 System Admins and Developers
System Admins and Developers
アプリケーションのシリアル・パフォーマンスを最適化する方法
Oracle Solaris Studio 12.3
Darryl Gove、2011年12月
この記事では、Oracle Solaris Studioを使用し、適切なコンパイラ・フラグ、コンパイラ・オプション、およびその他の最適化を選択して、アプリケーションのシリアル・パフォーマンスを最適化する方法について説明します。
はじめに
SPARCアプリケーションまたは86アプリケーションで最適なパフォーマンスを得るには、最新のコンパイラを使用して、最善かつ最適な一連のコンパイラ・オプションを選択します。 Oracle Solaris Studioコンパイラは、このコンパイラを使って構築されたアプリケーションで、追加設定なしに最適なパフォーマンスを実現するべく機能します。 ただし、多くの場合、コンパイラ・オプションに少し微調整を加えることで、パフォーマンスの向上を得ることができます。 したがって、アプリケーションの最終バージョンをリリースする前に、実験的に最適化とチューニングに取り組むことが重要です。
このプロセスの一環として、アプリケーションで行った前提と合わせて、コンパイラはどう機能すべきかを正しく理解することが重要です。 特に、適切なコンパイラ・オプションを選択する際に、次の2つの重要な点を確認する必要があります。
- コンパイルされるアプリケーションが最終的に動作するプラットフォームに関して、把握していることは何か。
- コードで行われる前提に関して、把握していることは何か。
このほか、特定のコンパイルの目的について考慮すると役立ちます。 コンパイラ・オプションでは、特定のコンパイルがデバッグ、テスト、チューニング、または最終的なパフォーマンス最適化のいずれを支援することを目的としているかに応じて、さまざまなトレードオフを行うことができます。
注: この記事では、アプリケーションのシリアル・パフォーマンスの最適化について説明します。 マルチスレッド・アプリケーションまたはパラレル・アプリケーションの最適化については、『アプリケーションのパラレル・パフォーマンスを最適化する方法』を参照してください。
ターゲット・プラットフォームの特定
どの最適化オプションが適切なのかを把握するためには、コードを最終的にどのプラットフォームで実行するかを把握することが不可欠です。 プラットフォームの選択により、以下のことが決まります。
- 32ビットの命令セットか64ビットの命令セットか
- パフォーマンスを高めるためにコンパイラで使用できる、命令セットの拡張機能
- 命令実行時間に基づいた、命令のスケジューリング
- キャッシュ構成
32ビット・コードまたは64ビット・コードの生成
SPARCおよびx86プロセッサ・ファミリーでは、32ビット・コードと64ビット・コードの両方を実行できます。 64ビット・コードのおもな利点は、アプリケーションで32ビット・コードよりも大規模なデータセットを処理できることです。 ただし、この大容量のアドレス空間のために、変数の型が長くなり、ポインタのサイズが4バイトから8バイトに大きくなるため、アプリケーションのメモリ・フットプリントが大きくなります。 メモリ・フットプリントが大きくなるため、64ビット・バージョンのアプリケーションは32ビット・バージョンのアプリケーションよりも実行速度が遅くなる可能性があります。
その一方で、x86プラットフォームでは、64ビット・コードを実行した場合に、32ビット・コードを実行した場合と比較してアーキテクチャ上の利点がいくつかあります。 特に、アプリケーションでさらに多くのレジスタを使用でき、呼び出し規則が改善します。 これらの利点により、x86プラットフォームでは、通常、アプリケーションのメモリ・フットプリントが大幅に大きくならない限り、64ビット・バージョンのアプリケーションを同じコードの32ビット・バージョンよりも高速で実行できます。
SPARCプロセッサ・ラインでは、32ビット・バージョンのアプリケーションで64ビット命令セットのアーキテクチャ機能を使用できるように設計されていることから、異なるアプローチを取っています。 そのため、32ビット・コードから64ビット・コードに移行しても、アーキテクチャ上のパフォーマンス向上はありません。 つまり、SPARCプロセッサ用にコンパイルした64ビット・アプリケーションでは、メモリ・フットプリントが大きくなる分、コストが高くなるだけです。
32ビット・バイナリと64ビット・バイナリのいずれを生成するかを決定するのは、コンパイラ・フラグです。
- 32バイナリを生成するには、
-m32フラグを使用します。 - 64ビット・バイナリを生成するには、
-m64フラグを使用します。
32ビット・コードから64ビット・コードへの移行について、詳しくは『32ビット・アプリケーションから64ビット・アプリケーションへの変換:検討事項)』および『Sun Studio 10 Toolsetによる64 ビットx86の移行、デバッグ、チューニング』を参照してください。
適切なターゲット・プロセッサの指定
Oracle Solaris Studioコンパイラでは、-xtargetコンパイラ・フラグを使用してターゲット・プロセッサを非常に柔軟に選択できます。 コンパイラのデフォルトでは、"汎用"のバイナリ、つまりすべてのプラットフォームで適切に動作するバイナリが生成されます(-xtarget=generic)。 多くの状況で、汎用のバイナリは最適な選択肢となります。 ただし、次のような、異なるターゲットを選択するのが適切な状況もあります。
- 以前のターゲット設定をオーバーライドする。 コンパイラでは、オプションは左方向から右方向に評価されます。 コンパイル行に
-fastフラグを指定する場合、別の選択を行って暗黙的な設定-xtarget=nativeをオーバーライドするのが適切なことがあります。 - 特定のプロセッサの機能を利用する。 たとえば、新しいプロセッサほど、パフォーマンスの向上に活用できるさまざまな機能を備えている傾向があります。 これらの機能を備えていない古いプロセッサでは動作しないバイナリを生成すれば、コンパイラでこれらの機能を使用できます。
-xtargetフラグでは、実際には次の3つのフラグを設定します。
-xarchフラグでは、ターゲット・マシンのアーキテクチャを指定します。 このアーキテクチャは、基本的に、コンパイラが使用できる命令セットです。 アプリケーションを動作させるプロセッサが該当するアーキテクチャをサポートしていない場合は、アプリケーションが動作しない可能性があります。-xchipフラグでは、コンパイラに対して、コードを実行しているプロセッサを前提とするように指示します。 このフラグで、同じ処理のコーディングを複数の方法の中から選択する場合に、どの命令パターンを優先するかをコンパイラに指示します。 また、ストールを最小限に抑えるように命令をスケジューリングするため、使用する命令待機時間もコンパイラに指示します。-xcacheフラグでは、コンパイラに対して、キャッシュ階層を前提とするように指示します。 この選択は、操作対象のデータがキャッシュ内に収まるようにコンパイラがループの調整方法を選択できる状況において、浮動小数点コードに大きく影響する可能性があります。
SPARCプロセッサ・ファミリーのターゲット・アーキテクチャ
SPARCプロセッサ・ファミリーでは、ほとんどの状況でデフォルト設定-xtarget=genericが適しています。 この設定では、-m32フラグを使用すると、SPARC V8の命令セットを使用する32ビット・バイナリが生成され、-m64フラグを使用すると、SPARC V9の命令セットを使用する64ビット・バイナリが生成されます。 ターゲット・アーキテクチャを考慮に入れて異なる設定を指定する必要がある状況として、もっとも一般的な状況は、大量の浮動小数点計算が含まれたコードをコンパイルするという場合です。
たとえば、最新のSPARCプロセッサでは、浮動小数点乗累算(FMAまたはFMAC)命令をサポートしています。 これらの命令では、浮動小数点乗算と浮動小数点加算(または減算)を組み合わせて1つの演算にします。 FMA演算では通常、浮動小数点加算または浮動小数点乗算として完了するのに同じサイクル数が必要なため、これらの命令の使用により、パフォーマンスが大幅に向上します。 ただし、FMA命令を使用するようにコンパイルしたアプリケーションでは、命令を使用しないように同じアプリケーションをコンパイルした場合とは、結果が異なる可能性があります。 また、FMA命令を使用するようにコンパイルしたコードは、FMA命令をサポートしていないプラットフォームでは動作しません。
この説明として、以下の処理について考えてみます。 方程式に単語ROUNDを使用すると、Resultに保存されるときに、表現できるもっとも近い浮動小数点数に値が四捨五入されることを意味します。
Result = ROUND( (value1 * value2) + value3)
この1つのFMA命令は、次の2つの命令に置き換わるものです。
tmp = ROUND(value1 * value2) Result = ROUND(tmp + value3)
2つのバージョンの命令では、2つの四捨五入演算があることに注意してください。 計算した結果の最小位ビットが異なる可能性があるのは、このように四捨五入演算の数が異なるためです。 FMA実装は、融合型FMAとも呼ばれます。
FMA命令を生成するには、次のフラグを使用してバイナリをコンパイルします。
-xarch=sparcfmaf -fma=fused
あるいは、フラグ-xtarget=sparc64vi -fma=fusedまたはフラグ-xarch=sparcvis3 -fma=fusedを使用して、FMA命令を生成することもできます。 先に説明したように、生成されたコードは、FMA命令をサポートしていないプラットフォームでは動作しません。
x86プロセッサ・ファミリーのターゲット・アーキテクチャ
デフォルトでは、Oracle Solaris Studioコンパイラは32ビット汎用x86ベースのプロセッサをターゲットとするため、生成されたコードは、Intel Pentium Proから最新のIntelプロセッサ、AMD Opteronプロセッサまで、すべてのx86プロセッサで動作します。
-xtarget=genericを使用すると、もっとも広範囲なプロセッサで実行できるコードが生成されますが、このコードでは、最新のプロセッサで提供されているストリーミングSIMD拡張命令2(SSE2)の拡張機能を利用できません。 これらの命令を活用するには、フラグ-xarch=sse2を使用します。 ただし、ベクター化フラグ-xvector=simdも使用しないと、コンパイラがこれらの命令を使用する状況をすべて認識するとは限りません。
SPARCおよびx86ターゲット・アーキテクチャに適した推奨されるコンパイラ・フラグのまとめ
表1は、さまざまなSPARCおよびx86ターゲット・アーキテクチャでのコンパイルに推奨されるOracle Solaris Studioコンパイラ・フラグをまとめたものです。
表1. Oracle Solaris Studioフラグでのアーキテクチャとアドレス空間の指定| アーキテクチャ | 32ビット・アドレス空間 | 64ビット・アドレス空間 |
|---|---|---|
| SPARC | -xtarget=generic -m32 |
-xtarget=generic -m64 |
| SPARC64、SPARC T3 | -xtarget=sparc64vi -m32 -fma=fused |
-xtarget=sparc64vi -m64 -fma=fused |
| x86 | -xtarget=generic -m32 |
-xtarget=generic -m64 |
| X86/SSE2 | -xtarget=generic -xarch=sse2 -m32 -xvector=simd |
-xtarget=generic -xarchsse2 -m64 -xvector=simd |
コンパイラ最適化オプションの選択
コンパイラ・オプションの選択では、コンパイル時間、ランタイム、および(恐らく)アプリケーション動作の間でトレードオフを行います。 選択する最適化フラグに応じて、次の3つの重要な特性が変わります。
- コンパイルしたアプリケーションのランタイム
- コンパイルの所要時間
- 最終のバイナリで生じる可能性があるデバッグ作業の量
通常、最適化のレベルが高ければ高いほど、アプリケーションの実行速度が速くなります(また、コンパイルにかかる時間が長くなります)が、使用できるデバッグ情報が少なくなります。 最終的に、最適化レベルの個々の影響は、アプリケーションによって異なります。 これらのトレードオフの検討を最も簡単にするには、表2に示すように、3つのレベルの最適化を検討します。
表2. 3つのレベルの最適化と生成されるコードへの影響| 目的 | フラグ | コメント |
|---|---|---|
| 完全なデバッグ機能 | -g(最適化フラグなし) |
アプリケーションで完全なデバッグ機能を使用できますが、アプリケーションで最適化がほとんど実行されないため、パフォーマンスが低くなります。 |
| 最適化 | -g -O |
アプリケーションで適切なデバッグ機能を使用できます。また、アプリケーションで一連の適切な最適化が実行されるため、通常、パフォーマンスが大幅に向上します。 |
| 高い最適化 | -g -fast |
アプリケーションで適切なデバッグ機能を使用できます。また、アプリケーションで一連の最適化が数多く実行されるため、通常、高いパフォーマンスが得られます。 |
デバッグを目的としたコンパイル(-g)
-gオプションは、アルゴリズムのエラーがないかどうかをチェックできる、高性能なデバッグ・オプションです。 このフラグ・セットを使用すると、コードは記述したとおりに実行され、デバッガで変数を調べることができます。 最適化レベルが低いため、-gフラグでは、一部の小規模な最適化は無効になります(生成されるコードのデバッグを容易にするため)。 このフラグを高い最適化レベルで使用しても、生成されるコード(またはパフォーマンス)は変わりません。 ただし、高い最適化レベルでは、デバッガを使用して、逆アセンブルされたコードを正確なソース・コード行に常に関連付けできたり、メモリに保存されるのではなくレジスタに保持されているローカル変数の値を必ずしも特定できたりするとは限らないことに注意してください。
-gフラグを使ってコンパイルする大きな理由は、Oracle Solaris Studioのパフォーマンス・アナライザを使って、コードの所要時間をソース・コード行に直接割り当てることができるためです。これにより、パフォーマンスのボトルネックを特定するプロセスが大幅に容易になりまます。 パフォーマンス・アナライザの使用について、詳しくは『アプリケーション・パフォーマンスを分析および向上する方法』を参照してください。
基本的な最適化を目的としたコンパイル(-O)
基本的な最適化を行うには、-Oコンパイラ・フラグを使用します。 -Oフラグを使用すると、アプリケーションのコンパイルにそれほど長い時間をかけずに、適切なランタイム・パフォーマンスを実現できます。 最適化にデバッグ情報を組み込むには、-Oフラグに-gフラグを追加します。
Oracle Solaris Studioコンパイラ(-O3、-O4、-O5など)には、さまざまなレベルの最適化が用意されています。 これらのオプションについて、詳しくはOracle Solaris Studioのドキュメントを参照してください。
積極的な最適化を目的としたコンパイル(-fast)
コードを最適化するときに、出発点として-fastオプションを使用することが推奨されますが、得られたアプリケーションで意図した最適化が実現されない場合があります。 -fastオプションは、特定の選択されたコンパイラ・オプションとして定義されているため、リリースごとやコンパイラ間で変更される可能性があります。
また、-fastで選択したコンポーネント・オプションを、一部のプラットフォームで利用できない場合があります。 さらに、アプリケーションのコンパイルと関連付けを別々に実行する場合は、注意する必要があります。 この場合、適切に動作させるには、-fastを使用してアプリケーションのコンパイルと関連付けの両方を行います。
-fastオプションは、数多くの個々のコンパイル最適化を意味します。 これらの個々のオプションのオン/オフを自由に切り替えることができます。 -fastオプションを客観的に適用するのが理想的です。 たとえば、-fastを使ったコンパイルで5倍のパフォーマンスが得られる場合、-fastに含まれているどの特定のオプションがパフォーマンスの向上をもたらすかを確認するのは、明らかに価値があります。 以降のビルドでこれらのオプションを個別に使用すれば、さらに確定的かつ的を絞った最適化を実行できます。
-fastコンパイラ・フラグを使用する場合、次の影響に注意してください。
- ターゲット・アーキテクチャへの影響。
-fastコンパイラ・フラグを設定すると、-xtarget=nativeがコンパイルに設定されます。 このオプションで、開発システムのネイティブのチップと命令セットが検出され、そのシステムのコードがターゲットとなります。 そのため、ターゲット・プラットフォームが開発システムと同じであることが分かっている場合のみ、-xtarget=nativeを使用します。 そうでない場合は、-xtarget=genericを設定するか、-xtargetフラグを使用して目的のターゲット・アーキテクチャを選択します。
たとえば、FMA命令は、最新のSPARCプロセッサに実装されていますが、現在、古いプロセッサには実装されていません。 そのため、最新のSPARCシステムで構築し、
-xtarget=native -fma=fusedを使ってコンパイルしたバイナリは、古いシステムでは動作しません。 同じ問題が、古いx86プロセッサとシステムでは利用できない、Intel x86アーキテクチャのストリーミングSIMD拡張命令(SSE)の命令にも当てはまります。 - 浮動小数点演算への影響。
-fastオプションには、-fnsフラグと-fsimpleフラグによる浮動小数点演算の簡素化も含まれています。-fnsと-fsimpleを使用すると、パフォーマンスを大幅に向上できます。 ただし、これらのフラグを使用すると、精度が低下する上、コンパイラでIEEE-754の浮動小数点演算規格に準拠していない一部の最適化が実行されてしまいます。 浮動小数点表記の順序変更についても、言語規格への準拠が厳密でなくなります。 次に例を挙げます。
-fnsフラグを設定すると、非正規化数がゼロにフラッシュされます。 非正規化数は、正規形では小さすぎて表現できない、非常に小さい数です。-fsimpleを使用すると、たとえば、加算を実行する順序は重要ではなく、除算演算は逆数によって乗算に置き換えるのが安全であることを前提とするなど、数学の教科書で演算を示しているように、コンパイラで浮動小数点演算を処理できます。 紙の上での計算では、このような前提と変換は完全に受け入れられると思われますが、代数で精度の低い数を使った実際の数値計算になると、計算の精度が低下する可能性があります。 また、-fsimpleを使用すると、コンパイラで、浮動小数点計算において使用するデータがNaN(Not a Number)とならないように最適化を設定できるようになります。 NaNを使った計算を想定している場合は、コンパイルに-fsimpleを使用することは推奨されません。
そのため、これらのフラグを本番コードで使用することを決定する前に、パフォーマンスが向上するかどうか時間をかけて評価し、結果を慎重に確認してください。
- ポインタの別名設定への影響。
-fastコンパイラ最適化タグを使用すると、基本型では別名設定しないことがアサートされるため、コーディングの前提を確認する必要があります。 別名設定されたポインタは同じメモリ領域を指すため、一方のポインタからアクセスされる値を更新したら、もう一方のポインタからアクセスされる値も更新する必要があります。
以下のコードでは、
aとbが同じ(最初はゼロの)メモリの位置を指す場合、出力はa=2 b=2になります。 ただし、コンパイラでは別名設定がないことを前提としているため、コンパイラはaを読み取り、bを読み取り、aを増分し、bを増分し、aをメモリに格納し、bをメモリに格納し、print a=1 b=1になります。void function (int *a, int *b) { *b++; *a++; printf("a = %i b= %i\n",*a,*b) }コンパイラでは、別名設定は、あるポインタによってアドレス指定されているメモリに格納すると、他のポインタによってアドレス指定されているメモリが変更になる可能性があることを意味します。 そのため、コンパイラでは、式内の格納とロードの順序を変更しないように細心の注意を払う必要があります。また、コンパイラでは、新しいデータがメモリに格納されたら、ポインタによってアクセスされるメモリの値が再ロードされるようにする必要があります。 コンパイラでは、アサーションの違反があったかどうかはチェックされません。そのため、ソース・コードがアサーションに違反している場合、アプリケーションが意図したようには動作しない可能性があります。 コンパイラ・フラグで許可されている別名設定のレベルにソース・コードが従っていない場合、アプリケーションで生成される結果は予測できないものになります。
以下のフラグで、コンパイラに対して、コード内で前提とする別名設定のレベルを指示します。
-xrestrictでは、関数に渡されるすべてのポインタが制限付きのポインタであることをアサートします。 つまり、-xrestrictを使って2つのポインタが関数に渡された場合、コンパイラでは、これらの2つのポインタは重複したメモリを指さないことを前提とします。-xalias_levelでは、2つの異なるポインタ間の別名設定のレベルに関して、どのような前提を取ることができるかを示します。-xalias_levelは、コーディング・スタイルに関する文であると見なすことができます。 このフラグを使用して、コンパイラに対して、使用しているコーディング・スタイルでのポインタの処理方法を通知します。 たとえば、コンパイラ・フラグ-xalias_level=basicを使用して、コンパイラに対して、整数値を指すポインタは浮動小数点値を指すポインタと同じ位置を指さないことを通知します。
その他の最適化
最適化フラグに加えて、その他のさまざまなフラグと手法を使ってパフォーマンスを向上できます。
クロスファイルの最適化(-xipo)
-xipoオプションでは、リンク時にプログラム全体でプロシージャ間の最適化を実行します。 このアプローチを使用すると、さらに最適化を行う余地があるかどうか、リンク時に再度、オブジェクト・ファイルを確認します。 その際、あるファイルのコードを別のファイルのコードにインライン化するのが、最適化の余地としてもっとも一般的です。 インライン化とは、コンパイラによって、あるルーチンの呼び出しをそのルーチンからの実際のコードに置き換えることです。
インライン化は、2つの理由で役立ちます。まず、最も大きな理由として、別のルーチンを呼び出す際のオーバーヘッドを排除できます。 次に大きな理由として、インライン化によって、オブジェクト・コードで実行できる他のさらなる最適化が明らかになることがあります。 たとえば、次のルーチンでは、画像内の特定のポイントの色を計算するのに、ポイントの位置xと位置yを取得し、画像が含まれているメモリ・ブロック内のポイントの位置を計算しています。
int position(int x, int y)
{
return x + y*row_length;
}
for (x=0; x<100; x++)
{
value +=array[position(x,y)];
}
画像内のすべてのピクセルで動作するルーチンにコードをインライン化することで、コンパイラでは、乗算と加算を実行して各ポイントの各アドレスを計算する代わりに、次のポイントに到達するために現在のオフセットに1を追加するだけのコードを生成でき、その結果パフォーマンスが向上します。
for (x=0; x<100; x++)
{
value += array[x + y*row_length];
}
このコードをさらに最適化できます。
ytmp=y*row_length;
for (x=0; x<100; x++)
{
value += array[x+ytmp];
}
-xipoを使用した場合の欠点は、アプリケーションのコンパイル時間が大幅に長くなる可能性があること、また実行可能ファイルのサイズも大きくなる可能性があることです。 コンパイル時間が長くなってもパフォーマンスの向上に見合うかどうか、-xipoでコンパイルして確認する価値があります。
プロファイル・フィードバック(-xprofile=collect、-xprofile=use)
プログラムをコンパイルする際、コンパイラでは、プログラムのフロー(使用する分岐と使用しない分岐)の処理方法で、最善の方法を推測します。 大量の浮動小数点計算が含まれているコードでは、このアプローチで通常、適切なパフォーマンスが得られます。 ただし、多くの分岐処理が伴う整数プログラムでは、コンパイラの近似処理で最適なパフォーマンスが得られない場合があります。
プロファイル・フィードバックは、プログラムのサンプル実行に基づいて、実際に取得されるパスの実際の情報をコンパイラに提供することで、コンパイラがアプリケーションを最適化するのを支援します。 コードを介して重要なルートを把握することで、コンパイラではこれらのルートを確実に最適化できます。
プロファイル・フィードバックを使用するには、以下の手順を実行します。
-xprofile=collectフラグ・セットを使用して、特定のバージョンのアプリケーションをコンパイルします。- 代表的な入力データを使ってアプリケーションを実行し、ランタイム・パフォーマンス・プロファイルを収集します。
-xprofile=useと収集したパフォーマンス・プロファイル・データを組み合わせて使用し、アプリケーションを再コンパイルします。
このアプローチの欠点は、このアプローチが2回のコンパイルおよび1回のアプリケーション実行から成るため、コンパイル・サイクルが大幅に長くなる可能性があることです。 利点は、コンパイラでさらに最適な実行パスを生成して、アプリケーションのランタイムを高速化できることです。
代表的なデータセットとは、本番環境でアプリケーションに使用される実際のデータと同様の方法で、コードを実行するデータセットのことです。 また、代表的なデータセットを構築するために、アプリケーションをさまざまなワークロードで何度でも実行できます。 言うまでもなく、代表的なデータで、実際のワークロードの代表的ではない方法でコードの実行を管理する場合は、パフォーマンスが最適にならない可能性があります。 ただし、コードは通常、同様のルートで実行されるため、データが代表的であるかどうかに関係なく、多くの場合パフォーマンスが向上します。
ワークロードが代表的かどうかの判断について、詳しくは『カバレッジ分析と分岐分析を使用したプロファイル・フィードバック用の代表的な評価ワークロードの選択』を参照してください。
最適化の実践例
最適化は、さまざまな最適化を、その最適化で得られる利点と照らし合わせて評価する、段階的なプロセスです。 大きなパフォーマンス差をもたらす最適化については、最終的な実行可能なアプリケーションを構築するための候補として留意します。 さまざまなチューニング・オプションの例として、ここでは、マンデルブロ集合を計算する簡単なプログラムについて検討します。 リスト1に、このアプリケーションのコードを示します。
リスト1. マンデルブロ・アプリケーションのコード
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define SIZE 4000
int ** data;
int ** setup()
{
int i;
int **data;
data=(int**)malloc(sizeof(int*)*SIZE);
for (i=0; i<SIZE; i++)
{
data[i]=(int*)malloc(sizeof(int)*SIZE);
}
return data;
}
int inset(double ix, double iy)
{
int iterations=0;
double x=ix, y=iy, x2=x*x, y2=y*y;
while ((x2+y2<4) && (iterations<1000))
{
y = 2 * x * y + iy;
x = x2 - y2 + ix;
x2 = x * x;
y2 = y * y;
iterations++;
}
return iterations;
}
void loop()
{
int x,y;
double xv,yv;
#pragma omp parallel for private(y,xv,yv) schedule(guided)
for (x=0; x<SIZE; x++)
{
for (y=0; y<SIZE; y++)
{
xv = ((double)(x-SIZE/2))/(double)(SIZE/4);
yv = ((double)(y-SIZE/2))/(double)(SIZE/4);
data[x][y]=inset(xv,yv);
}
}
if (data[7][7]<0) {printf("Error");}
}
void main()
{
data = setup();
loop();
}
ベースラインを判断するため、まず、-g、-O、および-xtarget=genericコンパイラ・フラグを使用してアプリケーションをコンパイルします。 以下に、アプリケーション・ランタイムのタイミング情報を示します。
% cc -g -O -xtarget=generic mandle.c % timex ./a.out real 33.02 user 32.88 sys 0.09
このケースの開発システムはx86アーキテクチャに基づいているため、SSE2命令の使用を指定して、これらの命令を使用するとパフォーマンスが向上するかどうかを確認することに意味がありました。 -xtarget=nativeを使用する場合は、-xarch=sse2フラグを意味するため、このケースと同じ結果が得られます。
% cc -g -O -xarch=sse2 mandle.c % timex ./a.out real 12.05 user 11.92 sys 0.08
このケースでは、コンパイラに対してSSE2命令を生成しないように指示する場合と比較して、SSE2命令を使用し、コードの実行速度はほぼ3倍になります。 幸いなことに、現在、ほとんどのx86プロセッサがSSE2命令をサポートしているため、使用可能なハードウェアのほとんどがSSE2命令をサポートしていると想定しても比較的安全です。
次に、マンデルブロ計算の計算処理を実行するループについて記述したOpenMPディレクティブの使用をトリガーするように、-xopenmpフラグを設定します。 パラレル化されるループに関する情報を生成するように、また、潜在的な問題をレポートするように、-xvparaフラグと-xloopinfoフラグを指定します。
注: パラレル化と、-xopenmp、-xvpara、および-xloopinfoコンパイラ・フラグについて、詳しくは『アプリケーションのパラレル・パフォーマンスを最適化する方法』を参照してください。
% cc -g -O -xopenmp -xvpara -xloopinfo mandle.c "mandle.c", line 13: not parallelized, call may be unsafe "mandle.c", line 25: not parallelized, loop has multiple exits "mandle.c", line 41: PARALLELIZED, user pragma used "mandle.c", line 43: not parallelized, loop inside OpenMP region
環境変数OMP_NUM_THREADSを2に等しくなるように設定して、生成されたコードを実行します。
% export OMP_NUM_THREADS=2 % timex ./a.out real 8.72 user 11.92 sys 0.08
このケースでは、同じ量の処理が実行されるため、ユーザー時間が同じ(11.92秒)になることに注意してください。 ただし、2つのスレッドで処理が実行されるようになったため、実際の時間(実測時間)は短くなります。 2つのスレッド間で処理が不均等であるため、残念ながら、パフォーマンスは2倍にはなりません。 片方のスレッドでまず終了するため、遅いほうのスレッドでのパフォーマンスの向上が制限されています。 この動作を確認するには、プロファイル・アナライザを使用してプロファイルを収集し、図1に示すようにタイムライン表示を確認します(パフォーマンス・アナライザの使用について、詳しくは『アプリケーション・パフォーマンスを分析および向上する方法』を参照してください)。
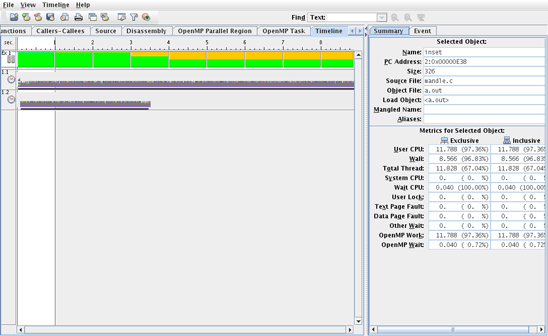
図1. パフォーマンス・アナライザのタイムライン表示で、スレッドの処理が2つのスレッドで均等に分割されていないことを把握
OpenMPディレクティブschedule(guided)を使用して、ループに使用されているスケジューリングを変更します。 このディレクティブを使用すると、2つのスレッドに処理を均等に分割する際、静的に分割するのではなく、各スレッドの所要時間がほぼ同じになるように、実行時に処理を動的に分割できます。 ソース・コードにこのわずかな変更を行って、アプリケーションを再コンパイルすると、ランタイム・パフォーマンスがさらに向上し、33秒以上かかっていた所要時間が7秒未満にまで高速化されます。
% timex ./a.out real 6.90 user 11.94 sys 0.08
図2に、最終的なマンデルブロ・アプリケーションの実行を表示した、Oracle Solaris Studioの統合開発環境(IDE)を示します。
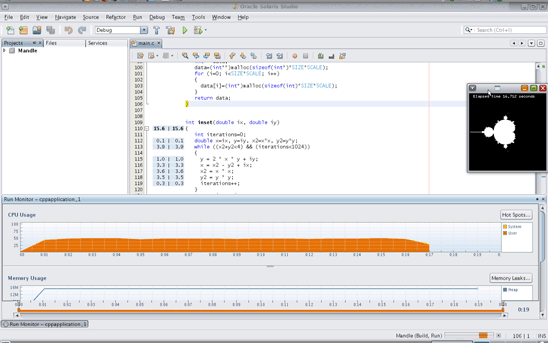
図2. IDEで、マンデルブロ・アプリケーションの最終的なプロファイル結果を確認
追加情報
コンパイラ・フラグとオプションについて、詳しくはOracle Solaris Studioの完全な製品ドキュメント(http://oracle.com/technetwork/server-storage/solarisstudio/documentation/oss123-docs-1357739.html)を参照してください。
次のドキュメントも参照してください。
- 『Oracle Solaris Studioでアプリケーション・パフォーマンスを最適化する方法』
- 『アプリケーション・パフォーマンスを分析および向上する方法』:
- 『アプリケーションのパラレル・パフォーマンスを最適化する方法』
- Oracle Solaris Studio製品のページ
| リビジョン1.0、13.12.11 |
Facebook、Twitter、またはOracle Blogsで最新情報をご確認ください。