Big Data-Plattform
Führen Sie nahtlos Apache Spark, Hive, Trino, Flink und mehr aus und skalieren Sie diese. Entdecken Sie die Leistungsfähigkeit einer einfachen Entwicklung und Visualisierung mithilfe von Data Science-Notizbüchern, bei der Sie vertraute Open Source-Tools nutzen können. Und das alles zu einem überragenden Preis-Leistungsverhältnis.
Entdecken Sie die Funktionen der OCI Big Data-Plattform
-
![]()
Open Source-Upstream-Services
Wir bieten Ihnen ein umfassendes Portfolio an Open Source-Komponenten wie Hadoop und Spark.
-
![]()
Vollständig verwaltet, autoskalierend und elastisch
Konzentrieren Sie sich auf Ihre Daten und Ihren Code – wir kümmern uns um den Rest.
-
![]()
Einfache Migration und Modernisierung
Open Source-Projekte lassen sich einfach verwenden und wir halten Sie in Bezug auf aktuelle Innovationen auf dem Laufenden.
-
![]()
Nativ in OCI integriert
Nutzen Sie mühelos alle Oracle Cloud Infrastructure-(OCI-)Services und erweitern Sie diese.
-
![]()
Sicherheit auf Unternehmensniveau
Über 30 Compliance-Zertifizierungen stellen Ihren Datenschutz sicher.
-
![]()




Daten sind der Rohstoff des maschinellen Lernens. Erfahren Sie, wie Sie in der Cloud bei den bereits vorhandenen Daten maschinelles Lernen einsetzen können.
Big Data-Cluster können einfach zu OCI migriert werden. Entdecken Sie die Richtlinien zu unserem Migrationshub.
Fassen Sie alle Ihre Daten in einem Data Lake zusammen
-
Komplette, integrierte Lösung
Stellen Sie eine vollständige, integrierte Lösung bereit, welche das Datenmanagement, die Datenintegration und die Data Science umfasst. Dies ermöglicht Analyseteams, den Wert von Unternehmensdaten zu maximieren. Die Kunden nehmen jegliche Daten über Batch-, Streaming- oder Echtzeitprozesse auf und speichern diese je nach Bedarf in Data Warehouses oder Data Lakes. Die Teams katalogisieren diese dann und bereiten sie mittels Daten-Governance auf, sodass sie für Analysen, Visualisierungen oder maschinelle Lernmodelle verwendet werden können. Die IT-Teams nutzen dabei konsistente Sicherheitsrichtlinien über alle Data Warehouses und Data Lakes hinweg.
-
Einfache Verwaltung und Bedienung
Steigern Sie die Produktivität von Entwicklern mit einem vollständig verwalteten, serverlosen Apache Spark-Cluster, auf das sich über APIs zugreifen lässt. Jedes Cluster wird automatisch bereitgestellt, gesichert und heruntergefahren, sodass sich die Workloads der Entwickler verringern. Die Kunden können vollständig verwaltete Hadoop-Cluster beliebiger Größe oder Form bereitstellen und anschließend mit einem einzigen Klick Sicherheitsfunktionen und Hochverfügbarkeit hinzufügen.
-
Bereitstellung in Oracle Cloud- oder Kunden-Data Centern
Stellen Sie die Oracle Big Data Services überall dort bereit, wo dies entsprechend der Anforderungen an die Kundendatenresidenz und -latenz erforderlich ist. Die Big Data Services können zusammen mit allen anderen Oracle Cloud Infrastructure-Diensten von den Kunden in der Oracle Public Cloud genutzt werden. Sie können aber auch als Teil der Oracle Dedicated Region Cloud@Customer-Umgebung in kundeneigenen Data Centern bereitgestellt werden.
Migrieren Sie Ihre Big Data-Workload zu OCI – und sparen Sie dabei.
Wechseln Sie mit OCI Big Data-Services reibungslos in die Cloud. Unser umfassender, bewährter Ansatz unterstützt eine problemlose Migration, unabhängig davon, ob Sie vorhandene Data Lakes, Spark, Hadoop, Flink, Hive oder andere Hadoop-Komponenten verwenden. Migrieren Sie zu OCI ohne umfangreiche Konfiguration oder Integration und mit nur minimalen Auswirkungen auf Ihre aktuelle Umgebung. Profitieren Sie von detaillierten Schritt-für-Schritt-Ressourcen und fachkundigen Anleitungen von den Ingenieuren und Partnern von Oracle, um einen nahtlosen Wechsel in die Cloud zu gewährleisten.
Verschieben Sie IhreUmgebung mit Apache Hadoop zu OCI Big Data
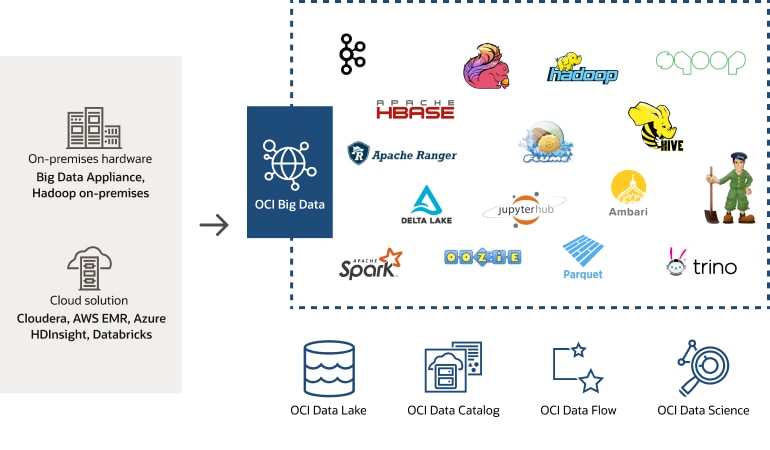
- Vollständig verwaltet: Wir unterstützen und verwalten Apache Hadoop- und Spark-Ökosysteme, damit Sie Ihre Big Data-Workload in der Cloud ausführen und skalieren können.
- Einfache Migration: Migrieren Sie Ihre Workload zu OCI und behalten Sie dabei Ihre vertrauten Open Source-Tools bei – und das alles zu einem überragenden Preis-Leistungsverhältnis.
- Nahtlose Integration: Sichern Sie sich eine einheitliche Erfahrung für alle Ihre Datenanwendungen in OCI und nutzen Sie Oracle Modern Data Platform.
Die Oracle Datenplattform erschließt das volle Potenzial Ihrer Daten
- Kombinieren Sie transaktionale und analytische Daten und vermeiden Sie Silos.
- Von Oracle IaaS bis Oracle SaaS oder irgendwas dazwischen – wählen Sie den gewünschten Kontrollumfang.
- Bringen Sie beliebige Daten auf die Plattform – Wir durchbrechen die Grenze zwischen strukturierten und unstrukturierten Daten.
- Entdecken Sie die Leistungsfähigkeit von OCI und seine Offenheit für andere Cloud-Serviceanbieter – Wir holen Sie dort ab, wo Sie sind.
- Nutzen Sie das führende Oracle Analytics Cloud-Reporting oder jede beliebige Analyseanwendung eines Drittanbieters – OCI ist offen.
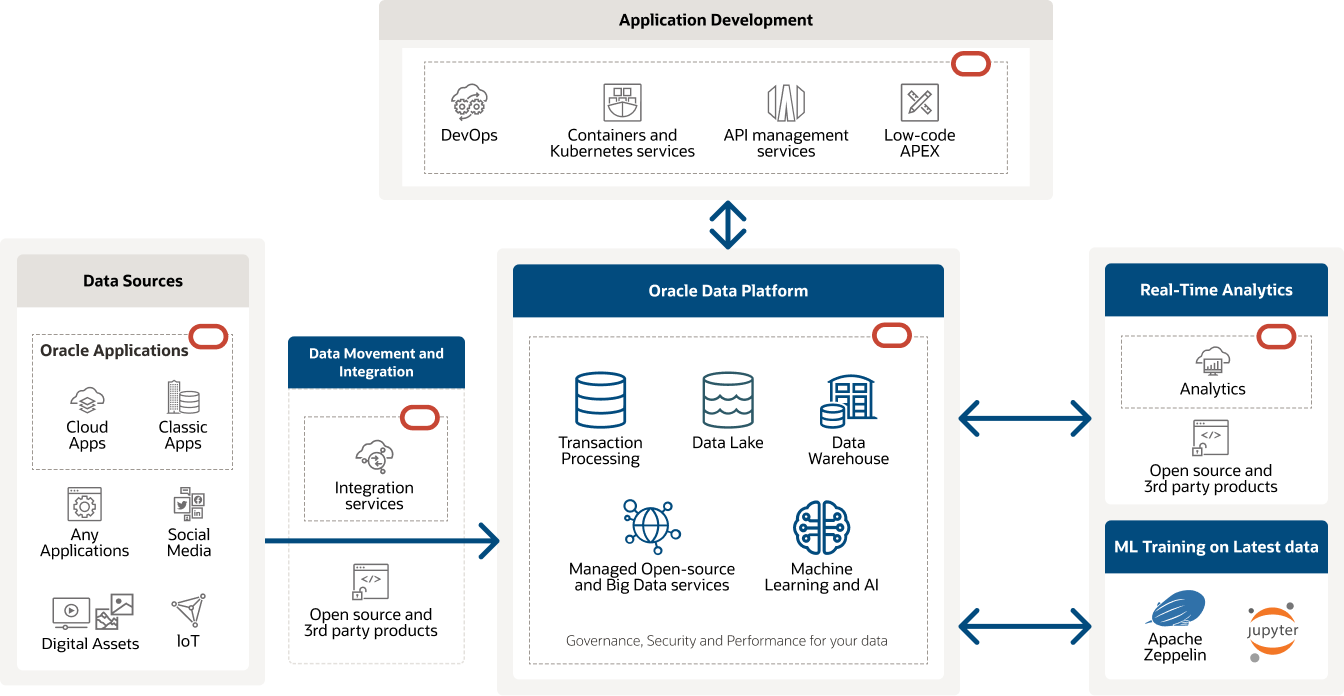 Das Diagramm zeigt die Oracle Datenplattform mit Datenquellen, Datenübertragungsservices wie Integrationsservices, den Kern der modernen Oracle Datenplattform und möglichen Ergebnis- und Anwendungsentwicklungs-Services.
Das Diagramm zeigt die Oracle Datenplattform mit Datenquellen, Datenübertragungsservices wie Integrationsservices, den Kern der modernen Oracle Datenplattform und möglichen Ergebnis- und Anwendungsentwicklungs-Services. Erfahren Sie, wie unsere Kunden Big Data nutzen



Big Data-Services von Oracle
-
Datenbewegung und -integration
-
Verbinden und erweitern Sie analytische Anwendungen mit einheitlichen Echtzeit-Transaktionsdaten, effizienten Batch-Loads und Streaming-Daten.
- OCI Data Integration
Vereinfachen Sie Ihre komplexen Prozesse zum Extrahieren, Transformieren und Laden von Daten (ETL/E-LT) in Data Lakes und Warehouses für Data Science und Analysen mit einem Data Flow-Designer (ohne Programmieraufwand). - Oracle Data Integrator
Data Integrator bietet eine erweiterte Datenmigration zum Extrahieren, Transformieren und Laden. Oracle Data Integrator ist sowohl für Cloud-Datenbanken von Oracle als auch für On-Premises-Datenbanken optimiert. - Oracle GoldenGate
Oracle GoldenGate ermöglicht Hochverfügbarkeit, Datenintegration in Echtzeit, Änderung von Datenerfassung, Datenreplikation, Transformationen und Überprüfung zwischen betrieblichen und analytischen Unternehmenssystemen. - OCI Streaming
Streaming bietet sofort einsatzbereite Integrationen für Hunderte von Produkten von Drittanbietern in verschiedenen Kategorien wie DevOps, Datenbanken, Big Data und SaaS-Anwendungen.
-
Big Data und Data Lake
-
Erfüllen Sie Ihre Big Data-Anforderungen in einer Open Source-Plattform
- OCI Big Data
Bei OCI Big Data handelt es sich um einen Hadoop-basierten Data Lake-Service zum Speichern und Analysieren großer Mengen roher Kundendaten. OCI Big Data ist ein verwalteter Dienst, der über einen vollständig integrierten Stack verfügt, der sowohl Open Source- als auch Oracle Tools zur Wertschöpfung enthält, um Ihren IT-Betrieb zu vereinfachen. - OCI Data Flow
Data Flow ist ein vollständig verwalteter Service von Apache Spark, mit dem Verarbeitungsaufgaben für extrem große Datenmengen ausgeführt werden können, ohne dass eine Infrastruktur bereitgestellt oder verwaltet werden muss. Dies ermöglicht eine schnelle Anwendungsbereitstellung, da sich Entwickler auf die App-Entwicklung und nicht auf die Infrastrukturverwaltung konzentrieren können. - OCI Data Catalog
Data Catalog unterstützt mithilfe eines Inventars an unternehmensweiten Datenbeständen Datenprofis im gesamten Unternehmen bei der Datensuche, -analyse und -verwaltung. - OCI Object Storage
Mit dem Object Storage können Kunden alle Arten von Daten in ihrem nativen Format speichern. Dies ist ideal zum Erstellen moderner Anwendungen, die Skalierbarkeit und Flexibilität erfordern.
-
KI und Machine Learning
-
Gewinnen Sie Erkenntnisse aus Daten mit vorgefertigten KI-Modellen, oder erstellen Sie Ihre eigenen.
- OCI AI Services
AI Services ist eine Sammlung von Services mit vordefinierten Modellen für maschinelles Lernen, die es Entwicklern erleichtern, KI auf Anwendungen und Geschäftsabläufe anzuwenden. Die Modelle können individuell trainiert werden, um genauere Geschäftsergebnisse zu erzielen. - OCI Data Science
Erstellen, trainieren, implementieren und verwalten Sie schnell ML-Modelle mit einem für Teams entwickelten Data-Science-Service. - Machine Learning in Oracle Database
Machine Learning in Oracle Database unterstützt Datenexploration, -aufbereitung und -modellierung für maschinelles Lernen in großem Maßstab. - MySQL HeatWave AutoML
HeatWave AutoML enthält alles, was Benutzer zum Erstellen, Trainieren, Bereitstellen und Erläutern von ML-Modellen in MySQL HeatWave benötigen, und das ohne zusätzliche Kosten.
Big Data-Architekturen auf OCI
Oracle erweitert seine Cloud-Services um neue Open-Source-Datenmanagementlösungen
Carter Shanklin, Senior Director Produktmanagement
Oracle Cloud Infrastructure (OCI) ist sehr erfreut, drei neue verwaltete Open-Source-Cloud-Services für das Datenmanagement sowie drei erhebliche Verbesserungen zu bestehenden Services ankündigen zu können. Diese Services bieten eine breite Palette von Funktionen, mit denen Unternehmen jeder Größe ihre Datenvorgänge verbessern können.
Ausgewählte Big Data-Blogs
- 19. September 2023 Oracle bietet Kunden frühzeitigen Zugriff auf OCI Data Lake
- 19. September 2023 Einführung in OCI Data Flow- SQL-Endpunkte
Erste Schritte mit der OCI Big Data-Plattform
Probieren Sie Always Free-Cloud-Services aus und erhalten Sie eine 30-Tage-Testversion
Oracle bietet ein kostenloses Kontingent ohne zeitliche Begrenzung für eine Auswahl von Services an, einschließlich Autonomous Data Warehouse, OCI Compute und Oracle Storage-Produkten, sowie 300 USD in kostenlosem Guthaben, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- Immer kostenlos
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- Compute VMs
- 100 GB Block-Volume
- 10 GB Objektspeicher
Mit einer praktischen Übung lernen
Man lernt am besten, wenn man es selbst ausprobiert. Probieren Sie diesen kostenlosen Data Lake-Workshop aus, der ein typisches Nutzungsszenario demonstriert und einige der Tools hervorhebt, die Sie zum Erstellen eines Data Lake verwenden können.
-
Mit Autonomous AI Database und Data Catalog auf den Data Lake zugreifen
In den Übungen dieses Workshops werden die Schritte erläutert, die Sie für den Zugriff auf einen Data Lake benötigen, der mit Oracle Object Storage-Buckets mit Oracle Autonomous AI Database und OCI Data Catalog erstellt wurde.
Übung für den Data Lake-Zugriff starten -
Erste Schritte mit Oracle Big Data Service
Erfahren Sie, wie Sie mit Big Data Service und OCI einen hochverfügbaren Hadoop-Cluster erstellen und überwachen. Darüber hinaus fügen Sie dem Cluster Oracle Cloud SQL hinzu und greifen auf das Dienstprogramm und den Master-Knoten zu. Außerdem erfahren Sie, wie Sie Cloudera Manager und Hue verwenden, um direkt in einem Webbrowser auf den Cluster zuzugreifen.
Data Lake-Übung starten -
Analytics und maschinelles Lernen mit Red Bull Racing entdecken
Nutzen Sie Analysen und maschinelles Lernen, um die Renndaten der letzten 70 Jahre zu analysieren. Finden Sie heraus, was manche Rennen so spannend macht, dass man nicht wegsehen kann, während andere eher vorhersehbar sind.
Übung zur Datenanalyse starten -
Erste Schritte mit Oracle Cloud Infrastructure Anomaly Detection
Erfahren Sie, wie Sie mit der Anomalieerkennung von OCI benutzerdefinierte ML-Modelle erstellen können. Sie verwenden von Benutzern hochgeladene Daten, einen speziellen Algorithmus, um ein Modell zu trainieren, und stellen das Modell in der Cloud-Umgebung bereit, um Anomalien zu erkennen.
Übung zur Anomalieerkennung jetzt starten
Vertrieb kontaktieren
Möchten Sie mehr über ein Data Lake erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten, z. B.
- Wie sehen die ersten Schritte mit einem Oracle Data Lake aus?
- Was kann ich mit einem Data Lake machen, was mit einem Data Warehouse nicht möglich ist?
- Wie kann mein Unternehmen von einem Data Lake profitieren?