Pivot e Unpivot
Uma das principais características de Oracle Database
Pivot e Unpivot
Apresente informações em um relatório com referências cruzadas com formato de planilha eletrônica a partir de qualquer tabela relacional usando código SQL simples, e armazene dados de uma tabela com referências cruzadas em uma tabela relacional.
Ver Índice da série (em inglês)
Pivot
Como você sabe, as tabelas relacionais são apresentadas em pares de coluna e valor. Vamos considerar o caso
de uma tabela chamada CUSTOMERS.
SQL> desc customers
Name Null? Type
------------------------------------------------------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
STATE_CODE VARCHAR2(2)
TIMES_PURCHASED NUMBER(3)
Quando essa tabela é selecionada:
select cust_id, state_code, times_purchased
from customers
order by cust_id;
Os dados de saída são apresentados assim:
CUST_ID STATE_CODE TIMES_PURCHASED
------- ---------- ---------------
1 CT 1
2 NY 10
3 NJ 2
4 NY 4
...
etc. ...
Observe que os dados são representados como linhas de valores: para cada cliente: o registro mostra seu estado de residência e as vezes que ele comprou na loja. À medida que o cliente compra novos itens na loja, a coluna times_purchased é atualizada.
Agora vamos ver como poderia se obter um relatório da frequência de compras por estado, isto é, quantos clientes compraram algo só uma vez, duas vezes, três vezes, etc., de cada estado. Na versão comum do SQL, é possível incluir a seguinte instrução:
select state_code, times_purchased, count(1) cnt
from customers
group by state_code, times_purchased;
Os dados de saída são apresentados assim:
ST TIMES_PURCHASED CNT
-- --------------- ----------
CT 0 90
CT 1 165
CT 2 179
CT 3 173
CT 4 173
CT 5 152
...
etc. ...
Essas são as informações que você precisa, mas seu formato torna a leitura difícil. Uma melhor maneira de apresentar os mesmos dados pode ser mediante relatórios com referências cruzadas, nos quais os dados podem ser organizados verticalmente e a lista de estados, horizontalmente, como em uma folha de cálculo.
Times_purchased
CT NY NJ ...
etc. ...
1 0 1 0 ...
2 23 119 37 ...
3 17 45 1 ...
...
etc. ...
Antes do surgimento do Oracle Database 11 g, para realizar essa ação era necessário usar algum tipo de função de decodificação para cada valor e escrever cada valor como coluna independente. Porém, essa técnica não é muito intuitiva.
Felizmente, agora há uma nova e útil característica, PIVOT, para reordenar dados e apresentar os resultados das consultas como tabela de referências cruzadas, com o operador pivot. A sintaxe da consulta é a seguinte:
select * from (
select times_purchased, state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
order by times_purchased
/
Os dados de saída são apresentados assim:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ---------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
... etc. ...
É possível ver no exemplo a praticidade do operador pivot. Os valores de state_code são apresentados na linha de cabeçalho, e não em uma coluna. A seguir, ilustra-se a mesma saída em formato de tabela tradicional:

Figura 1: Representação em tabela tradicional
Em um relatório com referências cruzadas, deseja-se transferir a coluna Times Purchased para a linha de
cabeçalho, como ilustrado na Figura 2. A coluna é transformada em linha, como se fosse rotada 90º no sentido
anti-horário, e passa a ser o cabeçalho. Essa rotação figurada deve ter um ponto de giro e, neste caso, esse
ponto é a expressão count(state_code).
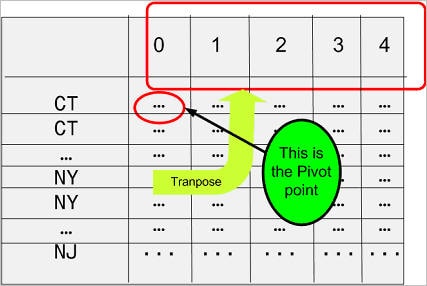
Figura 2 Representação reordenada
A seguir, detalha-se a expressão que deve ser incluída na consulta:
...
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
...
A segunda linha, for state_code ..., restringe a consulta aos valores enumerados.
Essa linha é necessária, pois, infelizmente, todos os valores possíveis devem ser conhecidos com
antecedência. Essa restrição é mais laxa no formato XML da consulta, que será apresentado abaixo, neste
artigo.
Observem-se as linhas de cabeçalho na saída:
. TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ---------- ---------- ---------- ----------
Os cabeçalhos de cada coluna são os dados da própria tabela: os códigos de estado. Embora esses códigos sejam bastante conhecidos, alguém poderia preferir mostrar os nomes dos estados em lugar dos códigos ("Connecticut" em lugar de "CT"). Nesse caso, é necessário fazer um pequeno ajuste na cláusula FOR da consulta, como mostrado abaixo:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY' as "New York",'CT' "Connecticut",'NJ'
"New Jersey",'FL' "Florida",'MO' as "Missouri")
)
order by 1
/
Puchase Frequency New York Connecticut New Jersey Florida Missouri
----------------- ---------- ----------- ---------- ---------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
,
etc. ...
A cláusula FOR pode incluir pseudônimos para esses valores, que serão transformados nos cabeçalhos de coluna.
Unpivot
Da mesma forma em que há matéria e antimatéria, para pivot deve existir unpivot, certo?
Falando sério, a necessidade de contar com um operador inverso a pivot é uma realidade. Vamos supor que você tem uma folha de cálculo com o relatório de referências cruzadas mostrado abaixo:
Purchase Frequency |
New York |
Connecticut |
New Jersey |
Flórida |
Missouri |
0 |
12 |
11 |
1 |
0 |
0 |
1 |
900 |
14 |
22 |
98 |
78 |
2 |
866 |
78 |
13 |
3 |
9 |
... |
. |
|
|
|
|
Agora você quer carregar os dados em uma tabela relacional chamada CUSTOMERS:
SQL> desc customers
Name Null? Type
----------------------------------------- -------- ---------------------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(20)
STATE_CODE VARCHAR2(2)
TIMES_PURCHASED NUMBER(3)
Os dados da planilha eletrônica devem ser passados do formato normalizado para um formato relacional, para depois serem armazenados. Claro que pode se usar uma complexa sequência de código SQL*:Loader ou SQL recorrendo a DECODE para carregar os dados na tabela CUSTOMERS. Ou pode se usar a operação inversa a pivot —UNPIVOT— para dividir as colunas e transformá-las em linhas; isto é possível no Oracle Database 11g.
É mais simples mostrar esta operação com um exemplo: Primeiro, vamos gerar uma tabela de referências cruzadas com a operação pivot:
1 create table cust_matrix
2 as
3 select * from (
4 select times_purchased as "Puchase Frequency", state_code
5 from customers t
6 )
7 pivot
8 (
9 count(state_code)
10 for state_code in ('NY' as "New York",'CT' "Conn",'NJ' "New Jersey",'FL' "Florida",
'MO' as "Missouri")
11 )
12* order by 1
É possível conferir como os dados são armazenados na tabela:
SQL> select * from cust_matrix
2 /
Puchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ---------- ---------- ---------- ---------
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
... etc. ...
Os dados na folha de cálculo da seguinte forma: Cada estado é uma coluna da tabela ("New York", "Conn", etc.).
SQL> desc cust_matrix
Name Null? Type
----------------------------------------- -------- ---------------------------
Puchase Frequency NUMBER(3)
New York NUMBER
Conn NUMBER
New Jersey NUMBER
Florida NUMBER
Missouri NUMBER
Os dados da tabela devem ser separados para que as linhas só mostrem o código de estado e as contagens para cada estado. Isto é possível com o operador unpivot como mostrado abaixo:
select *
from cust_matrix
unpivot
(
state_counts
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
)
order by "Puchase Frequency", state_code
/
Os dados de saída são apresentados assim:
Puchase Frequency STATE_CODE STATE_COUNTS
----------------- ---------- ------------
1 Conn 165
1 Florida 0
1 Missouri 0
1 New Jersey 0
1 New York 33048
2 Conn 179
2 Florida 0
2 Missouri 0
...
etc. ...
Observe-se que cada nome de coluna se transformou em um valor na coluna STATE_CODE. Como o Oracle soube que state_code é um nome de coluna? Porque isso é indicado na seguinte cláusula da consulta:
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
Nela, especifica-se que os valores "New York", "Conn", etc. correspondem a uma nova coluna, state_code, sobre a qual deseja-se aplicar a operação unpivot. Observe uma parte dos dados originais:
Purchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ---------- ---------- ---------- - ---------
1 33048 165 0 0 0
Ao transformar a coluna "New York" em um valor de linha, em qual coluna deveria se mostrar o valor 33048? Essa pergunta é respondida na cláusula logo acima da cláusula FOR do operador unpivot na consulta do exemplo. Como se especificou state_counts, esse é o nome da nova coluna criada na saída.
Unpivot pode ser a ação oposta a pivot, mas a primeira não necessariamente reverte os efeitos da segunda. Por exemplo, no caso mostrado, uma nova tabela, CUST_MATRIX, foi criada aplicando a operação pivot na tabela CUSTOMERS. A seguir, aplicou-se unpivot à tabela CUST_MATRIX, mas essa operação não recuperou todos os dados da tabela CUSTOMERS original. O relatório com referências cruzadas mostrou-se de forma diferente para poder ser carregado em uma tabela relacional. Então, unpivot não serve para desfazer o que o operador pivot faz, o que deve ser considerado caso você queira gerar uma tabela com essa operação e descartar a original.
Alguns dos interessantes usos de unpivot vão além da poderosa manipulação de dados mostrada no exemplo acima. O diretor do programa Oracle ACE na Amis Technologies Lucas Jellema mostrou como podem ser geradas linhas de dados específicos para fins de teste (conteúdo em inglês). Aqui vamos transcrever uma forma levemente alterada do código original para gerar vogais do alfabeto inglês:
select value
from
(
(
select
'a' v1,
'e' v2,
'i' v3,
'o' v4,
'u' v5
from dual
)
unpivot
(
value
for value_type in
(v1,v2,v3,v4,v5)
)
)
/
Os dados de saída são apresentados assim:
V
-
a
e
i
ou
s
Este modelo pode ser aplicado a qualquer tipo de gerador de linhas. Obrigado, Lucas, por ter nos mostrado este truque bacana.
Tipo XML
No exemplo anterior, foi necessário especificar os códigos de estado válidos para state_code:
for state_code in ('NY','CT','NJ','FL','MO')
Para isso, os valores presentes na coluna state_code devem ser conhecidos com antecedência. Se os valores disponíveis não são conhecidos, como a consulta é criada?
Há outra cláusula na operação pivot, XML, que permite gerar a saída reordenada como código XML no qual é possível incluir uma cláusula especial, ANY, em lugar de valores literais. Segue um exemplo:
select * from (
select times_purchased as "Purchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (any)
)
order by 1
/
A saída é apresentada em formato CLOB (objeto grande de caracteres), portanto, antes de executar a consulta, é conveniente conferir que tenha sido alocado um valor grande a LONGSIZE.
SQL> set long 99999
Há duas diferenças claras (marcadas em negrito) entre esta consulta e a operação pivot original. Primeiramente, foi especificada uma cláusula, pivot xml, em lugar de usar somente o operador pivot. Assim, a saída tem formato XML. Segundo, a cláusula FOR inclui for state_code in (any) em lugar de uma extensa lista de valores possíveis para state_code. A notação em XML permite usar a palavra-chave ANY, para assim evitar a necessidade de digitar os valores de state_code. Os dados de saída são apresentados assim:
Purchase Frequency STATE_CODE_XML
---------------------- --------------------------------------------------
1 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">165</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33048</colu
mn></item></PivotSet>
2 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">179</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33151</colu
mn></item></PivotSet>
... etc. ...</p>
Como é possível ver, a coluna STATE_CODE_XML é XMLTYPE, e o elemento raiz é . Cada valor é representado como um par de elementos nome e valor. Os dados de saída podem ser usados em qualquer analisador de XML para gerar saídas mais úteis.
Além da cláusula ANY, é possível incluir uma subconsulta. Vamos supor que você quer trabalhar com alguns estados preferidos; para isso, é necessário selecionar apenas as colunas relativas a esses estados. Os estados preferidos foram digitados em uma nova tabela chamada preferred_states:
SQL> create table preferred_states
2 (
3 state_code varchar2(2)
4 )
5 /
Table created.
SQL> insert into preferred_states values ('FL')
2> /
1 row created.
SQL> commit;
Commit complete.
Agora, a operação pivot tem a seguinte sintaxe:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (select state_code from preferred_states)
)
order by 1
/
A subconsulta da cláusula FOR pode incluir o que você quiser. Por exemplo, se você quer selecionar todos os registros sem restrições relativas a estados preferidos, pode usar o seguinte código como cláusula FOR: for state_code in (select distinct state_code from customers)
A subconsulta deve retornar valores diferenciados; caso contrário, a consulta não funcionará. Por isso incluímos a cláusula DISTINCT no exemplo.
Conclusão
Pivot adiciona uma funcionalidade muito importante e prática à linguagem SQL. Em lugar de criar um código complicado e pouco intuitivo com muitas funções de decodificação, é possível usar a função pivot para criar um relatório com referências cruzadas a partir de qualquer tabela relacional. Da mesma forma, é possível transformar qualquer relatório com referências cruzadas para ser armazenado como tabela relacional mediante a operação unpivot. Pivot pode produzir dados de saída em formato de texto comum ou XML.
No segundo caso, não é necessário informar o domínio de valores entre os quais a operação pivot vai procurar.
Mais informações sobre as operações pivot e unpivot disponíveis em Oracle Database 11g SQL Language Reference (Material de referência sobre a linguagem do Oracle Database 11g) (em inglês).