Risicoberekening en wettelijk verplichte rapportage verbeteren

Uitdagingen bij wettelijk verplichte rapportage
De rapportagevereisten van toezichthouders worden wereldwijd steeds complexer. Dit leidt tot een sterke stijging van de kosten en middelen voor de wettelijk verplichte rapportage over de afgelopen jaren. Financiële bedrijven vinden het lastig om de continue veranderingen te volgen. Ze moeten daarom manieren vinden om de steeds bredere eisen voor data efficiënter en nauwkeuriger te vervullen en onderwijl hun data-architectuur strategisch ontwikkelen om de prestaties te verbeteren en groei te stimuleren.
Veel financiële dienstverleners moeten nog steeds veel tijd en geschoold personeel inzetten om al hun wettelijk verplichte rapportages op te stellen. Zonder een geautomatiseerd systeem dat kwaliteitscontroles uitvoert en datasilo's elimineert, kunnen banken niet erop vertrouwen dat ze correcte officiële rapporten indienen. Of ze moeten ook nog eens vele uren besteden aan controle van de rapporten. Een andere uitdaging is toegang tot data op het gewenste detailniveau. Dit komt doordat verschillende systemen data op verschillende niveaus vastleggen. In leningssystemen worden bijvoorbeeld data vastgelegd op het niveau van rekeningen en transacties, terwijl in systemen voor het initiëren van leningen dit gebeurt op het niveau van aanvragen. En in creditcardsystemen gaat het allemaal weer op niveau van kaarten en transacties. Als financiële instellingen hun data op een consistent detailniveau kunnen analyseren, krijgen ze volledig inzicht in hun bedrijfsvoering, klanten en markten. Zo kunnen ze data in de context zien en relaties, patronen en trends identificeren die ze mogelijk over het hoofd zien als de data op een inconsistente manier worden geaggregeerd of gedeaggregeerd.
Om deze problemen op te lossen, definiëren financiële dienstverleners hun benadering van risicoberekening, verplichte rapportage en naleving opnieuw, als een holistisch proces. Ze zoeken een vorm van automatisering en governance die het proces van begin tot eind dekt, van vastleggen en analyseren van data tot rapportage, inclusief de uiteindelijke indiening bij de toezichthouders.
Compliance en risico's effectiever beheren met machine learning en AI
De volgende architectuur toont hoe we componenten en functionaliteiten van Oracle, zoals geavanceerde analyse, AI en machine learning, kunnen combineren tot een uitgebreid dataplatform voor verplichte rapportage en risicoberekening dat de integratie van data, datakwaliteit, standaardisatie, verwerking, herkomst en flexibiliteit vergemakkelijkt. Het dataplatform biedt financiële instellingen een robuuste basis waarmee ze kunnen voldoen aan wettelijke vereisten, op tijd nauwkeurige rapporten kunnen maken en effectieve risicoberekeningen kunnen uitvoeren.
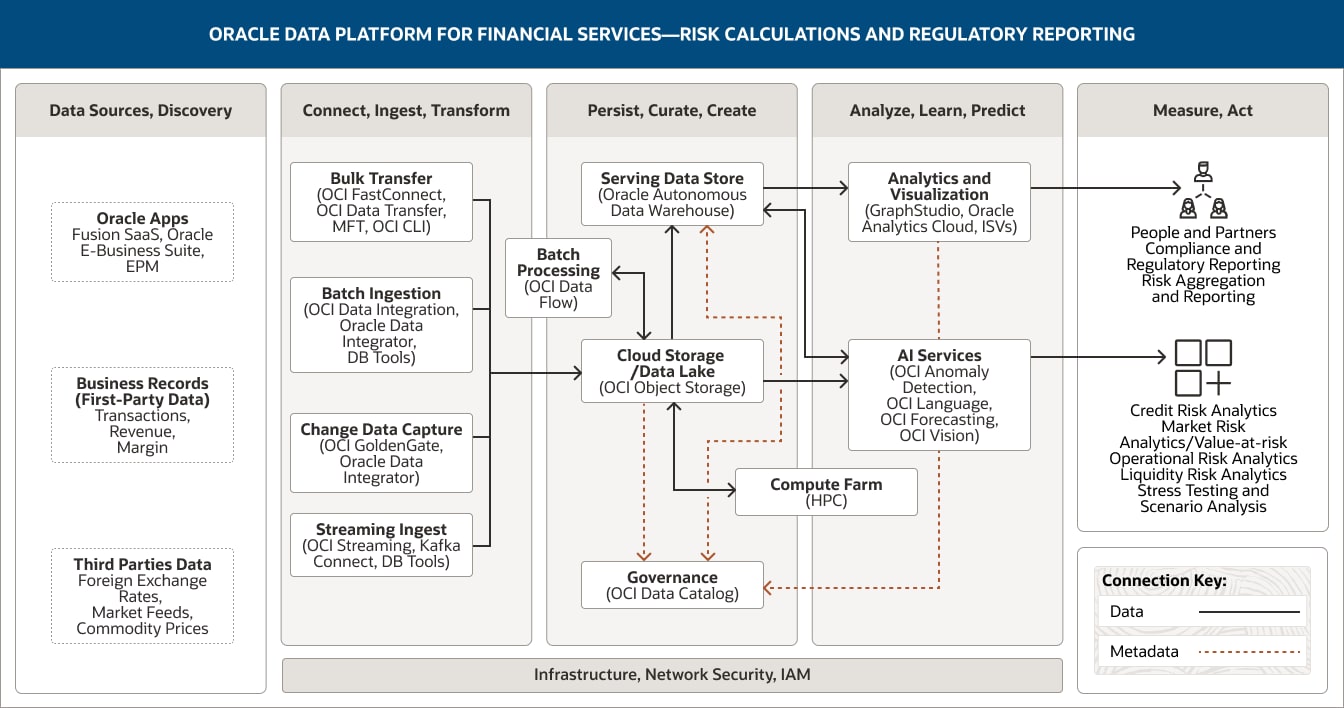
In deze afbeelding ziet u hoe het Oracle-dataplatform voor de gezondheidszorg kan worden toegepast om zorg op basis van waarde te ondersteunen met prestatiebewaking. Het platform omvat deze vijf pijlers:
- 1. Databronnen, discovery
- 2. Opnemen, transformeren
- 3. Persistent maken, samenstellen, maken
- 4. Analyseren, leren, voorspellen
- 5. Meten, handelen
De pijler Databronnen, discovery omvat drie categorieën data.
- 1. Oracle Apps omvat Fusion SaaS, Oracle E-Business Suite en EPM.
- 2. Bedrijfsrecords (eigen data) bestaat uit transacties, omzet en marge.
- 3. Externe data omvat data voor wisselkoersen, marktfeeds en grondstoffenprijzen.
De pijler Opnemen, transformeren omvat vier functionaliteiten.
- 1. Bulkoverdracht maakt gebruik van OCI FastConnect, OCI Data Transfer, MFT en OCI CLI.
- 2. Batchopname maakt gebruik van OCI Data Integration, Oracle Integration Cloud en Data Studio.
- 3. Wijzigingsdata vastleggen maakt gebruik van OCI GoldenGate en Oracle Data Integrator.
- 4. Streamingopname maakt gebruik van OCI Streaming, Kafka Connect en DB Tools.
Alle vier functionaliteiten verbinden unidirectioneel door naar de cloudopslag in de pijler Persistent maken, samenstellen, maken.
De pijler Persistent maken, samenstellen, maken omvat vijf functionaliteiten.
- 1. De aanbiedende dataopslag maakt gebruik van Autonomous Data Warehouse.
- 2. Rekenclusters maakt gebruik van HPC.
- 3. Cloudopslag maakt gebruik van OCI Object Storage.
- 4. Batchverwerking maakt gebruik van OCI Data Flow.
- 5. Governance maakt gebruik van OCI Data Catalog.
Deze functionaliteiten verbinden binnen de pijler onderling naar elkaar door. Cloudopslag/Data Lake verbindt unidirectioneel door naar de aanbiedende dataopslag en ook bidirectioneel naar Batchverwerking en Rekenclusters.
Twee functionaliteiten verbinden door naar de pijler Analyseren, leren, voorspellen: de aanbiedende dataopslag verbindt unidirectioneel door naar de functionaliteit Analyse en visualisatie en bidirectioneel naar de functionaliteit AI-services. Cloudopslag verbindt door naar de functionaliteit AI-services.
De pijler Analyseren, leren, voorspellen omvat drie functionaliteiten.
- 1. Analyse en visualisatie maakt gebruik van GraphStudio, Oracle Analytics Cloud en ISV's.
- 2. AI-services omvat OCI Anomaly Detection, OCI Language, OCI Forecasting en OCI Vision.
- 3. De aanbiedende dataopslag, Analyse en visualisatie en Objectopslag leveren metadata aan de OCI Data Catalog.
In de pijler Meten, handelen wordt vastgelegd hoe de data-analyse kan worden toegepast ter ondersteuning van een oplossing voor risicoberekening en verplichte rapportage. Deze toepassingen worden in twee groepen verdeeld.
- 1. De eerste groep, “Mensen en partners”, omvat compliance en verplichte rapportage naast risico-aggregatie en -rapportage.
- 2. De tweede groep, "Applicaties", omvat analyse van kredietrisico en marktrisico's, van potentieel verlies, van operationeel risico, van liquiditeitsrisico en stresstests en scenarioanalyse.
De drie centrale pijlers, Opnemen, transformeren; Persistent maken, samenstellen, maken; en Analyseren, leren, voorspellen, worden ondersteund door infrastructuur, netwerk, beveiliging en IAM.
Er zijn drie belangrijke manieren om data in een architectuur in te voegen, zodat financiële dienstverleners processen voor risicoberekening en verplichte rapportage kunnen stroomlijnen en de nauwkeurigheid kunnen verbeteren.
- Allereerst moeten we data opnemen vanuit transactiesystemen en de kernapplicaties voor bankieren. Deze data kunnen vervolgens worden verrijkt met klantdata uit externe bronnen, zoals ongestructureerde data uit sociale media. Frequente extracties van real time of bijna real time data waarvoor wijzigingsdata vastleggen is vereist, komen vaak voor. Data worden regelmatig door middel van Oracle Cloud Infrastructure (OCI) GoldenGate overgenomen uit transactie-, risico- en klantbeheersystemen. OCI GoldenGate is ook een cruciale component van zich ontwikkelende data mesh-architecturen. Hierin worden "dataproducten" beheerd via ondernemingsdatagrootboeken en meertalige datastromen, die continue transformatie- en laadprocessen uitvoeren (in plaats van de batchprocessen voor opname, extractie, transformatie en laden die worden gebruikt in monolithische architecturen).
- We kunnen nu door middel van streamingopname realtime handelsdata opnemen. Wanneer bijvoorbeeld een transactie wordt uitgevoerd, worden alle bijbehorende data opgenomen en vervolgens geïmplementeerd om rekeningen en grootboeken bij te werken, risico's opnieuw te berekenen en vereffeningsprocessen op te starten. Deze data worden opgenomen in ongestructureerde (onbewerkte) vorm via de HDFS/S3-connector voor persistentie op de lange termijn. Enkele basale transformaties/aggregaties worden uitgevoerd voordat de data in de cloudopslag worden opgeslagen. Parallel aan de opname kunnen we met streaminganalyses in realtime grote hoeveelheden data uit meerdere bronnen filteren, aggregeren, correleren en analyseren. Daarmee kunnen financiële instellingen bedreigingen en risico's voor hun bedrijfsvoering opsporen. Correlerende gebeurtenissen en geïdentificeerde patronen kunnen (handmatig) weer in het systeem worden ingevoerd. De onbewerkte data kunnen worden onderzocht met behulp van OCI Data Science. Bovendien kunnen events worden gegenereerd om acties te triggeren. Deze acties kunnen rechtstreeks op de klant gericht zijn, zoals klanten via e-mail of sms informeren over mogelijke fraude of gehackte debetkaarten blokkeren. Of ze kunnen interne processen stroomlijnen, bijvoorbeeld door het complianceteam te melden dat een potentieel probleem is gevonden. OCI GoldenGate Stream Analytics is een in-memory technologie die in real time analytische berekeningen uitvoert op streamingdata.
- Toegang tot historische prestatiedata, trends en patronen is nodig om risico's correct te kunnen begrijpen en voorspellen. Hiervoor moet meestal een groot volume transactiedata en andere operationele metrics en datasets (zoals marktdata en grondstofprijzen) worden geladen uit lokale dataopslagplaatsen, met behulp van methoden en services voor overdracht in bulk zoals OCI Data Transfer Service.
- De behoeften aan realtime data ontwikkelen zich steeds verder. Maar de meest voorkomende methode om data te extraheren uit kernsystemen voor bankieren, klanten en financiële diensten is nog steeds een batchopnamedoor middel van een ETL-proces (extractie, transformatie, laden). Batchopname wordt vaak gebruikt om data te importeren uit systemen die geen streamingopname ondersteunen, bijvoorbeeld oudere mainframesystemen, of data die niet noodzakelijk in real time moeten worden geanalyseerd, zoals lening- en hypotheekdata. Deze data zijn zeer gestructureerd en kennen een hoge mate van datakwaliteit/integriteit. Ze worden vaak in bulk verwerkt door de transactieapplicatie/het transactiesysteem volgens een specifiek schema, bijvoorbeeld per uur om 15 minuten na het uur of dagelijks op het middaguur. Voor complexe processen kunnen deze periodes langer zijn. Opname in bulk nadat verwerking van de brondata is voltooid, is de efficiëntste manier om data op te nemen voor wat betreft rekenkracht en netwerkbelasting. Batchopname kan vaak gebeuren, bijvoorbeeld elke 10 of 15 minuten. Deze opnamen zijn echter nog steeds batchbewerkingen, omdat hierin groepen transacties worden geëxtraheerd en verwerkt in plaats van afzonderlijke transacties. OCI biedt verschillende services voor de verwerking van batchopnamen, zoals de native OCI Data Integration-service of Oracle Data Integrator, die wordt uitgevoerd op een OCI Compute-instance. Afhankelijk van de volumes en datatypen kunnen data in een objectopslag worden geladen of rechtstreeks in een gestructureerde relationele database voor persistente opslag.
Datapersistentie en -verwerking zijn gebaseerd op drie (optioneel vier) componenten.
- Opgenomen onbewerkte data worden in cloudopslag opgeslagen voor algoritmische doeleinden. OCI Object Storage wordt gebruikt als de primaire datapersistentielaag. Spark in OCI Data Flow is de primaire batchverwerkingsengine voor data zoals transactie-, locatie-, applicatie- en geomapppingdata. Batchverwerking omvat diverse activiteiten, zoals uitfilteren van ruis, beheer van ontbrekende data en filteren op basis van gedefinieerde uitgaande datasets. Resultaten worden op basis van de benodigde verwerking en de gebruikte datatypen teruggeschreven naar verschillende lagen in de objectopslag of naar een persistente relationele repository.
- Deze verwerkte datasets worden geretourneerd naar de cloudopslag voor verdere persistentie, samenstelling en analyse. Uiteindelijk worden ze in geoptimaliseerde vorm geladen in de aanbiedende dataopslag, die hier wordt verzorgd door Oracle Autonomous Data Warehouse. De data is nu persistent gemaakt in geoptimaliseerde relationele vorm, voor beheer en beste queryprestaties. Afhankelijk van de voorkeur voor de architectuur kan dit ook worden bereikt met Oracle Big Data Service als een beheerde Hadoop-cluster. In dit gebruiksscenario zijn alle data waarmee de machine learning-modellen worden getraind, in onbewerkte vorm toegankelijk vanuit de objectopslag. Om de modellen te trainen worden historische patronen gecombineerd met records op transactieniveau, om potentiële risico's te identificeren en te labelen. Als we deze datasets combineren met andere, zoals apparaatdata en geografische data, kunnen we technieken uit de datawetenschap toepassen om bestaande modellen te verfijnen en nieuwe te ontwikkelen en zo risico's beter te beheren en te voorspellen. Met dit type persistentie kunnen data ook worden opgeslagen voor schema's die deel uitmaken van de dataopslagplaatsen die worden gelezen via externe tabellen en hybride partities.
- Zoals beschreven in de de paragraaf over opname, werken financiële dienstverleners met enorme hoeveelheden data, zoals historische marktdata, realtime transactiedata, economische indicatoren en nog veel meer. Met High Performance Computing (HPC) kunnen we grote datasets efficiënt verwerken en analyseren, wat uitgebreide risicobeoordeling mogelijk maakt. Voor het voorspellen van financiële risico's gebruiken we complexe wiskundige en statistische modellen, zoals Monte Carlo-simulaties, optieprijsmodellen en risicofactormodellen. Voor deze modellen is een aanzienlijke rekenkracht vereist om de berekeningen en simulaties nauwkeurig en snel uit te voeren. HPC-systemen in een rekencluster bieden de benodigde rekenresources waarmee we deze complexe modellen op zeer resource-efficiënte wijze kunnen verwerken door de principes van cloudcomputing toe te passen.
Het vermogen om te analyseren, te leren en te voorspellen is gebaseerd op drie technologieën.
- Services voor Analyse en visualisatie, zoals Oracle Analytics Cloud, leveren analyses op basis van samengestelde data uit de aanbiedende dataopslag . Dit omvat beschrijvende analyses (beschrijven de actuele trends voor risico-identificatie en gemarkeerde activiteit met histogrammen en grafieken), voorspellende analyses, zoals tijdreeksanalyse (voorspellen toekomstige patronen, identificeren trends en bepalen de waarschijnlijkheid van onzekere resultaten) en sturende analyses (stellen passende acties voor ter ondersteuning van optimale besluitvorming). Met deze analyses kunnen vragen worden beantwoord zoals: hoe verhoudt het gemarkeerde risico in deze periode zich tot het risico in eerdere perioden?
- Naast de geavanceerde analyses worden machine learning-modellen ontwikkeld, getraind en geïmplementeerd. Deze getrainde modellen kunnen worden uitgevoerd op zowel actuele als historische transactiedata. Dit helpt financiële organisaties risico's beter te voorspellen en te beheren, bijvoorbeeld door transactie- en gedragspatronen te koppelen om witwassen van geld te detecteren. De resultaten kunnen persistent worden gemaakt op de actieve laag en gerapporteerd met behulp van analyseprogramma's zoals Oracle Analytics Cloud. Om de training van het model te optimaliseren, kunnen het model en de data ook worden ingevoerd in machine learning-systemen zoals OCI Data Science. Daarin wordt het model verder getraind op een effectievere risicoanalyse. Deze modellen zijn toegankelijk via API's, zijn geïmplementeerd in de respectievelijke dataopslag of zijn geïntegreerd in de OCI GoldenGate pijplijn voor streaming van analyses.
- Daarnaast kunnen we de geavanceerde functionaliteiten van cloud-native services voor artificial intelligence gebruiken.
- OCI Anomaly Detection is een AI-service waarmee u eenvoudig bedrijfsspecifieke anomaliedetectiemodellen kunt bouwen. Deze kunnen kritieke incidenten markeren en zo de detectie en afhandeling ervan helpen versnellen. In dit gebruiksscenario zouden we deze modellen implementeren om non-compliance te identificeren en niet-naleving van IFRS 9 en IFRS 17, CECL, LDTI, OECD, Basel en andere normen en vereisten te bewaken. Deze identificatie kan samen met historische oplossingsdata worden gebruikt voor herstel en verbetering van processen. Voor risicobeoordeling, waaronder beoordeling van krediet-, liquiditeits-, markt- en bedrijfsrisico's, kan OCI Anomaly Detection worden gebruikt. Dit bewaakt de prestatiemetrics om ervoor te zorgen dat de huidige prestaties en transacties het algehele risico niet verhogen.
- We kunnen ook met behulp van OCI Anomaly Detection het aantal conforme/niet-conforme voorvallen per categorie controleren. Dit helpt te bepalen of een specifieke wijziging in het bedrijf ongebruikelijke compliance-escalaties veroorzaakt. Daarnaast kan OCI Anomaly Detection helpen de hoofdoorzaak van non-compliance te identificeren door de toepassing van nalevingsregels te monitoren. Hiermee wordt gecontroleerd of in recente transacties abnormaal gebruik is gedetecteerd.
- Met OCI Forecasting kunnen prestatiemetrics worden voorspeld, evenals externe factoren zoals marktcondities en gedrag van klanten. Daarmee kan de kans op risico's worden geanalyseerd en kunnen deze mogelijk worden aangewezen.
- Met OCI Language en OCI Vision kunnen documenten en tekst worden ingevoerd, om data voor risicobeheer te verrijken.
- Een andere cruciale component is datagovernance. Dit wordt mogelijk gemaakt door OCI Data Catalog. Dit is een gratis service voor datagovernance en beheer van metadata (voor zowel technische als zakelijke metatadata) voor alle databronnen in het data lakehouse-ecosysteem. OCI Data Catalog is ook een cruciale component voor query's vanuit Oracle Autonomous Data Warehouse naar OCI Object Storage, doordat hiermee snel data kan worden opgespoord, ongeacht op welke wijze deze is opgeslagen. Dit maakt het mogelijk voor eindgebruikers, ontwikkelaars en datawetenschappers om met een gezamenlijke querytaal (SQL) te werken in alle persistente dataopslagen binnen de architectuur.
- Uiteindelijk kunnen onze samengestelde, geteste, hoogwaardige en beheerde data en modellen beschikbaar worden gesteld als een dataproduct (API) in een data mesh-architectuur, voor distributie binnen de organisatie van de financiële dienstverlener.
Risicoberekening en verplichte rapportage verbeteren met het juiste dataplatform
Met Oracle Data Platform kunnen financiële dienstverleners de snelle ontwikkelingen op gebied van risicobeheer en verplichte rapportage bijhouden, de toenemende complexiteit van rapportagevereisten van toezichthouders over de hele wereld beheren en ervoor zorgen dat ze op het juiste detailniveau toegang hebben tot data. De oplossing van Oracle biedt een geïntegreerde omgeving en een geïntegreerd kader voor het beheer van risicodata. Hiermee zijn organisaties minder tijd kwijt aan de voorbereiding van wettelijk verplichte rapporten. Met een geautomatiseerde oplossing die kwaliteitsregels toepast en datasilo's elimineert, kunnen organisaties met vertrouwen hun verplichte rapporten indienen en de risico's beter begrijpen, beheren en minimaliseren.
Gerelateerde bronnen
-
Gebruiksscenario
360-graden klantinzichten voor financiële dienstverlening
Ontdek hoe u de eisen van klanten beter vervult met 360-graden klantinzichten via een geavanceerd dataplatform.
-
Gebruiksscenario
Bedrijfsvoering en prestaties in de financiële sector stimuleren
Ontdek hoe u uw activiteiten in de financiële dienstverlening efficiënter kunt beheren met een dataplatform dat prestaties helpt verbeteren met machine learning.
-
Gebruiksscenario
Fraudepreventie en anti-witwasmethoden
Ontdek in dit gebruiksscenario hoe Oracle Data Platform voor financiële dienstverlening u helpt risico's te verminderen, fraude-detectie en naleving te verbeteren.
Aan de slag
Probeer meer dan 20 'Altijd gratis'-cloudservices uit, met een proefversie van 30 dagen voor nog meer
Oracle biedt een Free Tier zonder tijdslimiet voor meer dan 20 services zoals Autonomous AI Database, computing op ARM en storage, evenals USD 300 aan gratis tegoed om extra cloudservices uit te proberen. Lees de informatie en meld u vandaag nog aan voor uw gratis account.
-
Wat is inbegrepen in Oracle Cloud Free Tier?
- Twee Autonomous AI Database instances, elk 20 GB
- Compute VM's van AMD en Arm
- 200 GB totale blokopslag
- 10 GB objectopslag
- 10 TB uitgaande dataoverdracht per maand
- Meer dan 10 extra 'Altijd gratis'-services
- $ 300 aan gratis tegoed voor 30 dagen voor nog meer
Leer met stapsgewijze begeleiding
Ervaar een breed scala aan OCI-services via zelfstudies en praktijklabs. Of u nu een ontwikkelaar, beheerder of analist bent, wij kunnen u laten zien hoe OCI werkt. Veel labs draaien op de Oracle Cloud Free Tier of een door Oracle geleverde gratis labomgeving.
-
Aan de slag met OCI Core Services
De labs in deze workshop bevatten een inleiding tot de kernservices van Oracle Cloud Infrastructure (OCI), waaronder virtuele cloudnetwerken (VCN) en compute- en opslagservices.
Start nu het lab voor OCI-kernservices -
Snel aan de slag met Autonomous AI Database
In deze workshop doorloopt u de stappen om aan de slag te gaan met Oracle Autonomous AI Database.
Begin nu aan het lab Snel aan de slag met Autonomous AI Database -
Een app bouwen vanuit een spreadsheet
Dit lab begeleidt u bij het uploaden van een spreadsheet naar een Oracle Database tabel en het maken van een applicatie op basis van deze nieuwe tabel.
Start deze training nu
Ontdek meer dan 150 best practices
Bekijk hoe onze architecten en andere klanten een breed scala aan workloads implementeren, van bedrijfsapps tot HPC, van microservices tot data lakes. Begrijp de best practices, hoor over andere architecten van klanten in onze reeks 'Built & Deployed' en implementeer veel workloads met onze 'click-to-deploy'-functie, of doe dit zelf vanuit onze GitHub-repository.
Populaire architecturen
- Apache Tomcat met MySQL Database Service
- Oracle Weblogic op Kubernetes met Jenkins
- Machine learning (ML)- en AI-omgevingen
- Tomcat op ARM met Oracle Autonomous AI Database
- Loganalyse met ELK-stack
- HPC met OpenFOAM
Bekijk hoeveel u kunt besparen op OCI
De prijsbepaling voor Oracle Cloud is eenvoudig, met wereldwijd consistente lage prijzen, met ondersteuning voor een breed scala aan gebruiksdoelen. Ga naar de kostencalculator voor een schatting van uw lage tarief en kies en configureer de services die u nodig hebt.
Ervaar het verschil:
- Een kwart van de kosten voor uitgaande bandbreedte
- Drie keer betere Compute prijs-prestatieverhouding
- Zelfde lage prijs in elke regio
- Lage prijzen zonder langetermijnverplichtingen
Neem contact op met de verkooporganisatie
Wilt u meer weten over Oracle Cloud Infrastructure? Laat een van onze experts u helpen.
-
Ze kunnen vragen beantwoorden zoals:
- Welke workloads draaien het beste op OCI?
- Hoe profiteer ik optimaal van Oracle investeringen?
- Wat zijn de voordelen van OCI ten opzichte van andere cloudcomputing-providers?
- Hoe kan OCI uw IaaS- en PaaS-doelen ondersteunen?