بنية ذكاء اصطناعي
تشغيل أحمال عمل الذكاء الاصطناعي الأكثر طلبًا بشكل أسرع، بما في ذلك تدريب نموذج متقدم الطبقة والاستدلال والذكاء الاصطناعي الخاص بالوكلاء والحوسبة العلمية ومحركات التوصيات، في أي مكان في سحابتنا الموزعة. استخدم مجموعة البنية التحتية من Oracle Cloud (OCI) الفائقة لما يصل إلى 131072 وحدة معالجة رسومات للأداء في zettascale.

انضم إلى Oracle في مؤتمر NVIDIA GTC
16-19 مارس 2026
سان خوسيه، كاليفورنيا، افتراضيًا
-
![]() استكشف اتجاهات الذكاء الاصطناعي التي تؤثر على الأعمال في عام 2026
استكشف اتجاهات الذكاء الاصطناعي التي تؤثر على الأعمال في عام 2026
انضم إلى سلسلة ندوات الويب لمعرفة كيف يمكن لمؤسستك البقاء جاهزة.
-
![]() المبادئ الأولى: مجموعات Zettascale OCI الفائقة
المبادئ الأولى: مجموعات Zettascale OCI الفائقة
يكشف كبار مهندسي OCI عن طريقة تشغيل شبكات المجموعات GenAI القابلة للتوسع—من عدد قليل من وحدات معالجة الرسومات إلى مجموعة OCI الفائقة zettascale مع 131072 وحدة معالجة رسومات NVIDIA Blackwell.
![]() الذكاء الاصطناعي قيد التنفيذ: 10 ابتكارات مُتطورة لاستكشافها الآن
الذكاء الاصطناعي قيد التنفيذ: 10 ابتكارات مُتطورة لاستكشافها الآن
اكتشف 10 تقنيات رائدة قائمة على الذكاء الاصطناعي تعيد تشكيل طريقة أداء المؤسسات للصيانة والتفاعل مع العملاء وتأمين البيانات وتقديم الرعاية الصحية والمزيد غير ذلك.
-
![]() مجموعة الإستراتيجية المؤسسية في AMD Instinct MI300X
مجموعة الإستراتيجية المؤسسية في AMD Instinct MI300X
اكتشف وجهة نظر المحللين حول البنية التحتية للذكاء الاصطناعي لـ OCI باستخدام وحدات معالجة الرسومات AMD وكيف يمكن لهذه المجموعة تحسين الإنتاجية وتسريع الوقت اللازم لتحقيق القيمة وتقليل تكاليف الطاقة.




الابتكار المشترك بين Oracle وNVIDIA
اكتشف كيف تسرع الشركتان اعتماد الذكاء الاصطناعي.
لماذا تتوافق مع البنية الأساسية للذكاء الاصطناعي من OCI؟

الأداء والقيمة
تعزيز تدريب الذكاء الاصطناعي باستخدام مثيلات وحدة معالجة الرسومات (GPU) الفريدة من OCI وشبكات مجموعات RDMA فائقة السرعة التي تقلل من زمن الوصول إلى ما لا يقل عن 2.5 ميكروثانية. احصل على أسعار أفضل حول الأجهزة الظاهرية لـ GPU.

تخزين HPC
استفد من تخزين ملفات OCI باستخدام أهداف التوصيل عالية الأداء (HPMT) ونظامLustre للتيرابايت في الثانية من الإنتاجية. استخدم ما يصل إلى 61.44 تيرابايت من تخزين NVMe، وهو الأعلى في المجال لمثيلات GPU.

الذكاء الاصطناعي السيادي
تتيح لك السحابة الموزعة من Oracle نشر البنية التحتية لحلول الذكاء الاصطناعي في أي مكان للمساعدة في تلبية متطلبات الأداء والأمان وسيادة حلول الذكاء الاصطناعي. تعرَّف على طريقة تقديم Oracle وNVIDIA للذكاء الاصطناعي السيادي في أي مكان.
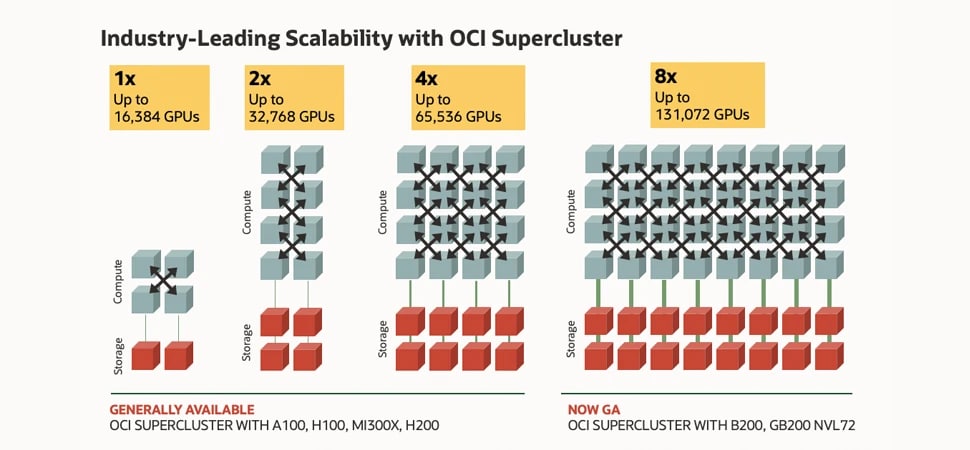 تعرض الصورة صناديق تمثل الحوسبة والتخزين، مُتصلة بخطوط لشبكات أنظمة المجموعات. في أقصى اليسار، توجد أربعة صناديق للحوسبة وصندوقان للتخزين لأصغر مجموعة بها 16000 وحدة معالجة رسومات NVIDIA H100. يوجد إلى اليمين 8 صناديق للحوسبة و4 صناديق للتخزين لـ 32000 وحدة معالجة رسومات NVIDIA A100 في مجموعة. بعد ذلك، توجد 16 صندوقًا من الحوسبة و8 صناديق تخزين لـ 64000 وحدة معالجة رسومات NVIDIA H200. أخيرًا، يوجد إلى أقصى اليمين 32 صندوقًا للحوسبة و16 صندوقًا للتخزين لـ 128000 وحدة معالجة رسومات NVIDIA Blackwell وGrace Blackwell. يُظهر هذا زيادة قابلية توسع في المجموعة الفائقة من OCI بمقدار 8X من أصغر 16000 تكوين GPU في أقصى اليسار إلى أكبر 128000 تكوين GPU في أقصى اليمين.
تعرض الصورة صناديق تمثل الحوسبة والتخزين، مُتصلة بخطوط لشبكات أنظمة المجموعات. في أقصى اليسار، توجد أربعة صناديق للحوسبة وصندوقان للتخزين لأصغر مجموعة بها 16000 وحدة معالجة رسومات NVIDIA H100. يوجد إلى اليمين 8 صناديق للحوسبة و4 صناديق للتخزين لـ 32000 وحدة معالجة رسومات NVIDIA A100 في مجموعة. بعد ذلك، توجد 16 صندوقًا من الحوسبة و8 صناديق تخزين لـ 64000 وحدة معالجة رسومات NVIDIA H200. أخيرًا، يوجد إلى أقصى اليمين 32 صندوقًا للحوسبة و16 صندوقًا للتخزين لـ 128000 وحدة معالجة رسومات NVIDIA Blackwell وGrace Blackwell. يُظهر هذا زيادة قابلية توسع في المجموعة الفائقة من OCI بمقدار 8X من أصغر 16000 تكوين GPU في أقصى اليسار إلى أكبر 128000 تكوين GPU في أقصى اليمين.
المجموعة الفائقة من OCI مع وحدات معالجة الرسومات NVIDIA Blackwell وHopper
ما يصل إلى 131072 وحدة معالجة رسومات، و8 أضعاف مزيد من قابلية التوسع
تمكن ابتكارات نسيج الشبكة المجموعة الفائقة من OCI من توسيع ما يصل إلى 131072 وحدة معالجة رسومات NVIDIA B200، وأكثر من 100000 وحدة معالجة رسومات Blackwell في NVIDIA Grace Blackwell Superchips، و65536 وحدة معالجة رسومات NVIDIA H200.
البنية التحتية للذكاء الاصطناعي لـ OCI لجميع احتياجاتك
سواء كنت تتطلع إلى إجراء استنتاج أو ضبط أو تدريب نماذج واسعة النطاق للذكاء الاصطناعي التوليدي، فإن OCI توفر خيارات مجموعات وحدة معالجة الرسومات للأجهزة الافتراضية والأجهزة بدون أنظمة تشغيل رائدة في المجال مدعومة بشبكة عرض نطاق ترددي فائق وتخزين عالي الأداء لتناسب احتياجات الذكاء الاصطناعي.
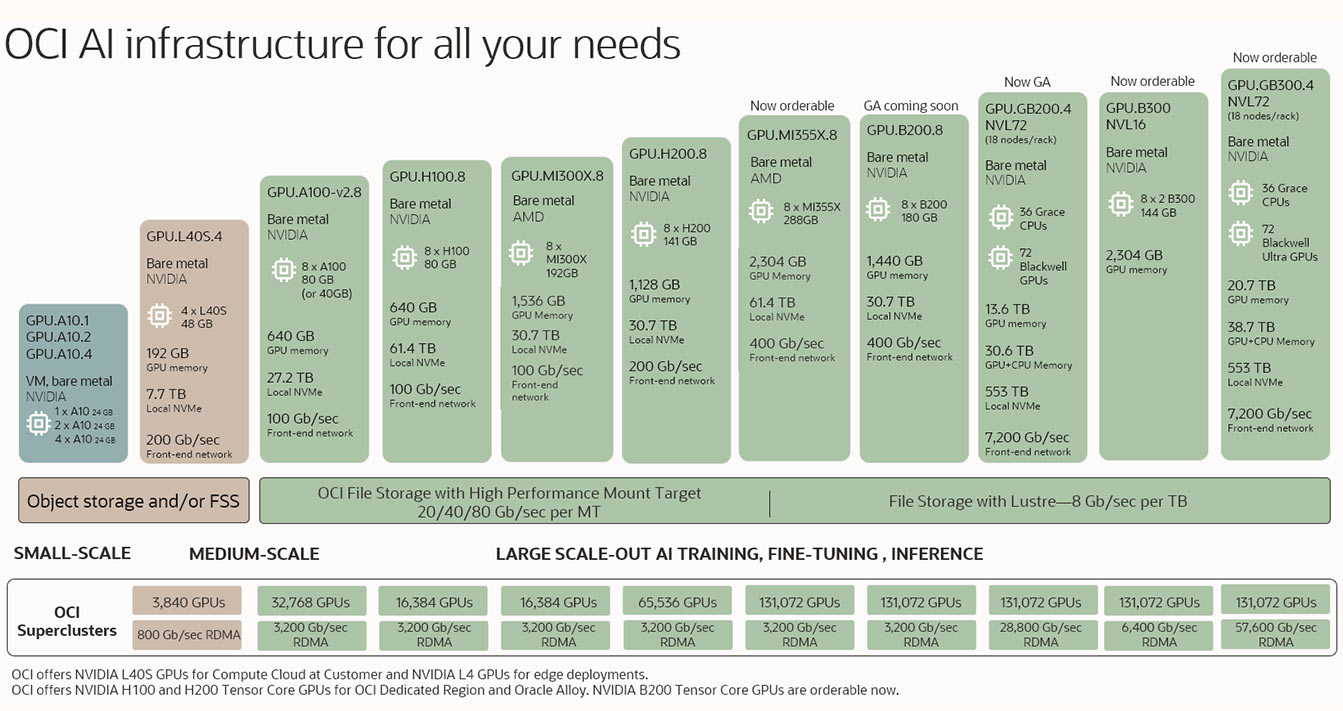 تعرض الصورة العديد من المنتجات للبنية التحتية للذكاء الاصطناعي بدءًا من أسفل اليسار مع أصغر التكوينات ثم تتزايد بشكل تدريجي إلى تكوينات متوسطة الحجم وعلى نطاق واسع. تأتي أصغر التكوينات مع وحدات معالجة رسومات واحدة فقط في جهاز ظاهري وأكبر التكوينات هي لأكثر من 100000 وحدة معالجة رسومات في مجموعات RDMA.
تعرض الصورة العديد من المنتجات للبنية التحتية للذكاء الاصطناعي بدءًا من أسفل اليسار مع أصغر التكوينات ثم تتزايد بشكل تدريجي إلى تكوينات متوسطة الحجم وعلى نطاق واسع. تأتي أصغر التكوينات مع وحدات معالجة رسومات واحدة فقط في جهاز ظاهري وأكبر التكوينات هي لأكثر من 100000 وحدة معالجة رسومات في مجموعات RDMA. في 11 يونيو، تعرّف على كيفية تشغيل الذكاء الاصطناعي في بيئات الإنتاج باستخدام OCI وNVIDIA RTX PRO.
استكشف المجموعات الفائقة من OCI لتدريب حلول الذكاء الاصطناعي على نطاق واسع
مجموعات واسعة النطاق مع NVIDIA Blackwell وHopper
الحوسبة الفائقة
• مثيلات دون أنظمة تشغيل بدون أي تكلفة إضافية لمراقب الأجهزة الافتراضية
• يتم تسريعها بواسطة NVIDIA Blackwell (GB200 NVL72 وHGX B200) و
Hopper (H200 وH100) ووحدات معالجة الرسومات من الجيل السابق
• خيار استخدام وحدات معالجة الرسومات AMD MI300X
• وحدة معالجة البيانات (DPU) لتسريع الأجهزة المدمجة
السعة الهائلة والتخزين عالي الإنتاجية
• التخزين المحلي: ما يصل إلى 61.44 تيرابايت من سعة NVMe SSD
• تخزين الملفات: تخزين الملفات المدار بواسطة Oracle مع Lustre وأهداف التثبيت عالية الأداء.
• تخزين الكتل: وحدات تخزين متوازنة وأداء أعلى وأداء فائق مع اتفاقية مستوى خدمة (SLA) للأداء
• تخزين الكائنات: طبقات فئات تخزين مُميزة وحدود استنساخ الحزم والسعة العالية
الشبكات فائقة السرعة
• RDMA مُصممة خصيصًا عبر بروتوكول Ethernet المتقارب (RoCE v2)
• زمن انتقال يتراوح من 2.5 إلى 9.1 ميكروثانية لشبكات المجموعات
• ما يصل إلى 3200 جيجابت/ثانية من عرض النطاق الترددي لشبكة المجموعة
• ما يصل إلى 400 جيجابت/ثانية من عرض النطاق الترددي لشبكة الواجهة الأمامية
الحوسبة في مجموعة OCI الفائقة
تتيح لك مثيلات OCI المُخصصة المدعومة بوحدات معالجة الرسومات NVIDIA GB200 NVL72 وNVIDIA B200 وNVIDIA H200 وAMD MI300X وNVIDIA L40S وNVIDIA H100 وNVIDIA A100 تشغيل نماذج ذكاء اصطناعي كبيرة لحالات الاستخدام التي تتضمن التعلم العميق والذكاء الاصطناعي للمحادثات والذكاء الاصطناعي التوليدي.
باستخدام مجموعة OCI الفائقة، يمكنك توسيع ما يصل إلى أكثر من 100000 GB200 رقائق فائقة و131072 B200 GPUs و65536 H200 GPUs و32768 A100 GPUs و16384 H100 GPUs و16384 MI300X GPUs و3840 L40S GPUs لكل مجموعة.

توسع+
الشبكات في مجموعة OCI الفائقة
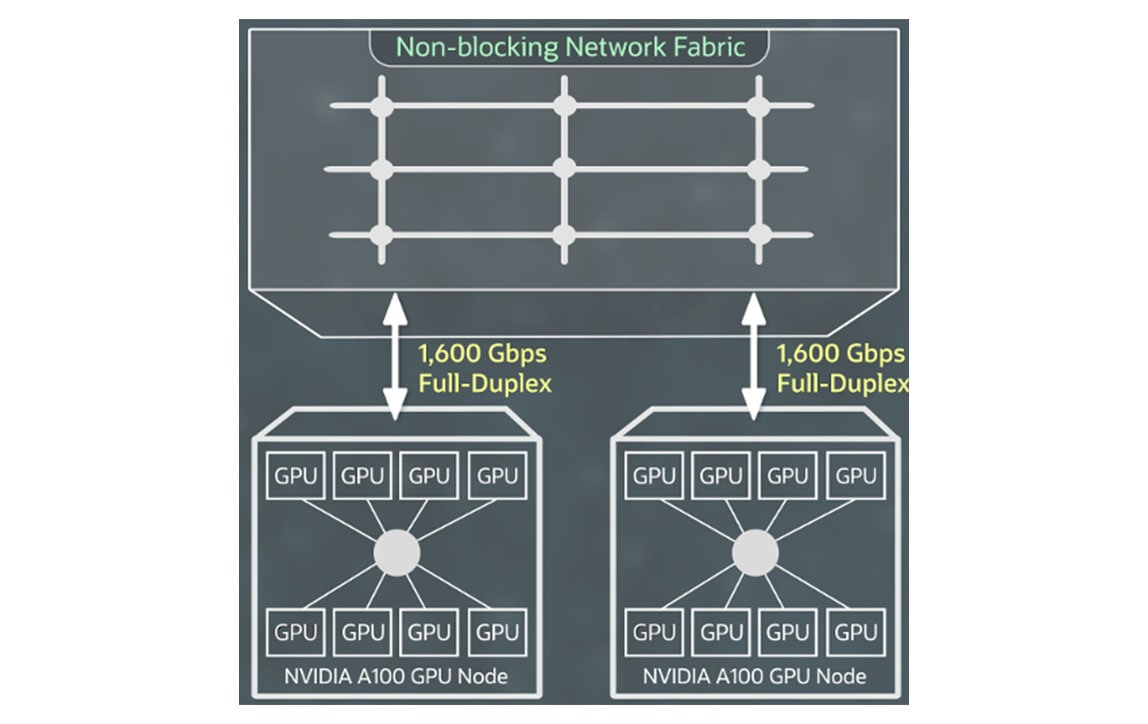
تتيح لك شبكة مجموعات RDMA عالية السرعة المدعومة ببطاقات واجهة الشبكة NVIDIA ConnectX مع RDMA عبر إصدار Ethernet المتقاربة 2 إنشاء مجموعات كبيرة من مثيلات وحدة معالجة الرسومات (GPU) بنفس الشبكات ذات زمن الوصول المنخفض للغاية وقابلية توسع التطبيقات التي تتوقعها في أماكن العمل.
لا تدفع رسومًا إضافية مقابل إمكانية مجموعات الوصول المباشر للذاكرة عن بُعد أو تخزين الكتل أو عرض النطاق الترددي للشبكة، وأول 10 تيرابايت من الإخراج مجاني.
توسع+
التخزين في المجموعة الفائقة من OCI
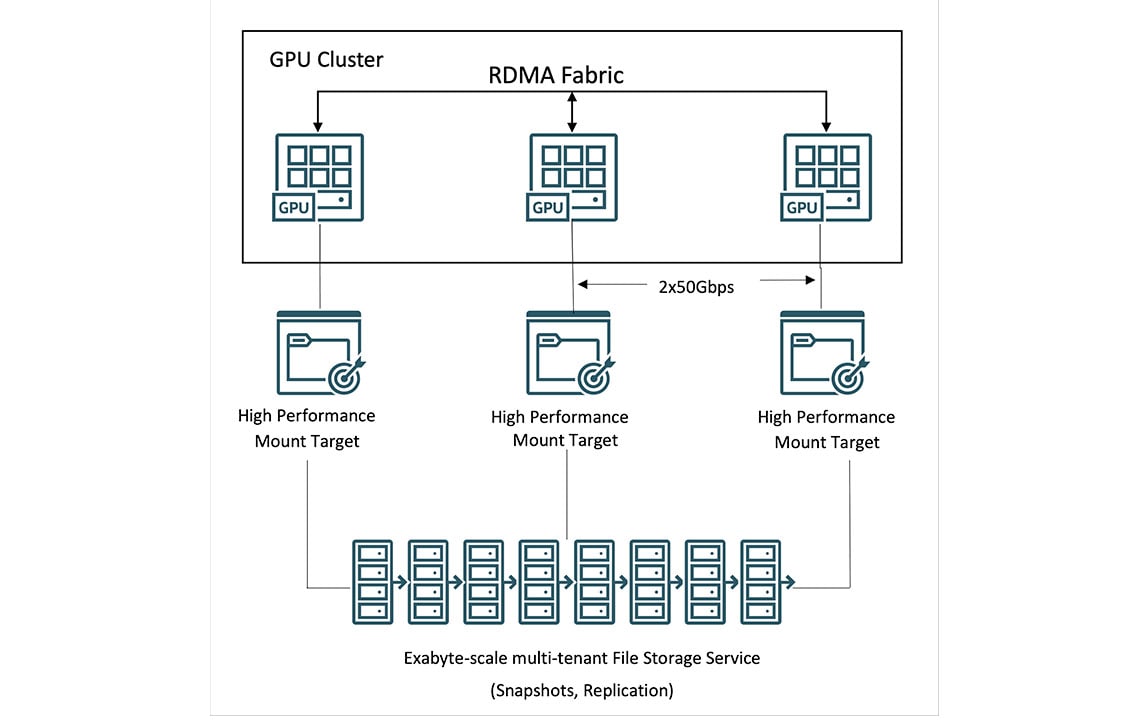
يمكن للعملاء من خلال المجموعات الفائقة من OCI، الوصول إلى التخزين المحلي والكتل والكائنات والملفات للحوسبة على نطاق البيتابايت. من بين مزودي السحابة الرئيسيين، توفر OCI أعلى سعة لتخزين لذاكرة NVMe المحلي عالي الأداء للحصول على نقاط تفتيش أكثر تكرارًا أثناء عمليات التدريب، مما يؤدي إلى استرداد أسرع من حالات الفشل.
بالنسبة إلى مجموعات البيانات الضخمة، توفر OCI تخزين ملفات عالي الأداء مع أهداف التوصيل ونظام Lustre. يمكن استخدام أنظمة ملفات الحوسبة العالية الأداء، بما في ذلك BeeGFS وGlusterFS وWEKA، للتدريب على حلول الذكاء الاصطناعي على نطاق واسع دون المساس بالأداء.

مجموعات OCI الفائقة في Zettascale
شاهد كبار المصممين في OCI يكشفون كيف تدعم شبكات المجموعات الذكاء الاصطناعي التوليدي القابل للتوسع. من عدد قليل من وحدات معالجة الرسومات إلى مجموعات OCI الفائقة من zettascale مع أكثر من 131000 وحدة معالجة رسومات NVIDIA Blackwell، توفر شبكات المجموعات سرعة عالية وزمن انتقال مُنخفض وشبكة مرنة لرحلة الذكاء الاصطناعي.
تختار Seekr منصة البنية التحتية من Oracle Cloud لتقديم الذكاء الاصطناعي الموثوق به إلى عملاء المؤسسات والحكومات على مستوى العالم
هابيل هابتيجورجيس، العلاقات العامة في Oracleأبرمت شركة Seekr، وهي شركة للذكاء الاصطناعي تركز على تقديم الذكاء الاصطناعي الموثوق به اتفاقية متعددة السنوات مع البنية التحتية من Oracle Cloud (OCI) لتسريع عمليات نشر الذكاء الاصطناعي للمؤسسات وتنفيذ استراتيجية مشتركة للانتقال إلى السوق.
اقرأ المنشور الكاملأبرز المدونات
- 26 مارس 2025 الإعلان عن إمكانات جديدة للبنية التحتية للذكاء الاصطناعي مع NVIDIA Blackwell للخدمات السحابية العامة والمحلية وموفري الخدمة
- 17 مارس 2025 تعزيز الابتكار في الذكاء الاصطناعي: NVIDIA AI Enterprise وNVIDIA NIM على OCI
- 17 مارس 2025 تقدم Oracle وNVIDIA الذكاء الاصطناعي السيادي في أي مكان
- 11 مارس 2025 انتقل من صفر إلى أن تكون بطل الذكاء الاصطناعي—نشر أحمال عمل الذكاء الاصطناعي بسرعة على OCI
حالات الاستخدام النموذجية للبنية الأساسية لحلول الذكاء الاصطناعي
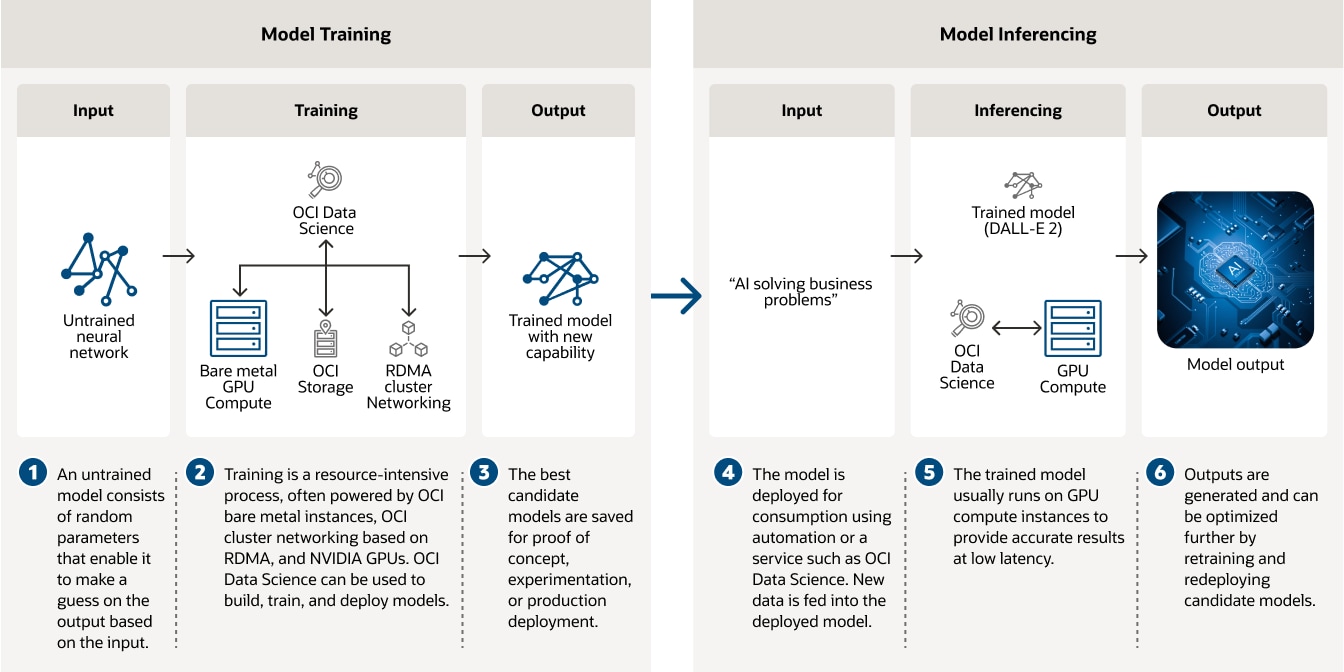
- التدريب على حلول التعلم العميق وطرق الاستنتاج
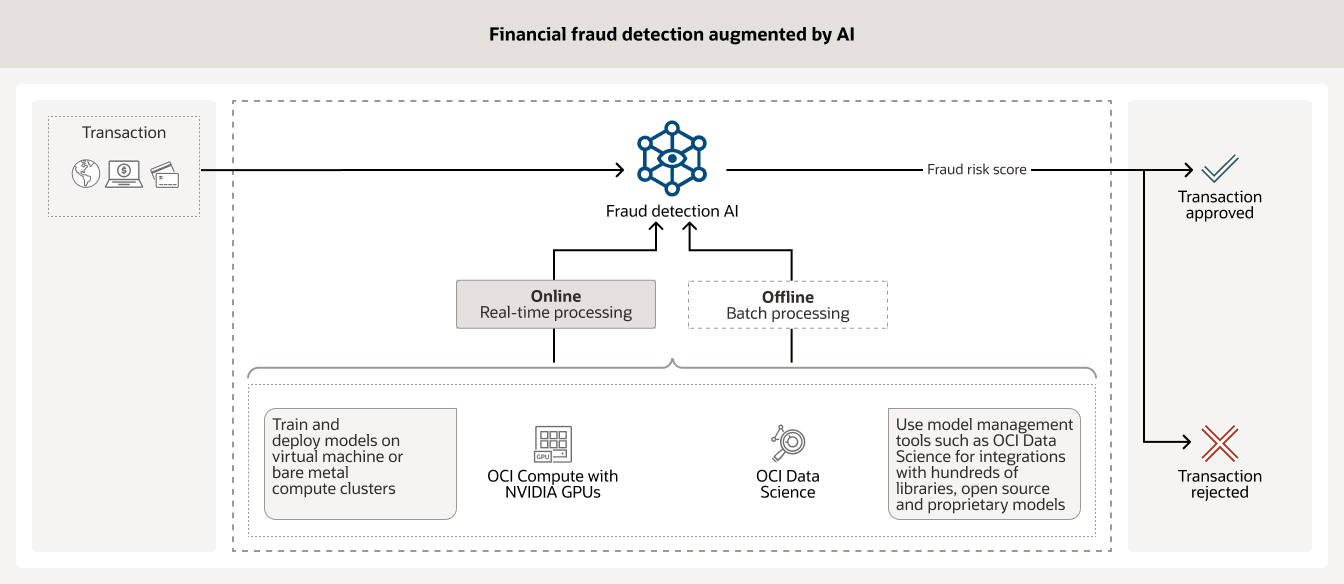
- الكشف عن الاحتيال المعزّز بحلول الذكاء الاصطناعي
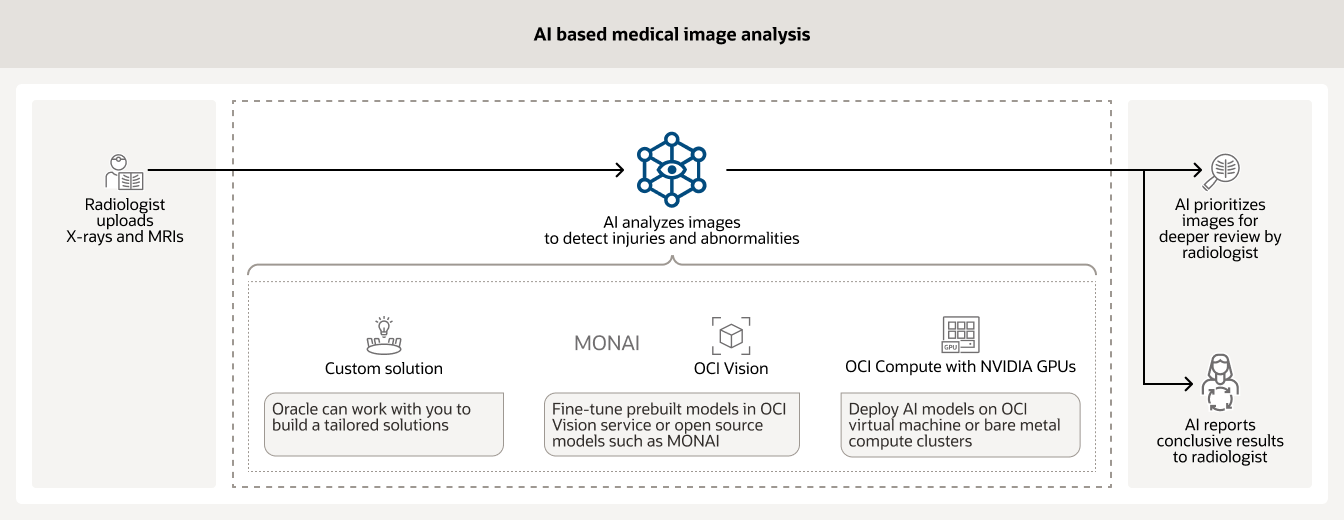
- تحليلات الصور الطبية القائمة على الذكاء الاصطناعي
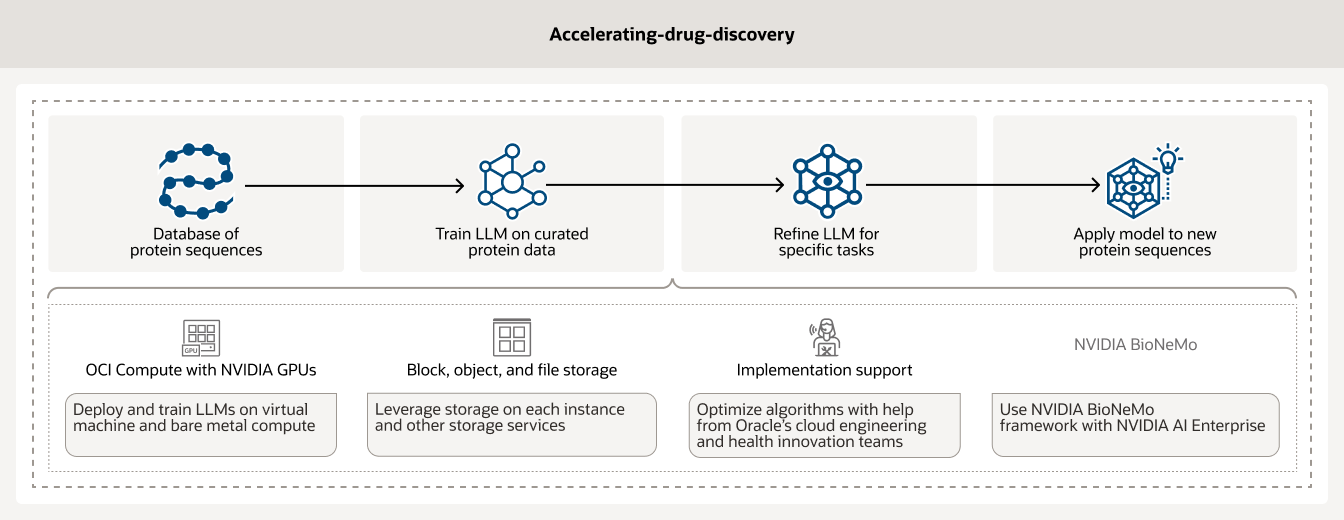
- استخدام حلول الذكاء الاصطناعي لتسريع اكتشاف العقاقير
تدريب نماذج حلول الذكاء الاصطناعي على مثيلات OCI المخصصة المدعومة بوحدات معالجة الرسومات وشبكات مجموعات الوصول المباشر للذاكرة عن بُعد وعلوم بيانات OCI.
تتطلب حماية مليارات المعاملات المالية التي تحدث كل يوم أدوات محسنة لحلول الذكاء الاصطناعي يمكنها تحليل كميات كبيرة من بيانات العملاء القديمة. تساعد نماذج حلول الذكاء الاصطناعي التي تعمل على حوسبة OCI المدعومة بوحدات معالجة الرسومات NVIDIA إلى جانب أدوات إدارة النماذج مثل علم بيانات OCI وغيرها من النماذج مفتوحة المصدر المؤسسات المالية على تخفيف الاحتيال.
غالبًا ما تستخدم حلول الذكاء الاصطناعي لتحليل أنواع مختلفة من الصور الطبية (مثل الأشعة السينية والتصوير بالرنين المغناطيسي) في المستشفى. يمكن للنماذج المدربة المساعدة في تحديد أولويات الحالات التي تحتاج إلى مراجعة فورية من قبل أخصائي الأشعة والإبلاغ عن نتائج قاطعة على الآخرين.
اكتشاف العقاقير عملية تستغرق وقتًا طويلاً ومكلفة قد تستغرق سنوات عديدة وتكلف ملايين الدولارات. من خلال الاستفادة من البنية الأساسية لحلول الذكاء الاصطناعي والتحليلات، يمكن للباحثين تسريع اكتشاف الأدوية. بالإضافة إلى ذلك، تتيح حوسبة OCI المدعومة بوحدات معالجة الرسومات NVIDIA إلى جانب أدوات إدارة سير عمل حلول الذكاء الاصطناعي مثل BioNeMo للعملاء تنظيم بياناتهم ومعالجتها مسبقًا.
قصص نجاح عملاء البنية الأساسية لحلول الذكاء الاصطناعي السحابية















ابدأ بالبنية الأساسية لحلول الذكاء الاصطناعي في OCI
الوصول إلى خبراء متخصّصين في مواد الذكاء الاصطناعي
احصل على المساعدة لبناء حل الذكاء الاصطناعي التالي أو نشر حمل العمل الخاص بك على البنية الأساسية للذكاء الاصطناعي في OCI.
-
يمكنهم الإجابة على أسئلة مثلما يلي:
- كيف يمكنني بدء استخدام Oracle Cloud؟
- ما هي أنواع أحمال عمل الذكاء الاصطناعي التي يمكنني تشغيلها على OCI؟
- ما هي أنواع خدمات الذكاء الاصطناعي التي تقدمها OCI؟
شاهد طريقة تطبيق الذكاء الاصطناعي اليوم
الدخول في حقبة جديدة من الإنتاجية مع حلول الذكاء الاصطناعي التوليدي لأعمالك. تعرّف على طريقة مساعدة Oracle العملاء على الاستفادة من الذكاء الاصطناعي المُضمن عبر مجموعة التكنولوجيا الكاملة.
-
ما الذي يمكنك تحقيقه باستخدام Oracle AI؟
- ضبط نماذج اللغات الكبيرة (LLM) بدقة في OCI
- أتمتة معالجة الفواتير
- إنشاء روبوت محادثة باستخدام RAG
- تلخيص محتوى الويب باستخدام الذكاء الاصطناعي التوليدي
- والمزيد!
الموارد الإضافية
تعرف على المزيد حول شبكات مجموعات الوصول المباشر للذاكرة عن بُعد، ومثيلات وحدات معالجة الرسومات، والخوادم بدون أنظمة تشغيل، وغيرها المزيد.
اعرف حجم المبلغ الذي يمكنك توفيره مع OCI
تسعير Oracle Cloud بسيط، مع وجود تسعير منخفض متسق في جميع أنحاء العالم، يدعم مجموعة واسعة من حالات الاستخدام. ولتقدير معدلك المنخفض، راجع مقدّر التكلفة وقم بتهيئة الخدمات لتناسب احتياجاتك.
لاحظ الفرق
- 1/4 تكاليف عرض النطاق الترددي الخارجي
- 3 أضعاف الأداء الحسابي للأسعار
- السعر المنخفض نفسه في كل منطقة
- تسعير منخفض من دون التزامات طويلة الأجل