Using Oracle Coherence with Spring Batch for High-Performance Data Processing
By Vijay Nair
How using the Spring Batch framework, in combination with a multithreaded approach to data loading, can improve the manageability and performance Coherence-based applications
Published December 2011
As more and more companies move toward the benefits of in-memory processing for their large data sets, the interest in products that facilitate it is growing rapidly. Oracle Coherence stands tall over many such products in this space due to its simple interface, broad support for popular platforms (e.g. C++, .Net, Hibernate, JPA), and scalability to accommodate terabytes of data with minimal configuration.
Furthermore, as the importance of the data grid cache grows within your environment, it becomes mandatory to ensure that:
- The time needed to load the data into the cache from any source (e.g. flat files/databases) is minimal
- The data loading into the cache is of acceptable quality and reliability
- Proper error handling mechanisms, such as notifications to appropriate departments, are in place
- Reports on cache data loads are available
Ensuring these aspects of the data loading process will guarantee reliability of the data on the data grid cache. Spring Batch, an open-source project out of the SpringSource portfolio, is a Java batch-processing framework that provides an infrastructure for processing large data with the properties described above.
This article demonstrates the loading of a CSV file into the Oracle Coherence cache using Spring Batch. For simplicity purposes, we will re-use the same contacts.csv file (modified to add 99,990 records) included with the example distribution file available with Oracle Coherence 3.7.1.
We will assume here that you have fair-to-medium level understanding of Coherence, Spring Framework, and Spring Batch.
Project Setup
Here we will use Oracle Enterprise Pack for Eclipse (OEPE), which offers a comprehensive set of plugins in case you want to run/debug applications using Oracle Fusion Middleware technologies (Coherence in our example), as our IDE. OEPE also offers comprehensive tooling support for Spring, making it indispensible for developers like me who work with both sets of technologies.
First, we will create a new Spring project in OEPE with the following folder structure and files (download sample here). You also need to add all Spring Framework core jar files (including their dependencies), Spring Batch jar files, and the Oracle Coherence jar file (available under <<COHERENCE_HOME>>/lib). In addition to using the example models provided along with Coherence, we need to compile all the Java files in the examples.zip file provided by Coherence and export them as a jar file – for example, as examples.jar.
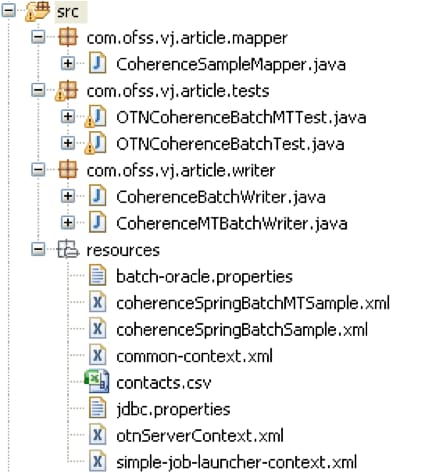
Figure 1 Our new Spring project
The modified contacts.csv file represents the contacts information. Each row from this file will be loaded into the cache as a map with a ContactId object as the key and the Contact object as the value. The Contact object contains:
- String representation of the first name
- String representation of the last name
- Two “Address” objects (Home and Work)
- Map containing two telephone numbers represented by “PhoneNumber” object
The ContactId object contains:
- String representation of the first name
- String representation of the last name
You need to ensure that the combination of the first name and the last name is unique for all the records as it is the key for our map. Some sample data is shown below.
John,Loehe,1968-01-01,675 Beacon St.,,Dthaba,SC,91666,US,Yoyodyne Propulsion Systems,330 Lectroid Rd.,Grover's Mill,NM,41888,US,home,11,74,286,6864191,work,11,45,362,5379579, John,Vadrypkwiy,1978-12-29,62 Beacon St.,,Zxnmgcw,OR,18083,US,Yoyodyne Propulsion Systems,330 Lectroid Rd.,Grover's Mill,DC,81140,US,home,11,82,98,4330491,work,11,56,422,7695959,
Using Spring Batch
Spring Batch is based the concept of an item reader and an item writer. It also offers the facility to create a custom mapper class that will map the data of each line in the file to our model file. To make the example a bit more interesting, we will demonstrate the execution of the loading using a single thread of execution as well as via multiple threads of execution.
First, we define a job named batchCoherence with a step that will use the FlatFileItemReader provided by Spring Batch as the reader, a custom mapper (CoherenceSampleMapper.java), and a custom writer (CoherenceBatchWriter.java).

Figure 2 batchCoherenceJob
The commit interval for the “chunk” is configured as 1,000 – that is, it will invoke the reader 1,000 times and populate a list with the 1,000 items. The writer will be invoked only once during this chunk, thereby offering a highly scalable architecture.
For the reader, we configure:
- The resource which will be loaded, in this case contacts.csv
- DelimitedLineTokenizer with the delimiter as “,”
- FieldSetMapper as our custom mapper (CoherenceSampleMapper.java) to convert each row into our desired model
The mapper implements the FieldSetMapper provided by the Spring Batch framework and is invoked for every row read from the file. The mapper then converts the data available to it into our Contact model returned back to the Spring Batch infrastructure.
The reader is show below:
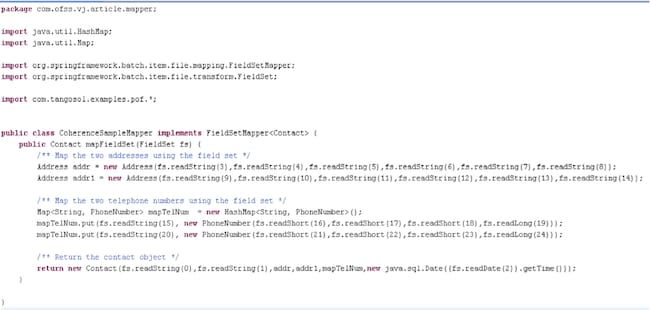
Figure 3 CoherenceSampleMapper.java
The custom writer has the following characteristics:
- We make it implement the ItemWriter interface provided by the Spring Batch framework and implement the write() method. As mentioned before, during each chunk operation, the reader is invoked 1,000 times, and after the mapping to the model, it is available as a list of items to the writer which can choose to perform any kind of operation on it - in our case, writing to a Coherence cache.
- We make it implement the StepExecutionListener interface provided by the Spring Batch framework and implement the beforeStep() and afterStep() methods. As the name suggests, this is a listener class that can trigger methods based on certain events. So in our case, we want to open our CacheFactory before the reading/writing begins in the beforeStep() method and close our CacheFactory gracefully after the push into the cache is complete in the afterStep() method.
- We make it implement the ChunkListener interface provided by the Spring Batch framework and implement the beforeChunk() and afterChunk() methods. This helps in performing certain activities before and after the reading and processing of each “chunk”. In our case we clear the Map “mapBatch” after each cache push.
The writer is shown below:

Figure 4 CoherenceBatchWriter.java
As you can see, Spring Batch provides many useful methods that can help you maintain code with responsibilities mapped out very clearly. In addition, in any of these listener methods, we can implement a useful notification/trigger mechanism in case there are failures either during the loading of the input file or failures during the push of the data into the cache. (This is beyond the scope of this article however.)
Preparing the Multithreaded Example
Next, to prepare for a comparison between single- and multithreaded approaches, we will define a new job named batchCoherenceJobmt with a step that will use the same FlatFileItemReader as the single-threaded example as well as the same custom mapper (CoherenceSampleMapper.java). We will also prepare a new custom multithreaded writer (CoherenceMTBatchWriter.java).

Figure 5 batchCoherenceJobmt
The tasklet this time is assigned for an execution with an async task executor - a Spring-provided task executor implementation - wherein the throttle limit is set as five. (Note that you can assign any kind of task executor implementation of Spring that will help in reuse of thread resources.)
The commit interval for the “chunk” is configured as 1,000 as before - it will invoke the reader a 1,000 times and populate a list with the 1,000 items. The writer will be invoked only once during this chunk.
The reader and the mapper are configured as in the single-threaded example:
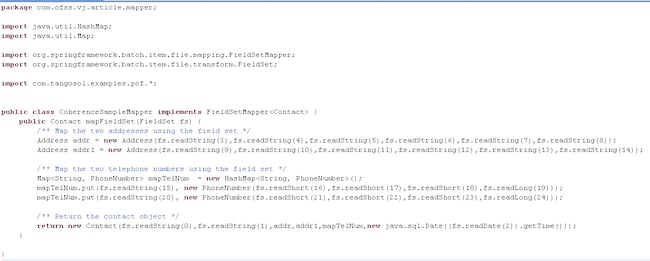
Figure 6 CoherenceSampleMapper.java (multithread version)
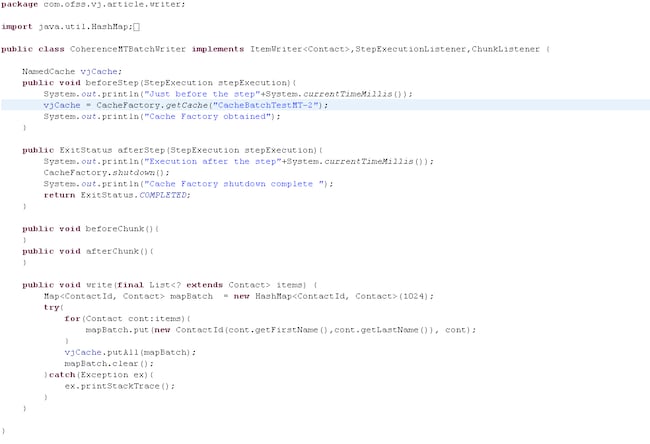
Figure 7 CoherenceBatchWriter.java (multithread version)
Here, we created a new Map<ContactId,Contact> and cleared it within the write method itself to make it thread-safe from a multithreaded execution perspective.
Now, let’s proceed to the testing phase and compare the single-threaded and multithreaded approaches to data loading. All tests were conducted on a laptop having an Intel Core Duo CPU @2.4 Ghz with 2GB of RAM.
Execution: Single Threaded
Since we use the Oracle Database repository as our batch repository to store information about the execution of each job, the same is mandatory for the Spring Batch metadata tables present in a database (see static.springsource.org/spring-batch/reference/html/metaDataSchema.html). For this example, you can configure the jdbc.properties under the resources folder to point to your test database. (You would need to add the ojdbc.jar [or appropriate] to your classpath before executing.)
First, we start a normal coherence server using cache-server.cmd located under <<COHERENCE_HOME>>/bin.
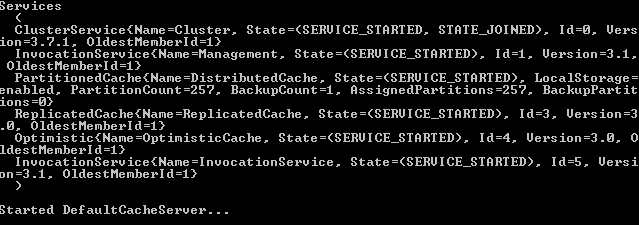
Figure 8Starting the server
We also start another coherence node using coherence.cmd located under <<COHERENCE_HOME>>/bin and enter:
Map <?>: cache CacheBatchTestNonMT
(our named cache for the single-threaded scenario)
This brings up the prompt for our named cache. A quick test using the size command indicates that this named cache is empty:
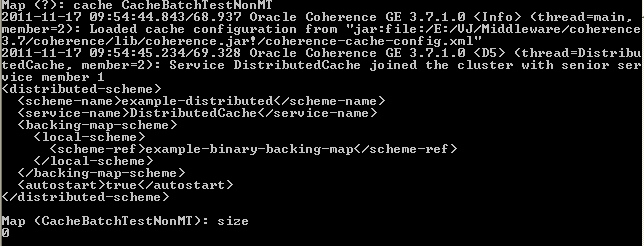
Figure 9Running the size test
Navigating back to Eclipse, we open a simple test case written using Spring’s JUnit support (OTNCoherenceBatchTest.java), which loads all the files required for our Spring application context.
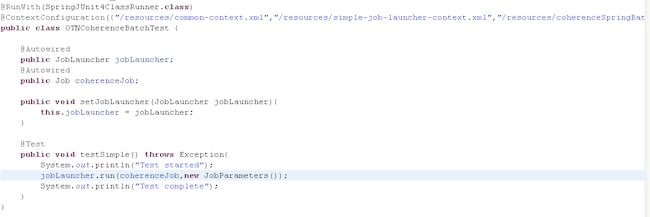
Figure 10OTNCoherenceBatchTest.java
Right-click on the class and select Run as JUnit test. In the Eclipse console, you can clearly see that it joins an existing cluster and a cache connection factory is obtained.
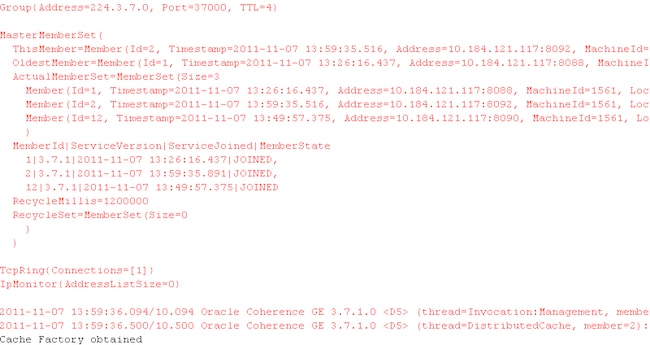
Figure 11Results of the JUnit test
In the main server (started using cache-server.cmd), you can see the data being transferred.

Figure 12Data transfer in progress
The Coherence node started using coherence.cmd, and the result after typing out size indicates our cache contains the data loaded from the file:
Map <CacheBatchTestNonMT): size
99990
Querying the batch step execution table, we get an execution time of 53.297 seconds.
Now, let’s compare this result with that of the multihreaded approach.
Execution: Multithreaded
We follow the same steps as before, except this time we use a new named cache called CacheBatchTestMT-2.
Run another JUnit test case created to test this (OTNCoherenceBatchMTTest.java) and check for size:
Map <CacheBatchTestMT-2>: size
99990
Querying the batch step execution table, we get an execution time of 28.218 seconds - an improvement of around 45% over the sequential methodology of execution.
Conclusion
Oracle Coherence is helping financial institutions around the world improve performance on their batch workloads by offering fast access to in-memory data grids, an essential aspect of batch processing. But as Coherence data grids grow in size, minimizing the time needed for loading the data as well as accessing it becomes extremely important for performance. As you've seen from the results above, a multithreaded approach to both these operations far outweighs the benefits of using a sequential approach. Using the Spring Batch infrastructure helps us to configure this approach declaratively pretty easily (e.g. using Spring task executors).
Vijay Nair works as a technical architect for Oracle FLEXCUBE Private Banking, part of the Financial Services Global Business Unit of Oracle. His interests lay primarily around scalable computing and applying these principles to real life scenarios within the private banking domain.