A snapshot is a staged copy of data in a Data Store that is used in one or more processes.
Note that you do not have to copy the data that you are working with, but doing so allows you greater access to Director's results browsing functionality, as you are able to drill down on processor metrics to see the data itself, at each stage in your processing.
Commonly, you might take a copy of the data when working on an audit process, or when defining the rules for data cleansing, but you might run a process in streaming mode (that is, without copying data into the repository) when you run a data cleansing process in production, in order to save time in execution. See the Performance Tuning Guide for more information.
You may define the following properties of a snapshot:
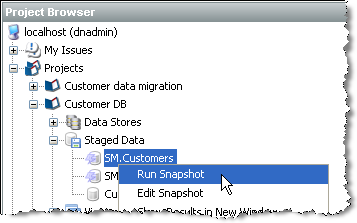
Once a snapshot configuration has been added, you can run the snapshot by right-clicking on it in the Project Browser, and selecting Run Snapshot:
Alternatively, you may choose to run the snapshot when you run the first process that uses it.
Snapshots are shared at the project level. This means that many processes in the same project may use the same snapshot, but processes in different projects may not. If you copy and paste a Snapshot configuration into a new project, this is an independent snapshot, and you will need to run it in order to use the staged data in a process (unless you are streaming data from the data source).
You can edit a snapshot using a Right-click menu option - for example to change the size of sample that you are working from.
Note that if you choose to rename a snapshot, and that snapshot is used in processes, those processes will be invalidated. They will not automatically point at the renamed snapshot. Processes refer to snapshots by name so that you can easily move configurations between servers, where internal IDs would be different.
If required, you can also delete a snapshot using a Right-click menu option. Note that if the snapshot is used by other configuration objects, a warning will be displayed as these objects may be in error.
Note that it is normally best to snapshot all columns, and select those you wish to work with in a given process by configuring the Reader.
It is possible to normalize various forms of No Data when data is copied into the repository as part of a snapshot. To do this, a Reference Data map is specified that lists a number of characters that are considered as No Data. Typically, these characters will be non-printing characters, such as ASCII characters 0-32. Whenever a data value consists only of No Data characters, it is normalized to a single value. In the default No Data Handling Reference Data, all No Data values are normalized to NULL values. This allows you to distinguish clearly between data that has some kind of value in it, and data that does not. Alternatively, the data may be snapshot as a direct copy, and the No Data Handling specified on a per process basis as part of the Reader configuration - thereby allowing for a pure analysis of the source data, and also uses of the same data where normalization of the No Data values is preferable.
There are two types of snapshot:
 Server-side
snapshots (that is, snapshots from server-based data stores);
Server-side
snapshots (that is, snapshots from server-based data stores);
 Client-side
snapshots (that is, snapshots from client-based
data stores).
Client-side
snapshots (that is, snapshots from client-based
data stores).
Server-side snapshots are used where the OEDQ host server has access to the data that needs to be copied - for example, it is either on the same machine, or on another machine to which the host has a local network connection.
Server-side snapshots may be reloaded either manually or automatically (for example, as part of a scheduled job) whenever the server has access to the data source. This means that when a process is scheduled for execution, it can automatically rerun the snapshot and pick up any changes in the data if required.
Client-side snapshots are used for sources of data that are accessed via the client rather than the server. For example, the data you wish to work with might be stored on a client machine that does not have a OEDQ host installed (that is, the client accesses an OEDQ host on the network). In this case, the data is copied to the OEDQ host's repository via connectors on the client.
Client-side snapshots may only be reloaded manually, by a user on a connected client machine with access to the data source - that is, by right-clicking on the snapshot, and selecting Run.
It is possible to cancel the running of a snapshot via a right click option. Once canceled, the snapshot icon in the Project Browser tree will be overlaid with the canceled indicator - see example below. If the snapshot is subsequently rerun successfully the canceled indicator will be removed.
Oracle ® Enterprise Data Quality Help version 9.0
Copyright ©
2006,2012, Oracle and/or its affiliates. All rights reserved.