Qu'est-ce que MongoDB ? Un guide d'expertise
Jeffrey Erickson | Senior Writer | 30 octobre 2024

MongoDB a été créé en 2007 par des développeurs qui voulaient suivre des nombres de petites transactions dans l'entreprise de service publicitaire. La nouvelle base de données, initialement appelée 10gen, contenait des données dans un simple « bucket » de documents de fichiers de type JSON, et elle pouvait évoluer très rapidement. Elle n'avait pas besoin d'un modèle de données ou d'une simultanéité d'accès aux transactions, car elle comptait simplement les impressions publicitaires et les enjeux étaient faibles.
Cependant, il s'est avéré que MongoDB apportait la simplicité que certains développeur recherchaient. Elle a été lancé sous le modèle de développement open source en 2009, avant de passer à SSPL (Server Side Public License) en 2018. Elle est devenue le magasin de données standard de facto pour de nombreuses stacks open source et compte comment clients Expedia, Lyft, eBay et biens d'autres. Découvrons son fonctionnement.
Qu'est-ce que MongoDB ?
MongoDB est une base de données orientée documents open source qui est largement utilisée dans les applications Web et mobiles modernes. Elle appartient à la catégorie des bases de données NoSQL. Autrement dit, elle adopte une approche flexible et orientée document pour stocker des données plutôt qu'une méthode relationnelle traditionnelle basée sur une table. Une grande partie de l'attrait de MongoDB est sa simplicité et la prise en compte de l'expérience développeur. Par exemple, les interactions Mongo sont définies par l'acronyme CRUD, pour create (créer), reade (lire), update (mettre à jour), delete (supprimer).
MongoDB enregistre les données dans des documents JSON qui facilitent l'utilisation des données stockées, qu'elles soient structurées, non structurées ou semi-structurées, pour différents types d'applications. Le modèle de données flexible de MongoDB permet aux développeurs de stocker des données non structurées tout en offrant une prise en charge de l'indexation pour un accès aux fichiers et une réplication plus rapides pour la protection et la disponibilité des données. Les développeurs peuvent donc concevoir des applications sophistiquées à l'aide de MongoDB.
Alors que MongoDB a été développé pour suivre les impressions sur des milliers de sites de services publicitaires, il a rapidement gagné en popularité en tant que magasin de données flexible dans le développement Web open source. Il a continuellement évolué depuis son lancement en 2007, accumulant un ensemble de fonctionnalités robuste qui comprend des requêtes ad hoc, l'indexation et l'agrégation en temps réel. Pour les développeurs, l'un des principaux avantages de MongoDB est que, par rapport aux bases de données relationnelles les plus populaires, il est intuitif et rapide à utiliser. Le type de documents JSON stockés dans MongoDB correspond aux types de données familiers trouvés dans les langages de programmation populaires, tels que les dictionnaires JavaScript ou Python. Mongo fournit également un menu complet de bibliothèques client avec prise en charge des pilotes pour la plupart des langages de programmation, y compris PHP, .Net, Java, Python, Node.js, et bien d'autres.
Comme tous les outils technologiques, MongoDB est fort dans certains domaines, mais a des points faibles dans d'autres. Il a été conçu pour suivre la publicité en ligne, qui nécessitait un accès simultané rapide, mais ne nécessitait qu'une précision transactionnelle faible et peu d'analyse en temps réel. Aujourd'hui encore, MongoDB est formé autour des principes BASE, qui sont synonymes de disponibilité, d'évolutivité et de cohérence éventuelle. Ainsi, MongoDB est généralement utilisé dans les scénarios où la haute disponibilité et l'évolutivité sont des considérations de conception principales. En revanche, pour des tâches telles que les opérations financières ou dans des environnements d'entreprise stratégiques, les développeurs optent généralement pour une base de données relationnelle. Ce type de bases de données offre des transactions ACID (atomicité, cohérence, isolation et durabilité) pour garantir la fiabilité et la cohérence des opérations de base de données. Plus récemment, cependant, le secteur de la tech propose des solutions qui peuvent donner aux développeurs le meilleur des deux mondes grâce à la simplicité de développement de JSON et aux avantages de SQL.

Comment les données circulent-elles entre les applications et la base de données MongoDB ?
- Les pilotes sont des bibliothèques spécifiques à la langue qui permettent aux applications de communiquer avec MongoDB.
- Le serveur de base de données MongoDB est l'endroit où vos données sont stockées et gérées. Il peut s'agir d'un cluster unique, réplique ou distribué.
- Les fichiers de données contiennent les documents réels dans la base de données MongoDB.
- Le système de stockage de blocs est l'endroit où les fichiers sont divisés en sections de taille fixe et stockés.
Environnements MongoDB
MongoDB est disponible dans une gamme de configurations et de niveaux de service pour répondre aux besoins des développeurs travaillant sur des projets de petites, moyennes et même grandes entreprises.
- MongoDB Atlas est une offre de base de données en tant que service de MongoDB pour déployer et gérer des bases de données sur les fournisseurs cloud. Atlas automatise de nombreuses tâches administratives, telles que la mise à l'échelle et les sauvegardes.
- MongoDB Community est une version open source de la base de données adaptée aux petits et moyens projets à la recherche d'une solution NoSQL. Comme il est open source, il est adapté à la modification et à l'innovation, et il offre aux développeurs une communauté robuste pour trouver de l'aide. Cependant, la version communautaire ne dispose pas d'un support officiel et d'accords de niveau de service (SLA), dispose de moins d'options de sécurité et ne propose que des outils de gestion limités.
- MongoDB Enterprise Advanced est la version premium pour les entreprises de MongoDB Community. Elle offre des options de sécurité améliorées et un moteur de stockage en mémoire pour prendre en charge les cas d'utilisation de niveau entreprise.
Points à retenir
- MongoDB est une base de données NoSQL populaire utilisée pour stocker des données structurées, semi-structurées et non structurées.
- Au lieu d'utiliser des tables, comme dans une base de données relationnelle traditionnelle, MongoDB stocke les données dans des documents JSON organisés en collections.
- Étant donné que MongoDB ne nécessite pas de schémas rigides, il permet un modèle de données flexible qui peut évoluer pour correspondre aux modifications apportées aux fonctionnalités de l'application.
- MongoDB a été conçu à l'origine pour un stockage et un rappel rapides dans l'entreprise de service publicitaire, avec peu de considération pour la cohérence des transactions ou l'analyse rapide des données. Des développements ultérieurs, tels que les fonctionnalités de sharding, étendent les fonctionnalités de MongoDB.
- Comme MongoDB offre des forces différentes d'une base de données relationnelle traditionnelle, les développeurs cherchent souvent des moyens d'obtenir le meilleur des deux approches.
Ce qu'il faut savoir sur MongoDB
MongoDB est une base de données NoSQL qui utilise un modèle de données orienté document, où chaque enregistrement est un document stocké dans une collection, au lieu des lignes et des colonnes communes aux bases de données relationnelles populaires, telles que MySQL.
MongoDB stocke des documents JSON à l'aide d'un format appelé BSON ou JSON binaire. La nature non relationnelle de ces documents signifie qu'ils peuvent stocker (et que la base de données peut traiter) des données d'application structurées ainsi que des données semi-structurées et non structurées. Contrairement aux bases de données relationnelles, MongoDB n'utilise pas de schémas rigides. Au lieu de cela, les documents sont flexibles et peuvent contenir des tableaux et des documents imbriqués, ce qui permet un stockage de données complexe et hiérarchique.
Lors de la gestion d'un jeux de données extrêmement volumineux, documentez les bases de données, telles que MongoDB, il est possible d'évoluer ou de distribuer les données sur plusieurs nœuds ou clusters à l'aide d'une technique appelée sharding. Ce modèle permet un stockage et un rappel rapides. Cette architecture est logique étant donné que MongoDB a été créé pour la diffusion d'annonces, où potentiellement des millions d'annonces pourraient avoir besoin d'être appelées sur des milliers de sites Web à tout moment. Il n'était pas nécessaire d'analyser une publicité par rapport à une autre, ce qui permettait de répartir et de séparer physiquement les données.
Les bases de données de documents hiérarchiques sont très rapides pour les opérations de lecture, mais l'analyse des données peut être lente car les systèmes doivent analyser les données dans toutes les entités imbriquées. En revanche, les bases de données relationnelles stockent leurs données dans des tables distinctes, et un seul « objet » peut être référencé dans de nombreuses tables de la base de données, ce qui permet des opérations d'analyse plus efficaces à grande échelle. Compte tenu de ces points forts différents, les équipes de développement opteront généralement pour le meilleur système de gestion des données pour les besoins actuels de leur application. Elles peuvent également choisir une base de données multimodale qui fournit un accès SQL complet aux données de document relationnel et JSON, ainsi qu'à de nombreux autres types de données.
Différence entre ACID et BASE
Votre choix dépend des besoins de votre application.
| ACID (atomicité, consistance, isolement, durabilité) | BASE (basiquement disponible, état souple, éventuellement cohérent) |
|---|---|
|
Atomicité : garantit qu'une transaction entière est traitée comme une seule unité. Soit toutes les modifications réussissent, soit elles échouent. Cela empêche les mises à jour partielles qui pourraient laisser vos données dans un état incohérent. Cohérence : garantit que la base de données passe d'un état valide à un autre après une transaction. Applique les règles métier et l'intégrité des données. Isolement : garantit que les transactions simultanées n'interfèrent pas les unes avec les autres. Chaque transaction semble être exécutée isolément, même si plusieurs transactions se produisent simultanément. Durabilité : une fois la transaction validée, les modifications sont écrites dans un stockage permanent et ne sont pas affectées par des défaillances du système, telles que des pannes. |
Basiquement disponible : se concentre sur l'optimisation de la disponibilité des données. Le système s'efforce de rester opérationnel même en cas de panne partielle, ce qui permet à la plupart des opérations de lecture et d'écriture de se poursuivre. État souple : la cohérence des données n'est pas immédiatement garantie après une opération d'écriture. Il peut y avoir un léger décalage avant que les modifications ne soient reflétées dans toutes les répliques, ce qui entraîne des incohérences temporaires. Cohérence à terme : au fil du temps, la cohérence est assurée via des processus en arrière-plan qui synchronisent les modifications entre les répliques. |
|
Avantages: Une grande intégrité des données et une forte cohérence rendent ACID idéal pour les applications qui exigent de la précision, telles que les transactions financières. |
Avantages: La haute disponibilité et l'évolutivité font de BASE une solution idéale pour les applications nécessitant une disponibilité et une réactivité élevées, en particulier dans les systèmes distribués. Les exigences de cohérence simplifiées permettent des vitesses d'écriture plus rapides et une meilleure évolutivité. |
|
Inconvénients: La surcharge de performances signifie que le maintien des garanties ACID peut ralentir les vitesses d'écriture. Les exigences de cohérence strictes peuvent devenir difficiles à gérer dans des environnements hautement évolutifs. |
Inconvénients: Des incohérences temporaires peuvent survenir lors de la synchronisation des données, ce qui rend BASE moins adapté aux applications où une intégrité stricte des données et une cohérence immédiate sont essentielles. |
Comment fonctionne MongoDB ?
MongoDB stocke les données dans des collections, l'équivalent des tables des bases de données relationnelles. Chaque collection contient plusieurs documents, dont la structure peut varier. Il n'est pas nécessaire de déclarer la structure des documents dans le système, car les documents sont auto-descriptifs, ce qui signifie que chaque document contient des métadonnées décrivant chaque champ du document.
Pour améliorer les performances, MongoDB prend en charge l'indexation sur tous les champs d'un document. Les index prennent en charge l'exécution efficace des interrogations et peuvent inclure des index principaux et secondaires. Le langage de requête de MongoDB prend en charge les opérations CRUD (créer, lire, mettre à jour, supprimer) et permet une agrégation complexe, la recherche de texte et les requêtes géospatiales. Pour améliorer les temps de réponse, MongoDB fournit une structure d'agrégation qui permet aux développeurs de configurer un traitement de données complexe côté serveur. Cela signifie qu'il peut effectuer des analyses sur le cluster où résident les données, sans avoir à les déplacer vers une autre plateforme, comme avec Apache Spark ou Hadoop. Cela peut réduire la quantité de données transférées vers et depuis les clients.
MongoDB s'efforce de fournir une haute disponibilité et d'améliorer les performances en prenant en charge les jeux de données de réplique. Les répliques peuvent être utilisées pour l'équilibrage de charge en répartissant les opérations de lecture et d'écriture sur toutes les instances. Ces ensembles de répliques assurent également la redondance et augmentent la disponibilité des données via plusieurs copies de données sur différents serveurs de base de données. En cas de panne matérielle ou de maintenance, les ensembles de répliques permettent à MongoDB de fournir un basculement automatique et une redondance des données.
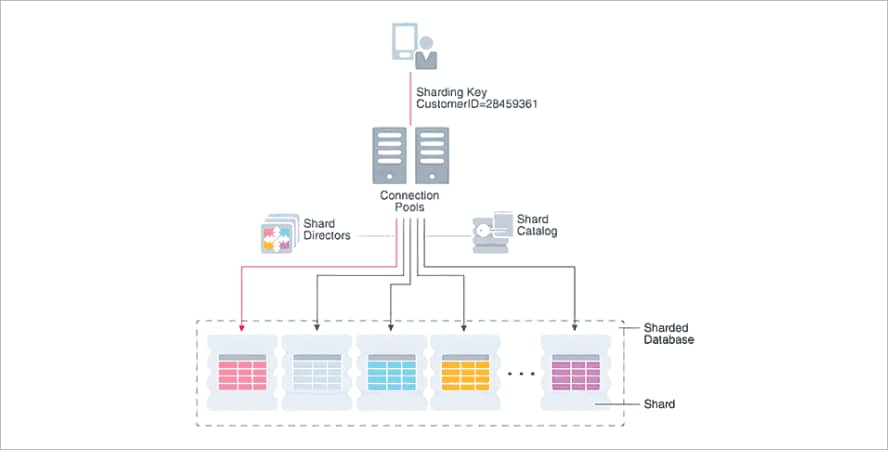
Pour des raisons d'évolutivité, MongoDB prend en charge le redimensionnement horizontal via le sharding, qui est un moyen de distribuer des données entre plusieurs bases de données sur plusieurs machines. Un cluster distribué peut être constitué de plusieurs ensembles de répliques. Le sharding est configuré en définissant une clé de shard, qui détermine la façon dont les données sont distribuées entre les shards. Cette technique peut aider à gérer des jeux de données volumineux et des opérations à haut débit en divisant le jeu de données et en le chargeant sur plusieurs serveurs.
Fonctionnement du sharding
Chaque shard est une instance de base de données indépendante qui héberge des sous-ensembles de données d'une base de données distribuée.
Différence entre MongoDB et les systèmes de gestion de base de données relationnelle
Chaque type de base de données (relationnelle, telle que MySQL, Postgres et Oracle Database, ou orientée document, telle que CouchDB, DynamoDB et MongoDB) présente des avantages et des points faibles. Le choix entre ces deux types de base de données dépend généralement des exigences et contraintes spécifiques de l'application en cours de développement.
Un système de gestion de base de données relationnelle (SGBDR) utilise un langage SQL (Structured Query Language), tandis que le format orienté document de MongoDB utilise des API de banque de documents. Toutefois, MongoDB Query Language (MQL) utilise un langage de type JavaScript avec des opérations telles que la création, la lecture, la mise à jour et la suppression de documents.
MongoDB n'a pas de concept de tables et de lignes et n'a pas de schéma. Il y a donc moins de structure à définir avant que la base de données puisse être utilisée. Cependant, sans schéma central, chaque application qui accède aux collections doit comprendre le document. Le « schéma » se trouve donc dans le code de l'application et n'est pas défini dans la base de données. Si une application modifie le schéma, d'autres applications peuvent se briser. Par rapport aux bases de données relationnelles, où un schéma est essentiellement un modèle de base pour le SGBDR et où l'organisation et l'interrelation des données sont explicitement définies, MongoDB ne dispose pas du concept inhérent de relations entre les données.
La flexibilité des banques de données est remarquable, car MongoDB utilise différents formats pour les données telles que les banques de valeurs clés, les graphiques et les documents, et les structures de données peuvent changer au fil du temps. Cela diffère d'un SGBDR, qui utilise des définitions, des hiérarchies et des procédures de validation strictes basées sur ces dernières pour garantir l'intégrité des données.
Bien que la configuration d'une instance MongoDB de base soit simple, la configuration et la maintenance d'un cluster MongoDB distribué à grande échelle avec sharding et répliques peuvent être complexes et nécessitent une bonne compréhension de son architecture et de ses options de configuration.
Différences clés
| Relationnelle | MongoDB | |
|---|---|---|
| Modèle de données | Utilise des tables avec des lignes et des colonnes fixes, et les données sont structurées dans un schéma prédéfini. | Utilise des ensembles de documents, qui sont des structures de type JSON avec des schémas dynamiques. |
| Flexibilité des schémas | Nécessite un schéma prédéfini qui doit être configuré pour pouvoir ajouter des données. | A un schéma dynamique. De nouveaux champs peuvent être ajoutés à un document sans affecter tous les autres documents de la collection. |
| Langue de requête | Utilise le langage SQL, qui est très puissant pour les interrogations complexes, pour définir et manipuler des données. | Utilise un langage de requête basé sur des documents qui est considéré comme plus intuitif mais moins complet et polyvalent que SQL. |
| Mise à l'échelle | Traditionnellement, elle évolue verticalement, ce qui augmente la puissance de la machine existante, bien que des fonctionnalités matures, telles que le sharding et Oracle Real Application Clusters, prennent en charge le redimensionnement horizontal. | Conçu pour évoluer horizontalement sur plusieurs machines à l'aide du sharding, qui distribue les données sur un cluster de machines. |
| Transactions | Prend en charge les transactions multilignes et est compatible ACID, ce qui le rend adapté aux applications où aucune donnée ne peut être perdue ou endommagée. | Prend en charge les transactions multidocument, mais est connu pour être moins robuste que la plupart des bases de données relationnelles traditionnelles, en particulier sur les données distribuées. |
| Performances | Conçue pour garantir des transactions précises, mais les performances peuvent être inférieures pour les volumes de données volumineux. Cependant, les performances d'analyse sont généralement meilleures. | Conçu pour des performances de lecture élevées sur de grands volumes de données. |
Pourquoi utiliser MongoDB ?
MongoDB est adapté à un large éventail d'utilisations, des applications CRUD simples, telles qu'une application de blogs ou de prise de notes, aux plateformes complexes, telles qu'Amazon Prime. MongoDB est souvent sélectionné pour les systèmes de gestion de contenu (CMS), les applications de jeu où la synchronisation des données doit être rapide et les données biométriques sur les soins de santé, parmi de nombreux autres cas d'utilisation. Sa polyvalence en a fait une pierre angulaire des piles de développement open source populaires, telles que MEAN et MERN.
Choisissez-le quand vous avez besoin de :
- Flexibilité. Le format de document JSON de MongoDB offre un moyen simple et intuitif de représenter des structures de données hiérarchiques qui nécessiteraient autrement des jointures complexes via des requêtes SQL.
- Disponibilité. Les fonctionnalités de base de données distribuée de MongoDB offrent une haute disponibilité, même avec des jeux de données volumineux et en constante évolution.
- Évolutivité. MongoDB est conçu pour collecter, traiter et analyser des jeux de données volumineux, en évolution rapide et divers.
- Performances . L'optimisation des performances par le biais de méthodes telles que la réplication, le sharding et d'autres, fait de MongoDB un choix viable pour les applications volumineuses dans des domaines tels que les médias et le divertissement.
- Compatibilité. Les documents de type JSON de MongoDB offrent une compatibilité facile avec les types de données familiers trouvés dans les langages de programmation populaires. En outre, les bibliothèques client MongoDB offrent des pilotes pour la plupart des langages de programmation, tels que PHP, .Net, JavaScript, et bien d'autres.
- Communauté de soutien . MongoDB est un magasin de données standard de facto dans de nombreuses piles de développement open source, où le soutien de la communauté est abondant.
Fonctionnalités de MongoDB
MongoDB est devenu populaire auprès des développeurs en partie grâce à son API intuitive, son modèle de données flexible et ses fonctionnalités qui incluent :
- Requêtes ad hoc. MongoDB prend en charge les requêtes de champ, de plage et d'expression régulière qui peuvent renvoyer des documents entiers, des champs de documents spécifiques ou des échantillons aléatoires de résultats.
- Indexage. MongoDB prend en charge plusieurs types d'index différents : champ unique, composé (plusieurs champs), clé multiple (tableau), géospatial, texte et hachage.
- Réplication. MongoDB offre une haute disponibilité avec des ensembles de répliques comprenant au moins deux copies des données. Les écritures sont gérées par la réplique principale, tandis que toute réplique peut traiter les demandes de lecture. Si la réplique principale échoue, une réplique secondaire est promue pour devenir la réplique principale.
- Évolutivité. Le redimensionnement des bases de données MongoDB est amélioré grâce au sharding, car les clusters stockent uniquement une partie des données d'une collection. Les clés de sharding déterminent la distribution de ces données.
- Équilibrage de charges. MongoDB peut évoluer verticalement et horizontalement, et grâce aux clusters distribués, l'équilibrage de charge peut être géré par la structure de base de la base de données. La réplication peut être utilisée pour réduire les charges sur les serveurs principaux.
- Stockage de fichiers. Les données sont stockées dans des documents qui sont facilement mappés avec des objets dans la plupart des langages de programmation, ce qui facilite l'accès aux applications.
- Traitement par lots. Le traitement des données peut être effectué de plusieurs façons. Parfois, cela se fait dans les documents eux-mêmes, d'autres fois avec une méthode d'écriture en masse qui réduit les opérations réseau.
Avantages de MongoDB
La popularité de MongoDB au sein de la communauté open source s'explique par son caractère plus intuitif et évolutif. Ces avantages comprennent :
- Facilité d'utilisation pour les développeurs. Les développeurs choisissent souvent MongoDB parce qu'il est facile de télécharger ou d'accéder au cloud, ce qui signifie qu'ils peuvent commencer rapidement, en partie parce qu'il est plus facile de travailler avec des documents plutôt que de créer un modèle de données et d'utiliser des tables.
- Efficacité. JSON offre un certain nombre d'efficacité, avec de petits fichiers de documents et un contenu lisible par l'homme. MongoDB encode les documents au format binaire (BSON), qui est plus compact et plus rapide à analyser que le texte brut.
- Schémas flexibles. Le modèle de données de document de MongoDB permet aux schémas flexibles et auto-descriptifs, permettant aux champs de varier d'un document à l'autre.
- Langage de requête simple. Le langage de requête MQL (MongoDB Query Language) est conçu pour être facile à utiliser pour les développeurs, ce qui permet aux requêtes et aux index complexes d'accélérer les requêtes couramment utilisées.
- Cloud natif. MongoDB Atlas est une base de données native du cloud, elle reçoit donc des mises à jour fréquentes et s'adapte rapidement aux nouvelles technologies. Son utilisation facilite également la migration d'une application vers le cloud.
Inconvénients de MongoDB
Bien que MongoDB offre de nombreux avantages, en particulier pour les applications nécessitant de la flexibilité et des performances élevées dans le cadre de volumes de données importants, il présente de nombreux inconvénients potentiels.
- Prise en charge des transactions Le support transactionnel par MongoDB n'est pas aussi mature ou robuste que celui des bases de données relationnelles traditionnelles. Les transactions complexes, en particulier celles qui couvrent plusieurs opérations, peuvent ne pas être aussi performantes et peuvent être difficiles à implémenter dans MongoDB.
- Cohérence des données Étant donné que MongoDB recourt à la « cohérence finale » (eventual consistency) pour les ensembles de répliques, tous les utilisateurs ne lisent pas toujours les mêmes données en même temps. Pour les applications qui exigent une forte cohérence, cela peut être un inconvénient sérieux.
- Opérations de jointure. MongoDB ne prend pas en charge les jointures comme le font les bases de données SQL. Cependant, il offre des options qui remplissent une fonction similaire, bien qu'elles soient généralement moins efficaces et puissent entraîner des requêtes plus complexes et des performances plus lentes, en particulier lorsqu'il s'agit de relations complexes entre les documents.
- Utilisation de la mémoire. MongoDB stocke les données et les index les plus fréquemment utilisés dans la RAM, de sorte que ses performances dépendent fortement de la quantité de RAM suffisante. Par conséquent, une base de données MongoDB peut consommer plus de ressources de mémoire et, éventuellement, plus de matériel que les autres bases de données.
- Surcharge de stockage. Le paradigme de document autonome utilisé par MongoDB peut entraîner des exigences de stockage plus élevées que les tables hautement normalisées des bases de données relationnelles. En outre, le schéma dynamique de MongoDB peut entraîner une redondance et une fragmentation des données qui peuvent augmenter l'utilisation du stockage et les coûts.
- Limites d'indexation. MongoDB prend en charge de nombreuses options d'indexation, mais le maintien d'un grand nombre d'index peut dégrader les performances en écriture. Il n'est tout simplement pas conçu pour les écritures fréquentes, car chaque opération d'écriture peut avoir besoin de mettre à jour plusieurs index, ce qui réduit souvent les performances des requêtes par rapport aux performances d'écriture.
- Coûts. Dans les scénarios nécessitant une haute disponibilité et une mise à l'échelle horizontale, le coût associé à l'exécution et à la maintenance d'un cluster MongoDB, en particulier dans les environnements cloud, peut être significatif. Le besoin de beaucoup de RAM et de stockage peut également augmenter les coûts. Cela est particulièrement vrai dans les situations de haute disponibilité où les bases de données de répliques nécessitent un nombre égal de ressources.
Compatibilité MongoDB
MongoDB est une base de données NoSQL qui fonctionne bien au sein de cet écosystème, mais elle est également conçue pour interagir avec d'autres types de systèmes de gestion de base de données via divers outils et connecteurs d'intégration de données. Cet ensemble d'outils inclut une infrastructure ETL (extraction, transformation, chargement) pour extraire et migrer des données à partir de MongoDB, et inversement. Cela est utile pour envoyer des données à une base de données relationnelle à des fins de reporting et d'analyse de données complexes. Les applications MongoDB peuvent également communiquer sur différentes plateformes de base de données à l'aide d'API REST.
Exécution de workloads MongoDB dans Oracle Autonomous Database
Un bon exemple de compatibilité MongoDB est l'API Oracle Database API for MongoDB, qui permet aux développeurs d'utiliser les pilotes et outils open source de MongoDB connectés à une instance Oracle Autonomous JSON Database. Cela leur donne accès aux fonctionnalités multimodèles d'Oracle et les aide à éviter de déplacer des données vers une base de données distincte pour les analyses, le machine learning et l'analyse spatiale. Considérez Autonomous JSON Database comme une alternative multimodale à MongoDB Atlas. Souvent, les applications nécessitent peu, voire pas, de modifications.
Migration de workloads MongoDB vers Autonomous JSON Database
Au lieu d'accéder aux fonctionnalités MongoDB via des API, les développeurs peuvent simplement migrer leurs workloads centrés sur JSON vers une Oracle Autonomous JSON Database sur Oracle Cloud Infrastructure (OCI). Cela fournit un service de base de données orientée documents cloud pour les applications centrées sur JSON qui dispose d'API de documents de type NoSQL (Simple Oracle Document Access, ou SODA, et Oracle Database API for MongoDB), d'une évolutivité sans serveur, de transactions ACID hautes performances, d'une sécurité complète et d'une tarification à l'utilisation faible. Il n'y a pas de temps d'inactivité car la migration de MongoDB vers Oracle Autonomous JSON Database est réalisée avec Oracle Cloud Infrastructure (OCI) GoldenGate.
Introduction à Autonomous Database
Les utilisateurs MongoDB disposent désormais d'un moyen plus polyvalent de créer des applications centrées sur JSON. Oracle Autonomous Database offre aux développeurs la flexibilité nécessaire pour répondre aux demandes de l'entreprise à l'aide d'une plateforme de données unique qui peut répondre à tous leurs besoins. Les développeurs peuvent ainsi utiliser SQL, des documents JSON, des graphiques, des géospatiaux, du texte et des vecteurs dans une seule base de données pour créer rapidement de nouvelles fonctionnalités.
En outre, une nouvelle fonctionnalité révolutionnaire d'Oracle Database, la dualité relationnelle JSON, offre les avantages des tables relationnelles et des documents JSON, sans les compromis de l'un ou l'autre modèle.
Autonomous Database offre des services d'IA intégrés et le machine learning (ML) dans la base de donnée pour améliorer les applications grâce à l'analyse du texte et des images, à l'identification vocale ou aux recommandations personnalisées. En outre, Autonomous Database Select AI traduit automatiquement les instructions en langage naturel en requêtes de base de données et vous permet d'avoir une conversation contextuelle, sans codage personnalisé ni opérations manuelles via une interface complexe. De plus, la base de données étant entièrement autonome, elle permet aux équipes de développement de rester concentrées sur la création d'applications en garantissant la disponibilité et la protection des données grâce à des mesures de sécurité automatisées et à une surveillance continue.
Vous pouvez commencer gratuitement dès aujourd'hui et même essayer un atelier pour apprendre à utiliser SQL, JSON et Oracle Graph dans la même application.
Avec des cas d'utilisation comprenant des plateformes de commerce électronique, des applications IoT, etc., MongoDB a prouvé sa polyvalence dans tous les secteurs. Sa capacité à gérer divers types de données et à prendre en charge des requêtes complexes la positionne comme un composant capable des piles de technologies modernes. Alors que les entreprises cherchent à extraire une valeur maximale de leurs données, MongoDB sera essentiel au succès.

Les développeurs et leurs collègues du business peuvent bénéficier d'applications natives du cloud spécialement conçues pour optimiser l'agilité, l'évolutivité et l'efficacité. En savoir plus et découvrir 10 autres façons d'améliorer le cloud.
FAQ sur MongoDB
Quelle est la différence entre SQL et MongoDB ?
MongoDB enregistre les données non structurées, ce qui ne convient pas à un langage SQL (Structured Query Language).
MongoDB est-il un langage de back-end ?
Non, mais il peut être utilisé dans le cadre d'une application Web back-end.
MongoDB est-il un langage ou un framework ?
Il s'agit d'un système de gestion de base de données qui utilise des données non structurées stockées dans des documents plutôt que dans des tables.