Enterprise Data Mesh
Oplossingen, gebruiksscenario's en casestudy's
Wat is data mesh?
Data mesh is een veelbesproken onderwerp voor bedrijfssoftware en is een nieuwe denkwijze over data op basis van een gedistribueerde architectuur voor databeheer. Het idee is om data beter toegankelijk en beschikbaar te maken voor zakelijke gebruikers door eigenaren, producenten en gebruikers van data rechtstreeks met elkaar te verbinden. Data mesh is bedoeld om de zakelijke resultaten van datagerichte oplossingen te verbeteren en de implementatie van moderne data-architecturen te bevorderen.
Vanuit zakelijk oogpunt introduceert data mesh nieuwe ideeën rond het begrip 'dataproduct'. Hierbij worden data als een product beschouwd waarmee een taak kan worden voltooid voor bijvoorbeeld het verbeteren van de besluitvorming, het opsporen van fraude of het waarschuwen voor veranderingen in de supply chain. Om hoogwaardige dataproducten te kunnen maken, moeten bedrijven kijken naar verschuivingen van de cultuur en mindset en moeten ze zich inzetten voor een meer multifunctionele benadering van modellering van bedrijfsdomeinen.
Vanuit technologisch oogpunt omvat de visie van Oracle voor data mesh drie belangrijke en nieuwe focusgebieden voor een datagestuurde architectuur:
- Tools die dataproducten leveren als dataverzamelingen, datagebeurtenissen en data-analyse
- Gedistribueerde, gedecentraliseerde data-architecturen zodat organisaties kunnen overstappen van een monolithische architectuur naar multicloud en hybride cloudcomputing of wereldwijd gedecentraliseerd kunnen werken
- Data in beweging voor organisaties die niet uitsluitend op gecentraliseerde, statische data in batches kunnen vertrouwen en die in plaats daarvan willen overstappen naar gebeurtenisgestuurde datagrootboeken en streamingpijplijnen voor realtime datagebeurtenissen om zo tijdigere analyses te kunnen bieden
Andere belangrijke aandachtspunten, zoals selfservicetools voor niet-technische gebruikers en sterke modellen voor geconsolideerd databeheer, zijn net zo belangrijk voor de data mesh-architectuur als voor andere, meer gecentraliseerde en klassieke databeheermethoden.
Een nieuw concept voor data

Een data mesh-benadering is een paradigmaverschuiving waarbij data worden beschouwd als een product. Met data mesh worden organisatorische en proceswijzigingen geïntroduceerd die organisaties nodig hebben om data te beheren als een tastbaar kapitaalactivum van het bedrijf. In de visie van Oracle voor een data mesh-architectuur moeten de verschillende organisatorische en analytische datadomeinen op elkaar worden afgestemd.
Een data mesh is bedoeld om producenten van data direct te koppelen aan zakelijke gebruikers en zoveel mogelijk de IT-tussenpersoon te verwijderen uit de projecten en processen waarmee data worden opgeslagen, voorbereid en getransformeerd.
Oracle wil haar klanten een platform bieden dat kan voldoen aan deze vereisten voor opkomende technologieën. Dit platform omvat tools voor dataproducten, gedecentraliseerde, gebeurtenisgestuurde architecturen en streamingpatronen voor data in beweging. Voor het modelleren van dataproductdomeinen en andere sociotechnische kwesties denkt Oracle hetzelfde als Zhamak Dehghani, visionair leider op het gebied van data mesh.
Voordelen van een data mesh
Investeren in een data mesh kan indrukwekkende voordelen opleveren, zoals:
- Perfect inzicht in de waarde van data door het toepassen van best practices op het gebied van dataproducten.
- Meer dan 99,999% operationele beschikbaarheid van data met behulp van op microservices gebaseerde datapijplijnen voor consolidatie en migratie.
- 10x snellere innovatiecycli, waarbij wordt overgestapt van handmatige, batchgerichte ETL naar continue transformatie en laden (CTL).
- Meer dan 70% reductie van datatechnologie, verbeteringen in CI/CD, selfservicetools voor datapijplijnen zonder code, en flexibele ontwikkeling.
Data mesh is meer dan een mindset
Data mesh bevindt zich nog in het beginstadium van marktontwikkeling. U ziet misschien een verscheidenheid aan marketingcontent over een oplossing die beweert 'data mesh' te zijn, maar deze zogenaamde data mesh-oplossingen voldoen vaak niet aan de basisprincipes.
Een goede data mesh is een mindset, een organisatiemodel en een ondernemingsdata-architectuur met ondersteunende tools. Een data mesh-oplossing moet een combinatie zijn van dataproducten, een gedecentraliseerde data-architectuur, domeingeoriënteerd eigendom van data, gedistribueerde data in beweging, selfservicetoegang en sterk databeheer.
Een data mesh is geen:
- Leveranciersproduct: een enkel data mesh-softwareproduct bestaat niet.
- Data lake of data lakehouse: deze zijn complementair en kunnen onderdeel zijn van een grotere data mesh die meerdere lakes, ponds en operationele recordsystemen omvat.
- Datacatalogus of -grafiek: een data mesh moet fysiek worden geïmplementeerd.
- Eenmalig consultatieproject: een data mesh is een traject en niet slechts één project.
- Selfservice-analyseproduct: klassieke selfservice-analyse, datavoorbereiding en data wrangling kunnen deel uitmaken van een data mesh en van andere data-architecturen.
- Datastructuur: het concept van een datastructuur is weliswaar conceptueel gerelateerd, maar omvat een verscheidenheid aan methoden voor data-integratie en -beheer. Data mesh is meer gekoppeld aan decentralisatie en domeingestuurde ontwerppatronen.
Waarom data mesh?
De monolithische data-architecturen van vroeger waren vaak omslachtig, duur en inflexibel. In de loop der jaren is duidelijk geworden dat het grootste deel van de tijd en kosten voor een digitaal bedrijfsplatform, van applicaties tot analyses, wordt besteed aan integraties. Om die reden mislukken de meeste platforminitiatieven.
Hoewel data mesh niet het perfecte alternatief is voor gecentraliseerde, monolithische data-architecturen, kunnen met de principes, methoden en technologieën van de data mesh-strategie enkele van de meest urgente moderniseringsdoelstellingen voor datagestuurde bedrijfsinitiatieven worden gerealiseerd.
De technologietrends die hebben geleid tot de opkomst van data mesh als oplossing zijn onder andere:
- 70-80% van de digitale transformaties mislukt
- De kosten van operationeel data-uitval stijgen
- Cloud lock-in is een reëel probleem en kan nog duurder worden
- Data lakes slagen zelden en zijn alleen gericht op analyses
- De opkomst van gedistribueerde data zorgt voor een meer effectieve, efficiënte en economische architectuur
- Organisatorische silo's leiden tot grotere problemen bij het delen van data
- Data zijn de katalysator voor concurrentievoordeel en goed databeheer is van essentieel belang
Lees het artikel van Zhamak Dehghani uit 2019 voor meer informatie over waarom data mesh nodig is: How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.
De data mesh definiëren
Volgens de gedecentraliseerde strategie achter data mesh moeten data worden behandeld als een product en moet er een selfservice data-infrastructuur worden gecreëerd om data beter toegankelijk te maken voor zakelijke gebruikers.
Resultaatgericht
Beschouwen als dataproduct- Verschuiving van de mindset naar het oogpunt van de dataconsument
- Eigenaren van datadomeinen zijn verantwoordelijk voor KPI's/SLA's van dataproducten
- Dezelfde datadomein- en technologiesemantiek voor iedereen
- Niet langer afschuiven van verantwoordelijkheden
- Registreer realtime datagebeurtenissen direct vanuit registratiesystemen en stel selfservicepijplijnen in staat om waar nodig data te leveren
- Een essentiële voorziening voor het activeren van gedecentraliseerde data en op bronnen afgestemde dataproducten
Afwijzing van een monolithische IT-architectuur
Gedecentraliseerde architectuur- Een architectuur gebouwd voor gedecentraliseerde data, services en clouds
- Ontworpen voor alle typen en formaten gebeurtenissen en elke mate van complexiteit
- Streamverwerking als standaard, batchverwerking als uitzondering
- Ontworpen voor ontwikkelaars en directe verbinding tussen dataconsumenten en dataproducenten
- Ingebouwde beveiliging, validatie, herkomst en transparantie
Oracle oplossingen voor het opzetten van een data mesh
Bij het omzetten van theorie in praktijk moeten hoogwaardige oplossingen voor bedrijfskritische data worden geïmplementeerd. Oracle biedt betrouwbare oplossingen voor het opzetten van een data mesh op bedrijfsniveau.
Maak en deel dataproducten
- Dataverzamelingen voor meerdere modellen met de geconvergeerde database van Oracle leiden tot dataproducten met de opmaak die dataconsumenten nodig hebben
- Selfservice dataproducten als applicaties of API's, die gebruikmaken van Oracle APEX Application Development en Oracle REST Data Services voor eenvoudige toegang en het delen van alle data
- Eén toegangspunt voor SQL-query's of datavirtualisatie met Oracle Cloud SQL en Big Data SQL
- Dataproducten voor machine learning met het datawetenschapsplatform van Oracle, de datacatalogus van Oracle Cloud Infrastructure (OCI) en het clouddataplatform van Oracle voor data lakehouses
- Op bronnen gebaseerde dataproducten als realtime gebeurtenissen, datawaarschuwingen en services voor onbewerkte datagebeurtenissen met Oracle Stream Analytics
- Op consumenten gebaseerde selfservice dataproducten in een uitgebreide Oracle Analytics Cloud oplossing
Gebruik van een gedecentraliseerde data-architectuur
- Flexibele CI/CD met 'service mesh' voor datacontainers met Oracle plug-in-databases met Kubernetes, Docker of cloud-native met Autonomous Database
- Datasynchronisatie tussen regio's, meerdere clouds en hybride clouds met Oracle GoldenGate microservices en Veridata, voor een betrouwbare actieve-actieve transactiestructuur.
- Profiteer van de meeste datagebeurtenissen van applicaties, bedrijfsprocessen en het Internet of Things (IoT) met Oracle Integration Cloud en Oracle Internet of Things Cloud
- Gebruik gebeurteniswachtrijen van Oracle GoldenGate of Oracle Transaction Manager for Microservices voor het sourcen van microservicesgebeurtenissen of realtime opslag in Kafka en data lakes
- Introduceer gedecentraliseerde ontwerppatronen op basis van domeinen in uw service mesh met Oracle Verrazzano, Helidon en Graal VM
3 essentiële kenmerken van een datamesh
Datamesh is niet alleen maar een nieuw modewoord in de technologie. Het is een nieuwe set principes, praktijken en technologische mogelijkheden die gegevens toegankelijker en vindbaarder maken. Het datameshconcept onderscheidt zich van eerdere generaties gegevensintegratiebenaderingen en -architecturen door de aanmoediging van een verschuiving van de gigantische, monolithische gegevensarchitecturen uit het verleden naar een moderne, gedistribueerde, gedecentraliseerde gegevensgestuurde architectuur van de toekomst. In de basis heeft het datameshconcept de volgende hoofdkenmerken:
1.Gegevensproductdenken
Een mentaliteitsverandering is de belangrijkste eerste stap naar een datamesh. De bereidheid om geleerde praktijken van innovatie te omarmen, is de springplank naar een succesvolle modernisering van de gegevensarchitectuur.
Deze geleerde praktijken zijn onder meer:
- Ontwerpdenken: een bewezen methodologie voor het oplossen van "ongestructureerde problemen", toegepast op bedrijfsgegevensdomeinen voor het bouwen van fantastische gegevensproducten
- Theorie van jobs-to-be-done: het toepassen van een klantgerichte innovatie en een resultaatgestuurd innovatieproces om ervoor te zorgen dat producten voor bedrijfsgegevens echte zakelijke problemen oplossen

Methodologieën voor ontwerpdenken bieden bewezen technieken die helpen om de organisatorische kokers te doorbreken die functieoverschrijdende innovatie vaak blokkeren. De theorie van jobs-to-be-done is de cruciale basis voor het ontwerpen van gegevensproducten die voldoen aan specifieke doelen van eindconsumenten, of voorzien in taken die moeten worden uitgevoerd. De theorie definieert het doel van het product.
Hoewel de gegevensproductbenadering aanvankelijk uit de datawetenschap kwam, wordt deze nu toegepast op alle aspecten van gegevensbeheer. In plaats van monolithische technologiearchitecturen te bouwen, is datamesh gericht op de gegevensgebruikers en de bedrijfsresultaten.
Gegevensproductdenken kan ook worden toegepast op andere gegevensarchitecturen, maar het is een essentieel onderdeel van een datamesh. Voor praktische voorbeelden van het toepassen van gegevensproductdenken kunt u de gedetailleerde analyse lezen die het team van Intuit schreef over hun ervaringen.
Gegevensproducten
Producten van elke soort, van ruwe grondstoffen tot artikelen in de lokale winkel, worden geproduceerd als activa van waarde, zijn bedoeld om te worden geconsumeerd en hebben een specifieke taak te vervullen. Gegevensproducten kunnen verschillende vormen aannemen, afhankelijk van het bedrijfsdomein of het probleem dat moet worden opgelost, en kunnen het volgende omvatten:
- Analyses: historische/realtime rapporten en dashboards
- Gegevenssets: gegevensverzamelingen in verschillende vormen/indelingen
- Modellen: domeinobjecten, gegevensmodellen, functies voor machine learning (ML)
- Algoritmen: ML-modellen, scorebepaling en bedrijfsregels
- Gegevensservices en API's: documenten, payloads, onderwerpen, REST-API's en meer
Een gegevensproduct wordt gemaakt voor gebruik en is doorgaans eigendom van een partij buiten de IT. Er moeten aanvullende kenmerken worden bijgehouden, zoals:
- Kaart van belanghebbenden: wie is de eigenaar van dit product en wie gebruikt het?
- Verpakking en documentatie: hoe wordt het gebruikt? Wat voor etiket krijgt het?
- Doel en waarde: wat is de impliciete/expliciete waarde van het product? Is er waardevermindering na verloop van tijd?
- Kwaliteit en consistentie: wat zijn de KPI's en SLA's van het gebruik? Is het verifieerbaar?
- Herkomst, levenscyclus en governance: is er vertrouwen in de gegevens en zijn ze verklaarbaar?
2.Gedecentraliseerde gegevensarchitectuur

Gedecentraliseerde IT-systemen horen bij deze tijd, en met de opkomst van SaaS-applicaties en publieke cloudinfrastructuur (IaaS) is de decentralisatie van applicaties en gegevens niet meer weg te denken. Applicatiesoftwarearchitecturen stappen over van de oude gecentraliseerde monolieten naar gedistribueerde microservices (een servicemesh). De gegevensarchitectuur zal ook gaan decentraliseren. Daarbij worden gegevens meer verspreid over een grotere verscheidenheid aan fysieke locaties en over vele netwerken. We noemen dit een datamesh.
Wat is een mesh?
Een mesh is een netwerktopologie die een grote groep niet-hiërarchische nodes laat samenwerken.
Veel voorkomende technische voorbeelden:
- WiFiMesh: veel nodes die samenwerken voor een betere dekking
- ZWave/Zigbee: netwerken van energiezuinige smart home-apparaten
- 5G-mesh: betrouwbaardere en veerkrachtigere telefoonverbindingen
- Starlink: wereldwijd satellietbreedbandnetwerk
- Servicemesh: een manier om uniforme controles te bieden voor gedecentraliseerde microservices (applicatiesoftware)
Datamesh is afgestemd op deze mesh-concepten en biedt een gedecentraliseerde manier om gegevens te verspreiden over virtuele/fysieke netwerken en over grote afstanden. Oude monolithische architecturen voor gegevensintegratie, zoals ETL en gegevensfederatietools, en nog recenter, openbare cloudservices zoals AWS Glue, vereisen een uiterst gecentraliseerde infrastructuur.
Een complete datameshoplossing moet kunnen functioneren in een multicloudkader, van on-premisesystemen en meerdere publieke clouds tot zelfs edge-netwerken.
Verspreide beveiliging
In een wereld waarin gegevens erg verspreid en gedecentraliseerd zijn, is de rol van informatiebeveiliging van het grootste belang. In tegenstelling tot sterk gecentraliseerde monolieten moeten verspreide systemen de activiteiten aansturen die nodig zijn om verschillende gebruikers te authenticeren en te autoriseren op verschillende toegangsniveaus. Vertrouwen veilig sturen over netwerken is moeilijk.
Enkele overwegingen zijn:
- Versleuteling van inactieve gegevens: zoals gegevens/gebeurtenissen die naar de opslag worden overgebracht
- Verspreide verificatie: voor services en gegevensopslag, zoals mTLS, certificaten, SSO, geheimopslag en gegevenskluizen
- Versleuteling van actieve gegevens: zoals gegevens/gebeurtenissen die geen vaste plek hebben in de opslag
- Identiteitsbeheer: LDAP/IAM-services, platformoverschrijdend
- Verspreide autorisaties: voor service-eindpunten om gegevens te bewerken
Bijvoorbeeld: Open Policy Agent (OPA) om policybeslissingspunt (PDP) te plaatsen in de container/K8S-cluster waar het microservice-eindpunt wordt verwerkt. LDAP/IAM kan elke service zijn die geschikt is voor JWT. - Deterministische maskering: om PII-gegevens betrouwbaar en consistent te verbergen
Beveiliging kan binnen elk IT-systeem moeilijk zijn, en het is nog moeilijker om een hoge mate van beveiliging te bieden binnen verspreide systemen. Dit is echter wel op te lossen.
Gedecentraliseerde gegevensdomeinen
Een kernprincipe van datamesh is het begrip verspreiding van eigendom en verantwoordelijkheid. Het wordt aanbevolen om het eigendom van gegevensproducten en gegevensdomeinen toe te vertrouwen aan de mensen in een organisatie die het dichtst bij de gegevens staan. In de praktijk kan dit worden afgestemd op de brongegevens (bijvoorbeeld ruwe gegevensbronnen, zoals de operationele registratiesystemen/applicaties) of op de analytische gegevens (bijvoorbeeld typische samengestelde of geaggregeerde gegevens die zijn geformatteerd voor eenvoudig gebruik door de gegevensconsumenten). In beide gevallen zijn de producenten en de consumenten van de gegevens vaak eerder afgestemd op bedrijfseenheden dan op IT-organisaties.
Bij oude manieren om gegevensdomeinen te organiseren gaat het vaak mis bij het afstemmen op de technologische oplossingen, zoals ETL-tools, data warehouses, data lakes of de structurele organisatie van een bedrijf (human resources, marketing en andere afdelingen). Voor een bepaald bedrijfsprobleem zijn de gegevensdomeinen echter vaak het best afgestemd op de omvang van het probleem dat wordt opgelost, de context van een bepaald bedrijfsproces of de groep applicaties op een specifiek probleemgebied. In grote organisaties gaan deze gegevensdomeinen gewoonlijk verder dan de interne organisaties en technologische voetafdrukken.
De functionele decompositie van gegevensdomeinen krijgt een hoge prioriteit in het gegevensnetwerk. Diverse gegevensdecompositiemethodologieën voor domeinmodellering kunnen worden toegepast op de datamesharchitectuur, waaronder klassieke datawarehouse-modellering (zoals Kimball en Inmon) of data vault-modellering, maar de meest gebruikte methodologie die momenteel wordt uitgeprobeerd in datamesharchitectuur is domain-driven design (DDD). De DDD-benadering kwam voort uit functionele decompositie van microservices en wordt nu toegepast in een datameshcontext.
3.Dynamische actieve gegevens
Een belangrijk gebied waarop Oracle een bijdrage heeft geleverd aan de discussie over datameshnetwerken is het vergroten van het belang van actieve gegevens als een belangrijk onderdeel van een moderne datamesh. Actieve gegevens zijn essentieel om datamesh uit de oude wereld van monolithische, gecentraliseerde batchverwerking te halen. De mogelijkheden van actieve gegevens zijn een antwoord op verschillende kernvragen over datamesh, zoals:
- Hoe kunnen we realtime toegang krijgen tot op bronnen afgestemde gegevensproducten?
- Welke tools kunnen vertrouwde gegevenstransacties verspreiden over een fysiek gedecentraliseerde datamesh?
- Wat kan ik gebruiken om gegevensgebeurtenissen beschikbaar te maken als gegevensproduct-API's?
- Hoe kan ik voor analytische gegevensproducten die voortdurend moeten worden bijgewerkt, afstemmen op gegevensdomeinen en zorgen voor vertrouwen en geldigheid?
Deze vragen zijn niet slechts "uitvoeringsdetails". Ze zijn van groot belang voor de gegevensarchitectuur zelf. Bij een domeingestuurd ontwerp voor statische gegevens worden andere technieken en hulpmiddelen gebruikt dan bij een dynamisch proces met actieve gegevens van hetzelfde ontwerp. In dynamische gegevensarchitecturen is het gegevensgrootboek bijvoorbeeld de centrale bron voor gegevensgebeurtenissen.
Gebeurtenisgestuurde gegevensgrootboeken

Grootboeken zijn een fundamenteel onderdeel van een goed werkende verspreide gegevensarchitectuur. Net als bij een kasboek worden in een gegevensgrootboek de transacties geregistreerd op het moment dat ze plaatsvinden.
Als we het grootboek verspreiden, worden de gegevensgebeurtenissen "opnieuw uitvoerbaar" op elke locatie. Sommige grootboeken lijken een beetje op een boordrecorder van een vliegtuig die wordt gebruikt voor hoge beschikbaarheid en noodherstel.
In tegenstelling tot gecentraliseerde en monolithische datastores, zijn verspreide grootboeken speciaal gebouwd om atomische gebeurtenissen en/of transacties bij te houden die in andere (externe) systemen plaatsvinden.
Een datamesh is niet slechts één type grootboek. Afhankelijk van de gebruiksscenario's en vereisten kan een datamesh gebruikmaken van verschillende soorten gebeurtenisgestuurde gegevensgrootboeken, waaronder:
- Grootboek voor activiteiten voor algemene doeleinden, zoals Kafka of Pulsar
- Gebeurtenisgestuurd gegevensgrootboek: verspreide CDC/replicatietools
- Berichtenmiddleware, inclusief ESB, MQ, JMS en AQ
- Blockchaingrootboek: voor veilige, onveranderbare transacties met meerdere partijen
Samen kunnen deze grootboeken fungeren als een soort duurzaam gebeurtenissenlog voor de hele onderneming, met een lopende lijst van gegevensgebeurtenissen op boekhoudsystemen en analysesystemen.
Meertalige gegevensstromen

Meertalige gegevensstromen komen vaker voor dan ooit. Ze zijn verschillend qua type gebeurtenis, payloads en transactiesemantiek. Een datamesh moet de nodige stroomtypes ondersteunen voor een verscheidenheid aan bedrijfsgegevensworkloads.
Eenvoudige gebeurtenissen:
Base64/JSON, onregelmatige, schemaloze gebeurtenissen
- Onregelmatige telemetrie, schaarse gebeurtenissen
Basisgebeurtenissen voor het loggen van apps/Internet of Things (IoT):
- JSON/Protobuf, kan een schema hebben
- MQTT, IoT-specifieke protocollen
Bedrijfsprocesgebeurtenissen van applicaties:
- SOAP/REST-gebeurtenissen - XML/XSD, JSON
- B2B-uitwisselingsprotocollen en standaarden
Gegevensgebeurtenissen/transacties:
- Logische wijzigingsrecords: LCR, SCN, URID
- Consistente grenzen, vastleggingen versus bewerkingen
Stroomgegevensverwerking
Stroomverwerking is de manier waarop gegevens worden gemanipuleerd binnen een gebeurtenissenstroom. In tegenstelling tot "lambda-functies" houdt de stroomverwerker de status van gegevensstromen binnen een bepaald tijdsvenster en kan hij veel geavanceerdere analytische query's op de gegevens toepassen.
- Drempels, waarschuwingen en telemetriebewaking
- RegEx-functies, wiskunde/logica en aaneenschakeling
- Record-by-record, vervangingen en maskeringen
Basisgegevens filteren:
Eenvoudige ETL:
CEP en complexe ETL:
- Complexe gebeurtenisverwerking (CEP)
- DML-verwerking (ACID) en tupels
- Aggregaties, referentiecodes, complexe joins
Stroomanalyses:
- Analyse van tijdreeksen en aangepaste tijdvensters
- Geospatiaal, machine learning en geïntegreerde AI
Andere belangrijke kenmerken en principes
Een datamesh heeft natuurlijk meer dan drie kenmerken. We hebben ons gericht op de drie hierboven genoemde aspecten als een manier om aandacht te vestigen op kenmerken waarvan Oracle denkt dat ze de nieuwe en unieke aspecten van de opkomende moderne datameshmethode zijn.
Andere belangrijke kenmerken van de datamesh zijn:
- Selfservicetools: datamesh omarmt de selfservicetrend van gegevensbeheer, waarbij ontwikkelaars steeds meer op het niveau van de gegevenseigenaars moeten zitten
- Governance van gegevens: datamesh doet ook mee met de reeds lang bestaande trend naar een meer geformaliseerd federatief governancemodel, zoals dat al vele jaren succesvol wordt uitgevoerd door chief data officers, data stewards en leveranciers van gegevenscatalogi.
- Bruikbaarheid van gegevens: als we ons verdiepen in de beginselen van datamesh moet er heel wat fundamenteel werk worden verricht om ervoor te zorgen dat de gegevensproducten bruikbaar zijn. Bij de beginselen voor gegevensproducten zal het gaan om gegevens die waardevol, bruikbaar en deelbaar zijn.
7 gebruiksscenario's voor datamesh
Een succesvolle datamesh voldoet aan gebruikscriteria voor zowel operationele als analytische gegevensdomeinen. De volgende zeven gebruiksscenario's illustreren de uiteenlopende mogelijkheden die een datamesh biedt voor ondernemingsgegevens.
Door realtime operationele gegevens en analyses te integreren, kunnen bedrijven betere operationele en strategische beslissingen nemen.MIT Sloan School of Management
1. Modernisering van applicaties
Naast de 'lift and shift'-migraties van monolithische gegevensarchitecturen naar de cloud willen veel organisaties ook hun gecentraliseerde applicaties uit het verleden buiten gebruik stellen en overstappen op een modernere architectuur voor microservicesapplicaties.


Maar monolieten van legacy-applicaties zijn meestal afhankelijk van enorme databases, waardoor de vraag rijst hoe het migratieplan moet worden gefaseerd om verstoring, risico's en kosten te beperken. Een datamesh kan een belangrijke operationele IT-mogelijkheid bieden voor klanten die gefaseerd overstappen van een monolithische naar een mesharchitectuur. Bijvoorbeeld:
- Subdomeinoverzetting van databasetransacties, zoals het filteren van gegevens op 'gebonden context'
- Bidirectionele transactiereplicatie voor gefaseerde migraties
- Platformoverschrijdende synchronisatie, zoals van mainframe naar DBaaS
In het woordenboek van microservices-architecten is deze aanpak het gebruik van een bidirectionele transacties-putbox om het wurgvijgmigratiepatroon mogelijk te maken, één gebonden context per keer.
2. Beschikbaarheid en continuïteit van gegevens

Bedrijfskritieke applicaties vereisen zeer hoge KPI's en SLA's rond veerkracht en continuïteit. Ongeacht of deze applicaties monolithisch of microservices zijn of iets ertussenin, ze moeten continue functioneren!
Voor bedrijfskritieke systemen is een verspreid gegevensmodel met uiteindelijke consistentie doorgaans niet acceptabel. Deze applicaties moeten echter in veel datacenters werken. Hiermee wordt de vraag voor bedrijfscontinuïteit gesteld: Hoe kan ik mijn apps in meerdere datacenters uitvoeren en toch de juiste en consistente gegevens garanderen?
Ongeacht of de monolithische architecturen gebruik maken van 'sharded datasets' of de microservices worden opgezet voor site-overschrijdende hoge beschikbaarheid, de datamesh biedt correcte, snelle gegevens op elke afstand.
Een datamesh kan de basis vormen voor gedecentraliseerde, maar toch 100% correcte data op verschillende sites. Bijvoorbeeld:
- Logische transacties met zeer lage latentie (platformoverschrijdend)
- ACID-compatibele garanties voor correcte gegevens
- Multi-actieve, bidirectionele en conflictoplossing
3. Sourcing van gebeurtenissen en transactie-outbox


Een modern, servicemesh-achtig platform gebruikt gebeurtenissen voor gegevensuitwisseling. In plaats van afhankelijk te zijn van batchverwerking in de datatier, worden de payloads van de gegevens continu verwerkt wanneer zich gebeurtenissen voordoen in de toepassing of de datastore.
Voor sommige architecturen moeten microservices gegevens met elkaar uitwisselen. Andere patronen vereisen uitwisseling tussen monolithische toepassingen of datastores. Hierbij staat de volgende vraag centraal: "Hoe kan ik betrouwbaar microservicegegevenspayloads uitwisselen tussen mijn apps en datastores?"
Een datamesh kan de basistechnologie leveren voor gegevensuitwisseling waarbij microservices centraal staan. Bijvoorbeeld:
- Microservice naar microservice binnen context
- Microservice naar microservice contextoverschrijdend
- Monoliet van/naar microservice
Microservicepatronen, zoals gebeurtenissourcing, CQRS en transactie-outbox zijn algemeen aanvaarde oplossingen. Een datamesh biedt de tools en frameworks om deze patronen op schaal herhaalbaar en betrouwbaar te maken.
4. Gebeurtenisgestuurde integratie
Naast ontwerppatronen voor microservices breidt de behoefte aan bedrijfsintegratie zich uit tot andere IT-systemen, zoals databases, bedrijfsprocessen, applicaties en alle soorten fysieke apparaten. Een datamesh vormt de basis voor de integratie van actieve gegevens.
Actieve gegevens zijn meestal gebeurtenisgestuurd. Een gebruikersactie, een apparaatgebeurtenis, een processtap of een datastoredoorvoering kunnen allemaal een gebeurtenis met een gegevenstoewijzing teweegbrengen. Deze gegevenspayloads zijn van cruciaal belang voor de integratie van Internet of Things (IoT)-systemen, bedrijfsprocessen en databases, datawarehouses en data lakes.
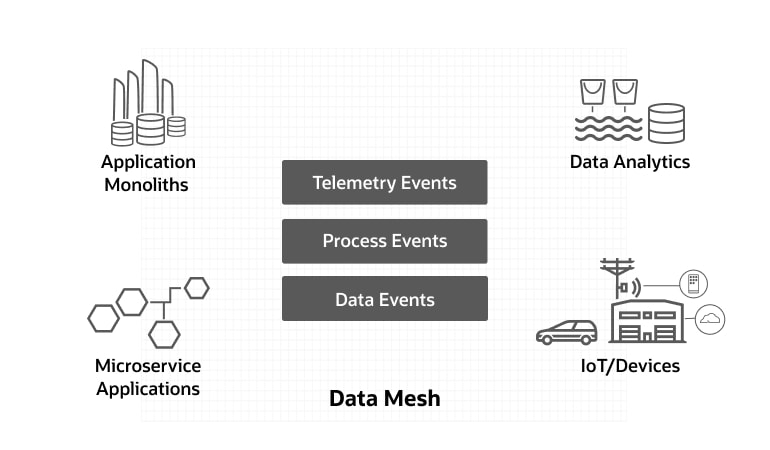
Een datamesh levert de basistechnologie voor realtime integratie in de hele onderneming. Bijvoorbeeld:
- Apparaatgebeurtenissen uit de echte wereld verbinden met IT-systemen
- Bedrijfsprocessen integreren in alle ERP-systemen
- Operationele databases afstemmen op analytische gegevensopslag
Grote organisaties hebben normaal gesproken een mix van oude en nieuwe systemen, monolieten en microservices, operationele en analytische datastores. Een datamesh kan deze middelen van verschillende bedrijfs- en datadomeinen samenbrengen.
5. Stroominvoer (voor analyse)

Analytische gegevensopslag kan datamarts, datawarehouses, OLAP-kubussen, datalakes en datalakehouse-technologieën zijn.
In het algemeen zijn er slechts twee manieren om gegevens in deze analytische datastores in te voeren:
- Batch-/microbatch laden: in een tijdsplanner
- Stroominvoer: onafhankelijk laden van gegevensgebeurtenissen
Een datamesh vormt de basis voor een invoermogelijkheid voor stroomgegevens. Bijvoorbeeld:
- Gegevensgebeurtenissen uit databases of datastores
- Apparaatgebeurtenissen van fysieke apparaattelemetrie
- Registratie van applicatiegebeurtenissen of bedrijfstransacties
Door gebeurtenissen per stroom in te voeren, kan de impact op de bronsystemen worden beperkt, kan de betrouwbaarheid van de gegevens worden verbeterd (belangrijk voor datawetenschap) en kunnen realtime analyses worden uitgevoerd.
6. Stroomgegevenspijplijnen

Zodra de gegevens in de analytische datastores zijn ingevoerd, zijn er gegevenspijplijnen nodig om de gegevens voor te bereiden en te transformeren in verschillende gegevensfasen of -zones. Dit proces van verfijning van gegevens is vaak nodig voor de downstream analytische gegevensproducten.
Een datanetwerk kan een onafhankelijk bestuurde gegevenspijplijnlaag bieden die werkt met de analytische datastores, en de volgende kerndiensten levert:
- Selfservicegegevensdetectie en -voorbereiding
- Governance van gegevensresources tussen domeinen
- Gegevensvoorbereiding en -transformatie in vereiste gegevensproductindelingen
- Gegevensverificatie op basis van beleid dat zorgt voor consistentie
Deze gegevenspijplijnen moeten kunnen werken in verschillende fysieke datastores (zoals marts, warehouses of lakes) of als een "pushdown datastroom" binnen analytische gegevensplatforms die stroomgegevens ondersteunen, zoals Apache Spark en andere data lakehouse-technologieën.
7 Stroomanalyses

Gebeurtenissen vinden continu plaats. De analyse van gebeurtenissen in een stroom kan van cruciaal belang zijn voor inzicht in wat er elk moment gebeurt.
Dit soort op tijdreeksen gebaseerde analyse van realtime gebeurtenisstromen kan belangrijk zijn voor werkelijke IoT-apparaatgegevens en voor inzicht in wat er gebeurt in uw IT-datacenters of in financiële transacties, zoals fraudebewaking.
Een volledig functionele datamesh bevat de basismogelijkheden voor het analyseren van allerlei soorten gebeurtenissen in verschillende tijdvensters. Bijvoorbeeld:
- Eenvoudige analyse van gebeurtenisstromen (webgebeurtenissen)
- Bewaking van bedrijfsactiviteiten (SOAP/REST-gebeurtenissen)
- Complexe verwerking van gebeurtenissen (correlatie van diverse stromen)
- Analyse van gegevensgebeurtenissen (voor DB/ACID-transacties)
Net als gegevenspijplijnen kunnen de stroomanalyses worden uitgevoerd binnen de gevestigde data lakehouse-infrastructuur, of afzonderlijk, als cloudnative diensten.
Behaal maximale waarde met een gemeenschappelijke mesh in het hele gegevensdomein
Koplopers op het gebied van gegevensintegratie streven naar realtime operationele en analytische integratie vanuit diverse veerkrachtige datastores. Er is onophoudelijk en snel geïnnoveerd naarmate de gegevensarchitectuur zich ontwikkelde op het gebied van stroomanalyses. Operationele hoge beschikbaarheid heeft geleid tot realtime analyses en automatisering van data engineering vereenvoudigt de voorbereiding van gegevens, waardoor datawetenschappers en analisten met selfservicetools hun werk kunnen doen.
Overzicht van gebruiksscenario's voor datamesh

Bouw een operationele en analytische mesh voor het hele gegevensgebied
Als al deze gegevensbeheerfuncties in een geïntegreerde architectuur werken, heeft dat invloed op elke gegevensconsument. Een datamesh helpt uw wereldwijde registratie- en betrokkenheidsystemen te verbeteren om betrouwbaar in realtime te werken. Hierdoor worden realtime gegevens beter afgestemd op managers van de branche, datawetenschappers en uw klanten. Het vereenvoudigt ook het gegevensbeheer voor uw microserviceapplicaties van de volgende generatie. Met behulp van moderne analytische methoden en tools kunnen uw eindgebruikers, analisten en datawetenschappers nog beter inspelen op de vraag van de klant en zo de concurrentie voor blijven. Zie de doelen en resultaten van Intuit voor een goed onderbouwd voorbeeld.
Profiteer van een datamesh op puntprojecten
Het is belangrijk om bij uw nieuwe mindset en operationeel model van gegevensproducten ervaring op te doen in elk gebied van deze technologie. Tijdens uw datameshreis kunt u aanzienlijke voordelen behalen door uw snelle gegevensarchitectuur te ontwikkelen op het gebied van stroomanalyses, door uw operationele investeringen in hoge beschikbaarheid te benutten voor realtime analyses en door realtime selfservice-analyses aan te bieden aan uw datawetenschappers en -analisten.
Vergelijken en tegen elkaar afzetten
| Gegevensmateriaal | Integratie van applicatieontwikkeling | Analytische datastore | |||||
|---|---|---|---|---|---|---|---|
| Datamesh | Data-integratie | Metacatalogus | Microservices | Berichten versturen | Data lakehouse | Verspreide DW | |
| Personen, processen en methoden: | |||||||
| Focus op gegevensproducten | beschikbaar |
beschikbaar |
beschikbaar |
1/4 aanbod |
1/4 aanbod |
3/4 aanbod |
3/4 aanbod |
| Technische architectuurkenmerken: | |||||||
| Verspreide architectuur | beschikbaar |
1/4 aanbod |
3/4 aanbod |
beschikbaar |
beschikbaar |
1/4 aanbod |
3/4 aanbod |
| Gebeurtenisgestuurde grootboeken | beschikbaar |
niet beschikbaar |
1/4 aanbod |
beschikbaar |
beschikbaar |
1/4 aanbod |
1/4 aanbod |
| ACID-ondersteuning | beschikbaar |
beschikbaar |
niet beschikbaar |
niet beschikbaar |
3/4 aanbod |
3/4 aanbod |
beschikbaar |
| Stroomgericht | beschikbaar |
1/4 aanbod |
niet beschikbaar |
niet beschikbaar |
1/4 aanbod |
3/4 aanbod |
1/4 aanbod |
| Focus op analytische gegevens | beschikbaar |
beschikbaar |
beschikbaar |
niet beschikbaar |
niet beschikbaar |
beschikbaar |
beschikbaar |
| Focus op operationele gegevens | beschikbaar |
1/4 aanbod |
beschikbaar |
beschikbaar |
beschikbaar |
niet beschikbaar |
niet beschikbaar |
| Fysieke en logische mesh | beschikbaar |
beschikbaar |
niet beschikbaar |
1/4 aanbod |
3/4 aanbod |
3/4 aanbod |
1/4 aanbod |
Bedrijfsresultaten
Algemene voordelen
Snellere, gegevensgestuurde innovatiecycli
Lagere kosten voor bedrijfskritische gegevensbewerkingen
Operationele resultaten
Multicloud-gegevensliquiditeit:
gegevenskapitaal vrij laten stromen
Realtime gegevens delen
: Ops-to-Ops en Ops-to-Analytics
Edge-gegevensservices op basis van locatie:
IRL-apparaat/gegevensgebeurtenissen op elkaar afstemmen
Gegevensuitwisseling over vertrouwde microservices:
sourcing van gebeurtenissen met correcte gegevens
- DataOps en CI/CD voor gegevens
Ononderbroken continuïteit:
99,999% SLA's voor up-time
- Cloudmigraties
Analytische resultaten
Gegevensproducten automatiseren en vereenvoudigen
: gegevenssets met meerdere modellen
Analyse van tijdreeksgegevens
: verschillen/gewijzigde records
: betrouwbaarheid per gebeurtenis
Volledige kopieën van gegevens voor operationele datastore overbodig maken
: op log gebaseerde grootboeken en pijplijnen
Verspreide data lakes en datawarehouses
: hybride/multicloud/wereldwijd
- Streamingintegratie/ETL
Voorspellende analyse
: monetisering van gegevens, nieuwe dataservices te koop
Alles samenbrengen
Digitale transformatie is heel moeilijk, en helaas zal het bij de meeste bedrijven niet helemaal lukken. In de loop der jaren worden technologie, softwareontwerp en gegevensarchitectuur steeds meer verspreid naarmate de moderne technieken steeds minder gecentraliseerd en monolithisch zijn.
Datamesh is een nieuw concept voor gegevens: een verschuiving naar sterk verspreide en realtime gegevensgebeurtenissen, in tegenstelling tot monolithische, gecentraliseerde en batchgewijze gegevensverwerking. In de kern is datamesh een culturele mentaliteitsverandering waarbij de behoeften van de gegevensconsumenten voorop wordt gesteld. Het is ook een ware technologische verschuiving, waarbij de platforms en diensten die een gedecentraliseerde gegevensarchitectuur mogelijk maken centraal staan.
Gebruiksscenario's voor datamesh omvatten zowel operationele als analytische gegevens, wat een belangrijk verschil is tussen conventionele data lakes/lakehouses en datawarehouses. Deze afstemming van operationele en analytische gegevensdomeinen is een kritieke factor voor de behoefte aan meer selfservice voor de gegevensconsument. Moderne gegevensplatformtechnologie kan de tussenpersoon wegnemen door gegevensproducenten rechtstreeks met gegevensconsumenten te verbinden.
Oracle is al lang de marktleider in essentiële gegevensoplossingen en heeft enkele van de modernste functies ontwikkeld voor het leveren van betrouwbare gegevenstools:
- Generation 2 Cloud-infrastructuur van Oracle met meer dan 33 actieve regio's
- Database voor meerdere modellen voor veranderende gegevensproducten
- Gebeurtenisgestuurd gegevensgrootboek op basis van microservices voor alle datastores
- Multicloud-stroomverwerking voor realtime vertrouwde gegevens
- API-platform, moderne AppDev en selfservice-tools
- Analyses, gegevensvisualisatie en cloud-native datawetenschap