Servicio Data Science
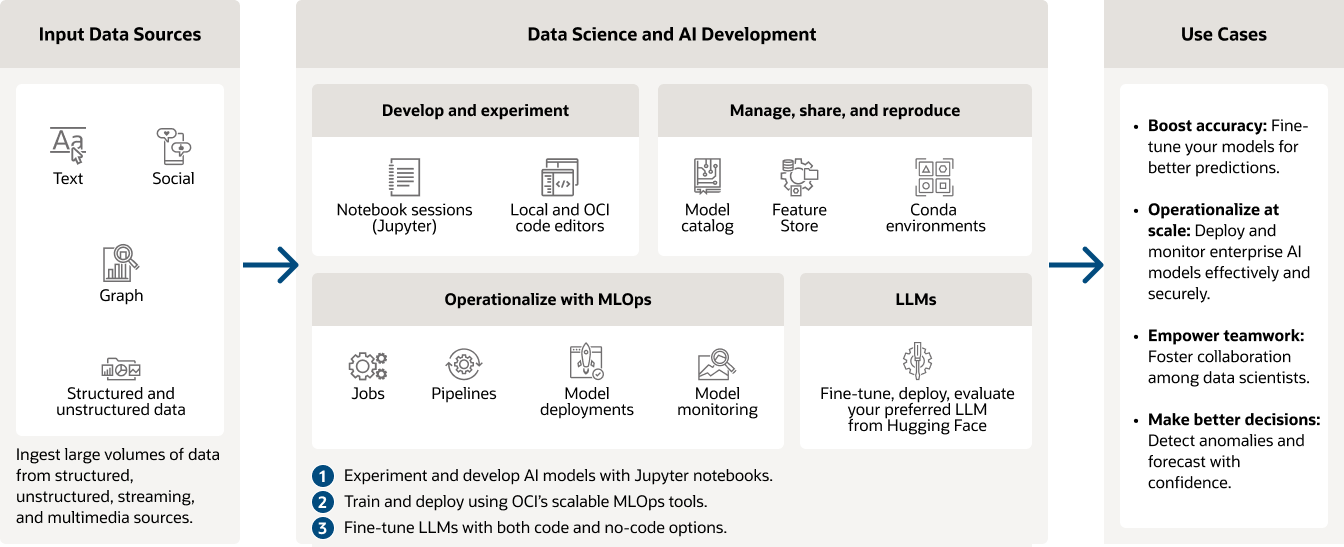
Oracle Cloud Infrastructure (OCI) Data Science es una plataforma totalmente gestionada que permite a los equipos de científicos de datos crear, entrenar, implementar y gestionar modelos de aprendizaje automático (ML) a través de Python y herramientas de código abierto. Utiliza un entorno basado en JupyterLab para experimentar y desarrollar modelos. Amplía el entrenamiento de modelos con GPU NVIDIA y formación distribuida. Incluye modelos en la fase de producción y mantenlos en condiciones adecuadas con capacidades de operaciones de aprendizaje automático (MLOps), como pipelines automatizados, implementación de modelos y control de modelos.

Simplifica tu trabajo con modelos básicos mediante la nueva función Acciones rápidas de IA de OCI Data Science
Las acciones rápidas de IA de OCI Data Science permiten que cualquier persona implemente, ajuste y evalúe fácilmente modelos básicos.
- OCI Data Science admite los modelos de peso abierto de OpenAI
OpenAI ha anunciado el lanzamiento de dos modelos de peso abierto, gpt-oss-120b y gpt-oss-20b, que se pueden desplegar y ajustar en OCI Data Science.
- Simplifica tu trabajo con modelos básicos
Implementa, ajusta y evalúa modelos básicos con acciones rápidas de IA de OCI Data Science.
- Ahora disponible: Cohere Embed 4 en OCI Generative AI
Mejora la generación aumentada por recuperación y búsqueda con el último modelo de integración de alto rendimiento de Cohere, al que ahora se puede acceder a través de OCI.
- Prueba OCI Data Science de forma gratuita
Una prueba gratuita de Oracle Cloud te permite acceder a OCI Data Science con 300 dólares en créditos gratuitos en la nube.
¿Cómo funciona OCI Data Science?
OCI Data Science es un servicio gestionado integral diseñado para simplificar el desarrollo, implementación y operación de modelos de IA y aprendizaje automático. Las características clave incluyen notebooks basados en Jupyter para experimentación, herramientas MLOps escalables para implementación y monitoreo de modelos, y soporte integrado para modelos de lenguaje grandes (LLM) a través de Hugging Face y otros frameworks.
Con herramientas robustas para colaboración, detección de anomalías y predicción, OCI Data Science permite a los equipos ofrecer información procesable de manera eficiente y segura.
AI Quick Actions en OCI Data Science simplifica la experiencia de sus usuarios, inclusive los que carecen de conocimientos técnicos, para que puedan implementar, personalizar, probar y evaluar modelos básicos más rápidamente y centrarse en crear aplicaciones generativas impulsadas por IA.
Casos de uso de OCI Data Science
Sector salud: riesgo de reingreso de pacientes
Identifica factores de riesgo y predice el riesgo de reingreso del paciente después de recibir el alta mediante la creación de un modelo predictivo. Utiliza datos, como la historia clínica del paciente, condiciones de salud, factores ambientales y tendencias médicas históricas, para construir un modelo más sólido que ayude a proporcionar la mejor atención a un costo menor.
Sector minorista: predice el valor de tiempo de vida de cliente
Utiliza técnicas de regresión en los datos para predecir el futuro gasto de los clientes. Analiza las transacciones anteriores y combina datos históricos de clientes con datos sobre tendencias, niveles de ingresos e incluso factores como el clima para crear modelos de aprendizaje automático que determinen si se deben crear campañas de marketing para mantener a los clientes actuales o adquirir otras nuevas.
Fabricación: mantenimiento predictivo
Crea modelos de detección de anomalías a partir de los datos de los sensores para detectar fallas de los equipos antes de que se conviertan en un problema más grave. o utiliza modelos de previsión para predecir el final de la vida útil de las piezas y la maquinaria. Aumenta el tiempo de actividad de los vehículos y la maquinaria utilizando métricas de operaciones de supervisión y aprendizaje automático.
Finanzas: detección de casos de fraude
Evita los casos de fraude y los delitos financieros con ciencia de datos. Crea un modelo de aprendizaje automático que pueda identificar eventos anómalos en tiempo real, incluidos importes fraudulentos o tipos inusuales de transacciones.
¿Por qué recurrir a OCI Data Science?
-
Ciencia de datos de alto rendimiento
Obtén acceso a flujos de trabajo automatizados para la creación de modelos. Pon en marcha el aprendizaje automático de manera más sencilla con trabajos reutilizables y organización completa durante todo el ciclo de vida del aprendizaje automático. Ejecuta cargas de trabajo distribuidas y de alto rendimiento con acceso a GPU de bajo costo.
-
Plataforma abierta
Obtén lo mejor del AA en Oracle gracias a sólidas alianzas con grandes socios, como Anaconda. Incorpora modelos, datos y código en el formato que necesites.
-
Mejor soporte de su categoría
Aprovecha el tratamiento de primer nivel para las alianzas estratégicas del aprendizaje automático. Los científicos de datos de Oracle están dedicados a garantizar el éxito de tu empresa.
Alianzas y éxitos de clientes con OCI Data Science





Arquitectura de referencia de IA / aprendizaje automático
-
Guías de soluciones
Descubre cómo un sistema sanitario almacena, utiliza y analiza los datos para acompañar el historial de un paciente desde el diagnóstico hasta su recuperación.
-
Arquitecturas de referencia
Utiliza este patrón para crear plataformas de aprendizaje automático diseñadas para científicos de datos.
-
Built and Deployed
Implementa rápidamente una arquitectura para gestionar de forma segura grandes cantidades de datos de origen y crear modelos predictivos y aprovecharlos en aplicaciones de rápido desarrollo.
-
Arquitecturas de referencia
Enriquece los datos de aplicaciones empresariales con datos sin procesar de otras fuentes y utiliza modelos de AA para incorporar inteligencia y conocimientos predictivos en los procesos comerciales.
Recursos de OCI Data Science:
-
Aprendizaje en la nube