Un enfoque de aprendizaje automático para predecir el tamaño de los hogares
Selim Mimaroglu, director de ciencia de datos y aprendizaje automático
Anqi Shen, científica de datos principal
El tamaño del hogar es una pieza de información importante que se usa para diversas tareas de elegibilidad y planificación: asequibilidad energética, asequibilidad del agua, planificación de redes, demanda y planificación del agua, programas de eficiencia energética que incluyen informes de energía del hogar con comparaciones entre vecinos, y planificación de la gestión de residuos. El sector de la construcción representa más del 30 % del consumo energético mundial total, y la cantidad de personas en los edificios residenciales, también conocida como “tamaño del hogar,” afecta significativamente el uso total de energía (Rueda 2021).
En los últimos años, ha habido un gran interés en la detección de ocupación mediante aprendizaje automático y termostatos inteligentes. La mayoría de los termostatos inteligentes pueden detectar la ocupación con precisión dentro del alcance de sus sensores. Existen buenos modelos y sus implementaciones en software que también pueden predecir la ocupación en un hogar. La detección de ocupación se usa como una parte integral de la eficiencia energética, especialmente con HVAC: cuando no hay ocupación, los puntos de ajuste de calefacción y refrigeración se ajustan para fomentar el ahorro de energía. La detección de ocupación, sin importar cómo se realice, tiene un resultado binario: ocupado vs. no ocupado. Aunque esta información puede ser muy útil en algunos escenarios, no es suficiente para llevar a cabo algunos de los casos de uso y tareas descritos anteriormente, especialmente para la planificación y elegibilidad de programas de asequibilidad.
En este trabajo, compartimos nuestro modelo de aprendizaje automático que puede predecir con gran precisión la cantidad de personas que viven en un hogar. Antes de entrar en detalles, es importante señalar que los datos granulares sobre tamaño del hogar no están disponibles en la mayoría de las regiones de los Estados Unidos. El censo de EE. UU. solo proporciona el tamaño promedio del hogar por zona censal. Aunque esta información puede ser útil en algunos casos, no puede responder preguntas detalladas, personales o a nivel de hogar, cuyas respuestas se necesitan para el Programa de Asistencia para la Eficiencia Energética en Hogares de Bajos Ingresos (LIHEAP) y el Programa de Asistencia para el Agua en Hogares de Bajos Ingresos (LIHWAP), así como para la mayoría de los programas estatales como el Programa de Asistencia Energética de Maryland (MEAP). El tamaño del hogar afecta el consumo de energía; algunos electrodomésticos grandes están correlacionados con el tamaño del hogar, como el calentador de agua, la lavadora, la secadora y el lavavajillas. El tamaño del hogar también afecta el uso de agua y la cantidad de residuos generados. Por lo tanto, conocer el tamaño del hogar a un nivel granular puede ser muy útil para la planificación (inteligente) de redes, la demanda y planificación del agua y la gestión de residuos.
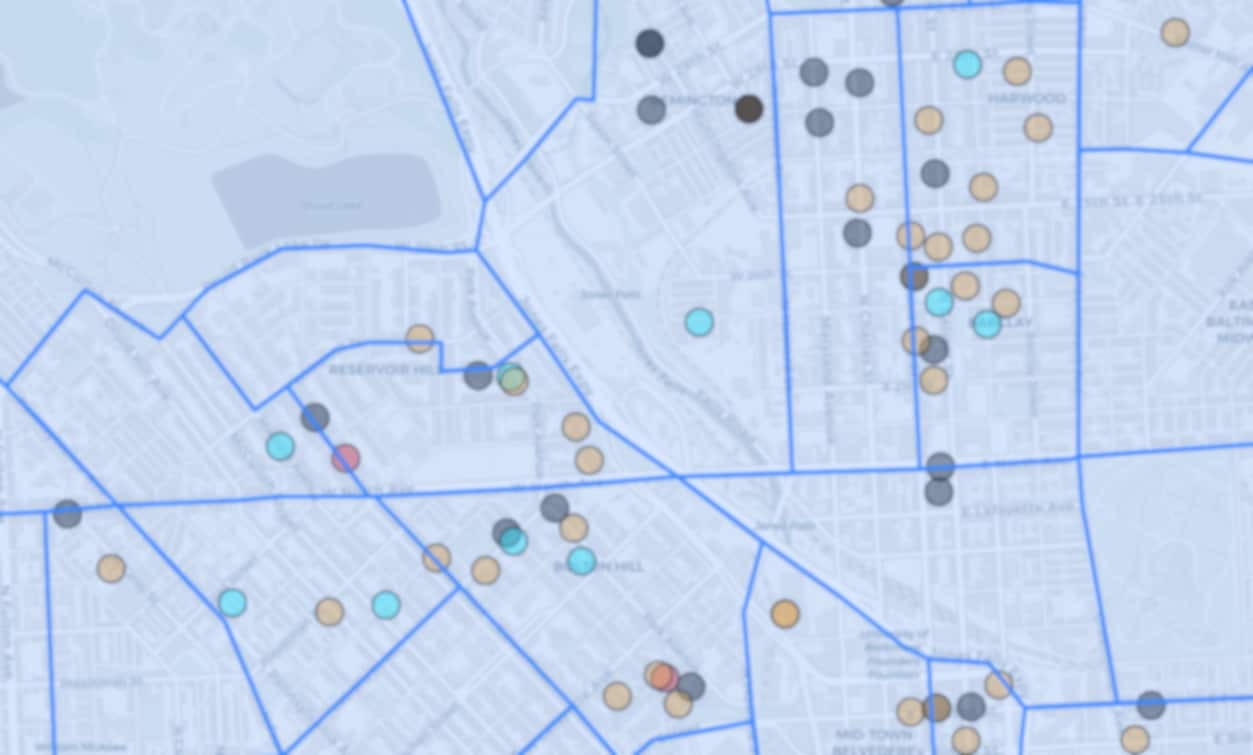
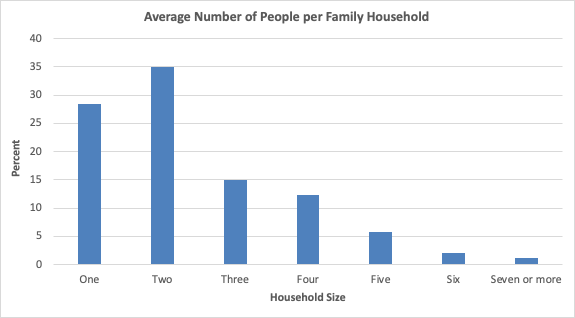
Nuestros modelos de aprendizaje profundo son capaces de predecir el tamaño del hogar a nivel personal, como se ve en la Figura 1. El censo de EE. UU. proporciona información sobre el tamaño promedio de las familias (Figura 2) para grandes regiones de varios cientos de hogares, conocidas como zonas censales. El censo de EE. UU. también proporciona la distribución del tamaño de los hogares (ver Figura 3, que representa esta información sobre algunas áreas en Maryland). Para la mayoría de las tareas de asequibilidad energética, asequibilidad del agua y planificación de redes, se necesita una granularidad más fina en el tamaño del hogar, similar a la que ofrece nuestro modelo.
Metodología de aprendizaje automático
Hemos revisado la bibliografía, pero no encontramos trabajos comparables de modelado con aprendizaje automático. Nuestro objetivo es predecir el tamaño del hogar a partir de datos de consumo eléctrico, que pueden provenir de la Infraestructura de Medición Avanzada (AMI) o de datos de facturación. Innovamos en nuestra arquitectura de aprendizaje profundo, tras revisar cuidadosamente las arquitecturas más avanzadas publicadas por investigadores. Tratamos de mantener el número de parámetros y la profundidad del modelo en niveles razonables para un entrenamiento y evaluación eficientes. Nuestra arquitectura final tiene aproximadamente 30 capas y está compuesta por alrededor de 600 000 parámetros.
Nuestros modelos pueden predecir el número de ocupantes activos en la casa con una granularidad semanal. Para granularidades mayores, como meses o un año, agregamos las salidas semanales a la granularidad objetivo.
Comparación
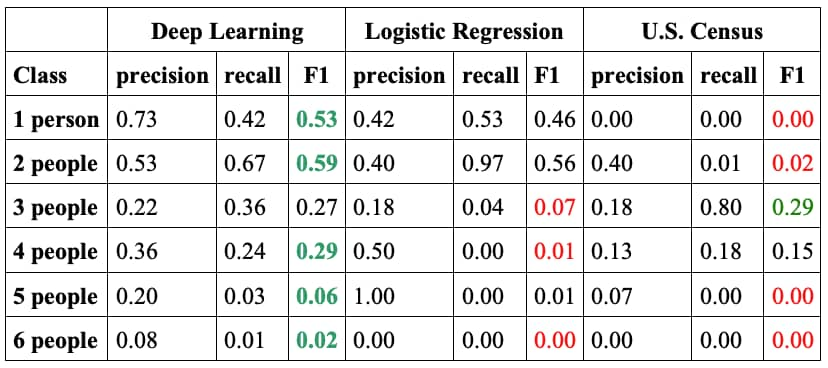
Realizamos comparaciones directas entre nuestro modelo de aprendizaje profundo, regresión logística y la zona censal del censo de EE. UU. en un área considerablemente grande de Maryland. La regresión logística, que es un modelo de clasificación popular, se entrena con el mismo conjunto de entrenamiento y se evalúa con el mismo conjunto de desarrollo que el modelo de aprendizaje profundo. Hemos listado precisión, exhaustividad y valores F1 en la Tabla 1 a continuación. La puntuación F1 es una forma de combinar la precisión y la exhaustividad del modelo, y se define como la media armónica de ambas. Puedes encontrar las definiciones formales en Wikipedia, pero de forma intuitiva, la exhaustividad es la capacidad del modelo para encontrar todos los casos relevantes, mientras que la precisión es la capacidad del modelo para identificar correctamente la clase correcta (en nuestro caso, el tamaño del hogar). Para cada métrica, un valor más alto es mejor, y el valor máximo puede ser 1,0. En cinco de las seis clases nuestro modelo es el ganador, y para la clase de tres personas, los resultados F1 de nuestro modelo son comparables al del ganador.
La Figura 3 (a continuación) muestra el consumo energético de tres hogares reales mediante datos AMI. Un lector novato podría pensar que, al observar los datos de consumo energético, sería fácil adivinar correctamente cuántas personas viven en estos hogares. Pero en la Figura 4 puedes ver que no es así: estos hogares no son fácilmente ni linealmente separables. Los tres ejemplos que se muestran aquí demuestran que nuestro modelo es lo suficientemente sofisticado y potente como para identificar correctamente el tamaño del hogar, especialmente —y lo más importante— en casos no intuitivos.

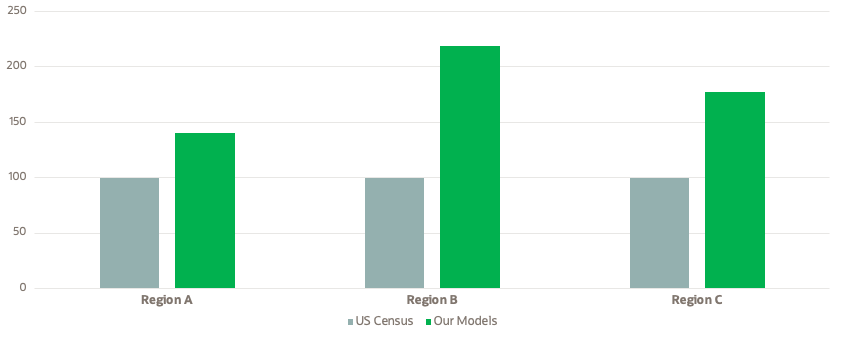
La Figura 4 muestra una comparación directa con datos de inscripción que predicen qué hogares están inscritos en el programa LIHEAP. Podemos ver que en cada región, nuestros modelos predicen más clientes inscritos. Como puede verse, el beneficio de usar nuestros modelos es enorme, alcanzando el 149 %, 177 % y 219 % en comparación con el enfoque del Censo de EE. UU.
Los clientes de bajos ingresos tienen dificultades para pagar sus facturas de servicios públicos. Nuestros modelos de aprendizaje profundo —ingresos, tamaño del hogar y otros— están ayudando a las empresas de servicios públicos a encontrar, contactar e inscribir a muchos más clientes de bajos ingresos en programas de asistencia financiera y eficiencia.