
利用整合的实时数据来优化效率并降低风险
如今的制造商要了解多个工厂的所有生产线效率 — 在第一时间知晓发生的问题,而不是事情发生了五到十分钟后才知晓。然而,这也是如今制造商面临的最大挑战之一,因为这需要他们从多个远程位置实时访问数据,而这些位置可能只有有限或零星的互联网连接。要解决这一问题,我们需要将机器学习 (ML) 和数据采集技术应用到网络边缘。
简化边缘决策
我们可以通过在 Oracle Data Platform 中配置 Oracle Roving Edge Devices (RED) 来解决这一难题。RED 可捕获、存储、运行和管理数据并从数据中获取洞察,帮助制造商在边缘实现决策流程和制造设备管理自动化。此外,面向制造业的 Oracle Data Platform 还提供异常检测功能,可用于解决生产线中断问题并提供与维护相关的洞察,帮助缓解和纠正问题。
以下架构展示了 Oracle Data Platform 如何支持工厂数据整合,通过在边缘部署高级分析和机器学习技术来识别异常、执行智能数据收集和提供实时运营信息。
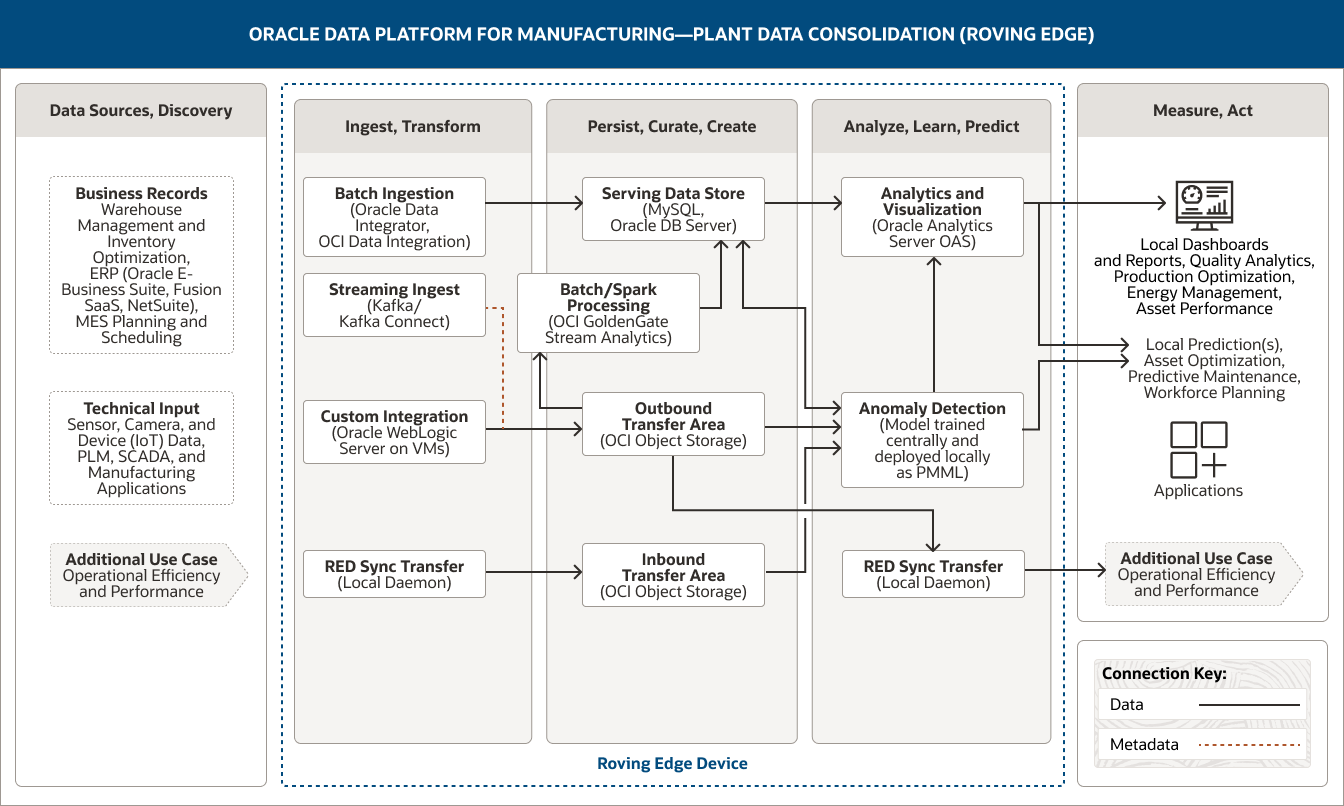
该图展示了面向制造业的 Oracle Data Platform 如何用于整合工厂数据。该平台包括以下五个支柱:
- 1. 数据源、探索
- 2. 摄取、转换
- 3. 持久保存、整理、创建
- 4. 分析、学习、预测
- 5. 评估、行动
“数据源、探索”支柱包括两类数据。
- 1. 业务记录数据包括仓库管理和库存优化数据、ERP(Oracle E-Business Suite、Oracle Fusion SaaS、Oracle NetSuite)数据以及 MES 计划和排程数据。
- 2. 技术输入数据包括传感器、摄像头等设备 (IoT) 数据以及来自 PLM、SCADA 和制造应用的数据。
“摄取、转换”支柱包括四个功能。
- 1. 批量摄取使用 Oracle Data Integrator 和 OCI Data Integration。
- 2. 流摄取使用 Kafka Connect。
- 3. 自定义集成使用虚拟机上的 Oracle WebLogic Server。
- 4. RED 同步传输使用本地守护进程。
批量摄取单向连接至服务数据存储。
流摄取和自定义集成单向连接至出站传输区域。
此外,RED 同步传输单向连接至入站传输区域。
“持久保存、整理、创建”支柱包括四个功能。
- 1. 服务数据存储使用 MySQL 和 Oracle DB 服务器。
- 2. 批处理/Spark 处理使用 OCI GoldenGate Stream Analytics。
- 3. 出站传输区域使用 OCI Object Storage。
- 4. 入站传输区域使用 OCI Object Storage。
这些功能在支柱内互联。批处理/Spark 处理单向连接至服务数据存储。
出站传输区域单向连接至批处理/Spark 处理。
连接到“分析、学习、预测”支柱的三个功能:
服务数据存储单向连接至分析和可视化功能,并双向连接至异常检测功能。出站传输区域单向连接至异常检测和 RED 同步传输功能。
入站传输区域单向连接至异常检测功能。
“分析、学习和预测”支柱包括三个功能。
- 1. 分析和可视化使用 Oracle Analytics Server。
- 2. 异常检测使用集中训练并在本地部署为 PMML 的模型。
- 3. RED 同步传输使用本地守护进程。
异常检测功能将单向连接至支柱中的分析和可视化功能。
连接到“评估、行动”支柱的三个功能:分析和可视化功能单向连接至本地仪表盘和报告以及本地预测。异常检测功能单向连接至本地预测,RED 同步传输功能单向连接至其它使用场景。
“评估、行动”支柱包含如何利用整合后的工厂数据。这些潜在用途可分为四组。
- 第一组包括本地仪表盘和报告。
- 第二组包括本地预测。
- 第三组包括应用。
- 第四组包含一个额外使用场景,即运营效率和性能。
“摄取、转换”、“持久保存、整理、创建”及“分析、学习、预测”这三大核心支柱由 Oracle Roving Edge Device 提供支持。
Oracle Data Platform 使用以下四种主要方法将数据注入架构中,以方便制造商了解运营效率和性能:
- 使用 Oracle Integration Repository 中的自定义集成来集成各种来源的结构化和非结构化数据,与设备、自定义 API 等进行交互。这可以从任何应用开发类型(如独立 Java 或 Python 代码、基于 Oracle WebLogic Server 的应用或基于 Kubernetes 的应用)摄取数据,并将数据存储在对象存储中,以供进一步细化,用于出站传输或馈送至 AI 模型。
- 使用 RED 数据同步将机器学习模型从集中位置(如 Oracle Cloud Infrastructure (OCI) 中存储训练模型的对象存储库)高效、便捷地传输至边缘。在这种使用场景中,边缘定义将 RED 与工厂内的其它机械部署在同一位置。新版本模型以“独立”预测模型标记语言 (PMML) 格式存储。本地守护进程将在发现新模型时执行更新,然后自动将其推送到 RED。RED 数据同步也非常适合用于将不同 RED 全天收集的所有数据(例如相关异常、信号等)传输到集中位置,如 OCI 上的对象存储,然后这些数据将用于生成运营报告和机器学习模型训练。RED 数据同步流程涉及的数据量将决定您对边缘到数据中心电信或卫星带宽的要求。
- 使用 Oracle Data Integrator 进行批量摄取,这是一个全面的数据集成解决方案,能够满足从大容量、高性能批量加载到事件驱动的滴流式集成流程和基于 SOA 的数据服务的所有数据集成需求。虽然实时需求在不断变化,但 ERP、计划、仓库管理和运输管理系统最常用的提取方法仍然使用提取、转换、加载或提取、加载和转换流程进行批量摄取。这些提取可以频繁进行,通常每 10 或 15 分钟提取一次,但它们本质上仍然是批量的,因为这些事务是以组(而非单个事务)的形式提取和处理的。OCI 提供多种服务来处理批量摄取,包括在 OCI Compute 实例上运行的原生 OCI Data Integration 服务或 Oracle Data Integrator。根据容量和数据类型,数据可以加载到对象存储中,或直接加载到结构化关系数据库中以进行永久性存储。
- 实时分析多个来源的数据可为制造企业提供关于运营效率和整体绩效的宝贵洞察。Oracle Data Platform 使用流摄取从多个 ISA-95 Level 2 系统(如数据采集与监控 (SCADA) 系统、可编程逻辑控制和批处理自动化系统)摄取数据流。在摄取流数据(事件)后,系统将对其执行一些基础的转换/聚合操作,然后将这些数据存储到对象存储中。我们可以使用流分析来识别关联事件,并(手动)反馈已识别的模式,以对原始数据进行数据科学检查。传统分析工具从静态数据中提取信息,而流分析则评估动态数据的价值,即实时评估。
数据持久性和处理建立在三个组件之上。
- 在服务数据存储中,数据处理将由 Oracle Database Server 或 MySQL 完成。服务数据存储提供一个持久关系层,通常用于通过基于 SQL 的工具直接将数据提供给最终用户。此外,该层还可为专门分析提供支持。
- 以原始形式(本机文件或提取形式)从数据源检索到的所有数据将被捕获并加载到对象存储中,用于当前或未来的机器学习模型训练。云端对象存储是我们数据平台最常用的数据持久层,同时也是入站传输区域和出站传输区域。它可用于结构化和非结构化数据。
- 除了将对象存储作为主要的数据持久层,Oracle Data Platform 还使用 OCI GoldenGate Stream Analytics 作为主要的处理引擎。批处理涉及多项活动,包括基本噪声处理、缺失数据管理和基于定义的出站数据集筛选。根据所需的处理和使用的数据类型,将结果写回各层对象存储或持久关系存储库。
分析、学习和预测能力建立在两种技术方法之上。
- 分析和可视化服务提供描述性分析(使用直方图和图表描述当前趋势)、预测性分析(预测未来事件、识别趋势以及确定不确定结果的可能性)和规范性分析(提出合适的行动,从而做出理想决策)。Oracle Analytics Server 提供与运营报告和规范性分析相关的说明性分析功能。此外,机器学习模型还可以直接嵌入到 Oracle Analytics Server 数据流中。Oracle Analytics Server 专为本地部署而设计,可提供仪表盘、报告、预警、自助数据准备和最终用户驱动的机器学习算法。面向制造业的 Oracle Data Platform 完全开放且灵活,如果需要,您也可以改为使用第三方工具。
- 除了使用高级分析之外,制造商还可以开发、训练和部署机器学习模型来支持异常检测。OCI Anomaly Detection 是一个人工智能服务,可针对各种业务轻松构建异常检测模型,标记关键事件,从而加快检测和解决速度。这些模型将集中进行训练,并以 PMML 格式部署,在本地作为 Java 或 Python 代码执行。
自动执行决策,提高盈利能力
Oracle Data Platform 让制造商能够充分发挥所有可用数据的价值,同时简化数据访问和存储。通过利用 Oracle Roving Edge Devices 将数据收集和机器学习评分推送到边缘,制造商将能够基于随时可用的准确数据做出更明智的业务决策,从而提高效率、生产能力并降低成本。
Related resources
-
Use case
Use Data to Improve Workplace Health and Safety
Learn how to make manufacturing operations safer using a data platform that helps you improve health and safety with advanced analytics.
-
Use case
Use Data to Improve Manufacturing Operational Efficiency and Performance
Learn how to manage manufacturing operations more efficiently using a data platform that helps improve performance with machine learning.
-
Use case
Use Your Data to Move from Reactive to Predictive Maintenance
Learn how to optimize assets with a data platform that enables predictive maintenance with machine learning.
开始行动
试用逾 20 个 Always Free 云技术服务,或在 30 天试用版中体验更多服务
Oracle 提供的免费套餐包含了 Autonomous AI Database、Arm Compute 和 Storage 等 20 多个服务,另外还有 300 美元的免费储值,让您可以试用更多云技术服务。立即获取详细信息并注册您的免费账户。
-
Oracle Cloud Free Tier 包含哪些内容?
- 2 个 Autonomous AI Database 实例,各 20 GB
- AMD 和 Arm Compute VM
- 总共 200 GB 块存储
- 10 GB 对象存储
- 每月 10 TB 出站数据传输
- 超过 10 个 Always Free 服务
- 价值 300 美元的免费储值,有效期 30 天
通过分步指导学习
通过教程和实操练习体验各种 OCI 服务。无论您是开发人员、管理员还是分析师,我们都可以帮助您了解 OCI 的工作原理。许多练习都运行于 Oracle Cloud Free Tier 或 Oracle 提供的免费练习环境中。
-
OCI 核心服务快速入门
本课程中的练习介绍了 Oracle Cloud Infrastructure (OCI) 核心服务,包括 Virtual Cloud Network (VCN) 以及计算和存储服务。
立即开始 OCI 核心服务练习 -
Autonomous AI Database 快速入门
在本课程中,您将了解如何开始使用 Oracle Autonomous AI Database。
立即开始 Autonomous AI Database 快速入门练习 -
基于电子表格构建应用
此练习将指导您如何将电子表格上传到 Oracle Database 表中,然后基于新表格创建应用。
立即开始练习
了解 150 多个优秀实践设计
了解我们的架构师和其他客户如何部署各种工作负载,包括从企业应用到高性能计算 (HPC),再从微服务到数据湖的工作负载。您可以观看“构建并部署”系列视频,参考来自其他客户架构师的优秀实践,使用“一键部署”功能或者通过 GitHub 库部署更多工作负载。
广受欢迎的架构
- Apache Tomcat 和 MySQL Database Service
- 在 Kubernetes 上运行 Oracle Weblogic 和 Jenkins
- 机器学习 (ML) 和人工智能 (AI) 环境
- 基于 Arm 的 Tomcat 和 Oracle Autonomous AI Database
- 使用 ELK Stack 进行日志分析
- 使用 OpenFOAM 的高性能计算
体验不同之处:
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 超低定价且无需缴付多年的承诺款
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。