Lab: Introduction to Oracle Solaris 11 ZFS File System
Hands-On Labs Of the System Admin and Developer Community of OTN
Oracle Solaris ZFS is a revolutionary file system that changes the way we look at storage allocation for open systems. This session is a hands-on tutorial on the basics of Oracle Solaris ZFS. It describes how devices are used in storage pools and considers performance and availability. It also looks at the various types of Oracle Solaris ZFS datasets that can be created and when to use each type. Participants will learn about file system snapshots, cloning data, allocation limits and recovering from common errors.
In the following exercises, we will create some zpools and explore different types of virtual devices (vdevs). We will also create two different types of ZFS datasets, file systems and volumes. We will customize some properties, snapshot and clone them, and finally perform some upgrades. In the advanced section, we will look at how some of the other Oracle Solaris services, like NFS (Network File System) and FMA (Fault Management Architecture) are tied into ZFS.
These exercises are meant to explore some of the possibilities. Armed with the manual pages and a group of willing assistants, you are encouraged to explore any other features of ZFS.
Lab activities
| Activity | Estimated Time | Exercises |
|---|---|---|
| Lab Overview | 5 min | N/A |
| Working with Pools | 15 min | Yes |
| Working with File Systems | 20 min | Yes |
| Error handling and recovery | 10 min | Yes |
Lab Overview
In this lab will be be using a VirtualBox guest for all of the exercises. We will be using a combination of flat files and virtual disks for different parts of the lab. Here is a quick overview of the configuration before we get started.
| Device | Usage |
|---|---|
| Disks: | c1t0d0 - Solaris root file system (rpool) |
| c4t1d0 - 8 GB data disk for ZFS use | |
| c4t1d0 - 8 GB data disk for ZFS use | |
| Flat files (500MB each) | /dev/dsk/disk1 |
| /dev/dsk/disk2 | |
| /dev/dsk/disk3 | |
| /dev/dsk/disk4 |
Lab Setup
Lab Installing Oracle Solaris 11 in Oracle VM VirtualBox must be completed before beginning this lab.
We need to add the two 8 GB virtual disks used throughout this lab to our VirtualBox guest.
If the Solaris virtual machine is running, shut it down.
In VirtualBox, select the settings for the OracleSolaris11_11-11 machine and select the Storage category on the left. Then click the Add Controller icon to add a SAS Controller:
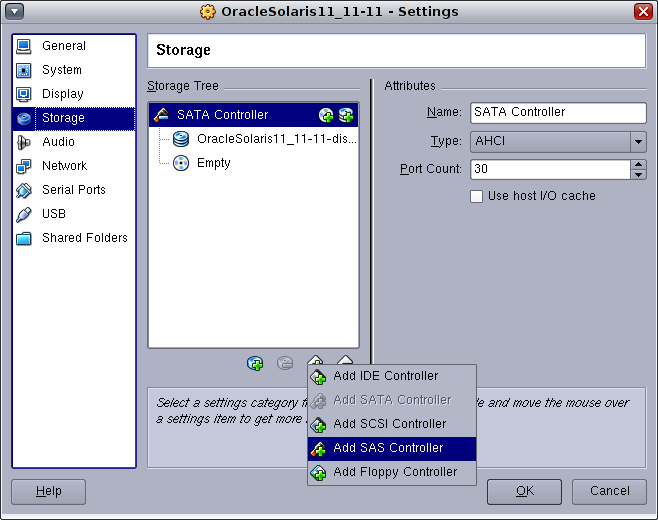
The click the icon to add a new disk to the SAS Controller:
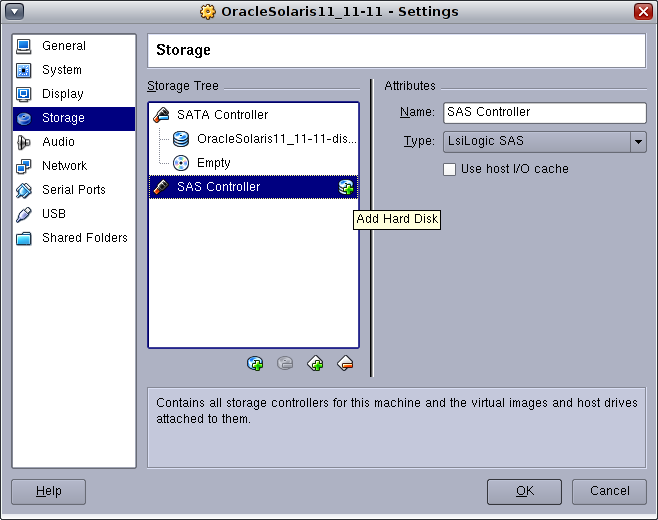
Create a new disk:
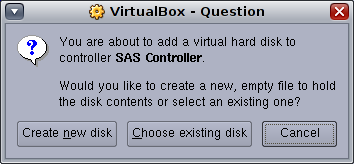
This will launch the Create New Virtual Disk Wizard:
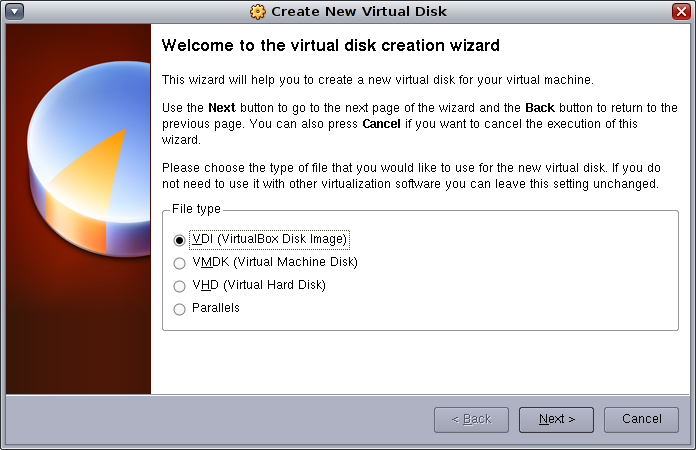
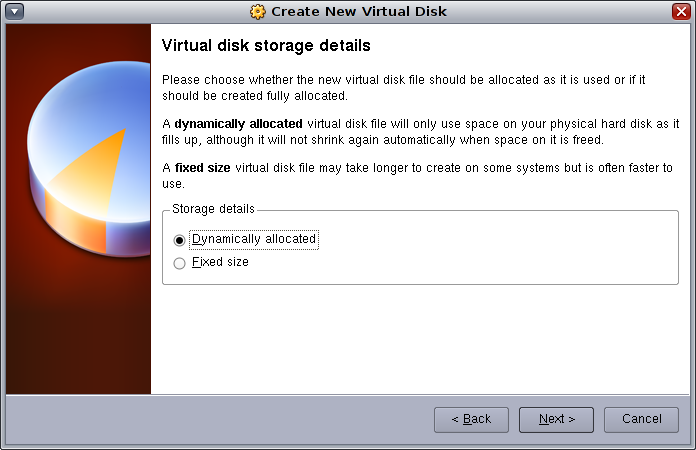
Click Next. We'll use the default Dynamically expanding storage type:
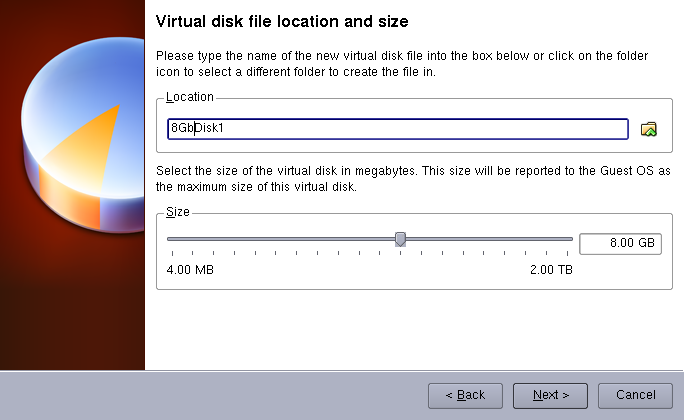
Click Next. Set the Disk's name to 8GDisk1.vdi. Set its size to 8 GB.
Click Next.
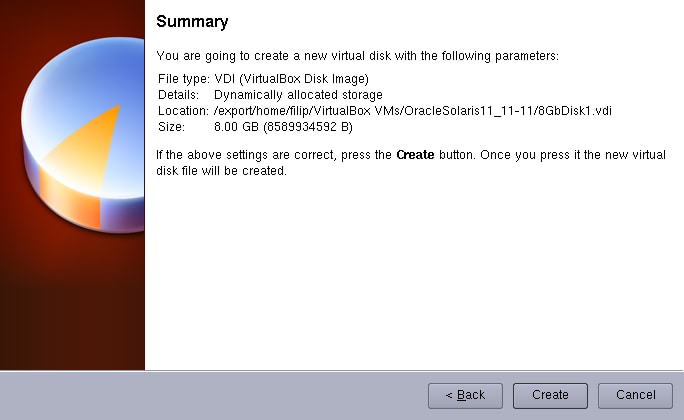
Then Create.
Repeat those steps, naming the second disk 8GDisk2.
Start the Solaris VM.
This will be an interactive lab run in a GNOME terminal window. Once logged in, bring up a terminal window and become the root user. The root password is the password you defined when you have imported Oracle Solaris 11 VM appliance into Oracle VM VirtualBox.
oracle@solaris:~$ su -
Password: <root password>
Oracle Corporation SunOS 5.11 11.0 November 2011
root@solaris:~#
Run format and note the device names as they may very well differ from the examples used in this lab:
# format < /dev/null
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c3t0d0 <ATA-VBOX HARDDISK-1.0 cyl 8351 alt 2 hd 255 sec 63>
/pci@0,0/pci8086,2829@d/disk@0,0
1. c4t0d0 <VBOX-HARDDISK-1.0-8.00GB>
/pci@0,0/pci1000,8000@16/sd@0,0
2. c4t1d0 <VBOX-HARDDISK-1.0-8.00GB>
/pci@0,0/pci1000,8000@16/sd@1,0
Specify disk (enter its number):
You're now ready to begin the lab exercises!
Exercise 1: Working with Pools
In the ZFS file sytems, storage devices are grouped into pools, called zpools. These pools provide all of the storage allocations that are used by the file systems and volumes that will be allocated from the pool. Let's begin by creating a simple zpool, called datapool.
First we need some storage devices. We will create 4 files and use them for our first pool.
# mkfile 500m /dev/dsk/disk1
# mkfile 500m /dev/dsk/disk2
# mkfile 500m /dev/dsk/disk3
# mkfile 500m /dev/dsk/disk4
Now let's create our first pool.
# zpool create datapool raidz disk1 disk2 disk3 disk4
That's all there is to it. We can use zpool status to see what our first pool looks like.
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
disk3 ONLINE 0 0 0
disk4 ONLINE 0 0 0
What we can see from this output that our new pool called datapool has a single ZFS virtual device (vdev) called raidz1-0. That vdev is comprised of our four disk files that we created in the previous step.
This type of vdev provides single device parity protection, meaning that if one device develops an error, no data is lost because it can be reconstructed using the remaining disk devices. This organization is commonly called a 3+1, 3 data disks plus one parity.
ZFS provides additional types of availability: raidz2 (2 device protection), raidz3 (3 device protection), mirroring and none. We will look at some of these in later exercises.
Before continuing, let's take a look at the currently mounted file systems.
NOTE: In Oracle Solaris 11 zfs list command shows how much space ZFS filesystems consume. In case you need to see how much space is available on non-ZFS filesystem, such as mounted over the network via NFS or another protocol, traditional df(1) command exists in Oracle Solaris 11 and can be used. System administrators familiar with df(1) can continue to use df(1), while using zfs list for ZFS filesystems is encouraged.
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
datapool 97.2K 1.41G 44.9K /datapool
rpool 7.91G 54.6G 39K /rpool
rpool/ROOT 6.36G 54.6G 31K legacy
rpool/ROOT/solaris 6.36G 54.6G 5.80G /
rpool/ROOT/solaris/var 467M 54.6G 226M /var
rpool/dump 516M 54.6G 500M -
rpool/export 6.52M 54.6G 33K /export
rpool/export/home 6.42M 54.6G 6.39M /export/home
rpool/export/home/oracle 31K 54.6G 31K /export/home/oracle
rpool/export/ips 63.5K 54.6G 32K /export/ips
rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example
rpool/swap 1.03G 54.6G 1.00G -
Notice that when we created the pool, ZFS also created the first file system and also mounted it. The default mountpoint is derived by the name of the pool, but can be changed if necessary. With ZFS there's no need to create a file system, make a directory to mount the file system. It is also unnecessary to add entries to /etc/vfstab. All of this is done when the pool is created, making ZFS much easier to use than traditional file systems.
Before looking at some other types of vdevs, let's destroy the datapool, and see what happens.
# zpool destroy datapool
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 7.91G 54.6G 39K /rpool
rpool/ROOT 6.36G 54.6G 31K legacy
rpool/ROOT/solaris 6.36G 54.6G 5.80G /
rpool/ROOT/solaris/var 467M 54.6G 226M /var
rpool/dump 516M 54.6G 500M -
rpool/export 6.52M 54.6G 33K /export
rpool/export/home 6.42M 54.6G 6.39M /export/home
rpool/export/home/oracle 31K 54.6G 31K /export/home/oracle
rpool/export/ips 63.5K 54.6G 32K /export/ips
rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example
rpool/swap 1.03G 54.6G 1.00G -
All file systems in the pool have been unmounted and the pool has been destroyed. The devices in the vdev have also been marked as free so they can be used again.
Let's now create a simple pool using a 2 way mirror instead of raidz.
# zpool create datapool mirror disk1 disk2
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
errors: No known data errors
Now the vdev name has changed to mirror-0 to indicate that data redundancy is provided by mirroring (redundant copies of the data) instead of parity as it was in our first example.
What happens if you try to use a disk device that is already being used by another pool? Let's take a look.
# zpool create datapool2 mirror disk1 disk2
invalid vdev specification
use '-f' to override the following errors:
/dev/dsk/disk1 is part of active pool 'datapool'
The usage error indicates that /dev/dsk/disk1 has been identified as being part of an existing pool called datapool. The -f flag to the zpool create command can override the failsafe in case datapool is no longer being used, but use that option with caution.
Since we have two additional disk devices (disk3 and disk4), let's see how easy it is to grow a ZFS pool.
# zpool list datapool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 492M 89.5K 492M 0% 1.00x ONLINE -
# zpool add datapool mirror disk3 disk4
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
disk3 ONLINE 0 0 0
disk4 ONLINE 0 0 0
errors: No known data errors
See that a second vdev (mirror-1) has been added to the pool. Let's look at the zpool listing now.
# zpool list datapool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 984M 92.5K 984M 0% 1.00x ONLINE -
Our pool has grown from 500MB to 1GB.
# zfs list datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 91K 952M 31K /datapool
Notice that you don't have to grow file systems when the pool capacity increases. File systems can use whatever space is available in the pool, subject to quota limitations, which we will see in a later exercise.
ZFS zpools can also be exported, allowing all of the data and associated configuration information to be moved from one system to another. For this example, let's use two of our SAS disks (c4t0d0 and c4t1d0).
# zpool create pool2 mirror c4t0d0 c4t1d0
# zpool status pool2
pool: pool2
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
pool2 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c4t0d0 ONLINE 0 0 0
c4t1d0 ONLINE 0 0 0
errors: No known data errors
As before, we have created a simple mirrored pool of two disks. In this case, the disk devices are real disks, not files. In this case we've told ZFS to use the entire disk (no slice number was included). If the disk was not labeled, ZFS will write a default label.
Now let's export pool2 so that another system can use it.
# zpool list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 984M 92.5K 984M 0% 1.00x ONLINE -
pool2 7.94G 83.5K 7.94G 0% 1.00x ONLINE -
rpool 19.9G 6.18G 13.7G 31% 1.00x ONLINE -
# zpool export pool2
# zpool list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 984M 92.5K 984M 0% 1.00x ONLINE -
rpool 19.9G 6.19G 13.7G 31% 1.00x ONLINE -
Let's import the pool, demonstrating another easy to use feature of ZFS.
# zpool import pool2
# zpool list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 984M 92.5K 984M 0% 1.00x ONLINE -
pool2 7.94G 132K 7.94G 0% 1.00x ONLINE -
rpool 19.9G 6.19G 13.7G 31% 1.00x ONLINE -
Notice that we didn't have to tell ZFS where the disks were located. All we told ZFS was the name of the pool. ZFS looked through all of the available disk devices and reassembled the pool, even if the device names had been changed.
What if we didn't know the name of the pool ? ZFS can help there too.
# zpool export pool2
# zpool import
pool: pool2
id: 12978869377007843914
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
pool2 ONLINE
mirror-0 ONLINE
c4t0d0 ONLINE
c4t1d0 ONLINE
# zpool import pool2
Without an argument, ZFS will look at all of the disks attached to the system and will provide a list of pool names that it can import. If it finds two pools of the same name, the unique identifier can be used to select which pool you want imported.
There are a lot of pool properties that you might want to customize for your environment. To see a list of these properties, use zpool get
# zpool get all pool2
NAME PROPERTY VALUE SOURCE
datapool size 7.94G -
datapool capacity 0% -
datapool altroot - default
datapool health ONLINE -
datapool guid 18069440062221314300 -
datapool version 33 default
datapool bootfs - default
datapool delegation on default
datapool autoreplace off default
datapool cachefile - default
datapool failmode wait default
datapool listsnapshots off default
datapool autoexpand off default
datapool dedupditto 0 default
datapool dedupratio 1.00x -
datapool free 7.94G -
datapool allocated 216K -
datapool readonly off
These properties are all described in the zpool(1M) man page. Type man zpool to get more information. To set a pool property, use zpool set. Note that not all properties can be changed (ex. version, free, allocated).
# zpool set listsnapshots=on pool2
# zpool get listsnapshots pool2
NAME PROPERTY VALUE SOURCE
pool2 listsnapshots on local
Before ending this exercise, let's take a look at one more zpool property: version. In this case the zpool version number is 31. To find out what features this provides, use zpool upgrade -v.
# zpool upgrade -v
This system is currently running ZFS pool version 33.
The following versions are supported:
VER DESCRIPTION
--- --------------------------------------------------------
1 Initial ZFS version
2 Ditto blocks (replicated metadata)
3 Hot spares and double parity RAID-Z
4 zpool history
5 Compression using the gzip algorithm
6 bootfs pool property
7 Separate intent log devices
8 Delegated administration
9 refquota and refreservation properties
10 Cache devices
11 Improved scrub performance
12 Snapshot properties
13 snapused property
14 passthrough-x aclinherit
15 user/group space accounting
16 stmf property support
17 Triple-parity RAID-Z
18 Snapshot user holds
19 Log device removal
20 Compression using zle (zero-length encoding)
21 Deduplication
22 Received properties
23 Slim ZIL
24 System attributes
25 Improved scrub stats
26 Improved snapshot deletion performance
27 Improved snapshot creation performance
28 Multiple vdev replacements
29 RAID-Z/mirror hybrid allocator
30 Encryption
31 Improved 'zfs list' performance
32 One MB blocksize
33 Improved share support
For more information on a particular version, including supported releases,
see the ZFS Administration Guide.
When you patch or upgrade Oracle Solaris, a new version of the zpool may be available. It is simple to upgrade an existing pool, adding the new functionality. In order to do that, let's create a pool using an older version number (yes, you can do that too), and then upgrade the pool.
# zpool destroy pool2
# zpool create -o version=17 pool2 mirror c4t0d0 c4t1d0
# zpool upgrade pool2
This system is currently running ZFS pool version 33.
Successfully upgraded 'pool2' from version 17 to version 33
And that's it - nothing more complicated than zpool upgrade. Now you can use features provided in the newer zpool version, like log device removal (19), snapshot user holds (18), etc.
One word of warning - this pool can no longer be imported on a system running a zpool version lower than 33.
We're done working with zpools. There are many more things you can do. If you want to explore, see the man page for zpool (man zpool) and ask a lab assistant if you need help.
Let's now clean up before proceeding.
# zpool destroy pool2
# zpool destroy datapool
Exercise 2: Working with Datasets (File Systems, Volumes)
Now that we understand how to manage ZFS zpools, the next topic are the file systems. We will use the term datasets because a zpool can provide many different types of access, not just through traditional file systems.
As we saw in the earlier exercise, a default dataset (file system) is automatically created when creating a zpool. Unlike other file system and volume managers, ZFS provides hierarchical datasets (peer, parents, children), allowing a single pool to provide many storage choices.
ZFS datasets are created, destroyed and managed using the zfs(1M) command. If you want to learn more, read the associated manual page by typing man zfs.
To begin working with datasets, let's create a simple pool, again called datapool and 4 additional datasets called bob joe fred and pat.
# zpool create datapool mirror c4t0d0 c4t1d0
# zfs create datapool/bob
# zfs create datapool/joe
# zfs create datapool/fred
# zfs create datapool/pat
We can use zfs list to get basic information about all of our ZFS datasets.
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 238K 7.81G 35K /datapool
datapool/bob 31K 7.81G 31K /datapool/bob
datapool/fred 31K 7.81G 31K /datapool/fred
datapool/joe 31K 7.81G 31K /datapool/joe
datapool/pat 31K 7.81G 31K /datapool/pa
By using zfs list -r datapool, we are listing all of the datasets in the pool named datapool. As in the earlier exercise, all of these datasets (file systems) have been automatically mounted.
If this was a traditional file system, you might think there was 39.05 GB (7.81 GB x 5) available for datapool and its 4 datasets, but the 8GB in the pool is shared across all of the datasets. Let's see how that works.
# mkfile 1024m /datapool/bob/bigfile
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 1.00G 6.81G 35K /datapool
datapool/bob 1.00G 6.81G 1.00G /datapool/bob
datapool/fred 31K 6.81G 31K /datapool/fred
datapool/joe 31K 6.81G 31K /datapool/joe
datapool/pat 31K 6.81G 31K /datapool/pat
Notice that in the USED column, datapool/bob shows 1GB in use. The other datasets show just the metadata overhead (21k), but their available space has been reduced to 6.81GB. That's because that is the amount of free space available to them after datapool/bob had consumed the 1GB.
A dataset can have children, just as a directory can have subdirectories. For datapool/fred, let's create a dataset for documents, and then underneath that, additional datasets for pictures, video and audio.
# zfs create datapool/fred/documents
# zfs create datapool/fred/documents/pictures
# zfs create datapool/fred/documents/video
# zfs create datapool/fred/documents/audio
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 1.00G 6.81G 35K /datapool
datapool/bob 1.00G 6.81G 1.00G /datapool/bob
datapool/fred 159K 6.81G 32K /datapool/fred
datapool/fred/documents 127K 6.81G 34K /datapool/fred/documents
datapool/fred/documents/audio 31K 6.81G 31K /datapool/fred/documents/audio
datapool/fred/documents/pictures 31K 6.81G 31K /datapool/fred/documents/pictures
datapool/fred/documents/video 31K 6.81G 31K /datapool/fred/documents/video
datapool/joe 31K 6.81G 31K /datapool/joe
datapool/pat 31K 6.81G 31K /datapool/pat
A common question is when do you create a subdirectory and when would you use a dataset? The simple answer is if you would want to change any of the ZFS dataset properties between a parent and child, you would create a new dataset. Since properties are applied to a dataset, all directories in that dataset have the same properties. If you want to change one, like quota, you have to create a child dataset.
Let's take a look at some of the ZFS dataset properties.
# zfs get all datapool
NAME PROPERTY VALUE SOURCE
datapool type filesystem -
datapool creation Tue Nov 22 3:28 2011 -
datapool used 1.00G -
datapool available 6.81G -
datapool referenced 35K -
datapool compressratio 1.00x -
datapool mounted yes -
datapool quota none default
datapool reservation none default
datapool recordsize 128K default
datapool mountpoint /datapool default
datapool sharenfs off default
datapool checksum on default
datapool compression off default
datapool atime on default
datapool devices on default
datapool exec on default
datapool setuid on default
datapool readonly off default
datapool zoned off default
datapool snapdir hidden default
datapool aclmode discard default
datapool aclinherit restricted default
datapool canmount on default
datapool xattr on default
datapool copies 1 default
datapool version 5 -
datapool utf8only off -
datapool normalization none -
datapool casesensitivity mixed -
datapool vscan off default
datapool nbmand off default
datapool sharesmb off default
datapool refquota none default
datapool refreservation none default
datapool primarycache all default
datapool secondarycache all default
datapool usedbysnapshots 0 -
datapool usedbydataset 35K -
datapool usedbychildren 1.00G -
datapool usedbyrefreservation 0 -
datapool logbias latency default
datapool dedup off default
datapool mlslabel none -
datapool sync standard default
datapool encryption off -
datapool keysource none default
datapool keystatus none -
datapool rekeydate - default
datapool rstchown on default
datapool shadow none -
That's a lot of properties. Each of these is described in the {{ zfs(1M) }} manual page (man zfs).
Let's look at a few examples.
ZFS dataset quotas are used to limit the amount of space consumed by a dataset and all of its children. Reservations are used to guarantee that a dataset can consume a specified amount of storage by removing that amount from the free space that the other datasets can use.
To set quotas and reservations, use the zfs set command.
# zfs set quota=2g datapool/fred
# zfs set reservation=1.5G datapool/fred
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 2.50G 5.31G 35K /datapool
datapool/bob 1.00G 5.31G 1.00G /datapool/bob
datapool/fred 159K 2.00G 32K /datapool/fred
datapool/fred/documents 127K 2.00G 34K /datapool/fred/documents
datapool/fred/documents/audio 31K 2.00G 31K /datapool/fred/documents/audio
datapool/fred/documents/pictures 31K 2.00G 31K /datapool/fred/documents/pictures
datapool/fred/documents/video 31K 2.00G 31K /datapool/fred/documents/video
datapool/joe 31K 5.31G 31K /datapool/joe
datapool/pat 31K 5.31G 31K /datapool/pat
The first thing to notice is that the available space for datapool/fred and all of its children is now 2GB, which was the quota we set with the command above. Also notice that the quota is inherited by all of the children.
The reservation is a bit harder to see.
Original pool size 7.81GB
In use by datapool/bob 1.0GB
Reservation by datapool/fred 1.5GB
So, datapool/joe should see 7.81GB - 1.0GB - 1.5GB = 5.31GB available.
With a traditional file system in operating systems, other than Oracle Solaris 11, changing a mountpoint would require:
- Unmounting the file system
- Making a new directory
- Editing /etc/vfstab
- Mounting the new file system
With ZFS it can be done with a single command. In the next example, let's move datapool/fred to a directory just called /fred.
# zfs set mountpoint=/fred datapool/fred
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 2.50G 5.31G 35K /datapool
datapool/bob 1.00G 5.31G 1.00G /datapool/bob
datapool/fred 159K 2.00G 32K /fred
datapool/fred/documents 127K 2.00G 34K /fred/documents
datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio
datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures
datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video
datapool/joe 31K 5.31G 31K /datapool/joe
datapool/pat 31K 5.31G 31K /datapool/pat
Notice that not only did it change datapool/fred, but also all of its children. In one single command. No unmounting, making directories. Just change the mountpoint.
All of these properties are preserved across exporting and importing of zpools.
# zpool export datapool
# zpool import datapool
# zfs list -r datapool
NAME USED AVAIL REFER MOUNTPOINT
datapool 2.50G 5.31G 34K /datapool
datapool/bob 1.00G 5.31G 1.00G /datapool/bob
datapool/fred 159K 2.00G 32K /fred
datapool/fred/documents 127K 2.00G 34K /fred/documents
datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio
datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures
datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video
datapool/joe 31K 5.31G 31K /datapool/joe
datapool/pat 31K 5.31G 31K /datapool/pat
Everything comes back exactly where you left it, before the export.
So far we have only looked at one type of dataset: the file system. Now let's take a look at zvols and what they do.
Volumes provide a block level (raw and cooked) interface into the zpool. Instead of creating a file system where you place files and directories, a single object is created and then accessed as if it were a real disk device. This would be used for things like raw database files, virtual machine disk images and legacy file systems. Oracle Solaris also uses this for the swap and dump devices when installed into a zpool.
# zfs list -r rpool
NAME USED AVAIL REFER MOUNTPOINT
rpool 7.91G 54.6G 39K /rpool
rpool/ROOT 6.36G 54.6G 31K legacy
rpool/ROOT/solaris 6.36G 54.6G 5.80G /
rpool/ROOT/solaris/var 467M 54.6G 226M /var
rpool/dump 516M 54.6G 500M -
rpool/export 6.49M 54.6G 33K /export
rpool/export/home 6.39M 54.6G 6.39M /export/home
rpool/export/ips 63.5K 54.6G 32K /export/ips
rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example
rpool/swap 1.03G 54.6G 1.00G -
In this example, rpool/dump is the dump device for Solaris and it 516MB. rpool/swap is the swap device and it is 1GB. As you can see, you can mix files and devices within the same pool.
Use zfs create -V to create a volume. Unlike a file system dataset, you must specific the size of the device when you create it, but you can change it later if needed. It's just another dataset property.
# zfs create -V 2g datapool/vol1
This creates two device nodes: /dev/zvol/dsk/datapool/vol1 (cooked) and /dev/zvol/rdsk/datapool/vol1 (raw). These can be used like any other raw or cooked device. We can even put a UFS file system on it.
# newfs /dev/zvol/rdsk/datapool/vol1
newfs: construct a new file system /dev/zvol/rdsk/datapool/vol1: (y/n)? y
Warning: 2082 sector(s) in last cylinder unallocated
/dev/zvol/rdsk/datapool/vol1: 4194270 sectors in 683 cylinders of 48 tracks, 128 sectors
2048.0MB in 43 cyl groups (16 c/g, 48.00MB/g, 11648 i/g)
super-block backups (for fsck -F ufs -o b=#) at:
32, 98464, 196896, 295328, 393760, 492192, 590624, 689056, 787488, 885920,
3248288, 3346720, 3445152, 3543584, 3642016, 3740448, 3838880, 3937312,
4035744, 4134176
Expanding a volume is just a matter of setting the dataset property volsize to a new value. Be careful when lowering the value as this will truncate the volume and you could lose data. In this next example, let's grow our volume from 2GB to 4GB. Since there is a UFS file system on it, we'll use growfs to make the file system use the new space.
# zfs set volsize=4g datapool/vol1
# growfs /dev/zvol/rdsk/datapool/vol1
Warning: 4130 sector(s) in last cylinder unallocated
/dev/zvol/rdsk/datapool/vol1: 8388574 sectors in 1366 cylinders of 48 tracks, 128 sectors
4096.0MB in 86 cyl groups (16 c/g, 48.00MB/g, 11648 i/g)
super-block backups (for fsck -F ufs -o b=#) at:
32, 98464, 196896, 295328, 393760, 492192, 590624, 689056, 787488, 885920,
7472672, 7571104, 7669536, 7767968, 7866400, 7964832, 8063264, 8161696,
8260128, 8358560
Like zpools, zfs can support any previous version of a dataset, meaning a dataset (and pool) can be created on an older release of Solaris and used on any newer release.
# zfs get version datapool
NAME PROPERTY VALUE SOURCE
datapool version 5 -
# zfs upgrade -v
The following filesystem versions are supported:
VER DESCRIPTION
--- --------------------------------------------------------
1 Initial ZFS filesystem version
2 Enhanced directory entries
3 Case insensitive and File system unique identifier (FUID)
4 userquota, groupquota properties
5 System attributes
For more information on a particular version, including supported releases,
see the ZFS Administration Guide.
Like in our previous zpool example, it is easy to upgrade a zfs dataset.
# zfs create -o version=2 datapool/old
# zfs get version datapool/old
NAME PROPERTY VALUE SOURCE
datapool/old version 2 -
# zfs upgrade datapool/old
1 filesystems upgraded
# zfs get version datapool/old
NAME PROPERTY VALUE SOURCE
datapool/old version 5 -
ZFS provides the ability to preserve the contents of a dataset through the use of snapshots.
# zfs snapshot datapool/bob@now
The value after the @ denotes the name of the snapshot. Any number of snapshots can be taken.
# zfs snapshot datapool/bob@just-a-bit-later
# zfs snapshot datapool/bob@even-later-still
# zfs list -r -t all datapool/bob
NAME USED AVAIL REFER MOUNTPOINT
NAME USED AVAIL REFER MOUNTPOINT
datapool/bob 1.00G 1.19G 1.00G /datapool/bob
datapool/bob@now 0 - 1.00G -
datapool/bob@just-a-bit-later 0 - 1.00G -
datapool/bob@even-later-still 0 - 1.00G -
Let's delete these snapshots so they don't get in the way of our next example.
# zfs destroy datapool/bob@even-later-still
# zfs destroy datapool/bob@just-a-bit-later
# zfs destroy datapool/bob@now
Now that we can create these point in time snapshots, we can use them to create new datasets. These are called clones. They are datasets, just like any other, but start off with the contents from the snapshot. Even more interesting, these clones only require space for the data that's different than the snapshot. That means that if 5 clones are created from a single snapshot, only 1 copy of the common data is required.
Remember that datapool/bob has a 1GB file in it? Let's snapshot it, and then clone it a few times to see this.
# zfs snapshot datapool/bob@original
# zfs clone datapool/bob@original datapool/newbob
# zfs clone datapool/bob@original datapool/newfred
# zfs clone datapool/bob@original datapool/newpat
# zfs clone datapool/bob@original datapool/newjoe
Let's use zfs list to get a better idea of what's going on.
# zfs list -r -o space datapool
NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
datapool 1.19G 6.63G 0 40K 0 6.63G
datapool/bob 1.19G 1.00G 0 1.00G 0 0
datapool/fred 2.00G 159K 0 32K 0 127K
datapool/fred/documents 2.00G 127K 0 34K 0 93K
datapool/fred/documents/audio 2.00G 31K 0 31K 0 0
datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0
datapool/fred/documents/video 2.00G 31K 0 31K 0 0
datapool/joe 1.19G 31K 0 31K 0 0
datapool/newbob 1.19G 18K 0 18K 0 0
datapool/newfred 1.19G 18K 0 18K 0 0
datapool/newjoe 1.19G 18K 0 18K 0 0
datapool/newpat 1.19G 18K 0 18K 0 0
datapool/old 1.19G 22K 0 22K 0 0
datapool/pat 1.19G 31K 0 31K 0 0
datapool/vol1 5.19G 4.13G 0 125M 4.00G 0
We can see that there's a 1GB file in datapool/bob. Right now, that's the dataset being charged with the copy, although all of the clones can use it.
Now let's delete it in the original file system, and all of the clones, and see what happens.
# rm /datapool/*/bigfile
# zfs list -r -o space datapool
NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
datapool 1.19G 6.63G 0 40K 0 6.63G
datapool/bob 1.19G 1.00G 1.00G 31K 0 0
datapool/fred 2.00G 159K 0 32K 0 127K
datapool/fred/documents 2.00G 127K 0 34K 0 93K
datapool/fred/documents/audio 2.00G 31K 0 31K 0 0
datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0
datapool/fred/documents/video 2.00G 31K 0 31K 0 0
datapool/joe 1.19G 31K 0 31K 0 0
datapool/newbob 1.19G 19K 0 19K 0 0
datapool/newfred 1.19G 19K 0 19K 0 0
datapool/newjoe 1.19G 19K 0 19K 0 0
datapool/newpat 1.19G 19K 0 19K 0 0
datapool/old 1.19G 22K 0 22K 0 0
datapool/pat 1.19G 31K 0 31K 0 0
datapool/vol1 5.19G 4.13G 0 125M 4.00G 0
Notice that the 1GB has not been freed (avail space is still 3.28G), but the USEDSNAP value for datapool/bob has gone from 0 to 1GB, indicating that the snapshot is now holding that 1GB of data. To free that space you will have to delete the snapshot. In this case you would also have to delete any clones that are derived from it.
# zfs destroy datapool/bob@original
cannot destroy 'datapool/bob@original': snapshot has dependent clones
use '-R' to destroy the following datasets:
datapool/newbob
datapool/newfred
datapool/newpat
datapool/newjoe
# zfs destroy -R datapool/bob@original
# zfs list -r -o space datapool
NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD
datapool 2.19G 5.63G 0 35K 0 5.63G
datapool/bob 2.19G 31K 0 31K 0 0
datapool/fred 2.00G 159K 0 32K 0 127K
datapool/fred/documents 2.00G 127K 0 34K 0 93K
datapool/fred/documents/audio 2.00G 31K 0 31K 0 0
datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0
datapool/fred/documents/video 2.00G 31K 0 31K 0 0
datapool/joe 2.19G 31K 0 31K 0 0
datapool/old 2.19G 22K 0 22K 0 0
datapool/pat 2.19G 31K 0 31K 0 0
datapool/vol1 6.19G 4.13G 0 125M 4.00G 0
Now the 1GB that we deleted has been freed because the last snapshot holding it has been deleted.
One last example and we'll leave snapshots. You can also take a snapshot of a dataset and all of its children. A recursive snapshot is atomic, meaning that it is a consistent point in time picture of the contents of all of the datasets. Use -r for a recursive snapshot.
# zfs snapshot -r datapool/fred@now
# zfs list -r -t all datapool/fred
NAME USED AVAIL REFER MOUNTPOINT
datapool/fred 159K 2.00G 32K /fred
datapool/fred@now 0 - 32K -
datapool/fred/documents 127K 2.00G 34K /fred/documents
datapool/fred/documents@now 0 - 34K -
datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio
datapool/fred/documents/audio@now 0 - 31K -
datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures
datapool/fred/documents/pictures@now 0 - 31K -
datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video
datapool/fred/documents/video@now 0 - 31K -
They can also be destroyed in a similar manner, using -r.
# zfs destroy -r datapool/fred@now
Compression is an interesting feature to be used with ZFS file systems. ZFS allows both compressed and noncompressed data to coexist. By turning on the compression property, all new blocks written will be compressed while the existing blocks will remain in their original state.
# zfs list datapool/bob
NAME USED AVAIL REFER MOUNTPOINT
datapool/bob 31K 2.19G 31K /datapool/bob
# mkfile 1g /datapool/bob/bigfile
# zfs list datapool/bob
NAME USED AVAIL REFER MOUNTPOINT
datapool/bob 1010M 1.20G 1010M /datapool/bob
Now let's turn on compression for datapool/bob and copy the original 1GB file. Verify that you now have 2 separate 1GB files when this is done.
# zfs set compression=on datapool/bob
# cp /datapool/bob/bigfile /datapool/bob/bigcompressedfile
# ls -la /datapool/bob
total 2097450
drwxr-xr-x 2 root root 4 Nov 22 04:29 .
drwxr-xr-x 6 root root 6 Nov 22 04:26 ..
-rw------- 1 root root 1073741824 Nov 22 04:29 bigcompressedfile
-rw------T 1 root root 1073741824 Nov 22 04:28 bigfile
# zfs list datapool/bob
NAME USED AVAIL REFER MOUNTPOINT
datapool/bob 1.00G 1.19G 1.00G /datapool/bob
There are now 2 different 1GB files in /datapool/bob, but df only says 1GB is used. It turns out that mkfile creates a file filled with zeroes. Those compress extremely well - too well, as they take up no space at all. To make things even more fun, copy the compressed file back on top of the original and they will both be compressed, and you'll get an extra 1GB of free space back in the pool.
# cp /datapool/bob/bigcompressedfile /datapool/bob/bigfile
# zfs list datapool/bob
NAME USED AVAIL REFER MOUNTPOINT
datapool/bob 31K 2.19G 31K /datapool/bob
Let's clean up before proceeding.
# zpool destroy datapool
Exercise 3: ZFS Integration with other parts of Solaris
In this section, we will explore a few examples of Solaris services that are integrated with ZFS. The first of these is the NFS server.
Each file system dataset has a property called sharenfs. This can be set to the values that you would typically place in /etc/dfs/dfstab. See the manual page for share_nfs for details on specific settings.
Create a simple pool called datapool with 3 datasets, fred, barney and dino.
# zpool create datapool c4t0d0
# zfs create datapool/fred
# zfs create datapool/barney
# zfs create datapool/dino
Verify that no file systems are shared and that the NFS server is not running.
# share
# svcs nfs/server
STATE STIME FMRI
disabled 12:47:45 svc:/network/nfs/server:default
NOTE: Setting NFS properties has been changed in Oracle Solaris 11 comparing to earlier Oracle Solaris versions, see man zfs_share for details.
Now let's set a few properties to enable sharing the filesystem over NFS:
# zfs set share=name=fred,path=/datapool/fred,prot=nfs,ro=* datapool/fred
name=fred,path=/datapool/fred,prot=nfs,sec=sys,ro=*
# zfs set share=name=barney,path=/datapool/barney,prot=nfs,rw=* datapool/barney
# zfs set sharenfs=on datapool/fred
# zfs set sharenfs=on datapool/barney
# share
fred /datapool/fred nfs sec=sys,ro
barney /datapool/barney nfs sec=sys,rw
# svcs nfs/server
STATE STIME FMRI
online 2:25:12 svc:/network/nfs/server:default
Not only were the file systems shared via NFS, the NFS server is now running.
Now let's export the pool and notice that the NFS shares have gone away, but the NFS server is still running.
# zpool export datapool
# share
# svcs nfs/server
STATE STIME FMRI
online 13:08:42 svc:/network/nfs/server:default
Notice that when the pool is imported, the NFS shares come back.
# zpool import datapool
# share
fred /datapool/fred nfs sec=sys,ro
barney /datapool/barney nfs sec=sys,rw
Let's clean up before proceeding.
# zpool destroy datapool
This is the most fun part of the ZFS hands on lab. In this part of the lab we are going to create a mirrored pool and place some data in it. We will then force some data corruption by doing some really dangerous things to the underlying storage. Once we've done this, we will watch ZFS correct all of the errors.
# zpool create datapool mirror disk1 disk2 spare disk3
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
spares
disk3 AVAIL
Notice the new vdev type of spare. This is used to designate a set of devices to be used as a spare in case too many errors are reported on a device in a data vdev.
Now let's put some data in the new pool. /usr/share/man is a good source of data. The snyc command simply flushes the file system buffers so the following disk space usage command will be accurate.
# cp -r /usr/share/man /datapool
# sync
# df -h /datapool
Filesystem Size Used Avail Use% Mounted on
datapool 460M 73M 388M 16% /datapool
Let's destroy one of the mirror halves, and see what ZFS does about it.
# dd if=/dev/zero of=/dev/dsk/disk1 bs=1024k count=100 conv=notrunc
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 2.23626 s, 46.9 MB/s
# zpool scrub datapool
# zpool status datapool
pool: datapool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Tue Apr 19 13:18:52 2011
46.6M scanned out of 72.8M at 4.24M/s, 0h0m to go
46.5M resilvered, 64.01% done
config:
NAME STATE READ WRITE CKSUM
datapool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
spare-0 DEGRADED 0 0 0
disk1 DEGRADED 0 0 14.6K too many errors
disk3 ONLINE 0 0 0 (resilvering)
disk2 ONLINE 0 0 0
spares
disk3 INUSE currently in use
errors: No known data errors
Since the data errors were injected silently, we had to tell ZFS to compare all of the replicas. zpool scrub does exactly that. When it finds an error, it generates an FMA error report and then tries to correct the error by rewriting the block, and reading it again. If too many errors are occuring, or the rewrite/reread cycle still fail, a hot spare is requested, if available. Notice that the hot spare is automatically resilvered and the pool is returned to the desired availability.
This can also be seen in the FMA error and fault reports.
# fmstat
module ev_recv ev_acpt wait svc_t %w %b open solve memsz bufsz
cpumem-retire 0 0 0.0 5.8 0 0 0 0 0 0
disk-transport 0 0 0.0 1954.1 0 0 0 0 32b 0
eft 431 0 0.0 32.4 0 0 0 0 1.3M 0
ext-event-transport 1 0 0.0 15.8 0 0 0 0 46b 0
fabric-xlate 0 0 0.0 6.1 0 0 0 0 0 0
fmd-self-diagnosis 183 0 0.0 3.8 0 0 0 0 0 0
io-retire 0 0 0.0 6.0 0 0 0 0 0 0
sensor-transport 0 0 0.0 201.8 0 0 0 0 32b 0
ses-log-transport 0 0 0.0 196.3 0 0 0 0 40b 0
software-diagnosis 0 0 0.0 5.8 0 0 0 0 316b 0
software-response 0 0 0.0 6.1 0 0 0 0 316b 0
sysevent-transport 0 0 0.0 3527.4 0 0 0 0 0 0
syslog-msgs 1 0 0.0 220.9 0 0 0 0 0 0
zfs-diagnosis 4881 4843 0.6 11.0 1 0 1 1 184b 140b
zfs-retire 29 0 0.0 433.3 0 0 0 0 8b 0
The zfs-diagnosis module was invoked each time an ZFS error was discovered. Once an unsatisfactory error threshold was reached, the zfs-retire agent was called to record the fault and start the hot sparing process. An error log message was written (syslog-msgs > 0).
Now let's put things back the way they were.
# zpool detach datapool disk1
# zpool replace datapool disk3 disk1
# zpool status datapool
pool: datapool
state: ONLINE
scan: resilvered 72.6M in 0h0m with 0 errors on Tue Apr 19 13:21:42 2011
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
errors: No known data errors
# zpool add datapool spare disk3
If you would like some more fun, try corrupting both halves of the mirror, and see what happens.
Summary
Congratulations! You have successfully completed the lab Introduction to the Oracle Solaris ZFS File System.
For additional information about the technologies used in this lab, please see the following links:
https://www.oracle.com/docs/tech/solclassbyitsel.pdf (PDF)
You can contact the lab author directly at: bob.netherton@oracle.com
Thank you for participating!