 Artigos
Cloud Computing
Artigos
Cloud Computing
Primeiros passos com Oracle Berkeley DB XML
Por Rodrigo Almeida
Postado en outubro 2011
O principal objetivo deste artigo é iniciar os primeiros passos com o Oracle Berkeley DB XML, em um outro artigo sobre a Introdução ao Oracle Berkeley DB XML, discutimos as características e funcionalidades desse pequeno banco de dados que as aplicações podem utilizar como uma solução de banco de dados para arquivos XML.
Assim sendo, vamos iniciar as nossas primeiras atividades, entendendo os seus componentes que compõe a sua arquitetura e alguns comandos de manipulação de dados em arquivos XML.
Para ajudar o nosso entendimento sobre os conceitos do Oracle Berkeley DB XML, vamos criar um projeto de AGENDA DE CONTATOS, primeiramente, manipulando os arquivos apenas usando o Oracle Berkeley DB XML, também conhecido como BDB.
Partindo como ponto de início esse pequeno projeto, estou disponibilizando para download um pacote com 4 arquivos em XML para realizarmos passo-a-passo os comandos do BDB, um modelo desses arquivos pode ser visto na imagem abaixo. Basta fazer o download do pacote clique aqui.
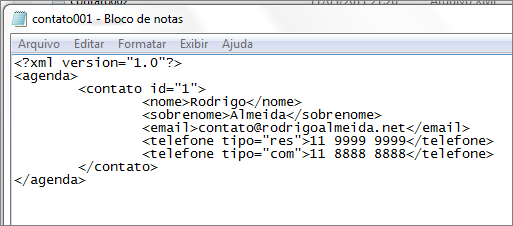
Agora que já conhecemos o modelo do arquivo e fizemos o download do pacote, vamos aos ensinamentos práticos do Oracle Berkeley DB XML e aprender sobre o conceito de Container.
Container
Assim como um banco de dados normal, o Oracle Berkeley DB XML também gera um banco de dados para XML em um arquivo em disco, com a extensão DBXML (Database XML) onde a sua aplicação através de uma API (Application Programming Interface) abre este arquivo, lê, escreve os dados e depois fecha. Como um arquivo convencional do sistema operacional.
Este simples conceito no Oracle Berkeley DB XML é chamado de Container, que funciona como uma área de memória do banco de dados permitindo o gerenciamento dos arquivos XML de forma muito mais performática e ágil para à aplicação.
1º Passo – Acessando o Oracle Berkeley DB XML

Para acessar o BDB em sua máquina após a instalação, basta executar o comando DBXML no prompt do DOS como está no exemplo acima.
2º Passo – Criando um container

Preste bem atenção!
No comando na imagem acima, estamos criando um container no BDB chamado AGENDA.DBXML, como explicado no início, que um container é um arquivo físico em disco para acesso aos nossos XMLs, ao emitir o comandoCreateContainer, será gerado um arquivo agenda.dbxml no caminho que chamei o shell DBXML.
Deste modo, perceba que estou iniciando a console do DBXML no caminho E:\Banco de dados\Berkeley\Exercicios, assim sendo, quando emitir o comando CreateContainer agenda.dbxml, será gerado o meu arquivo agenda.dbxml neste caminho.
A imagem abaixo mostra o arquivo gerado pelo comando de criação do container.

Posteriormente, quando sair do BDB ou reiniciar a máquina, quando precisar abrir o seu container, dependendo do caminho que está executando o seu shell, poderá dar erros dizendo que o arquivo não foi encontrado.
3º Passo – Criando um Documento XML

Quando realizar o download do pacote que disponibilizei, encontrará 4 arquivos xml de exemplo. Para incluir esse arquivo no Oracle Berkeley DB XML, basta utilizar o comando putDocument, que é composto pela seguinte estrutura:
dbxml> putDocument <alias> <nome_do_arquivo_fisico) f
onde,
<alias>, é o nome que será utilizado dentro do Oracle Berkeley DB XML.
<nome_do_arquivo_fisico>, é o nome do nosso arquivo XML que queremos manipular dentro da base.
f (file), é a variável que indica ao BDB que se trata de um arquivo.
A imagem acima mostra como incluir o documento contato001.xml no BDB.
4º Passo – Exibindo o arquivo no BDB

O comando print exibe o resultado do arquivo que já esta dentro do nosso banco de dados.
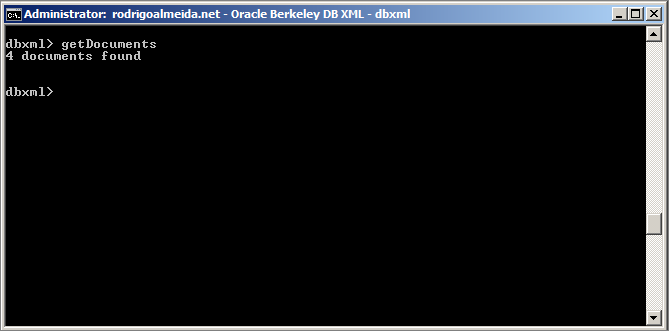
5º Passo – Verificando a quantidade de arquivos no Container

Para saber quantos arquivos existem em nosso container, basta emitir o comando getDocuments como mostra a imagem acima.
Importante lembrar que estamos incluindo arquivos físicos em XML ao nosso banco de dados.
6º Passo – Incluir os demais arquivos XML da agenda

No pacote de exercícios, estão 4 arquivos, no passo 3 incluímos o arquivo contato001.xml, agora, vamos incluir os demais arquivos (contato002.xml, contato003.xml e contato004.xml) em nosso banco de dados para melhorar os passos posteriores.
A imagem acima mostra a inclusão desses outros três arquivo.
7º Passo – Verificando a quantidade de arquivos
Novamente neste passo, estamos verificando quantos arquivos estão em nosso container.
8º Passo – Incluindo um arquivo XML diretamente no shell do DBXML

Neste passo, vamos utilizar outro método de inclusão de um arquivo XML, sem utilizar um arquivo físico XML, vamos incluir mais um contato em nossa agenda colocando o contéudo do XML diretamente no comando putDocument, como mostra a imagem.
Perceba que no final do comando, estamos usando a variável s (string) e também não estamos utilizando a marcação <?xml version=”1.0″?>, pois estamos incluindo um documento diretamente do BDB.
Então lembre-se, com o comando putDocument, a variável f (file) é para arquivo físico xml e s (string) para dados xml diretamente da console.
9º Passo – Removendo um arquivo xml do container
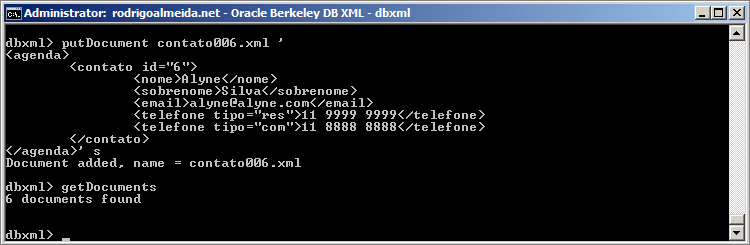
Neste passo, vamos treinar a remoção de um arquivo XML, para melhorar o entendimento dos passos anteriores, vou criar mais um contato novo, cujo o nome é contato006.xml diretamente da console do DBD usando o comandoputDocument.
Após a inclusão, verifico a quantidade de arquivos em meu container usando o getDocuments.
Agora, vou usar o comando removeDocument <alias> para remover o meu contato006.xml, veja como ficou a remoção do arquivo na imagem abaixo:

Sempre iremos utilizar o <alias> que criamos ao arquivo XML para remover, independente se é um arquivo físico ou dado xml direto do BDB. No exemplo abaixo, incluí o mesmo contato, só que agora, usando um arquivo físico XML, e perceba que o <alias> do meu arquivo é contato006.xml.

Uma observação importante, que quando removemos um arquivo físico XML do BDB, esse arquivo não é apagado no sistema operacional, será necessário scripts que iremos aprender mais para frente para realizar essa deleção ou através das APIs na aplicação.
10º Passo – Validando a quantidade de arquivos no container

Este passo é apenas para validar a quantidade de arquivos que possui o nosso container agenda.dbxml para os próximos passos.
11º Passo – Verificando o contéudo do nosso container

No passo 10 analisamos a quantidade de arquivos que possui o nosso container, após isso, neste passo estamos emitindo o comando print, ele irá exibir todo o contéudo dos arquivos presentes em nosso container. Veja uma diferença bacana, nos exemplos que incluímos usando a opção F no putDocument, está com a marcação <?xml?>, já no contato005.xml, que incluimos diretamente na console, não possui essa marcação, pois este arquivo será para trabalhar diretamente no BDB, sem arquivo físico.
XQUERY e XPATH
Nos próximos passos vamos começar a manipular os dados estruturados em XML dentro do Oracle Berkeley DB XML, para manipular os dados como se fosse a linguagem SQL, iremos utilizar sempre a cláusula QUERY, isso significa que iremos adotar a technologia XQUERY e XPATH para realizar consultar nos nós (nodes), elementos (element) e atributos (attribute) de um arquivo XML.
Nossa intenção nesse momento não é se aprofundar em XQUERY e XPATH, vamos deixar para um artigo mais específico sobre este assunto. Mas como esses são os nossos primeiros passos, vamos utilizar algumas de suas funções para recuperar os dados dos arquivos XML e conhecer um pouco mais sobre o Oracle Berkeley DB XML.
DICA
Sempre que usar o comando query no BDB, posteriormente use print para exibir os resultados, quem está acostumado com SQL vai estranhar um pouco, pois no BDB os resultados não são exibidos após o comando.
12º Passo – Consultando todos os arquivos XML usando XQUERY

Neste exemplo, estamos consultando todos os nós (nodes) e elementos (elements) de todos os arquivos XML.
13º Passo – Consultando todos os arquivos XML a partir do nó AGENDA

Agora, estamos consultando todos os arquivos do container, porém, a partir do nó AGENDA, perceba a diferença no resultado.
14º Passo – Consultando todos os elementos dos arquivos XML

No exemplo acima, estamos realizando uma consulta a partir dos nós AGENDA (PAI) e CONTATO (FILHO), o resultado será todos os elementos que estão abaixo da hierarquia. Veja que trouxe NOME,SOBRENOME,EMAIL e TELEFONE.
Isso é possível pois os arquivos XML possui hierarquia em sua estrutura, neste caso, o maior na hierarquia é o nó AGENDA e o menos é NOME,SOBRENOME,EMAIL e TELEFONE.
Outro ponto interessante é que o XQUERY possui justamente essa característica, realizar consultas hierarquicamente.
15º Passo – Consultando os dados em formato de String

A grande diferença neste tipo de consulta, que agora substituimos o * por String(), deste modo, as tags xml não serão exibidas no resultado, teremos somente o dado em sí, ou seja, a String.
16º Passo – Utilizando a função CONTAINS de XPATH nas consultas
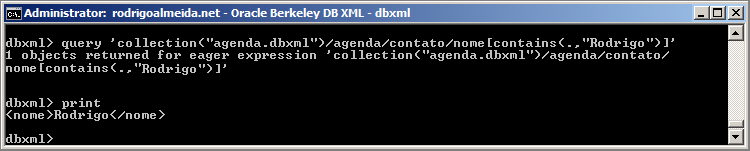
Para deixar nossos primeiros passos mais legal, vamos utilizar algumas funções do XPATH em nossas consultas, no exemplo acima, estou utilizando a função CONTAINS, procurando pelo resultado “Rodrigo” dentro do elemento AGENDA/CONTATO/NOME.
17º Passo – Utilizando a função CONTAINS de XPATH nas consultas exibindo em string

O mesmo conceito do passo anterior, porém, alterando o formato do resultado, sem as tags xml, queremos apenas o contéudo do elemente nome, e para isso, adicionamos a opção String() no final do comando.
18º Passo – Consulta por valores dentro de um elemento XML

Neste exemplo, estamos realizando uma consulta usando a função CONTAINS apenas dentro do elemento CONTATO.
19º Passo – Teste do Sensitive-case

Como o Oracle Berkeley DB XML foi escrito em C++, suas funções são todas sensitive-case, ou seja, se procurar por RODRIGO ou rodrigo, terá resultados diferentes. Nos próximos artigos irei passar as dicas de como consultar pegando todos os possíveis valor.
Mas neste exemplo, é apenas para ilustrar que realizando o mesmo tipo de consulta do passo 18, o BDB não nos retorna registros, pois escrevemos FERNANDA tudo em maiúsculo.
20º Passo – Filtrando resultado por XPATH

Veja a utilização da cláusula [@id="1"], isso é o XPATH em ação. Neste exemplo, estamos filtrando os resultados.
21º Passo – Filtrando dados por atributo do elemento

Outro tipo de filtro muito interessante no XQUERY, vamos realizar uma consulta no elemento TELEFONE, porém, filtrando por um atributo do elemento.
22º Passo – Consultando por arquivo XML específico

Outra possibilidade bem legal do BDB, em todos os nossos passos, utilizamos sempre Colection (coleção) para mencionar que estamos utilizando um banco de dados XML, no caso, um DBXML. Porém, o XQUERY também nos permite realizar uma consulta diretamente em nosso arquivo físico XML, como mostra a imagem acima.
23º Passo – Consulta XQUERY em arquivo XML usando função XPATH

24º Passo – Calculando o tempo de execução de uma Query

Assim como os bancos de dados relacionais, o Oracle Berkeley DB XML também permite ao desenvolvedor analisar o tempo de suas consultas dentro do BDB, para isso, utilize apenas o comando time antes da query como está no exemplo acima.
Como em nosso pequeno projeto temos poucos dados, os tempos são baixissímos, porém, o BDB pode suportar até 256TB em uma base DBXML, então para casos de banco de dados XML maiores, essa função é muito importante.
25º Passo – Analise de Plano de Execução
O Oracle Berkeley DB XML também permite realizar o plano de execução para as suas XQUERYS, muito importante para determinar quais tipos de índices serão necessários criar e saber qual ponto da sua query está com problemas.
Plano de execução e índices iremos abordar em outros artigos posteriores, esse não é o momento.
26º Passo – Informações sobre o seu Container

O comando info exibe todas as informações sobre o seu container, tais como versão, auto-indexação ativado, se é container padrão, se está trabalhando com metadata e etc.
27º Passo – Lista de índices do container

Comando utilizado para listar todos os índices criados em seu container, é bom saber que por padrão, a opçãoSetAutoIndexing é habilitado, ou seja, para todos os nós e elementos do seu arquivo xml é criado um índice, posteriormente será possível substituir esses tipos de índices baseados no seu tipo de consulta para ganhar performance.
Índice terá um artigo somente sobre o assunto.
28º Passo – Expressão FLWOR


Outro recurso muito poderoso do BDB, utilização do FLWOR (For Let Where Order by Return), que praticamente chega muito perto da linguagem SQL convencional dos bancos de dados relacionais e pode trazer resultados maravilhosos no BDB.
Estou apenas citando um exemplo, mas também terá artigos específicos sobre este assunto.
29º Passo – Excluir um Container

Criamos um container, criamos arquivos, manipulamos, usamos XQUERY, XPATH, índices, FLWOR e até mesmo podemos utilizar expressões regulares, mas se eu quiser acabar com tudo. Basta excluir o meu container.
Na imagem acima, estou excluindo o container agenda.dbxml que vou utilizar em todos os artigos sobre Oracle Berkeley DB XML, este passo é apenas opcional para testar o comando removeContainer <alias>.
Postado por Rodrigo Almeida. Bloggers regionais externos mas que conhecemos.
Entre em Contato Conosco
- Vendas: 0800-891-4433
- Contatos Globais
- Diretório de Suporte