
提升员工福利,改善护理服务
如今,医疗机构面临着两个严峻且相关的挑战:员工职业倦怠和人员短缺。近 50% 的受访医护人员表示,在官僚主义、行政任务和工作时间过长的重压下,他们出现了严重的职业倦怠症状。为了寻求生活与工作的平衡,许多医护人员选择离开医疗行业,从而导致医院出现难以填补的巨大人员缺口。超过一半的美国医院报告护士缺口超过 7.5%,自 2013 年以来,医院加班率和机构支出增加了 169%。更糟糕的是,许多预测指出,医护人员短缺问题将在未来十年变得更加严重。
为应对上述两个挑战,医疗机构应持续优化人员配备模型、重视提高医疗从业者的福利待遇并确保为患者提供最佳就医体验和疗效。对此,数据平台将发挥关键作用,让医疗机构能够集中访问不同系统的数据,使用高级分析和机器学习模型更准确地预测人员需求。借助数据平台提供的洞察,医疗机构将能够更好地平衡医护人员的工作量,确保随时有足够的人员配备,防止出现员工职业倦怠,进而改善患者护理。
利用机器学习轻松制定医护人员计划
临床数据可以让医护人员更好地了解患者,而人力资本管理 (HCM) 系统等运营系统可以提供医生和其他员工的历史排班、工作时间以及病假等信息,让医疗机构更好地了解其员工。如以下架构所示,Oracle Data Platform 统一了临床和运营数据,并使用高级分析和机器学习来帮助医疗机构了解:人员配备模型如何影响治疗效果;人员配备决策如何实时影响未来一周的护理;如果再次出现 COVID-19 感染高峰,需要填补哪些人员缺口;以及在不同的时间点分别适合哪种人员配置模型。
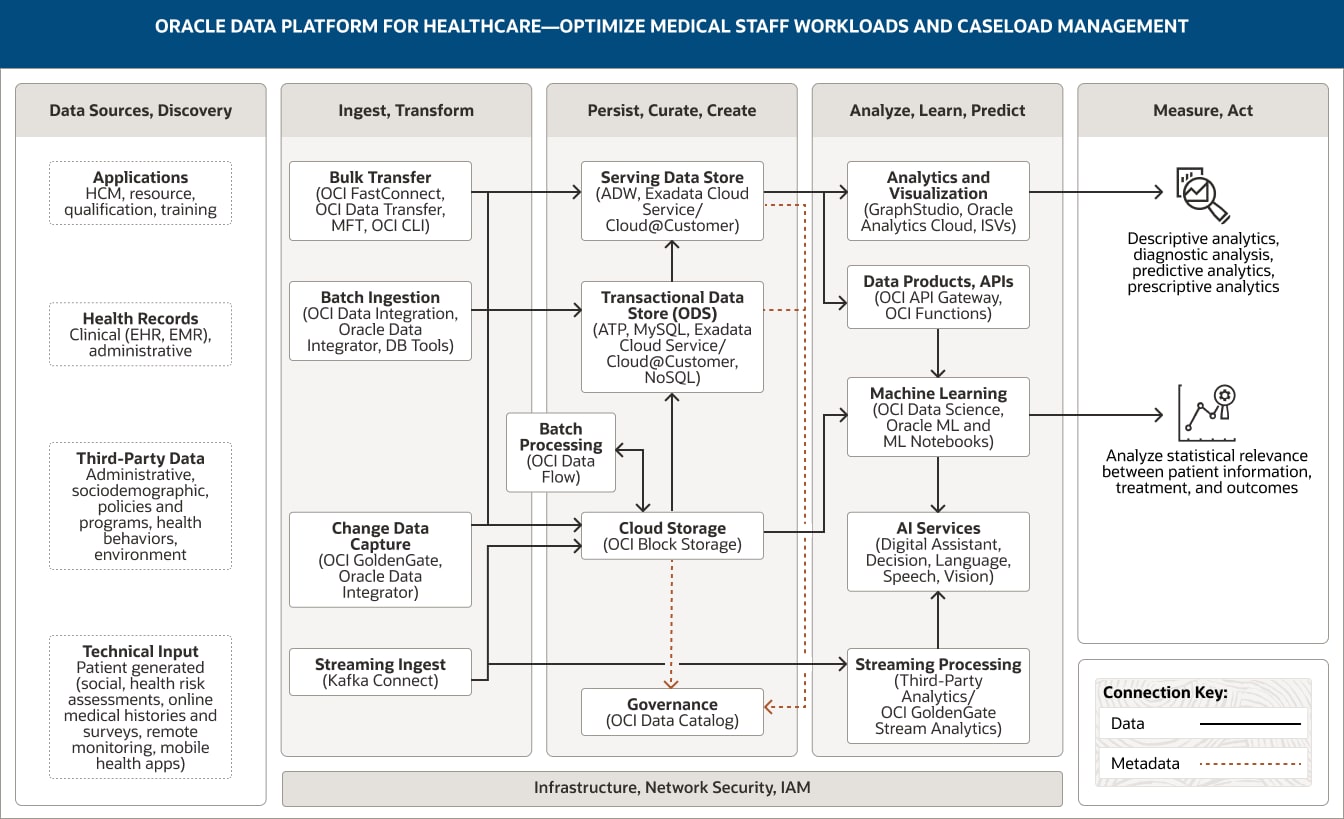
该图展示了面向医疗卫生行业的 Oracle Data Platform 如何用于优化医护人员工作量。该平台包括以下五个支柱:
- 1. 数据源、探索
- 2. 摄取、转换
- 3. 持久保存、整理、创建
- 4. 分析、学习、预测
- 5. 评估、行动
“数据源、探索”支柱包括四类数据。
- 1. 应用数据包括 HCM、资源、资格和培训数据。
- 2. 健康记录包括来自 EHR 和 EMR 的临床数据以及行政系统数据。
- 3. 第三方数据包括行政和社会人口数据、政策与方针相关数据、健康行为数据以及环境相关数据。
- 4. 技术输入数据包括患者生成的数据(如社交数据、健康风险评估、在线病史和调查结果)以及来自远程监视和移动健康应用的数据。
“摄取、转换”支柱包括四个功能。
- 1. 批量传输使用 OCI FastConnect、OCI Data Transfer、MFT 和 OCI CLI。
- 2. 批量摄取使用 OCI Data Integration、Oracle Data Integrator 和数据库工具。
- 3. 更改数据捕获使用 OCI GoldenGate 和 Oracle Data Integrator。
- 4. 流摄取使用 Kafka Connect。
所有四种功能均单向连接至“持久保存、整理、创建”支柱中的服务数据存储、云端存储和事务数据存储。
此外,流摄取连接至“分析、学习、预测”支柱中的流处理。
“持久保存、整理、创建”支柱包括五个功能。
- 1. 服务数据存储使用 Autonomous Data Warehouse、Exadata Cloud Service 和 Exadata Cloud@Customer。
- 2. 事务数据存储使用 Autonomous Transaction Processing、MySQL、Exadata Cloud Service、Exadata Cloud@Customer 和 NoSQL。
- 3. 云端存储使用 OCI Object Storage。
- 4. 批处理使用 OCI Data Flow。
- 5. 治理使用 OCI Data Catalog。
这些功能在支柱内互联。云端存储不仅单向连接至服务数据存储,还双向连接至批处理。
事务数据存储单向连接至服务数据存储。
有两个功能连接至“分析、学习、预测”支柱:服务数据存储连接至分析和可视化功能以及数据产品 API 功能;云端存储连接到机器学习功能。
“分析、学习和预测”支柱包括五个功能。
- 1. 分析和可视化使用 Oracle Analytics Cloud、GraphStudio 和 ISV。
- 2. 数据产品 API 使用 OCI API Gateway 和 OCI Functions。
- 3. 机器学习使用 OCI Data Science、Oracle Machine Learning 和 Oracle ML Notebooks。
- 4. AI 服务使用 Oracle Digital Assistant、OCI Decision、OCI Speech、OCI Language 和 OCI Vision。
- 5. 流处理使用 OCI GoldenGate Stream Analytics 和第三方的流分析。
该支柱内有三个连接的功能。数据产品 API 功能单向连接至机器学习功能,机器学习功能会单向连接至 AI 服务功能,流处理单向连接至 AI 服务功能。
服务数据存储、事务数据存储和对象存储为 OCI Data Catalog 提供元数据。
“评估、行动”支柱包含如何运用数据分析来优化医护人员工作量和病例管理。这些应用分为两组。
- 1. 第一组包括描述性分析、诊断分析以及预测性和规范性分析。
- 2. 第二组包括分析患者信息、治疗和结果之间的统计相关性。
- 3. “摄取、转换”、“持久保存、整理、创建”及“分析、学习、预测”这三大核心支柱由基础设施、网络、安全和 IAM 提供支持。
目前我们使用三种主要方法将数据注入架构中,以帮助医疗机构了解如何在不同时间点为每个部门提供最优的人员配置。
- 历史人员配备数据和患者相关数据对于了解和预测未来的人员配备需求至关重要。HCM 应用可提供必要的大量数据,用于洞察历史人员配备模型和每位员工。入院、出院和转院 (ADT) 应用可提供关于每位患者的详细基础信息。这些数据可使用第三方来源的患者数据进行扩充,包括来自社交媒体的非结构化数据。频繁实时提取或接近实时提取通常需要更改数据获取,使用 OCI GoldenGate 定期从 HCM 和 ADT 运营系统中摄取数据。OCI GoldenGate 也是不断变化的数据网格架构的重要组成部分,其中“数据产品”是核心数据对象。
- 现在,我们可以添加从可穿戴设备中获取的流数据,使用流处理服务/Kafka 实时摄取数据。例如,我们可以从带有 GPS 跟踪的可穿戴设备中摄取数据,以监视员工全天的位置和移动轨迹,并利用这些数据了解如何更合理地为各科室和患者分配医护人员。在摄取流数据(事件)后,系统将对其执行一些基础的转换/聚合操作,然后再将这些数据存储到云端存储中。
- 虽然实时需求在不断变化,但医疗卫生系统最常用的提取方法仍然是使用“提取、转换、加载”或“提取、加载和转换”流程进行批量摄取。批量摄取用于从不支持流摄取的系统(例如,旧的大型机系统)导入数据。为了全面了解患者需求,我们还需要通过快速医疗互操作性资源协议从电子医疗记录 (EMR) 或电子健康记录 (EHR) 等运营系统中摄取数据。这些数据可以源自于自各种产品和各个地理位置。批量摄取可以频繁进行,通常每 10 或 15 分钟摄取一次,但它们本质上仍然是批量的,因为这些事务是以组(而非单个事务)的形式提取和处理的。
收集的所有数据的数据持久性和处理选项基于四个组件。
- 摄取的原始数据存储在云端存储中执行批处理,包括必要的清理、扩充等操作,使数据转化为必要状态以供人员、应用或机器学习平台等下游用户使用。虽然某些数据可能被直接放置在服务数据存储中,但同时这些数据也会被放置在云端存储中。这些数据将使用 Spark 进行处理。处理过程将使用 OCI Data Flow 直接进行,也可以使用 OCI Data Integration 中的编排功能作为更大的管道的其中一部分来进行。这些处理过的数据集被返回到云端存储,以进行后续持久化、管理和分析,并最终以优化的形式加载到服务数据存储中,
- 事务数据存储用于生成运营报告,作为域数据仓库或企业数据仓库 (EDW) 的数据源。与用于提供战术和战略决策支持的 EDW 不同,事务数据存储可作为 EDW 的补充提供决策支持并用于运营报告、控制和帮助决策。运营数据存储 (ODS) 通常是一个关系数据库,可集成和持久保存来自多个来源的数据,用于为其它业务、报告、控制和运营决策提供支持。
- 我们现在已经创建了已处理的数据集,这些数据集已准备好以优化的关系形式持久保存,以在服务数据存储中进行管理和查询性能。这让医疗机构能够检查所有数据和变量,制定最合理的人员配备计划。
分析、预测和行动能力建立在两种技术方法之上。
- 分析和可视化服务提供描述性分析(使用直方图和图表描述当前趋势)、预测性分析(预测未来事件、识别趋势以及确定不确定结果的可能性)和规范性分析(提出合适的行动,从而做出理想决策)。分析和可视化的结合可以准确预测人员配备需求并提供适当建议。例如,分析可用于预测居住在特定地区的一组患者是否会受到温度等不同环境因素的影响,以及出现某些症状是否预示着即将爆发某种疾病,需要医疗机构更改人员配备模型来应对预期内的病例增加。
- 除了使用高级分析之外,我们还开发、训练并部署了机器学习模型。这些经过训练的模型可以对当前和历史运营数据运行以检测事件和趋势,例如员工不满意度上升,该趋势可能会进一步导致员工离职率上升。这些事件和其它结果可以持久保留在服务层,并使用 Oracle Analytics Cloud 等分析工具进行报告。您也可以将模型和数据馈送到 OCI Data Science 等机器学习系统中,以便进一步训练模型,在推广模型前获得更有效的人员配备模型建议。这些模型可以通过 API 访问,部署在服务数据存储中,或者将其嵌入到 OCI GoldenGate 流分析管道中。
- 您可以对经过整理、测试的高质量数据和模型应用治理规则和策略,将其作为数据网格架构中的“数据产品” (API) 公开,以便在整个医疗机构中分发。
不止人员配备:利用数据应对医疗卫生行业面临的其它重要挑战
Oracle Data Platform 不仅能够帮助医疗机构开发更好、更准确的人员配备模型,还可以帮助优化其它业务领域,进而改善患者护理、降低成本并提升员工体验。例如:
- 为目标患者群体提供全面、协调的护理。
- 提前识别疫情爆发时期出现系统故障的可能性,主动采取干预措施,确保系统正常运行。
- 监视患者队列趋势,评估护理方案的效果。
- 识别存在过度医疗问题的领域。
- 监视护理交付质量和成本。
- 构建患者风险分层模型。
- 预测患者重新入院风险。
- 提供预防性护理建议,支持患者自我管理。
相关资源
-
使用案例
医疗卫生供应链优化
了解如何使用面向医疗卫生行业的 Oracle Data Platform 提高供应链弹性。
-
使用案例
人口医疗管理
了解如何使用面向医疗卫生行业的 Oracle Data Platform 来优化人口医疗卫生管理,从而更好地满足患者需求,改善治疗效果并降低成本。
-
使用案例
通过绩效监视改进基于价值的护理
了解如何利用面向医疗卫生行业的 Oracle Data Platform 来轻松评估基于价值的护理策略。
开始行动
试用逾 20 个 Always Free 云技术服务,或在 30 天试用版中体验更多服务
Oracle 提供的免费套餐包含了 Autonomous AI Database、Arm Compute 和 Storage 等 20 多个服务,另外还有 300 美元的免费储值,让您可以试用更多云技术服务。立即获取详细信息并注册您的免费账户。
-
Oracle Cloud Free Tier 包含哪些内容?
- 2 个 Autonomous AI Database 实例,各 20 GB
- AMD 和 Arm Compute VM
- 总共 200 GB 块存储
- 10 GB 对象存储
- 每月 10 TB 出站数据传输
- 超过 10 个 Always Free 服务
- 价值 300 美元的免费储值,有效期 30 天
通过分步指导学习
通过教程和实操练习体验各种 OCI 服务。无论您是开发人员、管理员还是分析师,我们都可以帮助您了解 OCI 的工作原理。许多练习都运行于 Oracle Cloud Free Tier 或 Oracle 提供的免费练习环境中。
-
OCI 核心服务快速入门
本课程中的练习介绍了 Oracle Cloud Infrastructure (OCI) 核心服务,包括 Virtual Cloud Network (VCN) 以及计算和存储服务。
立即开始 OCI 核心服务练习 -
Autonomous AI Database 快速入门
在本课程中,您将了解如何开始使用 Oracle Autonomous AI Database。
立即开始 Autonomous AI Database 快速入门练习 -
基于电子表格构建应用
此练习将指导您如何将电子表格上传到 Oracle Database 表中,然后基于新表格创建应用。
立即开始练习
了解 150 多个优秀实践设计
了解我们的架构师和其他客户如何部署各种工作负载,包括从企业应用到高性能计算 (HPC),再从微服务到数据湖的工作负载。您可以观看“构建并部署”系列视频,参考来自其他客户架构师的优秀实践,使用“一键部署”功能或者通过 GitHub 库部署更多工作负载。
广受欢迎的架构
- Apache Tomcat 和 MySQL Database Service
- 在 Kubernetes 上运行 Oracle Weblogic 和 Jenkins
- 机器学习 (ML) 和人工智能 (AI) 环境
- 基于 Arm 的 Tomcat 和 Oracle Autonomous AI Database
- 使用 ELK Stack 进行日志分析
- 使用 OpenFOAM 的高性能计算
体验不同之处:
- 1/4 出站带宽成本
- 3 倍计算性价比
- 全球统一超低价格
- 超低定价且无需缴付多年的承诺款
注:为免疑义,本网页所用以下术语专指以下含义:
- 除Oracle隐私政策外,本网站中提及的“Oracle”专指Oracle境外公司而非甲骨文中国。
- 相关Cloud或云术语均指代Oracle境外公司提供的云技术或其解决方案。