MySQL HeatWave
Improve MySQL query performance by orders of magnitude and get real-time analytics on your transactional data—without the complexity, latency, risks, and cost of extract, transform, and load (ETL) duplication to a separate analytics database. Use automated, integrated, and secure generative AI and machine learning (ML) in one cloud service for transactions and lakehouse scale analytics.
MySQL Global Forum: Celebrating 30 Years of MySQL
Watch the recorded webcast at your convenience. Hear about MySQL best practices from community experts and learn about new enhancements for developer productivity, cloud services, GenAI, and more.
-
![]() Rich insights without complex data movement
Rich insights without complex data movement
NTT Solmare improved marketing campaigns and uncovered new revenue opportunities.
-
![]() Free MySQL HeatWave workshop
Free MySQL HeatWave workshop
Request a free expert-led workshop to evaluate MySQL HeatWave or get started with it.
-
![]() SmarterD speeds product roadmap by 12 months
SmarterD speeds product roadmap by 12 months
Learn how SmarterD fast-tracked its roadmap by 12 months and went from development to production in only one month using MySQL HeatWave GenAI.



Why use MySQL HeatWave?
A fully managed database service
- Power your most demanding OLTP workloads with the only cloud service built on MySQL Enterprise Edition, featuring real ACID compliance, high concurrency, and advanced security, including encryption, data masking, and a database firewall.
- Boost MySQL query performance with the only MySQL cloud service integrating the MySQL HeatWave in-memory query accelerator. Get real-time analytics on your transactional data without ETL duplication to a separate analytics database.
- Deploy MySQL HeatWave in your choice of public clouds: Oracle Cloud Infrastructure (OCI), Amazon Web Services (AWS), or Microsoft Azure.

Simplify AI innovation with built-in LLMs, vector store, and ML
- Use in-database large language models (LLMs) to instantly benefit from generative AI and have contextual conversations informed by your unstructured documents using natural language. Choose external LLMs, if needed, for your use case.
- Get more accurate and contextually relevant answers by letting LLMs search your proprietary documents—without AI expertise or moving data to a separate vector database. MySQL HeatWave Vector Store is integrated and automates embedding generation.
- Easily build, train, and explain ML models using data in object storage and MySQL Database. No separate ML cloud service or expertise is required.
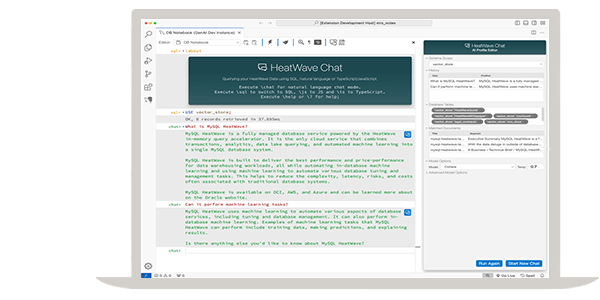
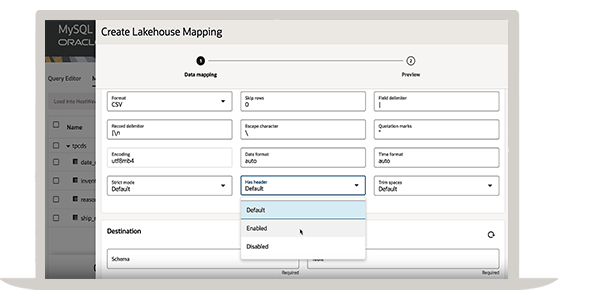
Get faster insights with the best performance for data warehouse and lakehouse workloads
- Eliminate the complexity, latency, cost, and risks of ETL duplication across separate analytics database and lakehouse services.
- Query data in object storage, MySQL databases, or a combination of both.
MySQL HeatWave customer successes








Featured MySQL HeatWave use cases
-
Get real-time marketing analytics
See how MySQL HeatWave enables digital marketing agency customers to send the right offer to the right prospect via the right channel at the right time—and provides real-time campaign performance analytics to make the best decisions.
Learn more about real-time marketing analytics with MySQL HeatWave
-
Scale startups while reducing costs
Discover why numerous fast-growing, cloud native organizations migrate to MySQL HeatWave to overcome their growing pains—improving performance, scalability, security, and productivity while reducing costs.
-
Deliver fintech solutions
The technology that fintechs rely on often determines their ability to deliver an innovative solution with the performance, scalability, security, reliability, and cost efficiency that will sway customers. Learn why fintech startups migrate to MySQL HeatWave.
Learn more about fintech solutions with MySQL HeatWave
-
Gain a competitive edge for ISV applications
For ISVs delivering SaaS applications, selecting the right cloud platform is crucial since it represents the foundation on which their applications are built and has a large impact on how well they can serve customers. See why MySQL HeatWave has become a popular choice for ISVs.
Common challenges when using Generative AI and ML, and how to help address them with HeatWave
Bertrand Matthelie, Senior Principal Product Marketing Director, Oracle
HeatWave GenAI provides integrated, automated, and secure generative AI with in-database LLMs; an automated, in-database vector store; scale-out vector processing; and the ability to have contextual conversations in natural language—letting you take advantage of generative AI without AI expertise and data movement.
See what top industry analysts say about MySQL HeatWave
-
![Moor Insights and Strategy logo]()
“In many ways, MySQL HeatWave is the very essence of what the cloud is about—commodity infrastructure architected in a scale-out fashion, enabling the best performance and price-performance for a given workload.”
Matt Kimball
Vice President and Principal Analyst, Moor Insights & Strategy -
![IDC logo]()
“Organizations looking for the best value in the cloud data lakehouse landscape must seriously consider MySQL HeatWave Lakehouse.”
Carl Olofson
Research Vice President, Data Management Software, IDC -
![Constellation Research logo]()
“Oracle’s seamless integration of GenAI and vector store into MySQL HeatWave transforms GenAI from a science project into a useful business tool and a platform for developers.”
Holger Mueller
VP and Principal Analyst, Constellation Research -
![The Futurum Group logo]()
“The in-database MySQL HeatWave AutoML makes Redshift ML look like yesterday’s tech in terms of engineering, performance and cost.”
Ron Westfall
Senior Analyst and Research Director, Futurum




Resources

Documentation
MySQL HeatWave is a massively parallel, high performance, in-memory query accelerator that increases MySQL performance by orders of magnitude for analytics and mixed workloads—without any changes to existing applications.

Cloud learning
Get the most out of MySQL HeatWave with a learning subscription.
Webinar series

Support and services
Get 24/7 access to support with My Oracle Support.
Get started with MySQL HeatWave
Learn with step-by-step guidance
Experience MySQL HeatWave at your own pace with step-by-step instructions.
Free MySQL HeatWave workshop
Request a free expert-led workshop to evaluate or get started with MySQL HeatWave.
Migrate to MySQL HeatWave on OCI or AWS
Access free step-by-step migration guides outlining best practices, technical training resources, and expert guidance from Oracle engineers and partners.
Sign up for the service
Sign up for a free trial of MySQL HeatWave. You’ll get access to free resources for an unlimited time.
Contact sales
Interested in learning more about MySQL HeatWave? Let one of our experts help.