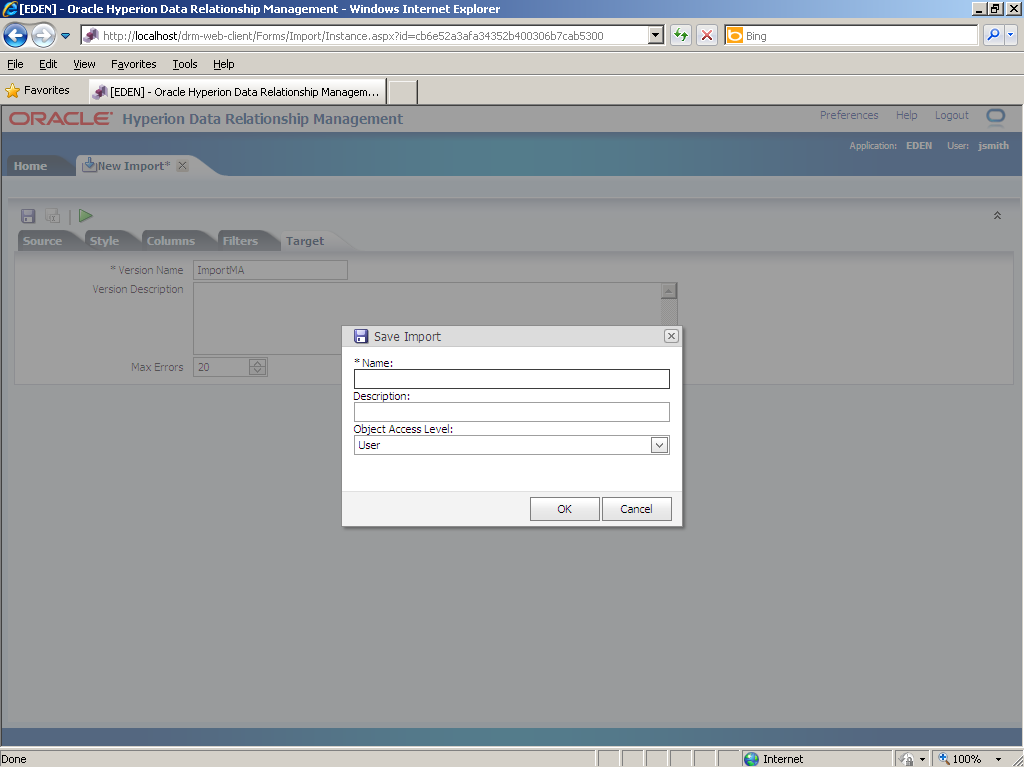
Running an Import
In this topic, you run an import.
. |
Click the standard import named ImportMA.
|
|---|---|
. |
Point to the Imports drop-down list.
|
. |
In the Imports drop-down list, select Open.
Use the import wizard to modify the source, style, columns, filters, and target of the import named ImportMA.
|
. |
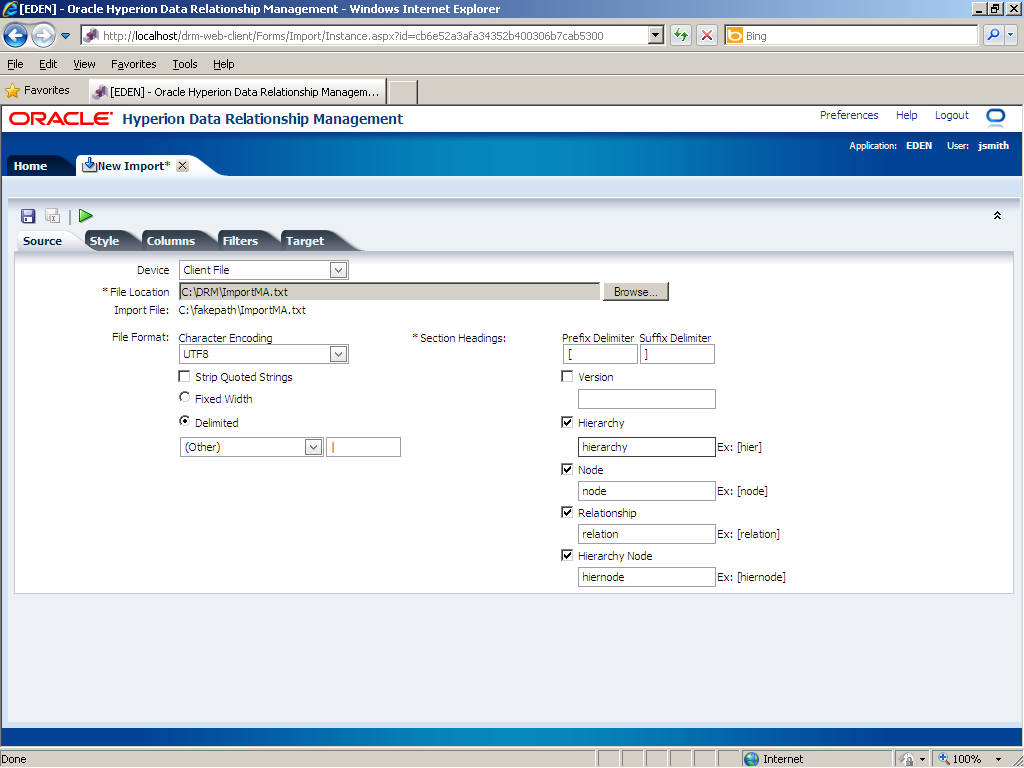
Click the Browse... button to select an import file for the source file. Note: You must select an import file each time you run an import.
Use the Choose File to Upload dialog box to browse to and select an import file.
|
. |
Click the ImportMA.txt file.
|
. |
Click Open.
|
. |
Click the Run (
The processing results are displayed. They indicate the completion status of the process; the statistics for errors; the statistics for hierarchies, nodes, and orphans that were created; and warning and error messages. In this example, the import was completed successfully and you have no warnings or error messages. The statistics show that 5 hierarchies, 123 nodes, and 2 orphan nodes were added. No duplicate nodes were found.
|
. |
Close the import.
|
. |
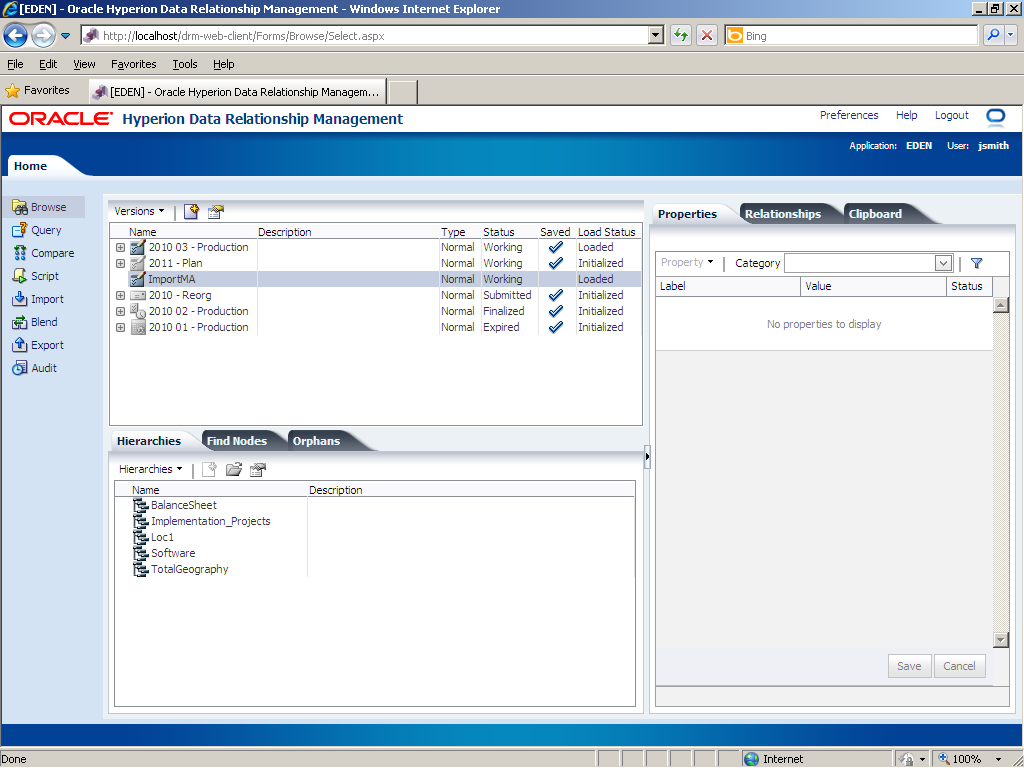
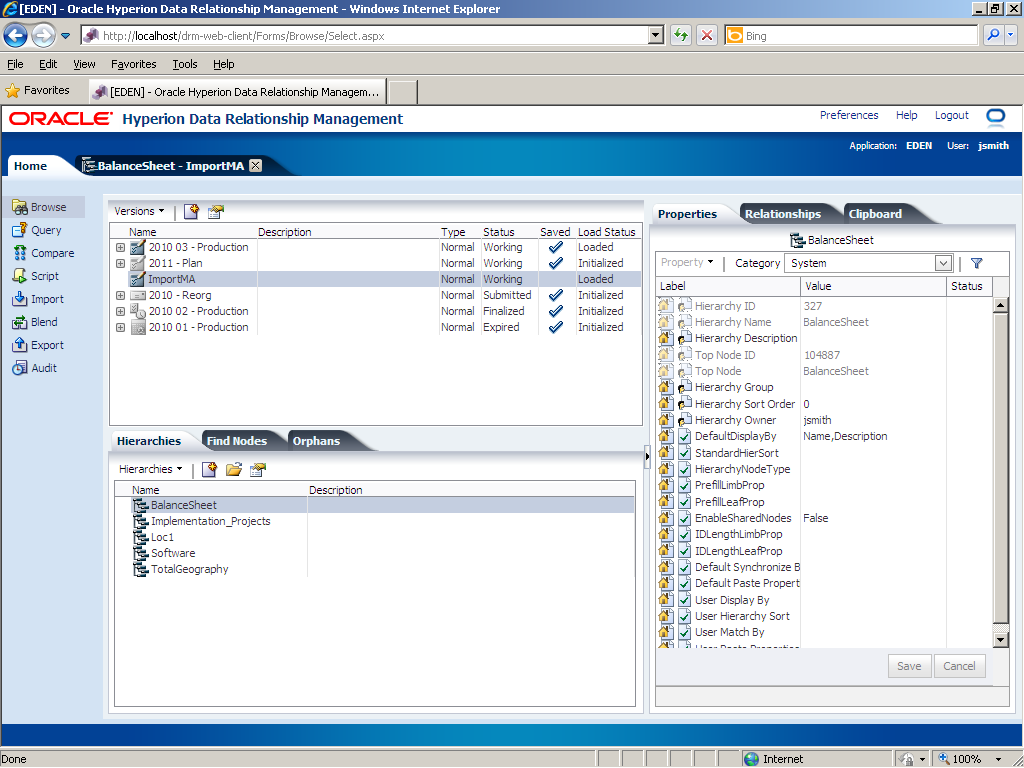
Click Browse to navigate to the Browse task group.
The ImportMA version is listed in the version list in the Browse task group. It is created in a detached state (not saved).
|
. |
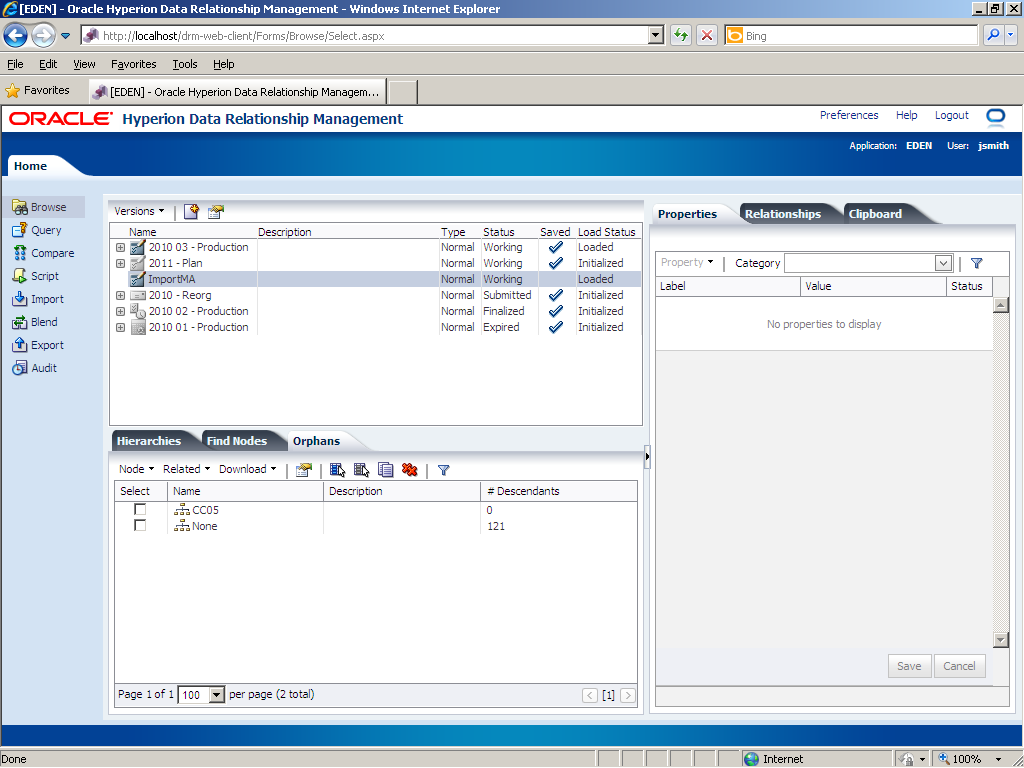
Click the Orphans tab.
The import added two orphan nodes (CC05 and None).
|
. |
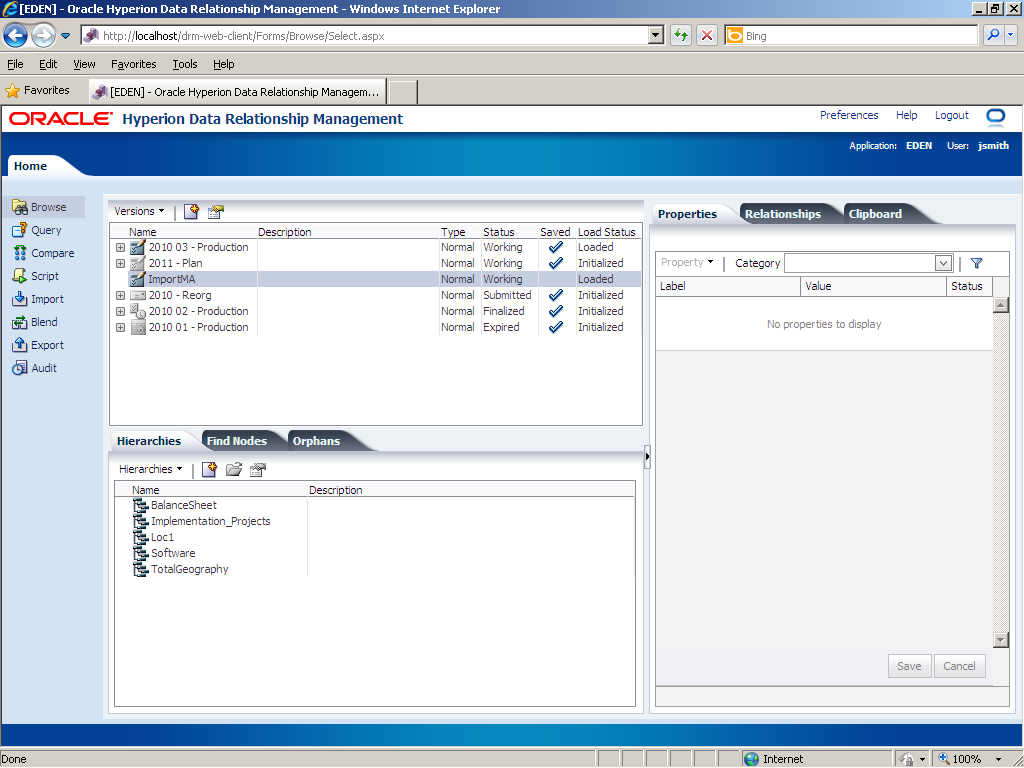
Click the Hierarchies tab.
|
. |
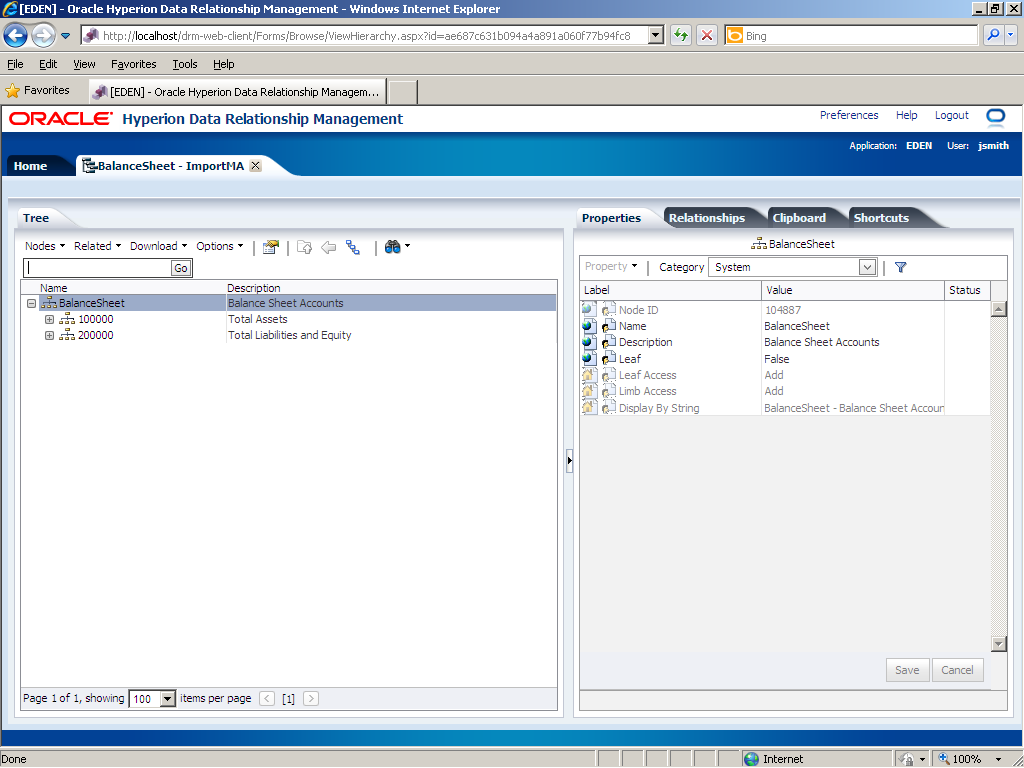
Click the BalanceSheet tab to open a hierarchy that was created by the import.
Use the BalanceSheet - ImportMA hierarchy tab to view and manage nodes in the BalanceSheet hierarchy.
|
. |
Click the Home tab.
You determined that the import created what you expected. Now you can save the version.
|
. |
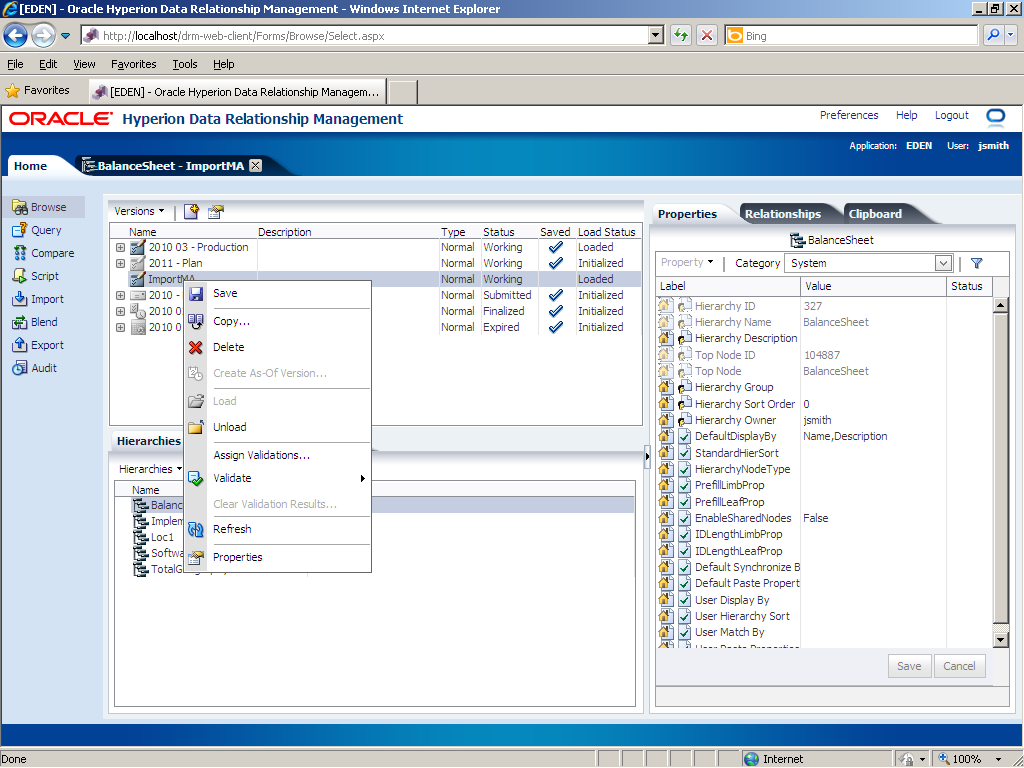
Right-click the ImportMA version.
|
. |
Click Save.
The ImportMA version is saved to the repository database.
|
 ) button to process the import.
) button to process the import.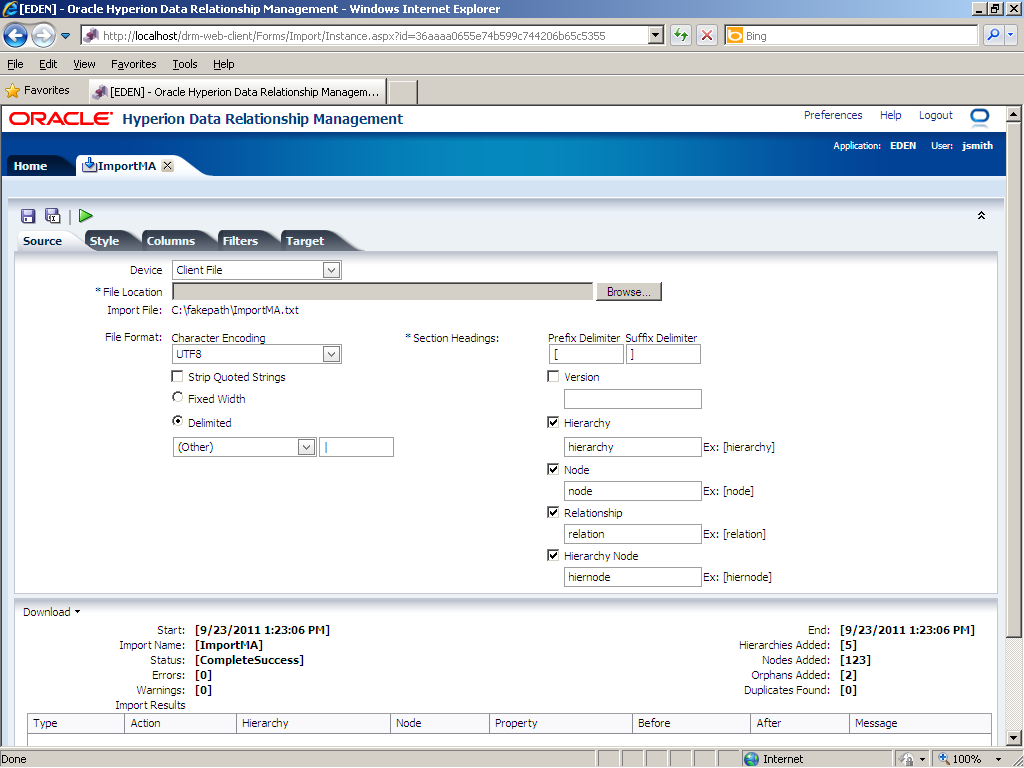
Summary
In this tutorial, you have learned how to create and run an import.
Resources
- Oracle EPM System, Fusion Edition 11.1.2.1 Documentation Library
- To learn more about Data Relationship Management, refer to additional OBEs in the OLL Web site
![]()