
了解您的客户及其行为,预测客户需求
金融服务组织(特别是零售银行、信用卡发行机构、私人财富管理公司和保险公司等消费领域的金融服务组织)非常依赖客户、市场、产品等方面的情报信息来成功开展营销活动、交叉销售和追加销售,以及在整个合作关系存续过程中为客户提供有效支持。在某些使用场景下 — 如提供产品建议、预测和响应客户需求、解决客户满意度问题 — 甚至需要实时情报。此外,此类企业还需要收集合适的数据用于模型学习,以便生成洞察,帮助改善营销、销售、运营以及最关键的客户体验。
在所有这些使用场景中,客户知识是重中之重。从对客户与组织之间多次互动的基础了解,到深入、详细地了解每位客户的行为、预期和金融服务互动背后隐藏的需求,360 度客户视图的概念如今已得到全面普及。当今的客户希望能够简单、便捷、直观地进行每一次互动 — 无论是点外卖、申请保险理赔还是开立支票账户,或者在线互动、使用 APP 或面对面互动 — 他们都希望获得始终一致、有凝聚力的无缝体验。
高满意度客户在现有银行开设新账户或购买新产品的可能性是勉强满意客户的 2.5 倍。尽管银行业为满足不断增长的客户期望持续投入了大量资源,但受到传统 IT 基础设施和数据孤岛的限制及其带来的数据质量和数据血统挑战的影响,他们仍然难以跟上零售行业的步伐。即使是客户体验超过平均水平的银行,通常也只有一半到三分之二的客户用“卓越”一词来评价其客户体验。
要满足客户期望,金融服务组织应继续应对传统基础设施中的孤立数据所带来的挑战,同时利用机器学习、人工智能和 360 度客户数据从被动互动转变为预测性互动。实现这一目标后,企业将获得巨大回报。据 McKinsey 发布的一份分析报告显示,在过去三年,客户体验排名前四的美国零售银行的存款增长明显高于同行,这一切都归功于他们维护现有客户和吸引新客户的能力。
利用机器学习充分发挥客户知识的价值
以下架构展示了 Oracle Data Platform 如何帮助金融服务组织对所有可用数据应用高级分析、机器学习和人工智能,利用从数据中获取的必要洞察打造高度相关、实时、个性化的客户体验。借助 Oracle Data Platform,他们将可以专注于主动互动,在从购物和开户到客户引导、关系扩展以及服务交付或保险理赔处理的整个客户生命周期中完美地执行每个接触点。
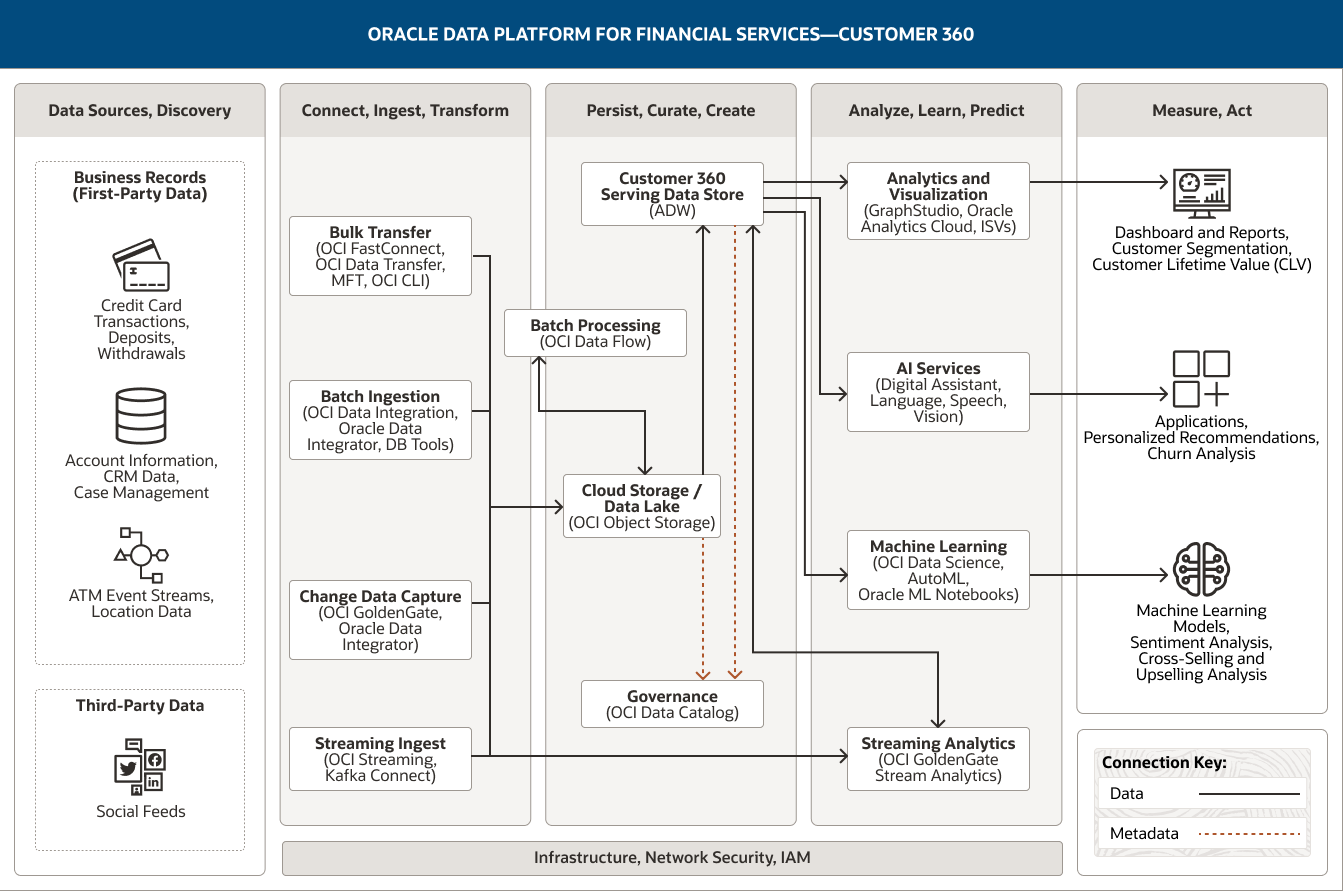
该图展示了面向金融服务行业的 Oracle Data Platform 可如何用于支持 360 度客户视图活动。该平台包括以下五个支柱:
- 1. 数据源、探索
- 2. 连接、摄取、转换
- 3. 持久保存、整理、创建
- 4. 分析、学习、预测
- 5. 评估、行动
“数据源、探索”支柱包括两类数据。
- 1. 业务记录(第一方数据)包括信用卡交易、存款、提款、账户信息、CRM 数据、案例管理数据、ATM 事件流和地点数据。
- 2. 第三方数据包括社交馈送。
“连接、摄取、转换”支柱包括四个功能。
- 1. 批量传输使用 OCI FastConnect、OCI Data Transfer、MFT 和 OCI CLI。
- 2. 批量摄取使用 OCI Data Integration、Oracle Data Integrator 和数据库工具。
- 3. 更改数据捕获使用 OCI GoldenGate 和 Oracle Data Integrator。
- 4. 流摄取使用 OCI Streaming 和 Kafka Connect。
所有四种功能都单向连接到“持久保存、整理、创建”支柱中的云端存储/数据湖功能。
此外,流摄取连接至“分析、学习、预测”支柱中的流处理。
“持久保存、整理、创建”支柱包括四个功能。
- 1. 360 度客户视图服务数据存储使用 Autonomous Data Warehouse 和 Exadata Cloud Service。
- 2. 云端存储/数据湖使用 OCI Object Storage。
- 3. 批处理使用 OCI Data Flow。
- 4. 治理使用 OCI Data Catalog。
这些功能在支柱内互联。云端存储/数据湖不仅单向连接至服务数据存储,还双向连接至批处理。
其中一个功能可连接至“分析、学习、预测”支柱:服务数据存储不仅单向连接至分析和可视化、人工智能服务和机器学习功能,还双向连接至流分析能力。
“分析、学习和预测”支柱包括四个功能。
- 1. 分析和可视化使用 Oracle Analytics Cloud、GraphStudio 和 ISV。
- 4. AI 服务使用 Oracle Digital Assistant、OCI Language、OCI Speech 和 OCI Vision。
- 3. 机器学习使用 OCI Data Science、Auto ML 和 Oracle Machine Learning Notebooks。
- 4. 流分析使用 OCI GoldenGate Stream Analytics。
“测量、行动”支柱包括三个使用者:仪表盘和报告、应用和机器学习模型。
“仪表盘和报告”包括客户细分以及客户终身价值 (CLV)
应用包括个性化建议和流失分析
机器学习模型包括情感分析、交叉销售和追加销售分析
“摄取、转换”、“持久保存、整理、创建”及“分析、学习、预测”这三大核心支柱由基础设施、网络、安全和 IAM 提供支持。
目前有三种主要方法可以将数据注入架构,帮助金融服务组织识别创建 360 度客户视图。
- 首先,我们需要摄取客户交易数据。交易数据包括存款和提款;这些数据是高度结构化的,通常存储在核心银行或运营应用和系统中。这些数据集通常包含大量本地数据,在大多数情况下,在源处理后进行批量摄取通常是较为有效的。这些数据摄取通常在特定时间进行,例如每隔一小时在每个整点后的 30 分或每天下午 2 点进行摄取(对于复杂流程,有时用的时间会更长)。
- 来自客户关系和体验系统的客户数据在摄取过程中几乎不需要进行转换或聚合,或者您也可以完全使用更改数据捕获流程来捕获在一开始通过批量加载的数据集更改。您可以从操作系统、网络点击、社交媒体馈送和第三方客户数据馈送获取更多数据。
- 流摄取用于摄取通过物联网、机器通信等方式从分支网点的信标中读取的数据。视频成像也可以用这种方式。此外,在此示例中,我们打算通过分析社交媒体消息、对第一方帖子的响应以及热门消息来分析和快速响应消费者情绪。在摄取社交媒体(应用)消息/事件时,我们可以选择执行一些基础的转换/聚合,然后再将数据存储到云端存储或数据湖中。我们还可以使用其它流分析来识别相关的消费者事件和行为,并将识别到的模式(手动)反馈至 OCI Data Science,以检查原始数据。
数据持久性和处理建立在三个(可选四个)组件之上。
- 已摄取的原始数据存储在云端存储中。我们将使用 OCI Data Flow 对推文 (JSON)、位置数据、来自信标和应用的传感器数据、地理映射数据和产品参考数据等当前持久保存的流数据执行批处理。这些处理过的数据集被返回到云端存储,以进行后续持久化、管理和分析,并最终以优化的形式加载到服务数据存储中,或者根据架构偏好使用 Oracle Big Data Service 作为托管 Hadoop 集群来对这些数据进行批处理。
- 我们创建了一个经过处理的数据集,以经过优化的关系形式持久保存数据,从而提高服务数据存储的管理效率和查询性能。这样,我们可以识别并返回热门的产品和消费者主题标签,这些主题标签可以使用来自企业系统的位置、库存和产品数据进行扩充。
分析、学习和预测能力建立在两种技术方法之上。
- 分析和可视化服务提供描述性分析(用直方图和图表描述当前趋势)、预测性分析(预测未来事件、识别趋势以及确定不确定结果的可能性)和规范性分析(提出合适的行动,从而做出理想决策),让金融服务机构能够轻松回答以下问题:
- 我们的追加销售活动是否与活动预测一致?客户互动活动是否因此发生了变化?
- 哪些产品的客户互动最多?它们与部门中最畅销的产品和服务相比如何?
- 是否出现“渠道疲劳”?如果出现了,它是否会导致客户脱离该渠道?
- 除了使用高级分析之外,我们还开发、训练并部署了机器学习模型。这些模型可以通过 API 访问,部署在服务数据存储中,或者将其嵌入到 OCI GoldenGate 流分析管道中。
- 您可以对经过整理、测试的高质量数据和模型应用治理规则和策略,并将其作为数据网格架构中的“数据产品” (API) 公开,以便在整个金融服务组织中分发。
利用自动化智能满足客户预期
通过利用每位客户生命周期内的所有可用数据(包括结构化、半结构化和非结构化数据),并应用高级大数据分析、机器学习和人工智能来分析完整的客户历史互动记录,金融服务组织可以
- 设计并提供即时、高度相关的个性化客户体验。
- 整合第二方和第三方数据来改善客户体验,并使用分析来预测(并影响)客户行为。
- 使用 AI 提供适当的后续行动建议,提供更加一致的客户互动体验,优化客户结果。
- 利用机器人顾问提供自助服务工具并帮助员工更好地为客户提供服务,将咨询和销售活动变被动为主动。
- 了解每位客户的历史互动记录,预测客户需求,确保在客户生命周期的每个阶段为客户提供超出预期的体验。
相关资源
-
使用案例
风险计算和监管报告
通过该使用场景,了解面向金融服务行业的 Oracle Data Platform 如何帮助您降低风险,提高合规性。
-
使用案例
提高金融服务行业的运营和绩效
了解如何利用可通过机器学习提高绩效的数据平台来更高效地管理金融服务运营。
-
使用案例
预防欺诈和反洗钱
通过此用例,了解面向金融服务的 Oracle Data Platform 如何帮助您降低风险并提高欺诈检测和合规性。
开始行动
试用逾 20 个 Always Free 云技术服务,或在 30 天试用版中体验更多服务
Oracle 提供的免费套餐包含了 Autonomous AI Database、Arm Compute 和 Storage 等 20 多个服务,另外还有 300 美元的免费储值,让您可以试用更多云技术服务。立即获取详细信息并注册您的免费账户。
-
Oracle Cloud Free Tier 包含哪些内容?
- 2 个 Autonomous AI Database 实例,各 20 GB
- AMD 和 Arm Compute VM
- 总共 200 GB 块存储
- 10 GB 对象存储
- 每月 10 TB 出站数据传输
- 超过 10 个 Always Free 服务
- 价值 300 美元的免费储值,有效期 30 天
通过分步指导学习
通过教程和实操练习体验各种 OCI 服务。无论您是开发人员、管理员还是分析师,我们都可以帮助您了解 OCI 的工作原理。许多练习都运行于 Oracle Cloud Free Tier 或 Oracle 提供的免费练习环境中。
-
OCI 核心服务快速入门
本课程中的练习介绍了 Oracle Cloud Infrastructure (OCI) 核心服务,包括 Virtual Cloud Network (VCN) 以及计算和存储服务。
立即开始 OCI 核心服务练习 -
Autonomous AI Database 快速入门
在本课程中,您将了解如何开始使用 Oracle Autonomous AI Database。
立即开始 Autonomous AI Database 快速入门练习 -
基于电子表格构建应用
此练习将指导您如何将电子表格上传到 Oracle Database 表中,然后基于新表格创建应用。
立即开始练习
了解 150 多个优秀实践设计
了解我们的架构师和其他客户如何部署各种工作负载,包括从企业应用到高性能计算 (HPC),再从微服务到数据湖的工作负载。您可以观看“构建并部署”系列视频,参考来自其他客户架构师的优秀实践,使用“一键部署”功能或者通过 GitHub 库部署更多工作负载。
广受欢迎的架构
- Apache Tomcat 和 MySQL Database Service
- 在 Kubernetes 上运行 Oracle Weblogic 和 Jenkins
- 机器学习 (ML) 和人工智能 (AI) 环境
- 基于 Arm 的 Tomcat 和 Oracle Autonomous AI Database
- 使用 ELK Stack 进行日志分析
- 使用 OpenFOAM 的高性能计算
体验不同之处:
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 超低定价且无需缴付多年的承诺款
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。