Before You Begin
Purpose
This tutorial covers the use of Oracle Data Miner 4.1 to perform data mining activities against Oracle Database 12c Release 12.1.0.2. Oracle Data Miner 4.1 is included as an extension of Oracle SQL Developer, version 4.1. In this lesson, you learn how to use Data Miner to create a classification model in order to solve a business problem.
Oracle SQL Developer is a free graphical tool for database development. With SQL Developer, you can browse database objects, run SQL statements and SQL scripts, and edit and debug PL/SQL statements. With SQL Developer, version 4.1, you can use the Oracle Data Miner against Oracle Database 12c.
Time to Complete
Approximately 45 mins
Background
Data mining is the process of extracting useful information from masses of data by extracting patterns and trends from the data. Data mining can be used to solve many kinds of business problems, including:
- Predict individual behavior, for example, the customers likely to respond to a promotional offer or the customers likely to buy a specific product (Classification)
- Find profiles of targeted people or items (Classification using Decision Trees)
- Find natural segments or clusters (Clustering)
- Identify factors more associated with a target attribute (Attribute Importance)
- Find co-occurring events or purchases (Associations, sometimes known as Market Basket Analysis)
- Find fraudulent or rare events (Anomaly Detection)
The phases of solving a business problem using Oracle Data Mining are as follows:
- Problem Definition in Terms of Data Mining and Business Goals
- Data Acquisition and Preparation
- Building and Evaluation of Models
- Deployment
Problem Definition and Business Goals
When performing data mining, the business problem must be well-defined and stated in terms of data mining functionality. For example, retail businesses, telephone companies, financial institutions, and other types of enterprises are interested in customer “churn” – that is, the act of a previously loyal customer in switching to a rival vendor. The statement “I want to use data mining to solve my churn problem” is much too vague. From a business point of view, the reality is that it is much more difficult and costly to try to win a defected customer back than to prevent a disaffected customer from leaving; furthermore, you may not be interested in retaining a low-value customer. Thus, from a data mining point of view, the problem is to predict which customers are likely to churn with high probability, and also to predict which of those are potentially high-value customers.
Data Acquisition and Preparation
A general rule of thumb in data mining is to gather as much information as possible about each individual, then let the data mining operations indicate any filtering of the data that might be beneficial. In particular, you should not eliminate some attribute because you think that it might not be important – let ODM’s algorithms make that decision. Moreover, since the goal is to build a profile of behavior that can be applied to any individual, you should eliminate specific identifiers such as name, street address, telephone number, etc. (however, attributes that indicate a general location without identifying a specific individual, such as Postal Code, may be helpful.) It is generally agreed that the data gathering and preparation phase consumes more than 50% of the time and effort of a data mining project.
Building and Evaluation of Models
The Workflow creation process of Oracle Data Miner automates many of the difficult tasks during the building and testing of models. It’s difficult to know in advance which algorithms will best solve the business problem, so normally several models are created and tested. No model is perfect, and the search for the best predictive model is not necessarily a question of determining the model with the highest accuracy, but rather a question of determining the types of errors that are tolerable in view of the business goals.
Deployment
Oracle Data Mining produces actionable results, but the results are not useful unless they can be placed into the correct hands quickly. The Oracle Data Miner user interface provides several options for publishing the results.
Scenario
This lesson focuses on a business problem that can be solved by applying a Classification model. In our scenario, ABC Company wants to identify customers who are most likely to purchase insurance.
Note: For the purposes of this tutorial, the "Data and Acquisition" phase has already been completed, and the sample data set contains all required data fields. Therefore, this lesson focuses primarliy on the "Building and Evaluation of Models" phase.
Context
Before starting this tutorial, you should have set up Oracle Data Miner for use within Oracle SQL Developer 4.1, by using the previous tutorial in this suite.
What Do You Need?
Have access to or have Installed the following:
- Oracle Database: Minimum: Oracle Database 12c Enterprise Edition, Release 1.0.2 (12.1.0.2.0) with the Advanced Analytics Option.
- The Oracle Database sample data, including the SH schema.
- SQL Developer 4.1
Create a Data Miner Project
Before you create a Data Miner Project and build a Data Miner workflow, it is helpful to organize the Data Miner interface components within SQL Developer to provide simplified access to the necesary Data Miner features.
To begin, close all of the SQL Developer interace elements (which may include the Connections tab, the Reports tab, and others), and leave only the Data Miner tab open, like this:
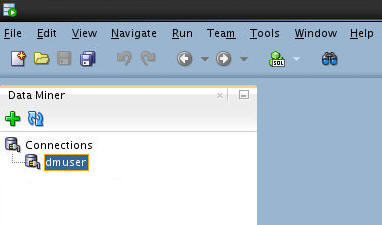
As shown above, the data miner user (dmuser) has been created and a SQL Developer connection has been established. In the Setting Up Oracle Data Miner 4.1 tutorial, you learn how to create a database account and SQL Developer connection for a data mining user named dmuser. This user has access to the sample data that you will be mining.
Note: If the Data Miner tab is not open, select Tools > Data Miner > Make Visible from the SQL Develper main menu.
-
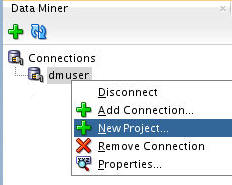
In the Data Miner tab, right-click dmuser and select New Project, as shown here:
-
In the Create Project window, enter a project name (in this example ABC Insurance) and then click OK.
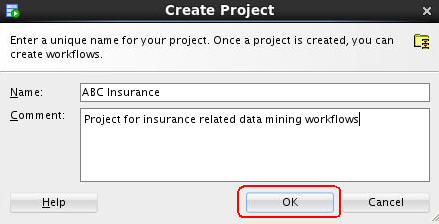
Note: You may optionally enter a comment that describes the intentions for this project. This description can be modified at any time.
Result: The new project appears below the data mining user connection node.
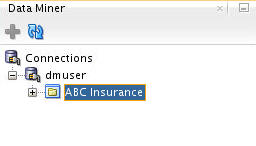
Next, you will learn how to build a workflow for the classification model.
Build A Data Mining Workflow
A Data Miner Workflow is a collection of connected nodes that describe a data mining processes.
A workflow:
- Provides directions for the Data Mining server. For example, the workflow says "Build a model with these characteristics." The model is built by the data mining server with the results returned to the workflow.
- Enables you to interactively build, analyze, and test a data mining process within a graphical environment.
- May be used to test and analyze only one cycle within a particular phase of a larger process, or it may encapsulate all phases of a process designed to solve a particular business problem.
What Does a Data Miner Workflow Contain?
Visually, the workflow window serves as a canvas on which you build the graphical representation of a data mining process flow, like the one you are going to create, shown here:

Notes:
- Each element in the process is represented by a graphical icon called a node.
- Each node has a specific purpose, contains specific instructions, and may be modified individually in numerous ways.
- When linked together, workflow nodes construct the modeling process by which your particular data mining problem is solved.
As you will learn, any node may be added to a workflow by simply dragging and dropping it onto the workflow area. Each node contains a set of default properties. You modify the properties as desired until you are ready to move onto the next step in the process.
Sample Data Mining Scenario
In this multistep topic, you will create a data mining process that predicts which existing customers are most likely to purchase insurance.
To accomplishe this goal, you build a workflow that enables you to:
- Identify and examine the source data
- Build and compare several Classification models
- Select and run the models that produce the most actionable results
To create the workflow for this process, perform the following steps.
Create a Workflow and Add a Data Source
-
Right-click your project (ABC Insurance) and select New Workflow from the menu.
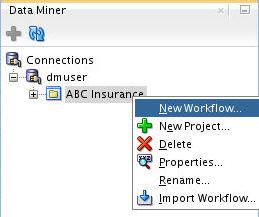
-
In the Create Workflow window, enter Targeting Best Customers as the name and click OK.
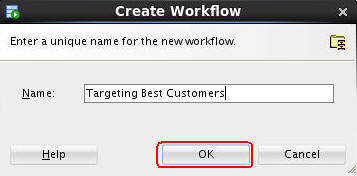
Result:
- In the middle of the SQL Developer window, an empty workflow tabbed window opens with the name that you specified.
- In addition, several other tabbed panes open.
- On the lower right-hand side of the interface the Properties tab is shown. On the upper right-hand side of the interface, the Components tab of the Workflow Editor appears. You learn more about these tabbed panes soon.
-
The first element of any workflow is the source data. Here, you add a Data Source node to the workflow, and select the INSUR_CUST_LTV_SAMPLE table as the data source.
A. In the Components tab, drill on the Data category. A group of six data nodes appear, as shown here:
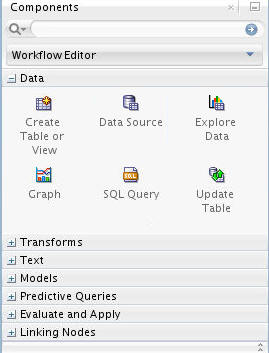
B. Drag and drop the Data Source node onto the Workflow pane. Result: A Data Source node appears in the Workflow pane and the Define Data Source wizard opens.

Notes:
- Workspace node names and model names are generated automatically by Oracle Data Miner. In this example, the name "Data Source" is generated. You may not get exactly the same node and model names as shown in this lesson.
- You can change the name of any workspace node in line or by using the Property Inspector. You will learn how to do this a bit later.
-
In Step 1 of the Wizard:
A. Select INSUR_CUST_LTV_SAMPLE from the Available Tables/Views list, as shown here:
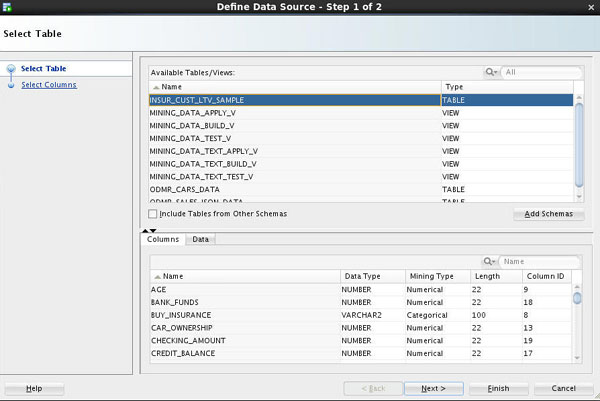
Note: You may use the two tabs in the bottom pane in the wizard to view and examine the selected table. The Columns tab displays information about the table structure, and the Data tab shows a subset of data from the selected table or view.
B. Click Next to continue.
-
In Step 2 of the wizard, you may remove individual columns that you don't need in your data source. In our case, we'll keep all of the attributes that are defined in the table. So here simply click Finish at the bottom of the wizard window.
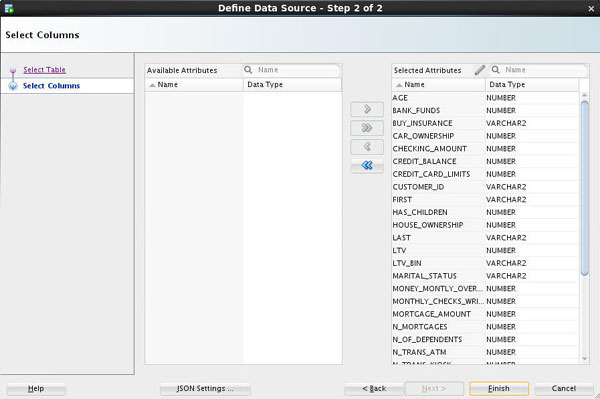
Result: As shown below, the data source node name is updated with the selected table name, and the properties associated with the node are displayed in the Properties tab.

Notes:
- You can resize nodes in the workflow canvas by entering or selecting a different value from the Zoom options. Notice that 75% has been selected from the Zoom pull-down list.
- You can move any Data Miner tab to a different location in the SQL Developer window. Notice that we've moved the Properties tab from the default lower-right location to beneath the workflow pane, simply by dragging the tab to the desired location.
- In the Properties tab, you may: A) View information about the columns in the table or view using the Data section; B) Generate a cache of output data to optimize viewing results using the Cache section. C) Change the node name and add descriptive information about any node by using the Details section.
As you will see later, you can open, close, resize, and move Data Miner tabbed panes around the SQL Developer window to suit your needs.
Examine the Data Source
You can use an Explore Data node to examine the source data. You can also use a Graph node to visualize data. Although these are optional steps in a workflow, Oracle Data Miner provides these tools to enable you to verify if the selected data meets the criteria to solve the stated business problem.
-
First, drag and drop the Explore Data node from the Data group to the Workflow, like this:
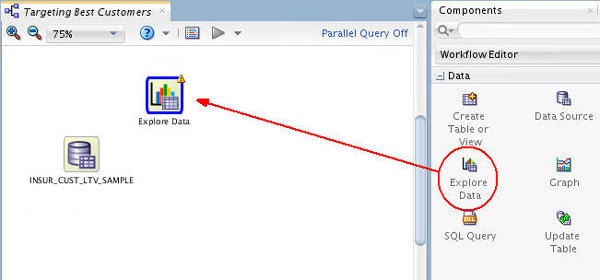
Result: A new Explore Data node appears in the workflow pane, as shown.
Notes:
- A yellow Information (!) icon in the border around any node indicates that it is not complete. Therefore, at least one addition step is required before the Explore Data node can be used.
- In this case, you must connect the data source node to the Explore Data node to enable further exploration of the source data.
-
To connect the data source and explore data nodes, use the following instructions:
A. Right-click the data source node (INSUR_CUST_LTV_SAMPLE), select Connect from the pop-up menu, and then drag the pointer to the Explore Data node, as shown here:

B. Then, click the Explore Data node to connect the two nodes. The resulting display looks something like this:
-
Next, select a "Group By" attribute for the data source.
A. Double-click the Explore Data node to display the Edit Explore Data Node window.
B. In the Group By list, select the BUY_INSURANCE attribute, as shown here:

C. Then, click OK.
Note: The Selected Attributes window also allows you to remove (or re-add) any attributes from the source data.
-
Next, right-click the Explore Data node and select Run.
Result:
- Data Miner saves the workflow document, and displays status information at the top of the Workflow pane while processing the node.
- As each node is processed, a green gear icon displays in the node border.
- When the update is complete, the data source and explore data nodes show a green check mark in the borders, like this:
Note: When you run any process from the workflow canvas, the steps that you have specified are executed by the Oracle Data Miner Server.
-
To see results from the Explore Data node, perform the following:
A. Right-click the Explore Data node and select View Data from the menu.
B. When a new tab opens for the Explore Data node, select the Statistics tab, as shown below.
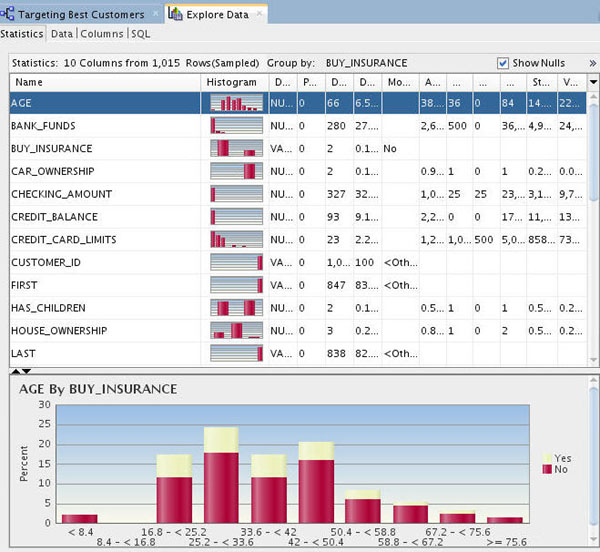
Notes:
- Data Miner calculates a variety of statistics about each attribute in the data set, as it relates to the "Group By" attribute that you previously defined (BUY_INSURANCE). Output columns include: a Histogram thumbnail, Data Type, Distinct Values, Distinct Percent, Mode, Average, Median, Min and Max value, Standard Deviation, and Variance.
- The display enables you to visualize and validate the data, and also to manually inspect the data for patterns or structure.
-
Next, use a Graph node to further visualize the data. Drag and drop the Graph node from the Data group to the workflow, like this:
Result: A new Graph node appears in the workflow pane, as shown. As seen before, a yellow Information (!) icon in the border around any node indicates that it is not complete.
-
Connect the data source node to the Graph node using the same technique as before. When connected, the nodes should look something like this:
-
Now, double-click the Graph node to display the New Graph window. Then specify the following attributes:
A. Click the Histogram button at the top, to select the graph type.
B. In the Title box, enter Histogram of AGE Grouped by LTV.
C. In the Histogram Settings region, select AGE for the Attribute value.
D. Then, enable the Group By option.
E. For the Group By Attribute option, select LTV_BIN.
The New Graph window should now look like this:
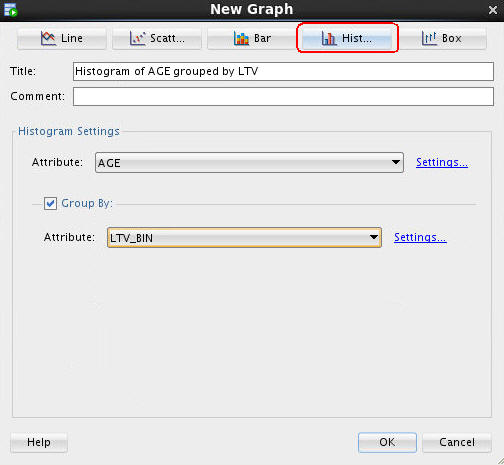
F. Click OK.
Result: The graph should look something like this:
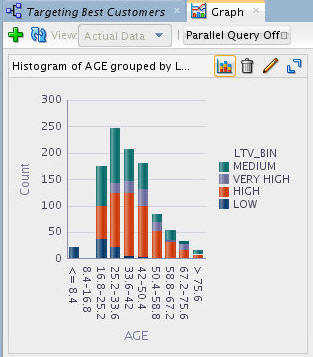
G. Optionally, you can select the Maximize tool
 to view a full-window display of the graph, like this:
to view a full-window display of the graph, like this: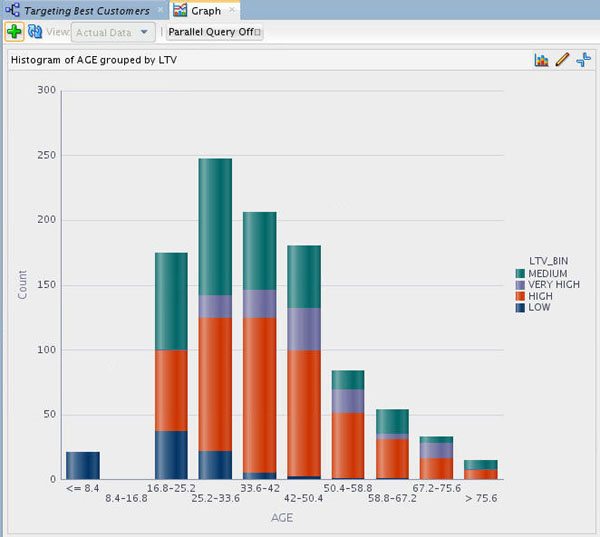
Note: Simply click the Restore tool (a toggle of the Maximize tool) to return to the original size.
-
You can create additional graphs within a single node by simply clicking the New Graph tool (green "+" icon), like this:
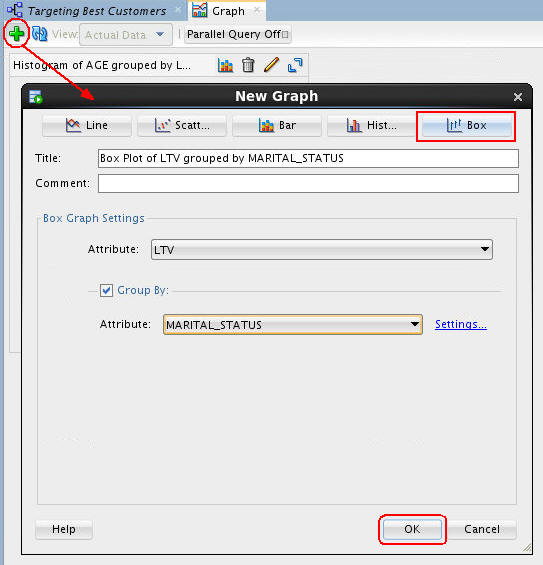
Notes: The example above defines a Box Plot of LTV (Life Time Value) grouped by MARITAL_STATUS.
The resulting display looks like this:
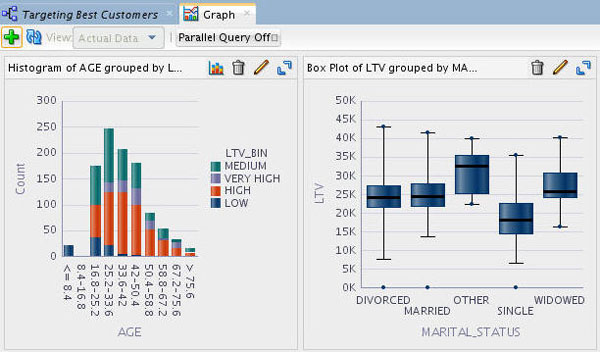
-
When you are done experimenting with the Graph node, dismiss the Graph tabbed window by clicking the Close icon (X).
Next, you move from a high-level manual analytic exercise to using the power of database data mining.
B. Select any of the attributes in the Name list to display the associated histogram in the bottom window.
C. When you are done examining the source data, dismiss the Expore Data tab by clicking the Close icon (X).
Create Classification Models
As stated in the Overview section of this tutorial, classification models are used to predict individual behavior. In this scenario, you want to predict which customers are most likely to buy insurance. Therefore, you will specify a classification model.
When using Oracle Data Miner, a classification model creates up to four models using different algorithms, and all of the models in the classification node have the same target and Case ID. This default behavior makes it easier to figure out which algorithm gives the best predictions. Here, you define a Classification node that uses all algorithms for the model.
Then, in the subsequent topic, you will run and examine each of the models
To create the default Classification models, follow these steps:
-
A. First, collapse the Data category, and expand the Models category in the Components tab:
B. Then, drag and drop the Classification node from the Components tab to the Workflow pane:
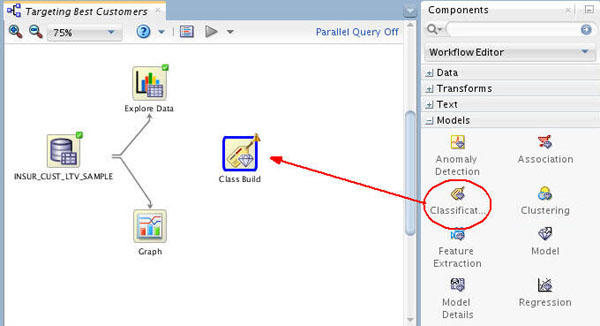
Result: A node with the name "Class Build" appears in the workflow:
-
Now, connect the data source node to the classification build node like this, using the same technique described previously.
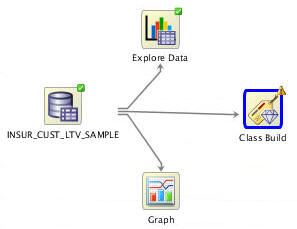
Result: The Edit Classification Build Node window automatically appears.
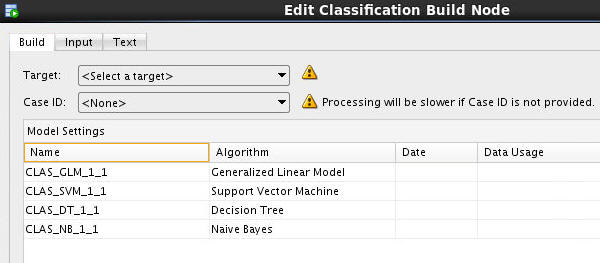
Notes: A yellow "!" indicator is displayed next to the Target and Case ID fields. This means that an attribute must be selected for these items. In addition, the names for each model are automatically generated, and yours may differ slightly from those in this example.
-
In the Edit Classification Build Node window:
A. Select BUY_INSURANCE as the Target attribute.
B. Select CUSTOMER_ID as the Case ID attribute.

Notes: Although not required, it is advised that you also define a Case ID to uniquely define each record. This helps with model repeatability and is consistent with good data mining practices. As stated previously, all four algorithms for Classification modeling are selected by default. They will be automatically run unless you specify otherwise.
-
Optionally, you can modify specific settings for any of the listed algorithms by double-clicking on any algorithm.
A. For example, double-click the algorithm column for the first (GLM) model to display the Advanced Model Settings window, as shown here:
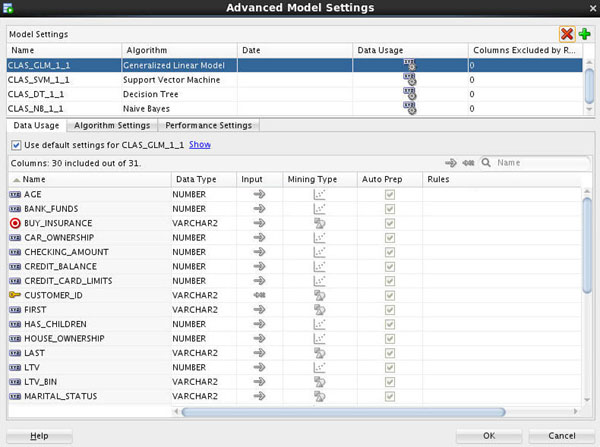
Notes: The Advanced Model Settings window enables you to specify data usage, algorithm settings, and performance settings for each of the four classification algorithms. You can also de-select (and re-select) any algorithm from this window using the red "x" or green "+" icons.
B. Select the Support Vector Machine (SVM) algorithm and click the Algorithm Settings tab.
C. Then, in the Kernel Function option, select Linear, as shown here:
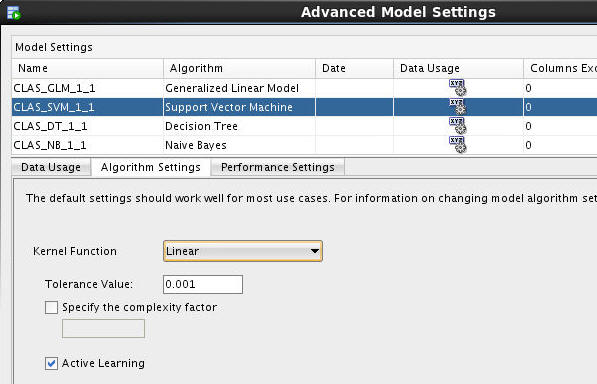
Note: We want to change the value of this Support Vector Machine (SVM) algorithm setting from the system determined value to Linear in order to make the model results easier to interpret.
D. Feel free to view any of the tabs for each algorithm, however do not modify any of the other default settings.
E. When you are done browsing, click OK to save the SVM algorithm setting.
-
Finally, click OK in the Edit Classification Build Node window to save your changes
Result: The classification build node is ready to run.
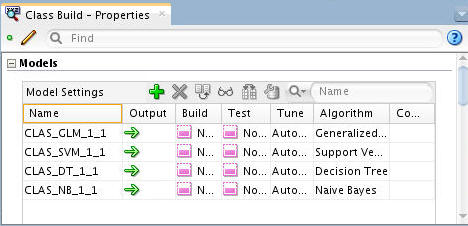
Note: In the Models section of the Properties tab, you can see the current status for each of the selected algorithms, as shown below:
-
Save the workflow by clicking the Save All icon in main toolbar.
Build the Models
In this topic, you build the selected models against the source data. This operation is also called “training”, and the model is said to “learn” from the training data.
A common data mining practice is to build (or train) your model against part of the source data, and then to test the model against the remaining portion of your data.
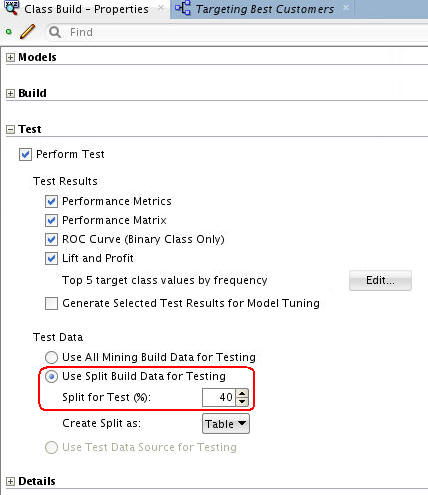
Before building the models, select Class Build node and expand the Test section of the Properties tab. In the Test section, you can specify:
- Whether or not to perform a test during the build process
- Which test results to generate
- How you want the test data managed
In the Test Data region, notice that the Split for Test value is 40, which means the model will be built (trained) against 60% of the data, and tested against the remaining 40% You can change this default setting to any split that you desire.
Next, you build the models
-
Right-click the Class Build node and select Run from the pop-up menu.
Notes:
- When the node runs it builds and tests all of the models that are defined in the node.
- As before, a green gear icon appears on the node borders to indicate a server process is running, and the status is shown at the top of the workflow window.
When the build is complete, all nodes contain a green check mark in the node border.
In addition, you can view several pieces of information about the build using the property inspectory.
-
Select the classification build node in the workflow, and then select the Models section in the Properties tab.

Notes:
- All four models have been succesfully built.
- The models all have the same target (BUY_INSURANCE) but use different algorithms.
- The source data is automatically divided into test data and build data.
Compare the Models
After you build/train the selected models, you can view and evaluate the results for all of the models in a comparative format. Here, you compare the relative results of all four classification models.
-
Right-click the classification build node and select Compare Test Results from the menu.
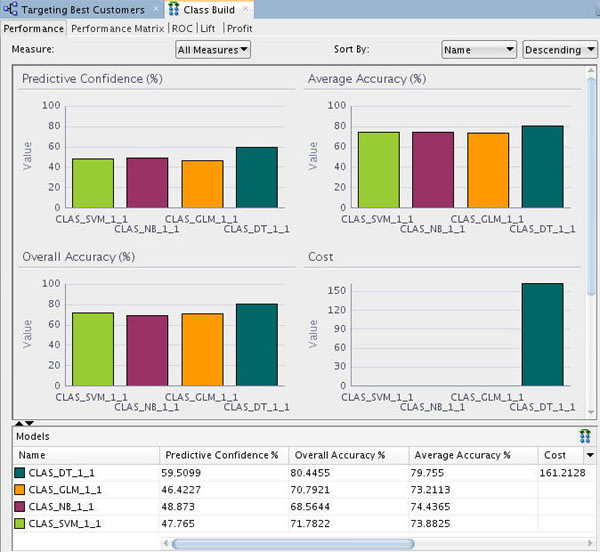
Results: A Class Build display tab opens, showing a graphical comparison of the four models in the Performance tab, as shown here:
Notes:
Since the sample data set is very small, the numbers you get may differ slightly from those shown in the tutorial example. In addition, the histogram colors that you see may be different then those shown in this example.
- The comparison results include five tabs: Performance, Performance Matrix, ROC, Lift, and Profit.
- The Performance tab provides numeric and graphical information for each model on Predictive Confidence, Average Accuracy, and Overall Accuracy.
- The Performance tab seems to indicate that the Decision Tree (DT) model is providing the highest predictive confidence, overall accuracy %, and average accuracy %. The other models show mixed results.
-
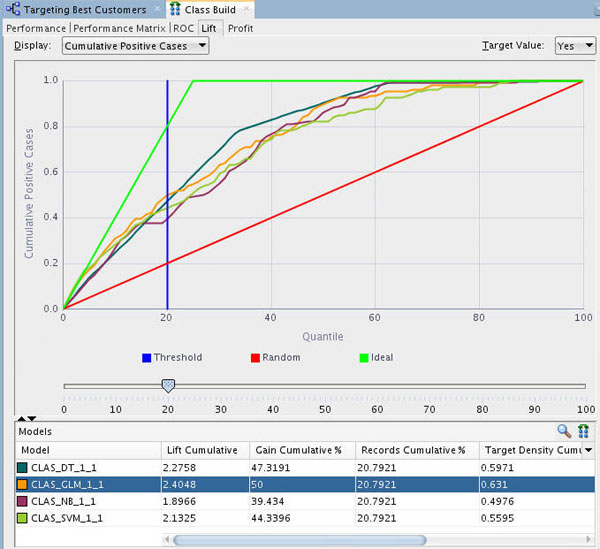
Select the Lift tab. Then, ensure that a Target Value of Yes is selected in the upper-right side of the graph.
Notes:
- The Lift tab provides a graphical presentation showing lift for each model, a red line for the random model, and a vertical blue line for threshold.
- Lift is a different type of model test. It is a measure of how “fast” the model finds the actual positive target values.
- The Lift viewer compares lift results for the given target value in each model.
- The Lift viewer displays Cumulative Positive Cases and Cumulative Lift.
Using the example shown above at the 20th quantile, the DT, Generalized Linear Model (GLM), and Support Vector Machine (SVM) models are very close in terms of the Lift Cumulative and Gain Cumulative %.
In the Lift tab, you can move the Quanitile measure point line along the X axis of the graph by using the slider tool, as shown below. The data in the Models pane at the bottom updates automatically as you move the slider left or right. Note the following, as shown in the image below:
- As you move up the quantile range, the Lift Cumulative and Gain Cumulative % of the DT model overtakes the other models, as shown at the 40th quantile.
- As you move up past the 40th quantile, the other models show divergent changes in Lift and Gain. However, the DT model continues to provides the best Lift and Gain results.

-
Next, select the Performance Matrix tab.

Notes: The Performance Matrix shows that the DT model has the highest Correct Predictions percentage, at over 80%. The SVM and GLM models are next in the low 70th percentile range.
-
Compare the details for the SVM and DT models.
First, select the SVM model to view the Target Value Details for this model. Recall that the "Target Value" for each of the models is the BUY_INSURANCE attribute.

Notes: The SVM model indicates a 69% correct prediction outcome for customers that don't buy insurance and a 78% correct prediction outcome for customers that do buy insurance.
Next, select the DT model.
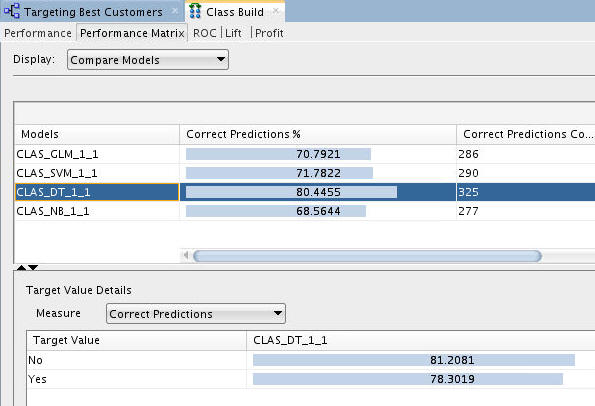
Notes: The DT model indicates a 81% correct prediction outcome for customers that don't buy insurance, and a 78% correct prediction outcome for customers that do buy insurance.
-
After considering the initial analysis, you decide to investigate the Decision Tree model more closely. Dismiss the Class Build tabbed window.
Select and Examine a Specific Model
Using the analysis performed in the previous topic, the Decision Tree model is selected for further analysis.
-
Back in the workflow pane, right-click the Class Build node again, and select View Models > CLAS_DT_1_1 (Note: The exact name of your Decision Tree model may be different).
Result: A window opens that displays a graphical presentation of the Decision Tree.
-
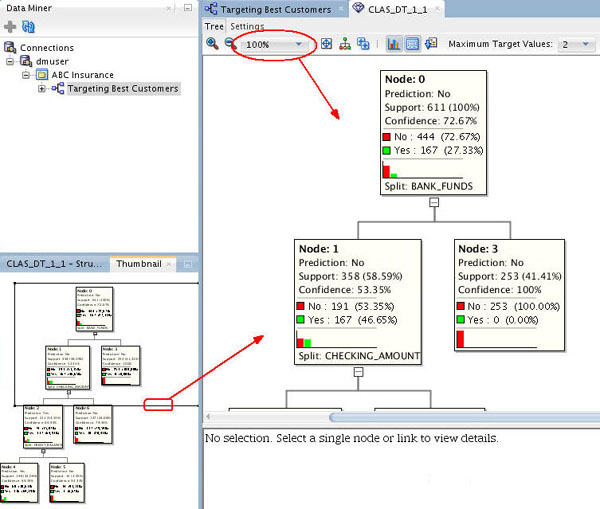
The interface provides several methods of viewing navigation:
- The Thumbnail tab provides a high level view of the entire tree. For example, the Thumbnail tab shows that this tree contains four levels, although you view fewer of the nodes in the primary display window.
- You can move the viewer box around within the Thumbnail tab to dynamically locate your view in the primary window. You can also use the scroll bars in the primary display window to select a different location within the decision tree display.
- Finally, you can change the viewer percentage zoom in the primary display window to increase or decrease the size of viewable content
For example, here we have the primary viewer window for the decision tree is set to 100% zoom, and the Thumbnail tab shows the entire tree, with the zoom portion outlined with the rectangle. You can change the zoom factor and scroll around in the main window using either the thumbnail tab or the primary window scroll bars.
-
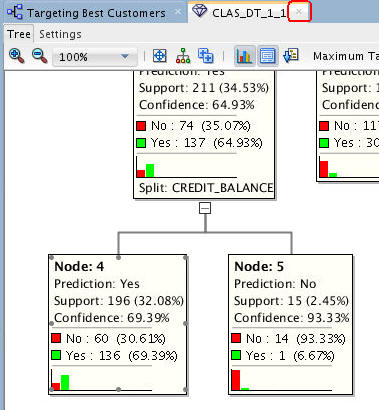
Navigate to and select Node 2.
Notes:
- At each level within the decision tree, an IF/THEN statement that describes a rule is displayed. As each additional level is added to the tree, another condition is added to the IF/THEN statement.
- For each node in the tree, summary information about the particular node is shown in the box.
- In addition, the IF/THEN statement rule appears in the Rule tab, as shown below, when you select a particular node.
- Commonly, a decision tree model would show a much larger set of levels and also nodes within each level in the decision tree. However, the data set used for this lesson is significantly smaller than a normal data mining set, and therefore the decision tree is also small.
-
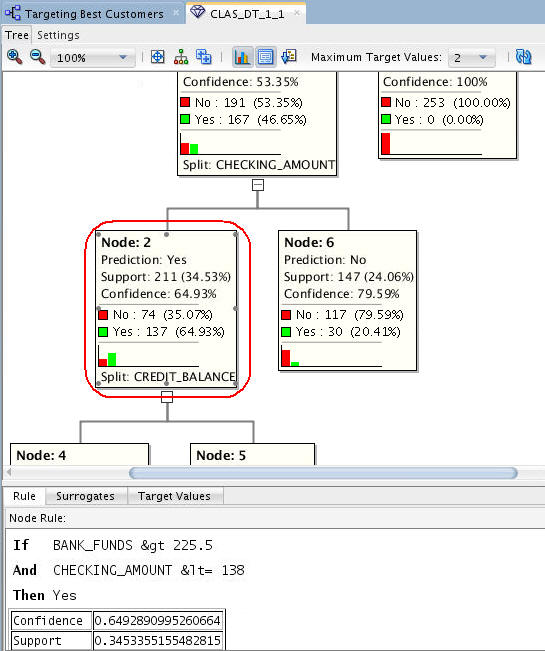
Notes:
- At this level, we see that the first split is based on the BANK_FUNDS attribute, and the second split is based on the CHECKING_AMOUNT attribute.
- Node 2 indicates that if BANK_FUNDS are greater than 225.5, and CHECKING_AMOUNT is less than or equal to 138, then there is a 64.9% chance that the customer will buy insurance.
- Data Miner also enables you to copy and paste chart images from virtually any image in the UI. Then, the image may be pasted into another document. For example, here we select Node 2 in the decision tree and copy it to the clipboard.
-
Next, select Node 4, at the bottom level in the tree.

Notes: At this bottom level in the tree, a final split is added for the CREDIT_BALANCE attribute.Therefore, This node indicates that if BANK_FUNDS are greater than 225.5, and CHECKING_AMOUNT is less than or equal to 138, and CREDIT_BALANCE is less than or equal to 1434.5, then there is a 69% chance that the customer will buy insurance..
-
Dismiss the Decision Tree display tab as shown here:
Apply the Model
In this topic, you apply the Decision Tree model and then create a table to display the results. You "apply" a model in order to make predictions - in this case to predict which customers are likely to buy insurance.
To apply a model, you perform the following steps:
- First, specify the desired model (or models) in the Class Build node.
- Second, add a new Data Source node to the workflow. (This node will serve as the "Apply" data.)
- Third, an Apply node to the workflow.
- Next, connect both the Class Build node and the new Data Source node to the Apply node.
- Finally, you run the Apply node to create predictive results from the model.
To apply the DT model, perform the following:
-
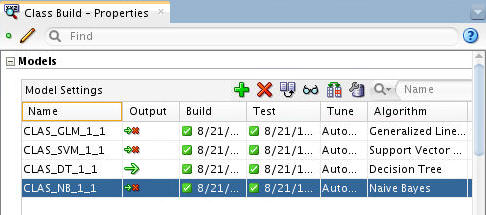
In the workflow, select the Class Build node. Then, using the Models section of the Properties tab, deselect all of the models except for the DT model.
To deselect a model, click the large green arrow in the model's Output column. This action adds a small red "x" to the column, indicating that the model will not be used in the next build.
When you finish, the Models tab of the Property Inspector should look like this:
-
Next, add a new Data Source node in the workflow. Note: Even though we are using the same table as the "Apply" data source, you must still add a second data source node to the workflow.
A. From the Data category in the Components tab, drag and drop a Data Source node to the workflow canvas, as shown below. The Define Data Source wizard opens automatically.
B. In the Define Data Source wizard, select the INSUR_CUST_LTV_SAMPLE table, and then click FINISH.

Result: A new data souce node appears on the workflow canvas, with the name INSUR_CUST_LTV_SAMPLE1.
-
Click on the the new data source node name in the workflow. Then, change the node name to INSUR_CUST_LTV_APPLY, as shown below:
Note: press [Enter] to complete the node name change
-
Next, expand the Evaluate and Apply category in the Components tab.
-
Drag and drop the Apply node to the workflow canvas, like this:
Note: The yellow exclamation mark in its border indicates that more information is required before the Apply node may be run.
-
Rename the Apply node to Apply Model, using the same technique as above.
-
Next, connect the Class Build node to the Apply Model node, like this:

-
Then, connect the INSUR_CUST_LTV_APPLY node to the Apply Model node, as shown here:
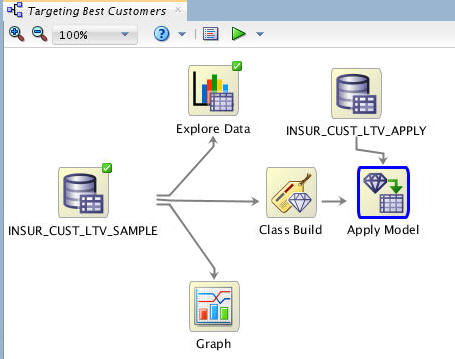
Notes: The yellow exclamation mark disappears from the Apply node border once the second link is completed. This indicates that the node is ready to be run.
-
Before you run the apply model node, consider the resulting output. By default, an apply node creates two columns of information for each customer:
- The prediction (Yes or No)
- The probability of the prediction
However, you really want to know this information for each customer, so that you can readily associate the predictive information with a given customer.
To get this information, you need to add a third column to the apply output: CUSTOMER_ID. Follow these instructions to add the customer id to the output:
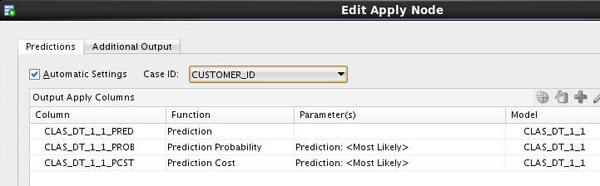
A. Right-click the Apply Model node and select Edit.
B. In the Predictions tab of the Edit Apply Node window, select CUSTOMER_ID as the Case ID.
Notice that the Prediction, Prediction Probability, and Prediction Cost columns are defined automatically in the Predictions tab.
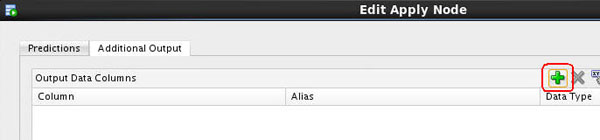
C. Select the Additional Output tab, and then click the green "+" sign, like this:
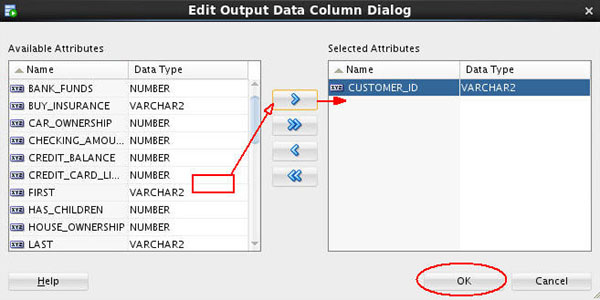
D. In the Edit Output Data Column Dialog:
- Select CUSTOMER_ID in the Available Attributes list.
- Move it to the Selected Attributes list by using the shuttle control.
- Then, click OK.
Result: The CUSTOMER_ID column is added to the Additional Output tab, as shown here:
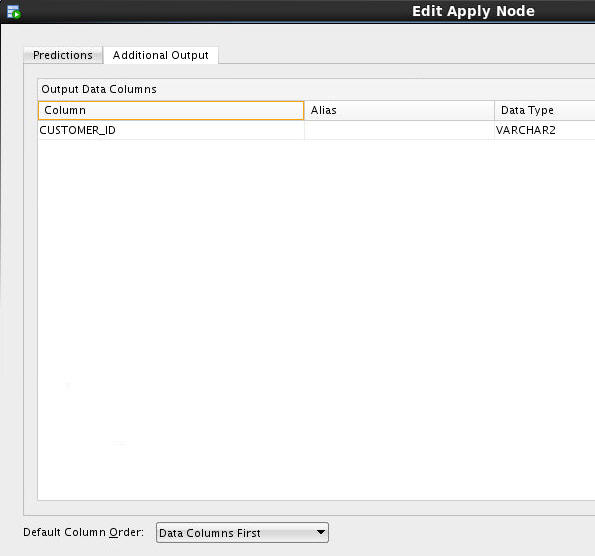
Also, notice that the Default Column Order option for output is to place the data columns first, and the prediction columns after. You can switch this order if desired.
E. Finally, click OK in the Edit Apply Node window to save your changes.
-
Now, you are ready to apply the model. Right-click the Apply Model node and select Run from the menu.
Result: As before, the workflow document is automatically saved, and small green gear icons appear in each of the nodes that are being processed. In addition, the execution status is shown at the top of the workflow pane.
When the process is complete, green check mark icons are displayed in the border of all workflow nodes to indicate that the server process completed successfully.
-
Optionally, you can create a database table to store the model prediction results (the "Apply" results).
To create a table of model prediction results, perform the following:
A. Using the Data category in the Components pane, drag the Create Table or View node to the workflow window, like this:
Result: An OUTPUT node is created (the name of your OUTPUT node may be different than shown in the example).
B. Connect the Apply Model node to the OUTPUT node, like this:
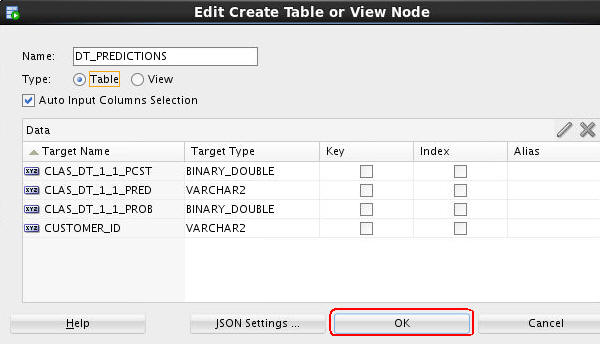
C. To specify a name for the table that will be created (otherwise, Data Miner will create a default name), do the following:
- Right-click the OUTPUT node and select Edit from the menu.
- In the Edit Create Table or View Node window, change the default table name to DT_PREDICTIONS, as shown below.
- Then click OK.
D. Lastly, right-click the DT_PREDICTIONS node and select Run from the menu.
Result: The workflow process is executed. When complete, all nodes contain a green check mark in the border, like this:
Note: After you run the OUTPUT node (DT_PREDICTIONS), the table is created in your schema.
-
To view the results, perform the following:
A. Right-click the DT_PREDICTIONS Table node and select View Data from the Menu.
Result: A new tab opens with the contents of the table:
- The table contains four columns: three for the prediction data, and one for the customer ID.
- You can sort the table results on any of the columns using the Sort button, as shown here.
- In this case, the table will be sorted using:
- First - the Predicted outcome (CLAS_DT_1_1_PRED), in Descending order (meaning that the prediction of "Yes" for buying insurance is first.
- Second - Prediction Probability (CLAS_DT_1_1_PROB), in Descending order (meaning that the highest prediction probabilities are at the top of the table display.
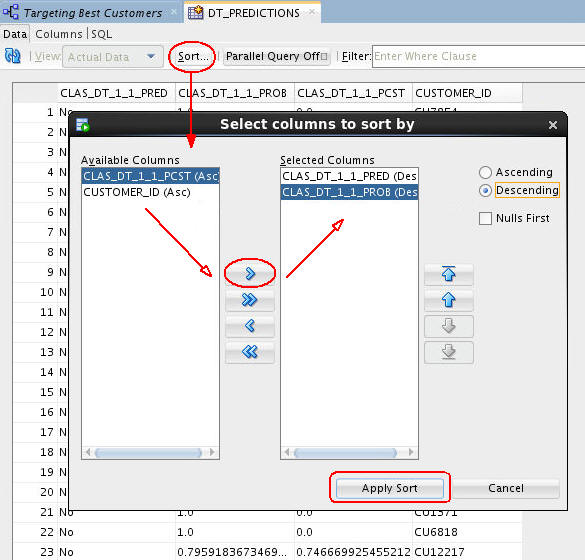
B. Finally, click Apply Sort to view the results.
Result: Your output should look something like this:
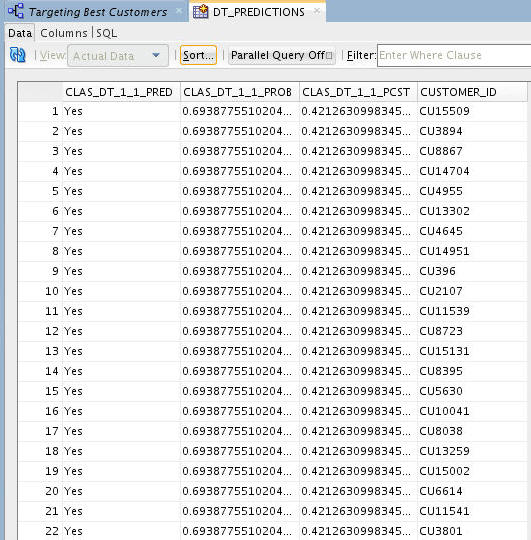
Notes:
- Each time you run an Apply node, Oracle Data Miner takes a different sample of the data to display. With each Apply, both the data and the order in which it is displayed may change. Therefore, the sample in your table may be different from the sample shown here. This is particularly evident when only a small pool of data is available, which is the case in the schema for this lesson.
- You can also filter the table by entering a Where clause in the Filter box.
- The table contents can be displayed using any Oracle application or tools, such as Oracle Application Express, Oracle BI Answers, Oracle BI Dashboards, and so on.
C. When you are done viewing the results, dismiss the tab for the DT_PREDICTIONS table, and click Save All.