
Best Practices anwenden, um die Analyse Ihrer kritischen Einzelhandelsdaten zu verbessern
Die Möglichkeit, Live-Datenanalysen mit hochwertigen Daten durchzuführen, ist für Unternehmen in vielen Branchen von entscheidender Bedeutung, besonders aber für Einzelhändler. Zeitnahe Erkenntnisse aus präzisen Daten können dazu beitragen, die Kundenzufriedenheit zu verbessern, indem sie sofortige Produktempfehlungen bieten und sicherstellen, dass der Bestand zur richtigen Zeit am richtigen Ort ist, Merchandising-, Marketing- und Verkaufsanstrengungen mit Echtzeitbewertungen der Performance von Werbeaktionen optimieren, Kosten und Risiken durch präzisere Bestandsprognosen senken und vieles mehr. Kurz gesagt, eine effektive Live-Datenanalyse hat das Potenzial, sich positiv auf die Einzelhandelsabläufe in Ihrem Unternehmen auszuwirken.
Um den größten Nutzen aus der Live-Datenanalyse zu ziehen, müssen Sie einen einzigen optimierten Ansatz für das Datenlebenszyklusmanagement Ihrer wichtigsten Datensätze implementieren. Der folgende Ansatz hilft Ihnen
- Reduzieren Sie die Komplexität und Duplizierung von Daten.
- Minimieren Sie die Risiken und Kosten im Zusammenhang mit minderwertigen Daten.
- Erstellen Sie eine einheitliche Ansicht Ihrer Daten.
- Stellen Sie Daten unternehmensweit in einheitlich bereit.
- Stellen Sie Selfservice-Business Intelligence (BI) für das Reporting und erweiterte Datenanalyse zur Verfügung, unabhängig von den Tools, die von den Domänenteams verwendet werden.
- Sorgen Sie für Flexibilität in Ihrer Datenlandschaft und halten Sie die Kosten für künftige Änderungen so gering wie möglich.
Modernisierung Ihrer Analysen mit einer optimierten Analyselösung
Die folgende Architektur demonstriert, wie Oracle Data Platform so entwickelt wurde, dass Einzelhändler ein einheitliches, umfassendes Framework für die Verwaltung des gesamten Datenanalyselebenszyklus erhalten. Im Mittelpunkt stehen zwei entscheidende Komponenten: der operative Datenspeicher (ODS), der zur Speicherung von Betriebsdaten verwendet wird, die in Rohform ohne Transformation aufgenommen und gespeichert werden, und ein Data Warehouse, in dem die Daten in optimierter Form für Abfrageleistung und erweiterte Analysen gespeichert werden.
Zusammen bilden ODS und Data Warehouse eine Datenplattform, die effizientere und erweiterte Analysen ermöglicht. Diese Kombination ermöglicht den effektiven Einsatz fortschrittlicher Analyse- und Visualisierungstools, wobei die Möglichkeit erhalten bleibt, die Daten in ihrer Rohform zu untersuchen, um Anomalien oder Erkenntnisse zu ermitteln, ohne die Leistung der zugrunde liegenden Transaktionsanwendung zu beeinträchtigen. Dieser Ansatz ist für Einzelhändler von Vorteil, da er eine widersprüchliche und ungenaue Duplizierung derselben Quelldaten verhindert, die, wenn sie als Entscheidungsgrundlage verwendet werden, zu Verzögerungen, Fehlern und letztlich zu Umsatzeinbußen führen können.
Sehen wir uns nun genauer an, wie Oracle Data Platform ein ODS, ein Data Warehouse und andere wichtige Komponenten integriert, um Einzelhändlern bei der effektiven Nutzung von Live-Datenanalysen zu helfen.
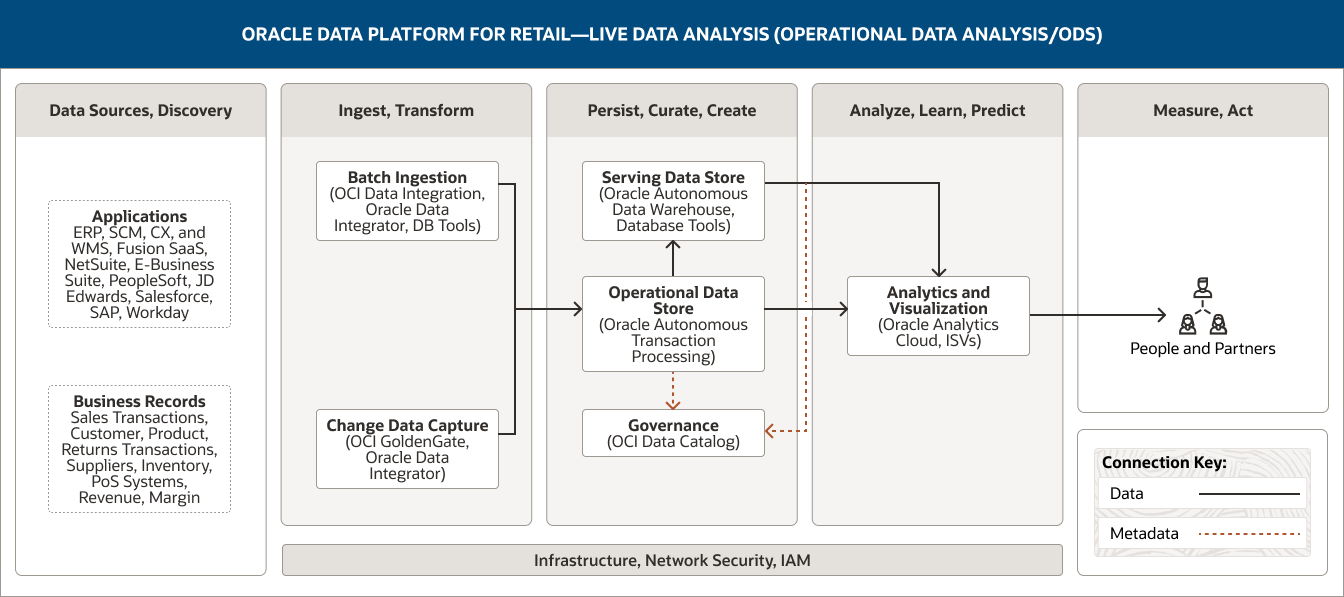
Diese Abbildung zeigt, wie Oracle Data Platform für den Einzelhandel zur Unterstützung der Analyse von Live- und historischen Daten in optimierter Form verwendet werden kann. Die Plattform umfasst die folgenden fünf Pillar:
- 1. Datenquellen, erkennen
- 2. Verbinden, aufnehmen und transformieren
- 3. Ausharren, kuratieren, schaffen
- 4. Analysieren, lernen, prognostizieren
- 5. Messen, handeln
Der Pillar „Datenquellen, Entdeckung“ umfasst zwei Datenkategorien.
- 1. Anwendungen umfassen Daten aus ERP, SCM, CX und WMS, Fusion SaaS, NetSuite, E-Business Suite, PeopleSoft, JD Edwards, SAP, Salesforce und Workday.
- 2. Geschäftsunterlagen umfassen Verkaufstransaktionen, Kundendaten, Produktdaten, Retourentransaktionen, Lieferantendaten, Bestandsdaten, Daten aus Kassensystemen sowie Umsatz- und Margendaten.
Die Säule „Verbinden, aufnehmen, transformieren“ umfasst zwei Funktionen.
- 1. Die Batch-Ingestion verwendet OCI Data Integration, Oracle Data Integrator und DB-Tools. Die Datenänderungserfassung verwendet OCI GoldenGate und Oracle Data Integrator.
- 2. Beide Funktionen verbinden sich unidirektional mit der Funktion „Operational Data Store“ in der Säule „Ausharren, kuratieren und schaffen“.
Die Säule „Ausharren, kuratieren und schaffen“ umfasst drei Funktionen.
- 1. Der Operational Data Store verwendet Oracle Autonomous Transaction Processing.
- 2. Der Serving Data Store verwendet Oracle Autonomous Data Warehouse und Datenbanktools.
- 3. Governance verwendet OCI Data Catalog.
Diese Funktionen sind innerhalb des Pillars miteinander verbunden. Der Operational Data Store ist unidirektional mit dem Serving Data Store verbunden.
Eine Fähigkeit ist mit der Säule „Analysieren, lernen, prognostizieren“ verbunden: Der Serving Data Store ist unidirektional mit der Analyse- und Visualisierungsfunktion verbunden.
Die Säule „Analysieren, lernen, prognostizieren“ umfasst eine Funktion.
- 1. Analysen und Visualisierungen verwenden Oracle Analytics Cloud, GraphStudio und ISVs.
Die Säule „Messen, handeln“ umfasst eine einzige Verbraucherkategorie: Dashboards und Berichte.
Die drei zentralen Pillar – Aufnehmen, transformieren; Ausharren, kuratieren, schaffen; und Analysieren, lernen, prognostizieren – werden durch Infrastruktur, Netzwerk, Sicherheit und IAM unterstützt.
Es gibt zwei (oder wahlweise drei) Hauptmethoden, um Daten in eine Architektur einzubringen, damit Einzelhändler ihre Daten besser analysieren können.
- Zu Beginn unseres Prozesses müssen wir Einblick in aktuelle Daten aus unseren Geschäftsunterlagen und Anwendungen erhalten (z. B. Lagerbestände an verschiedenen Einzelhandelsstandorten). Dazu verwenden wir OCI GoldenGate, um die Change Data Capture-Aufnahme (CDC) von nahezu Echtzeitdaten aus Betriebsdatenbanken zu aktivieren (Transaktionsverarbeitung). Dazu gehören alle Datensätze oder diskrete Datensätze im Zusammenhang mit Einzelhandelstransaktionen, einschließlich Point-of-Sale- und Web-Transaktionen (sowohl Verkäufe als auch Retouren), sowie Bestands-, Logistik- und Lieferkettendaten. Zusätzlich zum Auslösen der Datenaufnahme mit Hilfe von Zeitstempeln oder Flag-Filtern können die Daten auch über einen CDC-Mechanismus aufgenommen werden, der Änderungen sofort erkennt. OCI GoldenGate bietet einen CDC-Mechanismus, der Quelländerungen nichtinvasiv verarbeiten kann, indem er Protokolldateien abgeschlossener Transaktionen verarbeitet und diese erfassten Änderungen in externen, von der Datenbank unabhängigen Trail-Dateien speichert. Änderungen werden dann zuverlässig in eine Staging-Datenbank oder einen Operational Data Store übertragen.
- Wir können jetzt Datensätze hinzufügen, die für die wichtigsten Einzelhandelstransaktionen relevant sind, einschließlich Bestands- und Produktdaten, Kundendatensätze sowie Angebote und Preise. Solche Datensätze umfassen oft große Mengen von Daten, die oft On-Premises gespeichert werden, und in den meisten Fällen ist die Batchaufnahme am effizientesten.
Dennoch gibt es bei der Überlegung, wie Sie Transaktionsdaten aus betrieblichen Quellen sammeln, um Operational Data Stores zu füllen, einige Dinge zu beachten. Die verfügbaren Techniken unterscheiden sich vor allem in Bezug auf die Latenzzeit der Datenintegration und reichen von geplanten täglichen Batches bis zur kontinuierlichen Echtzeitintegration. Daten werden über inkrementelle Abfragen erfasst, die entweder auf der Grundlage eines Zeitstempels oder einer Kennzeichnung filtern. Die Techniken unterscheiden sich auch darin, ob sie eine Pull- oder Push-Operation verwenden; eine Pull-Operation zieht neue Daten in festen Intervallen ein, während eine Push-Operation Daten in das Ziel lädt, sobald eine Änderung auftritt. Eine tägliche Batchaufnahme ist am besten geeignet, wenn die Daten nicht tagesaktuell sein müssen, z. B. bei längerfristigen Trends oder bei Daten, die nur einmal täglich berechnet werden, wie z. B. Finanzabschlussdaten. Batchladevorgänge können in einem Ausfallzeitfenster ausgeführt werden, wenn das Geschäftsmodell keine 24-Stunden-Data-Warehouse-Verfügbarkeit erfordert. Es gibt verschiedene Techniken wie Echtzeit-Partitionierung oder Trickle and Flip, um die Auswirkungen einer Last auf ein Live-Data-Warehouse zu minimieren, wenn kein Ausfallzeitfenster verfügbar ist. - Optional können wir auch die Streamingaufnahme verwenden, um Daten aufzunehmen, die über IoT, Maschine-zu-Maschine-Kommunikation und andere Mittel von Beacons an Ladenstandorten gelesen werden. Auch Videobilder können auf diese Weise konsumiert werden. Darüber hinaus beabsichtigen wir in diesem Anwendungsfall, die Stimmung der Verbraucher zu analysieren und schnell darauf zu reagieren, indem wir Nachrichten in sozialen Medien, Antworten auf Beiträge von Erstanbietern und Trendmeldungen analysieren. Nachrichten/Ereignisse aus sozialen Medien (Anwendungen) werden mit der Option aufgenommen, einige grundlegende Umwandlungen/Aggregationen vorzunehmen, bevor die Daten im Cloud-Speicher abgelegt werden. Mit zusätzlichen Streamanalysen können korrelierende Verbraucherereignisse und -verhaltensweisen identifiziert werden, und die identifizierten Muster können (manuell) für OCI Data Science eingespeist werden, um die Rohdaten zu untersuchen.
Die Datenpersistenz und -verarbeitung basiert auf zwei Komponenten.
- Der Operational Data Store wird für das operative Reporting von Rohdaten und als Datenquelle für einen Service Data Store oder Enterprise Data Warehouse (EDW) auf Unternehmens- oder Domainebene oder verwendet. Es ist ein ergänzendes Element zu einem EDW in einer Entscheidungshilfeumgebung. Bei einem ODS handelt es sich in der Regel um eine relationale Datenbank zur Integration und Speicherung von Daten aus verschiedenen Quellen, die für zusätzliche Vorgänge, Berichte, Kontrollen und die Unterstützung operativer Entscheidungen verwendet werden, während die EDW für die taktische und strategische Entscheidungsunterstützung eingesetzt wird. In der Regel ist das Datenmodell des ODS dem Datenmodell der OLTP-Quellanwendung sehr ähnlich. Alle Quelldaten sollten vom ODS akzeptiert werden, und es sollten so gut wie keine Datenqualitätsregeln implementiert werden, um sicherzustellen, dass Sie einen Speicher haben, der alle Daten des Tages aus den operativen Systemen enthält. Im Gegensatz zu einer Produktionsstammdatenablage werden die Daten nicht an das operative System zurückgegeben. Data Warehouses sind in der Regel schreibgeschützt und werden nach einem bestimmten Zeitplan per Batch aktualisiert, während operative Datenspeicher nahezu in Echtzeit gepflegt werden und ständig mit Daten versorgt werden.
- Wir haben nun verarbeitete Datensätze erstellt, die in optimierter relationaler Form für die Kuration und Abfrageleistung im Serving Data Store aufbewahrt werden können. In diesem Anwendungsfall ist der Serving Data Store ein Data Warehouse, eine Art Aufbewahrungsplattform, die zur Unterstützung von Business Intelligence-Aktivitäten und zunehmend erweiterten Analysen konzipiert ist. Das Hauptziel eines Data Warehouse besteht darin, genaue Indikatoren zu konsolidieren und den Geschäftsanwendern zur Verfügung zu stellen, damit diese bei ihrer täglichen Arbeit und bei größeren strategischen Geschäftsentscheidungen fundierte Entscheidungen treffen können. Zu diesem Zweck sind Data Warehouses hochspezialisiert, enthalten oft große Mengen historischer Daten und sind ausschließlich für Abfragen und Analysen vorgesehen. Ein Data Warehouse zentralisiert und konsolidiert große Datenmengen aus verschiedenen Quellen, z. B. aus Anwendungsprotokolldateien und Transaktionsanwendungen, und stellt sie dann in optimaler Form für die Analyse bereit. Die Analysefunktionen ermöglichen es Unternehmen, wertvolle Geschäftsinformationen aus ihren Daten abzuleiten, um die Entscheidungsfindung zu verbessern. Im Laufe der Zeit wird ein Verlaufsdatensatz erstellt, der für Daten- und Geschäftsanalysten von unschätzbarem Wert sein kann. Aufgrund dieser Funktionen kann ein Data Warehouse als Source of Truth einer Organisation betrachtet werden. Es besteht die Tendenz, Data Warehouses als reine Technologie-Assets zu betrachten, aber sie bieten tatsächlich eine einzigartige Umgebung, um Geschäftsanwender und IT zusammenzubringen, um ein gemeinsames Verständnis der Betriebsumgebung eines Einzelhändlers zu entwickeln und zu liefern und um folgende Aufgaben zu erfüllen:
- Definieren von Geschäftsanforderungen (Schlüsselindikatoren); Identifizieren von Quelldaten, die Schlüsselindikatoren betreffen; und Festlegen von Geschäftsregeln zur Umwandlung von Quelldaten in Schlüsselindikatoren
- Modellieren der Datenstruktur des Ziellagers zur Speicherung der Schlüsselindikatoren
- Auffüllen der Indikatoren durch Implementierung von Geschäftsregeln
- Messen der Gesamtgenauigkeit der Daten durch Aufstellung von Datenqualitätsregeln
- Erstellen von Berichten über Schlüsselindikatoren
- Bereitstellen von Schlüsselindikatoren und Metadaten für Geschäftsanwender durch Ad-hoc-Abfragetools oder vordefinierte Berichte
- Messen der Zufriedenheit der Geschäftsanwender und Hinzufügen oder Ändern von Schlüsselindikatoren
Die Fähigkeit, zu analysieren, zu lernen und Vorhersagen zu treffen, beruht auf zwei Technologien.
- Analyse- und Visualisierungsservices liefern beschreibende Analysen (beschreibt aktuelle Trends mit Histogrammen und Diagrammen), prädiktive Analysen (sagt zukünftige Ereignisse voraus, identifiziert Trends und bestimmt die Wahrscheinlichkeit ungewisser Ergebnisse) und präskriptive Analysen (schlägt geeignete Maßnahmen vor, was zu einer optimalen Entscheidungsfindung führt), um Einzelhändlern zu helfen, beispielsweise folgende Fragen zu beantworten:
- Wie ist der tatsächliche Umsatz in dieser Periode im Vergleich zum aktuellen Plan?
- Wie hoch ist der Einzelhandelswert des Lagerbestands und wie ist er im Vergleich zum Vorjahreszeitraum?
- Was sind die meistverkauften Artikel in einem Geschäftsbereich bzw. einer Abteilung?
- Wie effektiv war die letzte Promotion?
Neben dem Einsatz von erweiterten Analysen und Visualisierungen können auch Modelle für maschinelles Lernen entwickelt, trainiert und bereitgestellt werden.
Governance ist ein wichtiger Faktor, der bei der Entwicklung einer solchen Lösung berücksichtigt werden muss. Geschäftsanwender vertrauen auf die Genauigkeit von Schlüsselindikatoren aus dem Data Warehouse, um Entscheidungen zu treffen. Wenn diese Indikatoren falsch sind, sind die Entscheidungen wahrscheinlich auch falsch. Abhängig von der von Ihnen definierten Datenqualitätsstrategie müssen Geschäftsanwender wahrscheinlich aktiv an der Überwachung von Datenabweichungen teilnehmen. Sie müssen dem IT-Team helfen, die Berechnung der Indikatoren zu verfeinern und bei der Qualifizierung und Identifizierung fehlerhafter Daten zu helfen. Dies führt in der Regel zur Änderung und der nachweisbaren Verbesserung der Geschäftsregeln.
- Unsere kuratierten, getesteten und qualitativ hochwertigen Daten und Modelle können Ihre Governance-Regeln und -Richtlinien anwenden und als „Datenprodukt“ (API) innerhalb einer Data-Mesh-Architektur für die Verteilung im Einzelhandel verfügbar gemacht werden. Dies kann für die Behebung von Datenqualitätsproblemen von entscheidender Bedeutung sein. Eine schlechte Datenqualität beeinflusst so gut wie jedes Einzelhandelsunternehmen. Uneinheitliche, ungenaue, unvollständige und veraltete Daten sind häufig die Ursache für teure Geschäftsprobleme wie betriebliche Ineffizienz, fehlerhafte Analysen, nicht realisierte Skaleneffekte und unzufriedene Kunden. Diese Datenqualitätsprobleme und die damit verbundenen Geschäftsprobleme können gelöst werden, indem ein umfassender Datenqualitätsaufwand im gesamten Unternehmen durch Nutzung der oben beschriebenen Funktionen der Architektur erreicht wird.
Bessere Entscheidungen mit besseren Daten treffen
Die Oracle Data Platform wurde entwickelt, um sicherzustellen, dass Sie unternehmensweit Zugriff auf einheitliche, qualitativ hochwertige Daten haben, wann und wo immer Sie sie benötigen, damit Sie Folgendes tun können:
- Fundiertere Entscheidungen treffen.
- Die Kosten zukünftiger Änderungen mit einer einheitlichen, aber flexiblen Datenlandschaft minimieren.
- Prozess- und Datenänderungen mit weniger Silos und ohne Auswirkungen auf die Datenverfügbarkeit und -qualität widerspiegeln.
- Das Risiko von Fehlern in kritischen Finanz- und Aufsichtsberichten durch die Beseitigung von Silokopien derselben Daten mit unterschiedlicher Transformationslogik in der gesamten Unternehmensdatenlandschaft mindern.
- Erweiterte Analysen und Datenermittlung für das Berichtswesen auf eigene Faust mit weitaus besserer Datenverfügbarkeit anbieten – der Zugriff auf Daten ist nicht mehr an die spezifischen Tools gebunden, die von den Domänenteams verwendet werden.
- Speicherkosten für das Wachstum von ODS und anderen Datenspeichern senken.
- Mehr Zeit in den Einblick in die Daten investieren und weniger Zeit in die Identifizierung von Diskrepanzen, die durch mehrere Kopien von Daten in unzusammenhängenden Silos entstehen.
- Das Risiko mindern, indem keine Mehrfachkopien von Daten mehr existieren, die die Angriffsfläche vergrößern.
Verwandte Ressourcen
-
Anwendungsfall
Einblicke zur Optimierung Ihrer Preisgestaltung im Einzelhandel
Erfahren Sie in diesem Anwendungsfall, wie Sie Ihren Bestand und Ihre Werbeaktionen mit Oracle Data Platform für den Einzelhandel optimieren können.
-
Anwendungsfall
Einblicke zur Optimierung Ihres Einzelhandelsbestands im Einzelhandel
Erfahren Sie, wie Sie Ihren Bestand und Ihre Werbeaktionen mit Oracle Data Platform für den Einzelhandel optimieren. Dieser Anwendungsfall zeigt Ihnen, wie Sie den Umsatz steigern und die Kundennachfrage besser decken können.
-
Anwendungsfall
Genaue Prognose zur Lieferantenvorlaufzeit mithilfe einer Datenplattform
Erfahren Sie, wie eine Datenplattform für den Einzelhandel die Vorlaufzeitprognose von Lieferanten verbessern kann, damit Sie sicherstellen können, dass Ihnen immer die richtigen Produkte zur Verfügung stehen, um die Kundennachfrage zu decken.
Erste Schritte
Mehr als 20 kostenlose Cloud-Services mit einer 30-tägigen Testversion für noch mehr
Oracle bietet ein Free Tier ohne zeitliche Begrenzung für eine Auswahl von mehr als 20 Services wie Autonomous AI Database , Arm Compute und Storage an. Darüber hinaus erhalten Sie 300 US-Dollar an kostenlosen Credits, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- AMD und Arm Compute-VMs
- Insgesamt 200 GB Blockspeicher
- 10 GB Objektspeicher
- 10 TB ausgehende Datenübertragung pro Monat
- Mehr als 10 permanent kostenlose Services
- Kostenlose Credits im Wert von 300 US-Dollar, 30 Tage lang noch mehr
Mit schrittweiser Anleitung lernen
Erleben Sie eine breite Palette von OCI-Services in Tutorials und praktischen Übungen. Unabhängig davon, ob Sie ein Entwickler, Administrator oder Analyst sind, können wir Ihnen zeigen, wie OCI funktioniert. Viele Übungen werden auf dem Free Tier von Oracle Cloud oder einer von Oracle bereitgestellten freien Laborumgebung ausgeführt.
-
Erste Schritte mit zentralen OCI-Services
Die Übungen in diesem Workshop umfassen eine Einführung in zentrale Oracle Cloud Infrastructure-(OCI-)Services wie virtuelle Cloud-Netzwerke (VCN) sowie Compute- und Speicherservices.
Übungen zu den zentralen OCI-Services jetzt starten -
Autonomous AI Database – Schnellstart
In diesem Workshop vermitteln wir Ihnen die ersten Schritte, um Oracle Autonomous AI Database zu nutzen.
Jetzt mit der Übung für den Schnelleinstieg in Autonomous AI Database beginnen -
App aus einer Kalkulationstabelle erstellen
In dieser Übung laden Sie eine Tabelle in eine Oracle Database-Tabelle hoch und erstellen anschließend eine Anwendung auf Basis dieser neuen Tabelle.
Diese Übung jetzt starten
Entdecken Sie mehr als 150 Best Practice-Designs
Erfahren Sie, wie unsere Architekten und anderen Kunden eine Vielzahl von Workloads bereitstellen, von Unternehmensanwendungen bis hin zu HPC, von Microservices bis hin zu Data Lakes. Informieren Sie sich über Best Practice, hören Sie von anderen Kundenarchitekten in unserer Reihe „Built & Deploy“, und stellen Sie außerdem viele Workloads mit unserer Funktion „Click-to-Deployment“ oder selbst aus unserem GitHub-Repository bereit.
Beliebte Architekturen
- Apache Tomcat mit MySQL Database Service
- Oracle Weblogic auf Kubernetes mit Jenkins
- ML- und KI-Umgebungen
- Tomcat on Arm mit Oracle Autonomous AI Database
- Loganalyse mit ELK-Stack
- HPC mit OpenFOAM
Erfahren Sie, wie viel Sie bei OCI sparen können
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Den Unterschied entdecken:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen
Vertrieb kontaktieren
Möchten Sie mehr über die Oracle Cloud Infrastructure erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten wie:
- Welche Workloads werden am besten auf OCI ausgeführt?
- Wie kann ich meine gesamten Oracle Investitionen optimal nutzen?
- Wie schlägt sich OCI verglichen mit anderen Cloud-Computing-Anbietern?
- Wie kann OCI Ihre IaaS- und PaaS-Ziele unterstützen?