Before You Begin
Purpose
This tutorial covers the use of Oracle Data Miner 4.1 to perform star schema mining activities against Oracle Database 12c Release 12.1.0.2. Oracle Data Miner 4.1 is included as an extension of Oracle SQL Developer, version 4.1.
A star schema is the simplest style of data warehouse schema. A star schema consists of one or more fact tables referencing any number of dimension tables. A fact table holds the main measure data; dimension tables contains attributes that describe data in the fact table.
Being able to perform data mining directly on data in its native stored format and tables inside the Oracle Database is a unique and differentiating feature of Oracle Advanced Analytics. It saves time, reduces data movement and mitigates data preparations and transformation efforts.
In this lesson, you use Oracle Data Miner against a very simple star schema consisting of one fact table (SALES) and two dimension tables (CUSTOMERS and SUPPLEMENTARY_DEMOGRAPHICS) in the sample Sales History (SH) schema that is shipped with Oracle Database.
In this tutorial, you will perform the following tasks:
- First, you create data sources for data in the SH schema.
- Then, you aggregate sales data by calculating the total number of items sold and total amount of money paid on a per customer basis - for each product.
- Next, the aggregated data is joined to the customer data.
- Finally, the new data is used to create classification models to predict likely Affinity Card customers, based on the aggregated data.
Time to Complete
Approximately 30 mins
Background
As stated previously, the data for this tutorial comes from the one of the Sample Schemas that shipped with Oracle Database: the Sales History (SH) schema.
This sample data set is not designed for data mining, nor has it been through the "Data Aquisition and Preparation" phase, as described in the "Using Oracle Data Mining 4.1". However, this tutorial demostrates how you can easily assemble the data from its original sources and build predictive models. You don’t have to export all tables and assemble/transform in other external statistical tools.
Context
Before starting this tutorial, you should have set up Oracle Data Miner for use within Oracle SQL Developer 4.1, by completing the Setting Up Oracle Data Miner 4.1 tutorial.
In addition, if you are new to Oracle Data Miner, we strongly suggested that you complete the Using Oracle Data Miner 4.1 tutorial.
What Do You Need?
Have access to or have Installed the following:
- Oracle Database: Minimum: Oracle Database 12c Enterprise Edition, Release 1.0.2 (12.1.0.2.0) with the Advanced Analytics Option.
- The Oracle Database sample data, including the SH schema.
- SQL Developer 4.1
Create a Data Miner Project
In the Setting Up Oracle Data Miner 4.1 tutorial, you learned how to create a database connection to a Data Miner user and install the Oracle Data Miner Repository, all from within SQL Developer.
In the Using Oracle Data Miner 4.1 tutorial you learned how to create Data Miner Project and Workflow.
Here, you will create a new Data Miner project using the existing Data Miner user connection.
Note: The layout and contents of your SQL Developer window may be different than the example shown below. Simply reorganize your SQL Developer enviroinment to match the example given.
-
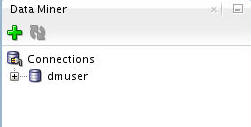
First, select the Data Miner tab. The dmuser connection that you created previously appears.
-
Right-click dmuser and select New Project from the menu.
-
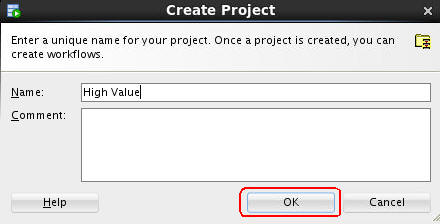
In the Create Project window, enter High Value as the project name and then click OK.
Result: The new project appears below the connection node.
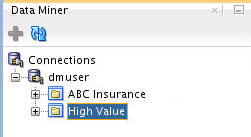
Note: The ABC Insurance project may be created by completing the Using Oracle Data Miner 4.1 tutorial.
Perform Star Schema Mining Tasks
In the Using Oracle Data Miner 4.1 tutorial, you selected data from the DMUSER schema to create and apply Classification models. In this tutorial, you will perform star schema mining in a different schema.
As you have already learned, data source nodes allow you to select any table or view in the current account (schema). In addition to tables in the current account, you can select tables in other accounts that you have permission to use. The DMUSER account also provides access to the Sales History (SH) schema, one of the Oracle Database Sample Schemas.
Create a Workflow and Add Data Sources
-
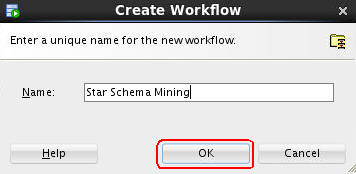
Right-click the High Value project and select New Workflow from the menu.
-
In the Create Workflow window, enter Star Schema Mining as the name and click OK.
Result: Just like in the Using Oracle Data Miner 4.1 tutorial, an empty workflow tabbed window opens with the Workflow name that you specified.
-
Next, add the first of three Data Source nodes for the SH schema to the workflow.
In the Component Palette, open the Data category, then drag/drop a Data Source node to the workflow pane, as shown here:
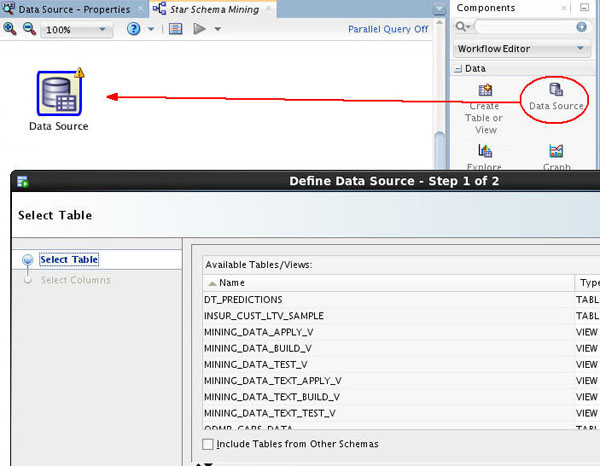
Now, you will add SH schema tables and views as available data sources.
-
In Step 1 of the Wizard:
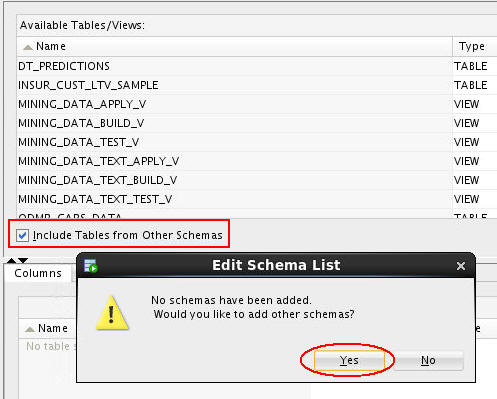
A. Select the Include Tables from Other Schemas option. Then, click Yes in the Edit Schema List information box.
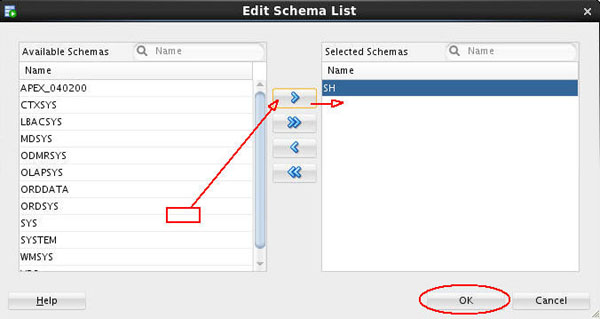
B. In the Edit Schema List dialog, move SH from the Available Schemas list to the Selected Schemas list as shown below. Then click OK.
C. Back in the Define Data Source wizard, select SH.CUSTOMERS from the Available Tables/Views list, and then click FINISH.
Result: As shown below, the data source node name is updated with the selected table name, and the properties associated with the node are displayed in the Property Inspector.
-
Now, add a second Data Source node to the workflow below the CUSTOMERS node. Then, in the wizard select the SH.SUPPLEMENTARY_DEMOGRAPHICS table, and click Finish.
-
Finally, add a third Data Source node to the workflow above CUSTOMERS node. In the wizard select the SH.SALES table and click Finish.
Result: The workflow should now look something like this:
-
Click the Save All tool in the SQL Developer toolbar.
In this topic, you will create a workflow and add two data source nodes for objects in the SH schema: one for the CUSTOMERS table and another for the SALES table.
Aggregate Data
Next, you use an Aggregate node to transform the data in SALES so that it is summarized (aggregated) on a per-customer basis.
-
First, drag and drop the Aggregate node from the Transforms group to the Workflow, like this:
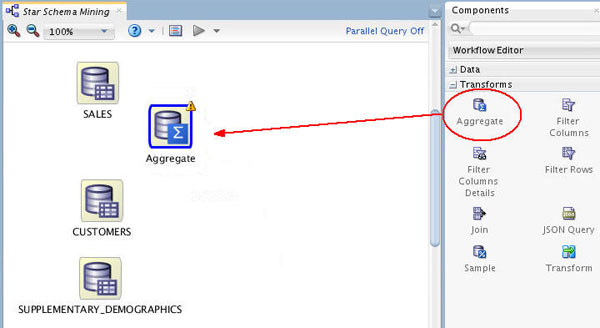
-
Connect the SALES data source node to the Aggregate node, by doing the following:
A. Right-click the SALES node, select Connect from the pop-up menu, and then drag the pointer to the Aggregate node.
B. Then, click the Aggregate node.
The workflow should now look something like this:
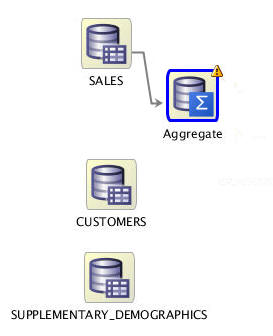
-
Double-click the Aggregate node to display to display the Edit Aggregation window.
-
Select a "Group By" attribute for the aggregation by performing the following:
A. Click Edit to open the Edit Group By window, as shown here:
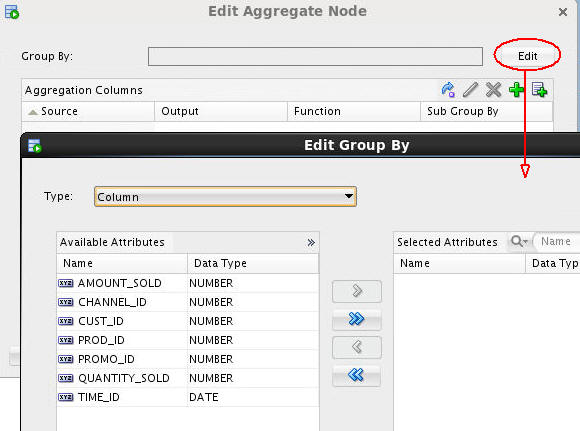
B. With Column selected as the Type value, move CUST_ID from the Available Attributes list to the Selected Attributes list, and then click OK, as shown below.
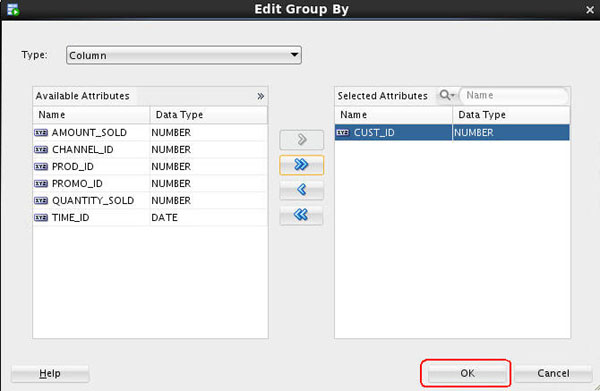
-
Next, use the Aggregation Wizard to define the aggregation rules.
A. Back in the Edit Aggregation window, click the Aggregation Wizard tool (as shown here) to launch the wizard:
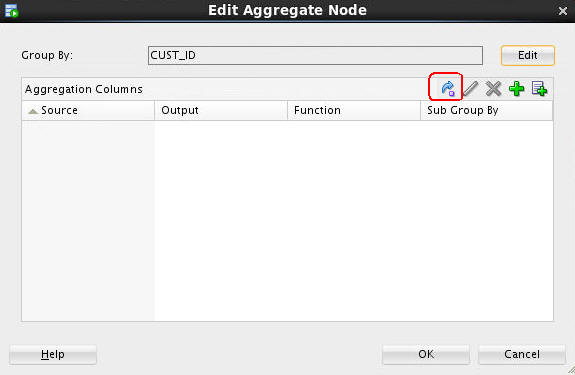
B. In the Define Aggregation Wizard, perform the following:
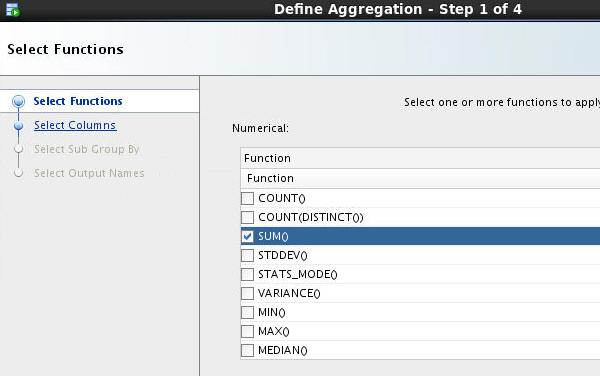
> In Step 1 of the wizard, select SUM() from the Numerical function list and click Next.
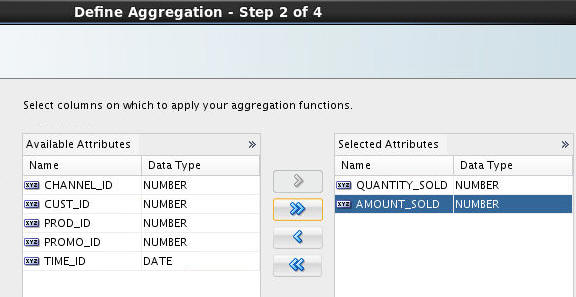
> In Step 2 of the wizard, move QUANTITY_SOLD and AMOUNT_SOLD to the Selected Attributes list and click Next.
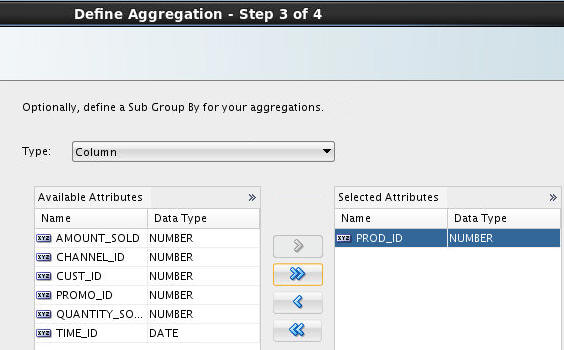
> In Step 3 of the wizard, move PROD_ID to the Selected Attributes list and click Next.
> In Step 4 of the wizard, accept the default aggregation names and click Finish.
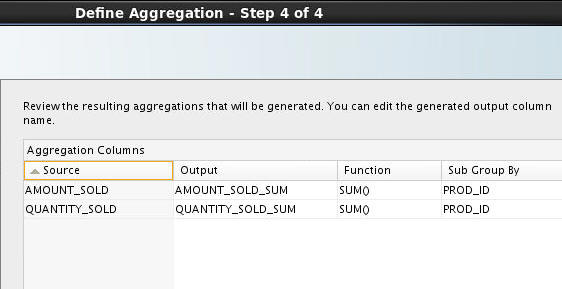
-
Back in the Edit Aggregation window, click OK to save the aggregation rules.
-
Right-click on the Aggregate node and select Run to run from the menu.
Result: The Aggregate node is executed and the process creates a nested table that can be used for data mining. After the process is done, the workflow display looks like this:

Join Data Sources
At this stage, the workflow contains three data sources and the aggregated output of SALES. Next, you use a Join node to combine CUSTOMERS, SUPPLEMENTARY_DEMOGRAPHICS, and Aggregated SALES into one data source.
Note: A Join combines rows from two or more tables, views, or materialized views. The join can select any columns from any of the tables being combined.
Here, you create an inner (or simple) join, which is a join of two or more tables that returns only those rows that satisfy the join condition.
Follow these steps:
-
Using the Transforms group, drag and drop a Join node to the workflow canvas, like this:
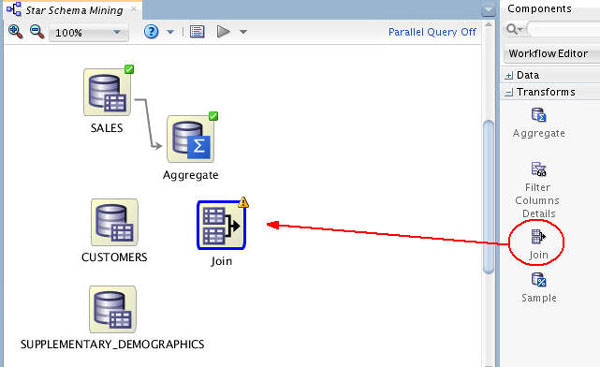
Notes: The yellow exclamation mark on the border indicates that more information needs to be specified before the node is complete. In this case, two actions are required: (A) The SUPPLEMENTARY_DEMOGRAPHICS, CUSTOMERS, and Aggregate (SALES) data nodes must be connected to the Join node. (B) The join columns must be specified in the Join node.
-
First, connect the CUSTOMERS data source node to the Join node using the right-mouse menu and the same technique described previously.
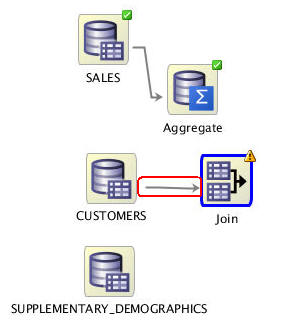
-
Then, connect the SUPPLEMENTARY_DEMOGRAPHICS node to the Join node, and the Aggregate node to the Join node. The workflow should now look something like this:
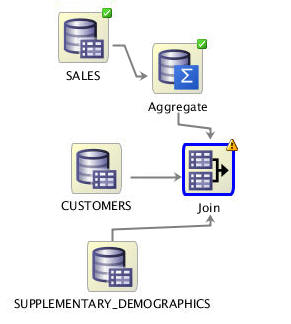
-
Now, to define the join, perform the following:
A. Double-click the Join node to open the Edit Join Node window.
B. Next, click the "+" tool to the right of the Join Columns header, as shown here:
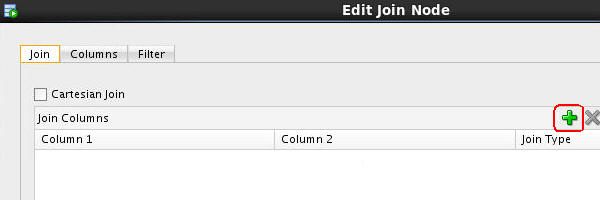
C. In the Edit Join Column Dialog, create two joins by performing the following:
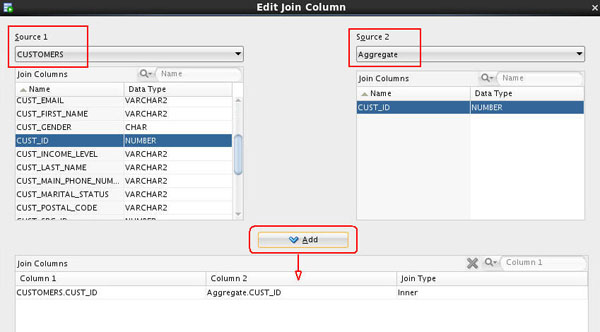
First join:
- Select CUSTOMERS in the Source 1 box, and Aggregate in the Source 2 box.
- Select CUST_ID as the join column in both Source 1 and in Source 2, and then click the Add button to populate the Join Columns box.
Second join:
- Back at the top of the window, select SUPPLEMENTARY_DEMOGRAPHICS in the Source 1 box, and CUSTOMERS in the Source 2 box.
- Select CUST_ID as the join column in both Source 1 and in Source 2, and then click the Add button to populate the Join Columns box.
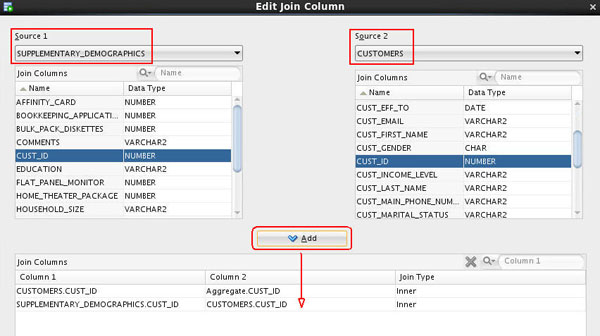
Note: Notice that the dialog determines that both Join Types are Inner.
D. Cick OK in the Edit Join Columns Dialog to complete the join specification.
Result: The join specification apears in the Edit Join Node window.
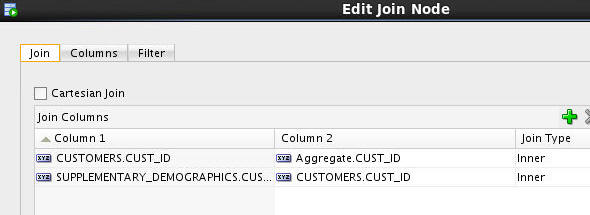
F. Finally, click OK in the Edit Join Node window.
Result: The Join node no longer contains the "!" warning, indicating that it is ready to run.
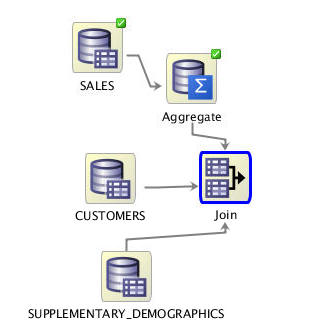
-
Next, right-click the Join node and select Run from the pop-up menu to create the join.
Result: The workflow document is saved and the join is executed. When complete, all of the nodes in the workflow canvas should contain green check marks:
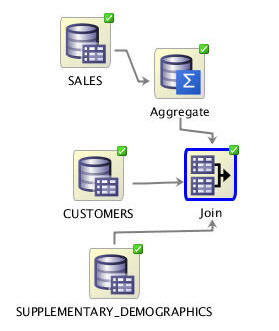
Create an Output Table for Increased Peformance
The output of the join node is a data flow. If you perform complex transformations, saving the result of the sequence of transformations as a table results in faster subsequent operations.
Therefore, you will create a table from the join node, and the Classification models are built against this table.
-
First, open the Data group in the Workflow Editor and then drag / drop the Create Table or View node to the workflow canvas like this:
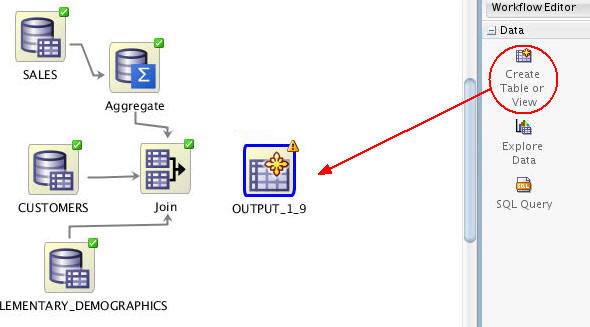
Result: An OUTPUT node appears. A generic name is automatically created for the node.
-
Next, using the technique you've learned to link nodes, connect the Join node to the OUTPUT node.
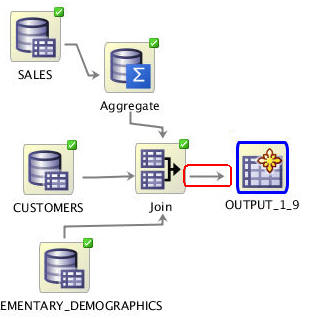
-
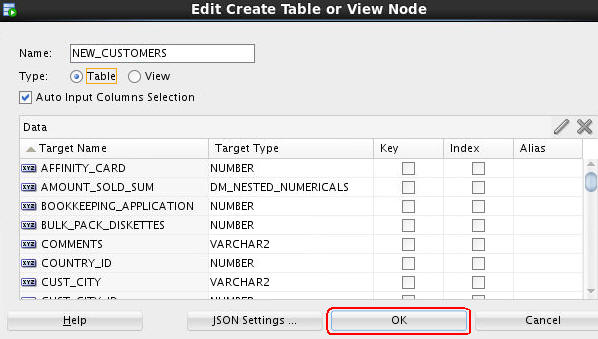
Double-click the OUTPUT node, and in the Edit Create Table or View Node window, perform the following:
- Name the output table NEW_CUSTOMERS
- Ensure that Table is selected as the Type
- Click OK
-
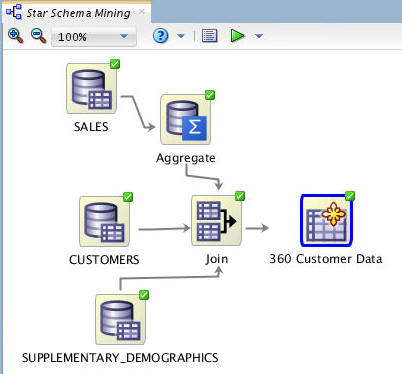
In the workflow, rename the NEW_CUSTOMERS node to 360 Customer Data.
-
Finally, right-click 360 Customer Data and select Run from the pop-up menu.
Result: The table is created. When the process is complete, the display should look something like this:
Build and Run Classification Models
In this topic, you build models that predict likely customer Affinity Card members, based on the aggregated data. Therefore, you will specify a classification model. By default, Oracle Data Miner selects all of the supported algorithms for a Classification model.
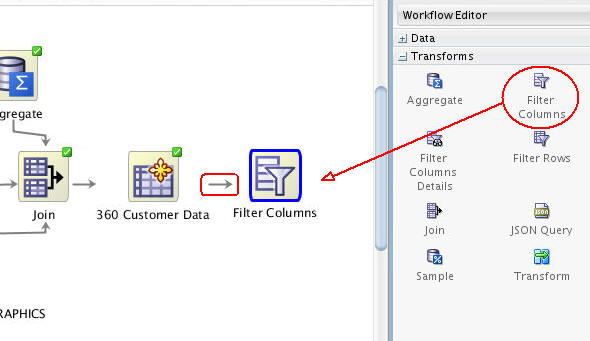
However, before creating the models, use a Filter Column node to assist in filtering out extraneous attributes.
-
To begin, add a Filter Columns node to the workflow by using the Transforms group. Then connect the 360 Customer Data node to the Filter Columns node, like this:
-
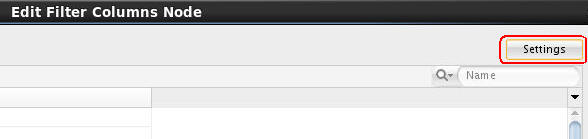
Next, double-click the Filter Columns node to open the Edit Filter Columns Node window. Then click the Settings button, as shown here:
-
In the Define Filter Column Settings, perform the following:
A. Enable the Attribute Importance option.
B. Select AFFINITY_CARD as the Target value.
C. Accept the remaining default settings that are enabled by the Attribute Importance option.

D. Click OK to save the filter column settings.
-
Now, click OK to close the Edit Filter Columns Node window.
-
In the workflow, right-click the Filter Columns Node and select Run from the menu.
Result: Data Miner uses the Filter Column Settings values to provide data on the relative importance of input attributes for predictive models. Double-click the Filter Columns node to view the result, shown here:
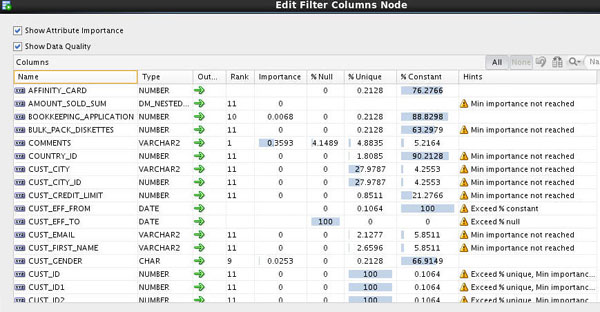
Notes: Using this attribute information, combined with knowledge of the data, we determine to filter out most of the attributes.
-
First, deselect the Show Data Quality option. Then, simply click the green arrow in the Output column for each attribute you wish to filter. This action changes the Output icon from a large green arrow to a small green arrow followed by a red "x". (This action may be reversed by doing the same thing.) Using this technique, filter out all of the attributes except for the following 15:
AFFINITY_CARD, AMOUNT_SOLD_SUM, BOOKKEEPING_APPLICATION, COMMENTS, CUST_GENDER, CUST_ID, CUST_INCOME_LEVEL, CUST_MARITAL_STATUS, EDUCATION, HOME_THEATER_PACKAGE, HOUSEHOLD_SIZE, OCCUPATION, QUANTITY_SOLD_SUM, YRS_RESIDENCE, Y_BOX_GAMES
Result: The Edit Filter Column Node values should now look like this:
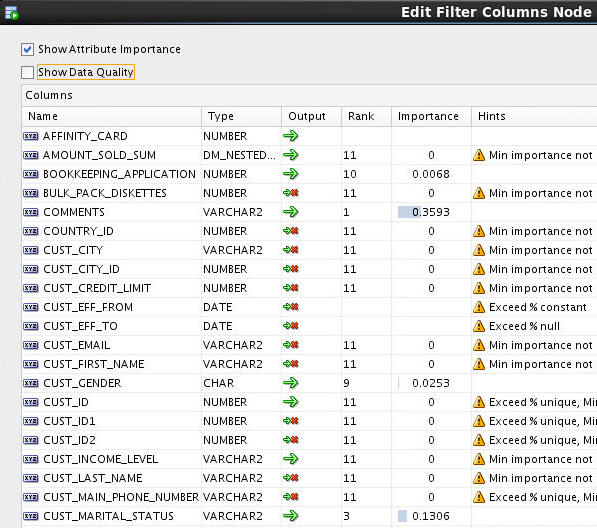
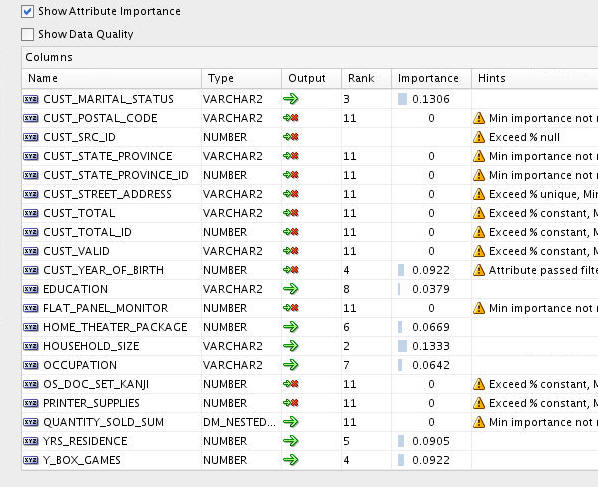
Finally, click OK to close the Edit Filter Column Node window.
-
Add a Classification node to the workflow by using the Models group, like this (notice that we have changed the workflow zoom value to 75% in order to see the entire workflow):
-
Next, connect the Filter Columns node to the Class Build node.
Result: the Edit Classification Build Node window automatically appears.
-
In the Edit Classification Build Node window, perform the following:
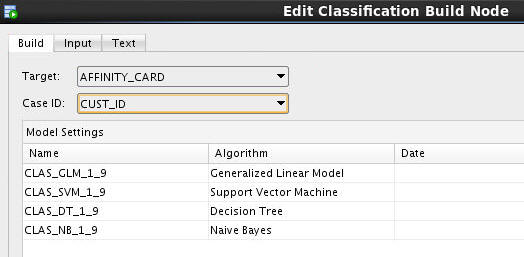
A. In the Build tab, select AFFINITY_CARD as the Target attribute and CUST_ID as the Case ID, as shown here:
B. Click on the Input tab and notice that only the 15 unfiltered attributes are available for the models. Perform the following:
> Frist, deselect the Determine inputs automatically option.
> Second, change the Mining Type for the following three attributes to Numerical: BOOKKEPPING_APPLICATION, HOME_THEATER_PACKAGE, and Y_BOX_GAMES. This is done by clicking on the attribute's Mining Type icon, and selecting from the drop-down list.
> Third, ensure that the COMMENTS attribute has a Mining Type of Text as shown below. If the auto-preparation feature selects Categorical as the Mining Type, change it to Text using the Mining Type icon.
Result: When finished, the values should look like this:
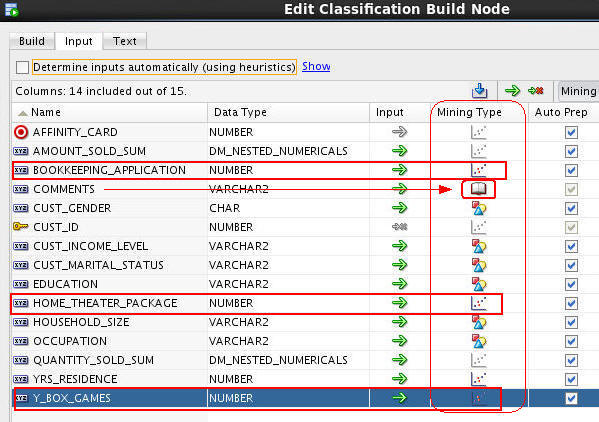
C. Then, click OK to save the new Mining Type specifications.
-
Next, change the name of the Class Build node to Predict AFFINITYCard.
-
Finally, right-click the Predict AFFINITYCard node and select Run from the menu.
When the model building process is complete, the workflow should look like this:
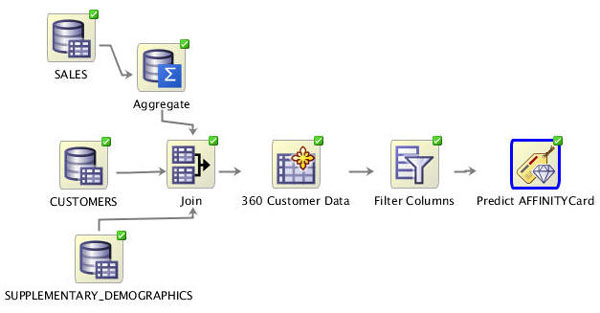
-
You can also view several pieces of information about the build using the Properties tab.
For example, select the Predict AFFINITYCard node in the workflow, and then choose the Models section in the Properties tab.
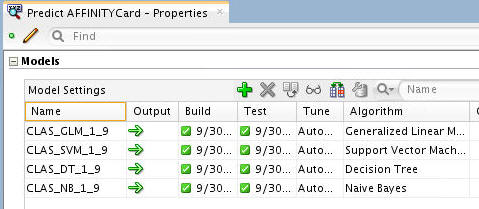
Notes:
- All four models have been succesfully built.
- The models all have the same target (AFFINITY_CARD) but use different algorithms.
- The source data is automatically divided into test data and build data.
Compare the Models
When execution of Predict AFFINITYCard node finishes, you have built and tested four classification models. You can view and compare the models.
Here, you view the relative results of the four classification models.
-
Right-click the Predict AFFINITYCard node and select Compare Test Results from the menu.
Results: The Predict AFFINITYCard display tab opens, showing a graphical comparison of the four models, as shown here:
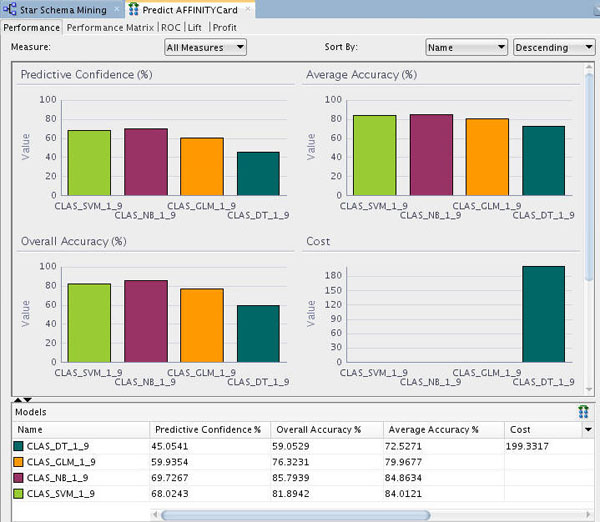
Notes: As stated previously, the sample data set is not prepared for mining per se, however the Data Mining Server still creates the specified models and generates predictions based on the aggregated data.
In terms of the Compare Test Results output, note the following:
- The histogram colors that you see may be different than those shown in this example.
- The comparison results include five tabs: Performance, Performance matrix, ROC, Lift, and Profit.
- The Performance tab provides numeric and graphical information for each model on Predictive Confidence, Average Accuracy, and Overall Accuracy.
- The Performance tab seems to indicate that the Naive Bayes (NB) and Support Vector Machine (SVM) algorithms are providing the highest confidence and accuracy results.
-
Select the Performance Matrix tab.
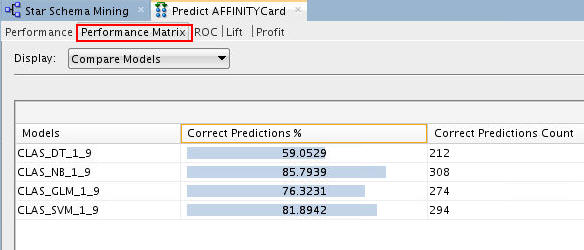
Notes:
The Performance Matrix shows that the NB and SVM models have a higher Correct Prediction percentage than the other models, at over 80% each.
-
Compare the details for the NB and SVM models.
A. First, select the NB model to view the Target Value Details for this model. Recall that the "Target Value" for each of the models is the AFFINITY_CARD attribute.
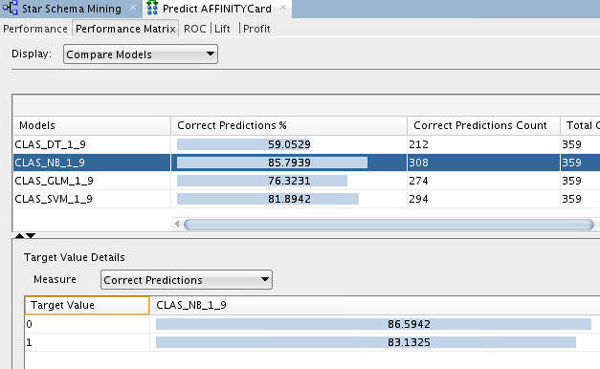
Note: The NB model indicates an 86.6% correct prediction outcome for customers who won't get the Affinity Card (0) and an 83% correct prediction outcome for customers who will get the Affinity Card (1).
B. Next, select the SVM model.
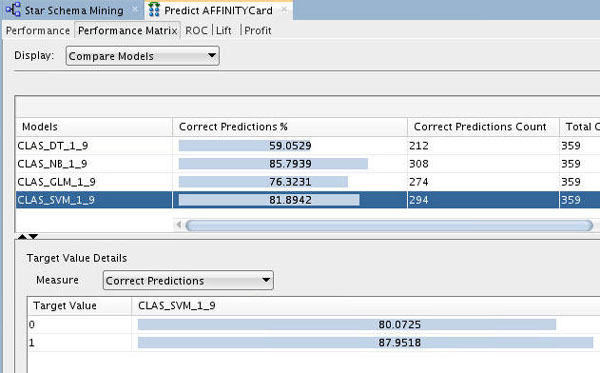
Notice that the SVM model indicates an 80% correct prediction outcome for customers who won't get the Affinity Card and an 88% correct prediction outcome for customers who will get the Affinity Card.
Conclusion: We decide to select the SVM model and apply it to our new customer data.
-
Dismiss the Predict AFFINITYCard tab.
Select and Apply the Model
In this topic, you apply the Support Vector Machine model and display the predictive results. As you learned in the Using Oracle Data Miner 4.1 tutorial, you "apply" a model in order to make predictions - in this case to predict which customers are likely to become Affinity Card members.
To apply a model, you perform the following steps:
- First, in the Class Build node specify the desired model (or models) to apply.
- Second, add a new Data Source node to the workflow. (This node will serve as the "Apply" data.)
- Third, add an Apply node to the workflow.
- Next, connect both the Class Build node and the new Data Source node to the Apply node.
- Finally, you run the Apply node to create predictive results from the model.
To apply the SVM model, perform the following:
-
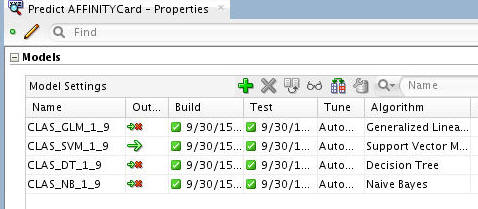
In the workflow, select the Predict AFFINITYCard node. Then, using the Models section of the Properties tab, deselect all of the models except for the SVM model.
To deselect a model, click the large green arrow in the model's Output column. This action adds a small red "x" to the column, indicating that the model will not be used in the next build.
When you finish, the Models tab of the Properties tab should look like this:
-
Next, add a new Data Source node in the workflow.
A. From the Data category in the Components tab, drag and drop a Data Source node to the workflow canvas, as shown below. The Define Data Source wizard opens automatically.
B. In the Define Data Source wizard, select the NEW_CUSTOMERS table, and then click FINISH.
Result: A new data souce node appears on the workflow canvas, with the name NEW_CUSTOMERS, as shown here.
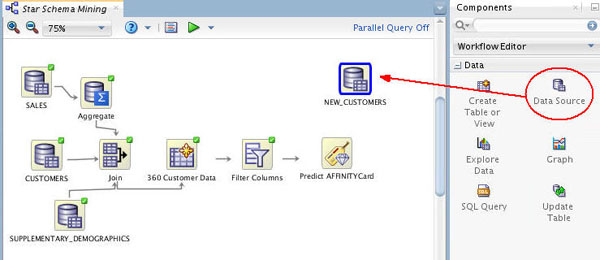
Notes: There isn’t a similar table provided in SH schema for the NEW_CUSTOMERS data (which was generated by the 360 Customer Data node.). Therefore, we will reuse the NEW_CUSTOMERS table as the 'Apply' data. Even though the data source is the same for both the Build and Apply tasks, you must still add a second data source for the workflow.
-
Next, expand the Evaluate and Apply category in the Components tab. Then drag and drop the Apply node to the workflow canvas, like this:.
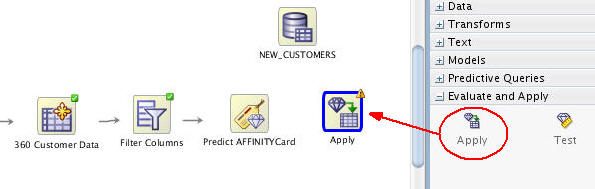
Note: The yellow exclamation mark in its border indicates that more information is required before the Apply node may be run.
-
Rename the Apply node to Likely Customers.
-
Next, connect the Predict AFFINITYCard node to the Likely Customers node, and then connect the NEW_CUSTOMERS node to the Likely Customers node. The result should look something like this:
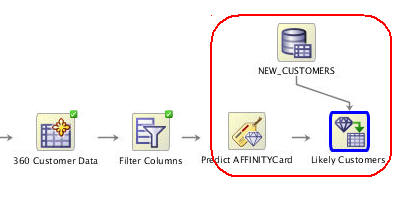
Notes: The yellow exclamation mark disappears from the Apply node border once the second link is completed. This indicates that the node is ready to be run.
-
Before you run the apply model node, consider the resulting output. By default, an apply node creates two columns of information for each customer:
- The prediction (Yes or No)
- The probability of the prediction
However, you really want to know this information for each customer, so that you can readily associate the predictive information with a given customer. To get this information, you need to add one or more columns to the apply output. Follow these instructions to add helpful customer information to the output:
A. Right-click the Likely Customers node and select Edit.
B. In the Predictions tab of the Edit Apply Node window, select CUST_ID as the Case ID.
Notice that the Prediction and Prediction Probability columns are defined automatically in the Predictions tab.
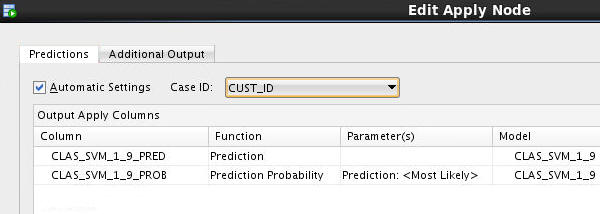
C. Select the Additional Output tab, and then click the green "+" sign, like this:
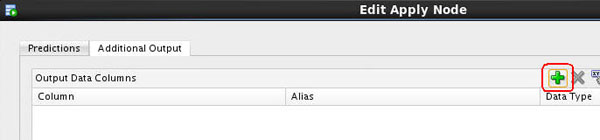
D. In the Edit Output Data Column Dialog:
- Multi-select the following values in the Available Attributes list: CUST_GENDER, CUST_ID, CUST_LAST_NAME, CUST_MARITAL_STATUS, HOUSEHOLD_SIZE, OCCUPATION, YRS_RESIDENCE.
- Move the values to the Selected Attributes list by using the shuttle control.
- Then, click OK.
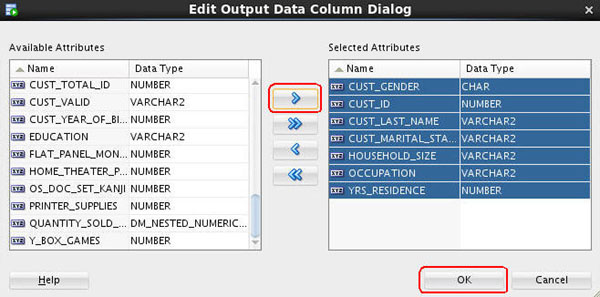
Result: The columns are added to the Additional Output tab.
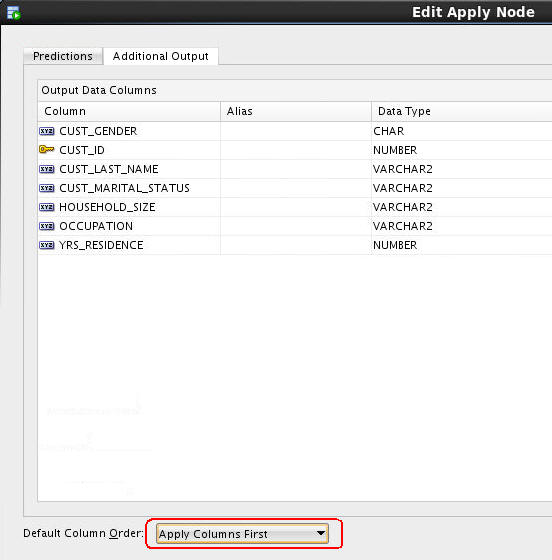
E. Also, notice that the Default Column Order option for output is to place the data columns first, and the prediction columns after. However, switch this order by selecting Apply Columns First, as shown above.
F. Finally, click OK in the Edit Apply Node window to save your changes.
-
Now, you are ready to apply the model. Right-click the Likely Customers node and select Run from the menu.
Result: As before, the workflow document is automatically saved, and small green gear icons appear in each of the nodes that are being processed. In addition, the execution status is shown at the top of the workflow pane.
When the process is complete, green check mark icons are displayed in the border of all workflow nodes to indicate that the server process completed successfully.
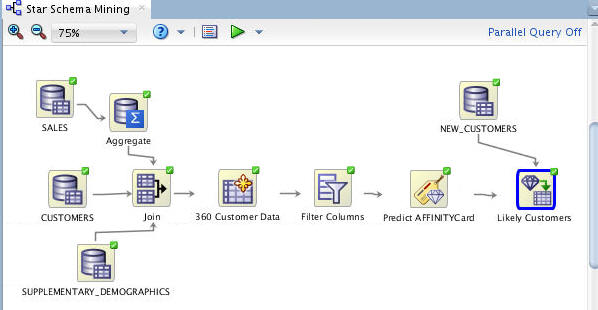
Optionally, you can create a database table to store the model prediction results, but we will view the results directly from the "Apply" node.
-
To view the results, perform the following:
A. Right-click the Likely Customers node and select View Data from the Menu.
Result: A new tab opens with the predictive results.
- The table contains the prediction columns and the output columns as specified earlier.
- You can sort the table results on any of the columns using the Sort button, as shown here.
- In this case, the table will be sorted using:
- First - the Predicted outcome (CLAS_SVM_1_9_PRED), in Descending order (meaning that the prediction of "Yes" for becoming an Affinity Card member.
- Second - Prediction Probability (CLAS_SVM_1_9_PROB), in Descending order (meaning that the highest prediction probabilities are at the top of the table display.
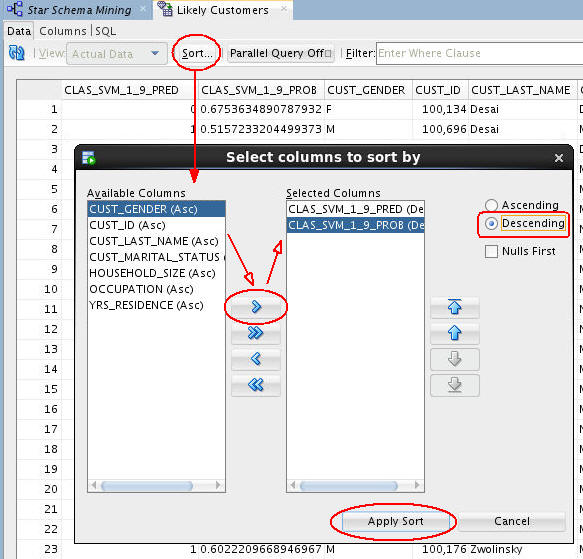
B. Finally, click Apply Sort to view the results.
Result: Your output should look something like this:
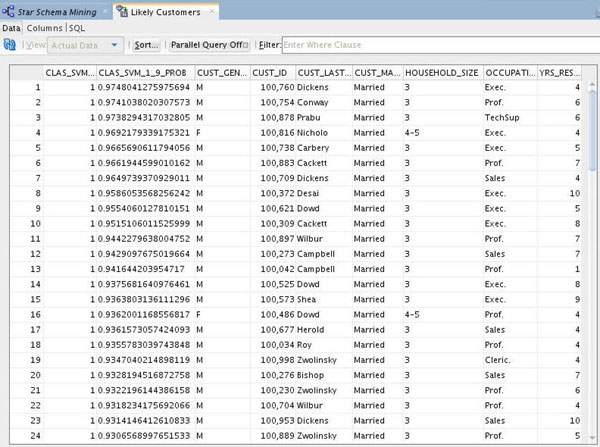
Notes:
- Each time you run an Apply node, Oracle Data Miner may take a different sample of the data to display. With each Apply, both the data and the order in which it is displayed may change. Therefore, the sample in your table may be different from the sample shown here. This is particularly evident when only a small pool of data is available, which is the case in the schema for this lesson.
- You can also filter the output by entering a Where clause in the Filter box.
- If saved in a table or view, the predictive results can be displayed using any application or tool that can read Oracle data, such as Oracle Application Express, Oracle BI Answers, Oracle BI Dashboards, and so on.
C. When you are done viewing the results, dismiss the tab for the Likely Customers tab table, and click Save All.