Operationele efficiëntie en prestaties in de productiesector stimuleren

Productie, kwaliteit en duurzaamheid verbeteren met geavanceerde analyses
Voor de productiesector is het gebruik van data om de operationele efficiëntie en prestaties te verbeteren bijzonder relevant. Dit komt doordat dit gebruiksscenario kan worden toegepast op alle soorten productiesystemen, zoals geautomatiseerde CNC-infrastructuur, supply chain- en magazijnsystemen, logistieke systemen en testsystemen, enzovoort.
Fabrikanten richtten zich van oudsher op historische beschrijvende en diagnostische metrics, maar nu beginnen ze geavanceerde analyses, machine learning en datawetenschap toe te passen om prestatieverbeteringen te meten en proactieve, voorspellende en sturende aanbevelingen te ontwikkelen.
Dit gebruiksscenario is gericht op de dataplatformarchitectuur die nodig is om data op te nemen, op te slaan, te beheren en er inzichten uit te verkrijgen. Het betreft hier data die worden geproduceerd door MES's (Management Execution-systemen), magazijnbeheersystemen (WHMS's), geautomatiseerde onderhoudsbeheersystemen (CMMS's) en onderhoudssystemen voor het meten van de operationele efficiëntie van apparatuur, lijnen en fabrieken en ook prestatiemetrics.
Door data over productieprocessen en prestaties op te nemen, samen te stellen en te analyseren, kunnen producenten knelpunten en inefficiënties identificeren en elimineren. Dit helpt hen de productieplanning te optimaliseren en de productie te verhogen. Als ze dezelfde benadering toepassen op data over productkwaliteit, kunnen fabrikanten patronen en de onderliggende oorzaken van defecten identificeren. Dit helpt hen effectievere maatregelen voor kwaliteitscontrole door te voeren. Als ze ook data over energieverbruik opnemen, kunnen fabrikanten bovendien gebieden identificeren waar zij het energieverbruik kunnen reduceren, wat de kosten verlaagt en duurzaamheid bevordert.
Predictief onderhoud optimaliseren en kosten reduceren met een alomvattend dataplatform
De hier getoonde architectuur laat zien hoe we aanbevolen Oracle-componenten kunnen worden gecombineerd tot een analyse-architectuur die de hele levenscyclus van data-analyse omvat, van discovery tot actie en metingen. Dit helpt fabrikanten de hierboven beschreven uiteenlopende zakelijke voordelen te behalen.
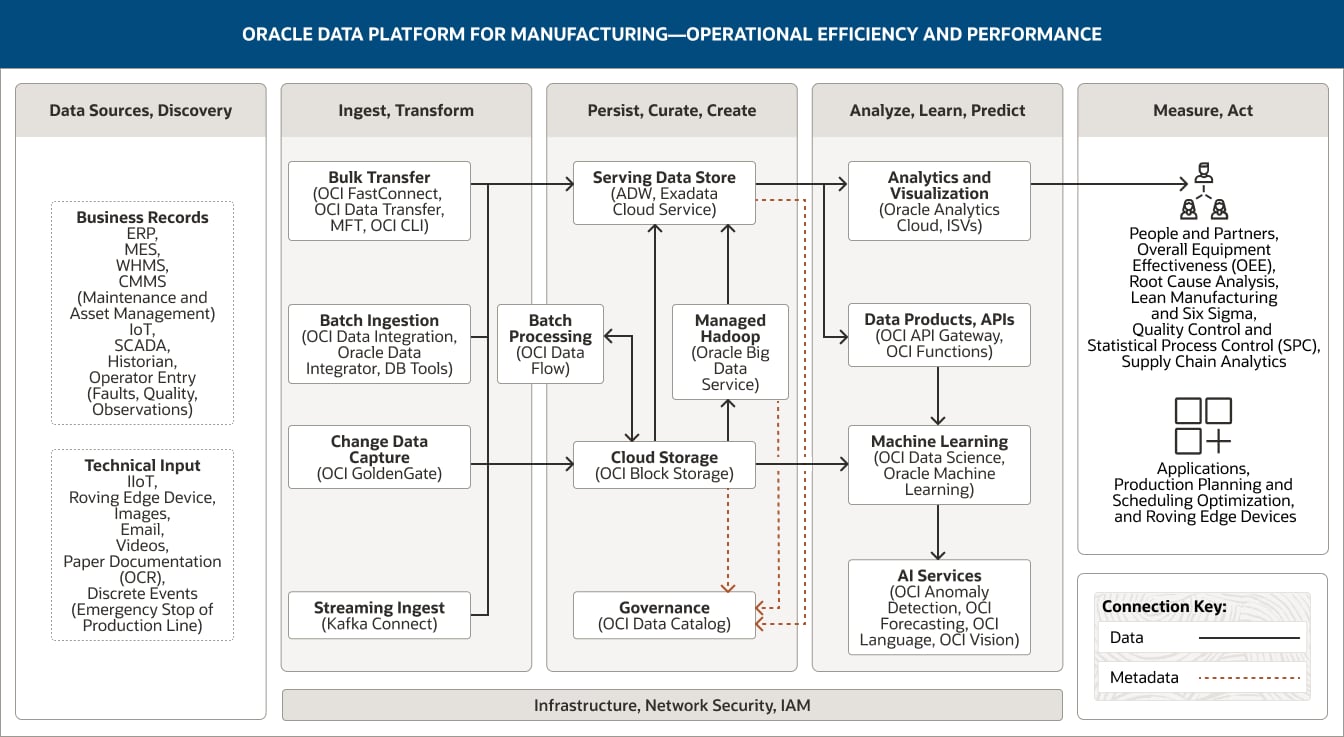
In deze afbeelding ziet u hoe het Oracle-dataplatform voor productiebedrijven kan worden toegepast om operationele efficiëntie en prestaties te ondersteunen. Het platform omvat deze vijf pijlers:
- 1. Databronnen, discovery
- 2. Opnemen, transformeren
- 3. Persistent maken, samenstellen, maken
- 4. Analyseren, leren, voorspellen
- 5. Meten, handelen
De pijler Databronnen, discovery omvat drie categorieën data.
- 1. Data in Oracle App omvat data uit Fusion SaaS, Oracle E-Business Suite, CX
- 2. Bedrijfsrecords (eigen data), CRM, Transacties, Rekening informatie, Omzet en Marge
- 3. Externe data omvat wisselkoersen, marktfeeds en grondstoffenprijzen.
De pijler Opnemen, transformeren omvat vier functionaliteiten.
- 1. Batchopname maakt gebruik van OCI Data Integration, Oracle Data Integrator en databasetools.
- 2. Bulkoverdracht maakt gebruik van OCI FastConnect, OCI Data Transfer, MFT en OCI CLI.
- 3. Wijzigingsdata vastleggen maakt gebruik van OCI GoldenGate.
- 4. Streamingopname maakt gebruik van OCI Streaming Kafka Connect.
Alle vier functionaliteiten verbinden unidirectioneel door naar de aanbiedende dataopslag en cloudopslag in de pijler Persistent maken, samenstellen, maken.
Bovendien verbindt streamingopname door naar de stroomverwerking binnen de pijler Analyseren, leren, voorspellen.
De pijler Persistent maken, samenstellen, maken omvat vijf functionaliteiten.
- 1. De aanbiedende dataopslag maakt gebruik van Oracle Autonomous Data Warehouse en Exadata Cloud Service.
- 2. Cloudopslag maakt gebruik van OCI Object Storage.
- 3. Beheerd Hadoop maakt gebruik van Oracle Big Data Service.
- 4. Batchverwerking maakt gebruik van OCI Data Flow.
- 5. Governance maakt gebruik van OCI Data Catalog.
Deze functionaliteiten verbinden binnen de pijler onderling naar elkaar door. Cloudopslag verbindt unidirectioneel door naar de aanbiedende dataopslag en ook bidirectioneel naar Batchverwerking.
Twee functionaliteiten verbinden door naar de pijler Analyseren, leren, voorspellen. De aanbiedende dataopslag verbindt door naar de functionaliteiten Analyse en visualisatie en naar de functionaliteit Dataproducten, API's. Cloudopslag verbindt door naar de functionaliteit Machine learning.
De pijler Analyseren, leren, voorspellen omvat twee functionaliteiten.
- 1. Analyse en visualisatie maakt gebruik van Oracle Analytics Cloud, GraphStudio en ISV's.
- 2. Machine learning maakt gebruik van Oracle Machine Learning.
De pijler Meten, Handelen vermeldt hoe data-analyse kan worden gebruikt: door mensen en partners.
Mensen en partners omvat Operationele efficiëntie (verwerkingstijden, foutpercentages, resourcegebruikt), Identificatie van procesknelpunten, Waarde levensduur klant, Markt- en concurrentieanalyse, Prestatietoeschrijving.
De drie centrale pijlers, Opnemen, transformeren; Persistent maken, samenstellen, maken; en Analyseren, leren, voorspellen, worden ondersteund door infrastructuur, netwerk, beveiliging en IAM.
Verbinding maken met data, ze opnemen en transformeren
Onze oplossing bestaat uit drie pijlers, die elk specifieke dataplatformfunctionaliteiten ondersteunen. De eerste pijler biedt de functionaliteit om verbinding te maken met data, ze op te nemen en te transformeren.
Er zijn vier belangrijke manieren om data in een architectuur in te voegen, zodat productiebedrijven hun operationele efficiëntie en prestaties kunnen verbeteren.
- Het proces start met het inschakelen van de bulkoverdracht van operationele transactiedata. Services voor bulkoverdracht worden gebruikt in situaties waarin grote hoeveelheden data voor het eerst naar Oracle Cloud Infrastructure (OCI) moeten worden overgebracht, zoals data uit bestaande lokale analyserepository's of andere cloudbronnen. Welke specifieke service voor bulkoverdracht we gebruiken, is afhankelijk van de locatie van de data en de frequentie waarmee ze moeten worden overgedragen. We kunnen bijvoorbeeld OCI Data Transfer Service of OCI Data Transfer Appliance gebruiken om een grote hoeveelheid lokale data te laden uit historische plannings- of datawarehouse-repository's. Wanneer voortduren grote hoeveelheden data moeten worden verplaatst, raden we aan dit te doen met OCI FastConnect. Dit biedt een dedicated privénetwerkverbinding met hoge bandbreedte tussen het datacenter van een klant en OCI.
- Regelmatige extracties van real time of bijna real time data zijn vaak vereist. Data worden regelmatig opgenomen uit systemen voor magazijnbeheer, planning en orderbeheer via OCI GoldenGate. OCI GoldenGate gebruikt Wijzigingsdata vastleggen om wijzigingsevents in de onderliggende structuur van de systemen te detecteren die onderhoud nodig hebben (bijvoorbeeld een nieuw onderdeel toevoegen, afgerond onderhoud, weersveranderingen e.d.) en verstuurt de data in real time naar een persistentielaag en/of de streaminglaag.
- Productiebedrijven kunnen waardevolle inzichten voor de operationele efficiëntie en algehele prestaties verkrijgen door in real time data uit meerdere bronnen te analyseren. In dit gebruiksscenario gebruiken we streamingopname om alle data op te nemen die zijn gelezen uit sensoren via IoT, M2M-communicatie (machine-to-machine) en andere middelen. Als een productiebedrijf predictief onderhoud wil kunnen uitvoeren op de bedrijfsmiddelen, is het vermogen om datastromen in real time vast te leggen en te analyseren echt cruciaal. Stromen kunnen afkomstig zijn uit verschillende ISA-95 Level 2 systemen, zoals SCADA-systemen (Supervisory Control and Data Acquisition), programmeerbare logische besturingen en batchautomatiseringssystemen. Data (events) worden opgenomen en enkele elementaire transformaties/aggregaties worden uitgevoerd voordat ze worden opgeslagen in OCI Object Storage. Aanvullende streaminganalyses kunnen worden gebruikt om correlerende events te identificeren en eventuele geïdentificeerde patronen (handmatig) weer in het systeem in te voeren. Daar worden de onbewerkte data dan onderzocht met behulp van OCI Data Science.
- Om deze hoogfrequente streamingdata in real time te analyseren, gebruiken we streamingverwerking voor geavanceerde analyses. Met traditionele analysetools wordt informatie geëxtraheerd uit inactieve data, maar met streaminganalyses wordt de waarde van actieve data beoordeeld, dus in real time. En dat is niet het enige voordeel. Omdat streaminganalyses in hoge mate geautomatiseerd kunnen zijn, helpt dit productiebedrijven de bedrijfskosten te verlagen. Streaminganalyses kunnen bijvoorbeeld realtime data leveren over elementaire kosten voor nutsvoorzieningen, zoals elektriciteit en water. Fabrieken kunnen vervolgens met behulp van een geautomatiseerd hulpprogramma voor streaminganalyse direct inzicht krijgen in gebieden waar optimalisatie kan helpen om energiekosten te reduceren en op de juiste manier te reageren op bepaalde operationele gebeurtenissen door middel van kunstmatige intelligentie. Met streaminganalyse kunnen ook in real time voorspellingen worden gedaan over toekomstige onderhoudsbehoeften van apparatuur. Zo kunnen bedrijven zich ruim van tevoren voorbereiden op reparaties of routineonderhoud.
- De behoeften aan realtime data ontwikkelen zich steeds verder. Maar de meest voorkomende methode om data te extraheren uit ERP-, plannings-, magazijnbeheerssystemen en systemen voor transportbeheer is nog steeds een batchopname door middel van een ETL-proces (extractie, transformatie, laden). Batchopname wordt gebruikt om data te importeren uit systemen die geen datastreaming ondersteunen (bijvoorbeeld oudere SCADA-systemen of systemen voor onderhoudsbeheer). Batchopname kan vaak gebeuren, bijvoorbeeld elke 10 of 15 minuten. Deze opnamen zijn echter nog steeds batchbewerkingen, omdat hierin groepen transacties worden geëxtraheerd en verwerkt in plaats van afzonderlijke transacties. OCI biedt verschillende services voor de verwerking van batchopnamen, zoals de native OCI Data Integration-service en Oracle Data Integrator, die wordt uitgevoerd op een OCI Compute-instance. De keuze voor een service zou in de eerste plaats gebaseerd zijn op de voorkeur van de klant, niet op technische vereisten.
Data persistent maken, verwerken en samenstellen
Datapersistentie en -verwerking zijn gebaseerd op drie (optioneel vier) componenten. Sommige klanten gebruiken al deze methoden, andere slechts een subset. Afhankelijk van de volumes en datatypen kunnen data in een objectopslag worden geladen of rechtstreeks in een gestructureerde relationele database voor persistente opslag. Wanneer we verwachten dat we datawetenschapsfunctionaliteit moeten toepassen, worden data die in onbewerkte vorm zijn opgehaald uit databronnen (als een niet-verwerkt native bestand of extractie), meestal vastgelegd vanuit transactiesystemen en geladen in de cloudopslag.
- Cloudopslag is de meest gebruikte laag voor datapersistentie voor ons dataplatform. Dit kan worden gebruikt voor zowel gestructureerde als ongestructureerde data. De basiselementen hierin zijn OCI Object Storage, OCI Data Flow en Oracle Autonomous Data Warehouse. Data die in de onbewerkte vorm zijn opgehaald uit databronnen, worden vastgelegd en in OCI Object Storage geladen. OCI Object Storage is de primaire laag voor datapersistentie. Spark in OCI Data Flow is de primaire engine voor batchverwerking. Batchverwerking omvat diverse activiteiten, zoals uitfilteren van ruis, beheer van ontbrekende data en filteren op basis van gedefinieerde uitgaande datasets. Resultaten worden op basis van de benodigde verwerking en de gebruikte datatypen teruggeschreven naar verschillende lagen in de objectopslag of naar een persistente relationele repository.
- Oracle Big Data Service voor Hadoop (beheerde Hadoop) kan een alternatief zijn voor een configuratie met OCI Object Storage en OCI Data Flow. De twee configuraties kunnen ook samen worden gebruikt, afhankelijk van de klant en of deze een bestaande investering in het Hadoop-ecosysteem heeft, vanuit het perspectief van producten of vaardigheden. Klanten die al gebruikmaken van objectopslag onder Hadoop (in plaats van het Hadoop Distributed File System), kunnen deze configuratie overzetten naar Oracle Big Data Service. Andere componenten in de Hadoop-omgeving, zoals Hive, kunnen ook worden toegevoegd en het gebruik van Big Data Service aandrijven, afhankelijk van de tools voor visualisatie en datawetenschap die de klant gebruikt of van plan is te gebruiken. Hoewel deze architectuur alle door Oracle geleverde services beschrijft, kunnen klanten ervoor kiezen om enkele van hun bestaande componenten te blijven gebruiken, met name tools voor visualisatie en datawetenschap waar ze al mee werken.
- We maken nu met behulp van een aanbiedende dataopslag onze samengestelde data persistent in een vorm die is geoptimaliseerd voor goede queryprestaties. De aanbiedende dataopslag biedt een permanente relationele laag. Van daaruit worden hoogwaardige samengestelde data rechtstreeks geleverd aan eindgebruikers met behulp van tools die gebruik maken van SQL. In deze oplossing wordt Oracle Autonomous Data Warehouse geïnstantieerd als de aanbiedende dataopslag voor het datawarehouse van de onderneming en zo nodig meer gespecialiseerde datamarts op domeinniveau. Het kan ook dienen als de databron voor datawetenschapsprojecten of de repository die Oracle Machine Learning vereist. De aanbiedende dataopslag kan een van de volgende vormen hebben: Oracle MySQL HeatWave, Oracle Database Exadata Cloud Service of Oracle Exadata Cloud@Customer.
Data analyseren, voorspellen en handelen
Het vermogen tot analyseren, voorspellen handelen wordt mogelijk gemaakt drie technologieën.
- Geavanceerde analysefunctionaliteiten zijn essentieel om onderhoud en prestaties te optimaliseren. In dit gebruiksscenario vertrouwen we op Oracle Analytics Cloud voor analyses en visualisaties. Dit stelt de organisatie in staat om gebruik te maken van beschrijvende analyses (beschrijven de huidige trends met histogrammen en grafieken), voorspellende analyses (voorspellen toekomstige gebeurtenissen, identificeren trends en bepalen de waarschijnlijkheid van onzekere resultaten) en sturende analyses (stellen geschikte acties voor die optimale besluitvorming ondersteunen).
- Naast geavanceerde analyses wordt steeds vaker gebruik gemaakt van datawetenschap, machine learning en kunstmatige intelligentie om anomaliën op te sporen, te voorspellen waar storingen kunnen optreden en het sourcingproces te optimaliseren. OCI Data Science, OCI AI Services of Oracle Machine Learning kunnen worden gebruikt in de databases. We bouwen en trainen onze voorspellende modellen met behulp van machine learning en datawetenschapmethoden. Deze machine learning-modellen kunnen vervolgens worden geïmplementeerd voor scorebepaling via API's of worden ingesloten als onderdeel van de analysepijplijn voor de OCI GoldenGate-stroom. In sommige gevallen kunnen deze modellen zelfs met de REST-API voor Oracle Machine Learning Services in de database worden geïmplementeerd. Om dit mogelijk te maken, moet het model de ONNX-indeling (Open Neural Network Exchange) hebben. Daarnaast kunnen OCI Data Science voor Jupyter/Python-gerichte notebooks of Oracle Machine Learning voor de Zeppelin-notebook en machine learning-algoritmen worden geïmplementeerd in de aanbiedende dataopslag of de opslag voor transactiedata. Oracle Machine Learning en OCI Data Science, alleen of in combinatie, kunnen op soortgelijke wijze modellen voor aanbevelingen en beslissingen ontwikkelen. Deze modellen kunnen worden geïmplementeerd als een service en we kunnen ze achter OCI API Gateway implementeren om te worden geleverd als 'dataproducten' en services. Tot slot kunnen de machine learning-modellen worden geïmplementeerd in applicaties die deel uitmaken van een gedistribueerd sturingssysteem (indien toegestaan), of in de edge via een Roving Edge-apparaat van Oracle of soortgelijk apparaat.
De diverse modellen die zijn gemaakt door datawetenschap te combineren met de patronen die met machine learning zijn geïdentificeerd, kunnen worden toegepast op respons- en besluitvormingssystemen die worden geleverd door AI-services.
- Met OCI Anomaly Detection kunnen prestatiemetrics van de supply chain (bijvoorbeeld grondstoffenvoorraden, doorloopsnelheid in de productie, werk in uitvoering, transittijden, voorraadomloopsnelheid e.d.) in real time worden gevolgd om verstoringen te identificeren en op te lossen. In een complexe supply chain kan de ernstkwalificatie van geïdentificeerde anomaliën helpen de juiste prioriteit voor actie toe te kennen aan waargenomen bedrijfsonderbrekingen.
- Met OCI Forecasting kunnen supply chain-metrics worden voorspeld, zoals vraag, aanbod en resourcecapaciteit. Zo kunnen vooraf de benodigde stappen worden gezet om hierop voorbereid te zijn.
- OCI Vision en OCI Language helpen beter inzicht te krijgen in documenten, zoals uitgaande productkwaliteitsrapporten en productdefectrapporten, om zo data uit de supply chain te verrijken.
De laatste maar cruciale component is datagovernance. Dit wordt mogelijk gemaakt door OCI Data Catalog. Dit is een gratis service voor datagovernance en beheer van metadata (voor zowel technische als zakelijke metatadata) voor alle databronnen in het data lakehouse-ecosysteem. OCI Data Catalog is ook een cruciale component voor query's vanuit Oracle Autonomous Data Warehouse naar OCI Object Storage, doordat hiermee snel data kan worden opgespoord, ongeacht op welke wijze deze is opgeslagen. Dit maakt het mogelijk voor eindgebruikers, ontwikkelaars en datawetenschappers om met een gezamenlijke querytaal (SQL) te werken in alle persistente dataopslagen binnen de architectuur.
De voordelen van het gebruik van data voor verbetering van de operationele efficiëntie en prestaties
Het bedrijfsleven moet steeds sneller opereren terwijl de concurrentie steeds zwaarder wordt. Oudere systemen die cruciale operationele data leveren, kunnen dit alles niet meer bijhouden. Deze systemen vereisen veel handmatige ingrepen om gefragmenteerde en geïsoleerde data te verzamelen, te integreren en er rapporten mee te genereren. Dat betekent dat de informatie te laat komt om het bedrijf het benodigde voordeel te leveren.
Als u uw productieactiviteiten wilt optimaliseren, is het cruciaal dat u uw productiemiddelen zo goed mogelijk kunt benutten. Iedere minuut dat u de verkeerde producten produceert of de juiste producten inefficiënt produceert, staat u niet alleen voor hogere kosten en verspilling. U kunt ook niet leveren wat uw klanten nodig hebben. Als productiebedrijven hun bedrijfsvoering optimalseren en prestaties verbeteren, profiteren zij van vele voordelen zoals:
- meer efficiëntie, lagere productietijd en -kosten, hogere productie en meer productiviteit;
- minder defecten, betere productkwaliteit en grotere klanttevredenheid;
- snellere identificatie van veiligheidsrisico's en gevaren, met als resultaat betere veiligheidsprocedures en minder arbeidsongevallen;
- minder verspilling, een efficiëntere supply chain en optimale voorraadniveaus;
- beter vermogen om te concurreren op prijs, kwaliteit en innovatie, waardoor bedrijven een concurrentievoordeel krijgen op hun markten;
- grotere duurzaamheid door reductie van afval, verhoging van de energie-efficiëntie en mininale milieu-effecten van productieprocessen.
Gerelateerde bronnen
-
Gebruiksscenario
Gebruik data om gezondheid en veiligheid op het werk te verbeteren
Ontdek hoe u uw productieactiviteiten veiliger kunt maken met een dataplatform dat u met geavanceerde analyses helpt gezondheid en veiligheid op het werk te verbeteren.
-
Gebruiksscenario
Edge Computing geeft u sneller inzichten in uw fabriek
Ontdek hoe u fabrieksdata efficiënter consolideert en sneller inzichten krijgt met Oracle Data Platform for Manufacturing.
-
Gebruiksscenario
Gebruik uw data om van reactief naar voorspellend onderhoud over te gaan
Ontdek hoe u assets optimaliseert met een dataplatform dat voorspellend onderhoud mogelijk maakt middels machine learning.
Aan de slag
Probeer meer dan 20 'Altijd gratis'-cloudservices uit, met een proefversie van 30 dagen voor nog meer
Oracle biedt een Free Tier zonder tijdslimiet voor meer dan 20 services zoals Autonomous AI Database, computing op ARM en storage, evenals USD 300 aan gratis tegoed om extra cloudservices uit te proberen. Lees de informatie en meld u vandaag nog aan voor uw gratis account.
-
Wat is inbegrepen in Oracle Cloud Free Tier?
- Twee Autonomous AI Database instances, elk 20 GB
- Compute VM's van AMD en Arm
- 200 GB totale blokopslag
- 10 GB objectopslag
- 10 TB uitgaande dataoverdracht per maand
- Meer dan 10 extra 'Altijd gratis'-services
- $ 300 aan gratis tegoed voor 30 dagen voor nog meer
Leer met stapsgewijze begeleiding
Ervaar een breed scala aan OCI-services via zelfstudies en praktijklabs. Of u nu een ontwikkelaar, beheerder of analist bent, wij kunnen u laten zien hoe OCI werkt. Veel labs draaien op de Oracle Cloud Free Tier of een door Oracle geleverde gratis labomgeving.
-
Aan de slag met OCI Core Services
De labs in deze workshop bevatten een inleiding tot de kernservices van Oracle Cloud Infrastructure (OCI), waaronder virtuele cloudnetwerken (VCN) en compute- en opslagservices.
Start nu het lab voor OCI-kernservices -
Snel aan de slag met Autonomous AI Database
In deze workshop doorloopt u de stappen om aan de slag te gaan met Oracle Autonomous AI Database.
Begin nu aan het lab Snel aan de slag met Autonomous AI Database -
Een app bouwen vanuit een spreadsheet
Dit lab begeleidt u bij het uploaden van een spreadsheet naar een Oracle Database tabel en het maken van een applicatie op basis van deze nieuwe tabel.
Start deze training nu
Ontdek meer dan 150 best practices
Bekijk hoe onze architecten en andere klanten een breed scala aan workloads implementeren, van bedrijfsapps tot HPC, van microservices tot data lakes. Begrijp de best practices, hoor over andere architecten van klanten in onze reeks 'Built & Deployed' en implementeer veel workloads met onze 'click-to-deploy'-functie, of doe dit zelf vanuit onze GitHub-repository.
Populaire architecturen
- Apache Tomcat met MySQL Database Service
- Oracle Weblogic op Kubernetes met Jenkins
- Machine learning (ML)- en AI-omgevingen
- Tomcat op ARM met Oracle Autonomous AI Database
- Loganalyse met ELK-stack
- HPC met OpenFOAM
Bekijk hoeveel u kunt besparen op OCI
De prijsbepaling voor Oracle Cloud is eenvoudig, met wereldwijd consistente lage prijzen, met ondersteuning voor een breed scala aan gebruiksdoelen. Ga naar de kostencalculator voor een schatting van uw lage tarief en kies en configureer de services die u nodig hebt.
Ervaar het verschil:
- Een kwart van de kosten voor uitgaande bandbreedte
- Drie keer betere Compute prijs-prestatieverhouding
- Zelfde lage prijs in elke regio
- Lage prijzen zonder langetermijnverplichtingen
Neem contact op met de verkooporganisatie
Wilt u meer weten over Oracle Cloud Infrastructure? Laat een van onze experts u helpen.
-
Ze kunnen vragen beantwoorden zoals:
- Welke workloads draaien het beste op OCI?
- Hoe profiteer ik optimaal van Oracle investeringen?
- Wat zijn de voordelen van OCI ten opzichte van andere cloudcomputing-providers?
- Hoe kan OCI uw IaaS- en PaaS-doelen ondersteunen?