Betrugsprävention und Geldwäschebekämpfung

Risiko minimieren und gleichzeitig nahtlosen Kundenservice bieten
Finanzbetrug stellt eine große Herausforderung für die Finanzdienstleistungsbranche dar. Er tritt nicht nur in vielen verschiedenen Formen auf, sondern ist aufgrund der Komplexität der Beziehungen zwischen Entitäten und verborgenen Mustern oft schwer zu erkennen. Und sobald er entdeckt wird, müssen Finanzinstitute Kunden in Echtzeit über betrügerische Aktivitäten informieren und sofort Maßnahmen ergreifen, um sie zu stoppen – zum Beispiel durch Sperren der Kreditkarte des Kunden.
Die Finanzdienstleistungsbranche ist ebenfalls reguliert und muss Aktivitäten zur Bekämpfung der Geldwäsche (Anti-Money Laundering, AML) melden und ihre Kunden mithilfe von Know-Your-Customer-(KYC-)Prozessen sorgfältig prüfen. Dies erfordert häufig die Analyse von Daten über Produkte, Märkte und Regionen hinweg, um Beziehungen und Muster für AML zu identifizieren.
Geldwäsche ist konzeptionell einfach: Schmutziges Geld wird herumgereicht, mit legitimen Geldern vermischt und dann in harte Vermögenswerte umgewandelt. In Wirklichkeit ist es weitaus komplizierter, sich auf eine lange, komplexe Reihe gültiger Überweisungen zwischen Konten zu verlassen, die mit synthetischen (oft gestohlenen) Identitäten erstellt wurden und häufig ähnliche Informationen wie E-Mail- und Straßenadressen verwenden. Kurz gesagt, handelt es sich um eine riesige Datenmenge, deshalb ist eine einheitliche Datenplattform, die fortschrittliche Analysetechniken wie Diagrammanalysen unterstützt, für AML-Programme unerlässlich.
Maschinelles Lernen für den Schutz sowohl von Kunden als auch Institutionen
Die Finanzdienstleistungsbranche wird nach wie vor stark überwacht und reguliert, und nur wenige Bereiche haben einen stärkeren Fokus auf die Regulierung erfahren als Aktivitäten zur Bekämpfung von Geldwäsche und Terrorismusfinanzierung. Finanzbetrug, der von riesigen kriminellen Netzwerken vorangetrieben wird, ist eine anspruchsvolle und wachsende Herausforderung, die Lösungen zur Bekämpfung der Geldwäsche erfordert, die unternehmensweit und auf der ganzen Welt Einblicke bieten.
Die folgende Architektur zeigt, wie Oracle Komponenten und Funktionen, einschließlich erweiterter Analysen und Machine Learning, kombiniert werden können, um eine Datenplattform zu erstellen, die den gesamten Datenanalyse-Lebenszyklus abdeckt und die Einblicke liefert, die AML-Teams benötigen, um die anomalen Verhaltensmuster zu identifizieren, die auf betrügerische Aktivitäten hinweisen können.
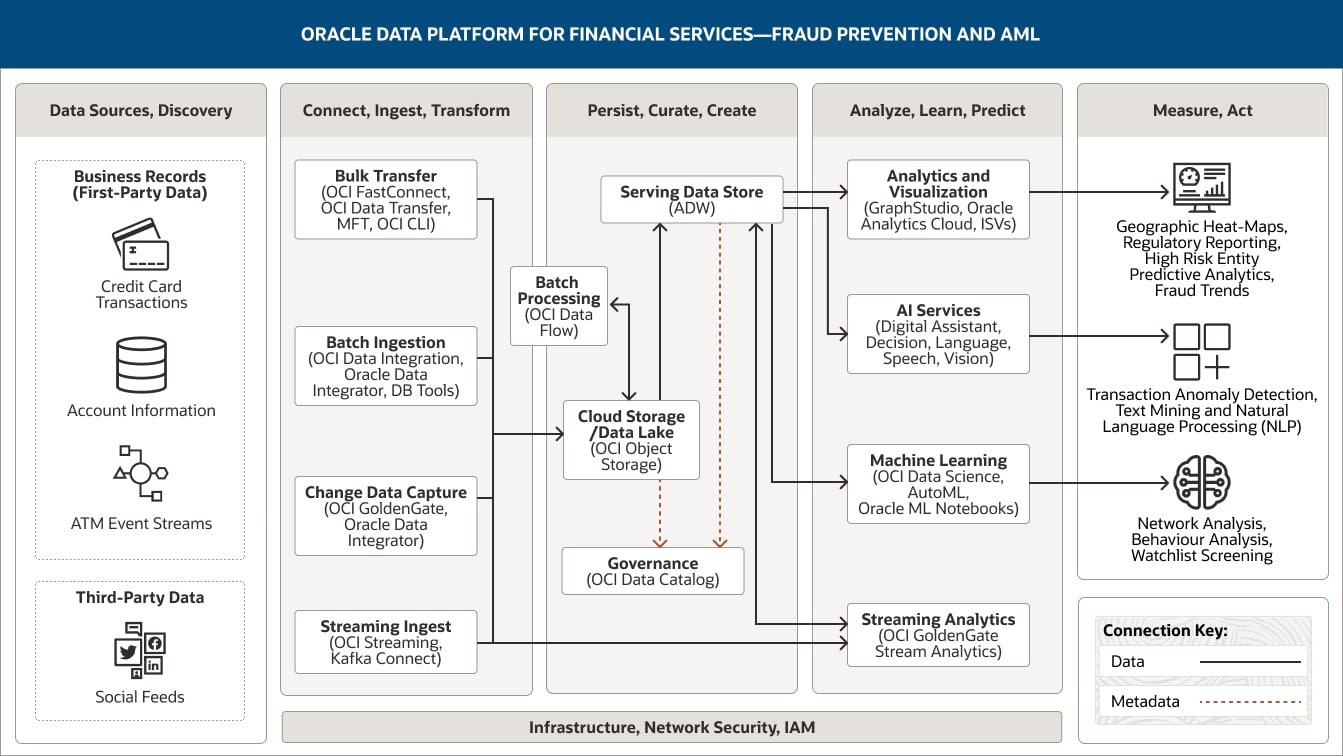
Diese Abbildung zeigt, wie Oracle Data Platform for Financial Services zur Unterstützung von Betrugsprävention und AML-Aktivitäten verwendet werden kann. Die Plattform umfasst die folgenden fünf Pillar:
- Datenquellen, Erkennung
- Verbinden, aufnehmen und transformieren
- Beibehalten, kurieren, erstellen
- Analysieren, lernen, prognostizieren
- Messen, handeln
Der Pillar „Datenquellen, Entdeckung“ umfasst zwei Datenkategorien.
Geschäftsdatensätze (First-Party-Daten) umfassen Kreditkartentransaktionen, Kontoinformationen und Geldautomaten-Ereignisstreams.
Third-Party-Daten umfassen Social Feeds.
Der Pillar „Verbinden, aufnehmen, transformieren“ umfasst vier Funktionen.
Die Massenübertragung verwendet OCI FastConnect, OCI Data Transfer, MFT und OCI CLI.
Die Batchaufnahme verwendet OCI Data Integration, Oracle Data Integrator und DB-Tools.
Die Datenänderungserfassung verwendet OCI GoldenGate und Oracle Data Integrator.
Die Streaming-Aufnahme verwendet OCI Streaming und Kafka Connect.
Alle vier Funktionen verbinden sich unidirektional mit der Cloud-Speicher-/Data Lake-Funktion innerhalb des Pillars „Beibehalten, kurieren, erstellen“.
Darüber hinaus ist die Streaming-Aufnahme mit der Stream-Verarbeitung innerhalb des Pillars „Analysieren, lernen, prognostizieren“ verbunden.
Der Pillar „Beibehalten, kurieren, erstellen“ umfasst vier Funktionen.
Der bereitstellende Datenspeicher verwendet Autonomous Data Warehouse und Exadata Cloud Service.
Der Cloud-Speicher/Data Lake verwendet OCI Object Storage.
Die Batchverarbeitung verwendet OCI Data Flow.
Governance verwendet OCI Data Catalog.
Diese Funktionen sind innerhalb des Pillars miteinander verbunden. Der Cloud-Speicher/Data Lake ist unidirektional mit dem bereitstellenden Datenspeicher und außerdem bidirektional mit der Batchverarbeitung verbunden.
Eine Funktion ist mit dem Pillar „Analysieren, lernen, prognostizieren“ verbunden: Der bereitstellende Datenspeicher ist unidirektional mit den Funktionen für Analyse und Visualisierung, KI-Services und maschinelles Lernen sowie bidirektional mit der Streaming-Analysefunktion verbunden.
Der Pillar „Analysieren, lernen, prognostizieren“ umfasst vier Funktionen.
Analysen und Visualisierungen verwenden Oracle Analytics Cloud, GraphStudio und ISVs.
KI-Services verwenden OCI Anomaly Detection, OCI Forecasting und OCI Language
Maschinelles Lernen verwendet OCI Data Science und Oracle Machine Learning Notebooks.
Streaming-Analysen verwenden OCI GoldenGate Stream Analytics.
Der Pillar „Messen, handeln“ umfasst drei Consumer: Dashboards und Berichte, Anwendungen und Machine Learning-(ML-)Modelle.
Personen und Partner umfassen geografische Heat-Maps, regulatorisches Reporting, Vorhersageanalysen für Hochrisikokörperschaften, Betrugsmuster.
Anwendungen umfassen Transaktionsanomalieerkennung, Text-Mining und Natural Language Processing (NLP).
Modelle für maschinelles Lernen umfassen Netzwerkanalyse, Verhaltensanalyse und Watchlist-Screening.
Die drei zentralen Pillar – Aufnehmen, transformieren; Ausharren, kuratieren, schaffen; und Analysieren, lernen, prognostizieren – werden durch Infrastruktur, Netzwerk, Sicherheit und IAM unterstützt.
Es gibt drei Möglichkeiten, Daten in eine Architektur einzuspeisen, damit Finanzdienstleistungsunternehmen potenziell betrügerische Aktivitäten erkennen können.
- Zunächst benötigen wir Daten aus Transaktionssystemen und Core-Banking-Anwendungen. Diese Daten können mit Kundendaten aus Third-Party-Quellen angereichert werden, was beispielsweise unstrukturierte Daten aus Social Media beinhalten könnte. Häufige Echtzeit- oder nahezu Echtzeit-Extracts, die eine Datenänderungserfassung erfordern, sind üblich, und Daten werden regelmäßig von Transaktions-, Risiko- und Kundenmanagementsystemen mit Oracle Cloud Infrastructure (OCI) GoldenGate aufgenommen. OCI GoldenGate ist auch eine entscheidende Komponente sich entwickelnder Data-Mesh-Architekturen, bei denen „Datenprodukte“ über Unternehmensdaten-Ledger und mehrsprachige Datenströme verwaltet werden, die kontinuierliche Transformations- und Ladeprozesse ausführen (anstelle der in monolithischen Architekturen verwendeten Batch-Aufnahme- und ETL-Prozesse).
- Wir können jetzt die Streaming-Aufnahme verwenden, um Daten von IoT-Sensoren, Web-Pipelines, Protokolldateien, Point-of-Sale-Geräten, Geldautomaten, Social Media und anderen Datenquellen in Echtzeit über OCI Streaming/Kafka einzuspeisen. Diese gestreamten Daten (Ereignisse) werden aufgenommen und einige grundlegende Transformationen/Aggregationen werden durchgeführt, bevor die Daten im Cloud-Speicher gespeichert werden. Parallel zur Aufnahme können wir mithilfe von Streaminganalysen große Datenmengen aus mehreren Quellen in Echtzeit filtern, aggregieren, korrelieren und analysieren. Dadurch können Finanzinstitute nicht nur geschäftliche Bedrohungen und Risiken erkennen, beispielsweise verdächtige Transaktionen von einem Geldautomaten, wie z. B. mehrfache wiederholte Transaktionen, sondern auch Einblicke in die Effizienz ihrer gesamten Betrugsprävention erhalten. Korrelierende Ereignisse und identifizierte Muster können (manuell) für eine datenwissenschaftliche Untersuchung der Rohdaten rückgekoppelt werden. Darüber hinaus können Ereignisse generiert werden, um Aktionen auszulösen, z. B. die Benachrichtigung von Kunden über potenziellen Betrug per E-Mail oder SMS oder die Sperrung kompromittierter Debitkarten. Oracle GoldenGate Stream Analytics ist eine In-Memory-Technologie, die Analyseberechnungen in Echtzeit für Streaming-Daten durchführt.
- Während sich die Echtzeitanforderungen weiterentwickeln, ist der häufigste Extrakt aus Core-Banking-, Kunden- und Finanzsystemen eine Stapelaufnahme mit einem Extraktions-, Transformations- und Ladeprozess (ETL). Die Batchaufnahme wird verwendet, um Daten aus Systemen zu importieren, die keine Streaming-Aufnahme unterstützen (z. B. ältere Mainframe-Systeme). Für die Prozesse zur Geldwäschebekämpfung und Know-Your-Customer werden Daten aus verschiedenen Betriebssystemen bezogen, z. B. Transaktionsverarbeitungssystemen für Giro- und Kreditkonten sowie Datenfeeds von Drittanbietern, die Kundeninformationen liefern. Die Daten stammen aus verschiedenen Produkten und Regionen. Batchaufnahmen können häufig sein, so oft wie alle 10 oder 15 Minuten. Sie sind jedoch immer noch in Batch-Form, da Transaktionsgruppen extrahiert und verarbeitet werden und nicht einzelne Transaktionen. OCI bietet verschiedene Services für die Batch-Ingestion, wie z. B. den nativen OCI Data Integration-Service und Oracle Data Integrator, die auf einer OCI Compute-Instanz ausgeführt werden. Je nach Volumes und Datentypen können Daten in den Objektspeicher oder direkt in eine strukturierte relationale Datenbank zur dauerhaften Speicherung geladen werden.
Die Datenpersistenz und -verarbeitung basieren auf drei (optional vier) Komponenten.
- Aufgenommene Rohdaten werden für algorithmische Zwecke im Cloud-Speicher gespeichert. Hierbei wird OCI Object Storage als primäre Datenpersistenzebene verwendet. Spark in OCI Data Flow ist die primäre Batchverarbeitungs-Engine für Daten wie Transaktions-, Standort-, Anwendungs- und Geomappingdaten. Die Batchverarbeitung umfasst mehrere Aktivitäten, einschließlich der grundlegenden Behandlung hinsichtlich der Qualität, der Verwaltung fehlender Daten und der Filterung basierend auf definierten ausgehenden Datasets. Die Ergebnisse werden basierend auf der erforderlichen Verarbeitung und den verwendeten Datentypen in verschiedene Ebenen des Objektspeichers oder in ein persistentes relationales Repository zurückgeschrieben.
- Diese verarbeiteten Datasets werden zur weiteren Persistenz, Pflege und Analyse an den Cloud-Speicher zurückgegeben und schließlich in optimierter Form in den bereitstellenden Datenspeicher geladen, der hier von Oracle Autonomous Database bereitgestellt wird. Daten werden jetzt in optimierter relationaler Form für Kuration und Abfrageleistung gespeichert. Alternativ kann dies je nach architektonischer Präferenz mit Oracle Big Data Service als verwalteter Hadoop-Cluster erreicht werden. In diesem Anwendungsfall wird im Objektspeicher auf alle Daten zugegriffen, die zum Trainieren der ML-Modelle erforderlich sind. Zum Trainieren der Modelle werden historische Muster mit Datensätzen auf Transaktionsebene kombiniert, um potenzielle Risiken zu identifizieren und zu kennzeichnen. Durch die Kombination dieser Datasets mit anderen, wie z. B. Gerätedaten und Geodaten, können wir Data-Science-Techniken anwenden, um bestehende Modelle zu verfeinern und neue zu entwickeln, um potenzielle Betrugsfälle besser vorhersagen zu können. Diese Art der Persistenz kann auch zum Speichern von Daten für Schemas verwendet werden, die Teil der Datenspeicher sind, auf die über externe Tabellen und Hybridpartitionen zugegriffen wird.
Die Fähigkeit zu analysieren, zu prognostizieren und zu handeln basiert auf drei Technologieansätzen.
- Analyse- und Visualisierungsservices wie Oracle Analytics Cloud liefern Analysen basierend auf den kuratierten Daten aus dem Datenspeicher der Bereitstellung. Dazu gehören beschreibende Analysen (beschreibt aktuelle Trends zur Betrugserkennung und gekennzeichnete Aktivitäten mit Histogrammen und Diagrammen), prädiktive Analysen, wie z. B. Zeitreihenanalysen (sagt zukünftige Muster voraus, identifiziert Trends und bestimmt die Wahrscheinlichkeit ungewisser Ergebnisse) und präskriptive Analysen (schlägt geeignete Maßnahmen vor, die zu einer optimalen Entscheidungsfindung führen). Diese Analysen können verwendet werden, um Fragen zu beantworten wie z. B.: Wie verhält sich der tatsächlich gemeldete Betrug in diesem Zeitraum im Vergleich zu früheren Zeiträumen?
- Neben der erweiterten Analyse werden Machine Learning-(ML-)Modelle entwickelt, trainiert und eingesetzt. Diese trainierten Modelle können sowohl auf aktuellen als auch auf historischen Transaktionsdaten ausgeführt werden, um Geldwäsche durch den Abgleich von Transaktions- und Verhaltensmustern zu erkennen. Die Ergebnisse können an die bereitstellende Schicht zurückgesendet und mit Analysetools wie Oracle Analytics Cloud gemeldet werden. Um das Modelltraining zu optimieren, können das Modell und die Daten auch in Machine Learning-Systeme wie OCI Data Science eingespeist werden, sodass die Modelle für eine effektivere Erkennung von Geldwäschebekämpfungsmustern weiter trainiert werden können, bevor sie beworben werden. Auf diese Modelle kann über APIs zugegriffen werden, die im bereitstellenden Datenspeicher bereitgestellt oder als Teil der Streaming-Analysepipeline von OCI GoldenGate eingebettet werden.
- Darüber hinaus können wir die erweiterten Funktionen von Cloud-nativen KI-Services nutzen.
- OCI Anomaly Detection ist ein KI-Service, mit dem Sie ganz einfach geschäftsspezifische Anomalieerkennungsmodelle erstellen können, die kritische Vorfälle kennzeichnen und die Erkennung und Lösung beschleunigen. In diesem Anwendungsfall würden wir diese Modelle einsetzen, um Betrug während des Lebenszyklus einer Transaktion zu erkennen, während Audits, in bestimmten Kontexten, zum Beispiel basierend auf dem Verkäufer, Händler oder der Art der Transaktion sowie in vielen anderen Szenarien. OCI Anomaly Detection kann all diese Arten von Betrug identifizieren, indem es historische Daten verwendet und ein geeignetes Anomalieerkennungsmodell erstellt. Wenn das Dataset beispielsweise die Art der Transaktion mit Betrag, Standort (Längen- und Breitengrad), Anbietername und andere Details enthält, kann OCI Anomaly Detection feststellen, ob der Betrug mit dem Transaktionsbetrag, dem Transaktionskonto oder dem Standort zusammenhängt wo die Transaktion stattgefunden hat, oder sich auf den Anbieter bezieht, der die Transaktion eingereicht hat.
- OCI Forecasting kann verwendet werden, um Transaktionsmetriken wie die Anzahl der Transaktionen, Transaktionsbeträge usw. für den nächsten Tag, die nächste Woche oder die nächsten Monate als Funktion der aktuellen Metriken und der Einflussnahme auf die Marktbedingungen zu prognostizieren. Diese Prognosen können wiederum zur Planung und zur Festlegung einer Grunderwartung zum Schutz vor Geldwäsche und anderem Betrug verwendet werden.
- OCI Language und OCI Vision können Dokumente und Text aufnehmen, die dazu beitragen können, die Daten für die Betrugserkennung und AML-Aktivitäten anzureichern.
- Data Governance ist eine weitere wichtige Komponente. Dies wird von OCI Data Catalog bereitgestellt, einem kostenlosen Service, der Data Governance und Metadatenverwaltung (sowohl für technische als auch für geschäftliche Metadaten) für alle Datenquellen im Data Lakehouse-Ökosystem bereitstellt. OCI Data Catalog ist ebenso eine wichtige Komponente für Abfragen von Oracle Autonomous Data Warehouse an OCI Object Storage, da damit Daten unabhängig von der Speichermethode schnell lokalisiert werden können. Dadurch können Endbenutzer, Entwickler und Data Scientists eine gemeinsame Zugriffssprache (SQL) für alle persistenten Datenspeicher in der Architektur verwenden.
- Letztendlich können unsere jetzt kuratierten, getesteten, hochwertigen und geregelten Daten und Modelle als Datenprodukt (API) innerhalb einer Datennetzarchitektur zur Verteilung über die Finanzdienstleistungsorganisation bereitgestellt werden.
Bessere Betrugsprävention und AML-Aktivitäten mit der richtigen Datenplattform
Mit Oracle Data Platform kann Ihr Unternehmen Geldwäsche effektiver aufdecken, die Genauigkeit und Effizienz von Ermittlungen bei Finanzkriminalität steigern und Reportingprozesse optimieren, um die Compliance-Kosten gering zu halten.
Verwandte Ressourcen
-
Anwendungsfall
Betrugsprävention und Geldwäschebekämpfung
Erfahren Sie, wie Oracle Data Platform for Financial Services Ihnen helfen kann, Risiken zu mindern sowie die Betrugserkennung und Compliance in diesem Anwendungsfall zu verbessern.
-
Anwendungsfall
Risikoberechnungen und regulatorisches Reporting
Erfahren Sie in diesem Anwendungsfall, wie Sie mit Oracle Data Platform für Finanzdienstleistungen Risiken mindern und die Einhaltung gesetzlicher Vorschriften verbessern können.
-
Anwendungsfall
Verbesserung der Abläufe und der Leistung von Finanzdienstleistungen
Erfahren Sie, wie Sie den Finanzdienstleistungsbetrieb mit einer Datenplattform, die mit maschinellem Lernen zur Leistungssteigerung beiträgt, effizienter verwalten können.
Erste Schritte
Mehr als 20 kostenlose Cloud-Services mit einer 30-tägigen Testversion für noch mehr
Oracle bietet ein Free Tier ohne zeitliche Begrenzung für eine Auswahl von mehr als 20 Services wie Autonomous AI Database , Arm Compute und Storage an. Darüber hinaus erhalten Sie 300 US-Dollar an kostenlosen Credits, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- AMD und Arm Compute-VMs
- Insgesamt 200 GB Blockspeicher
- 10 GB Objektspeicher
- 10 TB ausgehende Datenübertragung pro Monat
- Mehr als 10 permanent kostenlose Services
- Kostenlose Credits im Wert von 300 US-Dollar, 30 Tage lang noch mehr
Mit schrittweiser Anleitung lernen
Erleben Sie eine breite Palette von OCI-Services in Tutorials und praktischen Übungen. Unabhängig davon, ob Sie ein Entwickler, Administrator oder Analyst sind, können wir Ihnen zeigen, wie OCI funktioniert. Viele Übungen werden auf dem Free Tier von Oracle Cloud oder einer von Oracle bereitgestellten freien Laborumgebung ausgeführt.
-
Erste Schritte mit zentralen OCI-Services
Die Übungen in diesem Workshop umfassen eine Einführung in zentrale Oracle Cloud Infrastructure-(OCI-)Services wie virtuelle Cloud-Netzwerke (VCN) sowie Compute- und Speicherservices.
Übungen zu den zentralen OCI-Services jetzt starten -
Autonomous AI Database – Schnellstart
In diesem Workshop vermitteln wir Ihnen die ersten Schritte, um Oracle Autonomous AI Database zu nutzen.
Jetzt mit der Übung für den Schnelleinstieg in Autonomous AI Database beginnen -
App aus einer Kalkulationstabelle erstellen
In dieser Übung laden Sie eine Tabelle in eine Oracle Database-Tabelle hoch und erstellen anschließend eine Anwendung auf Basis dieser neuen Tabelle.
Diese Übung jetzt starten
Entdecken Sie mehr als 150 Best Practice-Designs
Erfahren Sie, wie unsere Architekten und anderen Kunden eine Vielzahl von Workloads bereitstellen, von Unternehmensanwendungen bis hin zu HPC, von Microservices bis hin zu Data Lakes. Informieren Sie sich über Best Practice, hören Sie von anderen Kundenarchitekten in unserer Reihe „Built & Deploy“, und stellen Sie außerdem viele Workloads mit unserer Funktion „Click-to-Deployment“ oder selbst aus unserem GitHub-Repository bereit.
Beliebte Architekturen
- Apache Tomcat mit MySQL Database Service
- Oracle Weblogic auf Kubernetes mit Jenkins
- ML- und KI-Umgebungen
- Tomcat on Arm mit Oracle Autonomous AI Database
- Loganalyse mit ELK-Stack
- HPC mit OpenFOAM
Erfahren Sie, wie viel Sie bei OCI sparen können
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Den Unterschied entdecken:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen
Vertrieb kontaktieren
Möchten Sie mehr über die Oracle Cloud Infrastructure erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten wie:
- Welche Workloads werden am besten auf OCI ausgeführt?
- Wie kann ich meine gesamten Oracle Investitionen optimal nutzen?
- Wie schlägt sich OCI verglichen mit anderen Cloud-Computing-Anbietern?
- Wie kann OCI Ihre IaaS- und PaaS-Ziele unterstützen?