Advanced Usage of the AWR Warehouse
by Kellyn Pot'vin
Published August 2010
Introduction
The idea of having all AWR data in one repository (available at our fingertips via Oracle Enterprise Manager 12c) is very enticing, but to have the option to query it directly (as many of my peers shall once they have business questions an AWR report or ADDM Comparison can’t answer) is impossible to ignore. I have no doubt they will be impressed with the data and design behind the simple grace of the AWR Warehouse, (AWRW) repository.
I’ve had the opportunity to work with both the Oracle EM12c AWR Warehouse interface, as well as work with the repository via SQL*Plus. I’ve dug in deep to understand what options and performance advantages exist with the AWR Warehouse repository and played devil’s advocate when the chance has arisen. I’m pleased to talk about all the impressive features that a centralized AWR Warehouse offers the IT business.
Design and Function
The AWR Warehouse is set up with the same objects as you are accustomed to in a standard AWR schema of any Oracle database. The enhancement lies in the partitioning, (either by DBID, SNAP_ID or a combination of both) that allows for quick loads, efficient querying and when requested, effective purging of unwanted data.
The jobs to both extract data from the source target, as well as load into the AWR repository is designed with “throttles” to ensure that if historical loads are being performed, no impact to user performance is felt.
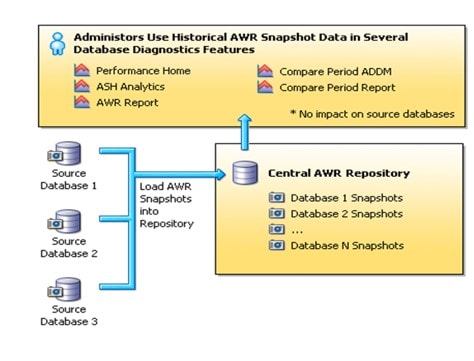
Figure 1.1 The AWR Warehouse Architecture and ETL Load process.
If for some reason the database was unavailable for uploads to the AWR Warehouse, due to maintenance or other outage, there are added “throttles” to ensure an ETL load is never too large and that oldest data is always loaded first to ensure retention times don’t impede the ability to offload the valuable AWR data to the repository.
During a “catch-up” period, the ETL jobs are run once every three hours instead of the once every 24hr. standard interval. The files are transferred from the source target file system to the AWR Warehouse server via a “Agent to Agent” push. This limits the pressure on the network and at no time, touches the EM12c Oracle Management Service, (OMS) and/or Oracle Management Repository, (OMR) server.
Requirements
The repository for the AWR Warehouse should be an 11.2.0.4 database or above and with the tuning and diagnostics pack, a limited EE license is available to use for the AWR Warehouse repository. Don’t attempt to use your EM12c repository, (OMR) for the repository. Considering the amount of data that will be housed here and use type, the two repository use would be highly incompatible long-term. There are patches and other requirements, so see MOS note 1907335.1 for the complete list and detailed steps of installation. For general introduction and set up instructions, see the AWS Warehouse section of the Oracle Documentation set here.
We are going to proceed onto more important things, like how to query the AWRW directly!
Why Mapping is Important
If you were to take your AWR queries "as is" and run them in the AWR Warehouse, you can almost guarantee inaccurate results. To demonstrate this, we can take a specific AQL_ID: "d17f7tgcaa416" to clarify why.
In the following query, using SQL_ID, ‘d17f7tqcaa416’ as an example, you quickly realize that the algorithm used to create the SQL_ID is not unique to the database, but is assigned viato the Oracle software and would be assigned to that query no matter what database it was run in. This is easily recognized as a feature if one were to trouble shoot performance from production to test to development or reporting where having a uniform generation of a unique identifier for a specific statement is valuable.

Due to this, any AWR query that is modified to run against the AWR Warehouse must have a join added to map the DBID so as to limit the results to the source target in question.
To map this data, we then inspect the AWR Warehouse DBSNMP schema and a very important table to the repository that is part of the AWR Warehouse:

This table has a simple, but effective design and is used to map data as part of ETL loads and will be used by EM12c to provide reports via the user interface against the AWR Warehouse and also by anyone wanting to query the AWR Warehouse efficiently.
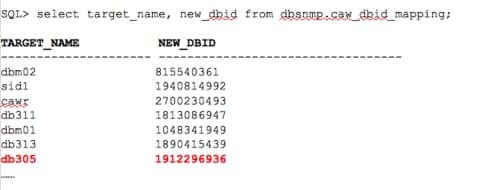
We can now easily add this table to our queries, join on the NEW_DBID, (if you rename your DBID, then understand why the OLD_DBID may be important for some historical queries….) and add the TARGET_NAME to your where clause.
Querying the AWR Warehouse
To update a query, we’ll start with a simple query to inspect information about a particular SQL_ID and the CPU usage per execution plan.
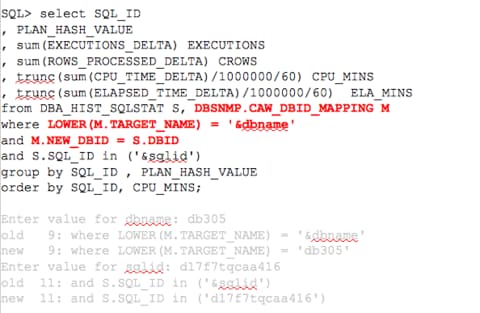

With just a few, simple changes, I now can see that I have seen a change in plan values for the SQL_ID d17f7tqcaa416 for the db305 database.
We can then build out on this and add a second database for comparison:
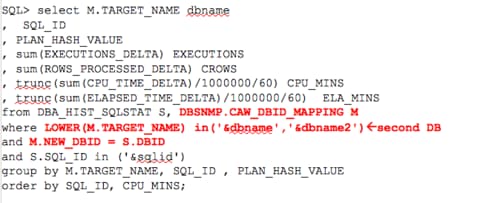
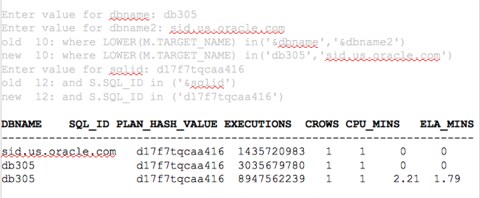
We’ve now demonstrated how a simple join offers performance data for the same query across more than one database.
The next query pulls more information, but still only requires the request for a DBNAME, (or two if you wish to compare or view more than one as we did in the previous query…) and then the join on the DBID to NEW_DBID.
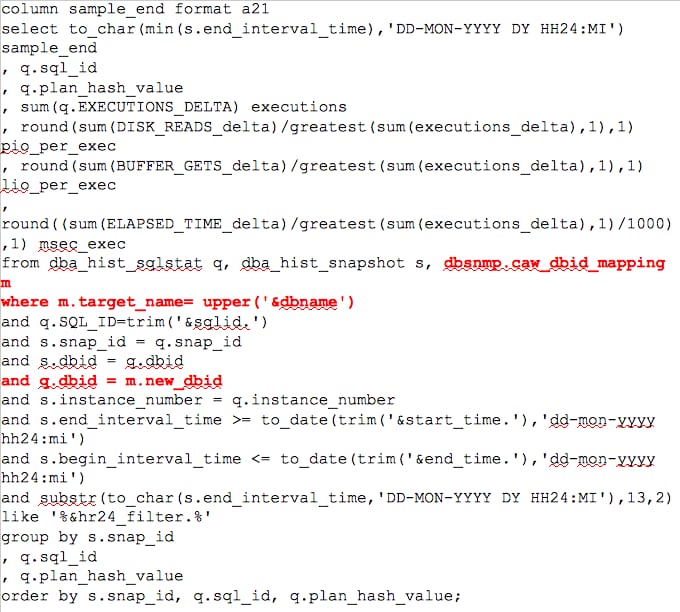
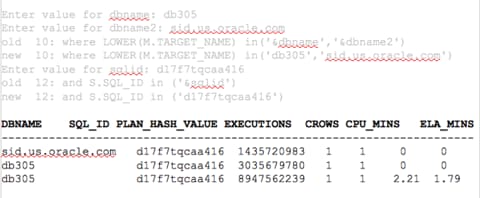
I can now query differences in plans, IO information, etc. and compare mid-year executions in June 2010 vs. June 2014. We can use this information to answer very specific business questions, performance changes or pull execution plans for comparison, as all of the DBA_HIST_XX data exists in the AWR Warehouse. With all of this data from the source, now offloaded to the AWR Warehouse available, you are able to perform full analysis against all history for the database. The AWR Warehouse is designed for advanced reporting vs. previous AWR repository that resided with the production environment and may have impacted production use if advanced analysis was performed on the source database.
Across Multiple Databases on One Host
As demonstrated with previous queries, we’ll now demonstrate results across more than just one database, but focus on values for an entire host and/or engineered system.
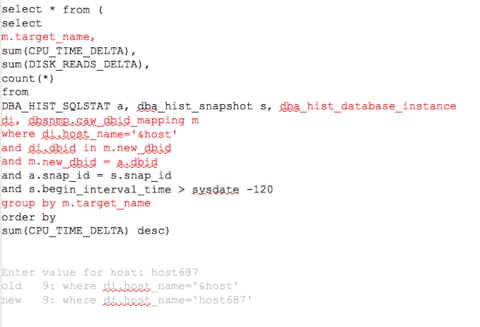
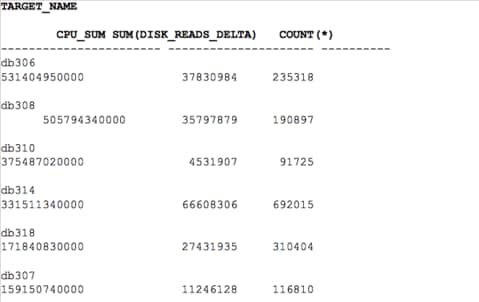
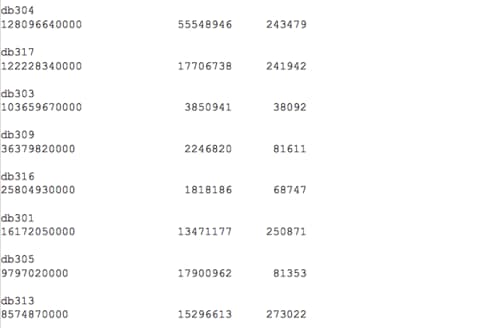
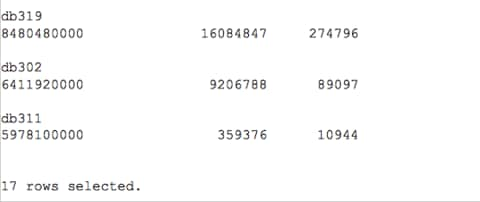
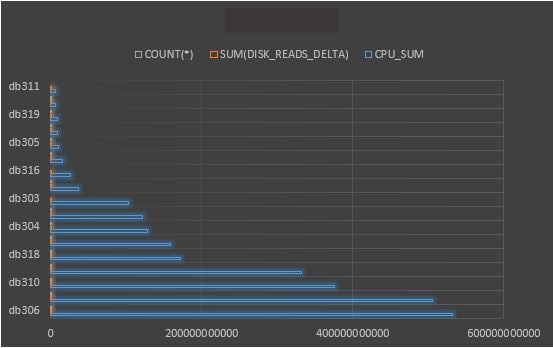
Displayed above are a high level view of CPU usage, disk reads and quantity of executions for the last 120 days across this host for all the databases that reside on it. We could also take this data and create a graph to give a visual view of this data for the business to understand the demands of one database over another:
What Can’t I do with the AWR Warehouse?
As the examples above demonstrate, there are very few performance issues that can’t be identified with the AWR Warehouse repository. The infinite retention and advanced warehouse features are only limited by the user’s vision to answer all the questions of Information Technology about a business’ database universe.
Enhancements and new ways of using this invaluable data arrives every day and more and more people are going to embrace AWR Warehouse in the year to come. Build the database, install the AWR Warehouse and start to use it -- The sky’s the limit.
About the Author
Kellyn Pot'Vin is an Oak Table Member and the Consulting Member for the Strategic Customer Program, a specialized group of Enterprise Manager specialists at Oracle. She specializes in environment optimization tuning, automation and creating systems that are robust and enterprise grade. Kellyn works almost exclusively on multi-TB size databases, including Exadata and solid state disk solutions and is known for her extensive work with both the Oracle Enterprise Manager 12c and its command line interface. She is the co-author on a number of technical books, hosts webinars for ODTUG, OTN and All Things Oracle and has presented at Oracle OpenWorld, HotSos, Collaborate, KSCOPE and numerous other US and European conferences. Kellyn is a strong advocate for Women in Technology (WIT), citing education on topics regarding stereotypes and presenting opportunities early as the path to overcoming challenges. Follow her on Twitter @DBAKevlar and on her blog at http://dbakevlar.com.