 Articles
Server and Storage Administration
Articles
Server and Storage Administration
マルチテナント・クラウド環境でのパフォーマンス分析
Orgad Kimchi著

仮想化されたマルチテナント・クラウド環境のパフォーマンス分析は、抽象化レイヤーがあるため困難です。この記事では、Oracle Solaris 11を使用してそのような制限を克服する方法について説明します。
2013年12月公開
|
準備
仮想化環境でのCPUワークロードの監視
仮想化環境でのディスクI/Oアクティビティの監視
仮想化環境でのメモリ使用状況の監視
仮想化環境でのネットワーク使用状況の監視
クリーンアップ・タスク
結論
参考資料
著者について
注:この記事の情報は、Oracle Solaris 11およびOracle Solaris 11.1に適用されます。
Oracle Solaris 11には、仮想化されたマルチテナント・クラウド環境でパフォーマンス分析を実施するための一連の新しいコマンドが付属しています。さまざまなユーザーが各種のワークロードを実行する仮想化されたマルチテナント・クラウド環境でのパフォーマンス分析は困難な作業です。その理由は次のとおりです。
- 仮想化ソフトウェアのタイプごとに、管理性を高めるための抽象化レイヤーが追加されます。抽象化レイヤーの追加によって仮想化されたリソースの管理は大幅に容易になりますが、過負荷状態の物理的なシステム・リソースを見つけることが難しくなります。
- 通常、Oracle Solarisゾーンごとにワークロードが異なります。このワークロードは、ディスクI/O、ネットワークI/O、CPU、メモリ、あるいはそれらの組合せの場合もあります。さらに、単一のOracle Solarisゾーンがシステム・リソース全体の過負荷状態の原因となる可能性もあります。
- 環境の観測は非常に困難で、環境をトップ・レベルから監視してすべての仮想インスタンス(非大域ゾーン)をリアルタイムで確認でき、さらに特定のリソースにドリルダウンできる必要があります。
Oracle Solaris 11を使用して仮想化されたパフォーマンス分析を実行するメリットは次のとおりです。
- 可観測性:Oracle Solaris大域ゾーンは、環境全体(同時にホストやVMを含む)を観測できない独自のハイパーバイザや最小限のオペレーティング・システムではなく、完全に機能するオペレーティング・システムです。大域ゾーンから、すべての非大域ゾーンのパフォーマンス・メトリックを確認できます。
- 統合:すべてのサブシステムが同じオペレーティング・システムの内部に組み込まれます。たとえば、ZFSファイル・システムとOracle Solaris Zones仮想化テクノロジーが一緒に統合されています。これは、多くのベンダーのテクノロジーが混在する状況よりも望ましいことです。テクノロジーが混在すると、異なるオペレーティング・システム(OS)サブシステム間で統合できなくなり、異なるすべてのOSサブシステムを同時に分析することが非常に困難になります。
- 仮想化の認識:Oracle Solarisの組込みコマンドは仮想化認識型であり、システム全体(Oracle Solaris大域ゾーン)のパフォーマンス統計を出力できます。これらのコマンドはすべてのリソース(Oracle Solaris非大域ゾーン)にドリルダウンできるのに加えて、パフォーマンス分析プロセス中に正確な結果を出力します。
この記事では、4つの例を詳しく見ていきながら、Oracle Solaris 11の組込みツールを使用してOracle Solaris Zonesによる仮想化環境を監視する方法について説明します。これらのツールには、CPU、メモリ、ディスク、ネットワークなどの特定のリソースにドリルダウンする機能があります。また、Oracle Solarisゾーンごとに統計を出力する機能や、実行中のアプリケーションに関する情報を出力する機能もあります。
この記事の例では、CPU、ディスク、ネットワークのワークロードを対象としたHadoop MapReduceベンチマークを使用します。Hadoopクラスタのセットアップは、"How to Set Up a Hadoop Cluster Using Oracle Solaris Zones"で説明しているセットアップに基づいています。この記事の例では、Hadoopクラスタのすべての構成要素は、Oracle Solaris Zones、ZFS、ネットワーク仮想化テクノロジーを使用してインストールされます。そのアーキテクチャを図1に示します。
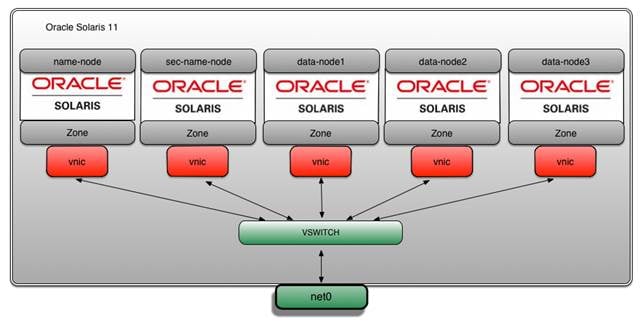
図1:アーキテクチャ
準備
最初に、zoneadmコマンドを使用して環境を確認します。
root@global_zone:~# zoneadm list -civ ID NAME STATUS PATH BRAND IP 0 global running / solaris shared 19 sec-name-node running /zones/sec-name-node solaris excl 23 data-node1 running /zones/data-node1 solaris excl 24 data-node3 running /zones/data-node3 solaris excl 25 data-node2 running /zones/data-node2 solaris excl 26 name-node running /zones/name-node solaris excl
見てのとおり、この環境には次の5つのOracle Solarisゾーンがあります。
name-nodesec-name-nodedata-node1data-node2data-node3
Oracle Solarisでのマルチスレッド認識を利用してシステムの使用状況を改善するために、Hadoopゾーンあたり25個のジョブ・スロット(合計75個)を有効化します。そのために、mapred-site.xmlに次のプロパティを追加します。
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>25</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>25</value>
</property>
ベンチマークを開始する前に、このHadoopクラスタの状態を確認します。
root@global_zone:~# zlogin -l hadoop name-node hadoop dfsadmin -report Oracle Corporation SunOS 5.11 11.1 December 2012 Configured Capacity:1445236931072 (1.31 TB) Present Capacity:1443007083849 (1.31 TB) DFS Remaining:1440410395136 (1.31 TB) DFS Used:2596688713 (2.42 GB) DFS Used%:0.18% Under replicated blocks:137 Blocks with corrupt replicas:0 Missing blocks:0 ------------------------------------------------- Datanodes available:3 (3 total, 0 dead)
3つのDataNodeが利用可能です。
注:DataNodeとは、Hadoop分散ファイル・システム(HDFS)でデータが格納されるノードのことです。DataNodeはスレーブとも呼ばれ、図2に示すTask Trackerプロセスを実行します。
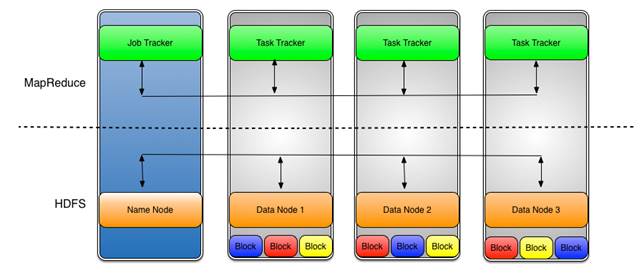
図2:DataNode
仮想化環境でのCPUワークロードの監視
あらゆるパフォーマンス分析におけるベスト・プラクティスは、どのリソースがもっとも負荷が高いかを確認するために実行環境を大局的に把握し、その後それぞれのリソースにドリルダウンすることです。表1に、この記事のCPUパフォーマンス分析で使用するコマンドの概要を示します。
表1:コマンドの概要| コマンド | 説明 |
|---|---|
psrinfo |
プロセッサ情報を表示する |
zonestat |
アクティブなゾーンの統計をレポートする |
mpstat |
プロセッサごとの統計またはプロセッサ・セットごとの統計をレポートする |
fsstat |
ファイル・システムの統計をレポートする |
vmstat |
仮想メモリの統計とCPUアクティビティをレポートする |
ps |
プロセスの統計をレポートする |
pginfo |
CPUトポロジを出力する |
pgstat |
プロセッサの使用統計をレポートする |
prstat |
アクティブなプロセスの統計をレポートする |
まず、物理的なリソース情報を取得します(リスト1を参照)。CPUはいくつあるでしょうか。
root@global_zone:~# psrinfo -pv
The physical processor has 16 cores and 128 virtual processors (0-127)
The core has 8 virtual processors (0-7)
The core has 8 virtual processors (8-15)
The core has 8 virtual processors (16-23)
The core has 8 virtual processors (24-31)
The core has 8 virtual processors (32-39)
The core has 8 virtual processors (40-47)
The core has 8 virtual processors (48-55)
The core has 8 virtual processors (56-63)
The core has 8 virtual processors (64-71)
The core has 8 virtual processors (72-79)
The core has 8 virtual processors (80-87)
The core has 8 virtual processors (88-95)
The core has 8 virtual processors (96-103)
The core has 8 virtual processors (104-111)
The core has 8 virtual processors (112-119)
The core has 8 virtual processors (120-127)
SPARC-T5 (chipid 0, clock 3600 MHz)
リスト1
リスト1では、オラクル製のSPARC T5プロセッサがあり、そのCPUの1つが割当て済みであることが分かります。このCPUには16個のコアと128個の仮想プロセッサ(コアあたり8個)があるため、最大128個のソフトウェア・スレッドを同時に実行できます。
注:psrinfo -pコマンドを使用すれば、物理的なCPUの数を把握できます。
パフォーマンス分析を開始する前に、それぞれのOracle Solarisゾーンのワークロード特性を理解し、CPU、メモリ、ディスクI/O、ネットワークI/Oのうち、どの制約を受けるかを判断する必要があります。そのために、Oracle Solaris 11のzonestat、mpstat、fsstatの各コマンドを使用します。次に、これらのコマンドの出力を使用して、この環境内で実行中のワークロードについて分析します。
環境に負荷をかけるために実行する第1のHadoopベンチマークは、Pi Estimatorです。Pi Estimatorは、モンテカルロ法により円周率の値を推定するMapReduceプログラムです。
この例では、128個のマップを使用し、各マップでは10億のサンプルを計算します(サンプルの総数は1,280億になります)。
注:CPUあたり1つのマップを実行します。
大域ゾーンから次のコマンドを実行して、Pi Estimatorプログラムを開始します。
root@global_zone:~# zlogin -l hadoop name-node hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi 128 1000000000
コマンドの意味は次のとおりです。
zlogin -l hadoop name-node:このコマンドをユーザーhadoopとして、name-nodeゾーンに対して実行することを指定するhadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi:Hadoopの.jarファイルを指定する128:マップ数を指定する1000000000:サンプル数を指定する
オプション:上のコマンドは、zloginコマンドを使用し、大域ゾーンに対して実行します。一方、次のようにname-nodeゾーンから直接コマンドを実行することもできます。
hadoop@name_node:$ hadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar pi 128 1000000000
hadoop job -listコマンドを使用して、MapReduceジョブを一覧表示できます。
まず、別のターミナル・ウィンドウを開き、リスト2に示すコマンドを実行します。
root@global_zone:~# zlogin -l hadoop name-node hadoop job -list Oracle Corporation SunOS 5.11 11.1 December 2012 1 jobs currently running JobId State StartTime UserName Priority SchedulingInfo job_201309081525_0135 1 1378711957491 hadoop NORMAL NA
リスト2
リスト2では、ジョブID(JobId)とその開始時刻(StartTime)を確認できます。
あるジョブの完全な説明(マップ/リデュース処理が完了した割合やすべてのジョブ・カウンタなど)については、次のコマンドを実行します。その際に、hadoop job -statusコマンドのパラメータとしてJobIdを指定します。
root@global_zone:~# zlogin -l hadoop name-node hadoop job -status job_201309081525_0135
このパフォーマンス分析で使用する1つ目のコマンドは、zonestatコマンドです。このコマンドを使用すれば、環境で実行中のすべてのOracle Solarisゾーンを監視して、CPU、メモリ、ネットワークの使用状況に関するリアルタイム統計を表示できます。
zonestatコマンドを10秒間隔で実行します(リスト3を参照)。
root@global_zone:~# zonestat 10 10
Interval:1, Duration:0:00:10
SUMMARY Cpus/Online:128/12 PhysMem:256G VirtMem:259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 118.10 92.2% 24.6G 9.62% 60.0G 23.0% 18.4E 100%
[system] 0.00 0.00% 9684M 3.69% 40.5G 15.5% - -
data-node3 42.13 32.9% 4897M 1.86% 6146M 2.30% 18.4E 100%
data-node1 41.49 32.4% 4891M 1.86% 6173M 2.31% 18.4E 100%
data-node2 33.97 26.5% 4851M 1.85% 6145M 2.30% 18.4E 100%
global 0.34 0.27% 283M 0.10% 420M 0.15% 2192 0.00%
name-node 0.15 0.11% 419M 0.15% 718M 0.26% 126 0.00%
sec-name-node 0.00 0.00% 205M 0.07% 363M 0.13% 0 0.00%
リスト3
リスト3のzonestatの出力より、Pi EstimatorプログラムがCPUの制約を受けるアプリケーションであることが分かります(%PART 92.2.0%)。
このzonestatコマンドが出力している情報は次のとおりです。
Zone列:ゾーン名
[total]:システム全体で使用されているリソースの総量[system]:カーネルによって使用されているか、特定のゾーンには関連付けられずに使用されているリソースの量
注:
zonestatを非大域ゾーン内から実行した場合は、この値はシステムとその他のすべてのゾーンによって消費されているリソースの集計となります。CPU:CPU情報
USED:使用されているCPUの数%PART:ゾーンがバインドされているプロセッサ・セットの計算能力に対するCPU使用率(%)
注:システム全体のプロセッサ情報を確認するには、
psrset -iコマンドを使用するか、/usr/dtrace/DTT/Binにあるcputypes.dというDTraceスクリプトを使用します。PhysMem:物理メモリ情報
USED:使用済みメモリ%USED:リソース総量に対する使用済みリソースの割合(%)
VirtMem:仮想メモリ情報
USED:使用済み仮想メモリ%USED:システム内の仮想メモリ総量に対する使用済みリソースの割合(%)
PhysNet:ネットワーク情報
PBYTE:物理帯域幅を消費する送受信済みバイト数%PUSH:利用可能な物理帯域幅の総量に対する送受信された総バイト数の割合(%)
zonestatコマンドは、特定の期間における使用状況の総計および最高値に関するレポートを出力できます。この情報は、ピーク時の使用状況を確認する場合に便利です。この情報は、現在のアクティビティと以前のアクティビティとの比較、および今後の拡張に向けたキャパシティ・プランニングで役立ちます。
たとえば、リスト4のコマンドは、10秒間隔で3分間サイレントに監視を行い、その後、使用状況の総計と最高値を示すレポートを生成します。
root@global_zone:~# zonestat -q -R total,high 10s 3m 3m
Report:Total Usage
Start:Wednesday, November 13, 2013 10:37:04 AM IST
End:Wednesday, November 13, 2013 10:40:04 AM IST
Intervals:18, Duration:0:03:00
SUMMARY Cpus/Online:128/12 PhysMem:256G VirtMem:259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 79.9 61.7% 29.5G 11.5% 61.7G 23.7% 7762 0.00%
[system] 3.63 2.83% 9538M 3.63% 37.7G 14.5% - -
data-node3 25.9 19.6% 557M 0.21% 5857M 2.20% 18.4E 100%
data-node2 24.81 19.3% 435M 0.16% 5715M 2.14% 18.4E 100%
data-node1 24.61 19.2% 552M 0.21% 5867M 2.20% 18.4E 100%
global 0.87 0.68% 6014M 2.29% 6134M 2.30% 908K 0.00%
name-node 0.06 0.04% 485M 0.18% 619M 0.23% 18.4E 100%
sec-name-node 0.00 0.00% 260M 0.09% 291M 0.10% 0 0.00%
Report:High Usage
Start:Wednesday, November 13, 2013 10:37:04 AM IST
End:Wednesday, November 13, 2013 10:40:04 AM IST
Intervals:18, Duration:0:03:00
SUMMARY Cpus/Online:128/12 PhysMem:256G VirtMem:259G
---CPU---- --PhysMem-- --VirtMem-- --PhysNet--
ZONE USED %PART USED %USED USED %USED PBYTE %PUSE
[total] 111.17 86.8% 31.5G 12.3% 63.8G 24.5% 892K 0.00%
[system] 23.65 18.4% 9643M 3.67% 37.8G 14.5% - -
data-node3 25.85 20.2% 557M 0.21% 976M 0.36% 18.4E 100%
data-node2 22.95 17.9% 435M 0.16% 534M 0.20% 18.4E 100%
data-node1 22.22 17.3% 552M 0.21% 774M 0.29% 18.4E 100%
global 2.87 2.24% 6014M 2.29% 6128M 2.30% 946K 0.00%
name-node 0.08 0.06% 485M 0.18% 619M 0.23% 18.4E 100%
sec-name-node 0.00 0.00% 260M 0.09% 291M 0.10% 0 0.00%
リスト4
リスト4の出力から分かることは次のとおりです。
- CPU使用率の平均は61.7%(
SUMMARY、%PART 61.7%) - CPU使用率の最高値は86.8%(
Report:High Usage、%PART 86.8%)
また、利用可能な各CPUに対してCPU使用率が均等に配分されているかを確認できます。リスト4より、使用されているCPU総数は111で、各DataNodeには22~26個のCPUが割り当てられていることが分かります。
また、zonestatコマンドは、長期間(数日、数週、数か月)のシステム使用状況の情報を収集する目的にも使用できます。たとえば、次のコマンドは、10秒間隔で24時間サイレントに監視を行い、1時間ごとの使用状況の総計と最高値のレポートを生成します。
root@global_zone:~# zonestat -q -R total,high 10s 24h 1h
利用可能な各CPUに対してCPU使用率が均等に配分されているかを示す便利なコマンドとして、ほかにmpstatコマンドがあります。
リスト5は、Oracle Solaris mpstat(1M)コマンドの出力です。1行につき1つの仮想CPUが示されています。
root@global_zone:~# mpstat 1 CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl 0 85 0 10183 683 59 931 40 269 464 2 1315 30 14 0 56 1 80 0 34872 484 9 1096 39 317 498 2 1437 34 14 0 51 2 72 0 15632 325 4 669 30 166 334 1 1321 37 9 0 54 3 42 0 13422 253 3 553 32 144 277 2 818 31 7 0 62 4 57 0 14009 351 5 736 43 204 352 2 936 28 8 0 64 5 67 0 10445 258 4 562 28 162 297 2 732 27 9 0 64 6 49 0 15770 322 5 660 36 187 304 2 332 32 7 0 60 7 44 0 5872 351 8 802 42 222 396 2 1077 30 9 0 61 8 34 0 12701 391 7 826 35 245 430 2 854 33 11 0 56 9 63 0 11926 578 7 1311 52 372 613 4 958 35 13 0 53 10 82 0 11602 423 7 930 43 222 432 3 991 32 10 0 58 11 24 0 14940 253 4 525 26 139 281 2 692 33 7 0 60 12 35 0 10450 285 3 571 17 141 307 2 713 30 8 0 62 13 46 0 27600 298 7 625 35 172 310 2 580 32 8 0 60 14 49 0 14039 371 5 770 30 212 377 2 726 28 9 0 63 15 73 0 10714 289 4 643 27 163 334 3 883 33 8 0 59
リスト5
リスト5に示すように、mpstatコマンドは次の情報をレポートします。
CPU列:論理CPU IDminf列:マイナー・フォルトの回数mjf列:メジャー・フォルトの回数xcal列:プロセッサ間のクロスコール数intr列:割込み回数ithr列:スレッドとして使用された割込み回数(低レベルIPL)csw列:コンテキスト・スイッチの回数(総数)icsw列:強制的なコンテキスト・スイッチの回数migr列:別のプロセッサへのスレッド移送回数smtx列:mutexロックでのスピン回数srw列:読取り/書込みロックでのスピン回数syscl列:システム・コール数usr列:CPUによって使用されたユーザー時間の割合(%)sys列:CPUによって使用されたシステム時間(カーネル)の割合(%)wt列:I/O待機時間(廃止予定のため、常にゼロ)idl列:アイドル時間の割合(%)
各CPUのビジー状態の程度をidlフィールドで確認できます。このフィールドは、アイドル時間の割合(%)を示します。また、dim_statツールを使用すれば、mpstatコマンドの出力を視覚化できます(図3を参照)。
図3:dim_statツールの出力
多くのCPUが搭載されたシステムでは、mpstatの出力に非常に時間がかかる場合があります。しかし、コアごとにCPU使用状況を監視することもできます(リスト6を参照)。
root@global_zone:~# mpstat -A core 10 COR minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl sze 3074 103 0 23654 1680 697 1264 644 277 502 10 11268 748 52 0 0 8 3078 95 0 32090 893 137 1228 635 281 439 8 10929 759 41 0 0 8 3082 94 0 31574 889 129 1245 629 308 560 9 12792 753 47 0 0 8 3086 111 0 20262 829 121 1200 615 277 512 7 12657 753 47 0 0 8 3090 155 0 16849 896 133 1276 646 281 567 9 12321 749 51 0 0 8 3094 123 0 24022 810 100 1210 617 283 512 8 12009 751 49 0 0 8 3098 101 0 25212 798 96 1186 594 286 577 6 14205 745 55 0 0 8 3102 111 0 25626 734 88 1091 555 230 489 10 11338 762 38 0 0 8 3106 126 0 31042 832 112 1206 614 281 513 11 11111 757 43 0 0 8 3110 126 0 33856 777 88 1167 596 245 596 10 12739 751 49 0 0 8 3114 136 0 21364 895 131 1280 646 273 586 7 13259 748 52 0 0 8 3118 128 0 28063 1021 111 1506 746 265 594 7 11178 752 48 0 0 8 3122 125 0 18047 918 124 1313 667 287 550 12 12720 749 51 0 0 8 3126 87 0 30336 898 130 1257 640 268 533 11 12930 747 53 0 0 8 3130 127 0 21213 944 138 1340 676 292 516 8 13842 748 52 0 0 8 3134 115 0 31696 767 103 1098 561 259 495 7 10162 755 45 0 0 8
リスト6
リスト6では、mpstatは各コアのCPUパフォーマンス統計を出力しており、SPARC T5 CPUのコア総数は16となっています。後ほど、各コアの監視方法と、浮動小数点パイプラインおよび整数パイプラインの観測方法について説明します。また、mpstatではソケットごと、あるいはプロセッサ・セットごとのパフォーマンス統計を出力でき、各コアのCPU数を出力できます(sze列)。その他の例についてはmpstat(1M)を参照してください。
このパフォーマンス分析で次に使用するコマンドはfsstatコマンドです。このコマンドはディスクI/Oの監視に便利です。このコマンドを使用して、ディスクごと、あるいはOracle SolarisゾーンごとのディスクI/Oアクティビティを監視できます。ここでは、このコマンドを使用して、Pi EstimatorがCPUの制約を受けるのに加えてディスクI/Oの制約も受けるかどうかを確認します。
たとえば、リスト7に示すコマンドを使用すれば、すべてのZFSファイル・システムへの書込みを10秒間隔で監視できます。
root@global_zone:~# fsstat -Z zfs 10 10
new name name attr attr lookup rddir read read write write
file remov chng get set ops ops ops bytes ops bytes
0 0 0 744 0 11.4K 0 6.01K 5.87M 0 0 zfs:global
0 0 0 151 0 3.27K 0 1.41K 1.94M 7 1.42K zfs:data-node1
0 0 0 359 0 8.72K 0 2.75K 3.95M 22 4.06K zfs:data-node2
0 0 0 413 0 9.03K 0 2.98K 4.22M 21 4.34K zfs:data-node3
0 0 0 14 0 51 0 0 0 0 0 zfs:name-node
0 0 0 14 0 51 0 0 0 0 0 zfs:sec-name-node
リスト7
デフォルトのレポートにはファイル・システムの一般的なアクティビティが示されます。リスト7に示すように、この出力では、類似した操作が次の一般的なカテゴリにまとめられます。
new file列:ファイル・システム・オブジェクト(ファイル、ディレクトリ、シンボリック・リンクなど)の作成操作の回数name remov列:名前の削除操作の回数name chng列:名前の変更操作の回数attr get列:オブジェクト属性の取得操作の回数attr set列:オブジェクト属性の変更操作の回数lookup ops列:オブジェクトのルックアップ操作の回数rddir ops列:ディレクトリ読取り操作の回数read ops列:データ読取り操作の回数read bytes列:データ読取り操作による送信済みバイト数write ops列:データ書込み操作の回数
リスト7のfsstatの出力より、読取り操作と書込み操作の回数を確認すると、ディスク使用率が非常に低いことが分かります。
zonestat、mpstat、fsstatの出力に従えば、Pi EstimatorプログラムはCPUの制約を受けるアプリケーションであるという結論に達します(この2つ目の例のディスクI/Oワークロードの把握方法については後ほど詳しく説明します)。
それでは、CPUパフォーマンス分析を続けましょう。次に検討する課題は、CPUアイドル時間が存在するかどうかです。
注:Pi Estimatorプログラムの実行が終了している場合は、再実行する必要があります。このプログラムの終了時には、次のようなジョブのサマリー情報が出力されます。
Job Finished in 309.819 seconds Estimated value of Pi is 3.14159266603125000000
リスト8に示すように、vmstatコマンドを使用してCPUアイドル時間が存在するかどうかを確認できます。
root@global_zone:~# vmstat 1 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id 8 0 0 213772168 245340872 770 5954 0 0 0 0 0 0 0 0 0 17732 161637 39181 93 7 0 12 0 0 213346168 244887200 134 2237 0 0 0 0 0 0 0 0 0 13689 140604 19640 96 4 0 17 0 0 212974464 244353760 124 1939 0 0 0 0 0 0 0 0 0 12079 130895 17225 96 4 0 29 0 0 212657512 243704448 118 2662 0 0 0 0 0 117 0 0 0 13804 131482 18530 95 5 0 41 0 0 210748016 241728920 202 2962 0 0 0 0 0 0 0 78 71 15214 122457 21418 96 4 0 32 0 0 209808688 240699416 80 2509 0 0 0 0 0 0 0 0 0 16524 146238 31628 97 3 0 36 0 0 209122192 239714912 13 1991 0 0 0 0 0 0 0 0 0 16743 132784 35315 97 3 0 22 0 0 207632424 238260184 0 2709 0 0 0 0 0 0 0 0 0 23357 146885 56380 96 4 0 13 0 0 206528520 236636888 0 1346 0 0 0 0 0 100 0 0 0 16161 74431 37560 98 2 0 1 0 0 206277936 236263016 0 1448 0 0 0 0 0 0 0 78 79 14499 59197 28766 96 1 3 0 0 0 206069656 235992504 0 1801 0 0 0 0 0 0 0 0 0 20478 66313 49291 90 2 8 18 0 0 205840984 235578720 0 957 0 0 0 0 0 0 0 0 0 15203 34428 28456 78 1 21 0 0 0 205762976 235447600 0 653 0 0 0 0 0 0 0 0 0 7977 8926 7977 62 0 38 0 0 0 205762976 235443400 910 1353 0 0 0 0 0 137 0 0 0 22505 14974 41402 59 3 39
リスト8
リスト8では、id列にCPUアイドル時間が示されます。id列の値が0の場合、システムのCPUは100%のビジー状態です。
次の課題は、利用可能なCPUを待機しているスレッドがあるかどうかです。これは実行キュー待機時間と呼ばれるもので、r列で容易に追跡できます。この列には、実行キュー内のカーネル・スレッド数が出力されます。実行キュー待機時間は、prstat -Lmコマンドを使用してLAT列の値を調べることで追跡することもできます。
また、prstatコマンドを使用すれば、CPUサイクルがユーザー・モードとシステム(カーネル)モードのどちらで消費されているかを確認できます。
root@global_zone:~# prstat -ZmL
Total:310 processes, 8269 lwps, load averages:47.63, 48.79, 36.98
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID
19338 hadoop 100 0.0 0.0 0.0 0.0 0.0 0.0 0.3 0 73 0 0 java/2
19329 hadoop 100 0.0 0.0 0.0 0.0 0.0 0.0 0.4 0 86 0 0 java/2
19519 hadoop 84 15 0.1 0.0 0.2 0.0 0.0 0.8 56 153 29K 0 java/2
19503 hadoop 88 11 0.1 0.0 0.3 0.1 0.0 1.0 52 168 23K 3 java/2
19536 hadoop 81 18 0.1 0.0 0.4 0.0 0.0 1.1 83 268 32K 0 java/2
19495 hadoop 89 9.6 0.1 0.0 0.3 0.7 0.0 0.7 51 163 21K 2 java/2
19523 hadoop 82 16 0.1 0.0 0.6 0.7 0.0 0.5 87 214 31K 0 java/2
19259 hadoop 97 0.0 0.0 0.0 0.0 2.9 0.0 0.1 4 36 9 1 java/2
19555 hadoop 73 24 0.2 0.0 1.9 0.0 0.1 0.9 207 207 35K 0 java/2
19263 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.3 6 66 13 2 java/2
19258 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.3 6 120 15 2 java/2
19285 hadoop 97 0.0 0.0 0.0 0.0 2.8 0.0 0.4 7 89 13 2 java/2
19331 hadoop 97 0.0 0.0 0.0 0.0 3.0 0.0 0.2 5 65 13 2 java/2
19272 hadoop 97 0.0 0.0 0.0 0.0 2.9 0.0 0.3 6 65 13 2 java/2
19313 hadoop 97 0.0 0.0 0.0 0.0 3.1 0.0 0.1 6 68 11 2 java/2
ZONEID NLWP SWAP RSS MEMORY TIME CPU ZONE
12 1722 5073M 3638M 28% 0:54:41 31% data-node1
13 1846 6131M 4757M 37% 0:50:54 39% data-node2
14 1426 4446M 3452M 28% 0:51:54 28% data-node3
0 1726 973M 603M 0.7% 0:45:37 0.1% global
15 446 883M 558M 5.6% 0:04:32 1.9% name-node
Total:295 processes, 7398 lwps, load averages:50.67, 49.39, 37.25
リスト9
リスト9に示すように、prstatの出力には次の列が表示されます。
USR列:プロセスがユーザー・モードで使用された時間の割合(%)SYS列:プロセスがシステム・モードで使用された時間の割合(%)TRP列:プロセスがシステム・トラップの処理で使用された時間の割合(%)TFL列:プロセスがテキスト・ページ・フォルトの処理で使用された時間の割合(%)DFL列:プロセスがデータ・ページ・フォルトの処理で使用された時間の割合(%)LCK列:プロセスがユーザー・ロックの待機で使用した時間の割合(%)SLP列:プロセスが休止中であった時間の割合(%)LAT列:プロセスがCPUの待機で使用した時間の割合(%)VCX列:自発的なコンテキスト・スイッチの回数ICX列:強制的なコンテキスト・スイッチの回数SCL列:システム・コール数SIG列:受信済みシグナル数
リスト9のprstatの出力によると、システムのCPUサイクルはユーザー・モード(USR)で消費されています。その他のprstatの例については、http://www.scalingbits.com/performance/prstatを参照してください。
仮想化認識型の便利なコマンドとして、psもあります。-Zオプションを使用すると、ZONE列ヘッダーが加わり、その下にプロセスが関連付けられているゾーンの名前が出力されます。
注:このコマンドは、自身が非大域ゾーン内部で実行中であることを認識します。そのため、このコマンドを非大域ゾーンから実行した場合に他のユーザー・プロセスを参照することはできません。
ps -efZコマンドを使用すると、現在実行中のすべてのプロセス(e)と、関連付けられたゾーン名(Z)が完全な形式で(f)表示されます。たとえば、現在実行中のすべてのHadoopプロセスを出力するには、リスト10のコマンドを使用します。
root@global_zone:~# ps -efZ | grep hadoop ZONE UID PID PPID C STIME TTY TIME CMD data-nod hadoop 14024 11795 0 07:38:19 ? 0:20 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 14026 11798 0 07:38:19 ? 0:19 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- name-nod hadoop 11621 1 0 07:20:12 ? 0:59 /usr/java/bin/java -Dproc_jobtracker -Xmx1000m -Dcom.sun.management.jmxremote - name-nod hadoop 11263 1 0 07:20:07 ? 0:27 /usr/java/bin/java -Dproc_namenode -Xmx1000m -Dcom.sun.management.jmxremote -Dc data-nod hadoop 13912 11798 0 07:38:18 ? 0:23 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 11730 1 1 07:20:14 ? 2:58 /usr/java/bin/java -Dproc_tasktracker -Xmx1000m -Dhadoop.log.dir=/var/log/hadoo data-nod hadoop 11458 1 0 07:20:09 ? 0:18 /usr/java/bin/java -Dproc_datanode -Xmx1000m -server -Dcom.sun.management.jmxre data-nod hadoop 13957 11798 1 07:38:18 ? 0:23 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13953 11795 0 7:38:18 ? 0:24 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13815 11730 0 7:38:15 ? 0:22 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop- data-nod hadoop 13965 11795 0 7:38:18 ? 0:22 /usr/jdk/instances/jdk1.6.0/jre/bin/java -Djava.library.path=/usr/local/hadoop-
リスト10
注:ZONE列の幅には8文字の上限があります。
1つのSPARC T5 CPUには16個のコアと128個のスレッドがあり、各コアには2つの整数パイプラインと1つの浮動小数点パイプラインがあります。SPARC T5 CPUアーキテクチャについて詳しくは、このホワイト・ペーパーを参照してください。
注:pginfo -p -Tコマンドを使用すれば、CPUトポロジを確認できます。詳しくは、https://blogs.oracle.com/d/entry/pginfo_pgstatを参照してください。
パイプラインの負荷状況を把握する必要がある場合に、この詳細レベルの情報を表示できるツールがpgstatです。
たとえば、リスト11のコマンドを使用して、pgstatレポートを3分間実行します。
root@global_zone:~# pgstat -A 60 3
SUMMARY:UTILIZATION OVER 180 SECONDS
------HARDWARE------ ------SOFTWARE------
PG RELATIONSHIP MIN AVG MAX MIN AVG MAX CPUS
0 System - - - 1.8% 79.1% 100.0% 0-127
3 Data_Pipe_to_memory - - - 1.8% 79.1% 100.0% 0-127
4 CPU_PM_Active_Power_Domain - - - 1.5% 78.4% 100.0% 0-15
2 Floating_Point_Unit 0.0% 8.8% 12.7% 1.8% 78.1% 100.0% 0-7
1 Integer_Pipeline 0.7% 91.2% 98.7% 1.8% 78.1% 100.0% 0-7
6 Floating_Point_Unit 0.0% 7.6% 12.7% 1.2% 78.8% 100.0% 8-15
5 Integer_Pipeline 1.0% 90.5% 98.9% 1.2% 78.8% 100.0% 8-15
9 CPU_PM_Active_Power_Domain - - - 2.4% 78.3% 100.0% 16-31
8 Floating_Point_Unit 0.0% 5.8% 12.7% 1.5% 82.0% 100.0% 16-23
7 Integer_Pipeline 0.9% 86.5% 99.2% 1.5% 82.0% 100.0% 16-23
11 Floating_Point_Unit 0.0% 5.5% 12.5% 3.2% 74.5% 100.0% 24-31
10 Integer_Pipeline 1.4% 85.4% 98.2% 3.2% 74.5% 100.0% 24-31
14 CPU_PM_Active_Power_Domain - - - 1.6% 78.8% 100.0% 32-47
13 Floating_Point_Unit 0.0% 7.9% 12.7% 2.5% 79.7% 100.0% 32-39
12 Integer_Pipeline 5.1% 90.5% 99.2% 2.5% 79.7% 100.0% 32-39
16 Floating_Point_Unit 0.0% 7.3% 12.6% 0.5% 77.7% 100.0% 40-47
15 Integer_Pipeline 1.0% 87.3% 98.5% 0.5% 77.7% 100.0% 40-47
19 CPU_PM_Active_Power_Domain - - - 1.2% 81.0% 100.0% 48-63
18 Floating_Point_Unit 0.0% 8.8% 12.8% 1.0% 84.7% 100.0% 48-55
17 Integer_Pipeline 0.7% 95.2% 99.5% 1.0% 84.7% 100.0% 48-55
21 Floating_Point_Unit 0.0% 7.7% 12.7% 1.4% 77.2% 100.0% 56-63
20 Integer_Pipeline 1.2% 90.4% 98.9% 1.4% 77.2% 100.0% 56-63
24 CPU_PM_Active_Power_Domain - - - 2.6% 78.9% 100.0% 64-79
23 Floating_Point_Unit 0.0% 7.1% 12.7% 4.7% 79.8% 100.0% 64-71
22 Integer_Pipeline 9.2% 88.4% 98.9% 4.7% 79.8% 100.0% 64-71
26 Floating_Point_Unit 0.0% 6.2% 12.6% 0.6% 77.9% 100.0% 72-79
25 Integer_Pipeline 0.8% 84.7% 98.4% 0.6% 77.9% 100.0% 72-79
...
リスト11
リスト11では、各パイプラインがどの程度のビジー状態であったかを確認でき(Integer_Pipeline、Floating_Point_Unit)、このシステムが最大で90%を超える整数パイプラインの使用率に達していることも分かります。さらに、メモリ帯域幅(Data_Pipe_to_memory)も確認できます。
次に、この負荷の原因となっているアプリケーションの観測を行います。たとえば、CPUがビジー状態になる原因となっているコード・パスはどれでしょうか。あるいは、このシステム負荷の原因となっているのは各ゾーンのどのプロセスでしょうか。
次の例では、あるOracle Solarisゾーンにドリルダウンして、この負荷の原因となっているアプリケーションまたはプロセスを把握します。
まずはdata-node1ゾーンにログインします。
root@global_zone:~# zlogin data-node1
注:data-node1ゾーンにログインできたかどうかは、zonenameコマンドを使用して確認できます。このコマンドは、現在のゾーン名を出力します。
root@data-node1:~# zonename data-node1
リスト12に示すように、ゾーン内部でprstatコマンドを使用して、システムの負荷の原因となっているプロセスを表示できます。
root@data-node1:~# prstat -mLc PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 22866 root 24 74 1.6 0.0 0.0 0.0 0.0 0.0 122 122 85K 0 prstat/1 22715 hadoop 80 3.3 0.1 0.0 0.0 4.0 0.1 12 45 201 4K 4 java/2 22704 hadoop 80 3.3 0.2 0.0 0.0 6.2 0.4 10 61 277 4K 10 java/2 22721 hadoop 79 3.4 0.2 0.0 0.0 3.5 0.3 14 52 290 4K 5 java/2 22740 hadoop 78 3.5 0.2 0.0 0.0 3.2 0.1 15 67 400 4K 9 java/2 22710 hadoop 78 3.2 0.2 0.0 0.0 5.9 0.1 13 53 313 4K 5 java/2 22691 hadoop 78 3.0 0.2 0.0 0.0 4.6 0.2 14 49 349 3K 5 java/2 22734 hadoop 77 3.5 0.2 0.0 0.0 3.5 0.2 15 55 373 4K 7 java/2 22746 hadoop 77 3.6 0.2 0.0 0.0 4.1 0.2 15 71 356 4K 9 java/2 22752 hadoop 76 3.6 0.2 0.0 0.0 5.6 0.2 14 76 323 4K 10 java/2 22767 hadoop 76 3.9 0.1 0.0 0.0 3.4 0.4 16 61 374 4K 9 java/2 22698 hadoop 76 3.3 0.2 0.0 0.0 4.2 0.0 16 65 324 4K 11 java/2 22792 hadoop 75 4.3 0.1 0.0 0.0 4.3 0.3 16 63 271 4K 6 java/2 22760 hadoop 76 3.7 0.1 0.0 0.0 6.0 0.9 14 67 280 4K 11 java/2 22685 hadoop 76 2.9 0.1 0.0 0.0 4.5 0.0 16 43 259 3K 4 java/2 Total:58 processes, 2011 lwps, load averages:58.00, 55.80, 41.70
リスト12
リスト12では、hadoopプロセスがシステムの負荷の原因となっています。
注:リスト12では、ローカル・ゾーン内部からprstatコマンドを実行して、ゾーンごとのパフォーマンス統計を確認できることが分かりました。一方、このコマンドを大域ゾーンから実行すれば、システム・ビュー全体を把握できます。これは仮想化認識型コマンドの一例です。仮想化認識型コマンドは自身が非大域ゾーンの内部で実行されていることを認識するため、その他のユーザー・プロセスを参照することはできません。
仮想化環境でのディスクI/Oアクティビティの監視
この2つ目の例では、Hadoopの組込みベンチマークを使用してディスクI/Oアクティビティの観測と監視を行います。表2に、この記事のディスクI/Oアクティビティの監視に使用するコマンドの概要を示します。
表2:コマンドの概要| コマンド | 概要 |
|---|---|
fsstat |
Oracle SolarisゾーンごとのディスクI/Oワークロードを表示する |
zpool iostat |
指定したプールのI/O統計を表示する |
iostat |
ディスクI/O統計をレポートする |
iotop |
ゾーンごとのプロセス別の上位ディスクI/Oイベントを表示する |
rwtop |
プロセス別の上位の読取り/書込みバイト数を表示する |
iopattern |
すべてのディスクに関するI/Oアクセス・パターンの詳細を表示する |
ZFSおよびディスクのレイアウトを図4に示します。
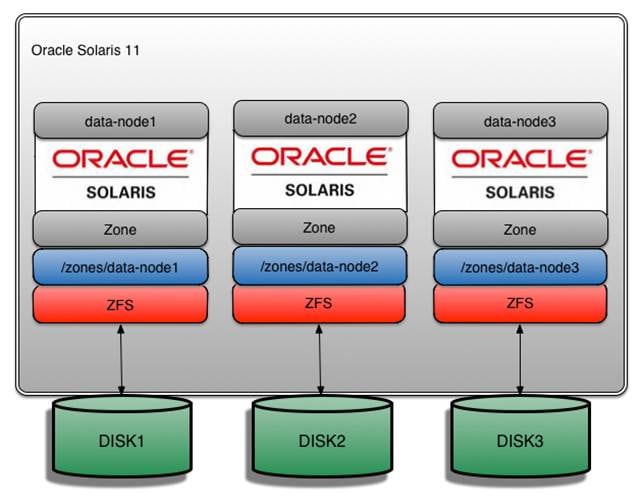
図4:ディスクのレイアウト
まずは、システム内のハード・ディスク数を出力します。
root@global_zone:~# format < /dev/null
Searching for disks...done
AVAILABLE DISK SELECTIONS:
0. c0t5001517803D013B3d0 <ATA-INTEL SSDSA2BZ30-0362 cyl 35769 alt 2 hd 128 sec 128> solaris
/scsi_vhci/disk@g5001517803d013b3
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD0/disk
1. c0t5000CCA0160D3264d0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca0160d3264
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD1/disk
2. c0t5000CCA01612A4F0d0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca01612a4f0
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD2/disk
3. c0t5000CCA016295ABCd0 <HITACHI-H109060SESUN600G-A31A-558.91GB>
/scsi_vhci/disk@g5000cca016295abc
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD3/disk
4. c0t5000CCA016359F94d0 <HITACHI-H109060SESUN600G-A31A cyl 64986 alt 2 hd 27 sec 668>
/scsi_vhci/disk@g5000cca016359f94
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD4/disk
5. c0t5000CCA0162A6E0Cd0 <HITACHI-H109060SESUN600G-A31A cyl 64986 alt 2 hd 27 sec 668> solaris
/scsi_vhci/disk@g5000cca0162a6e0c
/dev/chassis/SPARC_T5-2.AK00104209//SYS/SASBP/HDD5/disk
Specify disk (enter its number):
ディスクI/Oパフォーマンス分析では、次のような課題に取り組みます。
- I/Oのターゲットとなっているデバイスはどれか。
- 読込み/書込みの内訳はどうなっているか。また、ディスクのI/Oアクセス・パターンはどうなっているか。たとえば、ランダムな性質のイベントと順次的な性質のイベントの割合はそれぞれどの程度か。
- デバイス(ハード・ディスク)ごとの、ディスクI/Oの処理速度はどの程度か。
- ディスクがビジー状態になる原因となっているコード・パス(アプリケーション)はどれか。
Hadoopには、MapReduceシステム全体のベンチマークを測定できる複数のベンチマークが付属しています。MapReduceシステムは、現実的なワークロードを発生させる目的で使用できます。
このベンチマークを使用して、次の3つの主なタスクを実行します。
- ランダムなデータの生成
- そのランダムなデータに対するソートの実行
- 結果(データがソートされていること)の検証
まずは、RandomWriterを使用してランダムなデータを生成します。このツールは、ノードあたり10個のマップを使用してMapReduceジョブを実行します。各マップはキーと異なるサイズの値で構成される約10GBのランダムなバイナリ・データ(合計100GB)を生成します。表3に、構成用の変数を示します。
注:レプリケーション係数が3であるため、書き込まれる実際のデータ量は3倍になります。
表3:構成用の変数| 名前 | デフォルト値 | 説明 |
|---|---|---|
test.randomwriter.maps_per_host |
10 | ホストあたりのマップ数 |
test.randomwrite.bytes_per_map |
1073741824 | マップあたりの書込み済みバイト数 |
test.randomwrite.min_key |
10 | キーの最小サイズ(バイト単位) |
test.randomwrite.max_key |
1000 | キーの最大サイズ(バイト単位) |
test.randomwrite.min_value |
0 | 最小値 |
test.randomwrite.max_value |
20000 | 最大値 |
注:これらの値は、Hadoop構成ファイルのプロパティを設定することで自由に変更できます。詳しくは、RandomWriterを参照してください。
まず、コマンドの可読性を高めるためにHADOOP_INSTALL環境変数を編集します。
root@global_zone:~# export HADOOP_INSTALL=/usr/local/hadoop
オプション:.profileファイル内に次の環境変数を追加して、構成を永続化することもできます。
export HADOOP_INSTALL=/usr/local/hadoop
ベンチマークを実行できるように、ベンチマーク・ファイルのアクセス権を変更します。
root@global_zone:~# chmod +x /usr/local/hadoop/hadoop-examples-1.2.0.jar
次に、リスト13のコマンドを使用してランダムなデータを生成します。
root@global_zone:~# zlogin -l hadoop name-node hadoop jar $HADOOP_INSTALL/hadoop-examples-1.2.0.jar randomwriter random-data
リスト13
コマンドの意味は次のとおりです。
zlogin -l hadoop name-node:このコマンドをユーザーhadoopとして、name-nodeゾーンに対して実行することを指定するhadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar randomwriter:Hadoopの.jarファイルを指定するrandom-data:出力ディレクトリを指定する
ランダムなデータは、デフォルトで/user/hadoop/random-dataディレクトリ内に書き込まれます。
次のコマンドを使用して、生成されたファイルを確認できます。
root@global_zone:~# zlogin -l hadoop data-node1 hadoop dfs -ls /user/hadoop/random-data Oracle Corporation SunOS 5.11 11.1 December 2012 Found 32 items -rw-r--r-- 3 hadoop supergroup 0 2013-10-07 08:26 /user/hadoop/random-data/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2013-10-07 08:22 /user/hadoop/random-data/_logs -rw-r--r-- 3 hadoop supergroup 1077300619 2013-10-07 08:22 /user/hadoop/random-data/part-00000 -rw-r--r-- 3 hadoop supergroup 1077301332 2013-10-07 08:25 /user/hadoop/random-data/part-00001 -rw-r--r-- 3 hadoop supergroup 1077276968 2013-10-07 08:23 /user/hadoop/random-data/part-00002 -rw-r--r-- 3 hadoop supergroup 1077293150 2013-10-07 08:23 /user/hadoop/random-data/part-00003 -rw-r--r-- 3 hadoop supergroup 1077280173 2013-10-07 08:25 /user/hadoop/random-data/part-00004 -rw-r--r-- 3 hadoop supergroup 1077289790 2013-10-07 08:23 /user/hadoop/random-data/part-00005 -rw-r--r-- 3 hadoop supergroup 1077302329 2013-10-07 08:25 /user/hadoop/random-data/part-00006 -rw-r--r-- 3 hadoop supergroup 1077299723 2013-10-07 08:23 /user/hadoop/random-data/part-00007 -rw-r--r-- 3 hadoop supergroup 1077288561 2013-10-07 08:23 /user/hadoop/random-data/part-00008 -rw-r--r-- 3 hadoop supergroup 1077279776 2013-10-07 08:25
ディスクI/Oパフォーマンスの観測で使用する1つ目のコマンドはfsstatコマンドです。このコマンドを使用すれば、Oracle SolarisゾーンあたりのディスクI/Oワークロードを分析し、各ファイル・システムのファイル・システム統計を確認できます。
リスト14に、tmpfsとzfsの各ファイル・システムについて、システム上の各ゾーンに関するゾーンごとの統計とシステム全体の集計を示します。
root@global_zone:~# fsstat -A -Z tmpfs zfs 10 10
new name name attr attr lookup rddir read read write write
file remov chng get set ops ops ops bytes ops bytes
126 0 128 1.57K 512 15.9K 0 0 0 127 15.9K tmpfs
0 0 0 0 0 0 0 0 0 0 0 tmpfs:global
20 0 20 260 80 2.55K 0 0 0 20 2.50K tmpfs:data-node2
52 0 52 612 208 6.36K 0 0 0 52 6.50K tmpfs:data-node3
0 0 0 40 0 70 0 0 0 0 0 tmpfs:name-node
0 0 0 40 0 70 0 0 0 0 0 tmpfs:sec-name-node
54 0 56 656 224 6.83K 0 0 0 55 6.88K tmpfs:data-node1
156 0 162 1.78K 0 22.9K 0 28 3.16K 175K 5.45G zfs
0 0 0 0 0 3 0 2 599 0 0 zfs:global
52 0 54 511 0 4.52K 0 0 0 58.3K 1.82G zfs:data-node2
52 0 54 512 0 8.46K 0 12 1.28K 58.3K 1.82G zfs:data-node3
0 0 0 140 0 514 0 1 4 106 19.2K zfs:name-node
0 0 0 140 0 510 0 0 0 0 0 zfs:sec-name-node
52 0 54 518 0 8.95K 0 13 1.29K 58.3K 1.81G zfs:data-node1
リスト14
リスト14のコマンド出力より、tmpfsとzfsの各ファイル・システムに書き込まれたデータ量(read bytesとwrite bytes)が分かります。
次に、測定の対象を特定のOracle Solarisゾーンに絞り込みます。
次の例では、data-node1、data-node2、data-node3の各ゾーンに関するゾーンごとの統計と、tmpfsとzfsの各ファイル・システムに関するシステム全体の集計を示します。
root@global_zone:~# fsstat -A -Z -z data-node1 -z data-node2 -z data-node3 tmpfs zfs 10 10 new name name attr attr lookup rddir read read write write file remov chng get set ops ops ops bytes ops bytes 140 13 116 3.16K 512 42.7K 16 242 926K 250 342K tmpfs 20 0 20 266 80 2.56K 0 0 0 20 2.50K tmpfs:data-node2 57 5 46 1.35K 204 19.2K 8 115 436K 113 170K tmpfs:data-node3 63 8 50 1.47K 228 20.8K 8 127 491K 117 170K tmpfs:data-node1 154 0 94 7.74K 0 85.6K 40 20.9K 29.8M 127K 3.96G zfs 52 0 32 445 0 4.25K 0 0 0 43.0K 1.34G zfs:data-node2 52 0 32 2.98K 0 31.0K 20 6.63K 10.9M 43.1K 1.34G zfs:data-node3 50 0 30 3.04K 0 32.9K 20 7.21K 11.9M 41.0K 1.28G zfs:data-node1
MapReduceベンチマークの次の手順は、前の手順で生成したランダムなデータをソートするソート・プログラムを実行することです。リスト15のコマンドを実行します。
root@global_zone:~# zlogin -l hadoop name-node hadoop jar $HADOOP_INSTALL/hadoop-examples-1.2.0.jar sort random-data sorted-data Oracle Corporation SunOS 5.11 11.1 December 2012 Running on 3 nodes to sort from hdfs://name-node/user/hadoop/random-data into hdfs://name-node/user/hadoop/sorted-data with 67 reduces. Job started:Mon Oct 07 08:34:16 IST 2013 13/10/07 08:34:16 INFO mapred.FileInputFormat:Total input paths to process :30 13/10/07 08:34:17 INFO mapred.JobClient:Running job: job_201310062308_0015 13/10/07 08:34:18 INFO mapred.JobClient:map 0% reduce 0%
リスト15
コマンドの意味は次のとおりです。
zlogin -l hadoop name-node:このコマンドをユーザーhadoopとして、name-nodeゾーンに対して実行することを指定するhadoop jar /usr/local/hadoop/hadoop-examples-1.2.0.jar sort:Hadoopの.jarファイルを指定するrandom-data:入力ディレクトリを指定するsorted-data:出力ディレクトリを指定する
次に、ドリルダウンして個々のディスクの読取り/書込み操作を観測します。
まず、リスト16のコマンドを使用してZFSプール名を取得します。
root@global_zone:~# zpool list NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT data-node1-pool 556G 56.7G 499G 10% 1.00x ONLINE - data-node2-pool 556G 56.3G 500G 10% 1.00x ONLINE - data-node3-pool 556G 56.4G 500G 10% 1.00x ONLINE - rpool 278G 21.7G 256G 7% 1.00x ONLINE -
リスト16
リスト16では、表4に示す4つのZFS zpoolがあります。
表4:zpoolの概要| プール名 | ゾーン名 | マウント・ポイント |
|---|---|---|
rpool |
name-nodesec-name-node |
/zones/name-node/zones/sec-name-node |
data-node1-pool |
data-node1 |
/zones/data-node1 |
data-node2-pool |
data-node2 |
/zones/data-node2 |
data-node3-pool |
data-node3 |
/zones/data-node3 |
注:Hadoopのベスト・プラクティスは、DataNodeごとに異なるハード・ディスクを使用することです。そのため、I/O分散状況を改善するために、図4に示すように各DataNodeゾーンに独自のハード・ディスクを割り当てます。
次のコマンドを使用すれば、すべてのZFS zpoolを同時に監視できます。
root@global_zone:~# zpool iostat -v 10
capacity operations bandwidth
pool alloc free read write read write
------------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.1G 525G 2 9 124K 6.49M
c0t5000CCA0160D3264d0 31.1G 525G 2 9 124K 6.49M
------------------------- ----- ----- ----- ----- ----- -----
data-node2-pool 31.0G 525G 2 10 91.0K 6.50M
c0t5000CCA01612A4F0d0 31.0G 525G 2 10 91.0K 6.50M
------------------------- ----- ----- ----- ----- ----- -----
data-node3-pool 31.0G 525G 1 9 103K 6.49M
c0t5000CCA016295ABCd0 31.0G 525G 1 9 103K 6.49M
------------------------- ----- ----- ----- ----- ----- -----
rpool 22.0G 256G 10 7 95.0K 64.1K
c0t5001517803D013B3d0s0 22.0G 256G 10 7 95.0K 64.1K
------------------------- ----- ----- ----- ----- ----- -----
また、ドリルダウンも可能なため、data-node1ゾーンに関連付けられたディスクを監視してみましょう。
ZFSプール名をパラメータとして使用して、個々のディスクの読取り/書込み操作を観測できます(リスト17を参照)。
root@global_zone:~# zpool iostat -v data-node1-pool 10
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 55.8G 500G 1 8 403K 2.57M
c0t5000CCA0160D3264d0 55.8G 500G 1 8 403K 2.57M
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 50.0G 506G 157 18 25.7M 181K
c0t5000CCA0160D3264d0 50.0G 506G 157 18 25.7M 181K
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.0G 525G 0 21 612 72.7K
c0t5000CCA0160D3264d0 31.0G 525G 0 21 612 72.7K
----------------------- ----- ----- ----- ----- ----- -----
capacity operations bandwidth
pool alloc free read write read write
----------------------- ----- ----- ----- ----- ----- -----
data-node1-pool 31.0G 525G 36 17 19.4M 135K
c0t5000CCA0160D3264d0 31.0G 525G 36 17 19.4M 135K
----------------------- ----- ----- ----- ----- ----- -----
リスト17
リスト17では、c0t5000CCA0160D3264d0ディスク(data-node1-pool zpoolに関連付けられたディスク)の読取り/書込みデータ量を確認できます。そのためには、bandwidth readとbandwidth writeに示されている値を参照します。
また、iostatコマンドを使用して、デバイスごとのディスクI/O操作の処理速度を確認できます(リスト18を参照)。
root@global_zone:~# iostat -xnz 5 10
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
1.6 10.8 47.9 3765.1 0.0 0.2 0.1 16.4 0 2 c0t5001517803D013B3d0
1.2 7.1 365.9 2238.4 0.0 0.2 0.1 19.6 0 2 c0t5000CCA0160D3264d0
0.9 8.5 279.4 2237.7 0.0 0.2 0.1 16.7 0 2 c0t5000CCA01612A4F0d0
1.1 8.8 335.9 2237.2 0.0 0.2 0.1 16.3 0 2 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 16.6 0.0 50.1 0.0 0.0 0.0 0.3 0 0 c0t5001517803D013B3d0
31.0 15.6 13346.7 44.4 0.0 0.8 0.0 17.1 0 12 c0t5000CCA0160D3264d0
0.0 15.0 0.0 47.0 0.0 0.0 0.0 1.8 0 1 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 28.6 0.0 249.4 0.0 0.0 0.0 0.4 0 0 c0t5001517803D013B3d0
0.0 15.4 0.0 43.1 0.0 0.0 0.0 1.2 0 0 c0t5000CCA0160D3264d0
88.4 27.6 40257.3 238.9 0.0 2.5 0.0 21.9 1 32 c0t5000CCA016295ABCd0
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
0.0 15.4 0.0 38.3 0.0 0.0 0.0 0.2 0 0 c0t5001517803D013B3d0
0.0 26.4 0.0 205.7 0.0 0.1 0.0 2.6 0 1 c0t5000CCA0160D3264d0
0.0 14.2 0.0 38.1 0.0 0.0 0.0 1.4 0 0 c0t5000CCA016295ABCd0
リスト18
リスト18では、複数のディスクが1秒あたりの読取り(r/sec)において中程度の速度を維持し、スループットに13346KB/秒から40257KB/秒までの幅があり(kr/sec)、待機時間は最大で約22ミリ秒です(asvc_t)。
オプション:-Mオプションを使用すれば、KB/秒ではなくMB/秒単位でデータ・スループットを表示できます。
注:非大域ゾーン内部で実行した場合のiostatは、システム内のすべてのディスクに関するディスクI/O統計を出力します。ゾーンがアイドル状態なのにディスク・アクティビティが確認できることは不可解に思われるかもしれません。iostatコマンドは、自身が非大域ゾーンの内部で実行されているかどうかが分からないという意味で、仮想化認識型ではありません。
他の便利なツールとして、iotopというDTraceスクリプトがあります。このツールは、Oracle Solarisゾーンごとにプロセス別の上位のディスクI/Oイベントを表示します(リスト19を参照)。
root@global_zone:~# /usr/dtrace/DTT/iotop -Z 10 10
Tracing...Please wait.
2013 Oct 7 08:40:19, load:24.38, disk_r: 0 KB, disk_w: 1886 KB
ZONE PID PPID CMD DEVICE MAJ MIN D BYTES
0 717 0 zpool-data-node3 sd6 73 48 W 347648
0 5 0 zpool-rpool sd3 73 24 W 417280
0 896 0 zpool-data-node1 sd4 73 32 W 1195520
リスト19
リスト19では、ゾーンID(ZONE)、プロセスID(PID)、操作のタイプ(読取りまたは書込み、D)、操作の総サイズ(BYTES)を確認できます。
注:ゾーンIDを取得するために、zoneadm list -vコマンドを使用できます。
読取り/書込み回数については、アプリケーション・レベルで測定できます(リスト20を参照)。これは、システム・コールへの読取り/書込み回数と一致します。
root@global_zone:~# /usr/dtrace/DTT/rwtop -Z 10 10
Tracing...Please wait.
2013 Oct 7 8:41:41, load:21.88, app_r:219241 KB, app_w:306995 KB
ZONE PID PPID CMD D BYTES
3 3792 13851 java R 2588146
3 3725 13851 java R 2637274
6 4263 13929 java R 2662831
3 5382 13851 java R 2684596
6 3951 13929 java R 2697760
6 5508 13929 java R 2725159
6 4403 13929 java R 2760624
6 3482 13929 java R 2804553
6 5721 13929 java R 2809765
6 3494 13929 java R 2940105
3 3847 13851 java R 2961552
6 4509 13929 java R 2994121
6 4109 13929 java R 3060994
3 3660 13851 java R 3099585
6 3749 13929 java R 3161943
3 3435 13851 java R 3531230
6 3663 13929 java R 3730160
3 5101 13851 java R 3968720
6 4823 13929 java R 4030110
3 3905 13851 java R 4037610
3 4654 13851 java R 4106273
3 5230 13851 java R 4608408
3 4654 13851 java W 22666584
3 5101 13851 java W 23468253
6 5258 13929 java W 28658892
3 13851 1 java R 50977972
3 13851 1 java W 50999762
6 13929 1 java W 59310428
6 13929 1 java R 59433776
3 5382 13851 java W 88006519
3 5230 13851 java W 88185430
リスト20
リスト20では、rwtopコマンドにより、ディスクI/Oの観点からもっともビジー状態のプロセスがソートされています。また、このコマンドはゾーン名(ZONE)、プロセス名(CMD)、読取り操作か書込み操作か(D)、読取り済みまたは書込み済みバイト数(BYTES)を出力します。
次に、DTraceのiopatternスクリプトを使用してディスクI/Oパターンを分析し、ディスクI/Oパターンがランダムか順次的かを把握できます(リスト21を参照)。
root@global_zone:~# /usr/dtrace/DTT/iopattern %RAN %SEQ COUNT MIN MAX AVG KR KW 69 31 236 1024 1048576 448830 103441 0 75 25 577 512 1048576 327938 184306 479 92 8 598 512 1048576 198293 114275 1525 74 26 379 512 1048576 330296 121954 294 66 34 281 1024 1048576 500550 137358 0 80 20 346 1024 1048576 332114 112218 0 81 19 444 512 1048576 290734 124694 1366 65 35 337 512 1048576 490375 161139 244 75 25 704 512 1048576 353086 241105 1642 75 25 444 1024 1048576 386634 167642 0 77 23 666 1024 1048576 397105 258274 0 77 23 853 512 1048576 385908 320740 725 77 23 525 512 1048576 345048 175352 1553 68 32 253 512 1048576 508290 125355 228 64 36 237 1024 1048576 501317 116027 0
リスト21
リスト21の出力には次の項目が含まれています。
%RAN列:ランダムな性質のイベントの割合(%)%SEQ列:順次的な性質のイベントの割合(%)COUNT列:I/Oイベント数MIN列:I/Oイベントの最小サイズMAX列:I/Oイベントの最大サイズAVG列:I/Oイベントの平均サイズKR列:サンプル実行中の読取り済みキロバイト数の合計KW列:サンプル実行中の書込み済みキロバイト数の合計
このスクリプトの出力より、I/Oワークロードは主にランダム読取りであることが分かります(%RAN、KR)。
注:大部分のI/Oワークロードがランダムな場合は、フラッシュ・デバイスを利用することでI/Oパフォーマンスを改善できます。
仮想化環境でのメモリ使用状況の監視
次の例では、メモリ・サブシステムを監視します。表5に、この記事のメモリ使用状況の監視に使用するコマンドの概要を示します。
表5:コマンドの概要| コマンド | 説明 |
|---|---|
vmstat |
利用可能な空きメモリをレポートする |
prstat |
アクティブなプロセスの統計をレポートする |
zonestat |
アクティブなゾーンの統計をレポートする |
zvmstat |
ゾーンごとのvmstatスタイルの情報を表示する |
まず、システムに搭載されている物理メモリ容量を出力します。
root@global_zone:~# prtconf -v | grep Mem Memory size:262144 Megabytes
このシステムには256GBのメモリが搭載されています。
次に、システム・メモリの現在の割当て方法に関する詳細情報を取得します(リスト22を参照)。
root@global_zone:~# echo ::memstat | mdb -k Page Summary Pages MB %Tot ------------ ---------------- ---------------- ---- Kernel 1473974 11515 4% ZFS File Data 4990336 38987 15% Anon 2223697 17372 7% Exec and libs 3342 26 0% Page cache 5244141 40969 16% Free (cachelist) 27122 211 0% Free (freelist) 19591820 153061 58% Total 33554432 262144
リスト22
リスト22に示されるカテゴリの意味は次のとおりです。
Kernel:ページング不可能なカーネル割当てに使用される総メモリ量。カーネルが使用しているメモリ量と同一ZFS File Data:ZFS適応型置換キャッシュ(ARC)によって使用される総メモリ量Anon:匿名メモリ量。ユーザー・プロセスのヒープ、スタック、Copy-On-Writeページ、共有メモリ・マッピングなどが含まれるExec and libs:ユーザーのバイナリおよび共有ライブラリに使用される総メモリ量Page cache:マッピングされていないページ・キャッシュ量、つまりキャッシュ・リストにないページ・キャッシュの量。/tmp内のファイルもこのカテゴリに含まれるFree (cachelist):空きリスト上のページ・キャッシュ量。空きリストにはマッピングされていないファイル・ページが含まれ、通常はファイル・システム・キャッシュの大部分が当てはまるFree (freelist):実際に空いているメモリ量。ファイルやプロセスに関連付けられていないメモリ
システムで現在利用可能な空きメモリ量を把握するために、リスト23に示すようにvmstatコマンドを使用して、1行目以外の行のfree列(単位はKB)の値を確認できます(vmstatの1行目はブート時からのサマリー情報です)。
root@global_zone:~# vmstat 10 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s3 s4 s5 s6 in sy cs us sy id 1 0 0 202844144 233325872 315 1311 0 0 0 0 1 15 19 19 18 23352 32919 46222 3 4 93 4 0 0 110774160 142093304 347 3681 0 0 0 0 0 0 27 15 18 72275 48754 148884 1 11 88 5 0 0 110862440 142055728 347 3671 0 0 0 0 0 19 15 22 16 72286 48292 148838 1 11 88 3 0 0 111113056 142043608 331 3525 0 0 0 0 0 0 20 29 20 70099 49362 143970 1 11 88
リスト23
リスト23より、システムには約138GBの空きメモリがあることが分かります。これは、ファイルやプロセスに関連付けられていないメモリです。
システムの物理メモリが不足しているかどうかを判断するには、リスト23に示したvmstat出力のsr列を確認します。このsrはscan rate(スキャン率)の意味です。Oracle Solarisでは、メモリが不足している状況で、最近アクセスされていないメモリ・ページをスキャンして、空きリストに移動する処理を開始します。Oracle Solarisでは、srの値がゼロ以外の場合、物理メモリが不足していることを表しています。
vmstat -pを使用して、ページイン、ページアウト、ページ解放の各アクティビティを観測することもできます(リスト24を参照)。
root@global_zone:~# vmstat -p 10
memory page executable anonymous filesystem
swap free re mf fr de sr epi epo epf api apo apf fpi fpo fpf
201865936 232351696 315 1332 0 0 1 0 0 0 0 0 0 0 0 0
111431576 141932424 264 2779 0 0 0 0 0 0 0 0 0 0 0 0
111179136 141752728 243 2580 0 0 0 0 0 0 0 0 0 0 0 0
110802088 141459648 247 2656 0 0 0 0 0 0 0 0 0 0 0 0
リスト24
リスト24のvmstat出力にあるとおり、メモリには次の3つのタイプがあります。
- 実行可能メモリ(
epi、epo、epf):プログラムおよびライブラリ・テキストのために使用されるメモリ・ページ - 匿名(
api、apo、apf):ファイルに関連付けられていないメモリ・ページ。匿名メモリはプロセスのヒープやスタックなどに使用される。たとえば、プロセス・ページのスワップインまたはスワップアウトの実行中は、api列とapo列の数値が大きくなる - ファイル・システム(
fpi、fpo、fpf):ファイルI/Oのために使用されるメモリ・ページ
Oracle Solarisのアプリケーション・メモリ管理について詳しくは、"Solaris Application Memory Management"を参照してください。
システムや仮想マシン(非大域ゾーン)のプロセス統計を参照するために使用できる3つ目のコマンドは、prstatコマンドです(リスト25を参照)。
root@global_zone:~# prstat -ZmLc
PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP
20025 hadoop 293M 253M cpu60 59 0 0:00:49 12% java/68
20739 hadoop 285M 241M sleep 59 0 0:00:49 10% java/68
17206 hadoop 285M 237M sleep 59 0 0:01:07 10% java/68
17782 hadoop 281M 229M sleep 59 0 0:00:57 7.4% java/67
17356 hadoop 289M 241M sleep 59 0 0:01:04 7.0% java/68
11621 hadoop 166M 126M sleep 59 0 0:02:32 5.9% java/90
20924 hadoop 289M 237M sleep 59 0 0:00:49 5.3% java/68
17134 hadoop 289M 237M sleep 59 0 0:01:04 5.1% java/67
17498 hadoop 297M 257M sleep 59 0 0:00:57 4.8% java/68
17298 hadoop 297M 253M sleep 59 0 0:01:05 4.6% java/68
17940 hadoop 297M 249M sleep 59 0 0:00:52 4.3% java/68
18474 hadoop 289M 237M sleep 59 0 0:00:49 3.9% java/67
19600 hadoop 297M 253M sleep 59 0 0:00:49 3.8% java/68
20617 hadoop 297M 249M sleep 59 0 0:00:49 3.7% java/67
17432 hadoop 297M 249M sleep 59 0 0:01:03 3.6% java/68
ZONEID NPROC SWAP RSS MEMORY TIME CPU ZONE
4 74 7246M 6133M 2.3% 2:31:34 43% data-node2
3 53 7442M 6248M 2.4% 2:23:01 30% data-node1
5 52 7108M 6001M 2.3% 2:27:40 22% data-node3
2 32 675M 468M 0.1% 0:04:36 4.0% name-node
0 82 870M 414M 0.1% 1:19:20 1.0% global
Total:322 processes, 8024 lwps, load averages:15.54, 18.25, 20.09
リスト25
リスト25のprstat出力から分かるとおり、Oracle Solarisゾーンごとに次の情報が表示されます。
SWAP列:各ゾーンの仮想メモリの総サイズRSS列:ゾーンの物理メモリ使用サイズの合計(メイン・メモリの使用状況)MEMORY列:システム全体のリソースに対する消費されたメイン・メモリの割合(%)CPU列:システム全体のリソースに対する消費されたCPUの割合(%)ZONE列:各ゾーンの名前
ゾーンごとのメモリ統計の詳細を確認するには、zonestatコマンドを使用できます。たとえば、zonestat -rコマンドを使用してメモリ使用状況を分析できます(リスト26を参照)。
root@global_zone:~# zonestat -r memory 10
Collecting data for first interval...
Interval:1, Duration:0:00:10
PHYSICAL-MEMORY SYSTEM MEMORY
mem_default 256G
ZONE USED %USED CAP %CAP
[total] 87.0G 34.0% - -
[system] 68.9G 26.9% - -
data-node2 5956M 2.27% - -
data-node1 5942M 2.26% - -
data-node3 5702M 2.17% - -
name-node 444M 0.16% - -
global 285M 0.10% - -
sec-name-node 219M 0.08% - -
VIRTUAL-MEMORY SYSTEM MEMORY
vm_default 259G
ZONE USED %USED CAP %CAP
[total] 122G 47.0% - -
[system] 42.3G 16.2% - -
data-node2 27.1G 10.4% - -
data-node3 25.8G 9.96% - -
data-node1 25.4G 9.78% - -
name-node 762M 0.28% - -
sec-name-node 416M 0.15% - -
global 388M 0.14% - -
LOCKED-MEMORY SYSTEM MEMORY
mem_default 256G
ZONE USED %USED CAP %CAP
[total] 15.7G 6.16% - -
[system] 15.7G 6.16% - -
data-node1 0 0.00% - -
data-node2 0 0.00% - -
data-node3 0 0.00% - -
global 0 0.00% - -
name-node 0 0.00% - -
sec-name-node 0 0.00% - -
リスト26
リスト26の出力より、物理メモリ(PHYSICAL-MEMORY)、物理メモリの抽象表現である仮想メモリ(VIRTUAL-MEMORY)、ロックされたメモリ(LOCKED-MEMORY)のそれぞれについて、メモリ使用量が分かります。たとえば、特権プロセスは仮想メモリをロックできます。このロックされたメモリはページアウトされません。仮想化環境でメモリ使用状況を監視するために使用できる別のコマンドとして、zvmstatコマンドがあります。このコマンドは、各ゾーンについてvmstatの結果を出力します(リスト27を参照)。
root@global_zone:~# /usr/dtrace/DTT/Bin/zvmstat 10
ZONE re mf fr sr epi epo epf api apo apf fpi fpo fpf
global 273 218 0 0 0 0 0 0 0 0 0 0 0
sec-name-node 0 0 0 0 0 0 0 0 0 0 0 0 0
name-nodenode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node1ode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node2ode 0 0 0 0 0 0 0 0 0 0 0 0 0
data-node3ode 0 0 0 0 0 0 0 0 0 0 0 0 0
リスト27
リスト27に示される項目の意味は次のとおりです。
Zone列:ゾーン名re列:ページ回収の回数mf列:マイナー・フォルトの回数fr列:解放されたページの数sr列:スキャン率epi列:ページインされた実行可能ページの数vepo列:ページアウトされた実行可能ページの数epf列:解放された実行可能ページの数api列:ページインされた匿名ページの数apo列:ページアウトされた匿名ページの数apf列:解放された匿名ページの数fpi列:ページインされたファイル・システム・ページの数fpo列:ページアウトされたファイル・システム・ページの数fpf列:解放されたファイル・システム・ページの数
このメモリ測定の対象を絞り込んで、特定のゾーンをチェックできます。たとえば、name-nodeゾーンのメモリ使用状況を表示できます。
root@global_zone:~# prstat -mLz name-node
それでは、メモリ統計を確認するためにdata-node1ゾーンにドリルダウンしましょう。どのプロセスが物理メモリを専有しているかを確認するには、特定のOracle Solarisゾーンをどのように調査すればよいでしょうか。
まずは、そのゾーンにログインします。
root@global_zone:~# zlogin data-node1
次に、リスト28に示すコマンドを使用して、そのゾーンの物理メモリ使用サイズ(RSS)に従ってプロセスをソートします。RSSは、RAMに保持されているプロセス・メモリ部分です。メモリをもっとも多く消費しているプロセスが一番上に表示されます。
root@data-node1:~# prstat -s rss PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 10236 hadoop 179M 151M cpu20 52 0 0:05:26 8.5% java/132 11365 hadoop 193M 140M sleep 59 0 0:00:55 3.0% java/63 11381 hadoop 189M 136M cpu29 20 0 0:00:55 5.5% java/63 11346 hadoop 189M 120M cpu44 10 0 0:00:58 5.2% java/63 10648 hadoop 204M 120M sleep 59 0 0:02:09 0.1% java/151 11355 hadoop 165M 112M cpu8 50 0 0:00:56 6.1% java/63 11319 hadoop 165M 112M sleep 59 0 0:00:56 1.3% java/63 11337 hadoop 165M 112M cpu30 50 0 0:00:52 4.2% java/63 11327 hadoop 165M 112M cpu40 20 0 0:00:57 3.0% java/63 11332 hadoop 165M 112M cpu122 20 0 0:00:57 3.2% java/63 11323 hadoop 161M 108M sleep 10 0 0:00:56 5.2% java/63 11374 hadoop 149M 96M cpu88 10 0 0:00:55 3.2% java/63 7109 root 18M 18M sleep 59 0 0:00:11 0.0% svc.configd/17 7073 root 35M 17M sleep 59 0 0:00:05 0.0% svc.startd/14 9392 root 22M 16M sleep 59 0 0:00:00 0.0% fmd/11 Total:43 processes, 1047 lwps, load averages:31.82, 8.25, 3.02
リスト28
リスト28より、hadoopプロセスがもっとも多くのRSSメモリを使用しています。
仮想化環境でのネットワーク使用状況の監視
この最後の例では、ネットワークのパフォーマンスを監視します。表6に、この記事のネットワークのパフォーマンスの監視に使用するコマンドの概要を示します。
表6:コマンドの概要| コマンド | 説明 |
|---|---|
dladm |
データリンクを管理する |
dlstat |
データリンクの統計をレポートする |
zonestat |
アクティブなゾーンの統計をレポートする |
flowadm |
帯域幅リソース制御を管理する |
flowstat |
フローの統計をレポートする |
Hadoopクラスタでは、ほとんどのネットワーク・トラフィックはDataNode間のHDFSデータ・レプリケーション向けのトラフィックです。
これから検討する課題は次のとおりです。
- ネットワーク・トラフィック量がもっとも多いゾーンともっとも少ないゾーンはどれか。
- 現在処理しているネットワーク接続数の観点からもっともビジー状態にあるゾーンはどれか。
- Oracle Solarisゾーン、物理ネットワーク・カード、仮想ネットワーク・インタフェース・カード(VNIC)などの特定のネットワーク・リソースを監視するにはどうすればよいか。
まず、dladmコマンドを使用して物理ネットワーク・カード数を表示して、現在のネットワーク設定を再確認します。
root@global_zone:~# dladm show-phys LINK MEDIA STATE SPEED DUPLEX DEVICE net0 Ethernet up 1000 full ixgbe0 net2 Ethernet unknown 0 unknown ixgbe2 net1 Ethernet unknown 0 unknown ixgbe1 net3 Ethernet unknown 0 unknown ixgbe3 net4 Ethernet up 10 full usbecm0
次に、dladmコマンドを使用してVNIC情報を出力します(リスト29を参照)。
root@global_zone:~# dladm show-vnic LINK OVER SPEED MACADDRESS MACADDRTYPE VID name_node1 net0 1000 2:8:20:d4:31:b3 random 0 name-node/name_node1 net0 1000 2:8:20:d4:31:b3 random 0 secondary_name1 net0 1000 2:8:20:41:78:4b random 0 sec-name-node/secondary_name1 net0 1000 2:8:20:41:78:4b random 0 data_node1 net0 1000 2:8:20:f:3f:f7 random 0 data-node1/data_node1 net0 1000 2:8:20:f:3f:f7 random 0 data_node2 net0 1000 2:8:20:d0:38:ea random 0 data-node2/data_node2 net0 1000 2:8:20:d0:38:ea random 0 data_node3 net0 1000 2:8:20:54:da:7b random 0 data-node3/data_node3 net0 1000 2:8:20:54:da:7b random 0 sec-name-node/net0 net0 1000 2:8:20:da:2e:5b random 0 name-node/net0 net0 1000 2:8:20:30:cc:45 random 0 data-node1/net0 net0 1000 2:8:20:8b:7b:f6 random 0 data-node2/net0 net0 1000 2:8:20:6a:3f:38 random 0 data-node3/net0 net0 1000 2:8:20:5d:7:8e random 0
リスト29
リスト29に示すように、dladmは、関連付けられた物理インタフェース(OVER)、速度(SPEED)、MACアドレス(MACADDRESS)、VLAN ID(VID)を出力します。
見てのとおり、各ゾーンに1つずつ、5つのVNICがあります(図5を参照)。
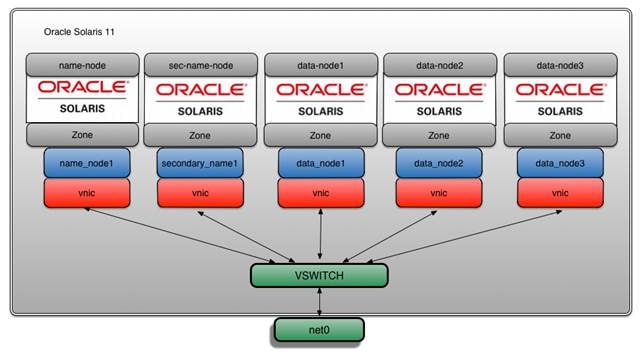
図5:VNIC
zonestatコマンドを-rオプション、-xオプションとともに使用して詳細なネットワーク情報を表示し、測定対象を特定のOracle Solarisゾーンに絞り込むことができます。たとえば、リスト30に示すように、3つのDataNodeゾーン(data-node1、data-node2、data-node3)のネットワーク・トラフィックを監視できます。
root@global_zone:~# zonestat -z data-node1 -z data-node2 -z data-node3 -r network -x 10
Collecting data for first interval...
Interval:1, Duration:0:00:10
NETWORK-DEVICE SPEED STATE TYPE
net0 1000mbps up phys
ZONE LINK TOBYTE MAXBW %MAXBW PRBYTE %PRBYTE POBYTE %POBYTE
[total] net0 269M - - 198 0.00% 18.4E 100%
global net0 2642 13474770085G - 198 0.00% 284 0.00%
data-node1 data-node1/net0 93.6M - - 0 0.00% 18.4E 100%
data-node3 data-node3/net0 91.3M - - 0 0.00% 18.4E 100%
data-node2 data-node2/net0 84.4M - - 0 0.00% 18.4E 100%
name-node name-node/net0 304K - - 0 0.00% 18.4E 100%
data-node3 data_node3 2340 - - 0 0.00% 0 0.00%
sec-name-node sec-name-node/net0 2340 - - 0 0.00% 0 0.00%
data-node2 data_node2 2280 - - 0 0.00% 0 0.00%
name-node name_node1 2280 - - 0 0.00% 0 0.00%
data-node1 data_node1 2220 - - 0 0.00% 0 0.00%
sec-name-node secondary_name1 2220 - - 0 0.00% 0 0.00%
リスト30
リスト30のコマンド出力には次の情報が含まれています。
- データリンク名(
LINK) - データリンクまたは仮想リンクにより送受信されたバイト数(
TOBYTE) - データリンクに構成されている最大帯域幅(
MAXBW) - 構成済みの最大帯域幅に対する送受信済みバイト数の合計の割合(%)(
%MAXBW) - 物理帯域幅を消費した受信済みバイト数(
PRBYTE) - 利用可能な物理帯域幅に対する、
PRBYTEの受信に使用された帯域幅の割合(%)(%PRBYE) - 物理帯域幅を消費した送信済みバイト数(
POBYTE) - 利用可能な物理帯域幅に対する、
POBYTEの送信に使用された帯域幅の割合(%)(%POBYE)
dlstatコマンドを使用して、3つのDataNodeに関連付けられた3つのVNICを監視できます(リスト31を参照)。
root@global_zone:~# dlstat -z data-node1,data-node2,data-node3 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
data-node1/data_node1 25.89K 1.57M 0 0
data-node2/data_node2 25.89K 1.57M 0 0
data-node3/data_node3 25.89K 1.57M 0 0
data-node1/net0 49.32M 54.99G 15.24M 52.59G
data-node2/net0 49.88M 55.80G 15.66M 54.16G
data-node3/net0 49.29M 54.60G 14.98M 52.95G
data-node1/data_node1 27 1.62K 0 0
data-node2/data_node2 27 1.62K 0 0
data-node3/data_node3 27 1.62K 0 0
data-node1/net0 50.69K 55.93M 16.06K 56.24M
data-node2/net0 49.20K 56.13M 16.32K 50.86M
data-node3/net0 46.87K 51.50M 13.90K 50.45M
リスト31
リスト31に示すように、dlstatコマンドは次の情報を表示します。
- インバウンド・パケット数(
IPKTS) - 受信済みバイト数(
RBYTES) - アウトバウンド・パケット数(
OPKTS) - 送信済みバイト数(
OBYTES)
特定のネットワーク・リソースにドリルダウンして、たとえば、物理ネットワーク・インタフェース(net0)を監視できます。
root@global_zone:~# dlstat net0 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
net0 39.41K 2.63M 8.16K 1.44M
net0 45 2.74K 1 198
net0 43 2.61K 1 150
net0 41 2.47K 1 150
^C
注:dlstatコマンドを停止するには、[Ctrl]キーを押しながら[c]キーを押します。
また、data-node1ゾーンに関連付けられたVNICのみを監視することもできます。
root@global_zone:~# dlstat name_node1 -i 10
LINK IPKTS RBYTES OPKTS OBYTES
data_node1 26.30K 1.59M 0 0
data_node1 42 2.70K 0 0
data_node1 43 2.58K 0 0
data_node1 31 1.86K 0 0
^C
注:dlstatは、非大域ゾーンから実行した場合には、そのゾーン内にあるリンクに関する統計のみを表示します。非大域ゾーンから他のゾーンのリンクを参照することはできません。
データセットの検証
仮想化環境でのディスクI/Oアクティビティの監視の項で説明したように、MapReduceベンチマークは3つのフェーズで構成されます。MapReduceベンチマークの最後の手順は、データがソートされたかどうかの検証です。
まず、.jarファイルを実行するためにファイルのアクセス権を変更します。
root@global_zone:~# chmod +x /usr/local/hadoop/hadoop-test-1.2.0.jar
次に、ソート済みのデータが正しいかどうかを検証するために、testmapredsortプログラムを実行します。このプログラムは、ソートされていないデータとソート済みのデータに対して一連のチェックを実行します。
それでは、ソート済みのデータが本当にソートされているかどうかを、次のコマンドを実行して判定しましょう。
root@global_zone:~# zlogin -l hadoop name-node hadoop jar /usr/local/hadoop/hadoop-test-1.2.0.jar testmapredsort -sortInput random-data -sortOutput sorted-data
コマンドの意味は次のとおりです。
zlogin -l hadoop name-node:このコマンドをユーザーhadoopとして、name-nodeゾーンに対して実行することを指定するhadoop jar /usr/local/hadoop/hadoop-test-1.2.0.jar testmapredsort:Hadoopの.jarファイルを指定する-sortInput random-data:ランダムなデータの入力ディレクトリを指定する-sortOutput sorted-data:ソート済みデータの出力ディレクトリを指定する
データがソート済みとして検証された場合は、次のメッセージが表示されます。
SUCCESS!Validated the MapReduce framework's 'sort' successfully.
特定のTCPまたはUDPネットワーク・ポートにおける2つのシステム間のネットワーク・トラフィックの監視
特定のTCPポートまたはUDPポートにおけるネットワーク・トラフィックを監視することもできます。この方法は、2つのHadoopクラスタ間のデータ・レプリケーションの進捗状況を監視する場合に便利です。たとえば、図6に示すように、異なるデータセンターにあるHadoopクラスタAからHadoopクラスタBへとレプリケーションされているデータを監視できます。
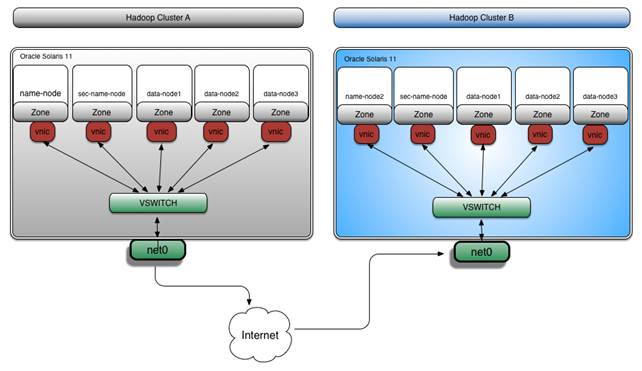
図6:Hadoopクラスタ間のデータのレプリケーション
Hadoopクラスタ間でデータをレプリケーションするために、distcpコマンドを使用できます。このコマンドは、Hadoopクラスタ間でデータをコピーするためのHadoopの組込みコマンドです。
root@global_zone:~# zlogin -l hadoop name-node hadoop distcp "hdfs://name-node:8020/benchmarks hdfs://name-node2:8020/backup"
注:name-nodeは1つ目のクラスタ上にあるNameNodeのホスト名で、name-node2は2つ目のクラスタ上にあるNameNodeのホスト名です。
これらのクラスタ間で、distcpが使用する特定のTCPポート(8020)上のネットワーク・トラフィックを監視する場合は、フローを使用できます。
フローとは、Oracle Solaris 11の新しいネットワーク仮想化アーキテクチャに組み込まれた、洗練されたサービス品質(QoS)メカニズムです。フローを使用すれば、特定のネットワーク・インタフェース上の特定のネットワーク・ポートについて、ネットワーク帯域幅の測定やネットワーク帯域幅に制限を設けることができます。さらに、フローの作成、変更、削除は、大域ゾーンでも非大域ゾーンでも実行できます。
次の例では、name_node1 VNIC上のTCP 8020ネットワーク・ポートに関連付けられるフローを設定します。
まずは、name-nodeゾーンにログインします。
root@global_zone:~# zlogin name-node
次に、name_node1 VNIC上にフローを作成します。
root@name-node:~# flowadm add-flow -l name_node1 -a transport=TCP,local_port=8020 distcp-flow
注:フローを有効化または無効化するために、ゾーンを再起動する必要はありません。これは、本番システムでネットワークのパフォーマンス問題をデバッグする必要がある場合に非常に便利です。
フローが作成されていることを検証します(リスト32を参照)。
root@name_node:~# flowadm show-flow FLOW LINK IPADDR PROTO LPORT RPORT DSFLD distcp-flow name_node1 -- tcp 8020 -- -
リスト32
リスト32では、関連付けられているVNIC(name_node1)とTCPポート番号(8020)に対してdistcp-flowフローが作成されています。
name_nodeゾーンでは、flowstat(1M)コマンドを使用できます。このコマンドは、ユーザー定義のフローに関する実行時統計をレポートします。受信側の統計のみ、または送信側の統計のみをレポートすることもできます。さらに、指定したリンク上のすべてのフローに関する統計や、特定のフローに関する統計を表示することもできます。
TCPポート8020を監視しているdistcp-flowフローの帯域幅をレポートするには、リスト33に示すコマンドを使用します。
root@name_node:~# flowstat -i 1 FLOW IPKTS RBYTES IDROPS OPKTS OBYTES ODROPS distcp-flow 24.72M 37.17G 0 3.09M 204.08M 0 distcp-flow 749.28K 1.13G 0 93.73K 6.19M 0 distcp-flow 783.68K 1.18G 0 98.03K 6.47M 0 distcp-flow 668.83K 1.01G 0 83.66K 5.52M 0 distcp-flow 783.87K 1.18G 0 98.07K 6.47M 0 distcp-flow 775.34K 1.17G 0 96.98K 6.40M 0 distcp-flow 777.15K 1.17G 0 97.21K 6.42M 0 ^C
リスト33
注:flowstatコマンドを停止するには、[Ctrl]キーを押しながら[c]キーを押します。
リスト33から分かるように、このflowstatコマンドにより、TCPポート8020のネットワーク統計が表示されます。また、name_node1ネットワーク・インタフェース上でフローを有効化しても、ネットワークのパフォーマンスは低下していません。
オプション:ネットワーク測定の終了後、フローを削除できます。
root@name_node:~# flowadm remove-flow distcp-flow
次に、フローが削除されたことを確認します。
root@name_node:~# flowadm show-flow
注:フローを削除するためにゾーンを再起動する必要はありません。これは、本番環境で非常に便利です。
ネットワークのパフォーマンス監視に関するその他の例については、"Oracle Solaris 11のツールを使用した高度なネットワーク監視"を参照してください。
クリーンアップ・タスク
(オプション)ベンチマークを終了したら、次のコマンドを使用して、生成されたすべてのファイルをHDFSから削除できます。
root@global_zone:~# zlogin -l hadoop name-node hadoop dfs -rmr hdfs://name-node/user/hadoop/random-data root@global_zone:~# zlogin -l hadoop name-node hadoop dfs -rmr hdfs://name-node/user/hadoop/sorted-data
結論
この記事では、Oracle Solaris 11の新しいパフォーマンス分析ツールを利用して、Hadoopクラスタをホストする仮想化環境の観察や監視を行う方法について説明しました。
参考資料
- How to Control Your Application's Network Bandwidth
- Oracle Solaris 11.1 の管理: Oracle Solaris ゾーン、Oracle Solaris 10 ゾーン、およびリソース管理
- How to Build Native Hadoop Libraries for Oracle Solaris 11
また、同著者による次の記事も参照してください。
- Oracle Solarisを使用してHadoop Clusterを設定する方法
- Oracle Solaris 11のツールを使用した高度なネットワーク監視
- How to Set Up a MongoDB NoSQL Cluster Using Oracle Solaris Zones
- How to Set Up a Hadoop Cluster Using Oracle Solaris Zones
- How to Migrate Oracle Database from Oracle Solaris 8 to Oracle Solaris 11
- Oracle VM Server for SPARCのライブ・マイグレーション機能を利用したアプリケーション可用性の向上:Oracle Databaseの例
- How Traffix Systems Optimized Its LTE Diameter Load Balancing and Routing Solutions Using Oracle Hardware and Software
- Orgadのブログ:The Art of Virtualization:Cloud Computing and Virtualization Use Cases and Tutorials
Oracle Solaris 11のその他の参考資料:
- ダウンロード:Oracle Solaris 11
- アクセス:Oracle Solaris 11の製品ドキュメント
- アクセス:Oracle Solaris 11に関するすべてのHow-To記事
- 学習:Oracle Solaris 11のトレーニングとサポート
- 参考:公式Oracle Solarisブログ
- Oracle Solarisのヒントと技:The ObservatoryブログとOTN Garageブログ
- Oracle Solarisのフォロー:FacebookとTwitter
著者について
Orgad Kimchiはオラクル(以前のSun Microsystems)のISV Engineeringチームに所属するPrincipal Software Engineerです。仮想化テクノロジー、ビッグ・データ・テクノロジー、クラウド・コンピューティング・テクノロジーの専門家として6年間従事しています。
| リビジョン1.0、2013年12月16日 |
false