Data Mesh für Unternehmen
Lösungen, Anwendungsfälle und Fallstudien
Was versteht man unter Data Mesh?
Data Mesh ist ein aktuelles Thema im Bereich Unternehmenssoftware und ein neuer Ansatz für die Datenverwaltung auf der Grundlage einer verteilten Architektur. Die Grundidee besteht darin, den Zugang zu Daten und deren Verfügbarkeit für Geschäftskunden zu verbessern, indem Dateneigentümer, Datenproduzenten und Datenkonsumenten direkt miteinander verbunden werden. Data Mesh zielt auf die Verbesserung der Geschäftsergebnisse datenzentrierter Lösungen sowie auf die Einführung moderner Datenarchitekturen ab.
Aus geschäftlicher Sicht führt Data Mesh neue Ideen rund um das „Datenproduktdenken“ ein. Mit anderen Worten, Daten werden als Produkt betrachtet, das eine „Aufgabe“ erfüllt, z. B. die Verbesserung der Entscheidungsfindung, die Aufdeckung von Betrug oder die Warnung des Unternehmens vor Veränderungen in der Lieferkette. Um hochwertige Datenprodukte zu erstellen, müssen Unternehmen einen Kultur- und Mentalitätswandel herbeiführen und sich zu einem funktionsübergreifenden Ansatz bei der Modellierung von Geschäftsbereichen verpflichten.
Von der technologischen Seite her betrachtet, umfasst die Sicht von Oracle auf das Data Mesh drei wichtige neue Schwerpunktbereiche für datengesteuerte Architektur:
- Tools, die Datenprodukte wie Datensammlung, Datenereignisse und Datenanalysen bereitstellen
- Verteilte, dezentrale Datenarchitekturen, die Organisationen helfen, die sich von monolithischen Architekturen wegbewegen wollen, hin zu Multicloud- und Hybrid-Cloud-Computing, oder die global dezentralisiert arbeiten müssen
- Daten in Bewegung für Unternehmen, die sich nicht ausschließlich auf zentralisierte, statische, batchorientierte Daten verlassen können und stattdessen zu ereignisgesteuerten Daten-Ledgern und Streaming-zentrierten Pipelines für Echtzeit-Datenereignisse übergehen, die schnellere Analysen ermöglichen
Andere wichtige Anliegen wie Selfservice-Tools für Laien und starke föderierte Daten-Governance-Modelle sind für die Data-Mesh-Architektur genauso wichtig wie für andere, stärker zentralisierte und klassische Datenmanagementmethoden.
Ein neues Konzept für Daten

Ein Data-Mesh-Ansatz ist ein Paradigmenwechsel hin zur Betrachtung von Daten als Produkt. Data Mesh führt organisatorische und verfahrenstechnische Änderungen ein, die Unternehmen benötigen, um Daten als materielles Kapital des Unternehmens zu verwalten. Die Perspektive von Oracle für die Data-Mesh-Architektur erfordert eine Anpassung über organisatorische und analytische Datenbereiche hinweg.
Ein Data Mesh zielt darauf ab, Datenproduzenten direkt mit Geschäftsnutzern zu verbinden und den IT-Vermittler aus den Projekten und Prozessen herauszunehmen, die Datenressourcen aufnehmen, aufbereiten und umwandeln.
Der Fokus von Oracle auf Data Mesh liegt in der Bereitstellung einer Plattform für unsere Kunden, die diese neuen technologischen Anforderungen erfüllen kann. Dazu gehören Tools für Datenprodukte, dezentrale, ereignisgesteuerte Architekturen und Streaming-Muster für Daten in Bewegung. Bei der Modellierung von Datenproduktdomänen und anderen soziotechnischen Belangen deckt sich Oracle mit der Arbeit des Vordenkers im Bereich Data Mesh, Zhamak Dehghani.
Vorteile eines Data Mesh
Die Investition in ein Data Mesh kann beeindruckende Vorteile bringen, darunter:
- Vollständige Klarheit über den Mehrwert von Daten durch angewandte Best Practices des Datenproduktdenkens.
- Mehr als 99,9999%ige operative Datenverfügbarkeit mithilfe von auf Microservices basierenden Datenpipelines für Datenkonsolidierung und Datenmigrationen.
- 10-mal schnellere Innovationszyklen, weg vom manuellen, Batch-orientierten ETL hin zu Continuous Transformation and Loading (CTL).
- Über 70 % weniger Daten-Engineering, Verbesserungen bei CI/CD, No-Code- und Selfservice-Datenpipeline-Tools und agile Entwicklung.
Data Mesh ist mehr als nur eine Denkweise
Data Mesh befindet sich noch im Anfangsstadium der Marktreife. Während Sie also eine Vielzahl von Marketing-Inhalten über eine Lösung sehen könnten, die behauptet, „Data Mesh“ zu sein, entsprechen diese sogenannten Data-Mesh-Lösungen oft nicht dem Kernansatz oder den Prinzipien.
Ein richtiges Data Mesh ist eine Denkweise, ein Organisationsmodell und ein Ansatz für eine Unternehmensdatenarchitektur mit unterstützenden Tools. Eine Data-Mesh-Lösung sollte eine Mischung aus Datenproduktdenken, dezentralisierter Datenarchitektur, domainorientiertem Datenbesitz, verteilten Daten in Bewegung, Selfservice-Zugriff und starker Data Governance aufweisen.
Ein Data Mesh ist keines der folgenden Elemente:
- Ein Produkt eines Händlers: Es gibt kein alleinstehendes Data-Mesh-Softwareprodukt.
- Ein Data Lake oder Data Lakehouses: Diese ergänzen einander und können Teil eines größeren Data Mesh sein, das mehrere Seen, Teiche und operative Aufzeichnungssysteme umfasst.
- Ein Datenkatalog oder Diagramm: Ein Data Mesh benötigt eine physische Implementierung.
- Ein einmaliges Beratungsprojekt: Data Mesh ist eine Reise, kein einmaliges Projekt.
- Ein Selfservice-Analyseprodukt: Klassische Selfservice-Analysen, Datenaufbereitung und Data Wrangling können Teil eines Data Mesh sowie anderer Datenarchitekturen sein.
- Eine Data Fabric: Obwohl konzeptionell verwandt, umfasst das Data-Fabric-Konzept eine Vielzahl von Datenintegrations- und Datenverwaltungsstilen, während Data Mesh eher mit Dezentralisierung und bereichsbezogenen Entwurfsmustern in Verbindung gebracht wird.
Warum Data Mesh?
Die traurige Wahrheit ist, dass die monolithischen Datenarchitekturen der Vergangenheit mühsam, kostspielig und unflexibel waren. Im Laufe der Jahre hat sich gezeigt, dass die meiste Zeit und das meiste Geld für digitale Geschäftsplattformen, von Anwendungen bis hin zu Analysen, in Integrationsbemühungen fließen. Folglich scheitern die meisten Plattforminitiativen.
Data Mesh ist zwar kein Wundermittel für zentralisierte, monolithische Datenarchitekturen, doch die Prinzipien, Praktiken und Technologien der Data Mesh-Strategie sind darauf ausgelegt, einige der dringendsten und bisher nicht angegangenen Modernisierungsziele für datengesteuerte Geschäftsinitiativen zu lösen.
Einige der Technologietrends, die zum Aufkommen von Data Mesh als Lösung geführt haben, sind:
- 70-80 % der digitalen Transformationen scheitern
- Die Kosten für betriebliche Datenausfälle steigen
- Die Cloud-Bindung ist real und könnte kostspieliger werden
- Data Lakes sind selten erfolgreich und konzentrieren sich nur auf Analysen
- Der Anstieg der verteilten Daten erzwingt eine effektivere, effizientere und wirtschaftlichere Architektur
- Organisationssilos verschlimmern Probleme beim Datenaustausch
- Daten sind der Katalysator für Wettbewerbsvorteile und müssen gut verwaltet werden
Weitere Informationen dazu, warum Data-Mesh heute benötigt wird, finden Sie im Originalbericht von Zhamak Dehghani aus dem Jahr 2019: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
Data Mesh definieren
Die dezentralisierte Strategie hinter Data Mesh besteht darin, Daten als Produkt zu behandeln, indem eine Selfservice-Dateninfrastruktur geschaffen wird, um Daten für Geschäftsnutzer zugänglicher zu machen.
Ergebnisorientiert
Datenproduktdenken- Umstellung der Denkweise auf die Sichtweise des Datenkonsumenten
- Eigentümer von Datendomänen sind für Datenprodukt-KPIs/SLAs verantwortlich
- Gleiche Datendomain- und Technologie-Mesh-Semantik für alle
- Schluss mit dem „über die Mauer werfen“ von Daten
- Datenereignisse in Echtzeit direkt aus Datensystemen erfassen und Self-Service-Pipelines zur Bereitstellung von Daten bei Bedarf aktivieren
- Eine wesentliche Fähigkeit, um dezentrale Daten und quellenorientierte Datenprodukte zu ermöglichen
Lehnt eine monolithische IT-Architektur ab
Dezentralisierte Architektur- Eine Architektur, die für dezentrale Daten, Services und Clouds entwickelt wurde
- Konzipiert, um alle Arten, Formate und Komplexitäten von Ereignissen zu bewältigen
- Standardmäßige Stream-Verarbeitung, Batch-Verarbeitung als Ausnahme
- Entwickelt, um Entwickler zu unterstützen und Datenkonsumenten direkt mit Datenproduzenten zu verbinden
- Integrierte Sicherheit, Validierung, Herkunft und Transparenz
Oracle Funktionen zum Antrieb eines Data Mesh
Wenn die Theorie in die Praxis umgesetzt wird, ist es notwendig, Lösungen der Unternehmensklasse für unternehmenskritische Daten einzusetzen. Hier kann Oracle eine Reihe von vertrauenswürdigen Lösungen zur Unterstützung eines Enterprise Data Mesh bereitstellen.
Erstellen und Teilen von Datenprodukten
- Multimodell-Datenerfassungen mit der konvergierten Oracle-Datenbank ermöglichen „Shape Shifting“-Datenprodukte in den von Datenkonsumenten benötigten Formaten
- Selfservice-Datenprodukte als Anwendungen oder APIs, die Oracle APEX Application Development und Oracle REST Data Services für den einfachen Zugriff und die Freigabe aller Daten verwenden
- Zentraler Zugriffspunkt für SQL-Abfragen oder Datenvirtualisierung mit Oracle Cloud SQL und Big Data SQL
- Datenprodukte für maschinelles Lernen mit der Data Science-Plattform von Oracle, dem Oracle Cloud Infrastructure (OCI) Data Catalog und der Cloud-Datenplattform von Oracle für Data Lakehouses
- Quellennahe Datenprodukte als Echtzeitereignisse, Datenwarnungen und Rohdatenereignisdienste mit Oracle Stream Analytics
- Verbrauchernahe Selfservice-Datenprodukte in einer umfassenden Oracle Analytics Cloud-Lösung
Betrieb einer dezentralen Datenarchitektur
- Agiles CI/CD im „Service Mesh“-Stil für Datencontainer mithilfe von erweiterbaren Oracle Datenbanken mit Kubernetes, Docker oder Cloud-nativ mit Autonomous Database
- Regionsübergreifende, Multicloud- und Hybrid-Cloud-Data-Sync mit Oracle GoldenGate-Microservices und Veridata für eine vertrauenswürdige Active-Active-Transaktionsstruktur
- Mit Oracle Integration Cloud und Oracle Internet of Things Cloud können Sie die meisten Anwendungs-, Geschäftsprozesse und Internet of Things-(IoT-)Datenereignisse nutzen
- Verwenden Sie Oracle GoldenGate oder Oracle Transaction Manager for Microservices-Event-Queues für die Beschaffung von Ereignissen für Microservices oder die Aufnahme in Echtzeit in Kafka und Data Lakes
- Bringen Sie mit Oracle Verrazzano, Helidon und Graal VM dezentrale domänenspezifische Designmuster in Ihr Service-Mesh
3 Hauptmerkmale eines Data Meshs
Data Mesh ist mehr als nur ein neues technisches Schlagwort. Es handelt sich um eine neu entstehende Reihe von Prinzipien, Praktiken und Technologiefähigkeiten, die Daten zugänglicher und auffindbarer machen. Das Data-Mesh-Konzept unterscheidet sich von früheren Generationen von Datenintegrationsansätzen und -architekturen, indem es eine Abkehr von vergangenen riesigen, monolithischen Unternehmensdatenarchitekturen hin zu einer modernen, verteilten, dezentralisierten datengesteuerten Architektur der Zukunft fördert. Die Grundlage des Data-Mesh-Konzepts umfasst die folgenden Hauptmerkmale:
1. Datenproduktdenken
Eine Änderung der Denkweise ist der wichtigste erste Schritt in Richtung eines Data Meshs. Die Bereitschaft, die erlernten Praktiken der Innovation anzunehmen, ist das Sprungbrett für eine erfolgreiche Modernisierung der Datenarchitektur.
Diese erlernten Tätigkeitsbereiche umfassen:
- Design Thinking – eine bewährte Methode zur Lösung „bösartiger Probleme“, die auf Unternehmensdatendomänen angewendet wird, um großartige Datenprodukte zu erstellen.
- „Jobs to be done“-Theorie – – Anwendung einer kundenorientierten Innovation und eines ergebnisorientierten Innovationsprozesses, um sicherzustellen, dass Unternehmensdatenprodukte echte Geschäftsprobleme lösen.

Design-Thinking-Methoden bieten bewährte Techniken, die dabei helfen, organisatorische Silos abzubauen, die häufig funktionsübergreifende Innovationen blockieren. Die „Jobs to be done“-Theorie ist die entscheidende Grundlage für die Entwicklung von Datenprodukten, die bestimmte Endverbraucherziele – oder zu erledigende Aufgaben – erfüllen. Außerdem definiert sie den Zweck des Produkts.
Obwohl der Datenproduktansatz ursprünglich aus der Data-Science-Community hervorgegangen ist, wird er mittlerweile auch auf alle Aspekte des Datenmanagements angewendet. Anstatt monolithische Technologiearchitekturen aufzubauen, konzentriert sich Data Mesh auf die Datenkonsumenten und die Geschäftsergebnisse.
Während das Datenproduktdenken auf andere Datenarchitekturen angewendet werden kann, ist es ein wesentlicher Bestandteil eines Data Meshs. Als pragmatische Beispiele für die Anwendung des Datenproduktdenkens hat das Team von Intuit eine detaillierte Analyse seiner Erfahrungen verfasst.
Datenprodukte
Produkte jeglicher Art – von Rohwaren bis hin zu Artikeln in Ihrem örtlichen Geschäft – werden als Wertgüter hergestellt, die zum Konsum bestimmt sind und eine bestimmte Aufgabe erfüllen müssen. Datenprodukte können je nach Geschäftsbereich oder zu lösendem Problem unterschiedliche Formen annehmen und Folgendes umfassen:
- Analysen – Verlaufs-/Echtzeitberichte und Dashboards
- Datasets – Datensammlungen in verschiedenen Formen/Formaten
- Modelle – Domänenobjekte, Datenmodelle, Funktionen für maschinelles Lernen (ML)
- Algorithmen – ML-Modelle, Bewertung, Geschäftsregeln
- Datenservices und APIs – Dokumente, Payloads, Themen, REST-APIs und mehr
Ein Datenprodukt wird für den Verbrauch erstellt, gehört normalerweise nicht der IT und erfordert die Verfolgung zusätzlicher Attribute, wie z. B.:
- Stakeholder-Karte – Wem gehört, wer erstellt und konsumiert dieses Produkt?
- Verpackung und Dokumentation – Wie wird es verbraucht? Wie ist es gekennzeichnet?
- Zweck und Wert – Was ist der implizite/explizite Wert des Produkts? Wird es im Laufe der Zeit eine Abschreibung geben?
- Qualität und Konsistenz – Was sind die KPIs und SLAs für die Nutzung? Kann es überprüft werden?
- Herkunft, Lebenszyklus und Governance – Gibt es Vertrauen und Erklärbarkeit der Daten?
2. Dezentrale Datenarchitektur

Dezentralisierte IT-Systeme sind eine moderne Realität, und mit dem Aufkommen von SaaS-Anwendungen und Public-Cloud-Infrastrukturen (IaaS) wird die Dezentralisierung von Anwendungen und Daten Bestand haben. Architekturen von Anwendungssoftware verlagern sich weg von den zentralisierten Monolithen der Vergangenheit hin zu verteilten Microservices (ein Service-Mesh). Die Datenarchitektur wird dem gleichen Trend zur Dezentralisierung folgen, wobei Daten stärker über eine größere Vielfalt physischer Standorte und über viele Netzwerke verteilt werden. Wir bezeichnen dies als Data Mesh.
Was versteht man unter einem Mesh?
Ein Mesh ist eine Netzwerktopologie, mit der eine große Gruppe nicht hierarchischer Knoten zusammenarbeiten kann.
Einige gängige technische Beispiele sind:
- WiFiMesh – viele Knoten arbeiten zusammen, um eine bessere Abdeckung zu erzielen
- ZWave/Zigbee – energiesparende Smart-Home-Gerätenetzwerke
- 5G-Mesh – zuverlässigere und widerstandsfähigere Mobilfunkverbindungen
- Starlink – Satelliten-Breitband-Mesh auf globaler Ebene
- Service Mesh – eine Möglichkeit zur Bereitstellung einheitlicher Kontrollen über dezentrale Microservices (Anwendungssoftware)
Data Mesh ist auf diese Mesh-Konzepte ausgerichtet und bietet eine dezentrale Möglichkeit, Daten über virtuelle/physische Netzwerke und über große Entfernungen zu verteilen. Ältere monolithische Architekturen zur Datenintegration wie ETL und Datenföderationstools – und in jüngerer Zeit Public Cloud-Services wie AWS Glue – erfordern eine stark zentralisierte Infrastruktur.
Eine vollständige Data-Mesh-Lösung sollte in der Lage sein, in einem Multicloud-Framework zu arbeiten, das potenziell von On-Premises-Systemen, mehreren Public Clouds und sogar bis zu Edge-Netzwerken reichen kann.
Verteilte Sicherheit
In einer Welt, in der Daten stark verteilt und dezentralisiert sind, ist die Rolle der Informationssicherheit von größter Bedeutung. Im Gegensatz zu stark zentralisierten Monolithen müssen verteilte Systeme die Aktivitäten delegieren, die zur Authentifizierung und Autorisierung verschiedener Benutzer für unterschiedliche Zugriffsebenen erforderlich sind. Eine sichere netzwerkübergreifende Delegierung von Vertrauen ist schwierig.
Einige Überlegungen beinhalten:
- Verschlüsselung im Ruhezustand – als Daten/Ereignisse, die in den Speicher geschrieben werden
- Verteilte Authentifizierung – für Services und Datenspeicher wie mTLS, Zertifikate, SSO, Secret Stores und Data Vaults
- Verschlüsselung in Bewegung – als Daten/Ereignisse, die im Arbeitsspeicher fließen
- Identity Management – Services vom Typ LDAP/IAM, plattformübergreifend
- Verteilte Autorisierungen – für Serviceendpunkte zum Überarbeiten von Daten
Zum Beispiel:Open Policy Agent (OPA) Sidecar to Place Policy Entscheidungspunkt (PDP) innerhalb des Container/K8S-Clusters, an dem der Microservice-Endpunkt verarbeitet wird. LDAP/IAM kann jeder JWT-fähige Service sein - Deterministische Maskierung – um PII-Daten zuverlässig und konsistent zu verschleiern
Sicherheit innerhalb eines beliebigen IT-Systems kann schwierig sein, und es ist sogar noch schwieriger, eine hohe Sicherheit innerhalb verteilter Systeme bereitzustellen. Dies sind jedoch lösbare Probleme.
Dezentrale Datendomänen
Ein Kerngedanke von Data Mesh ist das Konzept der Verteilung von Eigentum und Verantwortung. Die bewährte Methode besteht darin, das Eigentum an Datenprodukten und Datendomänen den Personen in einer Organisation zu übertragen, die den Daten am nächsten stehen. In der Praxis kann dies auf Quelldaten (z. B. Rohdatenquellen wie die operativen Aufzeichnungssysteme/Anwendungen) oder auf die Analysedaten (z. B. typischerweise zusammengesetzte oder aggregierte Daten, die für eine einfache Nutzung durch die Datenkonsumenten formatiert sind) ausgerichtet sein. In beiden Fällen sind die Erzeuger und Verbraucher der Daten oft eher mit Geschäftseinheiten als mit IT-Organisationen verbunden.
Alte Formen der Organisation von Datendomänen geraten oft in die Falle, sich an Technologielösungen wie ETL-Tools, Data Warehouses, Data Lakes oder der strukturellen Organisation eines Unternehmens (Personalwesen, Marketing und andere Geschäftszweige) auszurichten. Für ein bestimmtes Geschäftsproblem sind die Datendomänen jedoch häufig am besten auf den Umfang des zu lösenden Problems, den Kontext eines bestimmten Geschäftsprozesses oder die Anwendungsfamilie in einem bestimmten Problembereich ausgerichtet. In großen Organisationen erstrecken sich diese Datendomänen normalerweise über die internen Organisationen und technologischen Footprints.
Die funktionale Zerlegung von Datendomänen nimmt im Data Mesh einen gehobenen erstklassigen Stellenwert ein. Verschiedene Datenzerlegungsmethoden für die Domänenmodellierung können in die Data Mesh-Architektur nachgerüstet werden, einschließlich der klassischen Data Warehouse-Modellierung (wie Kimball und Inmon) oder der Data Vault-Modellierung. Die gängigste Methode, die derzeit in der Data-Mesh-Architektur ausprobiert wird, ist jedoch das domänengesteuerte Design (DDD). Der DDD-Ansatz ist aus der funktionalen Zerlegung von Microservices hervorgegangen und wird nun in einem Data Mesh-Kontext angewendet.
3. Dynamische Daten in Bewegung
Ein wichtiger Bereich, in dem Oracle die Data Mesh-Diskussion ergänzt hat, ist die Hervorhebung der Bedeutung von Daten in Bewegung als Hauptbestandteil eines modernen Data Meshs. Daten in Bewegung sind von grundlegender Bedeutung, um das Data Mesh aus der alten Welt der monolithischen, zentralisierten Batch-Verarbeitung herauszuholen. Die Fähigkeiten von Daten in Bewegung beantworten mehrere zentrale Fragen zum Datennetz, wie zum Beispiel:
- Wie können wir in Echtzeit auf quellenorientierte Datenprodukte zugreifen?
- Welche Tools können die Mittel für verteilte vertrauenswürdige Datentransaktionen über ein physisch dezentralisiertes Data Mesh bereitstellen?
- Was kann ich verwenden, wenn ich Datenereignisse als Datenprodukt-APIs verfügbar machen muss?
- Wie würde ich mich bei analytischen Datenprodukten, die ständig auf dem neuesten Stand sein müssen, an Datendomänen ausrichten und Vertrauen und Gültigkeit sicherstellen?
Bei diesen Fragen geht es nicht nur um die „Implementierungsdetails“, sondern auch um zentrale Aspekte der Datenarchitektur selbst. Ein domänengesteuertes Design für statische Daten verwendet andere Techniken und Tools als ein dynamischer Data-in-Motion-Prozess desselben Designs. Beispielsweise ist in dynamischen Datenarchitekturen das Daten-Ledger für Datenereignisse die zentrale Quelle der Wahrheit.
Ereignisgesteuerte Daten-Ledger

Ledger (Bücher) sind eine grundlegende Komponente für die Funktion einer verteilten Datenarchitektur. Genau wie bei einem Buchhaltungsbuch zeichnet ein Daten-Ledger die Transaktionen auf, während sie stattfinden.
Wenn wir das Ledger verteilen, können die Datenereignisse an jedem Ort „wiedergegeben werden“. Einige Ledger sind ein bisschen wie der Flugschreiber im Flugzeug, der für Hochverfügbarkeit und Disaster Recovery eingesetzt wird.
Im Gegensatz zu zentralisierten und monolithischen Datenspeichern sind Distributed Ledger speziell darauf ausgelegt, atomare Ereignisse und/oder Transaktionen zu verfolgen, die in anderen (externen) Systemen stattfinden.
Ein Data Mesh ist nicht nur eine Art Ledger. Abhängig von den Anwendungsfällen und Anforderungen kann ein Data Mesh verschiedene Arten von ereignisgesteuerten Daten-Ledgern verwenden, darunter die folgenden:
- Allgemeines Ereignis-Ledger – wie Kafka oder Pulsar
- Daten-Ereignis-Ledger – verteilte CDC/Replikationstools
- Messaging-Middleware – einschließlich ESB, MQ, JMS und AQ
- Blockchain-Ledger – für sichere, unveränderliche Transaktionen mit mehreren Parteien
Zusammen können diese Ledger als eine Art dauerhaftes Ereignisprotokoll für das gesamte Unternehmen fungieren und eine fortlaufende Liste von Datenereignissen bereitstellen, die in Aufzeichnungs- und Analysesystemen auftreten.
Mehrsprachige Datenstreams

Mehrsprachige Datenstreams sind verbreiteter denn je. Sie variieren je nach Ereignistypen, Payload und unterschiedlicher Transaktionssemantik. Ein Data Mesh sollte die erforderlichen Stream-Typen für eine Vielzahl von Unternehmensdaten-Workloads unterstützen.
Einfache Ereignisse:
- Base64/JSON – rohe, schemalose Ereignisse
- Rohe Telemetriedaten – spärliche Ereignisse
Grundlegende App-Protokollierung/Internet of Things-(IoT-)Ereignisse:
- JSON/Protobuf – möglicherweise mit Schema
- MQTT – IoT-spezifische Protokolle
Geschäftsprozessereignisse von Anwendungen:
- SOAP/REST-Ereignisse – XML/XSD, JSON
- B2B – Austauschprotokolle und -standards
Datenereignisse/Transaktionen:
- Logische Änderungsdatensätze – LCR, SCN, URID
- Konsistente Grenzwerte – Commits im Vergleich zu Vorgängen
Streamdaten-Verarbeitung
Bei der Stream-Verarbeitung werden Daten innerhalb eines Ereignisstreams bearbeitet. Im Gegensatz zu „Lambda-Funktionen“ behält der Stream-Prozessor die Zustandsbeschaffenheit von Datenflüssen innerhalb eines bestimmten Zeitfensters bei und kann viel fortschrittlichere analytische Abfragen auf die Daten anwenden.
- Schwellenwerte, Warnungen und Telemetrieüberwachung
- RegEx-Funktionen, Mathematik/Logik und Verkettung
- Datensatz für Datensatz, Substitutionen und Maskierung
Grundlegende Datenfilterung:
Einfacher ETL-Prozess:
CEP und komplexe ETL-Prozesse:
- Komplexe Ereignisverarbeitung (CEP)
- DML (ACID)-Verarbeitung und Gruppen von Tupeln
- Aggregate, Lookups, komplexe Verknüpfungen
Stream Analytics:
- Zeitreihenanalysen und benutzerdefinierte Zeitfenster
- Geodaten, maschinelles Lernen und eingebettete KI
Andere wichtige Attribute und Prinzipien
Natürlich gibt es mehr als nur drei Attribute eines Data Meshs. Wir haben uns auf die drei oben genannten konzentriert, um die Aufmerksamkeit auf Attribute zu lenken, von denen Oracle glaubt, dass sie einige der neuen und einzigartigen Aspekte des aufkommenden modernen Data Mesh-Ansatzes sind.
Weitere wichtige Data Mesh-Attribute sind:
- Selfservice-Tooling – Data Mesh nimmt den allgemeinen Datenverwaltungstrend in Richtung Selfservice auf, Citizen Developer müssen zunehmend aus den Reihen der Dateneigentümer kommen
- Daten-Governance – Data Mesh hat auch den langjährigen Trend zu einem stärker formalisierten föderierten Governance-Modell aufgegriffen, wie er seit vielen Jahren von Chief Data Officers, Data Stewards und Anbietern von Datenkatalogen verfochten wird.
- Datennutzbarkeit – Wenn wir uns mit den Prinzipien des Data Mesh befassen, gibt es eine Menge Grundlagenarbeit, um sicherzustellen, dass Datenprodukte in hohem Maße nutzbar sind. Prinzipien für Datenprodukte werden sich mit Daten befassen, die wertvoll und nutzbar sind und auch geteilt werden können.
7 Anwendungsfälle für Data Mesh
Ein erfolgreiches Data Mesh erfüllt Anwendungsfälle sowohl für operative als auch für analytische Datendomänen. Die folgenden sieben Anwendungsfälle veranschaulichen die Breite der Möglichkeiten, die ein Data Mesh für Unternehmensdaten bietet.
Durch die Integration von Betriebsdaten und Analysen in Echtzeit können Unternehmen bessere operative und strategische Entscheidungen treffen.MIT Sloan School of Management
1. Modernisierung von Anwendungen
Abgesehen von „Lift-and-Shift“-Migrationen von monolithischen Datenarchitekturen in die Cloud versuchen viele Unternehmen auch, ihre zentralisierten Anwendungen der Vergangenheit aufzugeben und auf eine modernere Microservices-Anwendungsarchitektur umzusteigen.


Monolithen von Legacy-Anwendungen sind jedoch in der Regel auf riesige Datenbanken angewiesen, was die Frage aufwirft, wie der Migrationsplan gestuft werden kann, um Störungen, Risiken und Kosten zu verringern. Ein Data Mesh kann eine wichtige operative IT-Funktionalität für Kunden bereitstellen, die einen schrittweisen Übergang von einer monolithischen zu einer Mesh-Architektur durchführen. Beispiel:
- Subdomain-Auslagerung von Datenbanktransaktionen, z. B. Filtern von Daten nach „gebundenen Kontext“
- Bidirektionale Transaktionsreplikation für schrittweise Migrationen
- Plattformübergreifende Synchronisierung, wie z. B. Mainframe zu DBaaS
Im Jargon der Microservices-Architekten verwendet dieser Ansatz einen bidirektionalen Transaktionsausgang, um das Würgefeigen-Migrationsmuster zu ermöglichen, einen gebundenen Kontext nach dem anderen.
2. Datenverfügbarkeit und Kontinuität

Geschäftskritische Anwendungen erfordern sehr hohe KPIs und SLAs in Bezug auf Resilienz und Kontinuität. Unabhängig davon, ob diese Anwendungen monolithisch, Microservices oder etwas dazwischen sind, können sie nicht ausfallen!
Für geschäftskritische Systeme ist ein verteiltes Eventual-Consistency-Datenmodell normalerweise nicht akzeptabel. Diese Anwendungen müssen jedoch in vielen Data Centern betrieben werden. Dies wirft die Business-Continuity-Frage auf: „Wie kann ich meine Anwendungen in mehr als einem Data Center ausführen und gleichzeitig korrekte und konsistente Daten garantieren?“
Unabhängig davon, ob die monolithischen Architekturen „Sharded Datasets“ nutzen oder die Microservices auf standortübergreifende High Availability ausgelegt sind, das Data Mesh bietet korrekte und schnelle Daten auf jede Distanz.
Ein Data Mesh kann die Grundlage für dezentrale und dennoch standortübergreifend 100 % korrekte Daten bilden. Beispiel:
- Logische Transaktionen mit sehr geringer Latenz (plattformübergreifend)
- ACID-fähige Garantien für korrekte Daten
- Multiaktiv, bidirektional und Konfliktlösung
3. Event Sourcing und Transaktionsausgang


Eine moderne Plattform im Service-Mesh-Stil verwendet Ereignisse für den Datenaustausch. Anstatt von der Batch-Verarbeitung in der Datenebene abhängig zu sein, fließen Datennutzlasten kontinuierlich, wenn Ereignisse in der Anwendung oder im Datenspeicher eintreten.
Bei manchen Architekturen müssen Microservices Daten-Payloads untereinander austauschen. Und andere Schemata erfordern den Austausch zwischen monolithischen Anwendungen oder Datenspeichern. Dies wirft die Frage auf: „Wie kann ich Microservice-Daten-Payloads zuverlässig zwischen meinen Apps und Datenspeichern austauschen?“
Ein Data Mesh kann die grundlegende Technologie für den Microservices-zentrierten Datenaustausch liefern. Beispiel:
- Microservice zu Microservice im Kontext
- Kontextübergreifend von Microservice zu Microservice
- Monolith zu/von Microservice
Microservices-Schemata wie Event Sourcing, CQRS und Transaktionsausgang sind allgemein bekannte Lösungen – ein Data Mesh stellt die Tools und Frameworks bereit, um diese Schemata in großem Maßstab wiederholbar und zuverlässig zu machen.
4. Ereignisgesteuerte Integration
Über Microservice-Designmuster hinaus erstreckt sich der Bedarf an Unternehmensintegration auf andere IT-Systeme wie Datenbanken, Geschäftsprozesse, Anwendungen und physische Geräte aller Art. Ein Data Mesh bildet die Grundlage für die Integration von Daten in Bewegung.
Daten in Bewegung sind typischerweise ereignisgesteuert. Eine Benutzeraktion, ein Geräteereignis, ein Prozessschritt oder ein Datenspeicher-Commit können alle ein Ereignis mit einer Daten-Payload auslösen. Diese Daten-Payloads sind entscheidend für die Integration von Internet of Things-(IoT-)Systemen, Geschäftsprozessen und Datenbanken, Data Warehouses und Data Lakes.
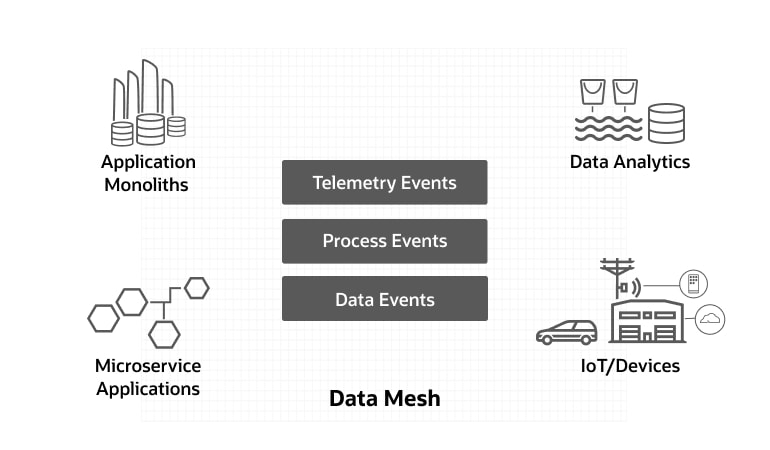
Ein Data Mesh liefert die grundlegende Technologie für die Echtzeit-Integration im gesamten Unternehmen. Beispiel:
- Verbinden realer Geräteereignisse mit IT-Systemen
- Integration von Geschäftsprozessen über ERP-Systeme hinweg
- Abgleich von Betriebsdatenbanken mit analytischen Datenspeichern
Große Organisationen werden natürlich eine Mischung aus alten und neuen Systemen, Monolithen und Microservices, operativen und analytischen Datenspeichern haben. Ein Data Mesh kann dazu beitragen, diese Ressourcen über verschiedene Geschäfts- und Datendomänen hinweg zu vereinheitlichen.
5. Streaming-Aufnahme (für Analysen)

Analytische Datenspeicher können Data Marts, Data Warehouses, OLAP-Cubes, Data Lakes und Data Lakehouse-Technologien umfassen.
Im Allgemeinen gibt es nur zwei Möglichkeiten, Daten in diese analytischen Datenspeicher zu bringen:
- Batch-/Mikro-Batch-Laden – auf einem Zeitplaner
- Streaming-Aufnahme – Kontinuierliches Laden von Datenereignissen
Ein Data Mesh bildet die Grundlage für eine Streaming-Datenaufnahmefunktion. Beispiel:
- Datenereignisse aus Datenbanken oder Datenspeichern
- Geräteereignisse aus der Telemetrie des physischen Geräts
- Ereignisprotokollierung von Anwendungen oder Geschäftstransaktionen
Die Aufnahme von Ereignissen per Stream kann die Auswirkungen auf die Quellsysteme verringern, die Genauigkeit der Daten verbessern (wichtig für Data Science) und Echtzeitanalysen ermöglichen.
6. Streaming-Datenpipelines

Nach der Aufnahme in die analytischen Datenspeicher sind in der Regel Datenpipelines erforderlich, um die Daten über verschiedene Datenphasen oder Datenzonen hinweg vorzubereiten und zu transformieren. Dieser Datenverfeinerungsprozess wird häufig für die nachgelagerten analytischen Datenprodukte benötigt.
Ein Data Mesh kann eine unabhängig verwaltete Datenpipeline-Schicht bereitstellen, die mit den analytischen Datenspeichern zusammenarbeitet und die folgenden Kernservices bereitstellt:
- Selfservice-Datenentdeckung und Datenvorbereitung
- Governance von Datenressourcen über Domänen hinweg
- Datenvorbereitung und Transformation in erforderliche Datenproduktformate
- Datenüberprüfung nach Policy, die Konsistenz gewährleistet
Diese Datenpipelines sollten in der Lage sein, über verschiedene physische Datenspeicher (z. B. Marts, Warehouses oder Lakes) oder als „Pushdown-Datenstream“ innerhalb von Analysedatenplattformen zu funktionieren, die Streaming-Daten unterstützen, wie z. B. Apache Spark und andere Data Lakehouse-Technologien.
7. Streaming-Analysen

Ereignisse finden ständig statt. Die Analyse von Ereignissen in einem Stream kann entscheidend sein, um zu verstehen, was von einem Moment zum anderen passiert.
Diese Art der zeitreihenbasierten Analyse von Echtzeit-Ereignisströmen kann wichtig sein für reale IoT-Gerätedaten und um zu verstehen, was in Ihren IT-Data-Centern oder bei Finanztransaktionen passiert, wie z. B. bei der Betrugsüberwachung.
Ein Data Mesh mit vollem Funktionsumfang umfasst die grundlegenden Funktionen zur Analyse von Ereignissen aller Art über viele verschiedene Arten von Ereigniszeitfenstern hinweg. Beispiel:
- Einfache Ereignisstreamanalyse (Web-Ereignisse)
- Überwachung der Geschäftsaktivitäten (SOAP/REST-Ereignisse)
- Komplexe Ereignisverarbeitung (Multistream-Korrelation)
- Datenereignisanalyse (bei DB/ACID-Transaktionen)
Wie Datenpipelines kann die Streaming-Analyse in der etablierten Data Lakehouse-Infrastruktur oder separat als Cloud-native Services ausgeführt werden.
Erzielen Sie maximalen Nutzen, indem Sie ein gemeinsames Mesh über den gesamten Datenbestand hinweg betreiben
Diejenigen, die an der Spitze der Datenintegration stehen, streben nach operativer und analytischer Datenintegration in Echtzeit aus einer vielfältigen Sammlung robuster Datenspeicher. Innovationen waren unerbittlich und schnell, als sich die Datenarchitektur zu Streaming-Analysen entwickelte. Die betriebliche High Availability hat zu Echtzeitanalysen geführt, und die Data-Engineering-Automatisierung vereinfacht die Datenvorbereitung, sodass Data Scientists und Analysten Selfservice-Tools nutzen können.
Zusammenfassung der Data Mesh-Anwendungsfälle

Erstellen Sie ein operatives und analytisches Netz über den gesamten Datenbestand
Die Einbindung all dieser Datenverwaltungsfunktionen in eine einheitliche Architektur wird sich auf jeden Datenkonsument auswirken. Ein Data Mesh trägt dazu bei, Ihre globalen Aufzeichnungs- und Interaktionssysteme zu verbessern, damit sie zuverlässig in Echtzeit funktionieren und diese Echtzeitdaten an Geschäftsbereichsleiter, Data Scientists und Ihre Kunden anpassen. Außerdem vereinfacht es das Datenmanagement für Ihre Microservice-Anwendungen der nächsten Generation. Durch den Einsatz moderner Analysemethoden und -tools können Ihre Endbenutzer, Analysten und Data Scientists noch besser auf Kundenanforderungen und Bedrohungen durch die Konkurrenz reagieren. Ein gut dokumentiertes Beispiel finden Sie in den Zielen und Ergebnissen von Intuit.
Profitieren Sie von einem Data Mesh bei Punktprojekten
Wenn Sie Ihre neue Denkweise und Ihr Betriebsmodell für Datenprodukte übernehmen, ist es wichtig, Erfahrungen mit jeder dieser Schlüsseltechnologien zu sammeln. Auf Ihrem Weg zum Data Mesh können Sie inkrementelle Vorteile erzielen, indem Sie Ihre schnelle Datenarchitektur in Streaming-Analysen weiterentwickeln, Ihre betrieblichen High-Availability-Investitionen in Echtzeitanalysen nutzen und Selfservice-Analysen in Echtzeit für Ihre Data Scientists und Analysten bereitstellen.
Vergleich und Gegenüberstellung
| Data Fabric | App-Dev-Integration | Analytischer Datenspeicher | |||||
|---|---|---|---|---|---|---|---|
| Data Mesh | Datenintegration | Metakatalog | Microservices | Messaging | Data Lakehouse | Verteiltes DW | |
| Mitarbeiter, Prozesse und Methoden: | |||||||
| Schwerpunkt Datenprodukt | verfügbar |
verfügbar |
verfügbar |
1/4 Angebot |
1/4 Angebot |
3/4 Angebot |
3/4 Angebot |
| Attribute der technischen Architektur: | |||||||
| Verteilte Architektur | verfügbar |
1/4 Angebot |
3/4 Angebot |
verfügbar |
verfügbar |
1/4 Angebot |
3/4 Angebot |
| Ereignisgesteuerte Ledger | verfügbar |
nicht verfügbar |
1/4 Angebot |
verfügbar |
verfügbar |
1/4 Angebot |
1/4 Angebot |
| ACID-Unterstützung | verfügbar |
verfügbar |
nicht verfügbar |
nicht verfügbar |
3/4 Angebot |
3/4 Angebot |
verfügbar |
| Streamorientiert | verfügbar |
1/4 Angebot |
nicht verfügbar |
nicht verfügbar |
1/4 Angebot |
3/4 Angebot |
1/4 Angebot |
| Fokus auf Analysedaten | verfügbar |
verfügbar |
verfügbar |
nicht verfügbar |
nicht verfügbar |
verfügbar |
verfügbar |
| Fokus auf Betriebsdaten | verfügbar |
1/4 Angebot |
verfügbar |
verfügbar |
verfügbar |
nicht verfügbar |
nicht verfügbar |
| Physisches und logisches Mesh | verfügbar |
verfügbar |
nicht verfügbar |
1/4 Angebot |
3/4 Angebot |
3/4 Angebot |
1/4 Angebot |
Geschäftsergebnisse
Gesamtvorteile
Schnellere, datengesteuerte Innovationszyklen
Geringere Kosten für unternehmenskritische Datenvorgänge
Betriebliche Ergebnisse
Multicloud-Datenliquidität
- Setzen Sie für einen freien Fluss Datenkapital frei
Datenfreigabe in Echtzeit
- Ops-to-Ops und Ops-to-Analytics
Edge, standortbasierte Datenservices
- IRL-Geräte-/Datenereignisse korrelieren
Vertrauenswürdiger Microservices-Datenaustausch
- Event Sourcing mit korrekten Daten
- DataOps und CI/CD für Daten
Ununterbrochene Kontinuität
- >99,999 % Betriebszeit-SLAs
- Cloud-Migrationen
Analyseergebnisse
Datenprodukte automatisieren und vereinfachen
- Datensätze mit mehreren Modellen
Zeitreihendatenanalyse
- Deltas/geänderte Datensätze
- Ereignistreue von Ereignis zu Ereignis
Beseitigung vollständiger Datenkopien für den Betriebsdatenspeicher
- Protokollbasierte Ledger und Pipelines
Verteilte Data Lakes und Warehouses
- Hybrid/Multicloud/global
- Streaming-Integration/ETL
Vorhersageanalyse
- Datenmonetarisierung, neue Datenservices zum Verkauf
Wir fassen zusammen
Die digitale Transformation ist sehr, sehr schwierig und leider werden die meisten Unternehmen daran scheitern. Im Laufe der Jahre werden Technologie, Softwaredesign und Datenarchitektur immer weiter verteilt, da sich moderne Techniken von stark zentralisierten und monolithischen Stilen entfernen.
Data Mesh ist ein neues Konzept für Daten – eine bewusste Verschiebung hin zu stark verteilten und Echtzeit-Datenereignissen im Gegensatz zu einer monolithischen, zentralisierten Datenverarbeitung im Batch-Stil. Im Kern ist Data Mesh ein kultureller Wandel der Denkweise, um die Bedürfnisse der Datenkonsumenten an die erste Stelle zu setzen. Außerdem ist es ein echter Technologiewandel, der die Plattformen und Services verbessert, die eine dezentrale Datenarchitektur ermöglichen.
Anwendungsfälle für Data Mesh umfassen sowohl Betriebsdaten als auch Analysedaten, was einen wesentlichen Unterschied zu herkömmlichen Data Lakes/Lakehouses und Data Warehouses darstellt. Diese Ausrichtung von operativen und analytischen Datendomänen ist ein entscheidender Faktor für die Notwendigkeit, mehr Selfservice für den Datenkonsument zu schaffen. Bei moderner Datenplattformtechnologie entfällt der Mittelsmann, indem Datenproduzenten direkt mit Datenkonsumenten verbunden werden.
Oracle ist seit Langem der Branchenführer bei unternehmenskritischen Datenlösungen und hat einige der modernsten Funktionen eingesetzt, um ein vertrauenswürdiges Data Mesh zu ermöglichen:
- Cloud-Infrastruktur der 2. Generation von Oracle mit mehr als 33 aktiven Regionen
- Datenbank mit mehreren Modellen für „formverändernde“ Datenprodukte
- Microservices-basiertes Datenereignis-Ledger für alle Datenspeicher
- Multicloud-Stream-Verarbeitung für vertrauenswürdige Daten in Echtzeit
- API-Plattform, modernes AppDev und Selfservice-Tools
- Analysen, Datenvisualisierung und Cloud-native Data Science