Streaming 常见问题解答
常见问题
什么是 Oracle Cloud Infrastructure Streaming?
Oracle Cloud Infrastructure (OCI) Streaming 是一个全托管、可扩展的持久消息传递解决方案,可用于从多个来源摄取海量连续数据流以便用户实时使用和处理。在所有受支持的 Oracle Cloud Infrastructure 区域中,您都可以使用 Streaming。有关详细列表,请访问区域和可用性域页面。
为何应使用 Streaming?
Streaming 是一种无服务器服务,可分流基础设施管理工作负载,包括数据流处理所需的网络、存储和配置。您不必担心基础设施的供应、持续维护或安全修补。Streaming 服务可在三个可用性域之间同步复制数据,从而提供高可用性和数据持久性。在具有单一可用性域的区域,数据将跨三个故障域进行复制。
如何使用 Streaming?
Streaming 可轻松收集、存储和处理数百个数据源实时生成的数据。从消息传递到复杂的数据流处理,其使用场景几乎是无限的。下面是 Streaming 的一些使用场景:
- 消息传递:使用 Streaming 来解耦大型系统的组件。生产者和消费者可以使用 Streaming 作为异步消息总线,并按照自己的步调独立行动。
- 指标和日志采集:使用 Streaming 替代传统的文件抓取方法,从而快速捕获关键运营数据,为索引编制、分析和可视化做好准备。
- Web 或移动活动数据采集:使用 Streaming 来从网站或移动应用获取活动数据,例如页面浏览量、搜索量,或者其它用户操作。您可以使用此信息来进行实时监视和分析,以及在数据仓库系统中进行脱机处理和报告。
- 基础设施和应用事件处理:使用 Streaming 作为云组件报告生命周期事件的统一入口,以便进行审计、核算以及相关活动。
如何快速开始使用 Streaming?
您可以按以下步骤来使用 Streaming:
- 使用 Oracle Cloud Infrastructure Console 或 CreateStream API 操作来创建一个流。
- 配置生产者以将消息发布至流。请参阅发布消息。
- 创建使用者以读取和处理流中的数据。请参阅使用消息。
或者,您也可以使用 Kafka API 来生成和使用流。有关更多信息,请参阅通过 Apache Kafka 使用 Streaming。
Streaming 的服务限额是多少?
通过在流中添加分区,Streaming 的吞吐量可无限扩展。然而,在使用 Streaming 时应当牢记一些限制:
- 一个流中的邮件的最长保留期为 7 天。
- 一个流中可生成的唯一消息最大为 1 兆字节 (MB)。
- 每一个分区每秒可处理高达 1 MB 吞吐量,写入请求数量不受任何限制。
- 每一个分区支持最高每秒 1 MB 的总数据写入速率和每秒 2 MB 的读取速率。
Streaming 与基于队列的服务相比如何?
Streaming 可提供基于流的语义。流语义可为每一个分区提供严格的顺序保证、消息重播性、客户端游标以及大规模水平吞吐量。相比之下,队列无法提供这些功能。当使用 FIFO 时,队列可以提供顺序保证,但这需要特殊设计且会增加一部分性能开销。
主要概念
什么是流?
流是一种分区的、仅追加的消息日志,生产者应用可以在其中写入数据,而使用者应用可以从中读取数据。
什么是流池?
流池是一种用于组织和管理流的分组。流池支持跨多个流共享配置设置,可简化操作和运营。例如,用户可以在流池上共享自定义加密密钥等安全设置,对池内所有流的数据进行加密。借助流池,您还可以限制对其中所有流的互联网访问,从而为流创建 Private Endpoint。对于使用 Streaming 的 Kafka 兼容性功能的客户,流池可充当虚拟 Kafka 集群的根,将针对该虚拟集群的所有操作限制在该流池的范围之内。
什么是分区?
分区是一个基本吞吐量单位,您可以使用分区在流中进行水平扩展,实现并行消息生产和使用。一个分区提供 1 MB/秒的数据输入和 2 MB/秒的数据输出。在创建流时,您可以根据应用的吞吐量需求来指定分区数量。例如,您可以创建一个具有 10 个分区的流,这样可以在流中实现 10MB/秒的输入吞吐量和 20MB/秒的输出吞吐量。
什么是消息?
消息存储在流中,一条消息是一个 Base64 编码数据单元。一个流的一个分区中可生成的最大消息为 1 MB。
什么是键?
键是一种用于对相关消息进行分组的标识符。具有相同键的消息将被写入同一分区。Streaming 可确保特定分区的所有使用者始终按照与写入时完全相同的顺序读取该分区中的消息。
什么是生产者?
生产者指可将消息写入到流的客户端应用。
什么是使用者和使用者组?
使用者指可从一个或多个流中读取消息的客户端应用。一个使用者组由一组可协调一个流中所有分区的消息的实例构成。在任何特定时间,来自特定分区的消息只能由组中的单一使用者使用。
什么是游标?
游标是指向流中某个位置的指针。该位置既可以是指向一个分区中特定偏移量或时间,也可以是指向组当前位置的指针。
什么是偏移?
在一个分区中,每条消息都有一个偏移标识符。使用者可以从特定偏移量开始读取消息,也可以从所选择的任何偏移点进行读取。使用者还可以提交最新处理的偏移,这样可以在停止工作后重新开始工作时继续工作,而不会重播或丢失消息。
安全
使用 Oracle Cloud Infrastructure Streaming 时的数据安全性如何?
默认情况下,Streaming 将同时对数据进行动态和静态加密。同时,Streaming 与 Oracle Cloud Infrastructure Identity and Access Management (IAM) 全面集成,您可以使用访问策略来选择性地为用户和用户组授予权限。在使用 REST API 时,您还可以通过支持 HTTPS 协议的 SSL 端点,从 Streaming 中 PUT 和 GET 数据。此外,Streaming 还提供全面的租户级数据隔离,不会产生任何“坏邻居”问题。
我是否可以使用自己的主密钥集对流中的数据进行加密?
Streaming 不仅对数据进行静态和动态加密,同时还能确保消息完整性。您可以选择由 Oracle 来执行数据加密,或者在需要满足特定的合规性或安全性标准时,使用 Oracle Cloud Infrastructure Vault 来安全存储和管理您自己的加密密钥。
在创建流池之后可以对其进行哪些安全设置?
您可以随时编辑流池的数据加密设置,在“Oracle 密钥加密”和“客户密钥加密”之间切换。在 Streaming 中,您可以无限次数地执行该活动。
如何管理和控制对流的访问?
Streaming 与 Oracle Cloud Infrastructure IAM 全面集成。每个流都会分配一个隔间。用户可以指定基于角色的访问控制策略,这些策略可用于描述租户、隔间或单个流级别的细粒度规则。
指定访问策略的形式如下:"Allow <subject> to <verb> <resource-type> in <location> where <conditions>"。
Kafka 用户需要对 Streaming 使用哪种身份验证机制?
Kafka 协议的身份验证使用身份验证令牌和 SASL/PLAIN 机制。您可以在控制台用户详细信息页面上生成令牌。有关详细信息,请参阅使用身份令牌。我们建议您创建一个专用组/用户,并为该组授予在适当的隔间或租户中管理流的权限。随后,您可以为所创建的用户生成身份验证令牌,并在 Kafka 客户端配置中使用。
是否可以在不使用公共 IP 的情况下从我的 Virtual Cloud Network (VCN) 对 Streaming API 进行专有访问?
Private Endpoint 将限制对租户内指定的 Virtual Cloud Network (VCN) 的访问,因此无法通过互联网访问其中的流。Private Endpoint 会将 VCN 内的专有 IP 地址与流池相关联,避免 Streaming 流量遍历互联网。要为 Streaming 创建 Private Endpoint,请在创建流池时设置使用专有子网访问 VCN。有关更多信息,请参阅关于 Private Endpoint 和 VCN 与子网。
集成
如何结合使用 Oracle Cloud Infrastructure Streaming 与 Oracle Cloud Infrastructure Object Storage?
您可以将流的内容直接写入 Object Storage 桶,这通常可以将数据长期持久存储在流中。这可以使用 Kafka Connect for S3 和 Streaming 来实现。有关更多信息,请参阅从 Oracle Streaming Service 发布到 Object Storage 博客。
如何结合使用 Streaming 与 Oracle Autonomous AI Database?
您可以从 Oracle Autonomous AI Transaction Processing 实例的表中提取数据。有关更多信息,请参阅使用 Kafka Connect、Oracle Streaming Service 和 Autonomous Database 博客。
如何结合使用 Streaming 与 Micronaut?
您可以使用 Kafka SDK 从 Streaming 生成和使用消息,还可以使用 Micronaut 对 Kafka 的内置支持。有关更多信息,请参阅通过 Micronaut 的 Kafka 支持和 Oracle Streaming 服务轻松实现消息传递博客。
如何使用 Streaming 从 MQTT 代理提取 IoT 数据?
有关更多信息,请参阅将来自 MQTT 代理的物联网数据提取到 OCI-Oracle Streaming Service、OCI-Kafka Connect Harness 和 Oracle Kubernetes 引擎博客。
Oracle GoldenGate for Big Data 与 Streaming 兼容吗?
Oracle GoldenGate for Big Data 现已通过认证,能够与 Streaming 集成。有关更多信息,请参阅 Oracle GoldenGate for Big Data 文档中的连接 Oracle Streaming Service。
是否可以直接将数据从 Streaming 提取到 Oracle Autonomous AI Lakehouse?
您需要使用 Kafka JDBC Sink Connect 来直接将流数据传输到 Oracle Autonomous AI Lakehouse。
- 使用 Kafka Connect、Oracle Streaming Service 和 Autonomous Database 博客文章阐述了如何使用 Kafka Connect 源连接器将 Oracle Autonomous AI Lakehouse 数据推送到流。对于反向操作,请使用 Sink 连接器。
- OSS 数据近乎实时地传输至 ADW 博客文章阐述了如何使用包含对象存储路径的外部表从 Oracle Autonomous AI Lakehouse 获取数据。
定价
Oracle Cloud Infrastructure Streaming 如何收费?
Streaming 采用简单的即用即付定价模式,可确保您只为所使用的资源付费。定价维度包括
- GET/PUT 请求价格:数据传输量 (GB)
- 存储价格(取决于数据的保留小时数):每小时存储量 (GB)
有关最新定价信息,请参阅 OCI Streaming 产品页面。
如果我未使用服务,那么是否会向我收取供应费用?
在 Streaming 的定价模式下,您只需在默认服务限额范围内使用该服务时付费。
将数据移入和移出 Streaming 是否需要额外付费?
将数据移入和移出 Streaming 不需要额外付费。此外,用户也可以利用强大的 Service Connector Hub,以无服务器方式将数据移入和移出 Streaming,这同样不需要额外付费。
可以通过免费套餐使用 Streaming 吗?
目前,免费套餐并不包含 Streaming。
管理 Oracle Cloud Infrastructure 流
访问 Streaming 需要什么样的 IAM 权限?
Identity and Access Management 允许您控制哪些人有权访问您的云技术资源。要使用 Oracle Cloud Infrastructure 资源,无论您使用 Console 还是 SDK、CLI 或其它工具的 REST API,都需要在管理员编写的策略中为您指定所需的访问类型。访问策略的指定形式如下:
Allow <subject> to <verb> <resource-type> in <location> where <conditions>
租户的管理员可以使用策略
Allow group StreamAdmins to manage streams in tenancy
这将允许指定的 StreamAdmins 组执行所有操作,包括创建、更新、列出以及删除流及其相关资源。但是,您始终可以指定更加精细化的策略,确保只有组中的选定用户才有资格执行可针对特定流执行的部分活动。如果您刚开始接触策略,请参阅策略快速入门和常见策略。如果您希望更加深入地了解如何为 Streaming 编写策略,请参阅 IAM 策略参考中的 Streaming 服务详细信息。
如何自动大规模部署流?
您可以使用 Oracle Cloud Infrastructure Resource Manager 或适用于 Oracle Cloud Infrastructure 的 Terraform 提供程序来供应流及其所有相关组件,例如 IAM 策略、分区、加密设置等。有关 Terraform 提供程序的详细信息,请参阅关于 Streaming 的 Terraform 主题。
如何确定所需要的分区数量?
在创建流时,您需要指定流的分区数量。应用的预期吞吐量可以帮助您确定流的分区数量。您可以将平均消息大小乘以每秒写入的最大消息数来估算预期吞吐量。由于单一分区限制为每秒 1 MB 的写入速率,因此更高的吞吐量需要额外的分区来避免节流。为了帮助您应对应用峰值需求,我们建议分区规模略高于最大吞吐量。
如何在流中创建和删除分区?
您可以使用 Console 或采用程序化方式,在创建流时创建分区。
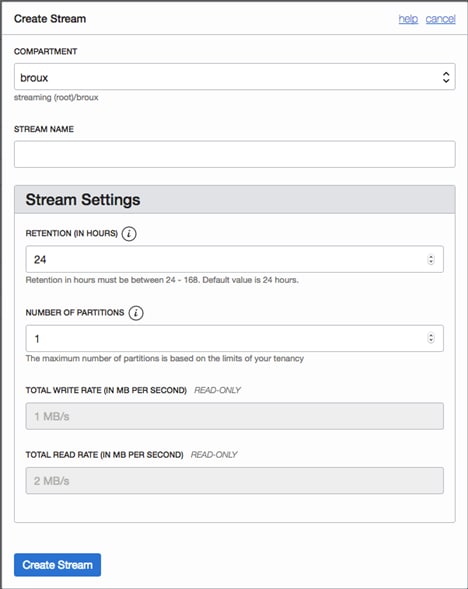
Console UI:
程序化方式:
创建流
CreateStreamDetails streamDetails =
CreateStreamDetails.builder()
.compartmentId(compartmentId)
.name(streamName)
.partitions(partitions)
.build();
SDK 中提供了一个更加详细的示例。
Streaming 可在内部管理分区,而无需您手动管理。用户无法直接删除分区。在删除一个流时,与该流关联的所有分区都将被删除。
一个流的最小吞吐量是多少?
Oracle Cloud Infrastructure 流的吞吐量由分区定义。一个分区支持 1MB/秒的数据输入和 2MB/秒的数据输出。
一个流的最大吞吐量是多少?
您可以通过添加更多分区来扩展 Oracle Cloud Infrastructure 流的吞吐量。流可以容纳的分区数量没有理论上限。然而,每一个 Oracle Cloud Infrastructure 租户都将通用储值类型账户的默认分区限制设置为 5。如果需要更多分区,您可以随时申请提高服务限额。
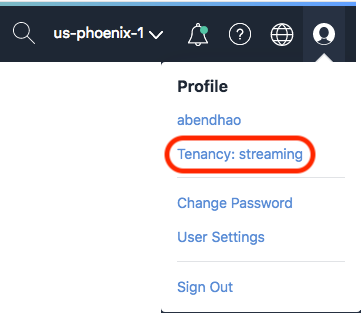
如何使用 Oracle Cloud Infrastructure Console 提高租户的服务限额?
您可以通过以下步骤来请求提高服务限额:
- 在 Console 的右上角打开 User 菜单并点击 Tenancy:<tenancy_name>。
![]()
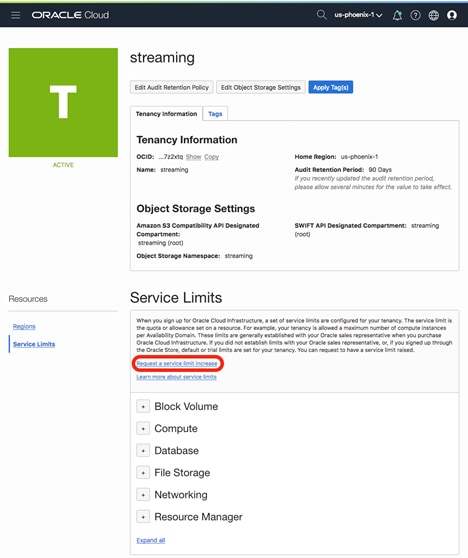
- 点击 Service Limits,然后点击 Request a service limit increase。
![]()
- 填写表单,在 Service Category 中选择 Others,并在 Resource 中选择 Other Limits。在 Reason for Request 中请求增加租户中 Streaming 服务的分区数量。
流管理有哪些优秀实践?
在创建流时,请牢记以下优秀实践:
- 流名称在流池中应当是唯一的。也就是说,您只能在同一隔间中创建两个具有相同名称的流,但前提是它们位于不同的流池中。
- 创建流后,无法更改其中的分区数量。我们建议所分配的分区规模略高于您的最大吞吐量。这将帮助您应对应用峰值需求。
- 创建流后,无法更改保留时长。默认情况下,流中的数据将存储 24 小时。但是,您可以通过配置,将数据保留 24 到 168 小时。流中存储的数据量不会对流的性能产生任何影响。
将消息生成到 Oracle Cloud Infrastructure 流
如何将数据生成到一个流?
当流创建完成并处于“活动”状态之后,您就可以开始生成消息了。您可以使用控制台或通过 API 来将消息生成到流中。
控制台:转至控制台的 Streaming 服务区域,该区域位于 Solutions and Platform > Analytics 选项卡中。如果已经创建了流,请在隔间中选择一个流,并导航至“Stream Details”页面。点击控制台上的“Produce test Message”按钮。这将为消息随机分配一个分区键,并且将写入到流的分区中。您可以点击 Load Messages 按钮,在 Recent Messages 中查看消息。
API:您可以使用 Oracle Cloud Infrastructure Streaming API 或 Kafka API 来生成流。消息将发布到流中的一个分区。如果有多个分区,则可以指定一个键来选择将消息发送至哪些分区,如果不指定键,Streaming 将通过生成 UUID 来为您分配一个键,然后将消息发送至随机分区。这将确保没有键的消息均匀分布于所有分区中。但是,我们建议您在任何情况下都指定一个消息键,以便显式控制数据的分区策略。
有关使用 Streaming SDK 将消息生成到流的示例,请参阅文档。
如何确定使用者将使用哪一个分区?
当使用 Oracle Cloud Infrastructure API 生成消息时,分区逻辑将由 Streaming 控制。这称为服务器端分区。作为用户,您可以根据键来选择要发送到哪一个分区。键将转换为散列形式,并且最终值将用于确定要将消息发送到的分区号。具有相同键的消息将进入同一分区。具有不同键的消息可能会进入不同的分区,也可能会进入到同一分区。
但是,如果使用 Kafka API 来生成流,则分区将由 Kafka 客户端控制,并且 Kafka 客户端中的分区程序将负责分区逻辑。这称为客户端分区。
如何生成有效的分区键?
为了确保均匀分发消息,您需要一个有效的消息键值。要创建一个值,请考虑流处理数据的选择性和基数。
- 基数:请根据具体使用场景选择生成的唯一键的总数。更高的键基数通常意味着更好的分布。
- 选择性:请考虑每一个键的消息数量。更高的选择性意味着每一个键有更多消息,这可能会导致热点。
请始终选择更高的基数,设置更低的选择性。
如何确保按照与生成消息相同的顺序将消息传递给使用者?
Streaming 可保证在一个分区内进行线性化的读取和写入操作。如果要确保具有相同值的消息进入同一分区,请对这些消息使用相同的键。
消息大小将对流的吞吐量产生哪些影响?
一个分区支持 1 MB/秒的数据输入速率,支持多达 1000 条 PUT 消息每秒。因此,如果记录大小小于 1 KB,分区的实际数据输入速率将小于 1 MB/秒 — 这受每秒最大 PUT 消息数量的限制。我们建议您批量生成消息,原因如下:
- 这将减少发送至服务的 PUT 请求的数量,从而避免节流。
- 这有助于提高吞吐量。
批量消息的大小不应超过 1 MB。如果超过此限制,则会触发节流机制。
如何处理大于 1 MB 的消息?
您可以通过分块,或使用 Oracle Cloud Infrastructure Object Storage 来发送消息。
- 分块:您可以将大型工作负载拆分为多个 Streaming 可接受的较小的块。块采用与普通非分块消息相同的方式存储在服务中。唯一的区别在于,使用者需要保留这些块并收集所有块来组合成消息。分区中的块可以与普通消息交织在一起。
- Object Storage:大型工作负载放置在 Object Storage 中,并且仅传输指向该数据的指针。接收器将识别此类指针工作负载,透明地从 Object Storage 中读取数据,并将其提供给最终用户。
如果生成速度大于分区所允许的速度,那么会发生什么情况?
当生产者以大于每秒 1 MB 的速度生产消息时,请求将受到限制,并向客户端返回 429, Too Many Requests 错误,这表示每个分区每秒收到的请求过多。
使用 Oracle Cloud Infrastructure 流消息
如何从流中读取数据?
使用者是可从一个或多个流中读取消息的实体。此实体可以单独存在,也可以是使用者组的一部分。要使用消息,您需要创建一个游标,然后使用该游标来读取消息。游标将指向流中某个位置。该位置可以是分区中的特定偏移量或时间,或者组的当前位置。根据要读取的位置,您可以选择使用不同类型的游标:TRIM_HORIZON、AT_OFFSET、AFTER_OFFSET、AT_TIME 和 LATEST。
有关更多信息,请参阅使用消息的相关文档。
在任何特定时间点,我可以从流中使用的最大消息数量是多少?
GetMessagesRequest 类的 getLimit( ) 方法将返回最多数量的消息。您可以指定 10000 以内的任何值。该服务默认将返回尽可能多的消息。请考虑您的平均消息大小,以避免超出流的吞吐量。Streaming GetMessages 批量大小取决于为特定流生成的平均消息大小。
如何避免向使用者发送重复消息?
Streaming 服务为使用者提供“至少一次”的交付语义。我们建议由使用者应用来处理重复项。例如,当之前非活动的使用者组实例重新加入组并开始使用之前所分配实例尚未提交的消息时,可能会发生重复删除处理。
如何知道使用者是否落后?
如果生产速度快于使用速度,则使用者就会落后。要确定您的使用者是否落后,可以使用消息的时间戳。如果使用者落后,请考虑生成一个新使用者来接管第一个使用者的某些分区。如果您在单一分区上落后,则无法恢复。
请考虑以下选项:
- 增加流中的分区数量。
- 如果问题是由热点引起的,那么请更改消息键策略。
- 减少消息处理时间,或并行处理请求。
如果希望了解特定分区中还有多少消息待使用,那么请使用 LATEST 类型的游标,获取下一条已发布消息的偏移量,并使用与您的偏移量相对应的增量。由于我们没有密集偏移,因此您只能得到一个粗略的估计。然而,如果生产者停止生产,那么您将无法获取该信息,因为您永远都无法获取下一条已发布消息的偏移量。
使用者组是如何工作的?
可以将使用者配置为组成员,以组成员的身份来使用消息。流分区在组成员间分配,以便来自任何单一分区的消息仅会发送至单一使用者。当使用者加入或离开使用者组之后,分区分配会重新平衡。有关更多信息,请参阅使用者组的相关文档。
为何应当使用使用者组?
使用者组具有以下优势:
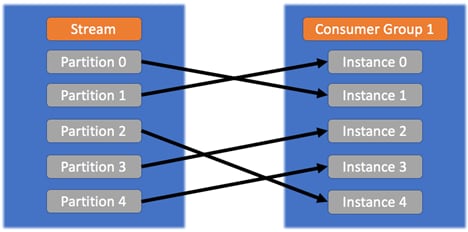
- 使用者组中的每一个实例都将从一个或多个“自动”分配的分区接收消息,而其他实例(分配给不同的分区)则不会收到相同的消息。这样一来,通过让一个实例仅读取一个分区,我们可以将实例数量扩展为分区数量。在这种情况下,加入该组的新实例处于空闲状态,而不会分配给任何分区。
- 实例作为不同使用者组的一部分意味着将提供一种发布-订阅模式,在该模式中,来自分区的消息将被发送至跨不同组的所有实例。
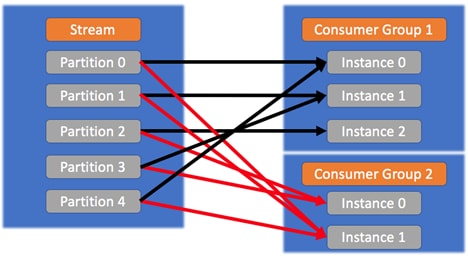
在同一个使用者组中,规则如下图所示:![]()
在不同的组中,实例会收到相同的消息,如下图所示:
![]()
当不同应用以不同方式处理分区内的相关消息时,这非常有用。我们希望所有相关应用均从分区接收所有相同的消息。 - 当某实例加入一个组时,如果有足够的分区可用(即尚未达到每一个分区一个实例的限制),则会开始重新均衡。分区重新分配给当前实例,再加上新实例。同样,如果某实例离开组,则会将分区重新分配给其余实例。
- 系统将自动管理偏移提交。
每一个流中的使用者组数量有限制吗?
每一个流最多支持 50 个使用者组。使用者组是临时的。如果在流的保留期内未使用,那么这些使用者组就会消失。
在使用使用者和使用者组时,我需要注意哪些超时?
Streaming 的以下要素会有超时:
- 游标: 只要您继续使用消息,就不需要创建游标。如果消息使用停止超过 5 分钟,则需要重新创建游标。
- 实例:如果某实例停止使用消息的时间超过 30 秒,则会将其从使用者组中删除,并将其分区重新分配给另一个实例。这称为重新均衡。
什么是使用者组内部的重新均衡?
在重新均衡流程中,属于同一使用者组的一组实例通过协调,确保拥有属于特定流的一组互斥分区。当使用者组成功完成重新均衡操作时,流中的每一个分区均归该组内的一个或多个使用者实例所有。
哪些事件将触发使用者组内部的重新均衡活动?
当使用者组的实例因无法发送心跳超过 30 秒而变为非活动状态或流程终止时,使用者组内将触发重新均衡活动。这是为了处理非活动实例之前使用的分区,并将其重新分配给活动实例。同样,当使用者组中之前非活动的实例加入该组时,这将触发重新均衡流程分配一个分区并从中开始使用。当实例重新加入该组时,Streaming 并不会保证将该实例重新分配给同一分区。
如何从使用者故障中恢复?
要从故障中恢复,您需要存储针对每一个分区所处理的最后一条消息的偏移量,以便于在需要重新启动使用者时可从该消息开始使用。
注意:请勿存储游标;它们将在 5 分钟后过期。
我们并不针对所处理的最后一条消息的偏移量的存储方式提供任何指导,您可以使用所需要的任何方法。例如,您可以将游标存储在另一个流上,或者也可以存储在 VM 上的文件中或 Object Storage 桶中。当使用者重新启动时,读取所处理的最后一条消息的偏移量,然后创建 AFTER_OFFSET 类型的游标并指定刚获取的偏移量。
Oracle Cloud Infrastructure Streaming 的 Kafka 兼容性
如何将现有 Kafka 应用与 Streaming 相集成?
Streaming 提供了一个 Kafka 端点,可供现有基于 Apache Kafka 的应用使用。要实现全托管式 Kafka 体验,只需进行配置更改即可。Streaming 的 Kafka 兼容性为运行您自己的 Kafka 集群提供了一种替代方案。Streaming 支持 Apache Kafka 1.0 和更高版本的客户端,并且可以与现有 Kafka 应用、工具和框架协同作业。
我的现有 Kafka 应用需要进行哪些配置更改才能与 Streaming 交互?
使用 Kafka 应用的客户只需更改其 Kafka 配置文件的以下参数,即可迁移至 Streaming。
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="{username}" password="{pwd}"; bootstrap.servers: kafka.streaming.{region}.com:9092 # Application settings
topicName: [streamOcid]
如何结合使用 Kafka Connect 与 Streaming?
要结合使用 Kafka 连接器与 Streaming,请使用 Console 或命令行接口 (CLI) 创建一个 Kafka Connect 配置。Streaming API 将调用这些配置 harnesses。特定隔间中创建的 Kafka Connect 配置仅适用于同一隔间中的流。您可以使用多个具有相同 Kafka Connect 配置的 Kafka 连接器。如果需要在单独的隔间中生成或使用流,或者需要更大的容量来避免达到 Kafka Connect 配置上的节流限制(例如,连接器过多或使用连接器的员工过多),则可以创建更多的 Kafka 连接器配置。
Streaming 提供哪些第一方和第三方产品集成?
Streaming 的 Kafka Connect 兼容性意味着您可以利用许多现有的第一方和第三方连接器将数据从源移至目标。适用于 Oracle 产品的 Kafka 连接器包括:
- Oracle Cloud Infrastructure Object Storage(使用 Kafka Connect for S3)
- Kafka Connect Amazon S3 源连接器,适用于生产者
- Kafka Connect Amazon S3 sink 连接器,适用于使用者
- Oracle Integration Cloud
- Oracle AI Database(使用 Kafka Connect JDBC)
- Oracle GoldenGate
有关第三方 Kafka 源连接器和 sink 连接器的完整列表,请参阅官方 Confluent Kafka 平台。
监视 Oracle Cloud Infrastructure 流
可在何处监视流?
Streaming 与 Oracle Cloud Infrastructure Monitoring 全面集成。在 Console 中选择要监视的流。在 Stream Details 页面中,导航至 Resources 区域,点击 Produce Monitoring Charts 监视生产者请求,或者点击 Consume Monitoring Charts 监视使用者端指标。这些指标适用于流层面,而不是分区层面。有关受支持的 Streaming 指标的描述,请参阅文档。
监视 Streaming 时有哪些可用的统计信息?
Console 中可用的每一个指标均提供以下统计信息:
- 费率、和值和均值
- 最小值、最大值和计数
- P50、P90、P95、P99 和 P99.9
这些统计信息按以下时间间隔提供:
- 自动
- 1 分钟
- 5 分钟
- 1 小时
我通常应当为哪些指标设置警报?
对于生产者,请考虑根据以下指标设置警报:
- Put Messages Latency:延迟增加意味着消息发布时间更长,这可能表示存在网络问题。
- Put Messages Total Throughput:
- 总吞吐量的大幅增长可能表示将达到每个分区每秒 1 MB 的限制,并且该事件将触发限制机制。
- 大幅减少可能意味着客户生产者遇到问题或将要停止。
- Put Messages Throttled Records:当消息受到限制时,获取通知非常重要。
- Put Messages Failure:如果 put 消息启动失败,则需要获取通知,以便于运营团队调查原因。
对于使用者,请考虑根据以下指标设置相同的警报:
- Get Messages Latency
- Get Messages Total Throughput
- Get Messages Throttled Requests
- Get Messages Failure
如何获知我的流运行状况良好?
当流处于活动状态时,其运行状况良好。如果您可以将消息生成到流中,并获得成功响应,则表示流运行状况良好。当流中生成数据后,使用者可以在配置的保留期内对其进行访问。如果 GetMessages API 调用返回更高级别的内部服务器错误,则表示该服务不正常。
运行状况良好的流也具有正常的指标:
- Put Messages Latency 较低。
- Put Messages Total Throughput 接近每个分区每秒 1 MB。
- Put Messages Throttled Records 接近于 0。
- Put Messages Failure 接近于 0。
- Get Messages Latency 较低。
- Get Messages Total Throughput 接近每分区每秒 2 MB。
- Get Messages Throttled Requests 接近于 0。
- Get Messages Failure 接近于 0。
流中的消息在什么情况下会受到限制?
节流表示该流无法处理任何新的读取或写入操作。超过以下阈值时将激活节流机制:
- GetMessages:每秒五次调用或每个分区每秒 2 MB
- PutMessages:每个分区每秒 1 MB
- 管理和控制平台操作,例如 CreateCursor 和 ListStream 等:每个流每秒五次调用
可在何处找到 API 错误列表?
有关 API 错误的详细信息,请参阅文档。
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。