Erstellen eines Provisionierungsprofiles
Navigieren Sie über "Enterprise"->"Database Cloud"->"Home" zur Homepage der Datenbank Cloud.
Die Datenbank Cloud HomePage ist am Anfang leer. Sie dient zur Übersicht der Anforderungen, Fehler, Performance etc.
Das eigentliche Setup wird aber nicht hier vorgenommen, die Seite wird später (nach dem Anlegen der Cloud) zum Prüfen des Setups/Checken der Logs benötigt.
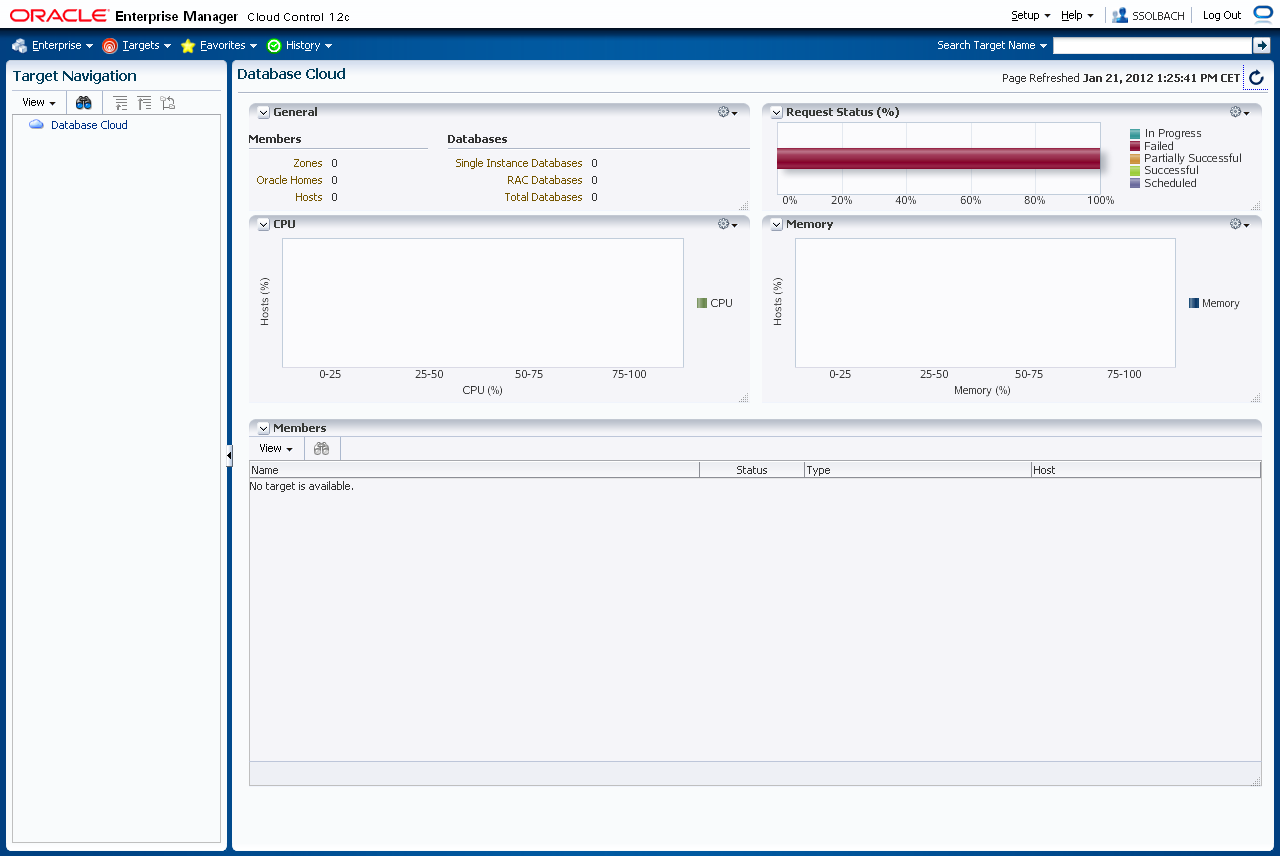
Zur Vorbereitung muss ein Datenbank Provisionierungsprofil erstellt werden. Letztendlich ist dies ein Datenbank Template, welches für die Benutzung durch die Self Service Anwendung angepasst wird.
Wichtig: Die Anweisungen im Handbuch, welche Optionen später "gelocked", also im Profil nicht von den Usern angepasst werden müssen, sind sehr restriktiv. Hat man darin eine Abweichung, funktioniert der Self Service Vorgang später nicht. Leider ist der Fehler in den Logdateien von Enterprise Manager später auch sehr schwer zu finden.
Deswegen sollte hierauf insbesondere geachtet werden.
Navigieren Sie zu "Enterprise" -> "Provisioning" -> "Database Provisioning".
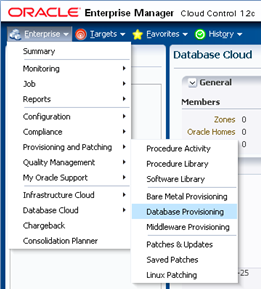
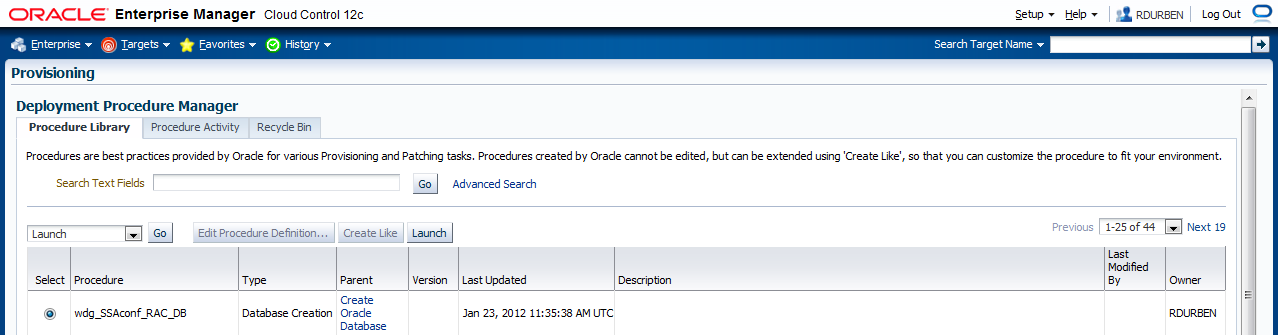
Auf der Seite "Database Provisioning" ist die Prozedur "Create Oracle Database" der Ausgangspunkt für alle DBaaS Cloud Setup Szenarien.
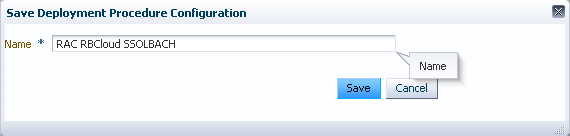
Egal ob Single Instance oder RAC. Sie erstellen eine neue Prozedur, jedoch nicht über "Edit" oder "Create like", sondern mit "Launch". Dieser Umstand kann etwas verwirrend sein,
da die Prozedur nicht wirklich ausgeführt wird, sondern nur angepasst werden soll.
Wie Sie aber später sehen, wird die Ausführung nur angedeutet und die Prozedur dann gespeichert.
Klicken Sie auf die Prozedur und dann auf "Launch".
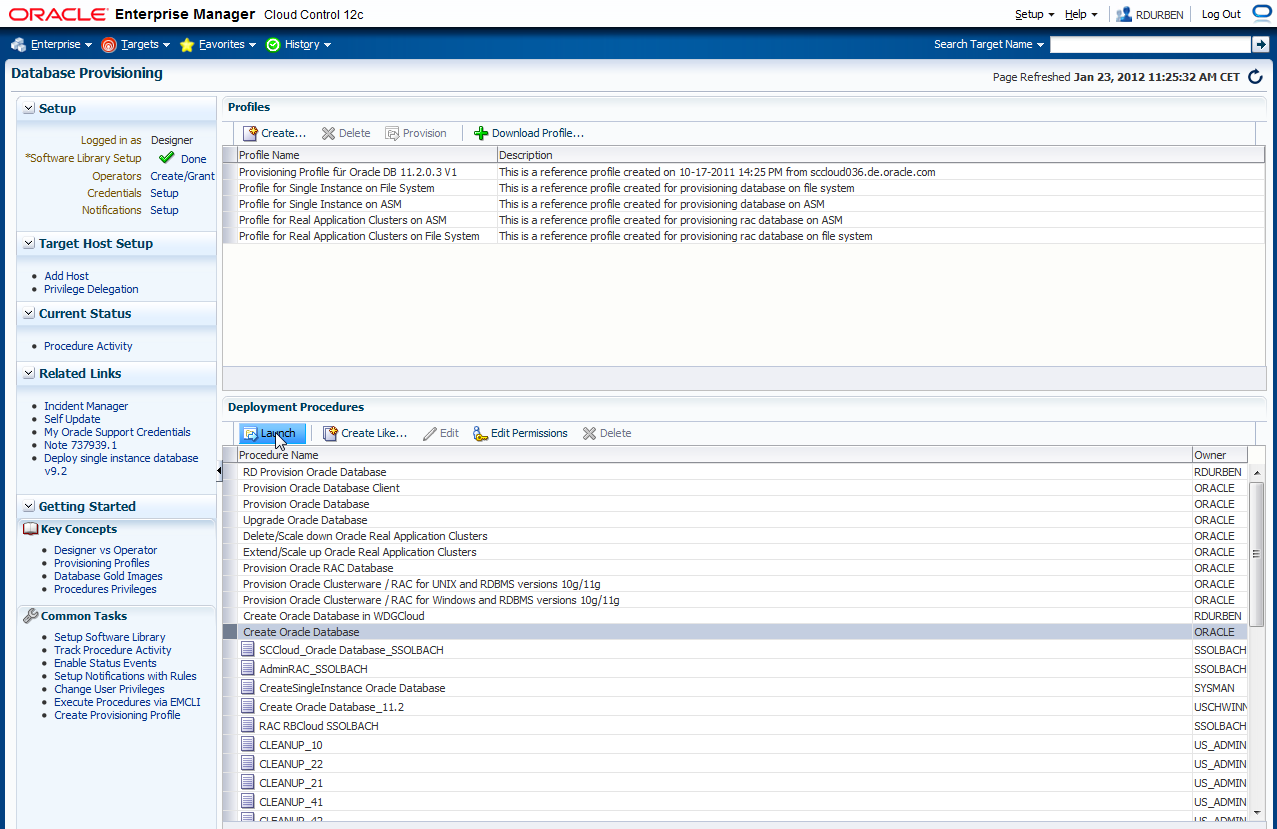
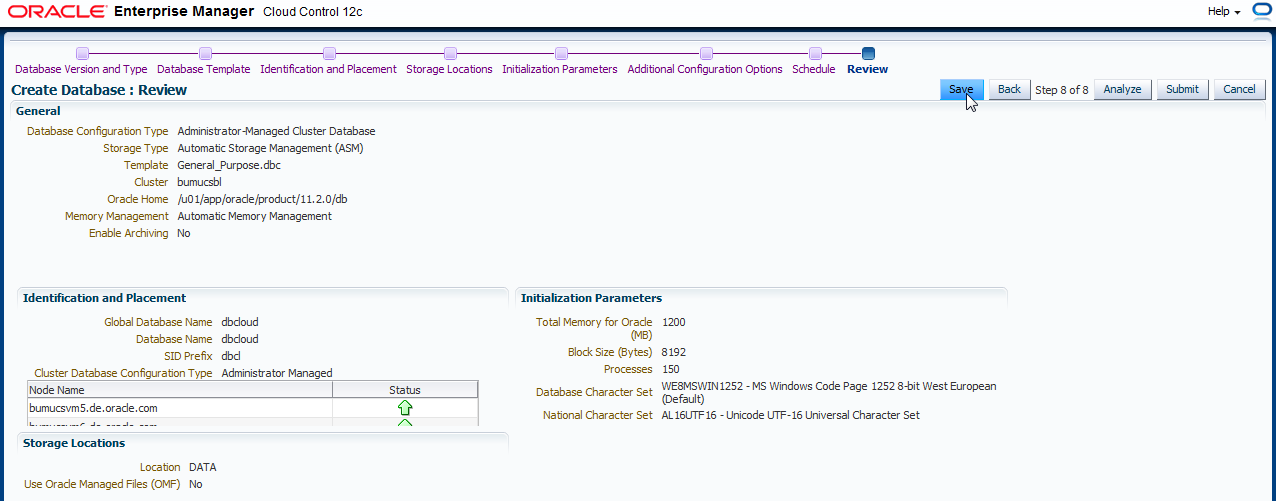
Sie gelangen in einen Wizard. Im ersten Schritt wählen Sie die Datenbankversion aus. Diese Version der Oracle Datenbank muss später auf den Servern installiert sein. Des Weiteren geben Sie den Datenbanktyp an (Single Instance, RAC oder RAC One Node). In diesem Beispiel soll mit RAC Datenbanken gearbeitet werden. Schließen Sie das Schloß bei "database version" und beim "database type" mit einem Klick auf das Schloßsymbol.
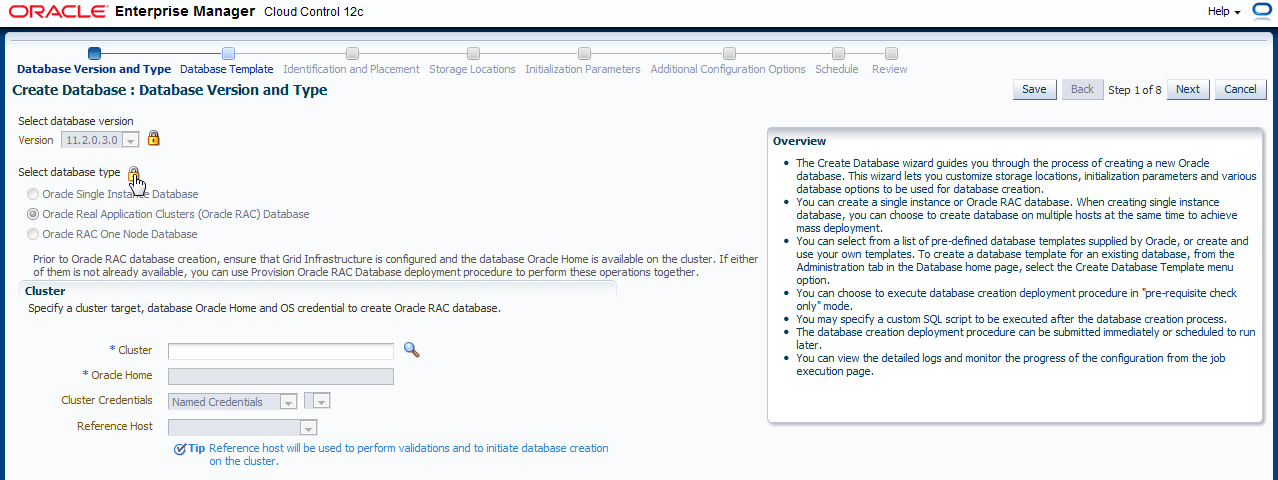
Tragen Sie nun den Cluster ein, auf dem die RAC Datenbanken laufen werden. Klicken Sie auf die Lupe neben dem Feld "Cluster".
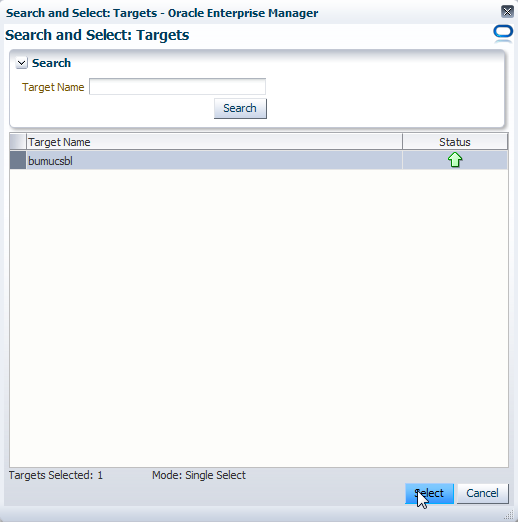
Die verfügbaren Cluster mit vorbereiteter Grid Infrastruktur (passend zur eben angegebenen Datenbankversion) werden angezeigt. Wählen Sie den Cluster aus und klicken auf "Select".
Wählen Sie das entsprechende Oracle Home auf dem Cluster. Klicken Sie auf die Lupe...
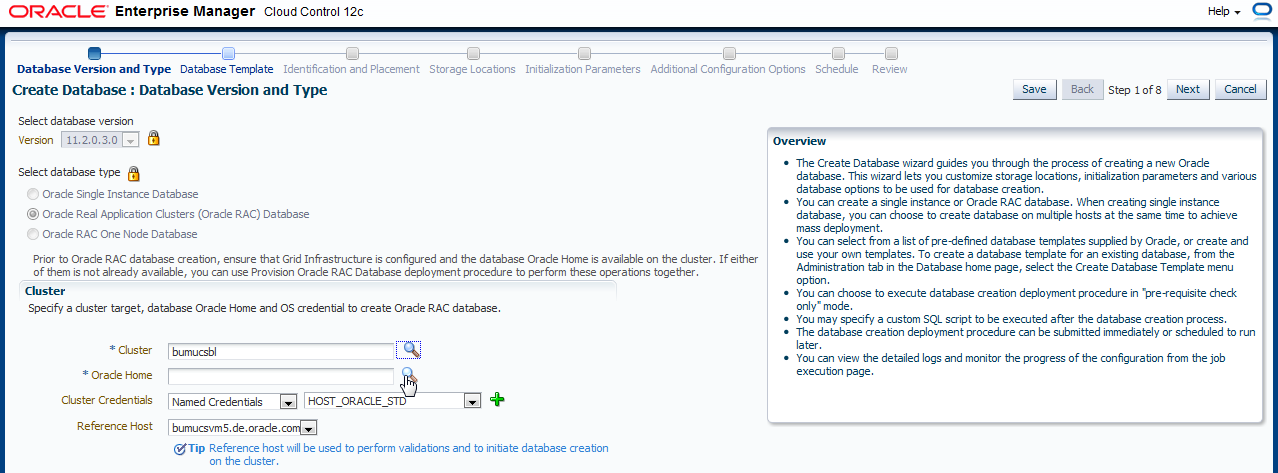
... und wählen das Oracle Home aus. Klicken Sie auf "Select".
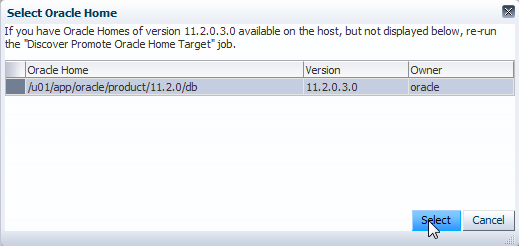
Jetzt geben Sie noch ein passendes Named Credential für den Oracle-Benutzer auf Betriebssystemebene an. Dazu ein wichtiger Hinweis: Diese dürfen keine Credentials sein, in denen SUDO Rechte definiert wurden. Ist dies der Fall kommt es beim Prüfen der DB-Home Installationen zu einem Fehler.
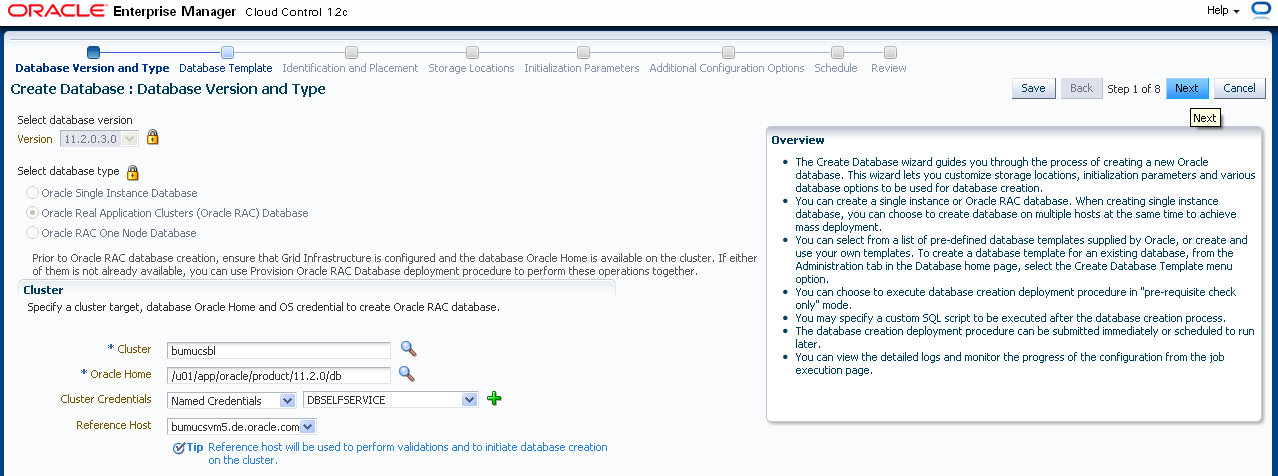
Dann legen Sie den Referenzknoten fest. Dieser Referenzknoten muss im Moment immer Online sein (auch bei einem RAC), da genau über diesen Knoten versucht wird die Datenbank zu deployen. Ist dieser unten, ist es nicht möglich einen anderen Agenten im RAC zu verwenden. Diese Einschränkung ist bekannt und wird sich in einer der nächsten EM Cloud Plugins ändern.
Wenn Sie alles eingegeben haben, klicken Sie auf "Next".
Der nächste Schritt braucht beim initialen Aufrufen etwas länger.
Hier wird der Referenzknoten (über den EM Agent) kontaktiert und die entsprechende Oracle Home Version/RAC Verfügbarkeit abgeprüft.
Des Weiteren wird nachgeschaut welche Templates auf dem Zielknoten (DBCA Templates) bereits verfügbar sind. Dieser Schritt kann eine Minute oder länger dauern.
Sollte man sich vertippt haben und Korrekturen anbringen müssen, ist dies kein Problem. Es wird dann nicht erneut so streng geprüft. D.h. die langen Wartezeiten treten beim Vor und Zurück navigieren nicht mehr auf.
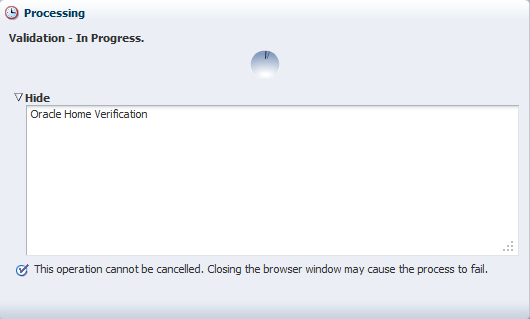
Im 2. Schritt des Deployments kann man ein Template vom DBCA des Referenz-/Zielknotens wählen. In unserem Fall nehmen wir eine General Purpose, da hier das Anlegen der Datenbank etwas schneller abläuft.
Es wäre ebenfalls möglich ein Template aus der sogenannten Software Library (einem zentralen Repository des Enterprise Managers) zu verwenden.
Allerdings wird dann beim Deployment immer erst das Template auf den Zielknoten kopiert, was die Geschwindigkeit beim Anlegen der Datenbank im Self Service Portal natürlich beeinflusst.
Damit hat man aber den Vorteil bei Änderungen des Templates, dieses nur an einer Stelle updaten zu müssen (falls es mehrere Clouds geben sollte).
Klicken Sie auf das Schloß von "Specify Template"...
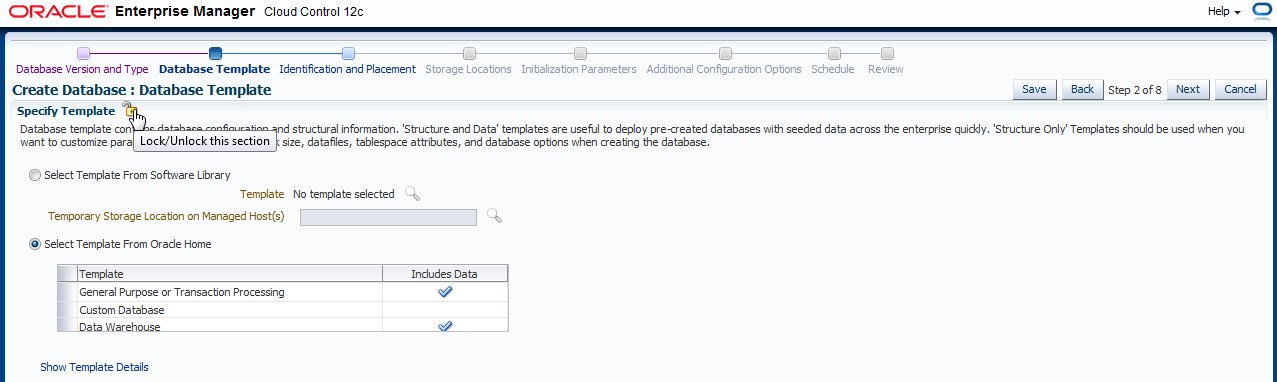
und klicken dann auf "Next".
Ob das Template verfügbar ist wird nun geprüft.
Ebenfalls ob dies auf allen Knoten des RACs zur Verfügung steht und welche weiteren Optionen dann beim Anlegen notwendig sind.
Diese werden dann in Schritt 3 angezeigt.
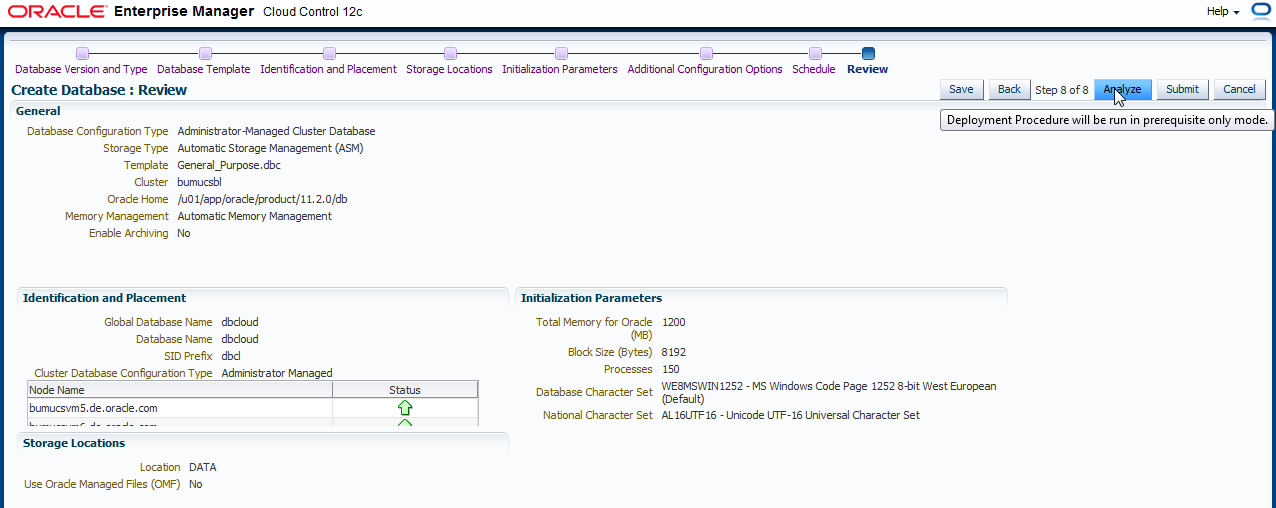
Auf der nächsten Seite kann man bei RAC den Konfigurationstyp auswählen: Policy Managed oder Administrator Managed. In der aktuellen Version unterstützt das Deployment im Self Service Umfeld nur Administrator Managed, da nur hiermit die größere Flexibilität vorhanden ist, wenn mehrere Datenbanken auf den Servern erstellt werden. Ansonsten müsste man bei der Überschneidung der Serverpools aufpassen und ausserdem hätte dies Auswirkungen, da der Enduser dann nicht mehr die Anzahl der Instanzen festelegen kann. Sie werden dies später im Self Service Portal sehen.
Wählen Sie dann die Knoten, auf denen die RAC-Datenbanken laufen können sollen.
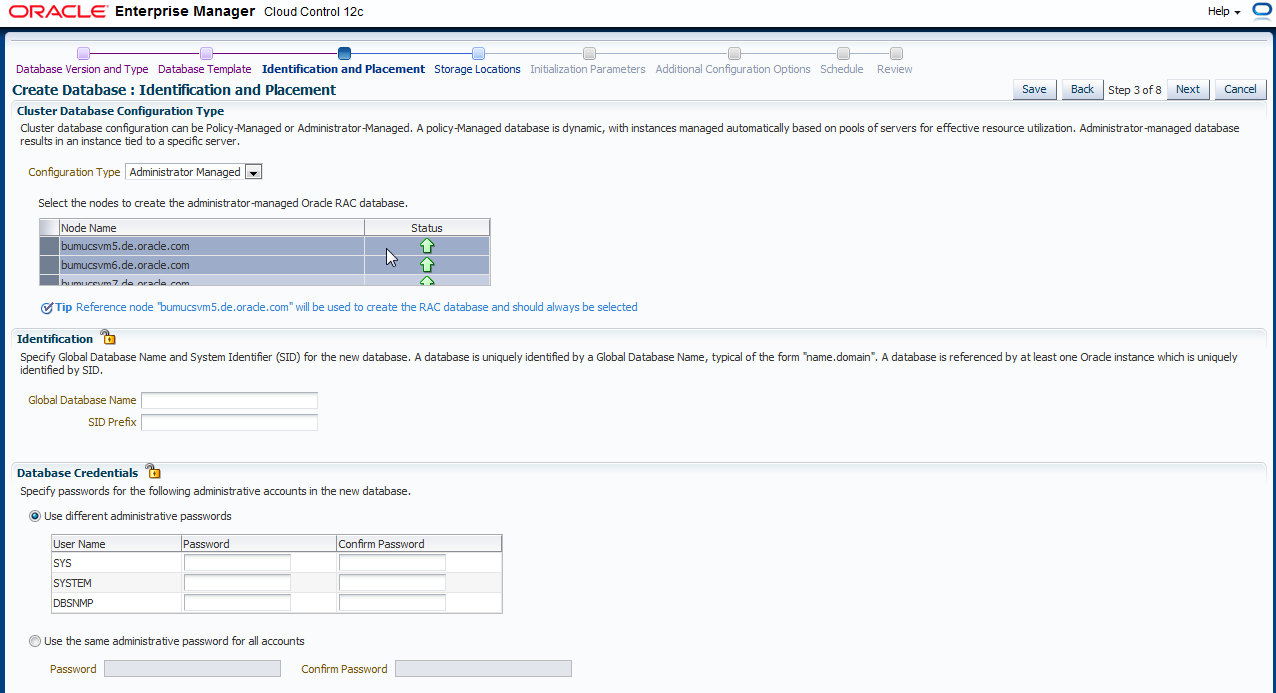
Die Eingabe von "Global Database Name", sowie "SID Prefix" sind unwichtig, da später ja mehrere Datenbanken bestellt werden und dieses überschrieben wird. Daher muss das Schloß auch geöffnet bleiben!
Anders mit den Credentials. Diese werden jetzt festgelegt, da SYS/SYSTEM und DBSNMP User dem Benutzer der Self Service Anwendung nicht bekannt gemacht werden. Schließen Sie das Schloß zu den "Database Credentials". Klicken Sie nach allen Eingaben auf "Next".
Wieder findet eine Prüfung statt.
Im nächsten Schritt wird der Speicherort der Datendateien festgelegt (beim RAC natürlich ASM). Des Weiteren die entsprechende Diskgruppe für Daten und die Fast Recovery Area. Archivelogging könnte ebenfalls eingeschaltet werden (dies ist notwendig, damit die Benutzer der Self Service Anwendung später auch ein Backup und Recovery Ihrer Datenbank durchführen dürfen). In unserem Fall ersparen wir uns den Overhead von Archive Logging.
Schließen Sie die Schlösser von "Storage Type" und "Recovery Files Location" und klicken auf "Next".
Wieder wird geprüft.
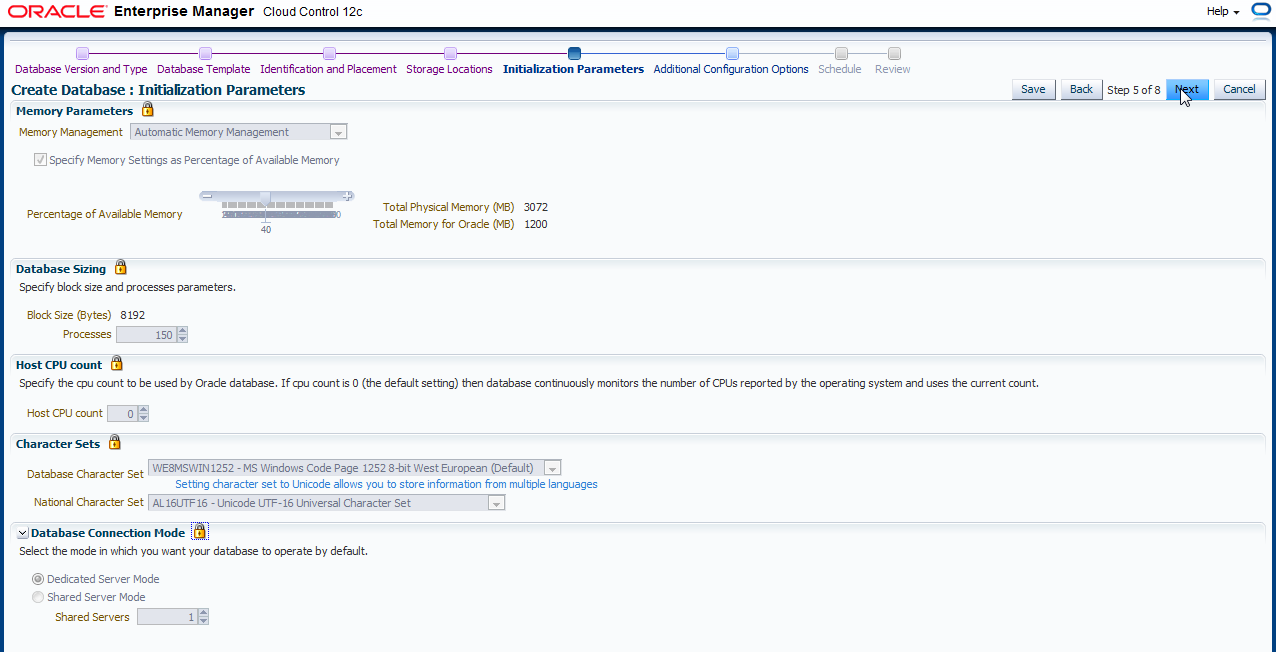
Vom DBCA bekannt, werden jetzt Initialisierungsparameter (Memory, Processes, Character Set und DB Connection Mode) festgelegt. Besonders ist hier noch die mögliche Angabe eines CPU Counts für die Datenbank Instanz. Dies ist gerade für Cloud Umgebungen mit mehreren
Datenbanken pro Rechner wichtig.
Hausnummer: Summe CPUs aller DBs < 3x CPUs des Rechners.
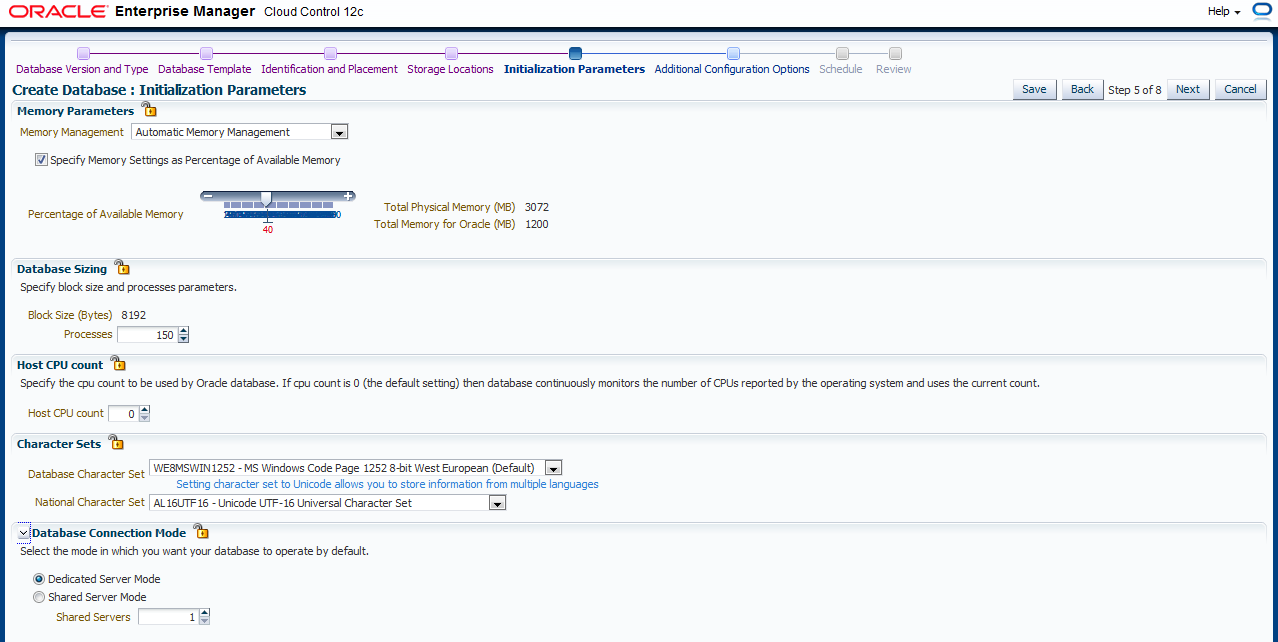
In diesem Beispiel werden einige Eingaben gemacht:
- Memory-Einstellung: Beachten Sie, dass in einer Cloud mehrere Instanzen erstellt werden. In diesem Beispiel wurde ein kleiner Server verwendet, bei dem die Einstellung von 40% ein Minimum für den Betrieb der Datenbank darstellt, jedoch nicht viele parallele Instanzen zuläßt. Schließen Sie das Schloß.
- Die maximale Anzahl von Prozessen sollte minimal 150 betragen. Schließen Sie das Schloß.
- CPU Count belassen Sie auf 0. Schließen Sie das Schloß.
- Belassen Sie den Default Character Set. Schließen Sie das Schloß.
- Stellen Sie den Database Connection Mode ein. Schließen Sie das Schloß.
Nach allen Eingaben klicken Sie auf "Next".
Erstellen eines Benutzers und einer Rolle für die Self Service Anwender
Erstellen Sie eine "leere" Rolle, ohne Rechte. Navigieren Sie dazu über "Setup"->"Security"->"Roles".
Klicken Sie auf Create, um eine Rolle zu erstellen. Entfernen Sie alle Rechte. Die Rolle wird später mit Rechten gefüllt.

Erstellen Sie nun einen Benutzer, der später die Self Service Anwendung nutzen soll. Dazu navigieren Sie über "Setup"->"Security"->"Administrators".
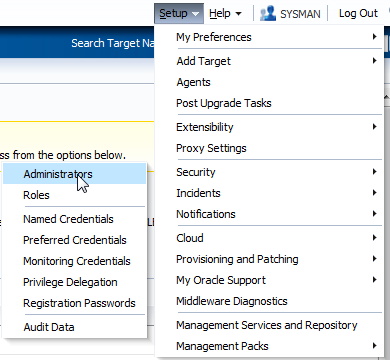
Klicken Sie auf "Create"

und erstellen einen neuen Benutzer, der nur die oben erstellte Rolle als Privileg zugewiesen bekommt und sonst nichts.
Erstellen einer Datenbankzone
Nun geht es an das Einrichten der eigentlichen DBaaS Cloud Umgebung. Navigieren Sie zu "Setup"->"Cloud"->"Database".
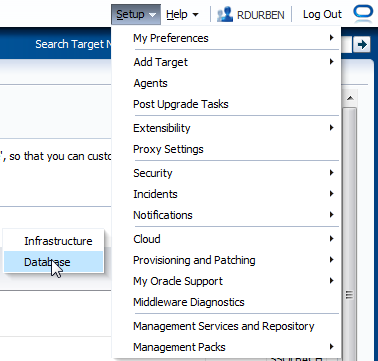
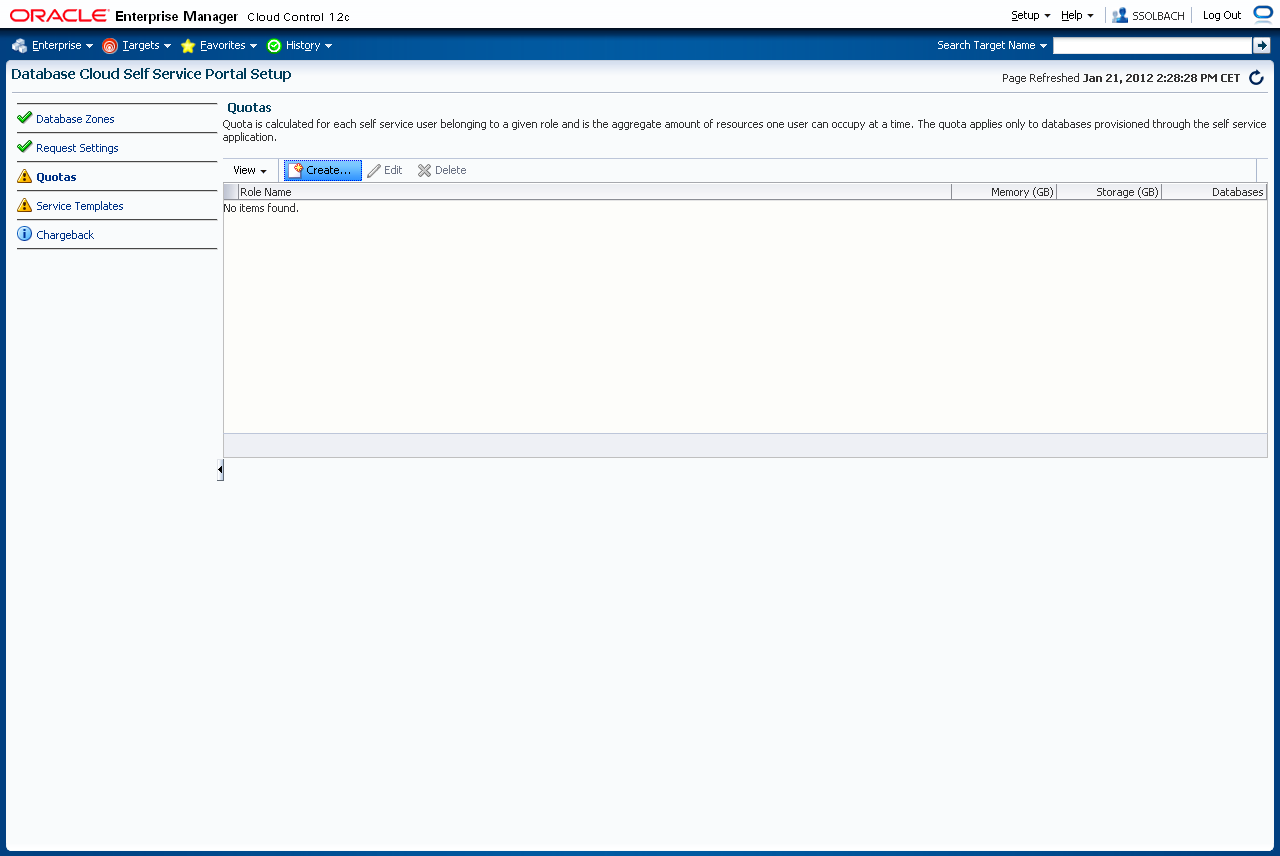
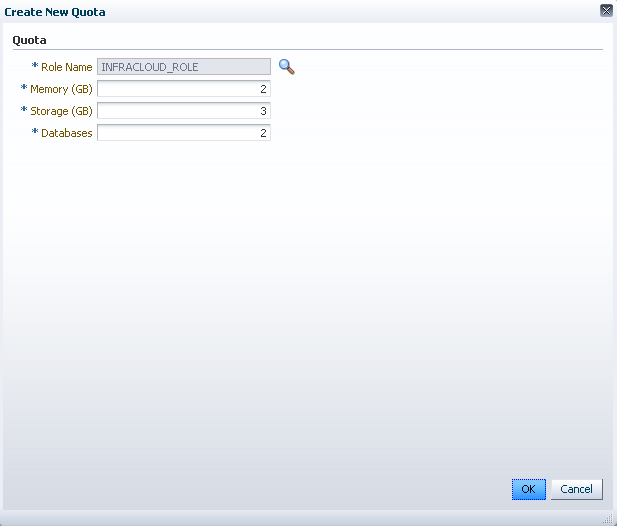
Im Normalfall sind alle noch nicht vergebenen Attribute mit einem gelben Ausrufezeichen versehen. Das heisst wir fangen vorne an und erstellen als erstes eine Datenbank Zone und weisen Rechte/Rollen zu. Klicken Sie auf "Create".
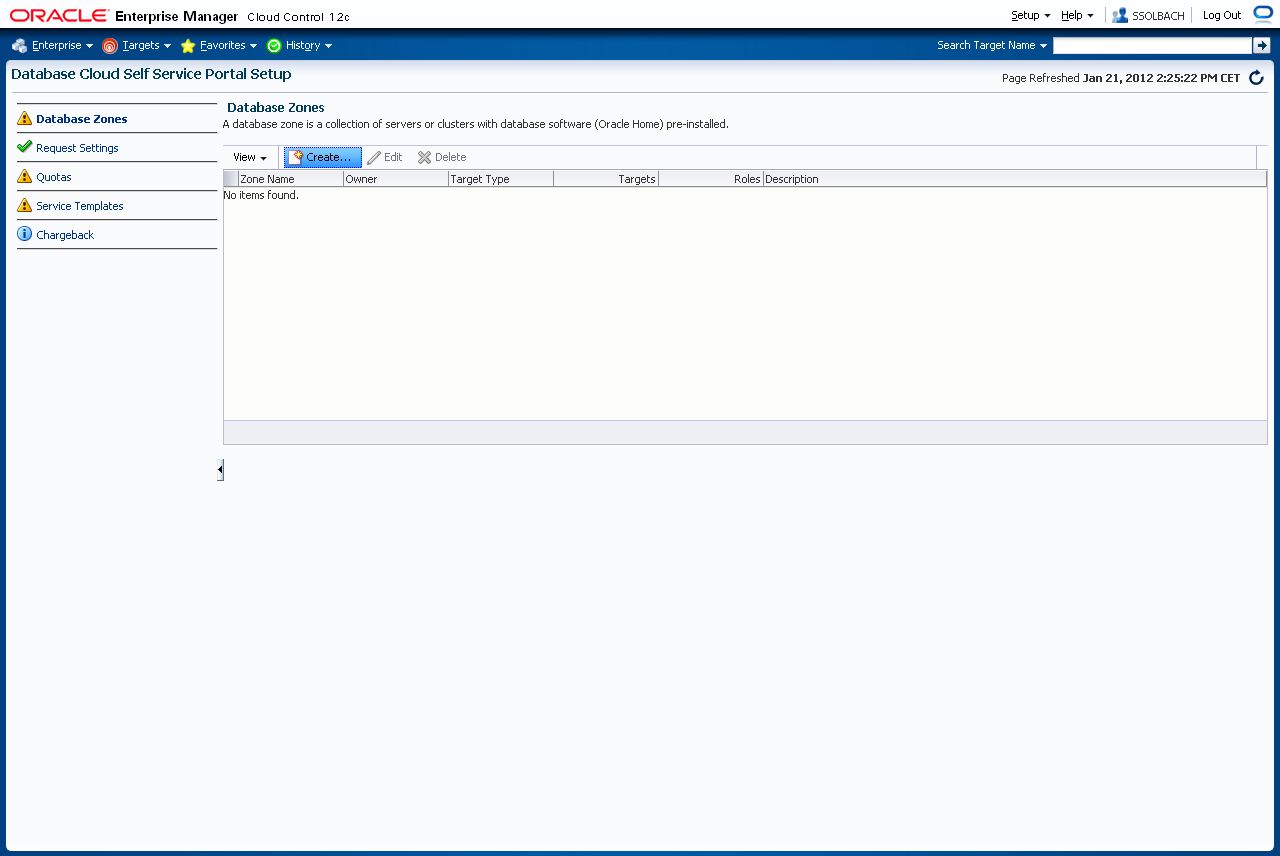
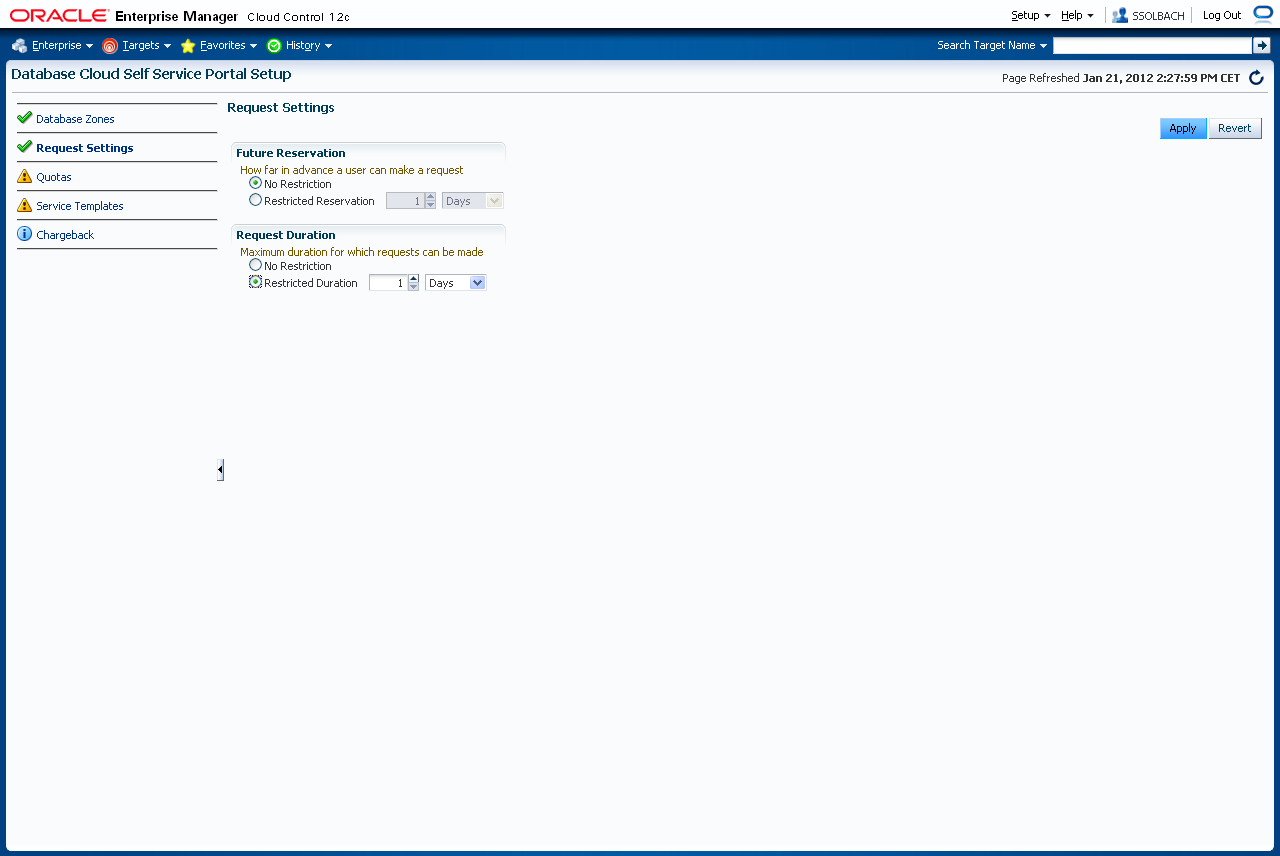
Geben Sie einen Namen für die neue Datenbankzone und ggf. eine Beschreibung an. Sie geben dann die maximale Auslastung der Cloud Zone an. Vorsicht: Der Default für die maximale Anzahl der Instanzen steht auf einer Instanz. Akzeptiert man hier den einfach den Default, schlägt das spätere Anlegen einer RAC Datenbank fehl, da ein RAC ja mindestens 2 Instanzen hat. Die Einstellung gilt für die komplette Zone, nicht für den einzelnen Knoten.
Der Fehler äußert sich später so, dass später beim Anlegen der Datenbank im Profil der Self Service Anwendung nur ein "null" beim "Placement Check" zurück kommt, da er keinen passenden Knoten für das Placement der Datenbank gefunden hat. Dass das an einer zu kleinen Anzahl Instanzen innerhalb der Zone liegen könnte ist aber weder direkt aus dem Logfile, noch für den Enduser wirklich ersichtlich.
Wenn alle Eingaben getätigt sind, klicken Sie auf "Next".
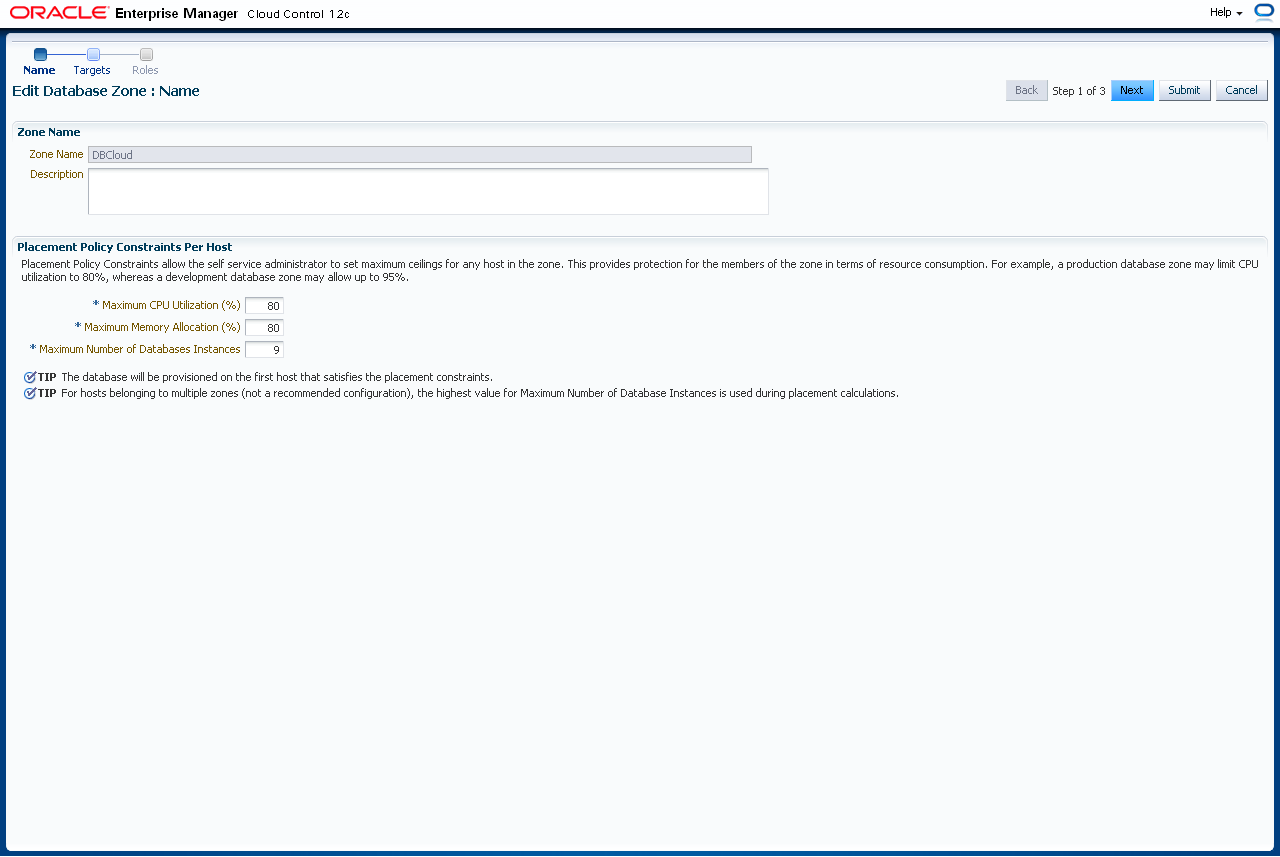
Sie wählen jetzt das Datenbank-Home. Wählen Sie den "Target Type" Oracle Home, die Plattform, als "Configuration" Real Application Cluster und die Version (hier 11.2.0.3). Klicken Sie auf "Add".
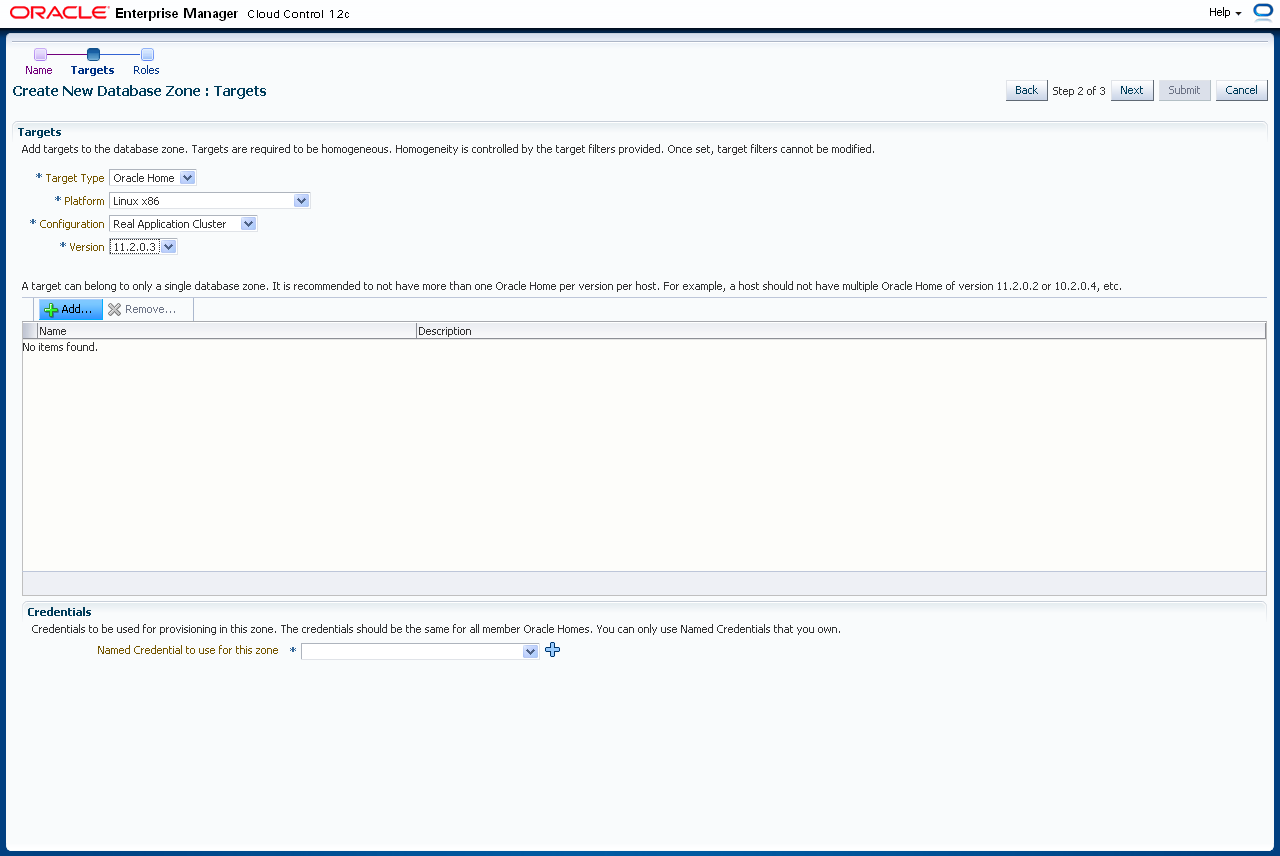
Es werden nun alle passenden Konfigurationen angezeigt die Cloud Control kennt. Wählen Sie alle Oracle Homes, die berücksichtigt werden sollen (hier sind das alle) und klicken auf "Select". Generell sollte bei einer RAC Konfiguration natürlich darauf geachtet werden, alle Knoten eines Clusters zu wählen. Es dürfen aber durchaus mehrere RAC Cluster in einer Zone enthalten sein (wie auch mehrere Single Instance Datenbanken).
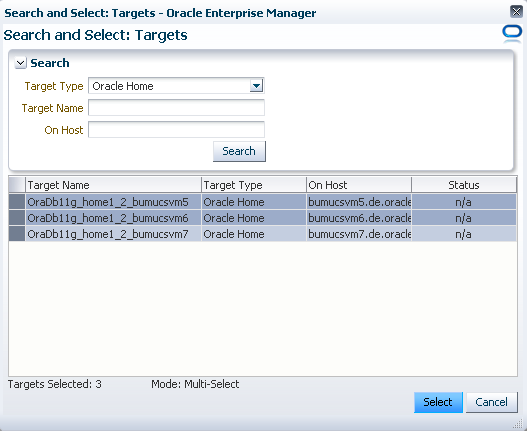
Geben Sie das Named Credential für den Oracle User der beteiligten Server an, welches für alle gleich sein muss.
und klicken auf "Next".
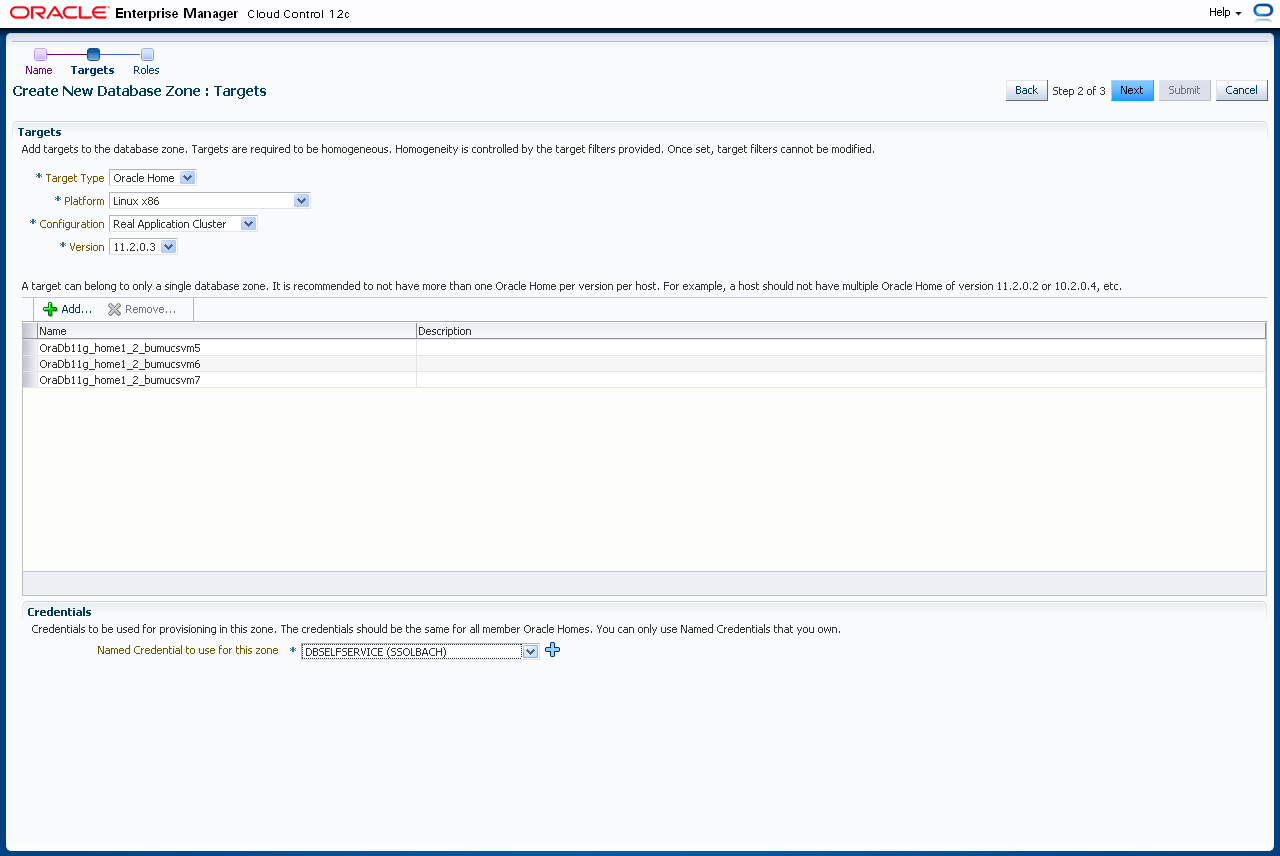
Jetzt legen Sie fest, über welche Rolle der Zugriff auf diese Datenbankzone erfolgen soll. Diese Rolle wurde oben definiert. Wählen Sie die Rolle aus und klicken "Select".
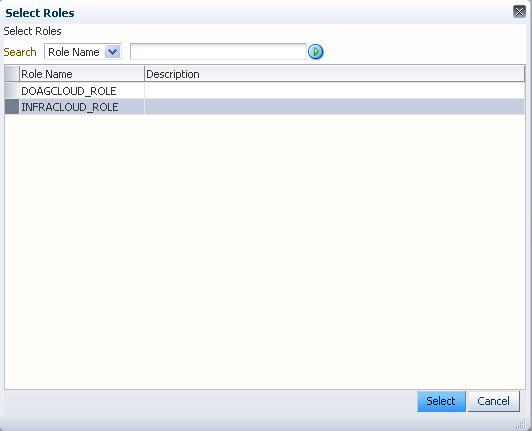
Erstellen Sie die Datenbankzone mit einem Klick auf "Submit".
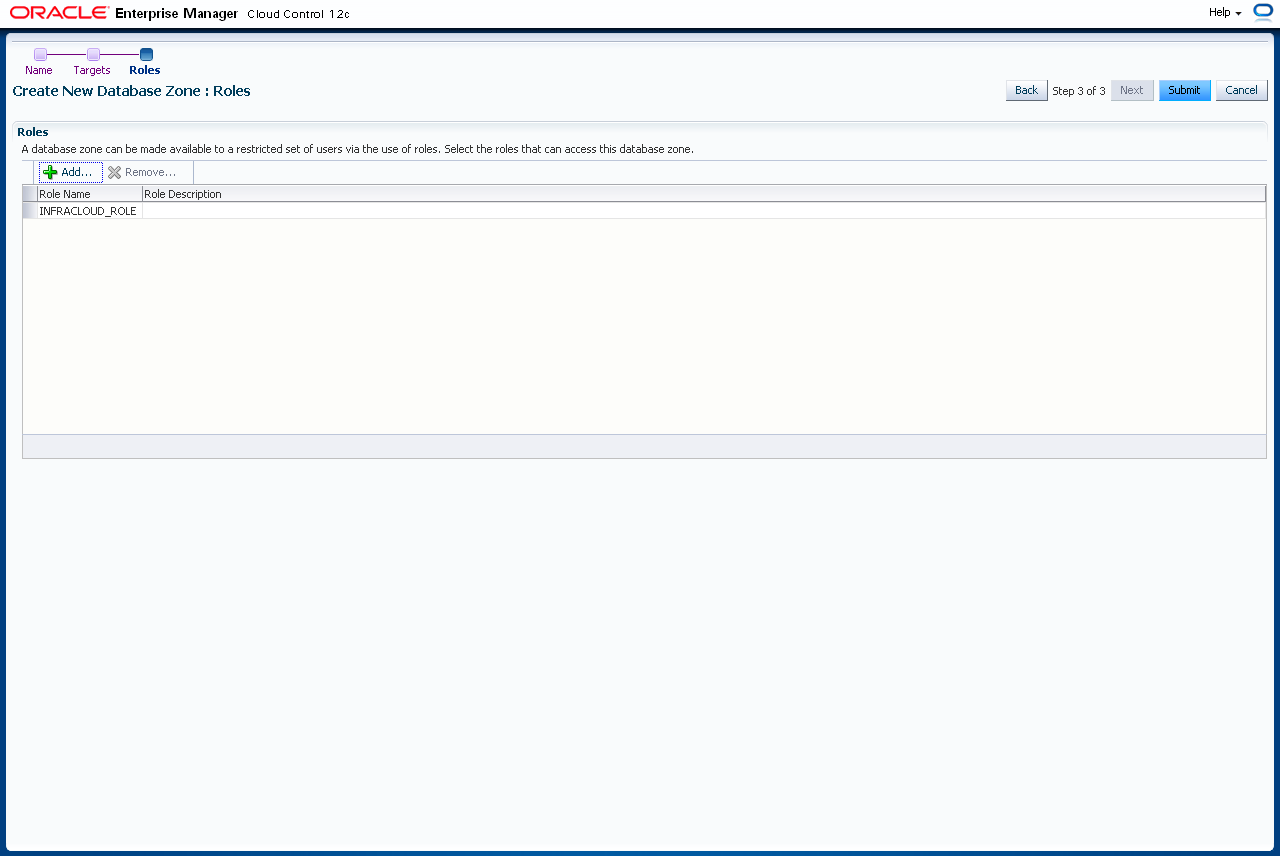
Sie können beliebig viele Datenbankzonen erstellen.
Einstellen der Service Templates
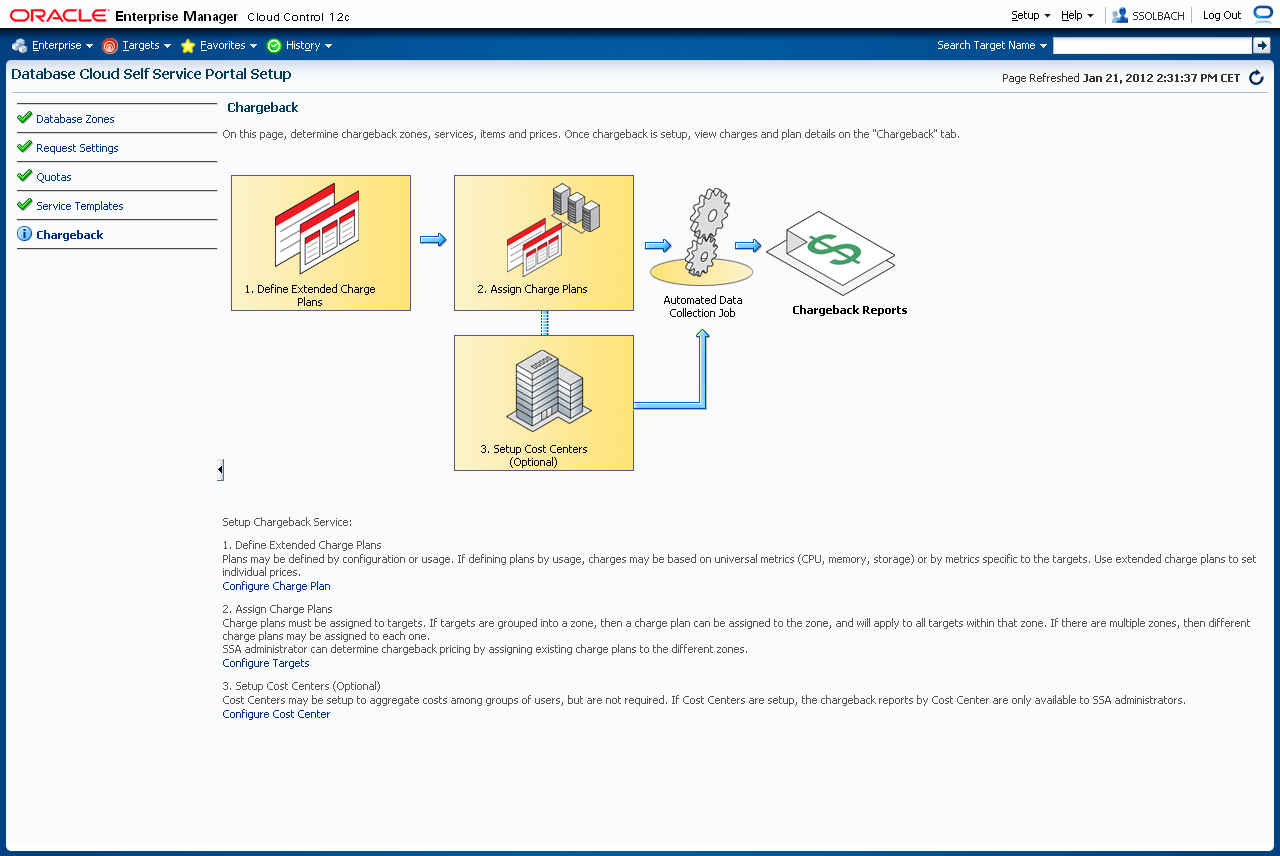
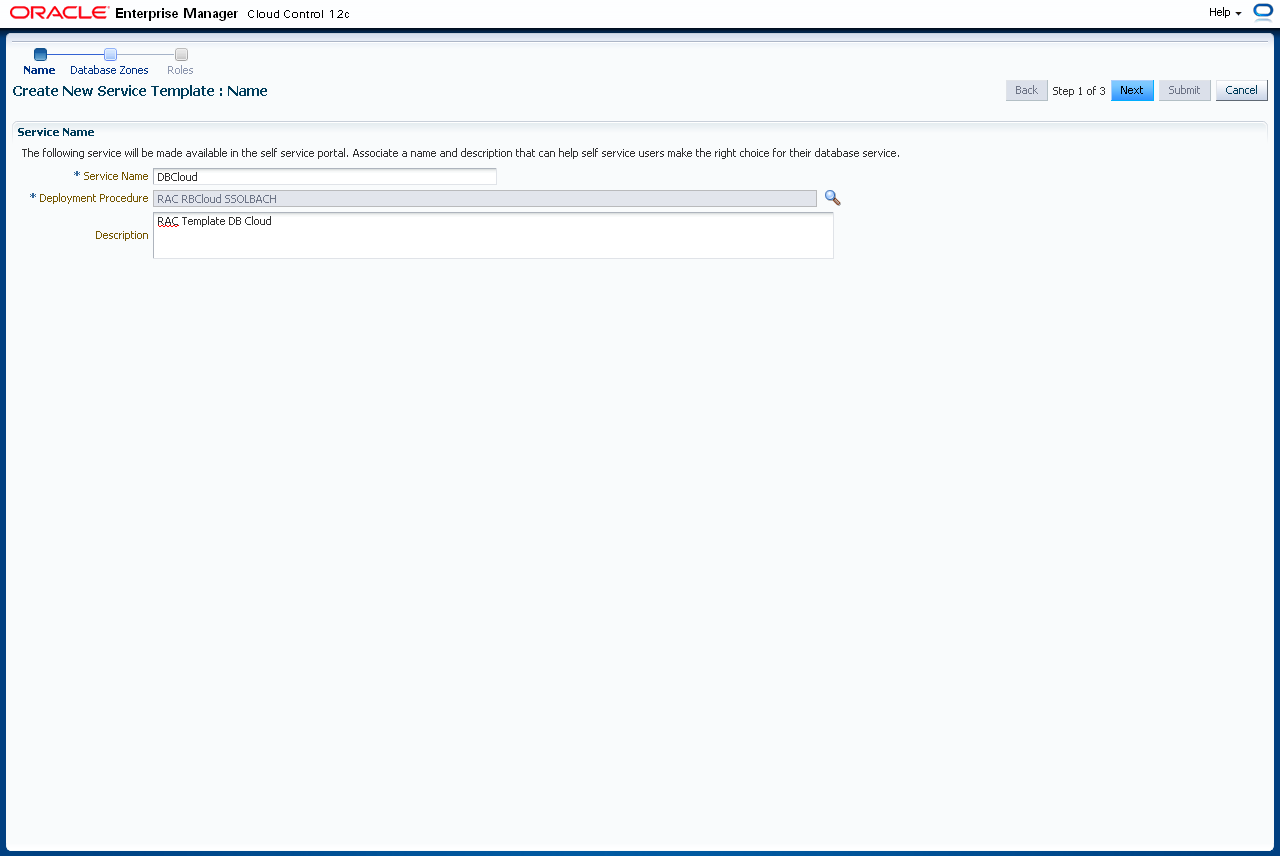
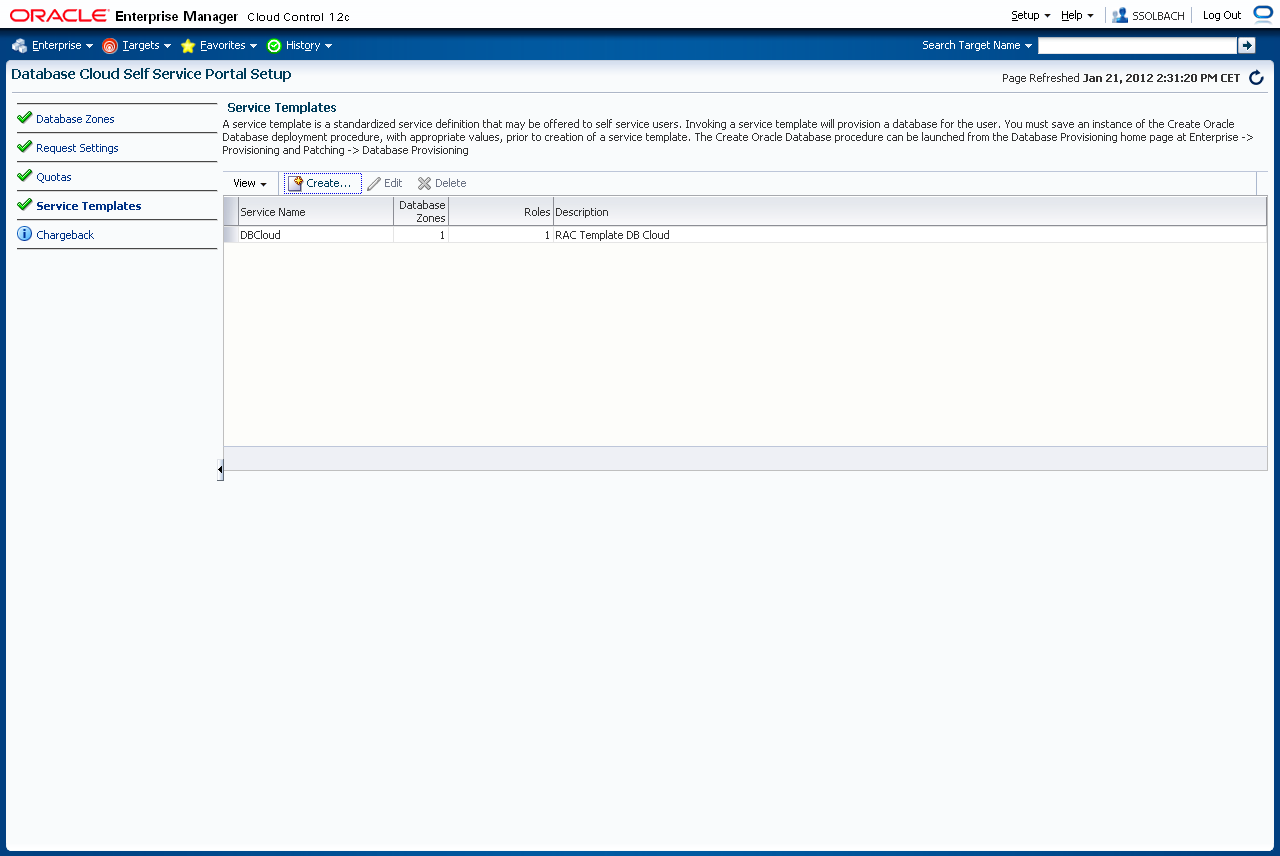
Mit der Einstellung der Service Templates geschieht die Zuweisung der Provisionierungsprofile zur jeweiligen Datenbankzone und Rolle. Navigieren Sie zu "Setup"->"Cloud"->"Database". Klicken Sie links auf "Service Templates". Klicken Sie auf "Create".
Vergeben Sie einen Namen und eine Berschreibung und klicken auf "Next".
Wählen Sie die von Ihnen zuvor gespeicherte Deployment Prozedur aus und klicken auf "Select".
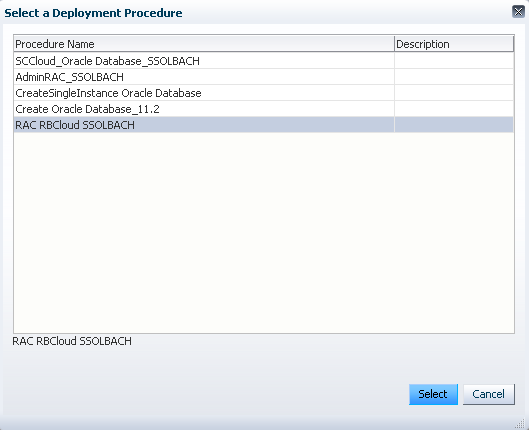
Im Wizard klicken Sie auf "Next". Mit einem Klick auf "Add" fügen Sie eine Datenbankzone hinzu. Wählen Sie die zuvor erstellte Datenbankzone aus und klicken auf "Select".
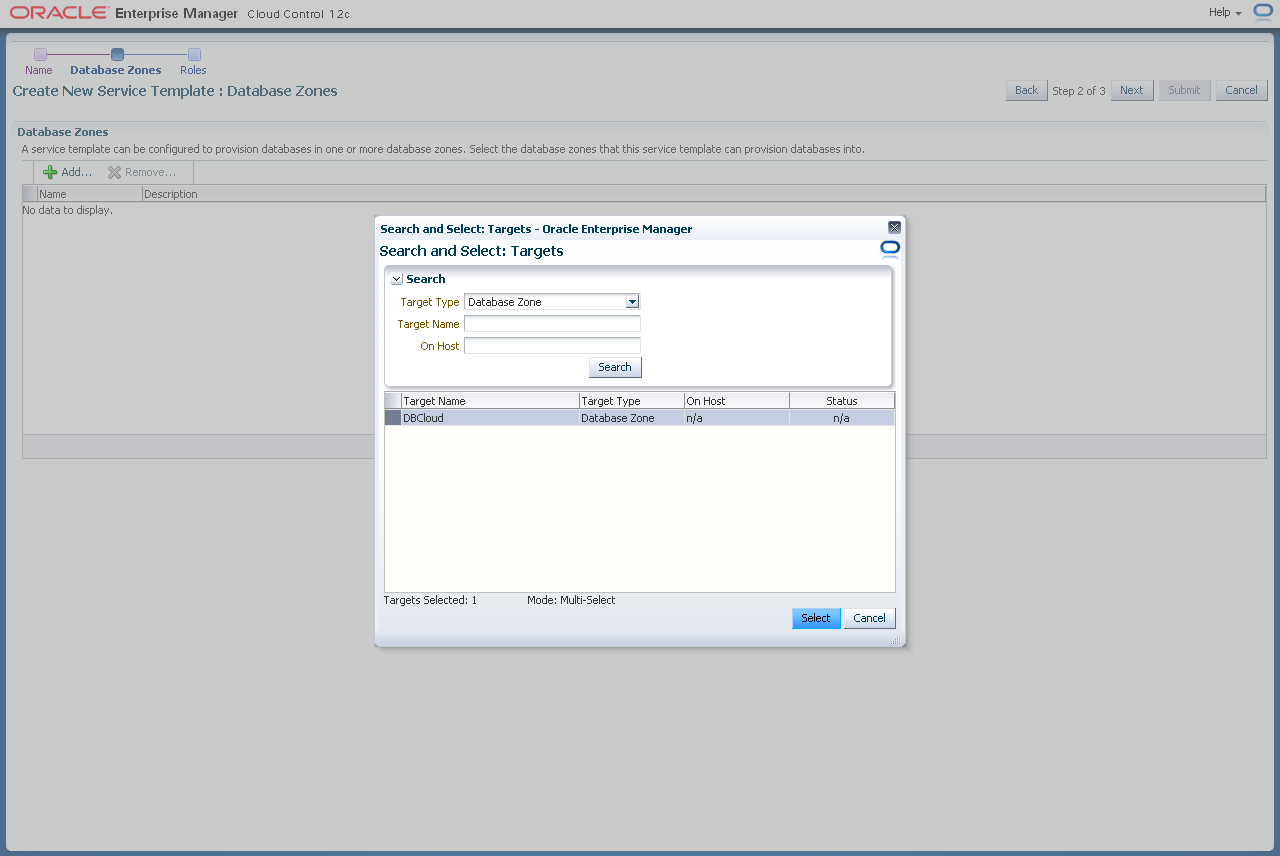
Klicken Sie auf "Next".
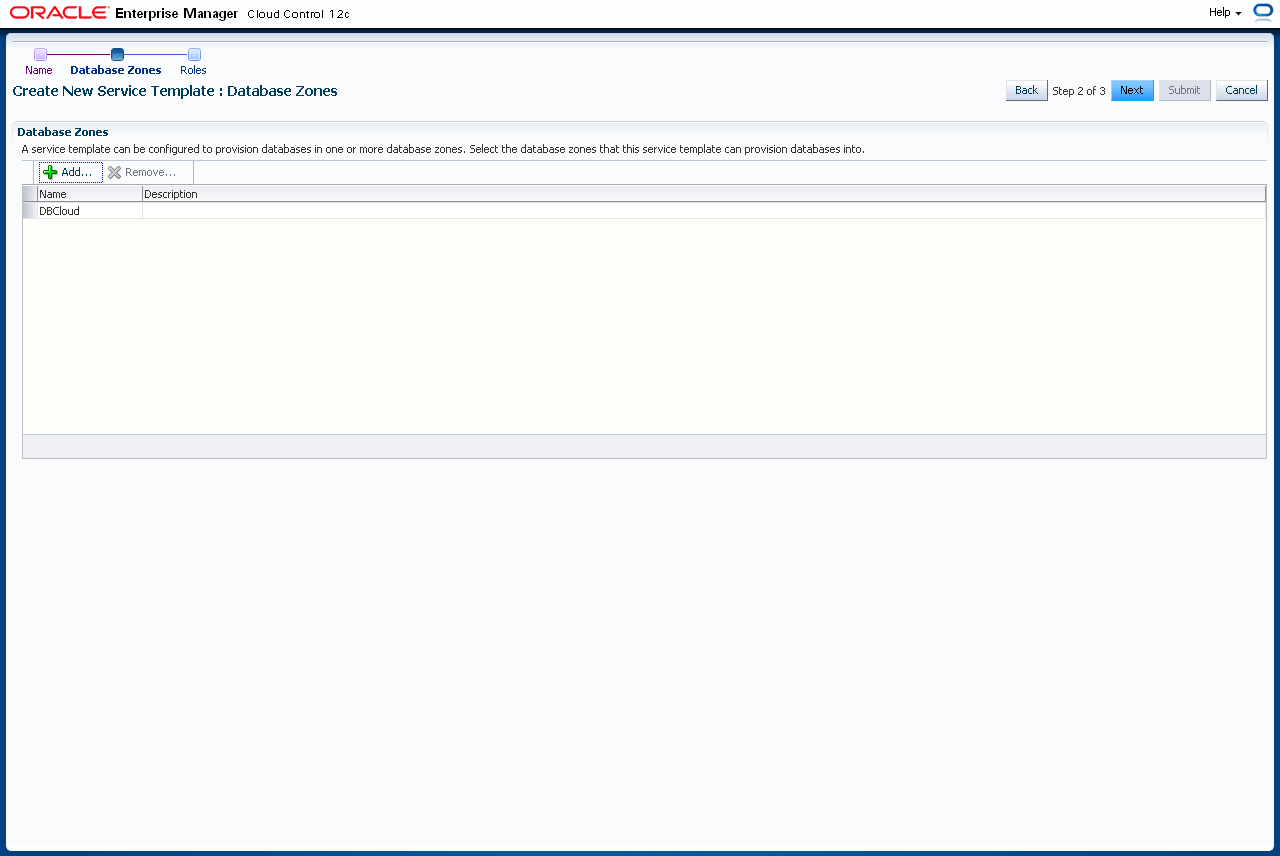
Mit einem Klick auf "Add" fügen Sie die Rolle zu, mit der der Endbenutzer auf dieses Service Template zugreifen darf. Wählen Sie die Rolle aus und klicken "Select".
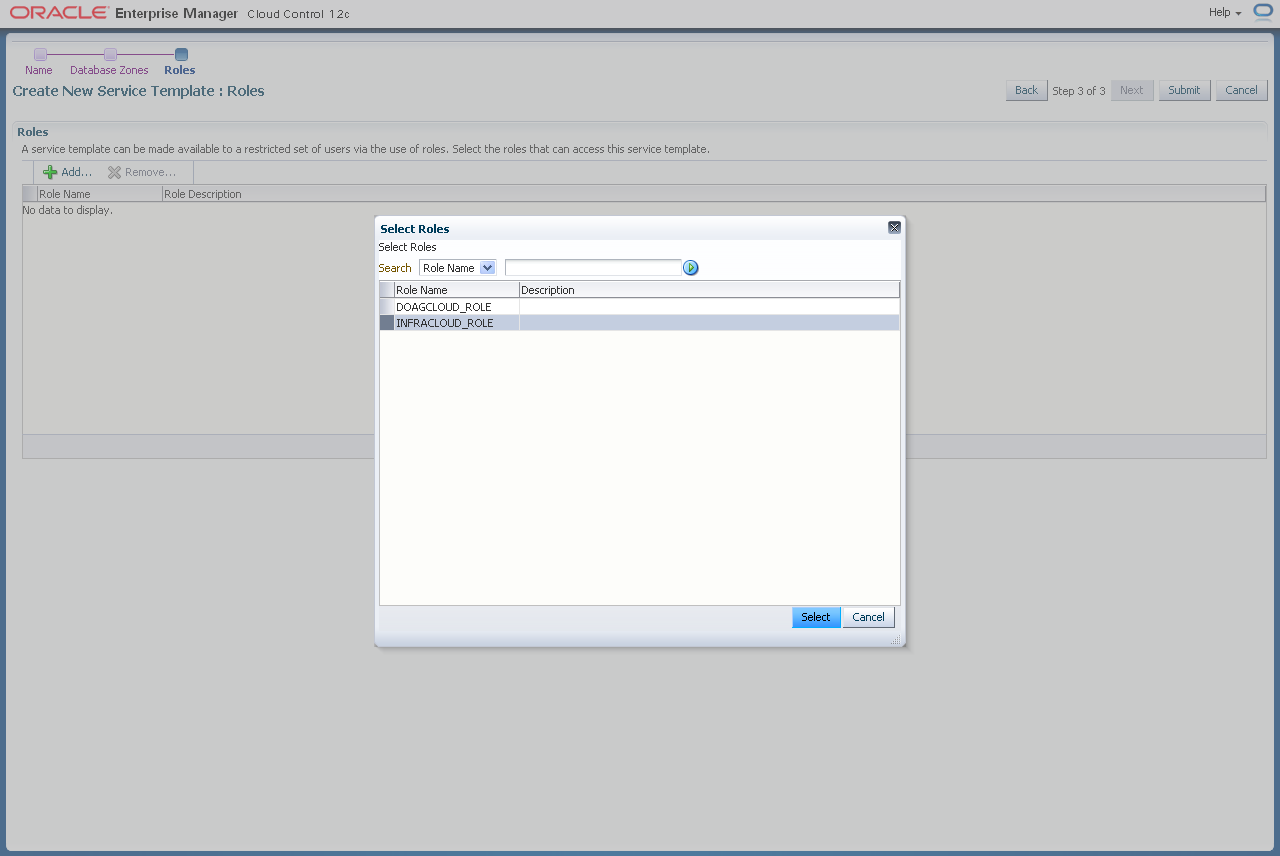
Mit einem Klick auf "Submit" wird dieses Service Template erstellt.
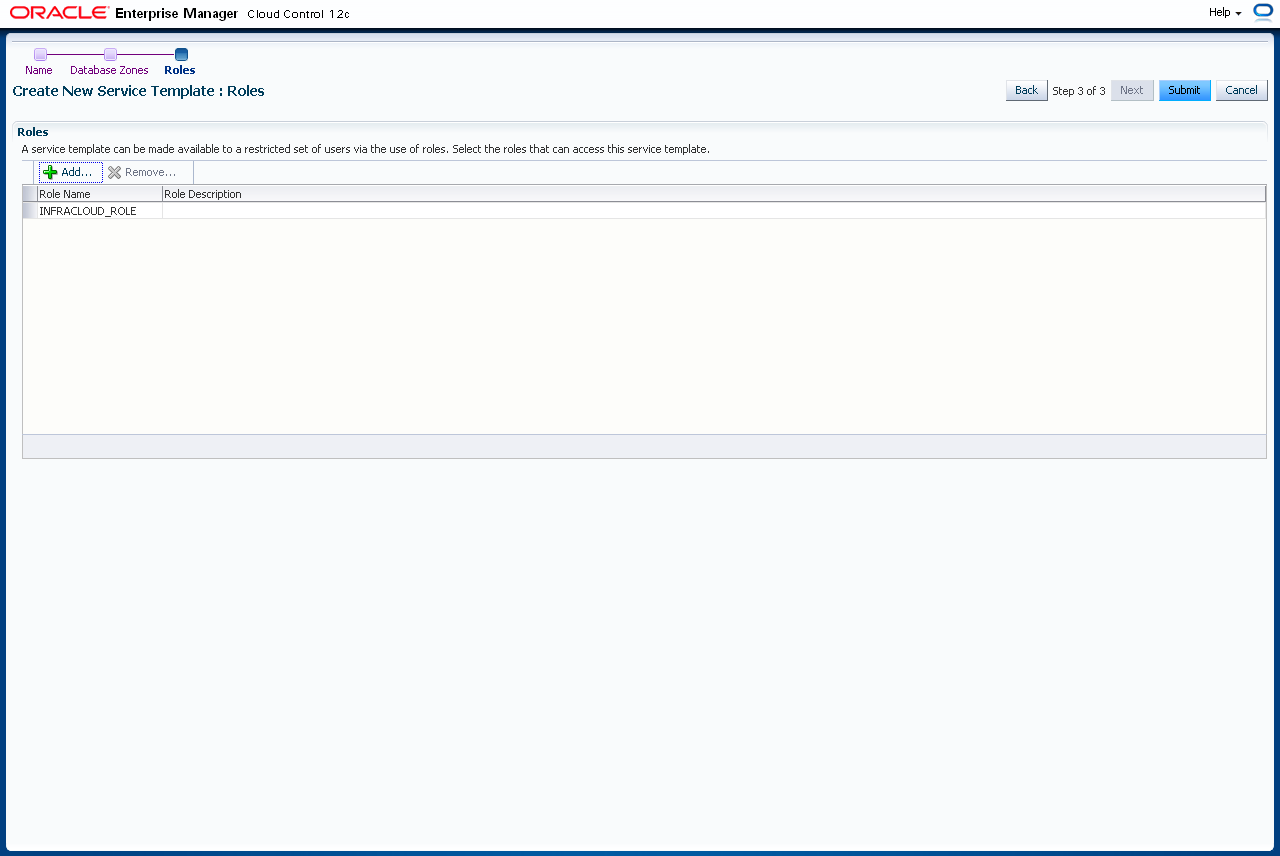
Prüfen Sie die Zuweisung der Templates. Die Zuweisung der Templates sind Benutzergebunden (d.h. an den Self Service Administrator). Selbst ein Super-User kann eine Zuweisung eines Templates zu einer Zone nicht löschen oder ändern, sollte diese von einem anderen Administrator angelegt worden sein. Auch hier ist die Fehlermeldung leider nicht aussagekräftig, ausser dass eine Änderung nicht möglich ist.
Nutzung der Datenbank Cloud
Der Self Service Benutzer startet Cloud Control (Sie können einen anderen Browser starten, um das ganze parallel zu betrachten ) mit der normalen URL. Die Login Seite zum Enterprise Manager kann übrigen anders (mit eigenem Firmenlogo) gestaltet werden, so dass beim Login auf das Self Service Portal der EM nicht direkt ersichtlich ist.
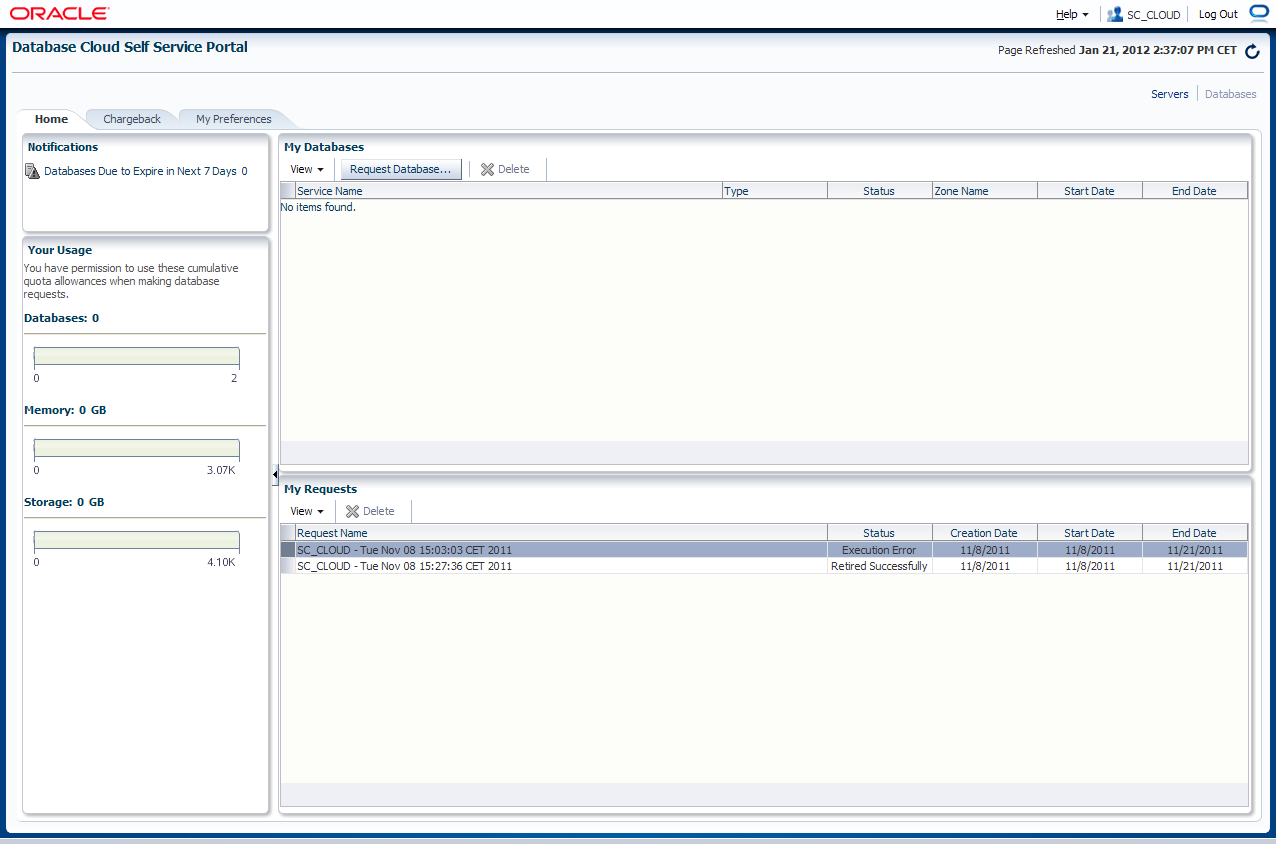
Der Benutzer gelangt sofort in die Self Service Anwendung. Da der Benutzer eine Datenbank beantragen möchte, klickt er oben rechts auf "Databases" und dann auf den Button "Request Database".
Der Benutzer wählt ein Provisionierungsprofil aus. Hier zeigt sich, dass leicht verständliche Beschreibungen von Vorteil sind. Die Auswahl wird mit "Select" bestätigt.
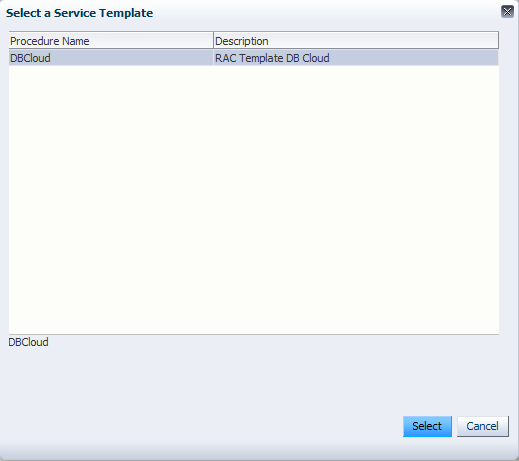
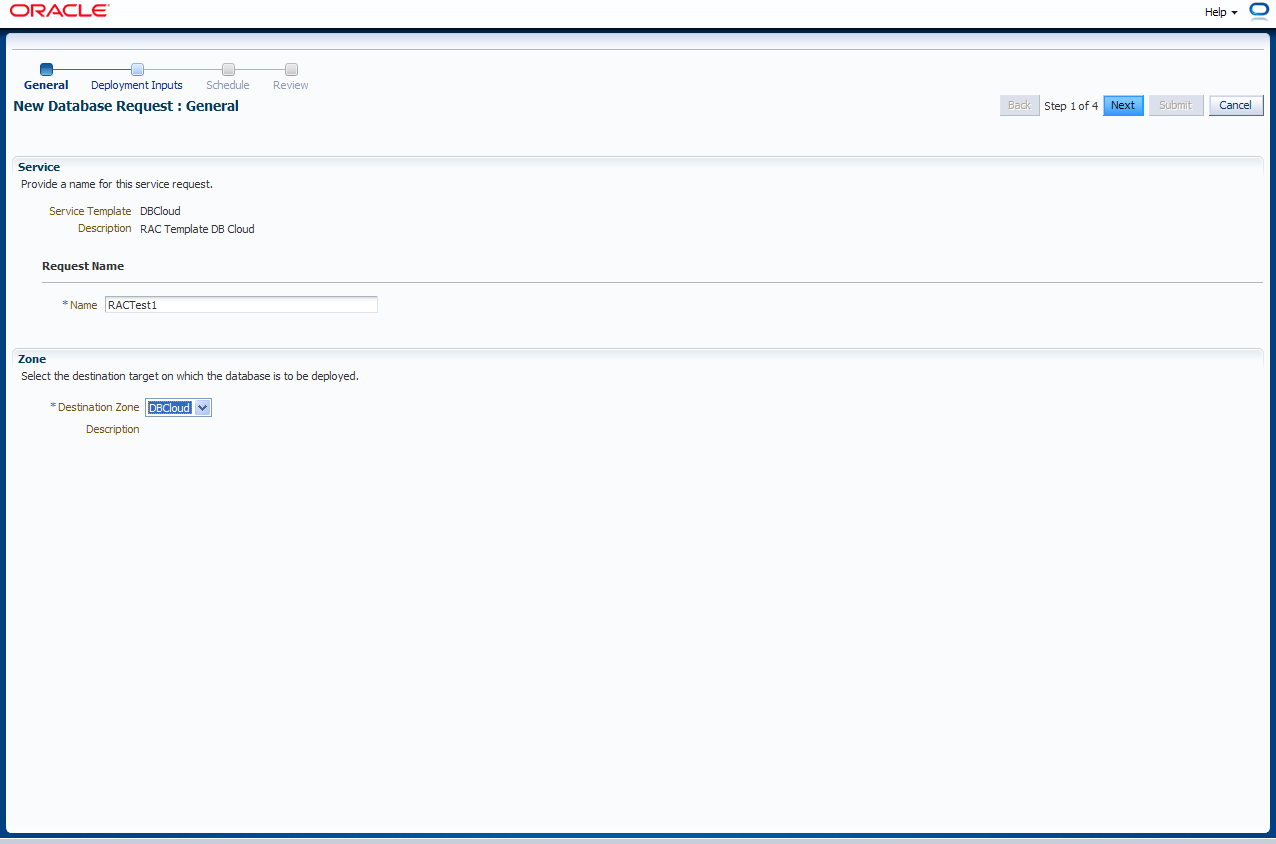
Der Benutzer gibt einen Request-Namen ein und wählt die Datenbankzone aus. Mit "Next" geht es weiter.
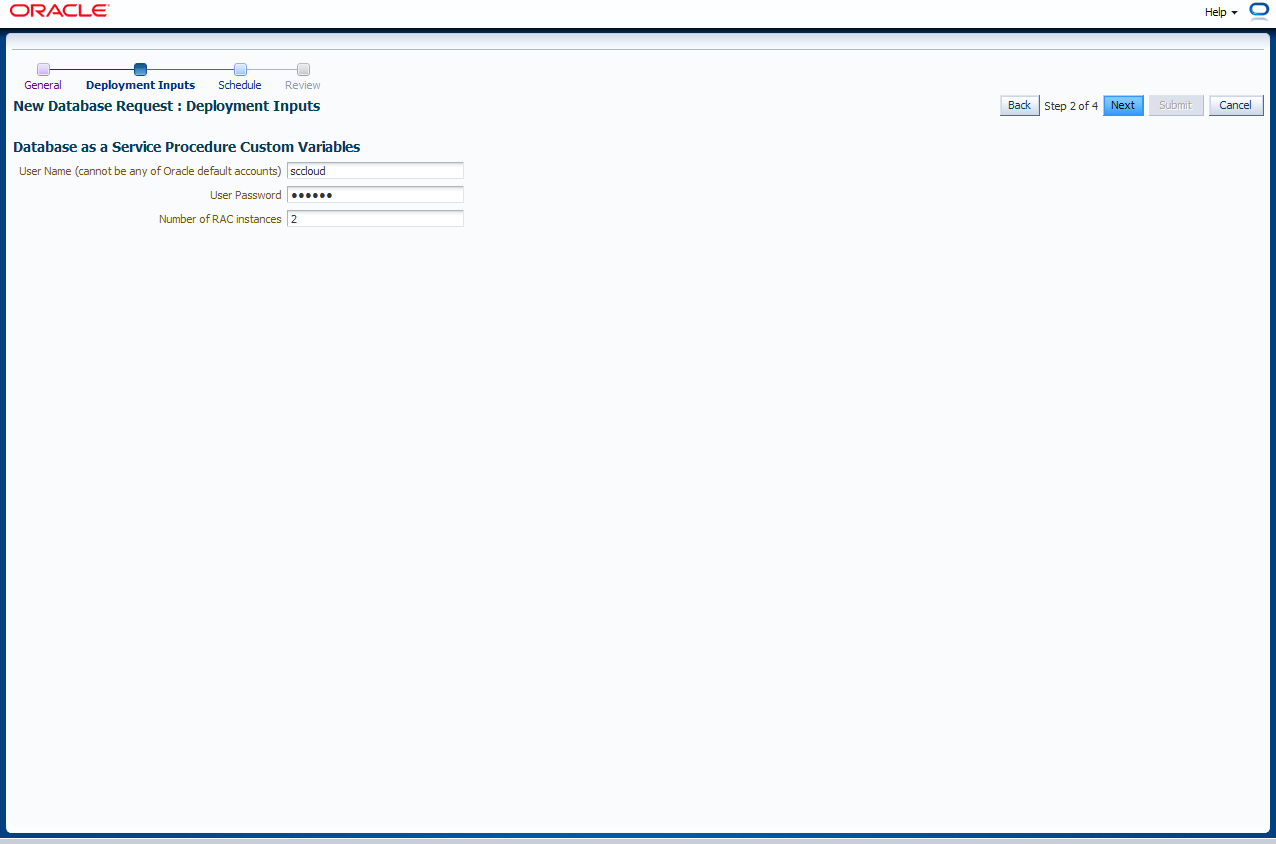
Jetzt wird ein Datenbank Benutzer Name und Passwort eingegeben, der natürlich kein Default Account (SYS,SYSTEM,...) sein darf. Mit diesem Benutzernamen kann der Nutzer der Self Service Anwendung später auf die Datenbank zugreifen. Bei RAC Datenbanken wie hier wird auch die Anzahl der Instanzen angegeben. In diesem Beispiel soll ein 2-Knoten-RAC beantragt werden. Mit "Next" geht es weiter.
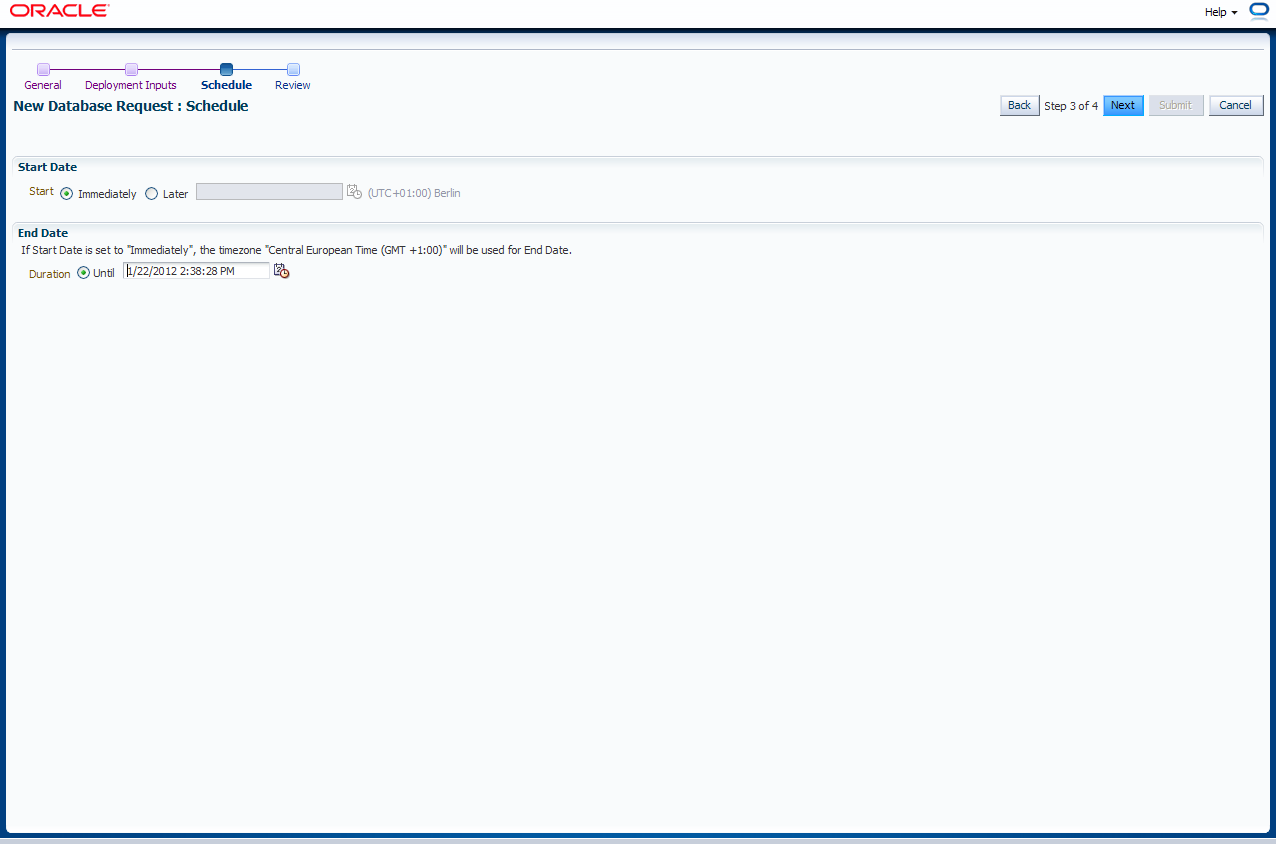
Die Erzeugung der Datenbank kann sofort erfolgen oder für einen späteren Zeitpunkt geplant werden. Mit "Next" geht es weiter.
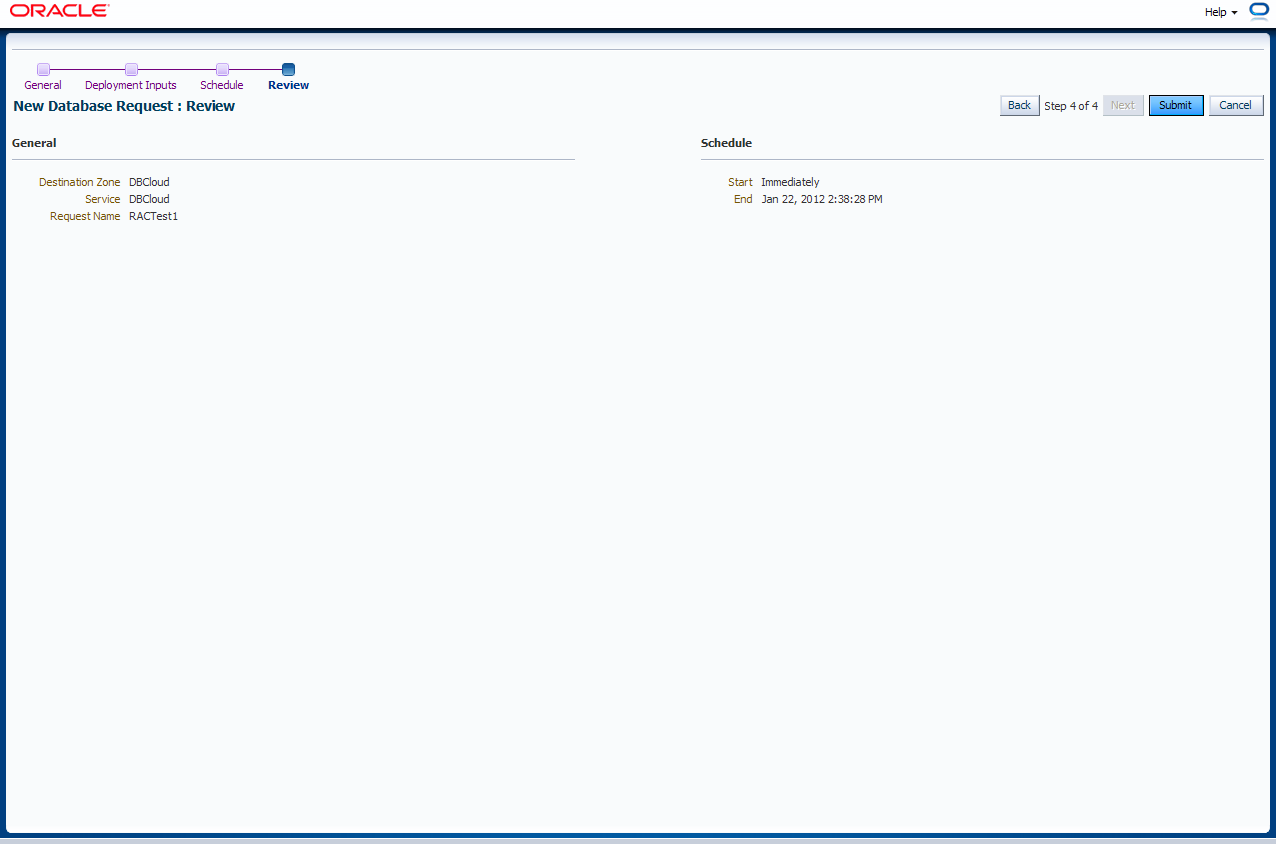
Es erscheint ein kurzes Review. Mit "Submit" wird der Request abgeschickt.
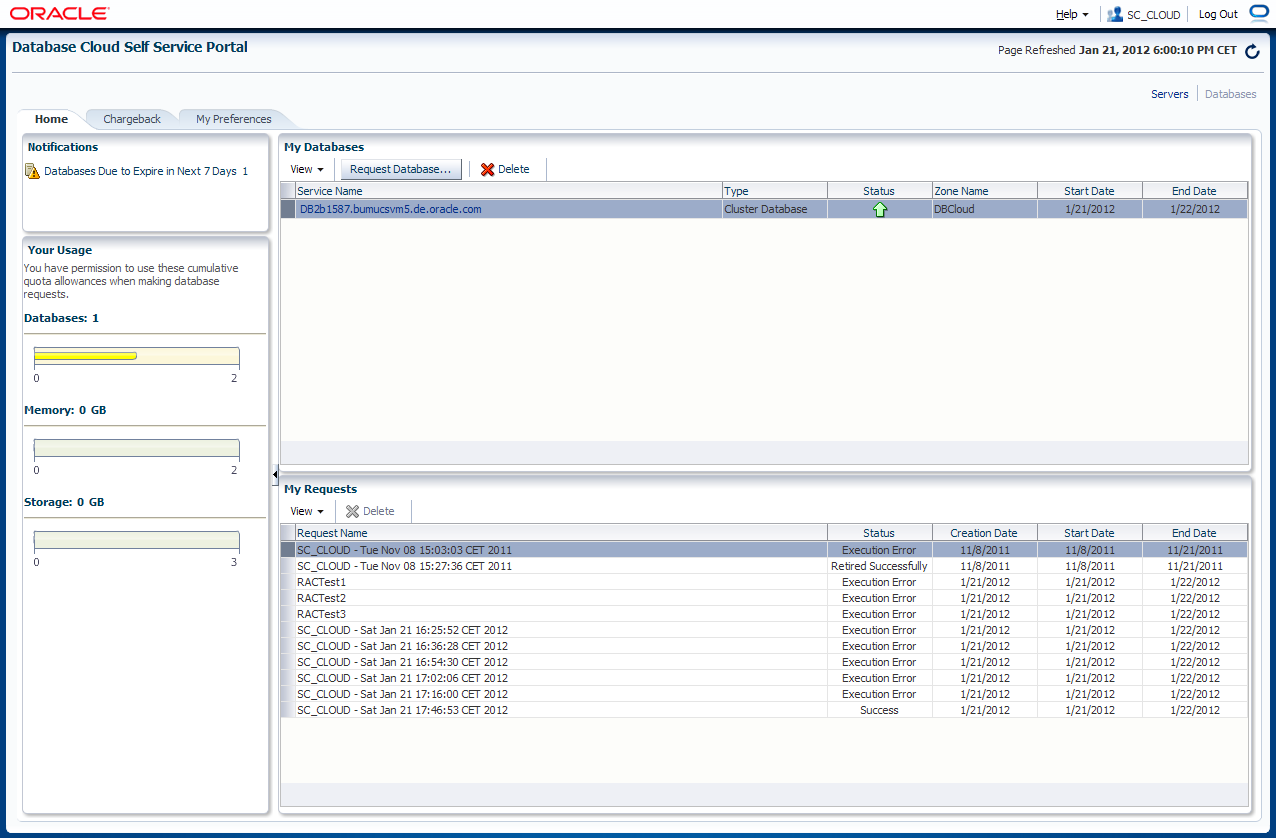
Wenn die Datenbank fertig ist, erscheint diese in der Homepage der Self Service Anwendung.
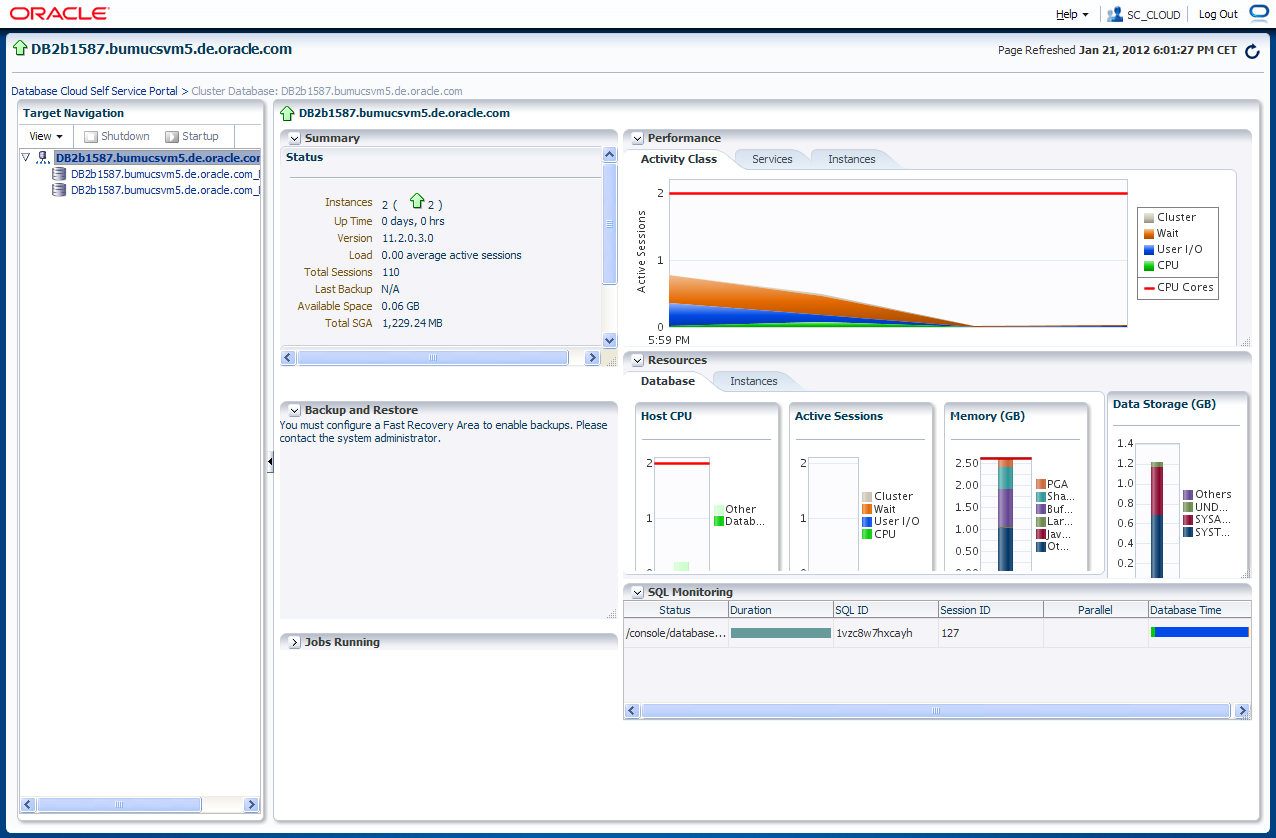
Ein Klick auf den Servicenamen bringt Sie auf die Datenbank-Homepage innerhalb der Self Service Anwendung. Hier finden Sie die Administrationsfunktionen für den Benutzer der Self Service Anwendung.
Monitoring und Troubleshooting
Während die Datenbank angelegt wird, kann der Jobfortschritt vom DB Cloud Administrator verfolgt und eingesehen werden. Tritt ein Fehler bei "Obtain the Target Node List" auf, so konnte kein passender Knoten für das Deployment gefunden werden. Dies kann u.U. an falschen Rechten bzw. falschen Maximalwerten der Datenbankzone liegen (oder wenn die Maximalwerte erreicht wurden). Ein Fehler bei "Configure und Create Database" deutet auf einen Fehler im Provisioning Profil hin (Tipp: Attribut "Lock" Status überprüfen) oder im Falle von RAC an "User defined Ressourcen", wie z.B. einer zusätzlichen VIP oder ähnlichem. Es ist empfohlen am Anfang auf einer Standard RAC Installation anzufangen und möglichst wenig zu ändern.
Schlägt "Assign the Target Priviledges" fehl, konnte der User nicht angelegt werden. In den meisten Fällen liegt dies an einem Problem zwischen dem EM Agent und dem Listener der Datenbank. Damit dies reibungslos funktioniert, muss der EM Agent mit den TNS_ADMIN Variable gestartet werden, die auf den Listener hinweist (im Falle von RAC dem Listener der Grid Infrastruktur).
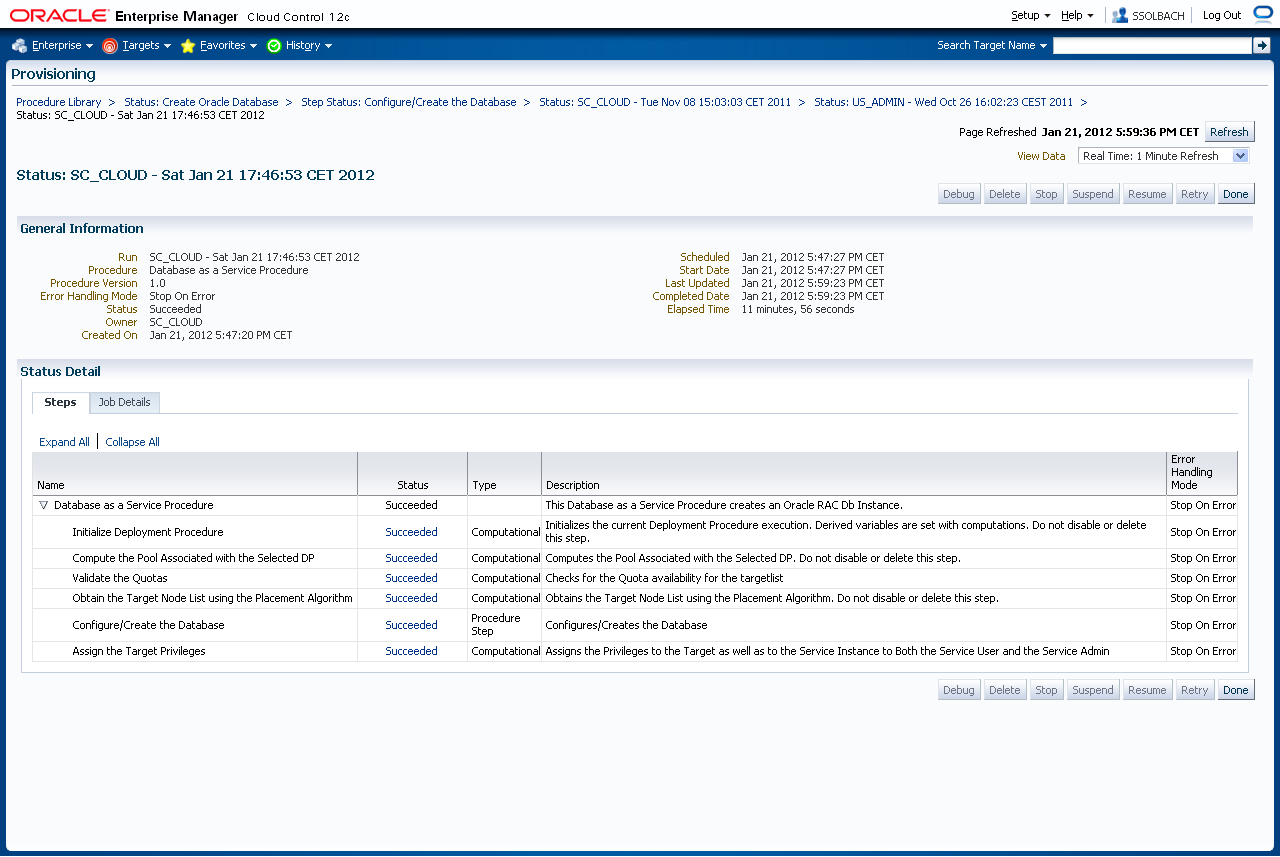
Die nachfolgende Sicht bekommt der DB Cloud Administrator wenn die erste Cloud DB läuft. Es werden immer alle Requests gespeichert und angezeigt, auch wenn diese fehlerhaft waren.
 DBA Community - Februar 2012
DBA Community - Februar 2012