Oracle Exadata Commands Reference Part 4: Metrics and Reporting
by Arup Nanda
Learn how to use various metrics and reports available to measure the efficiency and effectiveness of your Exadata Database Machine environment.
(The purpose of this guide is educational; it is not intended to replace official Oracle-provided manuals or other documentation. The information in this guide is not validated by Oracle, is not supported by Oracle, and should only be used at your own risk.)
To keep a handle on the Oracle Exadata Database Machine’s reliability and efficiency you will need to measure several health metrics. Monitoring these metrics is likely to be your most common activity, but even so you would probably want a heads-up when something is amiss. In this final installment, you will learn how to check these metrics, either via the CellCLI interface or Oracle Enterprise Manager, and receive alerts based on certain conditions.
Metrics Using CellCLI
First, let’s see how to get the metrics through CellCLI. To check the current metrics, simply use the following command:
CellCLI> list metriccurrent
It will show all the metrics, which quickly becomes impossible to read. Instead you may want to focus on specific ones. For example, to display a specific metric called GD_IO_RQ_W_SM, use it as a modifier. (If you are wondering what this metric is about, you will learn that shortly.)
CellCLI> list metriccurrent gd_io_rq_w_sm
GD_IO_RQ_W_SM PRODATA_CD_00_cell01 2,665 IO requests
GD_IO_RQ_W_SM PRODATA_CD_01_cell01 5,710 IO requests
GD_IO_RQ_W_SM PRODATA_CD_02_cell01 2,454 IO requests
… output truncated …
The metric shows you the I/O requests to the different cell disks. While this may be good for a quick glance at some single parameter, it’s not super-useful for checking up on all the other metrics. To get a longer list of metrics, use the detail option.
CellCLI> list metriccurrent gd_io_rq_w_sm detail
name: GD_IO_RQ_W_SM
alertState: normal
collectionTime: 2011-05-26T11:25:33-04:00
metricObjectName: PRODATA_CD_02_cell01
metricType: Cumulative
metricValue: 2,456 IO requests
objectType: GRIDDISK
name: GD_IO_RQ_W_SM
alertState: normal
collectionTime: 2011-05-26T11:25:33-04:00
metricObjectName: PRODATA_CD_03_cell01
metricType: Cumulative
metricValue: 2,982 IO requests
objectType: GRIDDISK
name: GD_IO_RQ_W_SM
alertState: normal
collectionTime: 2011-05-26T11:25:33-04:00
metricObjectName: PRODATA_CD_04_cell01
metricType: Cumulative
metricValue: 1,631 IO requests
objectType: GRIDDISK
… output truncated …
The output shows the name metric, the object on which this metric is defined (e.g. PRODATA_CD_02_cell01), the type of that object (e.g. grid disk), when the metric was collected, and the current value, among others.
The objects on which the metrics have been defined are wide ranging in types. For instance, here is the metric for rate of reception for I/O packets, which is defined on the object type Cell.
CellCLI> list metriccurrent n_nic_rcv_sec detail
name: N_NIC_RCV_SEC
alertState: normal
collectionTime: 2011-05-26T11:23:28-04:00
metricObjectName: cell01
metricType: Rate
metricValue: 3.7 packets/sec
objectType: CELL
Attributes
What other information does current metric show? To know that answer, use the following command.
CellCLI> describe metriccurrent
name
alertState
collectionTime
metricObjectName
metricType
metricValue
objectType
Note the attribute called alertState, which is probably the most important for you. If the metric is within the limit defined as safe, the alertState will be set to normal. You can use this command to display the interesting attributes where the alert has been triggered, i.e. alertState is non-zero:
CellCLI> list metriccurrent attributes name,metricObjectName,metricType,metricValue,objectType -
> where alertState != 'normal'
Alternatively you can select the current metrics on other types of objects as well. For instance, here is an example of checking the metrics on the interconnect.
CellCLI> list metriccurrent attributes name,metricObjectName,
metricType,metricValue,alertState -
> where objectType = 'HOST_INTERCONNECT'
N_MB_DROP proddb01.xxxx.xxxx Cumulative 0.0 MB normal
N_MB_DROP proddb02.xxxx.xxxx Cumulative 0.0 MB normal
N_MB_DROP proddb03.xxxx.xxxx Cumulative 0.0 MB normal
N_MB_DROP proddb04.xxxx.xxxx Cumulative 0.0 MB normal
… outout truncated …
As always, refer to the describe command to learn about the order of the attributes, since the output does not have a heading. You can also skip naming the attribute and just use ALL, which will show all the attributes. Let’s see the metrics for a cell. Since we are running it on cell01, the metrics of only that cell is shown:
CellCLI> list metriccurrent attributes all where objectType = 'CELL'
CL_BBU_CHARGE normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 93.0 % CELL
CL_BBU_TEMP normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 41.0 C CELL
CL_CPUT normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 2.4 % CELL
CL_FANS normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 12 CELL
CL_MEMUT normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 41 % CELL
CL_RUNQ normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 0.7 CELL
CL_TEMP normal 2011-05-26T11:37:10-04:00 cell01 Instantaneous 25.0 C CELL
IORM_MODE normal 2011-05-26T11:36:34-04:00 cell01 Instantaneous 0 CELL
N_NIC_NW normal 2011-05-26T11:37:28-04:00 cell01 Instantaneous 3 CELL
N_NIC_RCV_SEC normal 2011-05-26T11:37:28-04:00 cell01 Rate 3.2 packets/sec CELL
N_NIC_TRANS_SEC normal 2011-05-26T11:37:28-04:00 cell01 Rate 3.6 packets/sec CELL
Let’s examine the meaning of these metrics in some detail:
CL_BBU_CHARGE |
Battery charge on the disk controller |
CL_BBU_TEMP |
Temperature of the disk controller battery |
CL_CPUT |
CPU utilization |
CL_FANS |
Number of working fans |
CL_FSUT |
%age utilization of file systems |
CL-MEMUT |
%age of memory use |
CL_RUNQ |
The run queue |
CL_TEMP |
Temperature of the cell |
IORM_MODE |
I/O Resource Management mode in effect |
N_NIC_NW |
Number of interconnects *not* working |
N_NIC_RCV_SEC |
Rate of reception of I/O packet |
N_NIC_TRANS_SEC |
Rate of transmission of I/O packet |
Speaking of current metrics, what are the names? You saw a few of them previously: N_MB_DROP, etc. To get a complete list, use the following command:
CellCLI> list metricdefinition
CD_IO_BY_R_LG
CD_IO_BY_R_LG_SEC
CD_IO_BY_R_SM
CD_IO_BY_R_SM_SEC
CD_IO_BY_W_LG
CD_IO_BY_W_LG_SEC
CD_IO_BY_W_SM
CD_IO_BY_W_SM_SEC
CD_IO_ERRS
CD_IO_ERRS_MIN
CD_IO_LOAD
CD_IO_RQ_R_LG
CD_IO_RQ_R_LG_SEC
CD_IO_RQ_R_SM
CD_IO_RQ_R_SM_SEC
CD_IO_RQ_W_LG
CD_IO_RQ_W_LG_SEC
CD_IO_RQ_W_SM
CD_IO_RQ_W_SM_SEC
CD_IO_ST_RQ
CD_IO_TM_R_LG
CD_IO_TM_R_LG_RQ
CD_IO_TM_R_SM
CD_IO_TM_R_SM_RQ
CD_IO_TM_W_LG
CD_IO_TM_W_LG_RQ
CD_IO_TM_W_SM
CD_IO_TM_W_SM_RQ
CG_FC_IO_BY_SEC
CG_FC_IO_RQ
CG_FC_IO_RQ_SEC
CG_FD_IO_BY_SEC
CG_FD_IO_LOAD
CG_FD_IO_RQ_LG
CG_FD_IO_RQ_LG_SEC
CG_FD_IO_RQ_SM
CG_FD_IO_RQ_SM_SEC
CG_IO_BY_SEC
CG_IO_LOAD
CG_IO_RQ_LG
CG_IO_RQ_LG_SEC
CG_IO_RQ_SM
CG_IO_RQ_SM_SEC
CG_IO_UTIL_LG
CG_IO_UTIL_SM
CG_IO_WT_LG
CG_IO_WT_LG_RQ
CG_IO_WT_SM
CG_IO_WT_SM_RQ
CL_BBU_CHARGE
CL_BBU_TEMP
CL_CPUT
CL_FANS
CL_FSUT
CL_MEMUT
CL_RUNQ
CL_TEMP
CT_FC_IO_BY_SEC
CT_FC_IO_RQ
CT_FC_IO_RQ_SEC
CT_FD_IO_BY_SEC
CT_FD_IO_LOAD
CT_FD_IO_RQ_LG
CT_FD_IO_RQ_LG_SEC
CT_FD_IO_RQ_SM
CT_FD_IO_RQ_SM_SEC
CT_IO_BY_SEC
CT_IO_LOAD
CT_IO_RQ_LG
CT_IO_RQ_LG_SEC
CT_IO_RQ_SM
CT_IO_RQ_SM_SEC
CT_IO_UTIL_LG
CT_IO_UTIL_SM
CT_IO_WT_LG
CT_IO_WT_LG_RQ
CT_IO_WT_SM
CT_IO_WT_SM_RQ
DB_FC_IO_BY_SEC
DB_FC_IO_RQ
DB_FC_IO_RQ_SEC
DB_FD_IO_BY_SEC
DB_FD_IO_LOAD
DB_FD_IO_RQ_LG
DB_FD_IO_RQ_LG_SEC
DB_FD_IO_RQ_SM
DB_FD_IO_RQ_SM_SEC
DB_IO_BY_SEC
DB_IO_LOAD
DB_IO_RQ_LG
DB_IO_RQ_LG_SEC
DB_IO_RQ_SM
DB_IO_RQ_SM_SEC
DB_IO_UTIL_LG
DB_IO_UTIL_SM
DB_IO_WT_LG
DB_IO_WT_LG_RQ
DB_IO_WT_SM
DB_IO_WT_SM_RQ
FC_BYKEEP_OVERWR
FC_BYKEEP_OVERWR_SEC
FC_BYKEEP_USED
FC_BY_USED
FC_IO_BYKEEP_R
FC_IO_BYKEEP_R_SEC
FC_IO_BYKEEP_W
FC_IO_BYKEEP_W_SEC
FC_IO_BY_R
FC_IO_BY_R_MISS
FC_IO_BY_R_MISS_SEC
FC_IO_BY_R_SEC
FC_IO_BY_R_SKIP
FC_IO_BY_R_SKIP_SEC
FC_IO_BY_W
FC_IO_BY_W_SEC
FC_IO_ERRS
FC_IO_RQKEEP_R
FC_IO_RQKEEP_R_MISS
FC_IO_RQKEEP_R_MISS_SEC
FC_IO_RQKEEP_R_SEC
FC_IO_RQKEEP_R_SKIP
FC_IO_RQKEEP_R_SKIP_SEC
FC_IO_RQKEEP_W
FC_IO_RQKEEP_W_SEC
FC_IO_RQ_R
FC_IO_RQ_R_MISS
FC_IO_RQ_R_MISS_SEC
FC_IO_RQ_R_SEC
FC_IO_RQ_R_SKIP
FC_IO_RQ_R_SKIP_SEC
FC_IO_RQ_W
FC_IO_RQ_W_SEC
GD_IO_BY_R_LG
GD_IO_BY_R_LG_SEC
GD_IO_BY_R_SM
GD_IO_BY_R_SM_SEC
GD_IO_BY_W_LG
GD_IO_BY_W_LG_SEC
GD_IO_BY_W_SM
GD_IO_BY_W_SM_SEC
GD_IO_ERRS
GD_IO_ERRS_MIN
GD_IO_RQ_R_LG
GD_IO_RQ_R_LG_SEC
GD_IO_RQ_R_SM
GD_IO_RQ_R_SM_SEC
GD_IO_RQ_W_LG
GD_IO_RQ_W_LG_SEC
GD_IO_RQ_W_SM
GD_IO_RQ_W_SM_SEC
IORM_MODE
N_MB_DROP
N_MB_DROP_SEC
N_MB_RDMA_DROP
N_MB_RDMA_DROP_SEC
N_MB_RECEIVED
N_MB_RECEIVED_SEC
N_MB_RESENT
N_MB_RESENT_SEC
N_MB_SENT
N_MB_SENT_SEC
N_NIC_NW
N_NIC_RCV_SEC
N_NIC_TRANS_SEC
N_RDMA_RETRY_TM
You can use any of these metrics in the metricType.
I am sure your next question is on the description of these metrics. To know more about each metric, issue the command with the name and the detail modifiers:
CellCLI> list metricdefinition cl_cput detail
name: CL_CPUT
description: "Cell CPU Utilization is the percentage of time over the
previous minute that the system CPUs were not idle (from /proc/stat)."
metricType: Instantaneous
objectType: CELL
unit:
Object Type
Not all metrics are available on all objects. For instance the temperature is a metric for cells but not the disks. Note the objectType attribute in the output above; it shows the type of the object. You can learn about metrics on a specific type of object.
First, see all the attributes you can choose:
CellCLI> describe metricdefinition
name
description
metricType
objectType
persistencePolicy
unit
This will allow you to use attributes all keywords and let you understand the heading of the output.
CellCLI> list metricdefinition attributes all where objecttype='CELL'
CL_BBU_CHARGE "Disk Controller Battery Charge" Instantaneous CELL %
CL_BBU_TEMP "Disk Controller Battery Temperature" Instantaneous CELL
CL_CPUT "Cell CPU Utilization is the percentage of time over the previous minute
that the system CPUs were not idle (from /proc/stat)." Instantaneous CELL %
CL_FANS "Number of working fans on the cell" Instantaneous CELL Number
CL_MEMUT "Percentage of total physical memory on the cell that is currently used" Instantaneous CELL %
CL_RUNQ "Average number (over the preceding minute) of processes in the Linux
run queue marked running or uninterruptible (from /proc/loadavg)." Instantaneous CELL Number
CL_TEMP "Temperature (Celsius) of the server, provided by the BMC" Instantaneous CELL C
IORM_MODE "I/O Resource Manager objective for the cell" Instantaneous CELL Number
N_NIC_NW "Number of non-working interconnects" Instantaneous CELL Number
N_NIC_RCV_SEC "Total number of IO packets received by interconnects per second" Rate CELL packets/sec
N_NIC_TRANS_SEC "Total number of IO packets transmitted by interconnects per second" Rate CELL packets/sec
Using this command you can get the description on any metric. Some of the metric values are 0. Let’s see all metrics of Grid Disks which are bigger than 0:
CellCLI> list metriccurrent attributes all where objectType = 'GRIDDISK' -
> and metricObjectName = 'PRODATA_CD_09_cell01' -
> and metricValue > 0
GD_IO_BY_R_LG normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 3.9MB GRIDDISK
GD_IO_BY_R_SM normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 29.3MB GRIDDISK
GD_IO_BY_W_LG normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 797MB GRIDDISK
GD_IO_BY_W_SM normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 73.3MB GRIDDISK
GD_IO_RQ_R_LG normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 4 IO requests GRIDDISK
GD_IO_RQ_R_SM normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 1,504 IO requests GRIDDISK
GD_IO_RQ_W_LG normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 3,230 IO requests GRIDDISK
GD_IO_RQ_W_SM normal 2011-05-26T11:38:34-04:00 PRODATA_CD_09_cell01 Cumulative 3,209 IO requests GRIDDISK
Current metrics are like the pulse of the cell – they give you the health and effectiveness of the cell at that time.
Metrics History
Sometimes you may be interested in the history of the metrics. For instance you may want to get an idea about the trending of the values. Use the following command:
CellCLI> list metrichistory
It will get you everything and in fact the output may not be practical. Instead, you may want to examine metrics of a specific object only, since the metrics could be highly context relative. Here is an example where you can see the history of all the metric values for the cells.
CellCLI> list metrichistory where objectType = 'CELL'
IORM_MODE cell01 0 2011-05-26T12:59:39-04:00
CL_BBU_TEMP cell01 41.0 C 2011-05-26T13:00:10-04:00
CL_CPUT cell01 0.6 % 2011-05-26T13:00:10-04:00
CL_FANS cell01 12 2011-05-26T13:00:10-04:00
CL_MEMUT cell01 41 % 2011-05-26T13:00:10-04:00
Don’t know what the columns are for? Just give the command describe metrichistory to see the attributes.
While the output shows the history of metrics, it’s a little difficult to parse. You may want to examine a single statistic, not a bunch of them. The following example shows the history of the temperature of the cell.
CellCLI> list metrichistory where objectType = 'CELL' -
> and name = 'CL_TEMP'
CL_TEMP cell01 25.0 C 2011-05-26T13:00:10-04:00
CL_TEMP cell01 25.0 C 2011-05-26T13:01:10-04:00
CL_TEMP cell01 25.0 C 2011-05-26T13:02:10-04:00
CL_TEMP cell01 25.0 C 2011-05-26T13:03:10-04:00
CL_TEMP cell01 25.0 C 2011-05-26T13:04:10-04:00
CL_TEMP cell01 25.0 C 2011-05-26T13:05:10-04:00
… output truncated …
Two of the often forgotten features of CellCLI is that you can invoke it with the –x option, which suppresses the banner, and the –n option, which suppresses the command line.
# cellcli -x -n -e "list metrichistory where objectType = 'CELL' and name = 'CL_TEMP'"
CL_TEMP prodcel01 24.0 C 2011-05-27T02:00:47-04:00
CL_TEMP prodcel01 24.0 C 2011-05-27T02:01:47-04:00
CL_TEMP prodcel01 24.0 C 2011-05-27T02:02:47-04:00
… output truncated …
This output can be taken straight to a spreadsheet program for charting or other types of analysis.
Alerts
Now that you learned about metrics, let’s see how you can use them to alert you when something happens. The Exadata Database Machine comes with a lot of predefined alerts out of the box. To see them use the following command. To get more information on them, use the detail modifier.
CellCLI> list alertdefinition detail
name: ADRAlert
alertShortName: ADR
alertSource: "Automatic Diagnostic Repository"
alertType: Stateless
description: "Incident Alert"
metricName:
name: HardwareAlert
alertShortName: Hardware
alertSource: Hardware
alertType: Stateless
description: "Hardware Alert"
metricName:
name: StatefulAlert_CD_IO_ERRS_MIN
alertShortName: CD_IO_ERRS_MIN
alertSource: Metric
alertType: Stateful
description: "Threshold Alert"
metricName: CD_IO_ERRS_MIN
name: StatefulAlert_CG_FC_IO_BY_SEC
alertShortName: CG_FC_IO_BY_SEC
alertSource: Metric
alertType: Stateful
description: "Threshold Alert"
metricName: CG_FC_IO_BY_SEC
… output truncated …
The alerts are based on metrics explained earlier. For instance, the alert StatefulAlert_CG_FC_IO_BY_SEC is based on the metric CG_FC_IO_BY_SEC. There are a few alerts which are not based on metrics. Here is how you can find them:
CellCLI> list alertdefinition attributes all where alertSource!='Metric'
ADRAlert ADR "Automatic Diagnostic Repository" Stateless "Incident Alert"
HardwareAlert Hardware Hardware Stateless "Hardware Alert"
Stateful_HardwareAlert Hardware Hardware Stateful "Hardware Stateful Alert"
Stateful_SoftwareAlert Software Software Stateful "Software Stateful Alert"
The next step is to define an alert based on a threshold. Here is how you can define a threshold on the metric CD_IO_ERRS_MIN on database called PRODB. You want the alert to be fired when the value is more than 10.
CellCLI> create threshold cd_io_errs_min.prodb comparison=">", critical=10
Threshold DB_IO_RQ_SM_SEC.PRODB successfully created
When an alert triggers, the cell takes the action on the notification schedule – it either sends an email or an SNMP trap, or both. Here is an example of an alert received via email. It shows that the cell failed to reach either the NTP or DNS server.

You can modify the threshold:
CellCLI> alter threshold DB_IO_RQ_SM_SEC.PRODB comparison=">", critical=100
Threshold DB_IO_RQ_SM_SEC.PRODB successfully altered
And, when not needed, you can drop the threshold.
CellCLI> drop threshold DB_IO_RQ_SM_SEC.PRODB
Threshold DB_IO_RQ_SM_SEC.PRODDB successfully dropped
When you drop the threshold, the alert (if generated earlier) will be cleared and new alert is generated informing that the threshold was cleared. Here is an example email with that information.

Using Grid Control
As you learned previously, you can administer the Exadata Database Machine in several ways: using the command-line tool CellCLI (or a number of cells at the same time by DCLI), using SRVCTL and CRSCTL, and via plain-old SQL commands. But the easiest approach, hands down, is to use Oracle Enterprise Manager Grid Control. The graphical interface simply makes the command interface intuitive and easy to read. If you already have a Grid Control infrastructure, it makes the decision very easy – you just add the Database Machine to it. If you don’t have Grid Control, perhaps you should seriously think about it now.
Setup
To manage the Database Machine via Grid Control, you need:
An agent installed in each of the compute nodes of DBM. No agent need be installed on the storage cells.
To configure access to the cells from the Oracle Management Server console machine
Let’s examine each approach in detail. The plugin is a jarfile you download and keep on the OMS server. The grid control agents are installed on the database compute nodes the same way you would have done for a normal database server. You can either push the agents from the Grid Control console, or download the agent software on the database compute nodes and install there. During the installation you will be asked the address and port number of the OMS server, which will complete the installation.
The storage plug-in is different. This is not an agent on the storage cells; rather it’s installed as a part of the OMS server. So you need to download the plugin (which is a file with .jar extension) to the machine on which you launched the browser (typically your desktop), not the storage cells. After that, fire up the Grid Control browser and follow the steps shown below.
1. Go to the Setup screen, shown below:
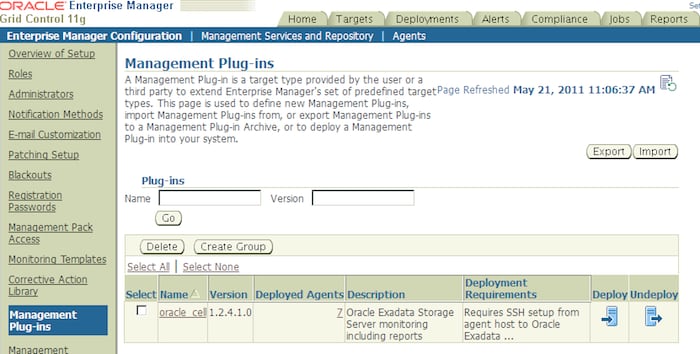
2. From the menu on the left, choose Management Plug-Ins.
3. You need to import the plug-in to OMS. Click on the Import button.
4. It will ask for a file name. Click on the button Browse, which will open the file explorer.
5. Select the jarfile you just downloaded and click OK.
6. The jarfile is actually an archive of different plug-ins inside. Choose the Exadata Storage Server Plugin.
7. Press the OK button.
8. You will be asked to enter preferred credentials. Make sure the userids and passwords are correct.
9. Click on the icon marked Deploy.
10. Click on the button Add Agents.
11. Click on Next and then Finish.
12. From the top bar menu (shown below) click on the hyperlink Agents.
13. Select the agent where you deployed the system management plug-in.
14. Go to the Management Agents page.
15. Select Oracle Exadata Storage Server target type from the drop down list.
16. Click on Add.
17. The screen will ask for the management IP of the storage server. Enter the IPs.
18. Click on the Test Connection button to ensure everything is working.
19. Click on the OK button.

That’s it; the storage servers are now ready to be monitored via Grid Control.
Basic Information
Once configured, your Exadata Database Machine shows up in Grid Control. The database compute nodes show up as normal database servers and the cluster shows up as a normal cluster database; there is nothing Exadata-specific in nature on those screens.
You may already be familiar with the normal Oracle RAC database management features on Grid Control, which applies to Exadata compute nodes as well. In this article we will assume you are familiar with the database management via Grid Control.
The real benefit comes in looking at the storage cells as an alternative to CellCLI. To check storage cells, go to Homepage > Targets > All Targets. In the Search dropdown box choose Oracle Exadata Storage Server and press Go. The resulting screen that comes up is similar to the picture shown below. Note the names have been erased.

This is a full rack Exadata so there are 14 cells, or storage servers named with a prefix _Cell01 through _Cell14. Clicking on each of the hyperlinked cell names takes you to the information screen of the respective cell (also known as Storage Server). Let’s click on cell#2. It brings up the cell details similar to a screen shown below:

This screen shows you three basic but very important metrics:
CPU Utilization %-age
Memory Utilization %-age
Temperature of the server
The screen gives only a glimpse of these three metrics for the last 24 hours or so. Note that memory utilization has been constant, which is pretty typical. Since this is a storage cell, the only software that runs here is Exadata Storage Server, not the database sessions which tend to fluctuate in memory usage. The temperature has been pretty steady but spiked a little at around 6AM. The CPU however may show a wide fluctuation because of the demand on the ES software as a result of cell offloading (described in detail in Part 1). If you click on CPU Utilization, you will see a dedicated screen for CPU utilization as shown below.

It shows a more detailed graph on the CPU busy-ness across a more granular scale. You can choose to get the refresh frequency of the metric by choosing from the drop-down menu View Data near the top right corner. Here I have chosen "Real Time: 5 Minute Refresh." It will get the data in the real time but refresh only every 5 minutes. That is why you will notice the graph is non-smooth. You can also choose a longer period such as “last 7 days” or even “last 31 days” but that information is no longer real time.
You can also choose the same information from Reports (described later in this installment). Clicking on Temperature and Memory graphs will provide similar data.
Cell Information
Since the cell contains hard drives, which are mechanical devices and generate a lot of heat, it will fail if the temperature is too high. The cells contain fans to force the hot air out and to reduce the temperature. There are 12 fans in each cell. Are they working? There are two power supplies in the cell for redundancy. Are both working? To know the answer to these questions and get other information on the cell, click on the hyperlink View Configuration to bring up a screen like the following.

The information shown here is pretty similar to what you would have seen in the list cell command in CellCLI. Let’s examine some of the interesting information on this screen and why you would like to know about them:
Status – of course you want to know if this cell is even online and servicing traffic.
Fan Count – number of working fans
Power Count – the number of working power supplies (there should be two)
SMTP Server – the email server that is used to send emails. Very important for alerts.
IP Address – IP of the cell
Interconnect Count – the number of cell interconnects. Default is three.
CPU Count – the number of CPU cores.
This is just a summary of the cell. The objective of the cell is to provide a storage platform for the Exadata Database Machine. So far, we have not seen anything about the actual storage in the cell. To know about the storage in the cells, look further down the page. There are five sections:
Grid disks
Cell disks
LUNs
Physical disks
I/O Resource Manager
Note the set of 5 hyperlinks toward the top of the screen that will direct you to the appropriate section:

Instead of looking at the sections in the way they have been laid out, I suggest you look in the order they are created. For instance a cell contains physical disks, from which LUNs are created, from which cell disks are created, from which grid disks are created. Finally, IORM (I/O Resource Manager) is used on the disks. Let’s look at them in the same logical order.
Physical Disks
To know about the physical disks available in the cell, this is the section to look at. Here is a partial screenshot.

If this looks familiar, it’s because this is formatted output from the CellCLI command LIST PHYSICALDISK DETAIL or LIST PHYSICALDISK ATTRIBUTES. The important columns here to note are:
LUN/s – the LUN which is created on this physical disk
Error Count – if there are any errors on these physical disks
Physical Interface – SAS for hard disks, ATA for flash disks. Some older Exadata Database Machines may have SATA hard disks and this column will show “sas”.
Size – The size in GB of the physical disks
Insert Time – the date and timestamp when these records were recorded in the repository.
LUNs
Next, let’s look at the LUNs in the cell by clicking on the Cell LUN Configuration hyperlink.

Again, this is the graphical representation of the LIST LUN ATTRIBUTES command. Note that the flash drives are also listed here, toward the bottom of the output. They are named with a prefix FD in the Cell Disk, unlike “CD” in case of regular SAS hard disks. LUNs are created from hard disk partitions, which are presented to the host (the storage cell) as a device. The device ID shows up here, along with the cell disks created on the LUN. The two columns that you should pay attention to are “Status” and “Error Count”.
If you see just 10 LUNs, click on the dropdown box and select all 28.
Cell Disks
Cell disks are created from the physical disks. In CellCLI, you got the list by using the LIST CELLDISK command. In Grid Control, clicking on the hyperlink Celldisk Configuration will give show the list of cell disks in a graphical manner, similar to one shown below. Like the previous section, click on the drop-down list to choose “All 28” to show all 28 cell disks on the same page. Again, you should pay attention to “Error Count” and “Status” columns.

Grid Disks
Grid Disks are created from the cell disks, and are used to build the ASM diskgroups. Obviously, these are the actual building blocks of the storage the ASM instance is aware of. Typically there is a one-to-one relationship between cell disk and grid disk, but if there is not one in your case, you may see less available space in your ASM diskgroup. Clicking on the Griddisk Configuration hyperlink brings up the screen similar to the following:

The key columns in this screen to look at are:
Status – if the grid disk is active. If inactive, it’s offline and ASM can’t use it.
Size – does the size sound right? Or was it created with less size from the cell disk? In that case the ASM instance will see that reduced size as well.
Error Count – have there been errors on this grid disk.
This brings us to the end of the basic building blocks of the storage cells, or storage servers. Using these graphical screens or the CellCLI commands you can get most of the information on these building blocks.
Now let’s get on to some of the more complex data needs: to gather the performance and management metrics on these components. For example, is the cell disk performing optimally, or are there any issues with the grid disk that may result in data loss?
Metrics
The best way to examine the metrics for these components is to explore them in the dedicated Metrics page in Grid Control. Note the set of hyperlinks toward the bottom of the page and click on All Metrics. It will bring up a screen as shown below.
Remember, metrics are gathered and stored in the OMS server and then presented as needed. Since they are stored in the OMS server, they affect the performance of the Exadata Database Machine little or none at all. The screen above shows the frequency these metrics are collected (15 minutes, 1 minute, etc.). Some of the metrics are real time (flash cache statistics for example); others do not have any schedule (such as error messages and alerts). The collection frequency is displayed under the column “Collection Schedule”.
When the metrics are collected, they are uploaded to the OMS server’s database. The screen above also shows how soon the metrics are uploaded after collection (the column “Upload Interval”), along with the date and time the last upload occurred (“Last Upload”).
Metrics can also be used to trigger alerts. For instance, if the cell offload efficiency falls below a certain threshold, you can trigger an alert. We will see how these alerts are set up later but the alerting threshold is shown in this screen as well, under the column “Threshold”.

The screen shows the metrics collected by Grid Control and the frequency of the collection. If you want, you can see all the sub categories and specific metric names by clicking on Expand All.
Let’s focus on only one category – Category Statistics. Click on the “+” before the category to show the various metrics; you will see a screen similar to the following:

Click on Category Small IO Requests/Sec.

Click on the eyeglass icon under the column “Details”.

Like all the other screens you saw earlier, you can choose a different refresh frequency by choosing the appropriate value from the drop-down menu “View Data”. Alternatively, you can choose historical records by selecting Last 24 hours, or Last 7 days, etc.
Reports
Reports are similar to screens reporting metrics but with some important differences. Some reports could be better for viewing certain metrics but the most valuable use of reports is to compare metrics across several components at a glance.
From the main Enterprise Manager page, choose the Reports tab from the ribbon of tabs at the top. Click on the Report tab and scroll down several pages to a collection of reports named “Storage”, as shown below:

This section shows all the metrics you might have seen earlier, but with a major difference: The reports are organized as independent entities, which can report the data on any component -- not driven from the details screen of the component itself. For instance, click on the hyperlink Celldisk Performance. It brings up a screen asking you to choose the cell disk you are interested in rather than choosing the cell disk screen first and then going to the performance metrics of that cell disk. You can choose a cell disk from the list by clicking on the flashlight icon (the list of values) and it brings up a screen as shown below.

If you click on one of the hyperlinked cell disks Cell Disk, you will see the data for that cell disk.

Grid Disk Performance
As you learned in Part 2 of this series, the grid disks are built from the cell disks and then used for ASM diskgroups. Thus the performance of the grid disks will directly affect the performance of the ASM diskgroups, which in turn will affect database performance. So it’s important to keep a tab on the grid disk performance and examine it if you see any issues in the database. From the report menu shown earlier, go to Storage > CELL > Grid Disk Performance. It will ask you to pick a cell from the list. Choosing Cell 02 will bring up a screen similar to this.

The other important metric to examine is host interconnect performance:

Doing Comparisons
Sometimes you wonder how one component such as a cell disk is doing compared to other cell disks. The comparison is a very neat feature in the Grid Control. First get to the page of the metric you are interested in:

Click on the hyperlink just below Related Links shown as Compare Objects Celldisk Name/Cell Name/Realm Name.

Then click on the OK button. The comparison will appear in the screen similar to the one shown below:

The comparison shows that cell disk CD_00_cell01 has a higher write throughput compared to the other two.
Metrics on Realms
A realm is a set of components enclosed within a logical boundary. Realms are used to separate systems for different usage – for instance you may create a realm each for database A, database B, etc. By default there is a single realm. Since all the cells belong to the realm, metrics for a realm go across the cells and are not limited to the current cell alone.
Let’s see an example. If you pull up the LUN Configuration report, you will see the following:

It shows 28 records since there are 28 LUNs in this cell. The scope of this report is the current cell, not the others. When you pull up the Realm LUN Configuration, it will show the LUNs of all the cells, as shown below.
Note the difference: 392 rows instead of 28. All the LUNs from all the cells have been shown here.

Choosing realms for reports can allow you to get the picture for a specific realm immediately. If there is only one realm, then all the cells are pulled together in the report. Consider a very important report – Realm Performance, shown below.

It shows you the metrics across all the cells in that realm. This is an excellent way to quickly compare various cells to see if they are uniformly loaded.
On the same line of thought, you may want to compare performance of the components of the cells, not just the cells. Choosing Realm Celldisk Performance from the View Report dropdown menu shows the performance of the cell disks across all the cells, not just that cell.

However, with the sheer amount of data in the report (392 rows), it may not be as useful. A better option may be is to compare the Cell Disk #1 of all the cells. You can do that by using a filter in the Celldisk field.

This shows the performance of the first cell disks of all the cells. From the above output, it is clear that Cell 05 is seeing some action while the others are practically idle. Since you don’t operate at the cell level, it can be assumed that the data distribution may not be uniform. Cell #5 may happen to have the most number of storage blocks.
Conclusion
In this installment you learned how to examine metrics from the storage cells using two different interfaces: the command-line tool CellCLI and Enterprise Manager Grid Control. Both have their own appeals. While the visual advantage of the Grid Control is undeniable, the command line tool may be useful in developing scripts and repeatable processes. The Exadata Database Machine comes with a lot of predefined alerts that can be configured via thresholds to make sure they trigger when the metric values fall outside the pre-specified boundary conditions.
This brings us to the end of this series. I hope you developed enough skills in this series to make the transition from DBA to DMA easily and quickly!
Arup Nanda (arup@proligence.com) has been an Oracle DBA for more than 14 years, handling all aspects of database administration, from performance tuning to security and disaster recovery. He is an Oracle ACE Director and was Oracle Magazine's DBA of the Year in 2003.