 Articles
Server and Storage Development
Articles
Server and Storage Development
マルチスレッド・プログラムのメモリ割当てによるパフォーマンスへの影響について
Rickey C. Weisner著、2012年3月
新型のマルチプロセッサ、マルチコア、マルチスレッド・ハードウェアでアプリケーションのスケーラビリティがない場合、メモリ・アロケータのロック競合の問題が発生している可能性があります。 問題を特定し、より適したアロケータを選択するためのツールを紹介します。
はじめに
新しいサーバーの本番稼働が今まさに始まりました。 このサーバーは複数のソケット、数十のコア、数百の仮想CPUで構成されています。 このサーバーの導入を推薦し、予算の獲得に奮闘し、ソリューションを実装したのはあなたです。 そのサーバーが今、本番環境で稼働しています。
しかし、サーバーに構成された数百のスレッドのうち、活動的に動作しているのはほんの一部のようです。 予測したトランザクション速度には程遠く、 システムの稼働率はわずか25%です。 この場合、誰に助けを求め、 何をすれば良いのでしょうか。 再就職のために履歴書を更新するしかないのでしょうか。
|
パニックになる前に、アプリケーションのロックの利用状況を確認しましょう。 効率的でスケーラビリティに優れた大量スレッドのアプリケーション開発には困難が伴います。 オペレーティング・システムの開発者は、特にメモリ割当てという機能分野において同じ問題に直面しています。
用語
この記事では、ソケットはチップ(1基のCPUハードウェア)を表します。 ソケットにはコアが含まれます。 コアは通常、独自の整数処理ユニットと1次キャッシュで構成されます(これに2次キャッシュが含まれることもあります)。 ハードウェア・スレッド、ストランド、または仮想CPU(vCPU)はレジスタのセットです。複数のvCPUは1次キャッシュなどのリソースを共有します。 ほとんどのオペレーティング・システムでは、vCPUの数をCPUとしてカウントし、レポートします。
背景
かつて、プログラムとオペレーティング・システムはシングルスレッドでした。 このようなシステムでは、実行中のプログラムはすべてのシステム・リソースにアクセスして制御します。 UNIXシステム上で実行するアプリケーションはメモリの割当てにmalloc() APIを、またメモリの解放にfree() APIを使用します。
malloc()を呼び出すと、プロセスで利用可能なアドレス空間が拡大するだけではなく、そのアドレス空間に関連付けられたランダム・アクセス・メモリ(RAM)の容量も増加します。 この仕組みは、デマンド・ページング方式のオペレーティング・システムの出現により大きく変化しました。 デマンド・ページング方式では、malloc()を呼び出すことによりアプリケーションで利用可能なアドレス空間は拡大するものの、ページが必要となるまではRAMは割り当てられません。 アプリケーションで利用可能なアドレス空間を拡大するには、sbrk() APIおよびbrk() APIを使用します。
よくある誤解として、free()によってプログラム・サイズ(アドレス空間)が削減されるというものがあります。 sbrk()/brk()によって設定されるアドレス空間は、sbrk()に負の値を渡すことで縮小できますが、実用上の問題からfree()はこのような技術を実装していません。これは、割当てのときと同じ順序でアドレス空間を削減する必要があるからです。
通常、空きメモリが少ないためにページ・スキャナが実行されるか、アプリケーションが終了すると、そのアドレス空間に関連付けられたRAMがカーネルに戻されます。 ここでメモリ・マップ・ファイルの出番です。 ファイルをプログラムのアドレス空間にマッピングする機能が、アドレス空間拡大のための第2の方式となります。 それまでの方式と大きく異なるのは、メモリ・マップ・ファイルがマッピングされていない場合、マッピングされていないアドレス空間に関連付けられているRAMがカーネルに戻されるため、プロセスの合計アドレス空間が縮小されるという点です。
マルチコア・ハードウェア・システムは、マルチスレッド・オペレーティング・システムやマルチスレッド・アプリケーションの登場につながりました。 その結果、プログラムの複数のコンポーネントが同時にアドレス空間を拡張する必要に迫られるようになります。 これらのアクティビティを同期する何らかの方式が必要になりました。
当初は、シングルプロセスのロックを使用して、libcのmalloc()およびfree()で保護された領域に単一のスレッドのみがアクセスすることを保証していました。 この単一のロックは、スレッド数の少ないアプリケーションや、malloc() APIおよびfree() APIの使用頻度が低いアプリケーションでは今でも十分に機能します。 しかし、多数のCPUを搭載した複数のシステムで稼働する大量スレッドのアプリケーションの場合は、スケーラビリティの問題に陥ることがあり、mallocとfreeのロックが競合するために、予測されるトランザクション速度は遅くなります。
問題を認識するための方法
デフォルトでは、ほとんどのUNIXオペレーティング・システムはlibcに存在するバージョンのmalloc()またはfree()を使用しています。 Oracle Solarisでは、malloc()およびfree()のアクセスは、プロセス単位のロックによって制御されます。 Oracle Solarisでロック競合の発生有無を判定するために使用する最初のツールは、prstat(1M)です。このツールを、-mLフラグ付きで、サンプリング間隔を1に設定して実行します。
2つのスレッドを使用するアプリケーションに対して実行したprstatの出力結果は次のとおりです。 一方のスレッドがmalloc()を呼び出し、もう一方がfree()を呼び出しています。
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4050 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 51 0 0 malloc_test/2 4050 root 97 3.0 0.0 0.0 0.0 0.0 0.0 0.0 0 53 8K 0 malloc_test/3
prstatの出力結果では、プロセスの各スレッドにつき1行の情報が表示されます。 各列の説明については、manページを参照してください。 今注目すべきところはLCK列です。これは、最後のサンプリング期間でユーザー・レベルのロック待ちに費やしたスレッド時間の割合です。 リスト1に、同じアプリケーションで8スレッドを使用した場合の出力結果を示します。
prstat出力結果
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 52 25 0 malloc_test/8 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 52 23 0 malloc_test/7 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 54 26 0 malloc_test/6 4054 root 100 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 51 25 0 malloc_test/9 4054 root 94 0.0 0.0 0.0 0.0 5.5 0.0 0.0 23 51 23 0 malloc_test/3 4054 root 94 0.0 0.0 0.0 0.0 5.6 0.0 0.0 25 48 25 0 malloc_test/4 4054 root 94 0.0 0.0 0.0 0.0 6.3 0.0 0.0 26 49 26 0 malloc_test/2 4054 root 93 0.0 0.0 0.0 0.0 6.7 0.0 0.0 25 50 25 0 malloc_test/5
8スレッドでは、一部にロック競合が発生し始めています。 さらにリスト2に、16スレッドを使用した場合の出力結果を示します。
リスト2:16スレッドの場合のprstat出力結果
PID USERNAME USR SYS TRP TFL DFL LCK SLP LAT VCX ICX SCL SIG PROCESS/LWPID 4065 root 63 37 0.0 0.0 0.0 0.0 0.0 0.0 51 222 .4M 0 malloc_test/31 4065 root 72 26 0.0 0.0 0.0 1.8 0.0 0.0 42 219 .3M 0 malloc_test/21 4065 root 66 30 0.0 0.0 0.0 4.1 0.0 0.0 47 216 .4M 0 malloc_test/27 4065 root 74 22 0.0 0.0 0.0 4.2 0.0 0.0 28 228 .3M 0 malloc_test/23 4065 root 71 13 0.0 0.0 0.0 15 0.0 0.0 11 210 .1M 0 malloc_test/30 4065 root 65 9.0 0.0 0.0 0.0 26 0.0 0.0 10 186 .1M 0 malloc_test/33 4065 root 37 28 0.0 0.0 0.0 35 0.0 0.0 36 146 .3M 0 malloc_test/18 4065 root 38 27 0.0 0.0 0.0 35 0.0 0.0 35 139 .3M 0 malloc_test/22 4065 root 58 0.0 0.0 0.0 0.0 42 0.0 0.0 28 148 40 0 malloc_test/2 4065 root 57 0.0 0.0 0.0 0.0 43 0.0 0.0 5 148 14 0 malloc_test/3 4065 root 37 8.1 0.0 0.0 0.0 55 0.0 0.0 12 112 .1M 0 malloc_test/32 4065 root 41 0.0 0.0 0.0 0.0 59 0.0 0.0 40 108 44 0 malloc_test/13 4065 root 23 15 0.0 0.0 0.0 62 0.0 0.0 23 88 .1M 0 malloc_test/29 4065 root 33 2.9 0.0 0.0 0.0 64 0.0 0.0 7 91 38K 0 malloc_test/24 4065 root 33 0.0 0.0 0.0 0.0 67 0.0 0.0 42 84 51 0 malloc_test/12 4065 root 32 0.0 0.0 0.0 0.0 68 0.0 0.0 1 82 2 0 malloc_test/14 4065 root 29 0.0 0.0 0.0 0.0 71 0.0 0.0 5 78 10 0 malloc_test/8 4065 root 27 0.0 0.0 0.0 0.0 73 0.0 0.0 5 72 7 0 malloc_test/16 4065 root 18 0.0 0.0 0.0 0.0 82 0.0 0.0 3 50 6 0 malloc_test/4 4065 root 2.7 0.0 0.0 0.0 0.0 97 0.0 0.0 7 9 18 0 malloc_test/11 4065 root 2.2 0.0 0.0 0.0 0.0 98 0.0 0.0 3 7 5 0 malloc_test/17
2スレッドと8スレッドの場合は、プロセス時間のほとんどが処理に利用されています。 しかし、16スレッドの場合は、一部のスレッドでロック待ちにほとんどの時間を費やしています。 では、どのロックが関係しているのでしょうか。 この疑問を解消するために、Oracle Solaris DTraceツールのplockstat(1M)を使用します。 今関心があるのは競合イベント(-C)です。 また、10秒間(-e 10)、既存の実行中のプロセス(-p)を監視します。
plockstat -C -e 10 -p `pgrep malloc_test` 0 Mutex block Count nsec Lock Caller 72 306257200 libc.so.1`libc_malloc_lock malloc_test`malloc_thread+0x6e8 64 321494102 libc.so.1`libc_malloc_lock malloc_test`free_thread+0x70c
最初の0はスピン数に関係する数値です (Oracle Solaris 10には、正確なスピン数の判定ができないバグがあります。 このバグはOracle Solaris 11で修正されています)。
この出力結果では、スレッドがブロックされた回数(Count)と、ブロック発生の平均時間(nsec、ナノ秒単位)を確認できます。 ロックに名前がある場合(Lock)、その名前とブロック発生時のスタック・ポインタ(Caller)が表示されます。 ここでは、同じロックの取得のために136回の待ちが発生し、その合計は0.3秒に上っています。これはパフォーマンス上の非常に大きな問題です。
大量スレッドの64ビット・アプリケーションが(数百まではいかなくても)数十のコアで稼働するようになってからは、明らかにマルチスレッド認識型のメモリ・アロケータが必要になりました。 Oracle Solarisには、2つのMTホット・メモリ・アロケータが付属しています。それぞれ、mtmallocとlibumemです。 また、広く知られ誰でも利用できるMTホット・アロケータとして、Hoardというアロケータも存在します。
Hoard
Hoardは、Emery Berger教授によって開発されたアロケータであり、 非常に多くの有名企業で商用利用されています。
Hoardは高速化と優れたスケーラビリティの実現、偽共有の回避、低い断片化率を目指しています。 偽共有は、異なるプロセッサ上の複数のスレッドが誤ってキャッシュ・ラインを共有する際に発生します。 偽共有によってキャッシュの効率的な利用が損なわれるため、パフォーマンスに悪影響を及ぼします。 断片化が発生すると、アプリケーションで本当に必要なメモリ容量よりも、プロセスによって実際に消費されるメモリ容量が多くなります。 断片化は、アドレス空間の浪費、または一種のメモリ・リークと考えることができます。 このような状況は、割当て用のアドレス空間がスレッド単位のプールに存在するのに、別のスレッドがその空間を利用できない場合に発生します。
Hoardはスレッド単位の複数のヒープと1つのグローバル・ヒープを管理します。 Hoardでは、この2種類のヒープ間でアドレス空間を動的に割り当てることで断片化の軽減や回避を行っており、あるスレッドが最初に割り当てたアドレス空間を別のスレッドが再利用できるようにしています。
スレッドIDに基づいたハッシュ・アルゴリズムによって、スレッドをヒープにマッピングします。 個々のヒープは、一連のスーパーブロックとして配置されます。スーパーブロックは、システムのページ・サイズの倍数です。 スーパーブロックの半分のサイズよりも大きな割当てはmmap()を使用して行い、その割当てのマッピング解除はmunmap()を使用して行います。
スーパーブロックには均一サイズの割当て領域が格納されます。 空のスーパーブロックは再利用され、新しいクラスに割り当てることが可能です。 この機能によって断片化が軽減されます (詳細は、Hoard: A Scalable Memory Allocator for Multithreaded Applicationsを参照)。
この文書で利用するHoardのバージョンは3.8です。 Hoard.hには次の定義が含まれています。
#define SUPERBLOCK_SIZE 65536 .
SUPERBLOCK_SIZEはスーパーブロックのサイズです。 この例では、スーパーブロックの半分のサイズとなる32KBよりも大きな割当てでmmap()が使用されます。

図1:Hoardの簡易アーキテクチャ
mtmallocメモリ・アロケータ
Hoardと同様に、mtmallocは複数の準プライベート・ヒープと1つのグローバル・ヒープを管理します。 mtmallocを使用すると、CPU数の2倍の数のバケットが作成されます。 バケットのインデックスにはスレッドIDが使用されます。 各バケットにはキャッシュのリンク・リストが含まれます。 各キャッシュには、一定サイズの割当て領域が含まれます。 各割当ては、2のべき乗のサイズに切り上げられます。 たとえば、100バイトを要求した場合は128バイトにパディングされ、128バイトのキャッシュが割り当てられます。
各キャッシュは、チャンクのリンク・リストです。 キャッシュの空き領域が不足すると、新しいチャンクを割り当てるためにsbrk()が呼び出されます。 チャンクのサイズはチューニング可能です。 しきい値(64k)よりも大きなサイズの割当ては、グローバルの超過サイズ・バケットから割り当てられます。
ロックには、バケット単位のロックとキャッシュ単位のロックが存在します。 さらに、超過サイズ割当て用のロックも存在します (このmalloc.cについてはopensolaris.orgを参照)。

図2:mtmallocの簡易アーキテクチャ
libumemメモリ・アロケータ
libumemは、SunOS 5.4で導入されたスラブ・アロケータのユーザーランド実装です (The Slab Allocator: An Object-Caching Kernel Memory AllocatorとMagazines and Vmem: Extending the Slab Allocator to Many CPUs and Arbitrary Resourcesを参照)。
このスラブ・アロケータは、一般的な型のオブジェクトをキャッシュして、すばやく再利用できるようにします。 スラブはメモリの連続領域であり、固定サイズのチャンクに分割されます。libumemはマガジン・レイヤーと呼ばれるCPU単位のキャッシュ構造を使用します。
マガジンは、基本的にはスタックです。 スタックの一番上から割当てをポップし、開放された割当てをスタックにプッシュします。 スタックが底に達したら、マガジンがvmemレイヤー(デポ)から再ロードされます。 このvmemアロケータはマガジンの共通バッキング・ストアを提供します (マガジンは動的にチューニングされるため、最適なパフォーマンスに達するまでのスラブの準備に数分かかることがあります)。 libumemを使用すると、それぞれのデータ構造を専用のキャッシュ・ライン上に維持するように、データ構造が慎重にパディングされます。そのため、偽共有が発生する可能性が低くなります。
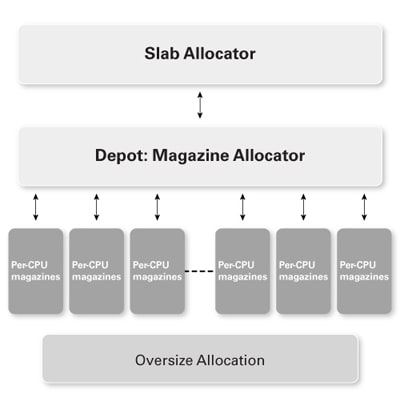
図3:libumemの簡易アーキテクチャ
新規のmtmallocメモリ・アロケータ
mtmallocが再開発され、Oracle Solaris 10 8/11以降で使用できるようになりました。また、Oracle Solaris 11でも使用できます(Performance Improvements for libmtmallocを参照)。
新規のmtmallocでは、キャッシュを保護するロックがなくなり、保護された情報への更新は不可分操作を使用して行われます。 検索を高速化するために、最後の割当てが行われた場所へのポインタが保管されます。
キャッシュのリンク・リストの代わりに、各項目でキャッシュへのポインタを保持する配列のリンク・リストが使用されます。 その結果参照のローカル性が確保され、パフォーマンスが向上します。 特定のフラグを設定すると、vCPU数の2倍の数値よりも小さいIDを持つスレッドがメモリの排他バケットを受け取るため、バケット単位のロックは利用されません。
64ビット・アプリケーションのキャッシュ増分のデフォルト・サイズは、元の9から変更されて64となりました。 この記事ではこれ以降、排他バケットを使用する新規のmtmallocアルゴリズムについては、新規の排他mtmallocと呼び、排他バケットを使用しない場合は新規の非排他mtmallocと呼ぶことにします。
テスト・ハーネス
では、どのアロケータが最適でしょうか。
それぞれの方式のパフォーマンスを評価するために、次の処理を実行するテスト・ハーネスを開発しました。
- 入力パラメータで指定された数の割当てスレッドを作成する
- 1つの割当てスレッドあたり1つの解放スレッドを作成する
- 入力パラメータで指定された回数のループ内で、指定された回数の割当てを実行する
- 関心のあるメトリックとして、ループ回数をカウントする
- 乱数ジェネレータ(
man rand_rを参照)を使用して、それぞれの割当てのサイズを選択する
最大割当てサイズは入力パラメータで指定します。 1ループあたり5000回の割当てを使用し、各テストの実行時間は約1,200秒とします。 最大割当てサイズとして、256バイト、1,024バイト、4,096バイト、16,384バイト、65,536バイトを使用します。
さらに、LD_PRELOAD_64を使用して、テスト対象のライブラリを事前にロードするようにリンカーに指示します。 LD_PRELOADは、本番環境での各ライブラリの実装に使用する方法でもあります。 異なるメモリ・アロケータを使用する別の方法として、アプリケーションのビルド時にライブラリをリンクすることもできます(例:-lmtmalloc)。
入力パラメータについて以下に説明します。また、ソースコードは私のブログにあります(Test Harness for Mallocを参照)。
テスト・プログラムmalloc_testに指定するフラグは次のとおりです。
-h:ヘルプの表示-c:サンプル回数(1回あたり3秒間サンプリングする場合の発行サンプル数)-t:スレッド数-s:割当てに対するmemsetの使用有無(0=使用しない、1=使用する)-m:最大割当てサイズ(バイト単位)-r:割当てサイズの決定に乱数ジェネレータを使用する場合に指定-n:1ループあたりの割当て回数(最大5000)-f:ループの一定回数実行後にプログラムを終了するかを指定(0=ループ回数を指定しない、xx=ループ回数)
割当てサイズの配分を確認するためにDTraceを使用できます。 最大割当てサイズが4KBの場合の配分を次に示します。
Date: 2011 May 27 12:32:21 cumulative malloc allocation sizes
malloc
value ------------- Distribution ------------- count
< 1024 |@@@@@@@@@@ 2331480
1024 |@@@@@@@@@@ 2349943
2048 |@@@@@@@@@@ 2347354
3072 |@@@@@@@@@@ 2348106
4096 | 18323
5120 | 0
このDTraceのコードは次のとおりです。
/* arg1には割当てサイズが含まれます */
pid$target::malloc*:entry
{ @[probefunc]=lquantize(arg1,1024,16684,1024); }
tick-10sec
{ printf("\n Date: %Y cumulative malloc allocation sizes \n", walltimestamp);
printa(@);
exit(0); }
テスト結果
最初のテストは、1ソケット、8コア、64のハードウェア・スレッド、64GBのRAMで構成されるUltraSPARC T2ベースのマシンで実行しました。 カーネルのバージョンはSunOS 5.10 Generic_141444-09です。その結果、表1のとおり超過サイズ割当てによるスケーラビリティの問題が発生しています。
さらに追加のテストを、2ソケット、32コア、256のハードウェア・スレッド、512GBのRAMで構成されるUltraSPARC T3ベースのマシンで実行しました。 カーネルのバージョンはSunOS 5.10 Generic_144408-04です。この2つ目のテストでは、超過サイズの問題を避けるために4KB未満の割当てのみを使用しました。 その結果(1秒あたりの平均ループ数)は表1の下側にまとめています。新規の排他mtmallocアルゴリズム(緑)ではパフォーマンスにまったく問題がなく、Hoardとlibumemで大量スレッドの場合(赤)にスケーラビリティの問題が発生していることが分かります。 ここではアドレス空間または空ページの割当てについてテストしているため、各システムのRAM容量は今回のテストには関係ありません。
| 1秒あたりのループ回数 (lps) |
lps | lps | lps | lps | lps | lps |
|---|---|---|---|---|---|---|
| スレッド数/ 割当てサイズ (UltraSPARC T2) |
Hoard | mtmalloc |
umem |
新規の排他mtmalloc |
新規の非排他mtmalloc |
libc malloc |
| 1スレッド、256バイト | 182 | 146 | 216 | 266 | 182 | 137 |
| 4スレッド、256バイト | 718 | 586 | 850 | 1067 | 733 | 114 |
| 8スレッド、256バイト | 1386 | 1127 | 1682 | 2081 | 1425 | 108 |
| 16スレッド、256バイト | 2386 | 1967 | 2999 | 3683 | 2548 | 99 |
| 32スレッド、256バイト | 2961 | 2800 | 4416 | 5497 | 3826 | 93 |
| 1スレッド、1,024バイト | 165 | 148 | 214 | 263 | 181 | 111 |
| 4スレッド、1,024バイト | 655 | 596 | 857 | 1051 | 726 | 87 |
| 8スレッド、1,024バイト | 1263 | 1145 | 1667 | 2054 | 1416 | 82 |
| 16スレッド、1,024バイト | 2123 | 2006 | 2970 | 3597 | 2516 | 79 |
| 32スレッド、1,024バイト | 2686 | 2869 | 4406 | 5384 | 3772 | 76 |
| 1スレッド、4,096バイト | 141 | 150 | 213 | 258 | 179 | 92 |
| 4スレッド、4,096バイト | 564 | 598 | 852 | 1033 | 716 | 70 |
| 8スレッド、4,096バイト | 1071 | 1148 | 1663 | 2014 | 1398 | 67 |
| 16スレッド、4,096バイト | 1739 | 2024 | 2235 | 3432 | 2471 | 66 |
| 32スレッド、4,096バイト | 2303 | 2916 | 2045 | 5230 | 3689 | 62 |
| 1スレッド、16,384バイト | 110 | 149 | 199 | 250 | 175 | 77 |
| 4スレッド、16,384バイト | 430 | 585 | 786 | 1000 | 701 | 58 |
| 8スレッド、16,384バイト | 805 | 1125 | 1492 | 1950 | 1363 | 53 |
| 16スレッド、16,384バイト | 1308 | 1916 | 1401 | 3394 | 2406 | 0 |
| 32スレッド、16,384バイト | 867 | 1872 | 1116 | 5031 | 3591 | 49 |
| 1スレッド、65,536バイト | 0 | 138 | 32 | 205 | 151 | 62 |
| 4スレッド、65,536バイト | 0 | 526 | 62 | 826 | 610 | 43 |
| 8スレッド、65,536バイト | 0 | 1021 | 56 | 1603 | 1184 | 41 |
| 16スレッド、65,536バイト | 0 | 1802 | 47 | 2727 | 2050 | 40 |
| 32スレッド、65,536バイト | 0 | 2568 | 38 | 3926 | 2992 | 39 |
| スレッド数/ 割当てサイズ (UltraSPARC T3) |
Hoard | mtmalloc |
umem |
新規の排他mtmalloc |
新規の非排他mtmalloc |
|
| 32スレッド、256バイト | 4597 | 5624 | 5406 | 8808 | 6608 | |
| 64スレッド、256バイト | 8780 | 9836 | 495 | 16508 | 11963 | |
| 128スレッド、256バイト | 8505 | 11844 | 287 | 27693 | 19767 | |
| 32スレッド、1,024バイト | 3832 | 5729 | 5629 | 8450 | 6581 | |
| 64スレッド、1,024バイト | 7292 | 10116 | 3703 | 16008 | 12220 | |
| 128スレッド、1,024バイト | 41 | 12521 | 608 | 27047 | 19535 | |
| 32スレッド、4,096バイト | 2034 | 5821 | 1475 | 9011 | 6639 | |
| 64スレッド、4,096バイト | 0 | 10136 | 1205 | 16732 | 11865 | |
| 128スレッド、4,096バイト | 0 | 12522 | 1149 | 26195 | 19220 |
結果と所見
どのメモリ・アロケータが最適であるかは、アプリケーションのメモリ利用パターンによって異なります。 どのような状況でも、超過サイズ割当てを使用するとアロケータがシングルスレッドになります。
新規の排他mtmallocアルゴリズムには、超過サイズのしきい値をチューニングできるというメリットがあります。 アプリケーションで排他フラグを使用できる場合は、明らかに新規の排他mtmallocのパフォーマンスが高くなります。 しかし、排他フラグを使用できない場合は、16スレッドまでであればlibumemのパフォーマンスの方が優れています。 アドレス空間の割当て速度を計測する場合に、どのアルゴリズムでもシステムのメモリ容量は関係ありません。 図4のグラフで、4KBの割当ての場合について見てみましょう。
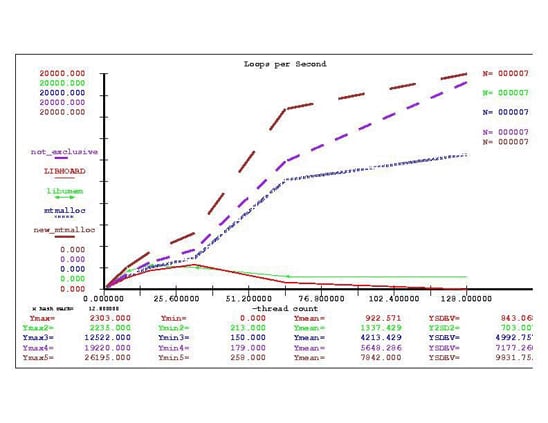
図4:Hoard、mtmalloc、libumemの1秒あたりのループ回数
ご覧のとおり、libumemとHoardは、スレッド数が32から64に増えるとスケーラビリティが悪化しています。つまり、アプリケーションの1秒あたりのトランザクション数が実際に減少しています。
チューニングを実行するにあたって、スレッド単位のヒープ数を増やすためのさまざまなオプションを試すことができます。 mtmallocの各アロケータは、新しいmtmallocアルゴリズムを使用すると高いスケーラビリティが維持され、排他オプションを指定したときにパフォーマンスがピークに達しています。また、新規の非排他mtmallocでもスケーラビリティが維持されています。
パフォーマンス
各方式のパフォーマンスの調査をさらに進めるために、スレッドの実行時に、スレッドのリソース・プロファイルについて調査します。 Oracle Solarisでは、procfsインタフェースを使用してこの調査を行うことができます。
tpryを使用して、テスト・ハーネスでのprocfsデータを収集できます(tpry, procfs Based Thread Monitoring SEToolkit Styleを参照)。 また、newbarを使用して、テスト・ハーネスのスレッドをグラフィカルに調査できます(newbar: a Post-Processing Visualization Toolを参照)。
図5から図9までのグラフ内の色は次の内容を示しています。
- 赤:カーネル時間の割合
- 緑:ユーザー・モードの時間の割合
- オレンジ:ロック待ちの時間の割合
- 黄:CPU待ちの時間の割合
ご覧のとおり、Hoardとlibumemではロック競合(オレンジ)がさまざまな割合で発生しています。それぞれのバーは、1つの間隔の100%を表しています。
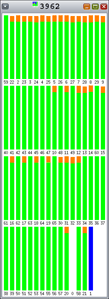 図5:Hoard: ロック競合の発生 |
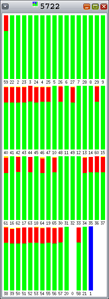 図6: |
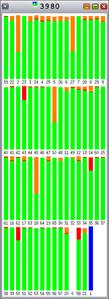 図7: |
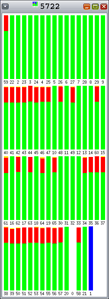 図8:新規の非排他 |
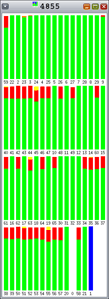 図9:新規の排他 |
また、Hoardが128スレッドまで拡張しなかった点にも注目しましょう。 この点について詳しく調査するために、procfsから取得したデータを確認できます。 もう一度説明すると、緑はユーザー・モードの時間の割合、赤はカーネル・モードの時間の割合です。 この結果、カーネル・モード(赤)のCPU時間が増加していることが分かります。 詳しくは、図10を参照してください。
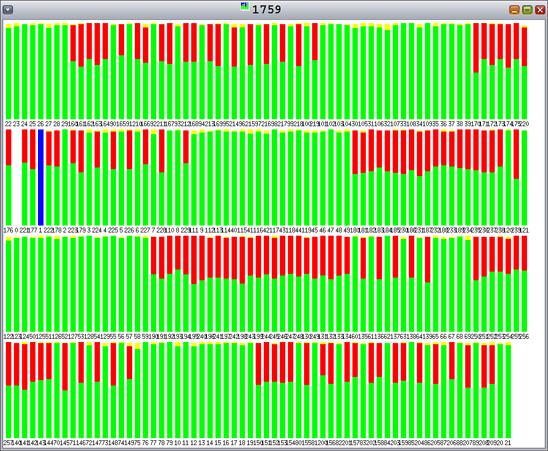
図10:Hoard、128の割当てスレッド、128の解放スレッド、4KBの割当ての場合—カーネル・モードの時間の増加
DTraceとtruss -c(man -s 1 truss)を使用すると、実行頻度のもっとも高いシステム・コールはlwp_parkであることが明らかになります。 この点をさらに詳しく調査するために、次のDTraceスクリプトを使用して、アプリケーションでもっとも使用頻度の高いシステム・コールを実行した際のスタックの内容を確認します。
syscall::lwp_park:entry
/ pid == $1 /
{ @[pid,ustack(3)]=count();
self->ts = vtimestamp; }
tick-10sec
{ printf("\n Date: %Y \n", walltimestamp);
printa(@);
trunc(@); }
UltraSPARC T3ベースのマシン上で、Hoard、128の割当てスレッド、128の解放スレッドを使用するテスト・ハーネスの実行中にこのスクリプトを実行すると、リスト3の出力結果が表示されます。
リスト3:スクリプトの出力結果
12 57564 :tick-10sec
Date: 2011 May 31 17:12:17
3774 libc.so.1`__lwp_park+0x10
libc.so.1`cond_wait_queue+0x4c
libc.so.1`cond_wait_common+0x2d4 826252
12 57564 :tick-10sec
Date: 2011 May 31 17:12:27
3774 libc.so.1`__lwp_park+0x10
libc.so.1`cond_wait_queue+0x4c
libc.so.1`cond_wait_common+0x2d4 891098
この結果から、Hoardはlibc.so.1`cond_wait_common+0x2d4を呼び出しており、条件変数でスラッシングが発生しているようです。
一方、図11に示すとおり、libumemではロック競合が発生します(オレンジはロック待ち時間の割合です)。
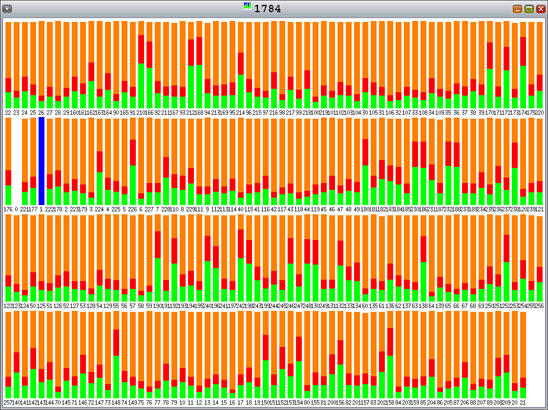
図11:libumem、128の割当てスレッド、128の解放スレッド、4KBの割当ての場合—ロック競合
新規の排他mtmallocアルゴリズムではロック競合は発生していません(図12を参照)。
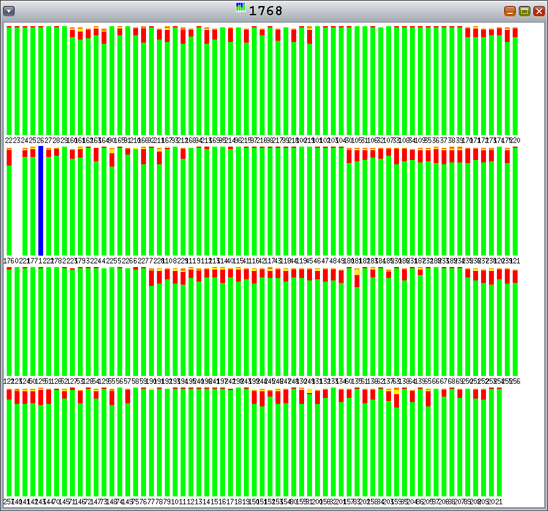
図12:新規の排他mtmalloc、128の割当てスレッド、128の解放スレッド—ロック競合なし
断片化
アロケータのシステム・メモリ利用の効率性を比較するために、4KBの割当てでこのテストを繰り返しました。
このテストでは、memsetを使用してすべての割当て済みメモリ・アドレスを操作し、RAMが各アドレスと確実に関連付けられるようにしています。 アプリケーションを3秒おきにテストし、一定数の割当てループが実行されているかどうかを確認しました。 割当ての上限に達したときには、すべてのスレッドですべて割当ての停止および開放を行うようにしています。
psコマンドを使用して、アプリケーションの終了前の物理メモリ使用サイズ(RSS)を推定しました。 サイズはキロバイト単位であり、小さいほど優れています。
| スレッド数/ 割当てサイズ |
Hoard | mtmalloc |
umem |
新規の排他mtmalloc |
新規の非排他mtmalloc |
|---|---|---|---|---|---|
| 32スレッド、4,096バイト | 1,073,248 | 1,483,840 | 570,704 | 1,451,144 | 1,451,144 |
libumemのメモリ・フットプリントがもっとも優れていますが、これはマガジンがCPU単位のレイヤーからデポに戻していると解釈できます。 また、Hoardも空のスーパーブロックをグローバル・キャッシュに戻しています。
それぞれのアルゴリズムには独自のメリットがあります。 Hoardは断片化の削減という面で高い評価を得ており、mtmallocはアドレス空間とメモリ制約を犠牲にしてパフォーマンスを高めています。
すべてのアロケータに、アロケータの割当てパターンを"チューニング"するためのオプションが用意されています。 最大のパフォーマンスを得るためには、アプリケーションのニーズに合わせてこれらのオプションを調査する必要があります。 この記事の調査結果としては、メモリ・フットプリントの小さいシステムほど、libumemおよびHoardを使用する方が適しています。
libumemには、パフォーマンスが最大に達するまでの起動時に、パフォーマンスの偏向が少し見られました。 図13で、20分間の実行における最初の5分間のパフォーマンスを比較しています。
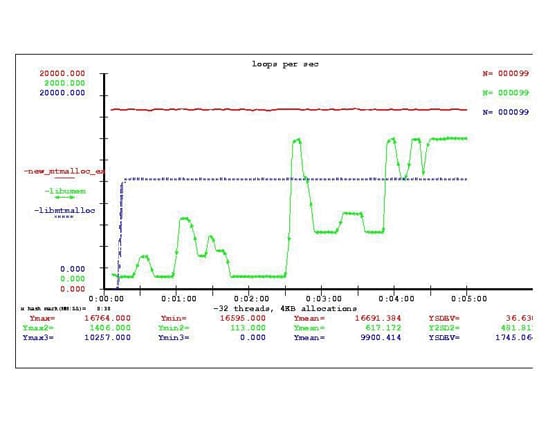
図13:起動時のパフォーマンス比較
結論
システムがスケーラビリティの確保のために大規模な並列処理に依存する度合いが高まる中で、大量スレッドの新しいアプリケーションにオペレーティング環境を対応させることが重要になっています。 メモリ・アロケータは、アプリケーションのアーキテクチャと運用上の制約を考慮して選択する必要があります。
短い待機時間(速い実行速度)や起動の早さが重要になる場合は、新規の非排他mtmallocアロケータを使用します。 さらに、アプリケーションで長期にわたるスレッドやスレッド・プールを使用する場合は、排他機能を有効にします。
中程度のスケーラビリティを維持し、RAMのフットプリントを小さくする場合は、libumemが適しています。 短期の超過サイズ・セグメントがある場合、Hoardは自動的にmmap()を使用するため、free()の呼出し時にアドレス空間とRAMが自動的に解放されます。
参考資料
このドキュメントで参照した情報は次のとおりです。
- Hoard: http://www.hoard.org/
- "Hoard: A Scalable Memory Allocator for Multithreaded Applications": http://www.cs.umass.edu/~emery/hoard/asplos2000.pdf
- opensolaris.orgの
malloc.c: http://src.opensolaris.org/source/xref/onnv/onnv-gate/usr/src/lib/libmalloc/common/malloc.c - "The Slab Allocator: An Object-Caching Kernel Memory Allocator": http://www.usenix.org/publications/library/proceedings/bos94/bonwick.html
- "Magazines and Vmem: Extending the Slab Allocator to Many CPUs and Arbitrary Resources": http://www.usenix.org/event/usenix01/full_papers/bonwick/bonwick_html/index.html
- "Performance Improvements for
libmtmalloc": http://arc.opensolaris.org/caselog/PSARC/2010/212/libmtmalloc_onepager.txt - "Test Harness for Malloc": https://blogs.oracle.com/rweisner/entry/test_harness_for_malloc
- "tpry, procfs Based Thread Monitoring SEToolkit Style": https://blogs.oracle.com/rweisner/entry/tpry_procfs_based_thread_monitoring
- "newbar: a Post-Processing Visualization": https://blogs.oracle.com/rweisner/entry/newbar_a_post_proceesing_visualization
| 改訂版1.0、2012年3月8日 |
Facebook、Twitter、またはOracle Blogsで最新情報をご確認ください。