 System Admins and Developers
Hands-On Labs
System Admins and Developers
Hands-On Labs
ラボ:Oracle Solaris 11 ZFSファイル・システムの概要
Oracle Solaris ZFSは、オープン・システムのストレージ割当てに関する見方を一変させる画期的なファイル・システムです。このセッションは、Oracle Solaris ZFSの基本を学習するハンズオン・チュートリアルです。デバイスがストレージ・プールにおいてどのように使用されるかを説明し、パフォーマンスや可用性にも言及します。 また、作成可能な各種のOracle Solaris ZFSデータセットと、それぞれのデータセットをどのような場合に使用するかについても説明します。さらに、ファイル・システムのスナップショット、データのクローニング、制限の割当て、一般的なエラーからのリカバリについて学習します。
以下の演習では、いくつかのzpoolを作成し、各種の仮想デバイス(vdev)について検討します。また、2つの異なる種類のZFSデータセット、ファイル・システム、およびボリュームを作成します。一部のプロパティをカスタマイズし、それらのスナップショットおよびクローンを作成し、最後に、いくつかのアップグレードを実行します。後半のセクションでは、NFS(ネットワーク・ファイル・システム)やFMA(障害管理アーキテクチャ)といったその他のOracle SolarisサービスがZFSとどのように結び付くのかという点についても学習します。
これらの演習では、可能性の一部を紹介することを意図しています。ZFSの他の機能についても、マニュアル・ページを参照したり、自発的な支援者のグループに質問したりして、ぜひ調べてみてください。
ラボでの作業
| 作業 | 予想所要時間 | 演習 |
|---|---|---|
| ラボの概要 | 5分間 | なし |
| プールの操作 | 15分間 | あり |
| ファイル・システムの操作 | 20分間 | あり |
| エラーの処理とリカバリ | 10分間 | あり |
ラボの概要
このラボでは、すべての演習にVirtualBoxゲストを使用します。各演習の内容に合わせて、フラット・ファイルと仮想ディスクを組み合わせて使用します。作業を開始する前に、ここで、構成について簡単に説明します。
| デバイス | 使用方法 |
|---|---|
| ディスク | c1t0d0 - Solarisのルート・ファイル・システム(rpool) |
| c4t1d0 - ZFS用の8GBのデータ・ディスク | |
| c4t1d0 - ZFS用の8GBのデータ・ディスク | |
| フラット・ファイル(それぞれ500MB) | /dev/dsk/disk1 |
| /dev/dsk/disk2 | |
| /dev/dsk/disk3 | |
| /dev/dsk/disk4 |
ラボのセットアップ
このラボを開始する前に、ラボ:Oracle Solaris 11のOracle VM VirtualBoxへのインストールを完了している必要があります。
また、このラボ全体を通じて使用する2つの8GBの仮想ディスクをVirtualBoxゲストに追加する必要があります。
Solaris仮想マシンが動作している場合は、停止してください。
VirtualBoxで、OracleSolaris11_11-11マシンの設定を選択し、左にある「Storage」カテゴリを選択します。次に、コントローラ追加アイコンを選択して、SASコントローラを追加します。
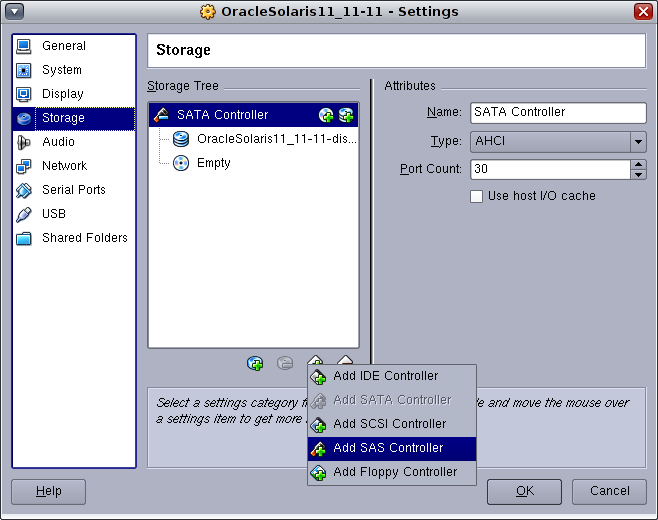
新しいディスクをSASコントローラに追加するアイコンをクリックします。
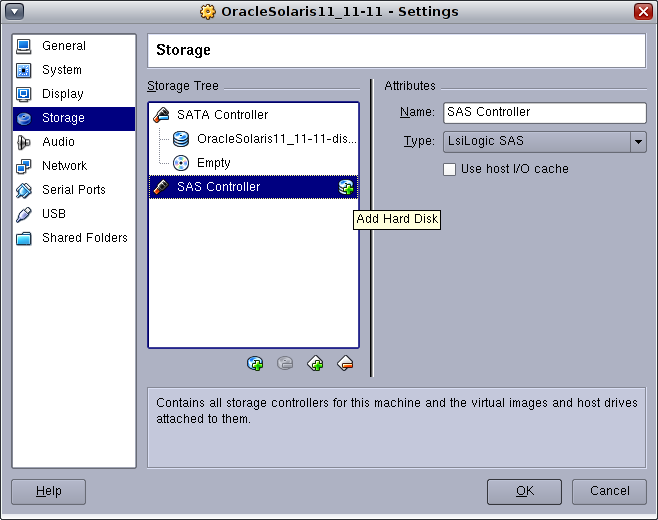
新しいディスクを作成します。
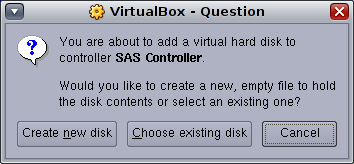
これにより、Create New Virtual Diskウィザードが起動します。
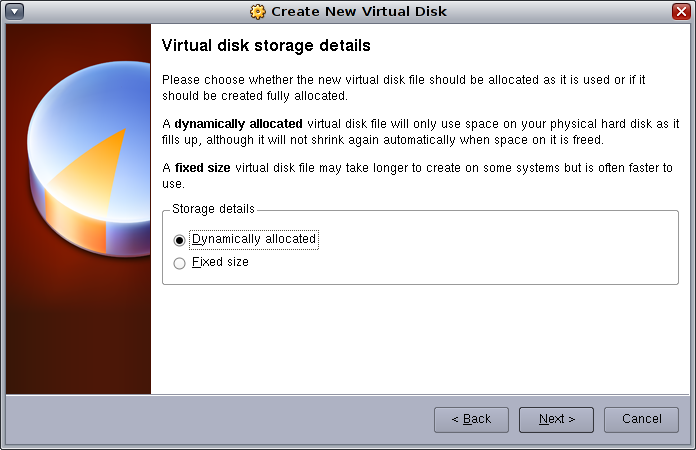
「Next」をクリックします。デフォルトの動的に拡張されるストレージ・タイプを使用します。
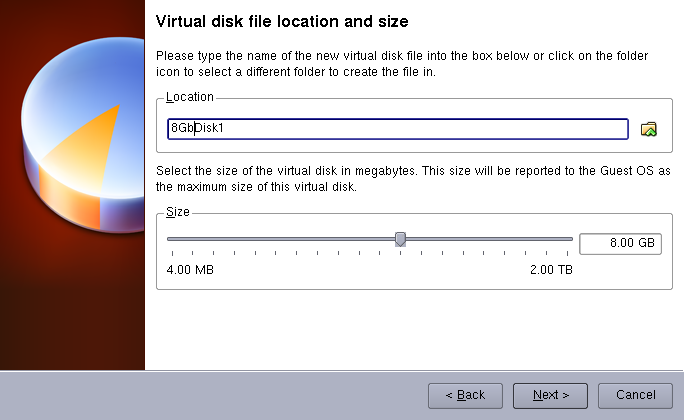
「Next」をクリックします。ディスクの名前を8GDisk1.vdiに設定します。サイズは8GBに設定します。
「Next」をクリックします。
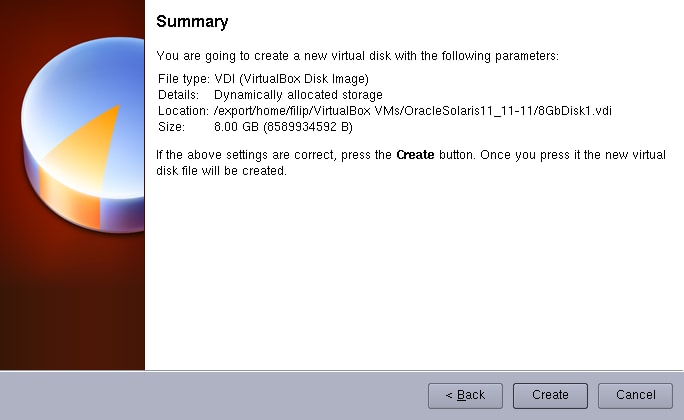
「Create」をクリックします。
上記の手順を繰り返して、8GDisk2という名前の2つ目のディスクを作成します。
Solaris VMを起動します。
この対話型のラボでは、GNOMEターミナル・ウィンドウを使用します。 ログインしたら、ターミナル・ウィンドウを開いて、rootユーザーになります。rootパスワードは、Oracle Solaris 11 VMアプライアンスをOracle VM VirtualBoxにインポートしたときに定義したパスワードです。
oracle@solaris:~$ su - Password: <root password> Oracle Corporation SunOS 5.11 11.0 November 2011 root@solaris:~#
formatを実行し、デバイス名をメモします(デバイス名はこのラボで使用する例と異なる場合があります)。
# format < /dev/null
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c3t0d0 <ATA-VBOX HARDDISK-1.0 cyl 8351 alt 2 hd 255 sec 63>
/pci@0,0/pci8086,2829@d/disk@0,0
1. c4t0d0 <VBOX-HARDDISK-1.0-8.00GB>
/pci@0,0/pci1000,8000@16/sd@0,0
2. c4t1d0 <VBOX-HARDDISK-1.0-8.00GB>
/pci@0,0/pci1000,8000@16/sd@1,0
Specify disk (enter its number):
これで、ラボの演習を開始する準備が整いました。
演習1:プールの操作
ZFSファイル・システムでは、ストレージ・デバイスが、zpoolと呼ばれるプールにグループ化されます。 これらのプールは、プールから割り当てられるファイル・システムおよびボリュームによって使用されるすべてのストレージ割当てを提供します。 まずは、datapoolという簡単なzpoolを作成しましょう。
最初に、いくつかのストレージ・デバイスが必要です。4つのファイルを作成し、それらを最初のプールに使用します。
# mkfile 500m /dev/dsk/disk1 # mkfile 500m /dev/dsk/disk2 # mkfile 500m /dev/dsk/disk3 # mkfile 500m /dev/dsk/disk4
プールの作成と破棄
では、最初のプールを作成しましょう。
# zpool create datapool raidz disk1 disk2 disk3 disk4
ここで必要なことは、これだけです。zpool statusコマンドを使用して、次のように最初のプールを調べることができます。
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
disk3 ONLINE 0 0 0
disk4 ONLINE 0 0 0
この出力から、datapoolという新しいプールにraidz1-0という1つのZFS仮想デバイス(vdev)があることが分かります。このvdevは、前の手順で作成した4つのディスク・ファイルで構成されます。
このタイプのvdevは、単一デバイス・パリティ保護を提供します。つまり、1つのデバイスでエラーが発生しても、残りのディスク・デバイスを使用してデータが再構築されるため、データが失われません。 この編成は、一般に、3+1と呼ばれます。3つのデータ・ディスクと1つのパリティという意味です。
ZFSで提供される可用性には、他に、raidz2(2デバイス保護)、raidz3(3デバイス保護)、ミラー化、および未保護があります。 これらの一部については、後の演習で説明します。
先に進む前に、現在マウントされているファイル・システムを確認しておきましょう。
注:Oracle Solaris 11では、zfs listコマンドにより、ZFSファイル・システムが消費する容量が示されます。ZFS以外のファイル・システム(NFSまたはその他のプロトコルを使用してネットワーク経由でマウントされているファイル・システムなど)で使用できる容量を確認するために、Oracle Solaris 11では、従来のdf(1)コマンドも使用できます。df(1)を使い慣れているシステム管理者は引き続きdf(1)を使用することもできますが、ZFSファイル・システムについてはzfs listを使用することを推奨します。
# zfs list NAME USED AVAIL REFER MOUNTPOINT datapool 97.2K 1.41G 44.9K /datapool rpool 7.91G 54.6G 39K /rpool rpool/ROOT 6.36G 54.6G 31K legacy rpool/ROOT/solaris 6.36G 54.6G 5.80G / rpool/ROOT/solaris/var 467M 54.6G 226M /var rpool/dump 516M 54.6G 500M - rpool/export 6.52M 54.6G 33K /export rpool/export/home 6.42M 54.6G 6.39M /export/home rpool/export/home/oracle 31K 54.6G 31K /export/home/oracle rpool/export/ips 63.5K 54.6G 32K /export/ips rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example rpool/swap 1.03G 54.6G 1.00G -
プールを作成したときに、ZFSによって最初のファイル・システムも作成され、マウントされていることに注意してください。 デフォルトのマウント・ポイントはプール名によって作成されますが、必要に応じて変更できます。ZFSでは、ファイル・システムを作成したり、ファイル・システムをマウントするディレクトリを作成したりする必要はありません。また、/etc/vfstabへのエントリの追加も不要です。これらはすべて、プールの作成時に実行されます。このため、ZFSは、従来のファイル・システムに比べて非常に使いやすくなっています。
他のタイプのvdevを見る前に、datapoolを破棄して、何が起こるか確認しましょう。
# zpool destroy datapool # zfs list NAME USED AVAIL REFER MOUNTPOINT rpool 7.91G 54.6G 39K /rpool rpool/ROOT 6.36G 54.6G 31K legacy rpool/ROOT/solaris 6.36G 54.6G 5.80G / rpool/ROOT/solaris/var 467M 54.6G 226M /var rpool/dump 516M 54.6G 500M - rpool/export 6.52M 54.6G 33K /export rpool/export/home 6.42M 54.6G 6.39M /export/home rpool/export/home/oracle 31K 54.6G 31K /export/home/oracle rpool/export/ips 63.5K 54.6G 32K /export/ips rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example rpool/swap 1.03G 54.6G 1.00G -
プール内のすべてのファイル・システムがアンマウントされ、プールが破棄されています。vdevに含まれていたデバイスも解放されており、それらのデバイスを再度使用できます。
ここで、raidzの代わりに2つの方法のミラー化を使用して簡単なプールを作成しましょう。
# zpool create datapool mirror disk1 disk2
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
errors: No known data errors
ここでは、vdev名がmirror-0に変更されています。これは、最初の例にあるようにパリティではなく、ミラー化(データの冗長コピー)によってデータが冗長化されていることを示しています。
別のプールですでに使用されているディスク・デバイスを使用しようとすると、どうなるでしょうか。実際にやってみましょう。
# zpool create datapool2 mirror disk1 disk2 invalid vdev specification use '-f' to override the following errors: /dev/dsk/disk1 is part of active pool 'datapool'
この使用エラーは、/dev/dsk/disk1がdatapoolという既存のプールの一部であると判断されたことを示しています。 zpool createコマンドで-fフラグを使用すると、datapoolが不用になった場合にフェイルセーフを無効化できますが、このオプションは慎重に使用してください。
プールへの容量の追加
2つの追加ディスク・デバイス(disk3とdisk4)があるので、ZFSプールをいかに簡単に拡張できるか見てみましょう。
# zpool list datapool
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
datapool 492M 89.5K 492M 0% 1.00x ONLINE -
# zpool add datapool mirror disk3 disk4
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
disk3 ONLINE 0 0 0
disk4 ONLINE 0 0 0
errors: No known data errors
2つ目のvdev(mirror-1)がプールに追加されていることを確認してください。 ここで、zpoolの詳細を表示しましょう。
# zpool list datapool NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT datapool 984M 92.5K 984M 0% 1.00x ONLINE -
プールが500MBから1GBに拡張されています。
# zfs list datapool NAME USED AVAIL REFER MOUNTPOINT datapool 91K 952M 31K /datapool
プールの容量を増加させるときにファイル・システムを拡張する必要がないことに注意してください。ファイル・システムは、割当て制限(後の演習で説明します)に従い、プール内の使用可能なすべての領域を使用できます。
プールのインポートとエクスポート
ZFSのzpoolは、エクスポートすることもできます。これにより、データと関連する構成情報のすべてを、システム間で移動することができます。例として、2つのSASディスク(c4t0d0とc4t1d0)を使用しましょう。
# zpool create pool2 mirror c4t0d0 c4t1d0
# zpool status pool2
pool: pool2
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
pool2 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
c4t0d0 ONLINE 0 0 0
c4t1d0 ONLINE 0 0 0
errors: No known data errors
前のとおりに、ミラー化された簡単なプールを持つ2つのディスクが作成されています。この場合のディスク・デバイスは、ファイルではなく、実際のディスクです。今回はディスク全体を使用するようにZFSに指示しています(スライス番号が含まれていません)。ディスクにラベルが付けられていない場合、ZFSはデフォルトのラベルを作成します。
ここで、別のシステムで使用できるようにpool2をエクスポートしましょう。
# zpool list NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT datapool 984M 92.5K 984M 0% 1.00x ONLINE - pool2 7.94G 83.5K 7.94G 0% 1.00x ONLINE - rpool 19.9G 6.18G 13.7G 31% 1.00x ONLINE - # zpool export pool2 # zpool list NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT datapool 984M 92.5K 984M 0% 1.00x ONLINE - rpool 19.9G 6.19G 13.7G 31% 1.00x ONLINE -
では、ZFSのもう一つの使いやすい機能を使用して、プールをインポートしましょう。
# zpool import pool2 # zpool list NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT datapool 984M 92.5K 984M 0% 1.00x ONLINE - pool2 7.94G 132K 7.94G 0% 1.00x ONLINE - rpool 19.9G 6.19G 13.7G 31% 1.00x ONLINE -
ディスクのある場所をZFSに対して示す必要がないことに注意してください。ZFSにプール名を示すだけで実行されます。デバイス名が変更されていても、ZFSは、使用可能なすべてのディスク・デバイスを調べて、プールを再構築します。
プール名が分からない場合は、どうでしょうか。 この場合も、ZFSが補助します。
# zpool export pool2
# zpool import
pool: pool2
id: 12978869377007843914
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
pool2 ONLINE
mirror-0 ONLINE
c4t0d0 ONLINE
c4t1d0 ONLINE
# zpool import pool2
引数がない場合、ZFSは、システムに接続されているすべてのディスクを調べて、インポート可能なプール名のリストを表示します。 同じ名前のプールが2つある場合は、一意の識別子を使用して、インポートするプールを選択できます。
プールのプロパティ
プールには、環境に合わせてカスタマイズできる多数のプロパティがあります。 これらのプロパティのリストを表示するには、zpool getを使用します。
# zpool get all pool2 NAME PROPERTY VALUE SOURCE datapool size 7.94G - datapool capacity 0% - datapool altroot - default datapool health ONLINE - datapool guid 18069440062221314300 - datapool version 33 default datapool bootfs - default datapool delegation on default datapool autoreplace off default datapool cachefile - default datapool failmode wait default datapool listsnapshots off default datapool autoexpand off default datapool dedupditto 0 default datapool dedupratio 1.00x - datapool free 7.94G - datapool allocated 216K - datapool readonly off
これらのプロパティの説明はすべて、zpool(1M)のマニュアル・ページに記載されています。詳しくは、man zpoolと入力して、表示されるマニュアル・ページを参照してください。 プールのプロパティを設定するには、zpool setを使用します。変更できないプロパティ(version、free、allocatedなど)もあることに注意してください。
# zpool set listsnapshots=on pool2 # zpool get listsnapshots pool2 NAME PROPERTY VALUE SOURCE pool2 listsnapshots on local
プールのアップグレード
この演習を終了する前に、あと1つだけzpoolのプロパティを説明します。それは、versionです。今回の場合、zpoolのバージョン番号は31です。 このバージョンで提供される機能を確認するには、zpool upgrade -vを使用します。
# zpool upgrade -v This system is currently running ZFS pool version 33. The following versions are supported: VER DESCRIPTION --- -------------------------------------------------------- 1 Initial ZFS version 2 Ditto blocks (replicated metadata) 3 Hot spares and double parity RAID-Z 4 zpool history 5 Compression using the gzip algorithm 6 bootfs pool property 7 Separate intent log devices 8 Delegated administration 9 refquota and refreservation properties 10 Cache devices 11 Improved scrub performance 12 Snapshot properties 13 snapused property 14 passthrough-x aclinherit 15 user/group space accounting 16 stmf property support 17 Triple-parity RAID-Z 18 Snapshot user holds 19 Log device removal 20 Compression using zle (zero-length encoding) 21 Deduplication 22 Received properties 23 Slim ZIL 24 System attributes 25 Improved scrub stats 26 Improved snapshot deletion performance 27 Improved snapshot creation performance 28 Multiple vdev replacements 29 RAID-Z/mirror hybrid allocator 30 Encryption 31 Improved 'zfs list' performance 32 One MB blocksize 33 Improved share support For more information on a particular version, including supported releases, see the ZFS Administration Guide.
Oracle Solarisにパッチを適用したり、Oracle Solarisをアップグレードしたりすると、新しいバージョンのzpoolが使用可能になる場合があります。 既存のプールをアップグレードして新しい機能を追加することは簡単です。 これを実行するために、まず、古いバージョン番号を使用してプールを作成し(このようなことも可能です)、次に、プールをアップグレードしましょう。
# zpool destroy pool2 # zpool create -o version=17 pool2 mirror c4t0d0 c4t1d0 # zpool upgrade pool2 This system is currently running ZFS pool version 33. Successfully upgraded 'pool2' from version 17 to version 33
以上で、この演習は終了です。zpoolのアップグレードよりも複雑なものはありません。 これで、新しいバージョンのzpoolが持つ機能(log device removal (19)、snapshot user holds (18)など)を使用できるようになりました。
ただし、このプールは、33よりも古いバージョンのzpoolを実行するシステムにはインポートできなくなっていることに注意してください。
zpoolの操作は完了です。できることは他にも数多くあります。詳しくは、zpoolのマニュアル・ページ(man zpool)を参照してください。支援が必要な場合は、ラボのアシスタントに要請してください。
では、次に進む前に、クリーンアップしておきましょう。
# zpool destroy pool2 # zpool destroy datapool
演習2:データセット(ファイル・システム、ボリューム)の操作
ZFS zpoolの管理方法を学習したので、次は、ファイル・システムについて学習します。zpoolは、従来のようなファイル・システムによる方法だけではなく、さまざまなタイプのアクセスを提供できるため、データセットという用語が使用されます。
前の演習で説明したように、zpoolの作成時にデフォルトのデータセット(ファイル・システム)が自動的に作成されます。 他のファイル・システムやボリューム・マネージャとは異なり、ZFSは、階層的なデータセット(ピア、親、子)を提供します。このため、単一のプールで多数のストレージを選択できるようになります。
ZFSデータセットは、zfs(1M)コマンドを使用して作成、破棄、および管理されます。 詳しくは、man zfsと入力することによって表示される関連マニュアル・ページを参照してください。
データセットの操作を開始するために、もう一度datapoolという簡単なプールと、bob、joe、fred、patという4つの追加データセットを作成しましょう。
# zpool create datapool mirror c4t0d0 c4t1d0 # zfs create datapool/bob # zfs create datapool/joe # zfs create datapool/fred # zfs create datapool/pat
zfs listを使用して、すべてのZFSデータセットに関する基本情報を確認できます。
# zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 238K 7.81G 35K /datapool datapool/bob 31K 7.81G 31K /datapool/bob datapool/fred 31K 7.81G 31K /datapool/fred datapool/joe 31K 7.81G 31K /datapool/joe datapool/pat 31K 7.81G 31K /datapool/pa
zfs list -r datapoolを使用して、datapoolというプールに含まれるすべてのデータセットのリストを表示します。 前の演習のように、これらのデータセット(ファイル・システム)はすべて、自動的にマウントされています。
これが従来のファイル・システムであれば、「datapoolとその4つのデータセットに使用できる容量は39.05GB(7.81GB x 5)あるがプールの容量のうち8GBはすべてのデータセットで共有される」ということを考慮しながら作業することになります。 では、動作を確認しましょう。
# mkfile 1024m /datapool/bob/bigfile # zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 1.00G 6.81G 35K /datapool datapool/bob 1.00G 6.81G 1.00G /datapool/bob datapool/fred 31K 6.81G 31K /datapool/fred datapool/joe 31K 6.81G 31K /datapool/joe datapool/pat 31K 6.81G 31K /datapool/pat
USED列に、datapool/bobで1GBが使用中であると示されていることに注意してください。他のデータセットではメタデータ・オーバーヘッド(21K)のみが示されていますが、使用可能領域は6.81GBに減少しています。これは、datapool/bobが1GBの容量を消費した後にその容量が使用可能な空き領域であるためです。
階層型のデータセット
ディレクトリがサブディレクトリを持つように、データセットは子データセットを持つことができます。 datapool/fredにドキュメント用のデータセット(documents)を作成し、そのデータセットの下に画像(pictures)、動画(video)、音声(audio)用の追加データセットを作成しましょう。
# zfs create datapool/fred/documents # zfs create datapool/fred/documents/pictures # zfs create datapool/fred/documents/video # zfs create datapool/fred/documents/audio # zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 1.00G 6.81G 35K /datapool datapool/bob 1.00G 6.81G 1.00G /datapool/bob datapool/fred 159K 6.81G 32K /datapool/fred datapool/fred/documents 127K 6.81G 34K /datapool/fred/documents datapool/fred/documents/audio 31K 6.81G 31K /datapool/fred/documents/audio datapool/fred/documents/pictures 31K 6.81G 31K /datapool/fred/documents/pictures datapool/fred/documents/video 31K 6.81G 31K /datapool/fred/documents/video datapool/joe 31K 6.81G 31K /datapool/joe datapool/pat 31K 6.81G 31K /datapool/pat
ZFSデータセットのプロパティ
一般に、サブディレクトリを作成するのは、どのような場合でしょうか。また、一般に、データセットを使用するのは、どのような場合でしょうか。その答えは、「親データセットと子データセットの間でZFSデータセットのプロパティを変更する場合に、新しいデータセットを作成する」という簡単なものです。プロパティはデータセットに適用されるため、あるデータセット内のすべてのディレクトリは同じプロパティを持ちます。いずれかのプロパティ(quotaなど)を変更する場合に、子データセットを作成する必要があります。
ZFSデータセットのプロパティをいくつか見てみましょう。
# zfs get all datapool NAME PROPERTY VALUE SOURCE datapool type filesystem - datapool creation Tue Nov 22 3:28 2011 - datapool used 1.00G - datapool available 6.81G - datapool referenced 35K - datapool compressratio 1.00x - datapool mounted yes - datapool quota none default datapool reservation none default datapool recordsize 128K default datapool mountpoint /datapool default datapool sharenfs off default datapool checksum on default datapool compression off default datapool atime on default datapool devices on default datapool exec on default datapool setuid on default datapool readonly off default datapool zoned off default datapool snapdir hidden default datapool aclmode discard default datapool aclinherit restricted default datapool canmount on default datapool xattr on default datapool copies 1 default datapool version 5 - datapool utf8only off - datapool normalization none - datapool casesensitivity mixed - datapool vscan off default datapool nbmand off default datapool sharesmb off default datapool refquota none default datapool refreservation none default datapool primarycache all default datapool secondarycache all default datapool usedbysnapshots 0 - datapool usedbydataset 35K - datapool usedbychildren 1.00G - datapool usedbyrefreservation 0 - datapool logbias latency default datapool dedup off default datapool mlslabel none - datapool sync standard default datapool encryption off - datapool keysource none default datapool keystatus none - datapool rekeydate - default datapool rstchown on default datapool shadow none -
このように多数のプロパティがあります。各プロパティの説明については、{{ zfs(1M) }}のマニュアル・ページ(man zfs)を参照してください。
いくつかの例を見てみましょう。
quotaとreservation
ZFSデータセットのquotaプロパティは、データセットとそのすべての子データセットが消費する領域の総容量を制限するために使用されます。 reservationプロパティは、指定されたストレージ容量をデータセットが消費できることを保証するために使用されます。このために、他のデータセットが使用できる空き容量から、その分の容量が差し引かれます。
quotaとreservationを設定するには、zfs setコマンドを使用します。
# zfs set quota=2g datapool/fred # zfs set reservation=1.5G datapool/fred # zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 2.50G 5.31G 35K /datapool datapool/bob 1.00G 5.31G 1.00G /datapool/bob datapool/fred 159K 2.00G 32K /datapool/fred datapool/fred/documents 127K 2.00G 34K /datapool/fred/documents datapool/fred/documents/audio 31K 2.00G 31K /datapool/fred/documents/audio datapool/fred/documents/pictures 31K 2.00G 31K /datapool/fred/documents/pictures datapool/fred/documents/video 31K 2.00G 31K /datapool/fred/documents/video datapool/joe 31K 5.31G 31K /datapool/joe datapool/pat 31K 5.31G 31K /datapool/pat
まず、datapool/fredとその子データセットの使用可能領域が2GBになっていることに注意してください。これは、上記のコマンドで設定したquotaです。 また、このquotaがすべての子データセットによって継承されていることにも注意してください。
reservationは少し分かりにくいですが、以下のようになっています。
元のプールのサイズは7.81GB
datapool/bobが使用中の容量は1.0GB
datapool/fredの予約容量(reservation)は1.5GB
このため、datapool/joeの使用可能領域が5.31GB(7.81GB - 1.0GB - 1.5GB = 5.31GB)になります。
マウント・ポイントの変更
Oracle Solaris 11以外のオペレーティング・システムで使用されている従来のファイル・システムでは、マウント・ポイントを変更するために以下の作業を行う必要があります。
- ファイル・システムのアンマウント
- 新しいディレクトリの作成
- /etc/vfstabの編集
- 新しいファイル・システムのマウント
ZFSでは、1つのコマンドで実行できます。 次の例で、datapool/fredを単に/fredというディレクトリに移動しましょう。
# zfs set mountpoint=/fred datapool/fred # zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 2.50G 5.31G 35K /datapool datapool/bob 1.00G 5.31G 1.00G /datapool/bob datapool/fred 159K 2.00G 32K /fred datapool/fred/documents 127K 2.00G 34K /fred/documents datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video datapool/joe 31K 5.31G 31K /datapool/joe datapool/pat 31K 5.31G 31K /datapool/pat
datapool/fredだけでなくそのすべての子データセットについても変更されていることに注意してください。1つのコマンドを1回実行するだけで完了します。ディレクトリをアンマウントしたり、作成したりする必要はなく、マウント・ポイントを変更するだけです。
これらのプロパティはすべて、zpoolのエクスポートおよびインポートでも保持されます。
# zpool export datapool # zpool import datapool # zfs list -r datapool NAME USED AVAIL REFER MOUNTPOINT datapool 2.50G 5.31G 34K /datapool datapool/bob 1.00G 5.31G 1.00G /datapool/bob datapool/fred 159K 2.00G 32K /fred datapool/fred/documents 127K 2.00G 34K /fred/documents datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video datapool/joe 31K 5.31G 31K /datapool/joe datapool/pat 31K 5.31G 31K /datapool/pat
すべてのものが、エクスポート前とまったく同じ状態になっています。
ZFSボリューム(zvol)
ここまでは、1つの種類のデータセット、つまりファイル・システムについてのみ説明してきました。ここでは、zvolとその動作について説明します。
これらのボリュームは、zpoolにブロック・レベル(RAWおよび構成済み)のインタフェースを提供します。ファイルやディレクトリを配置するファイル・システムを作成する代わりに、実際のディスク・デバイスのように、単一のオブジェクトが作成され、アクセスされます。このボリュームは、RAWデータベース・ファイル、仮想マシン・ディスク・イメージ、従来のファイル・システムなどのために作成されます。 Oracle Solarisでは、このボリュームを、zpoolにインストールする場合のスワップ・デバイスおよびダンプ・デバイスにも使用します。
# zfs list -r rpool NAME USED AVAIL REFER MOUNTPOINT rpool 7.91G 54.6G 39K /rpool rpool/ROOT 6.36G 54.6G 31K legacy rpool/ROOT/solaris 6.36G 54.6G 5.80G / rpool/ROOT/solaris/var 467M 54.6G 226M /var rpool/dump 516M 54.6G 500M - rpool/export 6.49M 54.6G 33K /export rpool/export/home 6.39M 54.6G 6.39M /export/home rpool/export/ips 63.5K 54.6G 32K /export/ips rpool/export/ips/example 31.5K 54.6G 31.5K /export/ips/example rpool/swap 1.03G 54.6G 1.00G -
この例で、rpool/dumpは、Solarisのダンプ・デバイスであり、その容量は516MBです。rpool/swapは、スワップ・デバイスであり、その容量は1GBです。 ここに表示されているように、ファイルとデバイスを同じプールに混在させることができます。
ボリュームを作成するには、zfs create -Vを使用します。 ファイル・システム・データセットとは異なり、作成時にデバイスのサイズを指定する必要がありますが、このサイズは後で必要に応じて変更できます。 これだけが、別のデータセット・プロパティです。
# zfs create -V 2g datapool/vol1
これにより、/dev/zvol/dsk/datapool/vol1(構成済み)と/dev/zvol/rdsk/datapool/vol1(RAW)という2つのデバイス・ノードが作成されます。 これらのボリュームは、他のRAWデバイスや構成済みデバイスと同様に使用できます。 これらのボリュームにUFSファイル・システムを配置することもできます。
# newfs /dev/zvol/rdsk/datapool/vol1 newfs: construct a new file system /dev/zvol/rdsk/datapool/vol1: (y/n)? y Warning: 2082 sector(s) in last cylinder unallocated /dev/zvol/rdsk/datapool/vol1: 4194270 sectors in 683 cylinders of 48 tracks, 128 sectors 2048.0MB in 43 cyl groups (16 c/g, 48.00MB/g, 11648 i/g) super-block backups (for fsck -F ufs -o b=#) at: 32, 98464, 196896, 295328, 393760, 492192, 590624, 689056, 787488, 885920, 3248288, 3346720, 3445152, 3543584, 3642016, 3740448, 3838880, 3937312, 4035744, 4134176
ボリュームの拡張は、データセットのvolsizeプロパティに新しい値を設定するだけで実行できます。この値を小さくする場合は、ボリュームが切り捨てられ、データを失う可能性があるため、注意してください。次の例で、ボリュームを2GBから4GBに拡張しましょう。ボリューム上にUFSファイル・システムがあるため、growfsを使用して、このファイル・システムが新しい領域を使用するようにします。
# zfs set volsize=4g datapool/vol1 # growfs /dev/zvol/rdsk/datapool/vol1 Warning: 4130 sector(s) in last cylinder unallocated /dev/zvol/rdsk/datapool/vol1: 8388574 sectors in 1366 cylinders of 48 tracks, 128 sectors 4096.0MB in 86 cyl groups (16 c/g, 48.00MB/g, 11648 i/g) super-block backups (for fsck -F ufs -o b=#) at: 32, 98464, 196896, 295328, 393760, 492192, 590624, 689056, 787488, 885920, 7472672, 7571104, 7669536, 7767968, 7866400, 7964832, 8063264, 8161696, 8260128, 8358560
ZFSデータセットのアップグレード
zpoolと同様に、zfsも任意の古いバージョンのデータセットをサポートできます。つまり、古いリリースのSolaris上でデータセット(およびプール)を作成し、それを新しいリリースのSolaris上で使用することができます。
# zfs get version datapool NAME PROPERTY VALUE SOURCE datapool version 5 - # zfs upgrade -v The following filesystem versions are supported: VER DESCRIPTION --- -------------------------------------------------------- 1 Initial ZFS filesystem version 2 Enhanced directory entries 3 Case insensitive and File system unique identifier (FUID) 4 userquota, groupquota properties 5 System attributes For more information on a particular version, including supported releases, see the ZFS Administration Guide.
前のzpoolの例と同様に、zfsデータセットも簡単にアップグレードできます。
# zfs create -o version=2 datapool/old # zfs get version datapool/old NAME PROPERTY VALUE SOURCE datapool/old version 2 - # zfs upgrade datapool/old 1 filesystems upgraded # zfs get version datapool/old NAME PROPERTY VALUE SOURCE datapool/old version 5 -
スナップショットとクローン
ZFSは、スナップショットを使用してデータセットの内容を保持する機能を提供します。
# zfs snapshot datapool/bob@now
@の後ろの値は、スナップショットの名前を示しています。多数のスナップショットを取得できます。
# zfs snapshot datapool/bob@just-a-bit-later # zfs snapshot datapool/bob@even-later-still # zfs list -r -t all datapool/bob NAME USED AVAIL REFER MOUNTPOINT NAME USED AVAIL REFER MOUNTPOINT datapool/bob 1.00G 1.19G 1.00G /datapool/bob datapool/bob@now 0 - 1.00G - datapool/bob@just-a-bit-later 0 - 1.00G - datapool/bob@even-later-still 0 - 1.00G -
この後の例で妨げとならないように、これらのスナップショットを削除しましょう。
# zfs destroy datapool/bob@even-later-still # zfs destroy datapool/bob@just-a-bit-later # zfs destroy datapool/bob@now
このようにして、任意の時点のスナップショットを取得できます。また、これらを使用して新しいデータセットを作成することができます。これらは、クローンと呼ばれます。 クローンはデータセットであり、他のデータセットとよく似ていますが、最初はスナップショットから取得したデータを持ちます。さらに興味深い点として、これらのクローンは、スナップショットと異なるデータのための領域しか必要としません。このため、1つのスナップショットから5つのクローンを作成するとしても、共通のデータについては1つのコピーしか必要ありません。
datapool/bobに1GBのファイルがあったことを思い出してください。上記のことを確認するために、このデータセットのスナップショットを取得し、そのスナップショットのクローンをいくつか作成します。
# zfs snapshot datapool/bob@original # zfs clone datapool/bob@original datapool/newbob # zfs clone datapool/bob@original datapool/newfred # zfs clone datapool/bob@original datapool/newpat # zfs clone datapool/bob@original datapool/newjoe
zfs listを使用して、何が起こっているか詳しく調べましょう。
# zfs list -r -o space datapool NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD datapool 1.19G 6.63G 0 40K 0 6.63G datapool/bob 1.19G 1.00G 0 1.00G 0 0 datapool/fred 2.00G 159K 0 32K 0 127K datapool/fred/documents 2.00G 127K 0 34K 0 93K datapool/fred/documents/audio 2.00G 31K 0 31K 0 0 datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0 datapool/fred/documents/video 2.00G 31K 0 31K 0 0 datapool/joe 1.19G 31K 0 31K 0 0 datapool/newbob 1.19G 18K 0 18K 0 0 datapool/newfred 1.19G 18K 0 18K 0 0 datapool/newjoe 1.19G 18K 0 18K 0 0 datapool/newpat 1.19G 18K 0 18K 0 0 datapool/old 1.19G 22K 0 22K 0 0 datapool/pat 1.19G 31K 0 31K 0 0 datapool/vol1 5.19G 4.13G 0 125M 4.00G 0
datapool/bobに1GBのファイルがあることが分かります。 この時点では、このデータセットがコピーの役割を担っていますが、すべてのクローンがそれを使用できます。
ここで、元のファイル・システム内のデータセットとそのすべてのクローンを削除して、何が起こるか見てみましょう。
# rm /datapool/*/bigfile # zfs list -r -o space datapool NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD datapool 1.19G 6.63G 0 40K 0 6.63G datapool/bob 1.19G 1.00G 1.00G 31K 0 0 datapool/fred 2.00G 159K 0 32K 0 127K datapool/fred/documents 2.00G 127K 0 34K 0 93K datapool/fred/documents/audio 2.00G 31K 0 31K 0 0 datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0 datapool/fred/documents/video 2.00G 31K 0 31K 0 0 datapool/joe 1.19G 31K 0 31K 0 0 datapool/newbob 1.19G 19K 0 19K 0 0 datapool/newfred 1.19G 19K 0 19K 0 0 datapool/newjoe 1.19G 19K 0 19K 0 0 datapool/newpat 1.19G 19K 0 19K 0 0 datapool/old 1.19G 22K 0 22K 0 0 datapool/pat 1.19G 31K 0 31K 0 0 datapool/vol1 5.19G 4.13G 0 125M 4.00G 0
1GBの容量は解放されていないのに(使用可能領域は3.28Gのまま)、datapool/bobのUSEDSNAP値が0から1GBに増えていることに注意してください。これは、この時点でスナップショットが1GBのデータを保持していることを示しています。 この領域を解放するには、スナップショットを削除する必要があります。今回の場合は、スナップショットから作成されたすべてのクローンも削除する必要があります。
# zfs destroy datapool/bob@original cannot destroy 'datapool/bob@original': snapshot has dependent clones use '-R' to destroy the following datasets: datapool/newbob datapool/newfred datapool/newpat datapool/newjoe # zfs destroy -R datapool/bob@original # zfs list -r -o space datapool NAME AVAIL USED USEDSNAP USEDDS USEDREFRESERV USEDCHILD datapool 2.19G 5.63G 0 35K 0 5.63G datapool/bob 2.19G 31K 0 31K 0 0 datapool/fred 2.00G 159K 0 32K 0 127K datapool/fred/documents 2.00G 127K 0 34K 0 93K datapool/fred/documents/audio 2.00G 31K 0 31K 0 0 datapool/fred/documents/pictures 2.00G 31K 0 31K 0 0 datapool/fred/documents/video 2.00G 31K 0 31K 0 0 datapool/joe 2.19G 31K 0 31K 0 0 datapool/old 2.19G 22K 0 22K 0 0 datapool/pat 2.19G 31K 0 31K 0 0 datapool/vol1 6.19G 4.13G 0 125M 4.00G 0
1GBの領域を保持していた最後のスナップショットが削除されたため、削除した1GBの容量が解放されています。
最後にもう一つ例を示します。この例では、スナップショットを削除しません。 スナップショットは、データセットとそのすべての子データセットについても取得することができます。再帰的なスナップショットは不可分です。つまり、このスナップショットは、すべてのデータセットの内容の、任意の時点での、一貫性のある写真のようなものです。 再帰的なスナップショットを取得するには、-rを使用します。
# zfs snapshot -r datapool/fred@now # zfs list -r -t all datapool/fred NAME USED AVAIL REFER MOUNTPOINT datapool/fred 159K 2.00G 32K /fred datapool/fred@now 0 - 32K - datapool/fred/documents 127K 2.00G 34K /fred/documents datapool/fred/documents@now 0 - 34K - datapool/fred/documents/audio 31K 2.00G 31K /fred/documents/audio datapool/fred/documents/audio@now 0 - 31K - datapool/fred/documents/pictures 31K 2.00G 31K /fred/documents/pictures datapool/fred/documents/pictures@now 0 - 31K - datapool/fred/documents/video 31K 2.00G 31K /fred/documents/video datapool/fred/documents/video@now 0 - 31K -
これらのスナップショットは、同様に-rを使用して破棄することができます。
# zfs destroy -r datapool/fred@now
圧縮
圧縮は、ZFSファイル・システムで使用できる興味深い機能です。ZFSでは、圧縮されたデータと圧縮されていないデータを混在させることができます。compressionプロパティを有効にすると、新しく書き込まれるすべてのブロックが圧縮されますが、既存のブロックは元の状態のままになります。
# zfs list datapool/bob NAME USED AVAIL REFER MOUNTPOINT datapool/bob 31K 2.19G 31K /datapool/bob # mkfile 1g /datapool/bob/bigfile # zfs list datapool/bob NAME USED AVAIL REFER MOUNTPOINT datapool/bob 1010M 1.20G 1010M /datapool/bob
ここで、datapool/bobのcompressionプロパティを有効にして、既存の1GBのファイルをコピーしましょう。それが完了したら、2つの個別の1GBのファイルがあることを確認してください。
# zfs set compression=on datapool/bob # cp /datapool/bob/bigfile /datapool/bob/bigcompressedfile # ls -la /datapool/bob total 2097450 drwxr-xr-x 2 root root 4 Nov 22 04:29 . drwxr-xr-x 6 root root 6 Nov 22 04:26 .. -rw------- 1 root root 1073741824 Nov 22 04:29 bigcompressedfile -rw------T 1 root root 1073741824 Nov 22 04:28 bigfile # zfs list datapool/bob NAME USED AVAIL REFER MOUNTPOINT datapool/bob 1.00G 1.19G 1.00G /datapool/bob
/datapool/bobに2つの異なる1GBのファイルがありますが、dfでは1GBのみが使用されていることが示されます。これにより、mkfileによって作成されたファイルがゼロで埋められたものであったことが分かります。このようなファイルの圧縮率は非常に高くなりますが、それらが領域をまったく持たないものであったために、圧縮されすぎています。 さらに興味深いことに、圧縮されたファイルをコピーして元の場所に戻すと、両方のファイルが圧縮され、プールに容量が戻されて空き容量が1GB増えます。
# cp /datapool/bob/bigcompressedfile /datapool/bob/bigfile # zfs list datapool/bob NAME USED AVAIL REFER MOUNTPOINT datapool/bob 31K 2.19G 31K /datapool/bob
次に進む前に、クリーンアップしておきましょう。
# zpool destroy datapool
演習3:ZFSとSolarisの他の部分との統合
このセクションでは、ZFSと統合されるSolarisサービスのいくつかの例について学習します。 まず、NFSサーバーについて説明します。
NFS
各ファイル・システム・データセットは、sharenfsというプロパティを持ちます。このプロパティは、一般に/etc/dfs/dfstabにある値に設定されます。具体的な設定について詳しくは、share_nfsのマニュアル・ページを参照してください。
3つのデータセット(fred、barney、dino)を使用してdatapoolという簡単なプールを作成します。
# zpool create datapool c4t0d0 # zfs create datapool/fred # zfs create datapool/barney # zfs create datapool/dino
共有されているファイル・システムがないことと、NFSサーバーが動作中ではないことを確認します。
# share # svcs nfs/server STATE STIME FMRI disabled 12:47:45 svc:/network/nfs/server:default
注:Oracle Solaris 11では、NFSプロパティの設定方法が以前のバージョンのOracle Solarisから変更されています。詳しくは、man zfs_shareを実行して表示されるマニュアル・ページを参照してください。
ここで、いくつかのプロパティを設定して、NFSを介したファイル・システムの共有を有効にしましょう。
# zfs set share=name=fred,path=/datapool/fred,prot=nfs,ro=* datapool/fred name=fred,path=/datapool/fred,prot=nfs,sec=sys,ro=* # zfs set share=name=barney,path=/datapool/barney,prot=nfs,rw=* datapool/barney # zfs set sharenfs=on datapool/fred # zfs set sharenfs=on datapool/barney # share fred /datapool/fred nfs sec=sys,ro barney /datapool/barney nfs sec=sys,rw # svcs nfs/server STATE STIME FMRI online 2:25:12 svc:/network/nfs/server:default
ファイル・システムがNFSを介して共有されているだけでなく、NFSサーバーも動作中になっています。
ここで、プールをエクスポートしましょう。NFS共有はなくなりますが、NFSは動作中のままであることに注意してください。
# zpool export datapool # share # svcs nfs/server STATE STIME FMRI online 13:08:42 svc:/network/nfs/server:default
プールがインポートされるとNFS共有が元に戻ることに注意してください。
# zpool import datapool # share fred /datapool/fred nfs sec=sys,ro barney /datapool/barney nfs sec=sys,rw
次に進む前に、クリーンアップしておきましょう。
# zpool destroy datapool
エラーのリカバリとFMA
このセクションでは、ZFSのハンズオン・ラボでもっとも興味深い内容を学習します。ここでは、ミラー化されたプールを作成し、そこに若干のデータを格納します。次に、基盤となっているストレージに対して実際に悪影響のある処置を実行して、一部のデータを破損させます。この作業の後に、ZFSによるすべてのエラーの修正を確認します。
# zpool create datapool mirror disk1 disk2 spare disk3
# zpool status datapool
pool: datapool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
datapool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
disk1 ONLINE 0 0 0
disk2 ONLINE 0 0 0
spares
disk3 AVAIL
新しいvdevタイプのspareに注目してください。 これは、データvdevに含まれるデバイスに関して過剰な数のエラーがレポートされた場合にスペアとして使用される一連のデバイスを示すために使用されます。
ここで、新しいプールに若干のデータを格納しましょう。/usr/share/manがデータのソースとして適しています。snycコマンドを使用するとファイル・システム・バッファを簡単にフラッシュできます。これにより、その後のディスク領域使用率コマンドが正確になります。
# cp -r /usr/share/man /datapool # sync # df -h /datapool Filesystem Size Used Avail Use% Mounted on datapool 460M 73M 388M 16% /datapool
ミラーの一方を破損させて、それに対するZFSの動作を確認しましょう。
# dd if=/dev/zero of=/dev/dsk/disk1 bs=1024k count=100 conv=notrunc
100+0 records in
100+0 records out
104857600 bytes (105 MB) copied, 2.23626 s, 46.9 MB/s
# zpool scrub datapool
# zpool status datapool
pool: datapool
state: DEGRADED
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scan: resilver in progress since Tue Apr 19 13:18:52 2011
46.6M scanned out of 72.8M at 4.24M/s, 0h0m to go
46.5M resilvered, 64.01% done
config:
NAME STATE READ WRITE CKSUM
datapool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
spare-0 DEGRADED 0 0 0
disk1 DEGRADED 0 0 14.6K too many errors
disk3 ONLINE 0 0 0 (resilvering)
disk2 ONLINE 0 0 0
spares
disk3 INUSE currently in use
errors: No known data errors
データ・エラーの発生は表面化されないため、ZFSにすべてのレプリカを比較させる必要があります。これは、zpool scrubによって実行できます。 エラーが検出されると、FMAエラー・レポートが作成され、ブロックの再書込みと再読取りによってエラーの修正が試みられます。 過剰な数のエラーが発生している場合、または再書込み/再読取りサイクルが依然として失敗する場合は、ホット・スペアがリクエストされます(使用可能な場合)。ホット・スペアが自動的にリシルバされ、プールが必要な可用性を取り戻すことに注意してください。
これは、FMAエラーおよび障害レポートでも確認できます。
# fmstat module ev_recv ev_acpt wait svc_t %w %b open solve memsz bufsz cpumem-retire 0 0 0.0 5.8 0 0 0 0 0 0 disk-transport 0 0 0.0 1954.1 0 0 0 0 32b 0 eft 431 0 0.0 32.4 0 0 0 0 1.3M 0 ext-event-transport 1 0 0.0 15.8 0 0 0 0 46b 0 fabric-xlate 0 0 0.0 6.1 0 0 0 0 0 0 fmd-self-diagnosis 183 0 0.0 3.8 0 0 0 0 0 0 io-retire 0 0 0.0 6.0 0 0 0 0 0 0 sensor-transport 0 0 0.0 201.8 0 0 0 0 32b 0 ses-log-transport 0 0 0.0 196.3 0 0 0 0 40b 0 software-diagnosis 0 0 0.0 5.8 0 0 0 0 316b 0 software-response 0 0 0.0 6.1 0 0 0 0 316b 0 sysevent-transport 0 0 0.0 3527.4 0 0 0 0 0 0 syslog-msgs 1 0 0.0 220.9 0 0 0 0 0 0 zfs-diagnosis 4881 4843 0.6 11.0 1 0 1 1 184b 140b zfs-retire 29 0 0.0 433.3 0 0 0 0 8b 0
ZFSエラーが検出されるたびzfs-diagnosisモジュールが起動されています。意にそぐわないエラーしきい値に達したときに、zfs-retireエージェントがコールされて障害が記録され、ホット・スペア・プロセスが開始されています。エラー・ログ・メッセージが書き込まれています(syslog-msgs > 0)。
では、元の状態に戻しましょう。
# zpool detach datapool disk1 # zpool replace datapool disk3 disk1 # zpool status datapool pool: datapool state: ONLINE scan: resilvered 72.6M in 0h0m with 0 errors on Tue Apr 19 13:21:42 2011 config: NAME STATE READ WRITE CKSUM datapool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 disk1 ONLINE 0 0 0 disk2 ONLINE 0 0 0 errors: No known data errors # zpool add datapool spare disk3
興味がある場合は、ミラーの両方を破損させてみて、何が起こるか調べてください。
まとめ
これで、Oracle Solaris ZFSファイル・システムの概要を学習するハンズオン・ラボは無事に完了です。
このラボで使用したテクノロジーについて詳しくは、次のリンクにアクセスしてください。
Oracle Solaris 11
Oracle Solaris:比類なき製品群
http://opensolaris.org/os/community/zfs
http://blogs.sun.com/bobn
電子メール(bob.netherton@oracle.com)によってラボの著者に直接問い合わせることができます。
ご参加くださり、ありがとうございました。
false