
利用高级分析提高产量、质量和可持续性
对于制造业来说,利用数据提高运营效率和绩效尤其重要,因为该使用场景可以应用于任何一种制造生产系统,包括计算机数控基础设施、供应链和仓库系统、物流和测试系统等。
虽然在传统上制造商非常重视历史描述和诊断指标,但现在,他们开始使用高级分析、机器学习和数据科学来评估绩效改进状况并提供前瞻性、预测性且规范性的建议。
该使用场景重点关注用于从制造执行系统 (MES)、仓库管理系统 (WHMS)、计算机化维护管理系统 (CMMS) 和维护系统中摄取、存储、管理和获得洞察所需的数据平台架构,以评估设备、生产线和工厂的运营效率以及绩效指标。
制造商可以通过摄取、整理和分析生产流程和绩效方面的数据来识别和消除瓶颈,解决低效问题,进而优化生产排程并增加产量。通过对产品质量数据应用同样的方法,制造商可以识别模式和产品不合格的根本原因,从而实施更有效的质量控制措施。此外,制造商还可以利用能源消耗数据确定有待提高能源效率的领域,以降低成本,提高可持续性。
通过功能全面的数据平台优化预测性维护,降低成本
下图架构展示了我们如何结合使用推荐的 Oracle 组件构建涵盖从探索到行动和评估的整个数据分析生命周期的分析架构,提供上述各种业务优势。
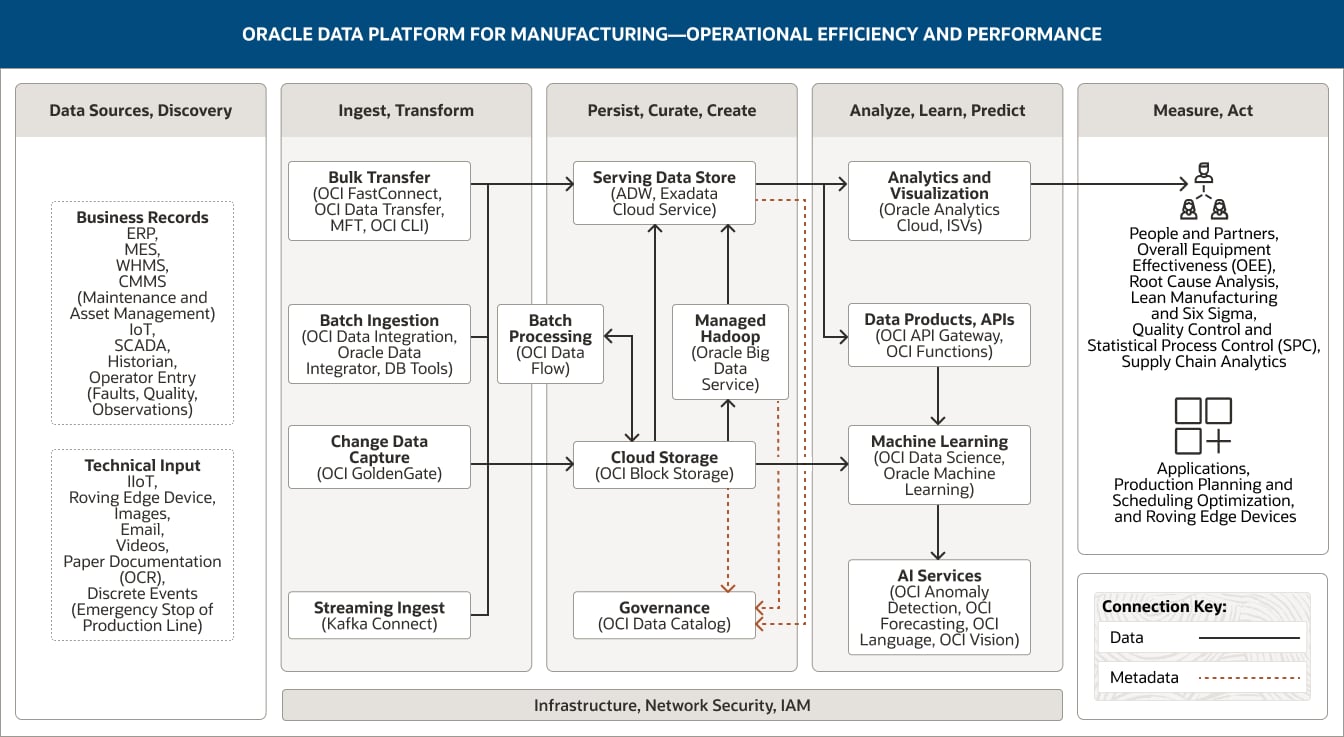
此图展示了面向制造业的 Oracle Data Platform 如何用于支持运营效率和绩效。该平台包括以下五个支柱:
- 1. 数据源、探索
- 2. 摄取、转换
- 3. 持久保存、整理、创建
- 4. 分析、学习、预测
- 5. 评估、行动
“数据源、探索”支柱包括三类数据。
- 1. Oracle 应用数据包括来自 Fusion SaaS、Oracle E-Business Suite、CX 的数据
- 2. 业务记录(第一方数据)包括 CRM、事务处理、账户信息、收入和利润
- 3. 第三方数据包括外汇汇率、市场反馈数据和商品价格
“摄取、转换”支柱包括四个功能。
- 1. 批量摄取使用 OCI Data Integration、Oracle Data Integrator 和数据库工具。
- 2. 批量传输使用 OCI FastConnect、OCI Data Transfer、MFT 和 OCI CLI。
- 3. 更改数据捕获使用 OCI GoldenGate。
- 4. 流摄取使用 OCI Streaming Kafka Connect。
所有四种功能都单向连接到“持久保存、整理、创建”支柱中的服务数据存储和云端存储。
此外,流摄取连接至“分析、学习、预测”支柱中的流处理。
“持久保存、整理、创建”支柱包括五个功能。
- 1. 服务数据存储使用 Oracle Autonomous Data Warehouse 和 Exadata Cloud Service。
- 2. 云端存储使用 OCI Object Storage。
- 3. 托管 Hadoop 使用 Oracle Big Data Service
- 4. 批处理使用 OCI Data Flow。
- 5. 治理使用 OCI Data Catalog。
这些功能在支柱内互联。云端存储不仅单向连接至服务数据存储,还双向连接至批处理。
这两种功能连接到“分析、学习、预测”支柱。服务数据存储连接到分析和可视化功能,也连接到数据产品及 API 功能。云端存储连接到机器学习功能。
“分析、学习和预测”支柱包括两个功能。
- 1. 分析和可视化使用 Oracle Analytics Cloud、GraphStudio 和 ISV。
- 2. 机器学习使用 Oracle Machine Learning。
“评估、行动”支柱可捕获如何使用数据分析:由人员和合作伙伴使用。
人员和合作伙伴包括运营效率(处理时间、错误率、资源利用率)、流程瓶颈标识、客户终身价值、市场和竞争分析、绩效归因。
“摄取、转换”、“持久保存、整理、创建”及“分析、学习、预测”这三大核心支柱由基础设施、网络、安全和 IAM 提供支持。
连接、摄取和转换数据
我们的解决方案由三大支柱组成,每个支柱都支持特定的数据平台功能。第一个支柱提供连接、摄取和转换数据功能。
我们通过四种主要方法将数据注入架构,帮助制造企业提高运营效率和绩效。
- 首先,我们将启用运营事务数据的批量传输。当首次需要将大量数据(例如来自现有本地分析存储库或其它云技术源的数据)移动到 Oracle Cloud Infrastructure (OCI) 时,可以使用批量传输服务。具体使用哪种批量传输服务取决于数据的位置和传输频率。举例来说,我们可以使用 OCI Data Transfer 服务或 OCI Data Transfer Appliance 从历史计划或数据仓库存储库中加载大量本地数据。当需要持续移动大量数据时,我们建议使用 OCI FastConnect,它可在客户的数据中心与 OCI 之间提供高带宽的专用网络连接。
- 通常需要频繁、实时或近乎实时的提取,并且使用 OCI GoldenGate 定期从仓库管理、调度和订单管理系统中提取数据。OCI GoldenGate 使用更改数据捕获来检测需要服务的系统底层结构中的更改事件(例如,添加新组件、完成维护操作、天气变化等)并将数据实时发送到持久层和/或流层。
- 对于制造公司而言,实时分析来自多个来源的数据有助于提供有关其运营效率和整体绩效的宝贵洞察。在该使用场景中,我们使用流摄取来摄取通过 IoT 和机器通信等方式从传感器中读取的所有数据。实时捕获和分析数据流的能力对于制造商执行预测性资产维护至关重要。数据流可以源自多个 ISA-95 2 级系统,例如监控控制与数据采集 (SCADA) 系统、可编程逻辑控制和批处理自动化系统。数据(事件)将被摄取,一些基本的转换/聚合将在其存储到 OCI Object Storage 之前进行。此外,还可以使用其它流分析来识别关联事件,并且可以(手动)反馈任何已识别的模式,使用 OCI Data Science 检查原始数据。
- 为了实时分析此高频流数据,我们将使用流处理提供高级分析。传统分析工具从静态数据中提取信息,而流分析则评估动态数据的价值,即实时评估。而这不是唯一的好处。由于流分析可以实现高度自动化,因此可以帮助制造商降低运营成本。例如,流分析可以提供有关基本公用事业成本(例如电力和水)的实时数据。然后,工厂可以使用自动化流分析工具来获取即时洞察,以优化相关方面,降低能源成本并使用人工智能对某些运营事件做出适当响应。流分析还可以对即将到来的设备维护要求进行实时预测,帮助企业提前为任何即将到来的维修或日常维护做好准备。
- 虽然实时需求在不断变化,但从 ERP、计划、仓库管理和运输管理系统中提取数据最常见的方法仍然是使用 ETL 流程进行批量摄取。批量摄取用于从不支持数据流的系统(例如,旧的 SCADA 或维护管理系统)导入数据。这些提取可以频繁进行,通常每 10 或 15 分钟提取一次,但它们本质上仍然是批量的,因为提取和处理的是一组事务而不是单个事务。OCI 提供各种服务来处理批量摄取,例如在 OCI Compute 实例上运行的本机 OCI Data Integration 服务和 Oracle Data Integrator。服务选择主要基于客户偏好,而不是技术要求。
持久保存、处理和整理数据
数据持久性和处理建立在三个(可选四个)组件之上。有些客户会使用所有组件,而另一些客户则使用其中的一个子集。根据容量和数据类型,数据可以加载到对象存储中,或直接加载到结构化关系数据库中以进行永久性存储。当我们预计应用数据科学功能时,从数据源以原始形式(作为未处理的本机文件或提取)检索的数据通常会被捕获,并从事务系统加载到云端存储中。
- 云端存储是我们的数据平台常用的数据持久性层。它可用于结构化和非结构化数据。OCI Object Storage、OCI Data Flow 和 Oracle Autonomous Data Warehouse 是基本构建块。以原始格式从数据源检索的数据将被捕获并加载到 OCI Object Storage 中。OCI Object Storage 是主要是数据持久性层,而 OCI Data Flow 中的 Spark 是主要批处理引擎。批处理涉及多项活动,包括基本噪声处理、缺失数据管理和基于定义的出站数据集筛选。根据所需的处理和使用的数据类型,将结果写回各层对象存储或持久关系存储库。
- 使用 Oracle Big Data Service for Hadoop(托管 Hadoop )替代 OCI Object Storage 和 OCI Data Flow 配置。这两种配置也可以结合使用,具体取决于客户以及客户是否投资了 Hadoop 生态系统,无论是产品还是技能。已经在 Hadoop 环境(非 Hadoop 分布式文件系统)中使用对象存储的客户可以将此配置转换为 Oracle Big Data Service。此外,Hadoop 环境中的其它组件(如 Hive)也可以发挥作用,推动使用 Big Data Service,具体取决于客户使用或打算使用的可视化和数据科学工具。虽然该架构概述了 Oracle 提供的所有服务,但客户可以选择继续使用现有的一些组件,特别是已经部署的可视化和数据科学工具。
- 我们现在将使用服务数据存储以优化的形式保存经过整理的数据,以提高查询性能。服务数据存储提供了一个持久的关系层,用于通过基于 SQL 的工具直接向最终用户提供经过整理的高质量数据。在此解决方案中,Oracle Autonomous Data Warehouse 被实例化为企业数据仓库的服务数据存储,如有需要,还可以被实例化更专业的域级数据集市。它也可以是数据科学项目的数据源或 Oracle Machine Learning 所需的存储库。服务数据存储可以采用多种形式,包括 Oracle MySQL HeatWave、Oracle Database Exadata Cloud Service 或 Oracle Exadata Cloud@Customer。
分析数据、预测和行动
有三种技术方法可以促进分析、预测和行动的能力。
- 高级分析功能对于维护和性能优化至关重要。在该使用场景中,我们依靠 Oracle Analytics Cloud 来提供分析和可视化。借助该解决方案,企业将能够使用描述性分析(用直方图和图表描述当前趋势)、预测性分析(预测未来事件、确定趋势以及确定不确定结果的可能性)和规范性分析(提出合适的行动建议,从而做出理想决策)。
- 除了高级分析之外,越来越多的数据科学、机器学习和人工智能还可用于查找异常、预测可能发生故障的位置并优化寻源流程。OCI Data Science、OCI AI 服务或 Oracle Machine Learning 都可在数据库中使用。我们使用机器学习和数据科学方法来构建和训练预测性维护模型。然后,我们可以通过 API 来部署这些机器学习模型以进行评分,或者将其嵌入到 OCI GoldenGate 流分析管道中。在某些情况下,这些模型甚至可以使用 Oracle Machine Learning Services REST API 部署在数据库中(为此,模型需要采用开放式神经网络交换格式)。此外,可以在服务或事务数据存储中部署用于以 Jupyter/Python 为中心的笔记本的 OCI Data Science 或用于 Zeppelin 笔记本和机器学习算法的 Oracle Machine Learning。同样,无论是单独使用还是搭配使用,Oracle Machine Learning 和 OCI Data Science 都可以用于开发建议模型/决策模型。这些模型可以作为服务部署,我们可以将其部署在 OCI API Gateway 后面,以作为“数据产品”和服务进行交付。构建后,机器学习模型可以部署到分布式控制系统的应用程序中(如果允许),或者通过 Oracle Roving Edge Device 或类似设备部署在边缘。
通过将数据科学与机器学习识别的模式相结合而创建的多个模型可应用于 AI 服务提供的响应和决策系统。
- OCI Anomaly Detection 可以帮助实时监视供应链绩效指标(例如,原材料库存、生产吞吐量、在制品、运输时间、库存周转率等),以识别和解决中断问题。在复杂的供应链中,已识别异常的严重性评分可以帮助确定观察到的业务中断的优先级,以便采取行动。
- OCI Forecasting 可以帮助预测供应链指标,例如需求、供应和资源容量,因此可以采取适当的行动,提前做好准备。
- OCI Vision 和 OCI Language 可以帮助理解用于扩充供应链数据的文档,如汇出的产品质量报告和产品缺陷报告。
最后一个也是关键的组成部分是数据治理。这是一项由 OCI Data Catalog 提供的免费服务,为数据平台生态系统中的所有数据源提供数据治理和元数据管理(包括技术和业务元数据)。OCI Data Catalog 也是从 Oracle Autonomous Data Warehouse 到 OCI Object Storage 的的重要查询组件,因为它提供了一种快速查找数据的方法,无论其存储方式如何。这允许最终用户、开发人员和数据科学家在架构中的所有持久数据存储中使用通用访问语言 (SQL)。
利用数据提高运营效率和绩效的好处
随着业务发展和竞争加剧,用于提供关键运营数据的旧系统已经无法跟上业务发展步伐。这些系统需要大量手动干预来汇总、集成分散的孤立数据并生成报告,而这种方式会导致信息延迟,无法为企业提供需要的优势。
充分利用生产资源对于优化制造运营也至关重要。在瑕疵品或低效生产流程上花费的时间不仅会增加成本和浪费,还会导致您无法交付让客户满意的产品。优化运营和提高绩效可以为制造商带来诸多好处,包括:
- 提高效率,减少生产时间和成本,增加产量并提高生产力
- 减少瑕疵品,提高产品质量和客户满意度
- 快速识别安全风险和危害,进而改善安全实践,减少工作场所事故
- 减少浪费,提高供应链效率并优化库存水平
- 提高价格、质量和创新方面的竞争力,助力企业创造市场竞争优势
- 通过减少浪费增强可持续发展能力,从而提高能源效率并尽可能减少制造流程对环境的影响
相关资源
-
使用案例
利用数据改善工作场所健康和安全状况
了解如何利用可通过高级分析改善健康和安全状况的数据平台来提高制造业运营安全性。
-
使用案例
利用边缘计算更快地获得有关制造工厂的洞察
了解如何利用面向制造业的 Oracle Data Platform 更高效地整合工厂数据,更快地获得洞察。
-
使用案例
利用数据从被动维护转变为预测性维护
了解如何利用数据平台优化资产,通过机器学习实现预测性维护。
开始行动
试用逾 20 个 Always Free 云技术服务,或在 30 天试用版中体验更多服务
Oracle 提供的免费套餐包含了 Autonomous AI Database、Arm Compute 和 Storage 等 20 多个服务,另外还有 300 美元的免费储值,让您可以试用更多云技术服务。立即获取详细信息并注册您的免费账户。
-
Oracle Cloud Free Tier 包含哪些内容?
- 2 个 Autonomous AI Database 实例,各 20 GB
- AMD 和 Arm Compute VM
- 总共 200 GB 块存储
- 10 GB 对象存储
- 每月 10 TB 出站数据传输
- 超过 10 个 Always Free 服务
- 价值 300 美元的免费储值,有效期 30 天
通过分步指导学习
通过教程和实操练习体验各种 OCI 服务。无论您是开发人员、管理员还是分析师,我们都可以帮助您了解 OCI 的工作原理。许多练习都运行于 Oracle Cloud Free Tier 或 Oracle 提供的免费练习环境中。
-
OCI 核心服务快速入门
本课程中的练习介绍了 Oracle Cloud Infrastructure (OCI) 核心服务,包括 Virtual Cloud Network (VCN) 以及计算和存储服务。
立即开始 OCI 核心服务练习 -
Autonomous AI Database 快速入门
在本课程中,您将了解如何开始使用 Oracle Autonomous AI Database。
立即开始 Autonomous AI Database 快速入门练习 -
基于电子表格构建应用
此练习将指导您如何将电子表格上传到 Oracle Database 表中,然后基于新表格创建应用。
立即开始练习
了解 150 多个优秀实践设计
了解我们的架构师和其他客户如何部署各种工作负载,包括从企业应用到高性能计算 (HPC),再从微服务到数据湖的工作负载。您可以观看“构建并部署”系列视频,参考来自其他客户架构师的优秀实践,使用“一键部署”功能或者通过 GitHub 库部署更多工作负载。
广受欢迎的架构
- Apache Tomcat 和 MySQL Database Service
- 在 Kubernetes 上运行 Oracle Weblogic 和 Jenkins
- 机器学习 (ML) 和人工智能 (AI) 环境
- 基于 Arm 的 Tomcat 和 Oracle Autonomous AI Database
- 使用 ELK Stack 进行日志分析
- 使用 OpenFOAM 的高性能计算
体验不同之处:
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 超低定价且无需缴付多年的承诺款
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。