Enterprise Data Mesh
Solutions, use cases, and case studies
What is data mesh?
A hot topic in enterprise software, data mesh is a new approach to thinking about data based on a distributed architecture for data management. The idea is to make data more accessible and available to business users by directly connecting data owners, data producers, and data consumers. Data mesh aims to improve business outcomes of data-centric solutions as well as drive adoption of modern data architectures.
From the business point of view, data mesh introduces new ideas around “data product thinking.” In other words, thinking about data as a product that fulfils a “job to be done”, for example, to improve decision-making, help detect fraud or alert the business to changes in supply chain conditions. To create high-value data products, companies must address culture and mindset shifts and commit to a more cross-functional approach to business domain modeling.
From the technology side, Oracle’s view on the data mesh involves three important new focus areas for data-driven architecture:
- Tools that provide data products as data collections, data events and data analytics
- Distributed, decentralized data architectures that help organizations who choose to move away from monolithic architectures, towards multi-cloud and hybrid-cloud computing, or who must operate in a globally decentralized manner
- Data in motion for organizations who can’t depend solely on centralized, static, batch-oriented data, and instead move towards event-driven data ledgers and streaming-centric pipelines for real-time data events that provide more timely analytics
Other important concerns such as self-service tooling for non-technical users and strong federated data governance models are just as important for data mesh architecture as they are for other, more centralized and classical data management methodologies.
A new concept for data

A data mesh approach is a paradigm shift to thinking about data as a product. Data mesh introduces organizational and process changes that companies will need to manage data as a tangible capital asset of the business. Oracle’s perspective for the data mesh architecture calls for alignment across organizational and analytic data domains.
A data mesh aims to link data producers directly to business users and, to the greatest degree possible, remove the IT middleman from the projects and processes that ingest, prepare, and transform data resources.
Oracle’s focus on data mesh has been in providing a platform for our customers that can address these emerging technology requirements. This includes tools for data products; decentralized, event-driven architectures; and streaming patterns for data in motion. For data product domain modeling and other sociotechnical concerns, Oracle aligns with the work being done by the thought leader in data mesh, Zhamak Dehghani.
Benefits of a data mesh
Investing in a data mesh can yield impressive benefits, including:
- Total clarity into data’s value through applied data product thinking best practices.
- More than 99.999% operational data availability using microservices-based data pipelines for data consolidation and data migrations.
- 10X faster innovation cycles, shifting away from manual, batch-oriented ETL to continuous transformation and loading (CTL).
- More than 70% reduction in data engineering, gains in CI/CD, no-code and self-serve data pipeline tooling, and agile development.
Data mesh is a mindset and more
Data mesh is still in the early stages of market maturity. So while you may see a variety marketing content about a solution that claims to be “data mesh,” often these so-called data mesh solutions don’t fit the core approach or principles.
A proper data mesh is a mindset, an organizational model, and an enterprise data architecture approach with supporting tools. A data mesh solution should have some mix of data product thinking, decentralized data architecture, domain-oriented data ownership, distributed data-in-motion, self-service access and strong data governance.
A data mesh is not any of the following:
- A vendor product: there is no singular data mesh software product.
- A data lake or data lake-houses: these are complementary and may be a part of larger data mesh that spans multiple lakes, ponds, and operational systems of record.
- A data catalog or graph: A data mesh needs a physical implementation.
- A one-off consulting project: data mesh is a journey, not a single project.
- A self-service analytics product: classical self-serve analytics, data preparation, and data wrangling can be a part of a data mesh as well as other data architectures.
- A data fabric: although conceptually related, the data fabric concept is more broadly inclusive of a variety of data integration and data management styles, whereas data mesh is more associated with decentralization and domain-driven design patterns.
Why data mesh?
The sad truth is that the monolithic data architectures of the past are cumbersome, expensive, and inflexible. Over the years, it’s become clear that most of the time and costs for digital business platform from applications to analytics are sunk into integration efforts. Consequently, most platform initiatives fail.
While data mesh is not a silver bullet for centralized, monolithic data architectures, the principles, practices, and technologies of the data mesh strategy are designed to solve some of the most pressing and unaddressed, modernization objectives for data-driven business initiatives.
Some of the technology trends that led to the emergence of data mesh as a solution include:
- 70-80% of digital transformations fail
- Costs of operational data outages are rising
- Cloud lock-in is real and can become more costly
- Data lakes rarely succeed and are only focused on analytics
- Rise of distributed data is forcing a more effective, efficient, and economic architecture
- Organizational silos worsen data-sharing issues
- Data is the catalyst for competitive edge and it is crucial to manage it well
To learn more about why data mesh is needed today, read Zhamak Dehghani’s original 2019 paper: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
Defining the data mesh
The decentralized strategy behind data mesh aims to treat data as a product by creating a self-service data infrastructure to make data more accessible to business users.
Outcomes focused
Data product thinking- Mindset shift to the data consumer’s point of view
- Data domain owners are responsible for data product KPIs/SLAs
- Same data domain and technology mesh semantics for all
- No more “throwing data over the wall”
- Capture real-time data events directly from systems of record and enable self-service pipelines to deliver data where needed
- An essential capability for enabling decentralized data and source-aligned data products
Rejects monolithic IT architecture
Decentralized architecture- An architecture built for decentralized data, services, and clouds
- Designed to handle all events types, formats and complexity
- Stream processing by default, batch processing by exception
- Built to empower developers and directly connect data consumers to data producers
- Built in security, validation, provenance, and transparency
Oracle capabilities to power a data mesh
When the theory moves to practice it is necessary to deploy enterprise class solutions for mission-critical data; that’s where Oracle can provide a range of trusted solutions to power up an enterprise data mesh.
Create and share data products
- Multi-model data collections with the Oracle converged database, empower "shape shifting" data products in the formats that data consumers require
- Self-service data products as applications or APIs, using Oracle APEX Application Development and Oracle REST Data Services for easy access and sharing of all data
- Single point of access for SQL queries or data virtualization with Oracle Cloud SQL and Big Data SQL
- Data products for machine learning with Oracle's data science platform, Oracle Cloud Infrastructure (OCI) Data Catalog and Oracle's cloud data platform for data lake houses
- Source-aligned data products as real-time events, data alerts, and raw data event services with Oracle Stream Analytics
- Consumer-aligned, self-service data products in a comprehensive Oracle Analytics Cloud solution
Operate a decentralized data architecture
- Agile, ‘service mesh’ style CI/CD for data containers using Oracle pluggable databases with Kubernetes, Docker or cloud-native with Autonomous Database
- Cross-region, multi-cloud, and hybrid-cloud data sync with Oracle GoldenGate microservices and Veridata, for a trusted active-active transaction fabric
- Tap into most application, business processes and Internet of Things (IoT) data events with Oracle Integration Cloud and Oracle Internet of Things Cloud
- Use Oracle GoldenGate or Oracle Transaction Manager for Microservices event queues for microservices event sourcing or real-time ingestion to Kafka and data lakes
- Bring decentralized domain driven design patterns to your service mesh with Oracle Verrazzano, Helidon and Graal VM
3 key attributes of a data mesh
Data mesh is more than just a new tech buzzword. It is newly emerging set of principles, practices, and technology capabilities that make data more accessible and discoverable. The data mesh concept distinguishes itself from prior generations of data integration approaches and architectures by encouraging a shift away from the giant, monolithic enterprise data architectures of the past, towards a modern, distributed, decentralized data-driven architecture of the future. The foundation of the data mesh concept involves the following key attributes:
1. Data product thinking
A mindset shift is the most important first step toward a data mesh. The willingness to embrace the learned practices of innovation is the springboard towards successful modernization of data architecture.
These learned practice areas include:
- Design thinking—a proven methodology for solving "wicked problems," applied to enterprise data domains for building great data products
- Jobs to be done theory——applying a customer-focused innovation and an outcomes-driven innovation process for ensuring that enterprise data products are solving real business problems

Design thinking methodologies bring proven techniques that help break down the organizational silos frequently blocking cross-functional innovation. The jobs to be done theory is the critical foundation for designing data products that fulfill specific end-consumer goals—or jobs to be done—it defines the product’s purpose.
Although the data product approach initially emerged from the data science community, it is now being applied to all aspects of data management. Instead of building monolithic technology architectures, data mesh focuses on the data consumers and the business outcomes.
While data product thinking can be applied to other data architectures, it is an essential part of a data mesh. For pragmatic examples of how to apply data product thinking, the team at Intuit wrote a detailed analysis of their experiences.
Data products
Products of any kind—from raw commodities to items at your local store—are produced as assets of value, intended to be consumed, and have a specific job to be done. Data products can take a variety of forms, depending on the business domain or problem to be solved, and may include:
- Analytics—historic/real-time reports and dashboards
- Data sets—data collections in different shapes/formats
- Models—domain objects, data models, machine learning (ML) features
- Algorithms—ML models, scoring, business rules
- Data services and APIs—docs, payloads, topics, REST APIs, and more
A data product is created for consumption, typically owned outside of IT and requires tracking of additional attributes, such as:
- Stakeholder map—Who owns creates and consumes this product?
- Packaging and documentation—How is it consumed? How is it labeled?
- Purpose and value—What is the implicit/explicit value of the product? Is there depreciation over time?
- Quality and consistency—What are the KPIs and SLAs of usage? Is it verifiable?
- Provenance, lifecycle, and governance—Is there trust and explainability of the data?
2. Decentralized data architecture

Decentralized IT systems are a modern reality, and with the rise of SaaS applications and public cloud infrastructure (IaaS), the decentralization of applications and data is here to stay. Application software architectures are shifting away from the centralized monoliths of the past to distributed microservices (a service mesh). Data architecture will follow the same trend toward decentralization, with data becoming more distributed across a wider variety of physical sites and across many networks. We call this a data mesh.
What is a mesh?
A mesh is a network topology that enables a large group of nonhierarchical nodes to work together collaboratively.
Some common tech examples include:
- WiFiMesh—many nodes working together for better coverage
- ZWave/Zigbee—low-energy smart home device networks
- 5G mesh—more reliable and resilient cell connections
- Starlink—satellite broadband mesh at global scale
- Service mesh—a way to provide unified controls over decentralized microservices (application software)
Data mesh is aligned to these mesh concepts and provides a decentralized way of distributing data across virtual/physical networks and across vast distances. Legacy data integration monolithic architectures, such as ETL and data federation tools—and even more recently, public cloud services, such as AWS Glue—require a highly centralized infrastructure.
A complete data mesh solution should be capable of operating in a multicloud framework, potentially spanning from on-premises systems, multiple public clouds, and even to edge networks.
Distributed security
In a world where data is highly distributed and decentralized, the role of information security is paramount. Unlike highly centralized monoliths, distributed systems must delegate out the activities necessary to authenticate and authorize various users to different levels of access. Securely delegating trust across networks is hard to do well.
Some considerations include:
- Encryption at rest—as data/events that are written to storage
- Distributed authentication—for services and datastores, such as mTLS, certificates, SSO, secret stores, and data vaults
- Encryption in motion—as data/events that are flowing in-memory
- Identity management—LDAP/IAM-type services, cross-platform
- Distributed authorizations—for service end-points to redact data
For example: Open Policy Agent (OPA) sidecar to place policy decision point (PDP) within the container/K8S cluster where the microservice endpoint is processing. LDAP/IAM may be any JWT-capable service. - Deterministic masking—to reliably and consistently obfuscate PII data
Security within any IT system can be difficult, and it is even more difficult to provide high security within distributed systems. However, these are solvable problems.
Decentralized data domains
A core tenet of data mesh is the notion of distribution of ownership and responsibility. The best practice is to federate the ownership of data products and data domains to the people in an organization who are closest to the data. In practice, this may align to source data (for example, raw data-sources, such as the operational systems of record / applications) or to the analytic data (for example, typically composite or aggregate data formatted for easy consumption by the data consumers). In both cases, the producers and consumers of the data are often aligned to business units rather than to IT organizations.
Old ways of organizing data domains often fall into the trap of aligning with the technology solutions , such as ETL tools, data warehouses, data lakes or the structural organization of a company (human resources, marketing and other lines of business). However, for a given business problem the data domains are often best aligned to the scope of the problem being solved, the context of a particular business process, or the family of applications in a specific problem area. In large organizations, these data domains usually cut across the internal organizations and technology footprints.
The functional decomposition of data domains takes on an elevated, first-class priority in the data mesh. Various data decomposition methodologies for domain modeling can be retrofit to data mesh architecture including classical data warehouse modeling (such as Kimball and Inmon) or data vault modeling, but the most common methodology currently being tried in data mesh architecture is domain-driven design (DDD). The DDD approach emerged from microservices functional decomposition and is now being applied in a data mesh context.
3. Dynamic data in motion
An important area where Oracle has added to the data mesh discussion is to elevate the importance of data in motion as a key ingredient to a modern data mesh. Data in motion is a fundamentally essential to take data mesh out of the legacy world of monolithic, centralized, batch-processing. The capabilities of data in motion answer several core data mesh questions, such as:
- How can we access source-aligned data products in real-time?
- What tools can provide the means to distributed trusted data transactions across a physically decentralized data mesh?
- When I need to make data events available as data product APIs, what can I use?
- For analytic data products that must be continuously up to date, how would I align to data domains and ensure trust and validity?
These questions are not just a matter of “implementation details” they are centrally important to the data architecture itself. A domain-driven design for static data will use different techniques and tools than a dynamic, data in motion process of the same design. For example, in dynamic data architectures, the data ledger is the central source of truth for data events.
Event-driven data ledgers

Ledgers are a fundamental component of making a distributed data architecture function. Just as with an accounting ledger, a data ledger records the transactions as they happen.
When we distribute the ledger, the data events become “replayable” in any location. Some ledgers are a bit like an airplane flight recorder that is used for high availability and disaster recovery.
Unlike centralized and monolithic datastores, distributed ledgers are purpose-built to keep track of atomic events and/or transactions that happen in other (external) systems.
A data mesh is not just one single kind of ledger. Depending on the use cases and requirements, a data mesh can make use of different types of event-driven data ledgers, including the following:
- General purpose event ledger—such as Kafka or Pulsar
- Data event ledger—distributed CDC/replication tools
- Messaging middleware—including ESB, MQ, JMS, and AQ
- Blockchain ledger—for secure, immutable, multi-party transactions
Together, these ledgers can act as a sort of durable event log for the whole enterprise, providing a running list of data events happening on systems of record and systems of analytics.
Polyglot data streams

Polyglot data streams are more prevalent than ever. They vary by event types, payloads, and different transaction semantics. A data mesh should support the necessary stream types for a variety of enterprise data workloads.
Simple events:
- Base64 / JSON—raw, schemaless events
- Raw telemetry—sparse events
Basic app logging /Internet of Things (IoT) events:
- JSON/Protobuf— may have schema
- MQTT—IoT-specific protocols
Application business process events:
- SOAP/REST events—XML/XSD, JSON
- B2B—exchange protocols and standards
Data events/transactions:
- Logical change records—LCR, SCN, URID
- Consistent boundaries—commits versus operations
Stream data processing
Stream processing is how data is manipulated within an event stream. Unlike “lambda functions,” the stream processor maintains statefulness of dataflows within a particular time window and can apply much more advanced analytic queries on the data.
- Thresholds, alerts, and telemetry monitoring
- RegEx functions, math/logic, and concatenation
- Record-by-record, substitutions, and masking
Basic data filtering:
Simple ETL:
CEP and complex ETL:
- Complex event processing (CEP)
- DML (ACID) processing and groups of tuples
- Aggregates, lookups, complex joins
Stream analytics:
- Time series analytics and custom time windows
- Geospatial, machine learning and embedded AI
Other important attributes and principles
Of course, there are more than just three attributes of a data mesh. We’ve focused on the three above as a way to bring attention to attributes that Oracle believes are some of the new and unique aspects of the emerging modern data mesh approach.
Other important data mesh attributes include:
- Self-service tooling— data mesh embraces the overall data management trend towards self-service, Citizen developers will must increasingly come from the ranks of the data owners
- Data governance— data mesh has also embraced the long-standing trend toward a more formalized federated governance model as championed by chief data officers, data Stewards and data catalog vendors for many years.
- Data usability — delving in to principles of data mesh, there is quite a lot of foundation work around ensuring that data products are highly usable. Principles for data products will be concerned with data that is valuable, usable, and feasible to share.
7 data mesh use cases
A successful data mesh fulfills use cases for operational as well as analytic data domains. The following seven use cases illustrate the breadth of capabilities that a data mesh brings to enterprise data.
By integrating real-time operational data and analytics, companies can make better operational and strategic decisions.MIT Sloan School of Management
1. Application modernization
Looking beyond 'lift and shift' migrations of monolithic data architectures to the cloud, many organizations also seek to retire their centralized applications of the past and move toward a more modern microservices application architecture.


But legacy applications monoliths typically depend on massive databases, raising the question of how to phase the migration plan to decrease disruption, risks, and costs. A data mesh can provide an important operational IT capability for customers doing phased transitions from monoliths to mesh architecture. For example:
- Sub-domain offloading of database transactions, such as filtering data by 'bounded context'
- Bidirectional transaction replication for phased migrations
- Cross-platform synchronization, such as mainframe to DBaaS
In the lingo of microservices architects, this approach is using a bidirectional transaction outbox to enable the strangler fig migration pattern , one bounded context at a time.
2. Data availability and continuity

Business-critical applications require very high KPIs and SLAs around resiliency and continuity. Regardless of whether these applications are monolithic, microservices or something in between, they can’t go down!
For mission-critical systems, a distributed eventual-consistency data model is usually not acceptable. However, these applications must operate across many data centers. This begs the business continuity question, “How can I run my apps across more than one data center while still guaranteeing correct and consistent data”
Regardless of whether the monolithic architectures are using ‘sharded datasets’ or the microservices are being set up for cross-site high availability, the data mesh offers correct, high-speed data at any distance.
A data mesh can provide the foundation for decentralized, yet 100% correct data across sites. For example:
- Very low latency logical transactions (cross-platform)
- ACID capable guarantees for correct data
- Multi-active, bidirectional, and conflict resolution
3. Event sourcing and transaction outbox


A modern, service mesh–style platform uses events for data interchange. Rather than depending on batch processing in the data tier, data payloads flow continuously when events happen in the application or datastore.
For some architectures, microservices need to exchange data payloads with each other. Other patterns require interchange between monolithic applications or datastores. This begs the question, “How can I reliably exchange microservice data payloads among my apps and datastores?”
A data mesh can supply the foundation technology for microservices-centric data interchange. For example:
- Microservice to microservice within context
- Microservice to microservice across contexts
- Monolith to/from microservice
Microservices patterns, such as event sourcing, CQRS, and transaction outbox, are commonly understood solutions; a data mesh provides the tooling and frameworks to make these patterns repeatable and reliable at scale.
4. Event-driven integration
Beyond microservice design patterns, the need for enterprise integration extends to other IT systems, such as databases, business processes, applications, and physical devices of all types. A data mesh provides the foundation for integrating data in motion.
Data in motion is typically event-driven. A user action, a device event, a process step, or a datastore commit can all initiate an event with a data payload. These data payloads are crucial for integrating Internet of Things (IoT) systems, business processes and databases, data warehouses, and data lakes.
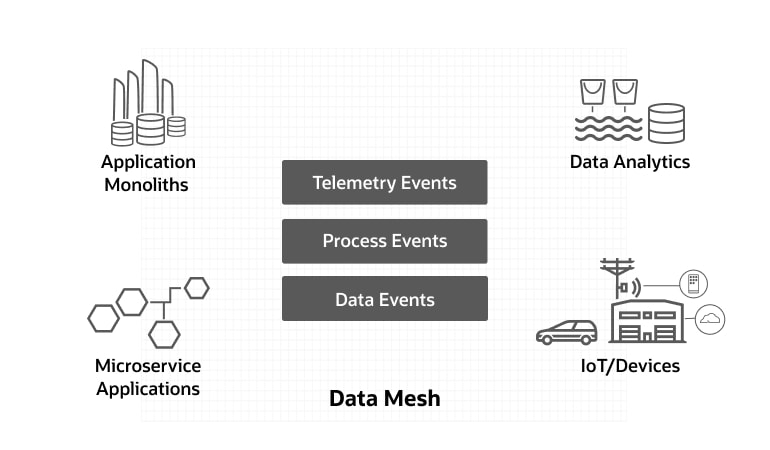
A data mesh supplies the foundation technology for real-time integration across the enterprise. For example:
- Connecting real-world device events to IT systems
- Integrating business processes across ERP systems
- Aligning operational databases with analytic datastores
Large organizations will naturally have a mix of old and new systems, monoliths and microservices, operational and analytic data stores; a data mesh can help to unify these resources across differing business and data domains.
5. Streaming ingest (for analytics)

Analytic data stores may include data marts, data warehouses, OLAP cubes, data lakes, and data lakehouse technologies.
Generally speaking, there are only two ways to bring data into these analytic datastores:
- Batch/micro-batch loading—on a time scheduler
- Streaming ingest—continuously loading data events
A data mesh provides the foundation for a streaming data ingest capability. For example:
- Data events from databases or datastores
- Device events from physical device telemetry
- Application event logging or business transactions
Ingesting events by stream can reduce the impact on the source systems, improve the fidelity of the data (important for data science), and enable real-time analytics.
6. Streaming data pipelines

Once ingested into the analytic datastores, there is usually a need for data pipelines to prepare and transform the data across different data stages or data zones. This data refinement process is often needed for the downstream analytic data products.
A data mesh can provide an independently governed data pipeline layer that works with the analytic datastores, providing the following core services:
- Self-service data discovery and data preparation
- Governance of data resources across domains
- Data preparation and transformation into required data product formats
- Data verification by policy that ensures consistency
These data pipelines should be capable of working across different physical datastores (such as marts, warehouses, or lakes) or as a “pushdown data stream” within analytic data platforms that support streaming data, such as Apache Spark and other data lakehouse technologies.
7. Streaming analytics

Events are continuously happening. The analysis of events in a stream can be crucial for understanding what is happening from moment to moment.
This kind of time-series-based analysis of real-time event streams may be important for real-world IoT device data and for understanding what is happening in your IT data centers or across financial transactions, such as fraud monitoring.
A full-featured data mesh will include the foundational capabilities to analyze events of all kinds, across many different types of event time windows. For example:
- Simple event stream analysis (web events)
- Business activity monitoring (SOAP/REST events)
- Complex event processing (multistream correlation)
- Data event analysis (on DB/ACID transactions)
Like data pipelines, the streaming analytics may be capable of running within established data lakehouse infrastructure, or separately, as cloud native services.
Achieve maximum value by operating a common mesh across the whole data estate
Those at the leading edge of data integration are seeking real-time operational and analytical data integration from a diverse collection of resilient datastores. Innovations have been relentless and fast as data architecture evolves into streaming analytics. Operational high availability has led to real-time analytics, and data engineering automation is simplifying data preparation, enabling data scientists and analysts with self-service tools.
Data mesh use cases summary

Build an operational and analytical mesh across the whole data estate
Putting all these data management capabilities to work into a unified architecture will impact every data consumer. A data mesh will help improve your global systems of record and systems of engagement to operate reliably in real time, aligning that real-time data to line-of-business managers, data scientists, and your customers. It also simplifies data management for your next-generation microservice applications. Using modern analytical methods and tools, your end users, analysts, and data scientists will be even more responsive to customer demand and competitive threats. To read about a well-documented example, see Intuit‘s goals and results.
Benefit from a data mesh on point projects
As you adopt your new data product mindset and operational model it is important to develop experience in each of these enabling technologies. On your data mesh journey, you can achieve incremental benefits by evolving your fast data architecture into streaming analytics, leveraging your operational high-availability investments into real-time analytics, and providing real-time, self-service analytics for your data scientists and analysts.
Compare and contrast
| Data fabric | App-Dev integration | Analytic data store | |||||
|---|---|---|---|---|---|---|---|
| Data mesh | Data integration | Metacatalog | Microservices | Messaging | Data lakehouse | Distributed DW | |
| People, process, and methods: | |||||||
| Data product focus | available |
available |
available |
1/4 offering |
1/4 offering |
3/4 offering |
3/4 offering |
| Technical architecture attributes: | |||||||
| Distributed Architecture | available |
1/4 offering |
3/4 offering |
available |
available |
1/4 offering |
3/4 offering |
| Event Driven Ledgers | available |
not available |
1/4 offering |
available |
available |
1/4 offering |
1/4 offering |
| ACID Support | available |
available |
not available |
not available |
3/4 offering |
3/4 offering |
available |
| Stream Oriented | available |
1/4 offering |
not available |
not available |
1/4 offering |
3/4 offering |
1/4 offering |
| Analytic Data Focus | available |
available |
available |
not available |
not available |
available |
available |
| Operational Data Focus | available |
1/4 offering |
available |
available |
available |
not available |
not available |
| Physical & Logical Mesh | available |
available |
not available |
1/4 offering |
3/4 offering |
3/4 offering |
1/4 offering |
Business outcomes
Overall benefits
Faster, data-driven innovation cycles
Reduced costs for mission-critical data operations
Operational outcomes
Multicloud data liquidity
- Unlock data capital to flow freely
Real-time data sharing
- Ops-to-Ops and Ops-to-analytics
Edge, location-based data services
- Correlate IRL device/data events
Trusted microservices data interchange
- Event sourcing with correct data
- DataOps and CI/CD for data
Uninterrupted continuity
- >99.999% up-time SLAs
- Cloud migrations
Analytic outcomes
Automate and simplify data products
- Multi-model data sets
Time series data analysis
- Deltas/changed records
- Event-by-event fidelity
Eliminate full data copies for operational datastore
- Log-based ledgers and pipelines
Distributed data lakes and warehouses
- Hybrid/multicloud/global
- Streaming integration / ETL
Predictive analytics
- Data monetization, new data services for sale
Bringing it all together
Digital transformation is very, very hard, and unfortunately, most companies will fail at it. Over the years, technology, software design, and data architecture are becoming increasingly more distributed, as modern techniques move away from highly centralized and monolithic styles.
Data mesh is a new concept for data—a deliberate shift toward highly distributed and real-time data events, as opposed to monolithic, centralized, and batch-style data processing. At its core, data mesh is a cultural mindset shift to put the needs of data consumers first. It is also a real technology shift, elevating the platforms and services that empower a decentralized data architecture.
Use cases for data mesh encompass both operational data and analytic data, which is one key difference from conventional data lakes/lakehouses and data warehouses. This alignment of operational and analytic data domains is a critical enabler for the need to drive more self-service for the data consumer. Modern data platform technology can help to remove the middleman in connecting data producers directly to data consumers.
Oracle has long been the industry leader in mission critical-data solutions and has fielded some of the most modern capabilities to empower a trusted data mesh:
- Oracle’s Generation 2 Cloud infrastructure with more than 33 active regions
- Multi-model database for "shape-shifting" data products
- Microservices-based data event ledger for all datastores
- Multicloud stream processing for real-time trusted data
- API platform, modern AppDev, and self-service tools
- Analytics, data visualization, and cloud native data science