Improve value-based care with performance monitoring

Improve staffing well-being and enhance patient care
Today’s health systems face two major, interrelated challenges: employee burnout and staffing shortages. Nearly 50% of surveyed physicians and nurses have reported substantial burnout symptoms due to the heavy burden of bureaucratic and administrative tasks and working too many hours. As a result, many workers have chosen to walk away from the industry in search of better work-life balance, leaving hospitals with large staffing gaps they’re unable to fill. More than half of US hospitals report nurse vacancy rates above 7.5%, and overtime and agency spend has increased 169% since 2013. Unfortunately, many estimates suggest the healthcare worker shortage will only get worse over the coming decade.
To face both these challenges, providers must continue to optimize their staffing models in ways that prioritize health practitioner well-being while ensuring the best possible patient experience and outcomes. Data platforms will play a critical role by giving providers central access to data from disparate systems and advanced analytics and machine learning models they can use to forecast staffing needs more accurately. With these insights, health organizations can better balance caseloads and help ensure adequate staffing at all times to prevent burnout and improve patient care.
Simplify healthcare staff planning with machine learning
While clinical data can tell practitioners a great deal about their patients, operational systems, such as human capital management (HCM) systems, can tell care organizations a great deal about their employees, providing information such as historical schedules, hours worked, and sick time taken by clinicians and other staff. As the following architecture demonstrates, Oracle Data Platform unifies clinical and operational data and uses advanced analytics and machine learning to help providers understand how staffing models impact patient outcomes, how staffing decisions may impact the next week of care in near real time, what staffing gaps may need to be filled in the event of another major surge in COVID-19 cases, what an optimal staffing model looks like for any given point in time, and more.
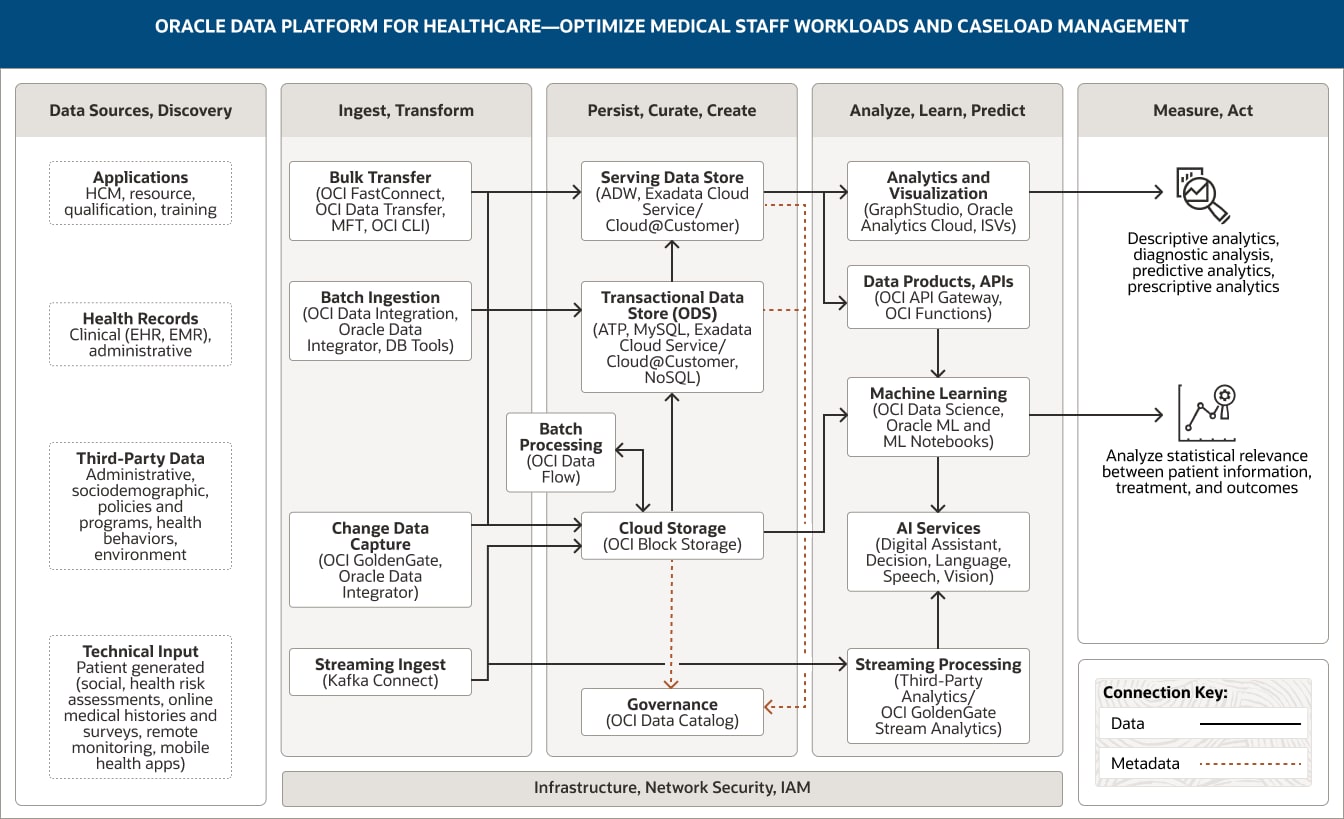
This image shows how Oracle Data Platform for healthcare can be used to optimize medical staff workloads. The platform includes the following five pillars:
- 1. Data Sources, Discovery
- 2. Ingest, Transform
- 3. Persist, Curate, Create
- 4. Analyze, Learn, Predict
- 5. Measure, Act
The Data Sources, Discovery pillar includes four categories of data.
- 1. Applications data comprises HCM, resource, qualification, and training data.
- 2. Health records include clinical data such as data from EHRs, EMRs, and administrative systems.
- 3. Third-party data comprises administrative and sociodemographic data and data related to policies and programs, health behaviors, and the environment.
- 4. Technical input data includes patient-generated data (such as social data, health risk assessments, online medical histories, and survey responses) and data from remote monitoring and mobile health apps.
The Ingest, Transform pillar comprises four capabilities.
- 1. Bulk transfer uses OCI FastConnect, OCI Data Transfer, MFT, and OCI CLI.
- 2. Batch ingestion uses OCI Data Integration, Oracle Data Integrator, and DB tools.
- 3. Change data capture uses OCI GoldenGate and Oracle Data Integrator.
- 4. Streaming ingest uses Kafka Connect.
All four capabilities connect unidirectionally into the serving data store, cloud storage, and transactional data store within the Persist, Curate, Create pillar.
Additionally, streaming ingest is connected to stream processing within the Analyze, Learn, Predict pillar.
The Persist, Curate, Create pillar comprises five capabilities.
- 1. The serving data store uses Autonomous Data Warehouse, Exadata Cloud Service, and Exadata Cloud@Customer.
- 2. The transactional data store uses Autonomous Transaction Processing, MySQL, Exadata Cloud Service, Exadata Cloud@Customer, and NoSQL.
- 3. Cloud storage uses OCI Object Storage.
- 4. Batch processing uses OCI Data Flow.
- 5. Governance uses OCI Data Catalog.
These capabilities are connected within the pillar. Cloud storage is unidirectionally connected to the serving data store; it is also bidirectionally connected to batch processing.
The transactional data store is unidirectionally connected to the serving data store.
Two capabilities connect into the Analyze, Learn, Predict pillar: The serving data store connects to both the analytics and visualization capability and the data products, APIs capability. Cloud storage connects to the machine learning capability.
The Analyze, Learn, Predict pillar comprises five capabilities.
- 1. Analytics and visualization uses Oracle Analytics Cloud, GraphStudio, and ISVs.
- 2. Data products, APIs uses OCI API Gateway and OCI Functions.
- 3. Machine learning uses OCI Data Science, Oracle Machine Learning, and Oracle ML Notebooks.
- 4. AI services uses Oracle Digital Assistant, OCI Decision, OCI Speech, OCI Language, and OCI Vision.
- 5. Streaming processing uses OCI GoldenGate Stream Analytics and stream analytics from third parties.
Three capabilities are connected within the pillar. The data products, APIs capability is unidirectionally connected to the machine learning capability, which is itself unidirectionally connected to the AI services capability, and stream processing is unidirectionally connected to the AI services capability.
The serving data store, transactional data store, and object storage supply metadata to OCI Data Catalog.
The Measure, Act pillar captures how the data analysis may be applied to support optimizing medical staff workloads and caseload management. These applications are divided into two groups.
- 1. The first group includes descriptive analytics, diagnostic analysis, and predictive and prescriptive analytics.
- 2. The second group includes analyzing statistical relevance between patient information, treatment, and outcomes.
- 3. The three central pillars—Ingest, Transform; Persist, Curate, Create; and Analyze, Learn, Predict—are supported by infrastructure, network, security, and IAM.
There are three main ways to inject data into an architecture to enable healthcare organizations to understand how to best staff each department at any given point in time.
- Historical staffing and patient-related data is critical to understand and predict future staffing needs. The HCM application will provide much of the data needed for insight into past staffing models and individual staff members. And the admission, discharge, and transfer (ADT) application will provide basic details about each patient. This data can be enriched with patient data from third-party sources, which could include unstructured data from social media, for example. Frequent real-time or near real-time extracts requiring change data capture are common, and data is regularly ingested from HCM and ADT operational systems using OCI GoldenGate. OCI GoldenGate is also a critical component of evolving data mesh architectures where “data products” are the central data objects.
- We can now add streaming data from wearable devices, which will be ingested in real time using a streaming service/Kafka. For example, we can ingest data from wearables with GPS tracking that monitor the location and movement of staff throughout the day and use it to understand how to better assign staff to units and patients. This streamed data (events) will be ingested and some basic transformations/aggregations will occur before the data is stored in cloud storage.
- While real-time needs are evolving, the most common extract from healthcare systems is a kind of batch ingestion using an extract, transform, and load or extract, load, and transform process. Batch ingestion is used to import data from systems that can’t support streaming ingestion (for example, older mainframe systems). To get a full understanding of patient needs, we also need to ingest data from an operational system such as an electronic medical record (EMR) or electronic health record (EHR) system, most likely via the Fast Healthcare Interoperability Resources protocol. The data is sourced across products and geographies. Batch ingestions can be frequent, as often as every 10 or 15 minutes, but they are still bulk in nature as transactions are extracted and processed in groups rather than individually.
Data persistence and processing options for all the collected data are built on four components.
- Ingested raw data is stored in cloud storage for batch processing, which will do the required cleansing, enriching, and so on to put the data into the necessary state to be consumed by downstream users, which could be people, applications, or machine learning platforms. Though some data may be directly placed in the serving data store, this data is also simultaneously placed in cloud storage. This data will be processed using Spark. Processing can be performed directly using OCI Data Flow or as part of a larger pipeline using the orchestration capabilities in OCI Data Integration. These processed datasets are returned to cloud storage for onward persistence, curation, and analysis and ultimately for loading in optimized form to the serving data store.
- The transactional data store is used for operational reporting and as a source of data for a domain data warehouse or an enterprise data warehouse (EDW). It is a complementary element to an EDW in a decision support environment and is used for operational reporting, controls, and decision-making, as opposed to the EDW, which is used for tactical and strategic decision support. An operational data store (ODS) is typically a relational database designed to integrate and persist data from multiple sources to be used for additional operations, reporting, controls, and operational decision support.
- We have now created processed datasets that are ready to be persisted in optimized relational form for curation and query performance in the serving data store. This gives providers access to examine all the data and variables necessary to develop optimal staffing plans.
The ability to analyze, predict, and act relies on two technologies.
- Analytics and visualization services deliver descriptive analytics (describes current trends with histograms and charts), predictive analytics (predicts future events, identifies trends, and determines the probabilities of uncertain outcomes), and prescriptive analytics (proposes suitable actions, leading to optimal decision-making). Together, they can be used to predict staffing needs and offer suitable recommendations. For example, analytics can be used to predict whether a cluster of patients living in a specific area, who are subjected to varying environmental impacts (such as temperature), and who show certain symptoms may indicate an impending illness outbreak that would require a provider to make changes to their staffing model to handle the anticipated caseload increase.
- Alongside the use of advanced analytics, machine learning models are developed, trained, and deployed. These trained models can be run on both current and historical operational data to detect events and trends, such as an increase in unhappy staff members, which may lead to higher turnover rates. These events and other results can be persisted back to the serving layer and reported using analytics tools such as Oracle Analytics Cloud. The model and data can also be fed into machine learning systems, such as OCI Data Science, to further train the models to recommend more-effective staffing models before promoting them. These models can be accessed via APIs, deployed within the serving data store, or embedded as part of the OCI GoldenGate streaming analytics pipeline.
- Our curated, tested, and high-quality data and models can have governance rules and policies applied and can be exposed as a data product (API) within a data mesh architecture for distribution across the healthcare organization.
Beyond staffing: Use data to tackle other key healthcare challenges
Beyond providing your healthcare organization with the ability to develop better, more accurate staffing models, Oracle Data Platform can also help you optimize operations in other areas to improve patient care, lower costs, and elevate the employee experience. Here are some examples.
- Drive holistic and coordinated care for target patient groups.
- Identify the potential for system failure in case of predicted pandemic surges well in advance, and proactively intervene to help ensure system success.
- Monitor patient cohort trends to evaluate the effectiveness of their care programs.
- Identify areas of treatment overuse.
- Monitor care delivery quality and cost.
- Build patient risk stratification models.
- Predict the risk of patient readmission.
- Recommend preventive care to support patient self-management.
Related resources
-
Use case
Healthcare supply chain optimization
Learn how to increase the resilience of your supply chain with Oracle Data Platform for healthcare.
-
Use case
Population healthcare management
Learn how to optimize population healthcare management to better meet patient needs, improve outcomes, and lower costs with Oracle Data Platform for healthcare.
-
Use case
Improve value-based care with performance monitoring
Learn how to simplify evaluating your value-based care strategy with Oracle Data Platform for healthcare.
Get started
Try 20+ Always Free cloud services, with a 30-day trial for even more
Oracle offers a Free Tier with no time limits on more than 20 services such as Autonomous AI Database, Arm Compute, and Storage, as well as US$300 in free credits to try additional cloud services. Get the details and sign up for your free account today.
-
What’s included with Oracle Cloud Free Tier?
- Two Autonomous AI Database instances, 20 GB each
- AMD and Arm Compute VMs
- 200 GB total block storage
- 10 GB object storage
- 10 TB outbound data transfer per month
- 10+ more Always Free services
- US$300 in free credits for 30 days for even more
Learn with step-by-step guidance
Experience a wide range of OCI services through tutorials and hands-on labs. Whether you're a developer, admin, or analyst, we can help you see how OCI works. Many labs run on the Oracle Cloud Free Tier or an Oracle-provided free lab environment.
-
Get started with OCI core services
The labs in this workshop cover an introduction to Oracle Cloud Infrastructure (OCI) core services including virtual cloud networks (VCN) and compute and storage services.
Start OCI core services lab now -
Autonomous AI Database quick start
In this workshop, you’ll go through the steps to get started using Oracle Autonomous AI Database.
Start Autonomous AI Database quick start lab now -
Build an app from a spreadsheet
This lab walks you through uploading a spreadsheet into an Oracle Database table, and then creating an application based on this new table.
Start this lab now
Explore over 150 best practice designs
See how our architects and other customers deploy a wide range of workloads, from enterprise apps to HPC, from microservices to data lakes. Understand the best practices, hear from other customer architects in our Built & Deployed series, and even deploy many workloads with our "click to deploy" capability or do it yourself from our GitHub repo.
Popular architectures
- Apache Tomcat with MySQL Database Service
- Oracle Weblogic on Kubernetes with Jenkins
- Machine-learning (ML) and AI environments
- Tomcat on Arm with Oracle Autonomous AI Database
- Log analysis with ELK Stack
- HPC with OpenFOAM
See how much you can save on OCI
Oracle Cloud pricing is simple, with consistent low pricing worldwide, supporting a wide range of use cases. To estimate your low rate, check out the cost estimator and configure the services to suit your needs.
Experience the difference:
- 1/4 the outbound bandwidth costs
- 3X the compute price-performance
- Same low price in every region
- Low pricing without long-term commitments
Contact sales
Interested in learning more about Oracle Cloud Infrastructure? Let one of our experts help.
-
They can answer questions like:
- What workloads run best on OCI?
- How do I get the most out of my overall Oracle investments?
- How does OCI compare to other cloud computing providers?
- How can OCI support your IaaS and PaaS goals?