Consolidación de datos de plantas de producción

Optimiza la eficiencia y reduce el riesgo con datos consolidados en tiempo real
Los fabricantes de hoy en día deben conocer la eficiencia con la que se ejecutan todas sus líneas en múltiples plantas: necesitan saber inmediatamente cuando se produce un problema, no cinco o diez minutos después del hecho. Sin embargo, este también es uno de sus mayores desafíos, ya que su capacidad para hacerlo depende del acceso en tiempo real a los datos de múltiples ubicaciones remotas que pueden tener conectividad a Internet limitada o esporádica. Para solucionar este problema, necesitamos llevar el machine learning (ML) y la adquisición de datos al perímetro de la red.
Simplifica la toma de decisiones en el perímetro
Podemos configurar Oracle Data Platform para resolver este desafío mediante la inclusión de Oracle Roving Edge Devices (RED). Cada RED se diseña para capturar, almacenar, ejecutar, gestionar y obtener insights a partir de los datos, lo que ofrece a los fabricantes la capacidad de automatizar el proceso de toma de decisiones y la gestión de los equipos de fabricación en el perímetro. Oracle Data Platform for Manufacturing también incluye capacidades de detección de anomalías que se pueden utilizar para abordar las interrupciones de la línea de fabricación y proporcionar insights sobre el mantenimiento para mejorar la mitigación y la solución de riesgos.
La siguiente arquitectura demuestra cómo Oracle Data Platform facilita la consolidación de datos de plantas mediante el despliegue de análisis avanzados y machine learning en el perímetro para identificar anomalías, realizar una recopilación de datos inteligente y proporcionar información operativa en tiempo real.
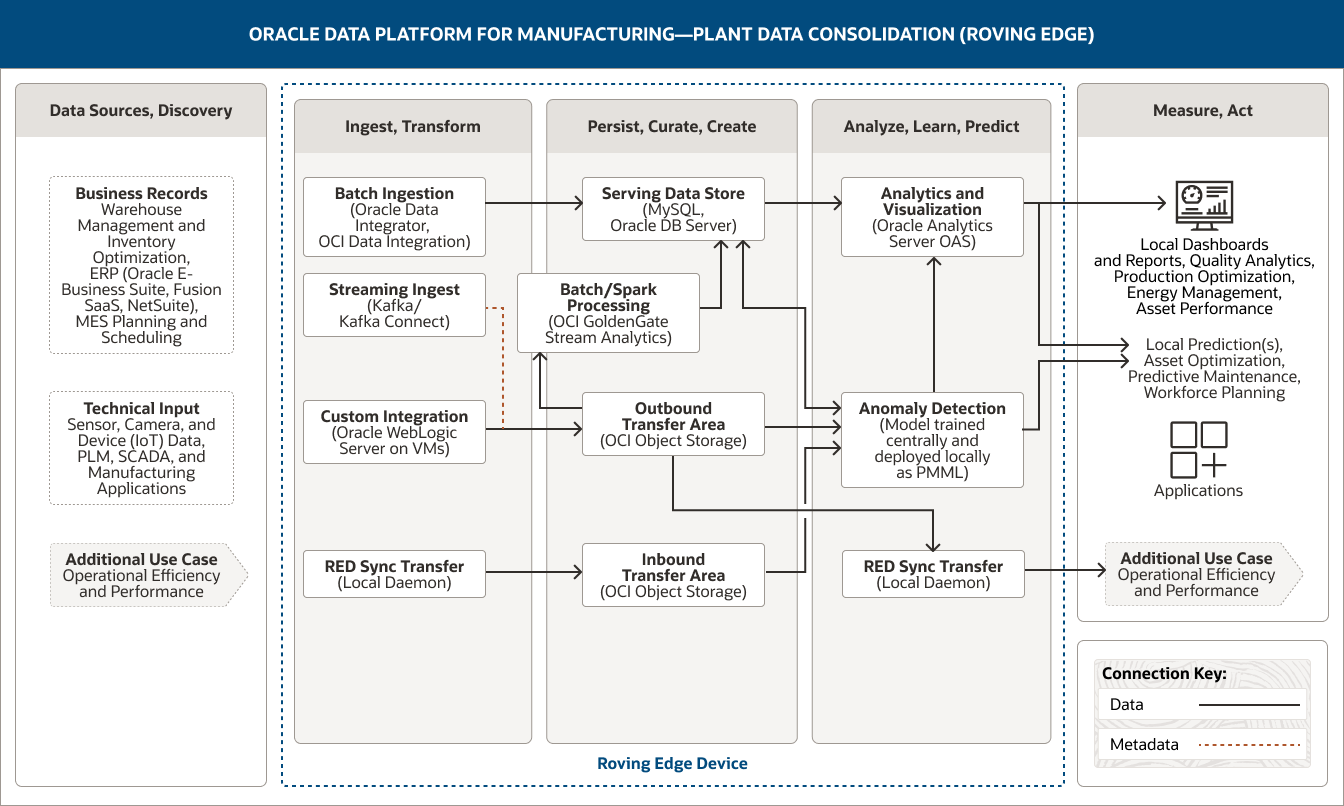
En esta imagen se muestra cómo se puede utilizar Oracle Data Platform for Manufacturing para consolidar los datos de plantas. La plataforma incluye estos cinco pilares:
- 1. Orígenes de datos, detección
- 2. Ingerir, transformar
- 3. Persistir, curar, crear
- 4. Analizar, aprender, predecir
- 5. Medir, actuar
El pilar "Orígenes de datos, detección" incluye dos categorías de información.
- 1. Los datos de los registros de negocio incluyen datos de gestión de almacenes y optimización de inventarios, datos de ERP (Oracle E-Business Suite, Fusion SaaS, NetSuite) y datos de planificación y programación de MES.
- 2. Los datos de entrada técnicos incluyen datos de sensores, cámaras y dispositivos (IdC) y datos de PLM, SCADA y aplicaciones de fabricación.
El pilar "Ingerir, transformar" comprende cuatro capacidades.
- 1. La ingesta por lotes utiliza Oracle Data Integrator y OCI Data Integration.
- 2. La ingesta de streaming utiliza Kafka Connect.
- 3. La integración personalizada utiliza Oracle WebLogic Server en máquinas virtuales.
- 4. La transferencia de sincronización de RED utiliza un daemon local.
La ingesta de lotes se conecta de forma unidireccional al almacén de datos en servicio.
La integración personalizada y la ingesta de streaming se conectan de forma unidireccional al área de transferencia de datos de salida.
Además, la transferencia de sincronización de RED se conecta unidireccionalmente al área de transferencia de datos de entrada.
El pilar Persistir, curar, crear incluye cuatro capacidades.
- 1. El almacén de datos de servicio utiliza MySQL y el servidor de Oracle DB.
- 2. El procesamiento por lotes/procesamiento de Spark utiliza OCI GoldenGate Stream Analytics.
- 3. El área de transferencia saliente utiliza OCI Object Storage.
- 4. El área de transferencia entrante utiliza OCI Object Storage.
Estas capacidades están conectadas dentro del pilar. El procesamiento por lotes/Spark se conecta unidireccionalmente al almacén de datos de servicio.
El área de transferencia saliente está unidireccionalmente conectada al procesamiento por lotes/Spark.
Tres capacidades se conectan al pilar "Analizar, aprender, predecir":
El almacén de datos de servicio se conecta de forma unidireccional a la capacidad de análisis y visualización, y de forma bidireccional a la capacidad de detección de anomalías. El área de transferencia saliente se conecta unidireccionalmente a las capacidades de detección de anomalías y transferencia de sincronización RED.
El área de transferencia entrante se conecta unidireccionalmente a la capacidad de detección de anomalías.
El pilar Analizar, aprender, predecir incluye tres capacidades.
- 1. El análisis y la visualización utilizan Oracle Analytics Server.
- 2. La detección de anomalías utiliza un modelo entrenado de forma centralizada y desplegado localmente como PMML.
- 3. La transferencia de sincronización de RED utiliza un daemon local.
La capacidad de detección de anomalías está unidireccionalmente conectada a la capacidad de análisis y visualización dentro del pilar.
Existen tres capacidades conectadas al pilar Medir, actuar. La capacidad de análisis y visualización está unidireccionalmente conectada a informes y paneles de control locales, así como a predicciones locales. La capacidad de detección de anomalías está unidireccionalmente conectada a predicciones locales, y la capacidad de transferencia de sincronización RED está unidireccionalmente conectada a un caso de uso adicional.
El pilar Medir, actuar captura cómo se pueden utilizar los datos de planta consolidados. Estos usos potenciales se dividen en cuatro grupos.
- El primer grupo incluye paneles de control e informes locales.
- El segundo grupo incluye predicciones locales.
- El tercer grupo incluye aplicaciones.
- El cuarto grupo contiene un caso de uso adicional, que es la eficiencia operativa y el rendimiento.
Los tres pilares centrales, Ingerir, transformar; Persistir, curar, crear; y Analizar, aprender, predecir, están respaldados por Oracle Roving Edge Devices.
Existen cuatro formas principales de inyectar datos en una arquitectura para que los fabricantes comprendan fácilmente la eficiencia y el rendimiento operativos.
- Una integración personalizada de Oracle Integration Repository nos permite integrar datos (estructurados y no estructurados) desde varias fuentes, lo que permite interacciones con dispositivos, API personalizadas, etc. Los datos se pueden ingerir desde cualquier tipo de desarrollo de aplicaciones (por ejemplo, código Java o Python independiente, aplicaciones basadas en Oracle WebLogic Server o basadas en Kubernetes). Los datos se almacenarán en el almacenamiento de objetos para una mayor acotación, transferencias salientes o alimentar modelos de IA.
- La sincronización de datos RED constituye una forma eficaz y sencilla de transferir modelos de machine learning desde una ubicación central (por ejemplo, el repositorio de almacenamiento de objetos de modelos entrenados en Oracle Cloud Infrastructure (OCI)) hasta el perímetro. En este caso de uso, la definición del perímetro implicaría colocar RED con otra maquinaria dentro de la propia planta. Las nuevas versiones de los modelos se almacenan en formato "independiente" de lenguaje de marcado de modelo predictivo (PMML). El daemon local realizará una actualización cuando se detecte un nuevo modelo y lo insertará automáticamente en RED. La sincronización de datos de RED también es una gran manera de transferir todos los datos recopilados por diferentes RED a lo largo del día (por ejemplo, anomalías relevantes, señales, etc.) a su ubicación central, probablemente al almacenamiento de objetos de OCI. Posteriormente, estos datos se utilizarán para la generación de informes operativos y el entrenamiento del modelo de machine learning. El volumen de datos involucrados en estos procesos de sincronización de datos RED determinará tus requisitos para el ancho de banda de telecomunicaciones o satélite del perímetro al centro de datos.
- La ingesta por lotes utiliza Oracle Data Integrator, una solución de integración de datos integral que cubre todos los requisitos de integración de datos: desde cargas por lotes de alto volumen, hasta procesos de integración de alimentación por goteo e impulsados por eventos, hasta servicios de datos habilitados por SOA. Aunque las necesidades en tiempo real no paran de cambiar, la extracción más común de los sistemas de ERP, planificación, gestión de almacenes y gestión de transporte se lleva a cabo mediante la ingesta por lotes utilizando un proceso de extracción, transformación y carga o extracción, carga y transformación. Estas extracciones podrían ser frecuentes, incluso cada 10 o 15 minutos, pero mantienen una naturaleza masiva, ya que se extraen y procesan en grupos de transacciones en lugar de transacciones individuales. OCI ofrece diferentes servicios para manejar la ingesta de lotes, como el servicio nativo de OCI Data Integration u Oracle Data Integrator que se ejecuta en una instancia de OCI Compute. En función del volumen y la tipología, los datos se pueden cargar en el almacenamiento de objetos o directamente en una base de datos relacional estructurada para almacenamiento persistente.
- Analizar datos en tiempo real a partir de varias fuentes puede brindar a las empresas de fabricación valiosos insights sobre su eficiencia operativa y su rendimiento general. Oracle Data Platform utiliza ingesta de streaming para ingerir streaming de datos de varios sistemas de nivel 2 ISA-95, como sistemas de control de supervisión y adquisición de datos (SCADA), controles lógicos programables y sistemas de automatización de lotes. Se ingerirán los datos de streaming (eventos) y se producirán algunas transformaciones/agregaciones básicas antes de que los datos se alojen en almacenes de objetos. Los análisis de streaming se pueden utilizar para identificar eventos correlativos, y los patrones identificados se retroalimenta (manualmente) para someter los datos en bruto a un examen de data science. Mientras que las herramientas de análisis tradicionales extraen información de datos en reposo, los análisis de flujo evalúan el valor de los datos en movimiento, es decir, en tiempo real.
La persistencia y el procesamiento de datos se basan en tres componentes.
- En el almacén de datos de servicio, Oracle Database Server o MySQL gestionará los datos para su procesamiento. El almacén de datos de servicio proporciona una capa relacional persistente que se utiliza para proporcionar datos directamente a los usuarios finales mediante herramientas basadas en SQL. También funciona como capa de servicios para análisis especializados.
- Todos los datos recuperados de orígenes de datos en su formato en bruto (como archivo nativo o extracción) se captan y cargan en el almacén de objetos para utilizarlos en el entrenamiento de modelos actuales o futuros de machine learning. El almacenamiento de objetos en la nube es la capa de persistencia de datos más común para nuestra plataforma de datos y sirve como área de transferencia entrante y como área de transferencia saliente. Se puede utilizar para datos tanto estructurados como no estructurados.
- Con el almacenamiento de objetos como principal capa de persistencia de datos, OCI GoldenGate Stream Analytics actúa como motor de procesamiento principal. El procesamiento por lotes incluye varias actividades, como tratamiento básico de ruido, gestión de datos ausentes y filtrado basado en conjuntos de datos de salida definidos. Los resultados se vuelven a escribir en varias capas de almacenamiento de objetos o en un repositorio relacional persistente dependiendo del procesamiento que sea necesario y los tipos de datos que se utilicen.
La capacidad de analizar, aprender y predecir se basa en dos tecnologías.
- Los servicios de análisis y visualización ofrecen análisis descriptivos (describen las tendencias actuales con histogramas y gráficos), predictivos (prevén eventos futuros, identifican tendencias y determinan las probabilidades de resultados inciertos) y prescriptivos (proponen acciones adecuadas, lo que lleva a una toma de decisiones óptima). Oracle Analytics Server proporciona la funcionalidad necesaria para realizar análisis descriptivos relacionados con la elaboración de informes operativos y análisis prescriptivos. Además, se pueden incorporar modelos de machine learning directamente en el flujo de datos de Oracle Analytics Server. Oracle Analytics Server está diseñado para ejecutarse de forma local y proporciona paneles de control, informes, alertas, preparación de datos de autoservicio y algoritmos de machine learning orientados al usuario final. Oracle Data Platform for Manufacturing es completamente abierta y flexible, por lo que, si lo deseas, tienes la posibilidad de utilizar herramientas de terceros.
- Además del uso de análisis avanzados, se desarrollan, entrenan y despliegan modelos de aprendizaje automático para reforzar la detección de anomalías. OCI Anomaly Detection es un servicio de IA que permite a los desarrolladores crear con facilidad modelos de detección de anomalías específicos de negocio que señalan incidentes críticos, lo que acelera su detección y resolución. Estos modelos se entrenarán en la ubicación central y se desplegarán en formato PMML para que se ejecuten localmente como código Java o Python.
Automatiza la toma de decisiones para impulsar la rentabilidad
La plataforma de datos de Oracle permite a los fabricantes aprovechar al máximo todos los datos disponibles, al tiempo que simplifica y optimiza el acceso y el almacenamiento. La capacidad de transferir la recopilación de datos y la puntuación del machine learning al perímetro mediante Oracle Roving Edge Devices ayuda a los fabricantes a tomar mejores decisiones de negocio basadas en datos precisos siempre disponibles cuando los necesites, de modo que aumentas la eficiencia y la producción a la vez que reduces los costos.
Recursos relacionados
-
Caso de uso
Utiliza los datos para mejorar la salud y la seguridad en el trabajo
Descubre cómo hacer que las operaciones de fabricación sean más seguras mediante una plataforma de datos que ayuda a mejorar la salud y la seguridad con análisis avanzados.
-
Caso de uso
Utiliza los datos para mejorar la eficiencia y el desempeño de las operaciones de fabricación
Aprende a gestionar las operaciones de fabricación de forma más eficiente mediante una plataforma de datos que mejora el desempeño con el aprendizaje automático.
-
Caso de uso
Utiliza tus datos para pasar del mantenimiento reactivo al predictivo
Descubre cómo optimizar los activos con una plataforma de datos que permita realizar un mantenimiento predictivo basado en machine learning (ML).
Comienza ahora
Prueba más de 20 servicios Always Free en la nube con un periodo de prueba de 30 días para conocerlos aún mejor
Oracle ofrece un modo gratuito sin límite de tiempo para más de 20 servicios, como Autonomous AI Database , Arm Compute y Storage, así como 300 dólares en créditos gratuitos para probar otros servicios en la nube. Obtén información detallada y regístrate hoy mismo para obtener tu cuenta gratuita.
-
¿Qué incluye el modo gratuito de Oracle Cloud?
- Dos instancias de Autonomous AI Database, cada una de 20 GB
- Máquinas virtuales de AMD y Arm Compute
- Almacenamiento de bloques total de 200 GB
- 10 GB de almacenamiento de objetos
- Transferencia de datos salientes de 10 TB por mes
- Más de 10 servicios Always Free
- 300 dólares estadounidenses en créditos gratuitos durante 30 días para obtener aún más
Aprende con la orientación paso a paso
Experimenta una amplia gama de servicios OCI mediante tutoriales y laboratorios prácticos. Tanto si eres un desarrollador, administrador o analista, podemos ayudarte a entender cómo funciona OCI. Muchos laboratorios se ejecutan en el modo gratuito de Oracle Cloud o en un entorno de laboratorio gratis proporcionado por Oracle.
-
Introducción a los servicios básicos de OCI
En los laboratorios de este taller se ofrece una introducción a los servicios básicos de Oracle Cloud Infrastructure (OCI), incluidas las redes virtuales en la nube (VCN) y los servicios informáticos y de almacenamiento.
Inicia el laboratorio de servicios básicos de OCI ahora -
Inicio rápido de Autonomous AI Database
En este taller, conocerás los pasos necesarios para comenzar a utilizar Oracle Autonomous AI Database.
Comienza el laboratorio de Autonomous AI Database ahora mismo -
Crea una aplicación a partir de una planilla
En este laboratorio recorrerás todo el proceso, desde la carga de una hoja de cálculo en una tabla de Oracle Database, hasta la creación de una aplicación basada en esta nueva tabla.
Comienza el laboratorio ahora mismo
Conoce más de 150 diseños de mejores prácticas
Descubre cómo nuestros arquitectos y otros clientes despliegan una amplia gama de cargas de trabajo, desde aplicaciones empresariales hasta computación de alto rendimiento, desde microservicios hasta lagos de datos. Comprende las mejores prácticas, aprende de otros arquitectos de clientes en nuestra serie Built & Deployed, e incluso despliega múltiples cargas de trabajo con nuestra capacidad de "hacer clic para desplegar" o hazlo tú mismo desde nuestro repositorio de GitHub.
Arquitecturas populares
- Apache Tomcat con MySQL Database Service
- Oracle Weblogic en Kubernetes con Jenkins
- Entornos de aprendizaje automático (ML) e IA
- Tomcat en Arm con Oracle Autonomous AI Database
- Análisis de registros con el stack ELK
- HPC con OpenFOAM
Descubre todo lo que puedes ahorrar en OCI
Los precios de Oracle Cloud son sencillos, con tarifas consistentemente bajas en todo el mundo, y con apoyo a una amplia gama de casos de uso. Para hacer una estimación de tu tarifa reducida, da un vistazo a la calculadora de costos y configura los servicios que se adapten mejor a tus necesidades.
Descubre la diferencia:
- 1/4 de los costos de ancho de banda saliente
- 3 veces la relación precio-rendimiento de los recursos informáticos
- El mismo bajo precio en cada región
- Precios bajos sin compromisos a largo plazo
Ponte en contacto con ventas
¿Te gustaría obtener más información sobre Oracle Cloud Infrastructure? Permite que uno de nuestros expertos te ayude.
-
Pueden responder a preguntas como:
- ¿Qué cargas de trabajo funcionan mejor en OCI?
- ¿Cómo puedo obtener el máximo rendimiento de mis inversiones generales de Oracle?
- ¿Cómo es OCI en comparación de otros proveedores de computación en la nube?
- ¿De qué forma OCI apoya la consecución de tus objetivos en materia de IaaS y PaaS?