Steigerung der betrieblichen Effizienz und Leistung in der Fertigung

Verbesserung von Leistung, Qualität und Nachhaltigkeit durch erweiterte Analysen
Für die Fertigungsindustrie ist die Verwendung von Daten zur Verbesserung der betrieblichen Effizienz und Leistung besonders relevant, da der Anwendungsfall auf jede Art von Fertigungssystem angewendet werden kann, einschließlich der Computerized Numerical Control-(CNC-)Infrastruktur, Lieferketten- und Warehouse-Systeme, Logistik- und Testsysteme usw.
Während sich Hersteller traditionell auf historische, beschreibende und diagnostische Metriken konzentriert haben, beginnen sie nun, erweiterte Analysen, maschinelles Lernen und Data Science einzusetzen, um Leistungssteigerungen zu messen sowie proaktive, prädiktive und präskriptive Empfehlungen zu entwickeln.
Dieser Anwendungsfall konzentriert sich auf die Architektur der Datenplattform, die erforderlich ist, um Daten aufzunehmen, zu speichern, zu verwalten und Erkenntnisse aus Daten zu gewinnen, die von Manufacturing Execution Systems (MES), Warehouse Management Systems (WHMS), Computerized Maintenance Management Systems (CMMS) und Instandhaltungssystemen erzeugt werden, um die betriebliche Effizienz von Anlagen, Produktionslinien und Werken sowie Leistungskennzahlen zu messen.
Durch die Erfassung, Aufbereitung und Analyse von Daten über Produktionsprozesse und -leistung können Hersteller Engpässe und Ineffizienzen erkennen und beseitigen, um Produktionspläne zu optimieren und den Output zu erhöhen. Die Anwendung des gleichen Ansatzes auf Daten zur Produktqualität ermöglicht es Herstellern, Muster und die Ursachen von Mängeln zu erkennen, was ihnen hilft, wirksamere Maßnahmen zur Qualitätskontrolle zu ergreifen. Darüber hinaus können Hersteller durch die Einbeziehung von Daten zum Energieverbrauch Bereiche ermitteln, in denen sie die Energieeffizienz steigern können, um Kosten zu senken und die Nachhaltigkeit zu verbessern.
Optimierung der vorausschauenden Wartung und Kostensenkung mit einer umfassenden Datenplattform
Die hier vorgestellte Architektur zeigt, wie wir empfohlene Oracle Komponenten kombinieren können, um eine Analysearchitektur aufzubauen, die den gesamten Datenanalyse-Lebenszyklus abdeckt (von der Erkennung bis zur Aktion und Messung) und die breite Palette der oben beschriebenen Geschäftsvorteile bietet.
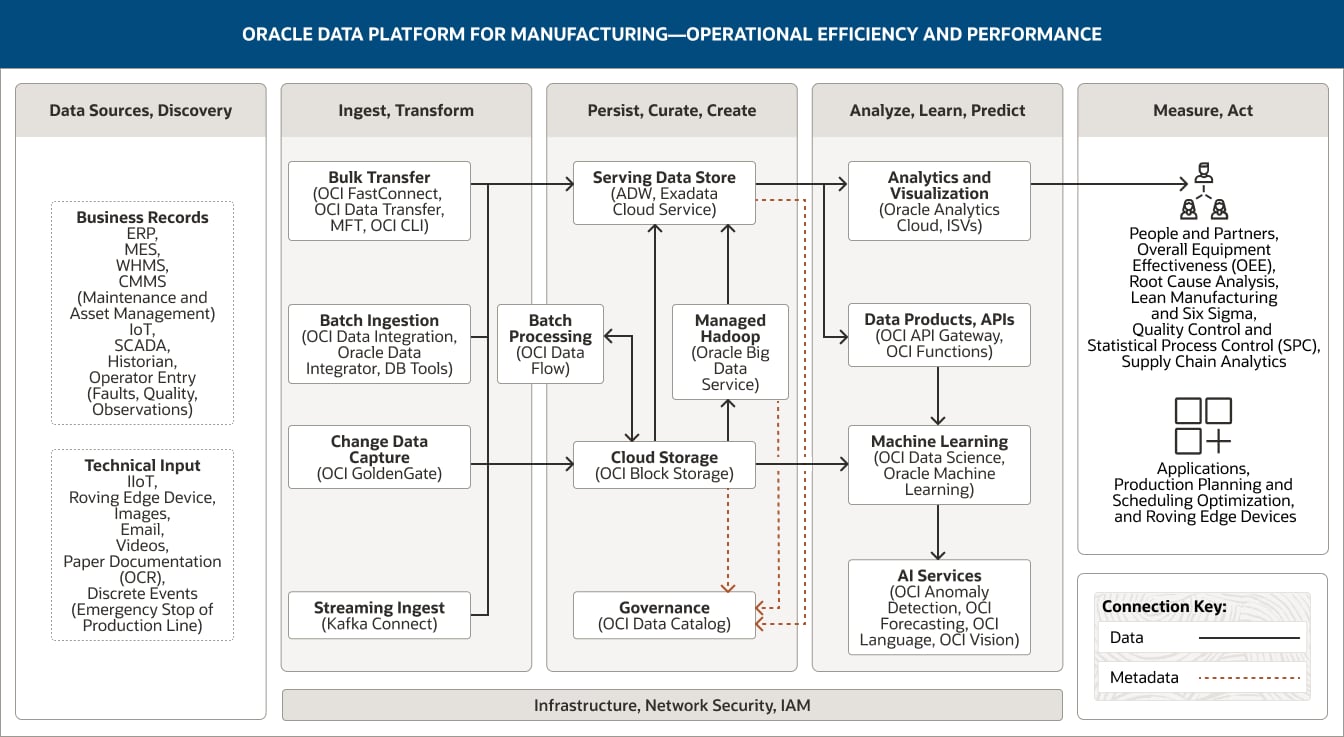
Diese Abbildung zeigt, wie die betriebliche Effizienz und Leistung mit Oracle Data Platform für die Fertigung unterstützt werden kann. Die Plattform umfasst die folgenden fünf Pillar:
- 1. Datenquellen, erkennen
- 2. Aufnehmen, transformieren
- 3. Ausharren, kuratieren, schaffen
- 4. Analysieren, lernen, prognostizieren
- 5. Messen, handeln
Der Pillar „Datenquellen, Entdeckung“ umfasst drei Datenkategorien.
- 1. Die Daten der Oracle App umfassen Daten aus Fusion SaaS, Oracle E-Business Suite, CX
- 2. Geschäftsdatensätze (First-Party-Daten) CRM, Transaktionen, Kontoinformationen, Umsatz und Gewinnspanne
- 3. Third-Party-Daten umfassen Devisenkurse, Marktfeeds und Rohstoffpreise
Der Pillar „Aufnehmen, transformieren“ umfasst vier Funktionen.
- 1. Die Batch-Ingestion verwendet OCI Data Integration, Oracle Data Integrator und DB-Tools.
- 2. Die Massenübertragung verwendet OCI FastConnect, OCI Data Transfer, MFT und OCI CLI.
- 3. Die Datenänderungserfassung verwendet OCI GoldenGate.
- 4. Die Streaming-Ingestion verwendet OCI Streaming Kafka Connect.
Alle vier Funktionen verbinden sich unidirektional mit dem bereitstellenden Datenspeicher und dem Cloud-Speicher innerhalb des Pillars „Beibehalten, kurieren, erstellen“.
Darüber hinaus ist die Streaming-Aufnahme mit der Stream-Verarbeitung innerhalb des Pillars „Analysieren, lernen, prognostizieren“ verbunden.
Der Pillar „Beibehalten, kurieren, erstellen“ umfasst fünf Funktionen.
- 1. Der zugrunde liegende Datenspeicher verwendet Oracle Autonomous Data Warehouse und Exadata Cloud Service.
- 2. Der Cloud-Speicher verwendet OCI Object Storage.
- 3. Managed Hadoop verwendet Oracle Big Data Service
- 4. Die Batchverarbeitung verwendet OCI Data Flow.
- 5. Governance verwendet OCI Data Catalog.
Diese Funktionen sind innerhalb des Pillars miteinander verbunden. Der Cloud-Speicher ist unidirektional mit dem Serving Data Store und außerdem bidirektional mit der Batchverarbeitung verbunden.
Zwei Funktionen sind mit dem Pillar „Analysieren, lernen, prognostizieren“ verbunden. Der bereitstellende Datenspeicher ist sowohl mit der Analyse- und Visualisierungsfunktion als auch mit den Datenprodukten und API-Funktionen verbunden. Der Cloud-Speicher ist mit der ML-Funktion verbunden.
Der Pillar „Analysieren, lernen, prognostizieren“ umfasst zwei Funktionen.
- 1. Analysen und Visualisierungen verwenden Oracle Analytics Cloud, GraphStudio und ISVs.
- 2. Maschinelles Lernen nutzt Oracle Machine Learning.
Der Pillar „Messen, handeln“ erfasst, wie die Datenanalyse verwendet werden kann: von Mitarbeitern und Partnern.
Mitarbieter und Partner umfassen betriebliche Effizienz (Verarbeitungszeiten, Fehlerquoten, Ressourcenauslastung), Identifizierung von Prozessengpässen, Customer Lifetime Value, Markt- und Wettbewerbsanalyse, Performance-Attribution.
Die drei zentralen Pillar – Aufnehmen, transformieren; Ausharren, kuratieren, schaffen; und Analysieren, lernen, prognostizieren – werden durch Infrastruktur, Netzwerk, Sicherheit und IAM unterstützt.
Daten verbinden, aufnehmen und transformieren
Unsere Lösung besteht aus drei Pillar, die jeweils spezifische Datenplattformfunktionen unterstützen. Der erste Pillar bietet die Möglichkeit, Daten zu verbinden, aufzunehmen und zu transformieren.
Es gibt vier wesentliche Möglichkeiten, um Daten in eine Architektur einzuspeisen, die es Fertigungsunternehmen ermöglicht, ihre betriebliche Effizienz und Leistung zu verbessern.
- Um unseren Prozess zu starten, aktivieren wir die Massenübertragung von operativen Transaktionsdaten. Bulk-Transfer-Services werden in Situationen verwendet, in denen große Datenmengen zum ersten Mal in die Oracle Cloud Infrastructure (OCI) verschoben werden müssen, z. B. Daten aus vorhandenen On-Premises-Analyse-Repositorys oder anderen Cloud-Quellen . Welcher Massenübertragungsdienst verwendet wird, hängt vom Speicherort der Daten und der Häufigkeit der Übertragung ab. Beispielsweise kann OCI Data Transfer Service oder OCI Data Transfer Appliance verwendet werden, um eine große Menge an On-Premises-Daten aus historischen Planungs- oder Data Warehouse-Repositorys zu laden. Wenn große Datenmengen kontinuierlich verschoben werden müssen, empfehlen wir die Verwendung von OCI FastConnect, das eine dedizierte private Netzwerkverbindung mit hoher Bandbreite zwischen dem Data Center eines Kunden und OCI bietet.
- Häufige Echtzeit- oder nahezu Echtzeit-Extrakte sind oft erforderlich, und Daten werden regelmäßig von Lagerverwaltungs-, Planungs- und Auftragsverwaltungssystemen mit OCI GoldenGate aufgenommen. OCI GoldenGate verwendet die Erfassung von Änderungsdaten, um Änderungsereignisse in der zugrunde liegenden Struktur der Systeme zu erkennen, die gewartet werden müssen (z. B. das Hinzufügen einer neuen Komponente, abgeschlossene Wartungsarbeiten, Wetteränderungen usw.) und sendet die Daten in Echtzeit an eine Persistenzschicht und/oder den Streaminglayer.
- Für Fertigungsunternehmen kann die Echtzeit-Analyse von Daten aus mehreren Quellen wertvolle Einblicke in ihre Betriebseffizienz und Gesamtleistung liefern. In diesem Anwendungsfall verwenden wir die Streaming-Ingestion, um alle Daten einzuspeisen, die von Sensoren über IoT, Machine-to-Machine-Kommunikation und andere Mittel gelesen werden. Die Möglichkeit, Datenstreams in Echtzeit zu erfassen und zu analysieren, ist entscheidend für einen Hersteller, der vorausschauende Anlagenwartungen durchführen möchte. Die Datenströme können von verschiedenen ISA-95 Level 2-Systemen stammen, z. B. von SCADA-Systemen (Supervisory Control and Data Acquisition), speicherprogrammierbaren Steuerungen und Batch-Automatisierungssystemen. Daten (Ereignisse) werden aufgenommen und es finden einige grundlegende Transformationen/Aggregationen statt, bevor sie im OCI Object Storage gespeichert werden. Mit zusätzlichen Streaminganalysen können korrelierende Ereignisse identifiziert werden, und alle identifizierten Muster können (manuell) zur Prüfung der Rohdaten anhand von OCI Data Science zurückgesendet werden.
- Um diese hochfrequenten Streaming-Daten in Echtzeit zu analysieren, verwenden wir die Streaming-Verarbeitung, um erweiterte Analysen bereitzustellen. Während herkömmliche Analysetools Informationen aus Daten im Ruhezustand extrahieren, bewertet die Streaming-Analyse den Wert von Daten in Bewegung, d. h. in Echtzeit. Und das ist nicht der einzige Vorteil. Da die Streaming-Analyse hochgradig automatisiert werden kann, kann sie den Herstellern beim Senken der Betriebskosten behilflich sein. Streaming-Analysen können beispielsweise Echtzeitdaten zu grundlegenden Versorgungskosten wie Strom und Wasser liefern. Fabriken und Werke können dann ein automatisiertes Streaming-Analysetool verwenden, um auf sofortige Einblicke in Bereiche zuzugreifen, die optimiert werden könnten, um die Energiekosten zu senken und mithilfe künstlicher Intelligenz angemessen auf bestimmte betriebliche Ereignisse zu reagieren. Streaming-Analysen können auch Echtzeitprognosen über bevorstehende Wartungsanforderungen für Geräte treffen und Unternehmen dabei helfen, sich frühzeitig auf anstehende Reparaturen oder routinemäßige Wartungsarbeiten vorzubereiten.
- Während sich die Echtzeitanforderungen weiterentwickeln, ist der häufigste Extract aus ERP-, Planungs-, Lagerverwaltungs- und Transportverwaltungssystemen eine Art Batch-Ingestion mit einem ETL-Prozess. Die Batch-Ingestion wird verwendet, um Daten aus Systemen zu importieren, die kein Datenstreaming unterstützen (z. B. ältere SCADA- oder Wartungsverwaltungssysteme). Diese Extracts können häufig aufgenommen werden, so oft wie alle 10 oder 15 Minuten. Sie sind jedoch immer noch in Batch-Form, da Transaktionsgruppen extrahiert und verarbeitet werden und nicht einzelne Transaktionen. OCI bietet verschiedene Services für die Batch-Ingestion, wie z. B. den nativen OCI Data Integration-Service und Oracle Data Integrator, die auf einer OCI Compute-Instanz ausgeführt werden. Die Wahl des Services würde in erster Linie eher auf Kundenpräferenzen als auf technischen Anforderungen basieren.
Daten beibehalten, verarbeiten und kuratieren
Die Datenpersistenz und -verarbeitung basieren auf drei (optional vier) Komponenten. Einige Kunden werden alle verwenden, und andere wiederum nur einen Teil. Je nach Volumes und Datentypen können Daten in den Objektspeicher oder direkt in eine strukturierte relationale Datenbank zur dauerhaften Speicherung geladen werden. Wenn wir die Anwendung von Data Science-Funktionen erwarten, werden Daten, die aus Datenquellen in ihrer Rohform (als unverarbeitete native Datei oder Extrakt) abgerufen werden, in der Regel erfasst und von Transaktionssystemen in den Cloud-Speicher geladen.
- Der Cloud-Speicher ist die häufigste Datenpersistenzschicht für unsere Datenplattform. Er kann sowohl für strukturierte als auch für unstrukturierte Daten verwendet werden. OCI Object Storage, OCI Data Flow und Oracle Autonomous Data Warehouse sind die grundlegenden Bausteine. Aus Datenquellen im Rohformat abgerufene Daten werden erfasst und in den OCI Object Storage geladen. OCI Object Storage ist die primäre Datenpersistenzschicht, und Spark in OCI Data Flow ist die primäre Batchverarbeitungs-Engine. Die Batchverarbeitung umfasst mehrere Aktivitäten, einschließlich der grundlegenden Behandlung hinsichtlich der Qualität, der Verwaltung fehlender Daten und der Filterung basierend auf definierten ausgehenden Datasets. Die Ergebnisse werden basierend auf der erforderlichen Verarbeitung und den verwendeten Datentypen in verschiedene Ebenen des Objektspeichers oder in ein persistentes relationales Repository zurückgeschrieben.
- Die Verwendung von Oracle Big Data Service for Hadoop (verwaltetes Hadoop) ist eine Alternative zur OCI Object Storage- und OCI Data Flow-Konfiguration. Die beiden Konfigurationen können auch zusammen verwendet werden, je nach Kunde und je nachdem, ob dieser das Hadoop-Ökosystem bereits nutzt, sei es in Bezug auf das Produkt oder die Fähigkeiten. Kunden, die bereits Objektspeicher unter Hadoop (anstelle des Hadoop Distributed File System) verwenden, können diese Konfiguration in Oracle Big Data Service überführen. Andere Komponenten in der Hadoop-Umgebung, wie z. B. Hive, können ebenfalls ins Spiel kommen und die Nutzung von Big Data Service vorantreiben, je nachdem, welche Visualisierungs- und Data Science-Tools der Kunde verwendet oder zu verwenden beabsichtigt. Während diese Architektur alle von Oracle bereitgestellten Dienste umfasst, können Kunden einige ihrer vorhandenen Komponenten weiter nutzen, insbesondere Visualisierungs- und Data Science-Tools, die sie bereits einsetzen.
- Wir verwenden jetzt einen bereitstellenden Datenspeicher, um unsere kuratierten Daten in einer für die Abfrageleistung optimierten Form zu speichern. Der bereitstellende Datenspeicher bietet eine persistente relationale Ebene, über die qualitativ hochwertige kuratierte Daten über SQL-basierte Tools direkt an Endbenutzer bereitgestellt werden. In dieser Lösung wird Oracle Autonomous Data Warehouse als bereitstellender Datenspeicher für das Data Warehouse des Unternehmens und, falls erforderlich, spezialisiertere Data Marts auf Domainebene instanziiert. Außerdem kann es die Datenquelle für Data Science-Projekte oder das für Oracle Machine Learning erforderliche Repository sein. Der bereitstellende Datenspeicher kann eine von mehreren Formen annehmen, einschließlich Oracle MySQL HeatWave, Oracle Database Exadata Cloud Service oder Oracle Exadata Cloud@Customer.
Daten analysieren, prognostizieren und handeln
Die Fähigkeit zu analysieren, zu prognostizieren und zu handeln wird durch drei Technologieansätze erleichtert.
- Erweiterte Analysefunktionen sind für die Wartungs- und Leistungsoptimierung von entscheidender Bedeutung. In diesem Anwendungsfall verlassen wir uns für die Bereitstellung von Analysen und Visualisierungen auf Oracle Analytics Cloud. Dadurch kann das Unternehmen deskriptive Analysen (beschreiben aktuelle Trends mit Histogrammen und Diagrammen), Vorhersageanalysen (sagen zukünftige Ereignisse voraus, identifiziert Trends und bestimmen die Wahrscheinlichkeit ungewisser Ergebnisse) und präskriptive Analysen (schlagen geeignete Maßnahmen vor, um eine optimale Entscheidungsfindung zu fördern) verwenden.
- Neben erweiterten Analysen werden zunehmend Data Science, maschinelles Lernen und künstliche Intelligenz eingesetzt, um nach Anomalien zu suchen, mögliche Ausfälle vorherzusagen und den Beschaffungsprozess zu optimieren. OCI Data Science, OCI AI Services bzw. Oracle Machine Learning können in Datenbanken verwendet werden. Wir verwenden maschinelles Lernen und Data Science, um unsere vorausschauenden Wartungsmodelle zu entwickeln und zu trainieren. Diese ML-Modelle können dann für die Bewertung über APIs bereitgestellt oder als Teil der OCI GoldenGate-Streamanalyse-Pipeline eingebettet werden. In einigen Fällen können diese Modelle sogar mithilfe der REST-API von Oracle Machine Learning Services in der Datenbank bereitgestellt werden (dazu muss das Modell im Open Neural Network Exchange-Format vorliegen). Darüber hinaus können OCI Data Science für Jupyter/Python-zentrierte Notebooks oder Oracle Machine Learning für das Zeppelin-Notebook und Algorithmen für maschinelles Lernen innerhalb des bereitstellenden oder Transaktionsdatenspeichers bereitgestellt werden. In ähnlicher Weise können Oracle Machine Learning und OCI Data Science (entweder allein oder in Kombination) Empfehlungs-/Entscheidungsmodelle entwickeln. Diese Modelle können als Service eingesetzt werden, und wir können sie hinter OCI API Gateway implementieren, um sie als „Datenprodukte“ und Services bereitzustellen. Schließlich können die Machine Learning-(ML-)Modelle nach der Erstellung in Anwendungen bereitgestellt werden, die Teil eines verteilten Steuerungssystems sind (sofern zulässig) oder am Rand über ein Oracle Roving Edge Device oder Ähnliches eingesetzt werden.
Die zahlreichen Modelle, die durch die Kombination von Data Science mit den durch maschinelles Lernen identifizierten Mustern erstellt wurden, können auf Reaktions- und Entscheidungssysteme angewendet werden, die von KI-Services bereitgestellt werden.
- Mit OCI Anomaly Detection können Sie Leistungsmetriken der Lieferkette (z. B. Rohmaterialbestand, Produktionsdurchsatz, laufende Arbeiten, Transitzeiten, Lagerumschlag usw.) in Echtzeit überwachen, um Störungen zu erkennen und zu beheben. In einer komplexen Lieferkette kann die Dringlichkeitsbewertung identifizierter Anomalien dabei helfen, beobachtete Geschäftsunterbrechungen für Maßnahmen zu priorisieren.
- Mit OCI Forecasting können Sie Metriken der Lieferkette wie Nachfrage, Angebot und Ressourcenkapazität prognostizieren, sodass für eine rechtzeitige Vorbereitung geeignete Maßnahmen ergriffen werden können.
- Mit OCI Vision und OCI Language können Sie Dokumente wie ausgehende Produktqualitätsberichte und Produktfehlerberichte verstehen, um Lieferkettendaten anzureichern.
Die letzte, aber entscheidende Komponente ist die Data Governance. Dies wird von OCI Data Catalog ausgeführt, einem kostenlosen Service, der Data Governance und Metadatenverwaltung (sowohl für technische als auch geschäftliche Metadaten) für alle Datenquellen im Datenplattform-Ökosystem bereitstellt. OCI Data Catalog ist ebenso eine wichtige Komponente für Abfragen von Oracle Autonomous Data Warehouse an OCI Object Storage, da damit Daten unabhängig von der Speichermethode schnell lokalisiert werden können. Dadurch können Endbenutzer, Entwickler und Data Scientists eine gemeinsame Zugriffssprache (SQL) für alle persistenten Datenspeicher in der Architektur verwenden.
Die Vorteile der Datennutzung zur Verbesserung der betrieblichen Effizienz und Leistung
Mit der zunehmenden Geschwindigkeit der Geschäftsabläufe und des Wettbewerbs können die alten Systeme zur Bereitstellung wichtiger Betriebsdaten nicht mehr mithalten. Diese Systeme erfordern viele manuelle Eingriffe, um fragmentierte und isolierte Daten zu sammeln, zu integrieren und Berichte zu erstellen, was bedeutet, dass die erforderlichen Informationen zu spät eintreffen, um dem Unternehmen den nötigen Vorteil zu verschaffen.
Die bestmögliche Nutzung Ihrer Produktionsressourcen ist entscheidend für die Optimierung Ihrer Produktionsabläufe. Jede Minute, die damit verbracht wird, die falschen Produkte oder die richtigen Produkte ineffizient zu produzieren, erhöht nicht nur die Kosten und den Ausschuss, sondern hält Sie auch davon ab, das zu liefern, was Ihre Kunden brauchen. Die Optimierung von Abläufen und die Verbesserung der Leistung können den Herstellern zahlreiche Vorteile bringen, darunter die folgenden:
- Höhere Effizienz, Verringerung der Produktionszeit und -kosten, Steigerung der Leistung und Verbesserung der Produktivität
- Weniger Mängel, bessere Produktqualität und höhere Kundenzufriedenheit
- Die schnelle Identifizierung von Sicherheitsrisiken und Gefahren, was zu verbesserten Sicherheitspraktiken und weniger Arbeitsunfällen führt
- Weniger Verschwendung, bessere Lieferketteneffizienz und optimierte Lagerbestände
- Eine bessere Wettbewerbsfähigkeit in Bezug auf Preis, Qualität und Innovation, die den Unternehmen einen Wettbewerbsvorteil auf ihren Märkten verschafft
- Verbesserte Nachhaltigkeit durch Abfallreduzierung, Steigerung der Energieeffizienz und Minimierung der Umweltauswirkungen von Fertigungsprozessen
Verwandte Ressourcen
-
Anwendungsfall
Einsatz von Daten zur Verbesserung des Arbeitsschutzes
Erfahren Sie, wie Sie mithilfe einer Datenplattform, die Sie anhand von erweiterten Analysen bei der Verbesserung des Arbeitsschutzes unterstützt, Ihre Fertigungsprozesse sicherer machen können.
-
Anwendungsfall
Schnellere Einblicke in Ihre Produktionsstätte mit Edge Computing
Erfahren Sie, wie Sie mit Oracle Data Platform für die Fertigung Werksdaten effizienter konsolidieren und schneller Einblicke erhalten.
-
Anwendungsfall
Daten nutzen, um von reaktiver zu vorausschauender Wartung überzugehen
Erfahren Sie, wie Sie Assets mit einer Datenplattform optimieren, die vorausschauende Wartung mit maschinellem Lernen ermöglicht.
Erste Schritte
Mehr als 20 kostenlose Cloud-Services mit einer 30-tägigen Testversion für noch mehr
Oracle bietet ein Free Tier ohne zeitliche Begrenzung für eine Auswahl von mehr als 20 Services wie Autonomous AI Database , Arm Compute und Storage an. Darüber hinaus erhalten Sie 300 US-Dollar an kostenlosen Credits, um zusätzliche Cloud-Services zu testen. Informieren Sie sich über die Einzelheiten und melden Sie sich noch heute für Ihr kostenloses Konto an.
-
Was ist im kostenlosen Oracle Cloud-Kontingent enthalten?
- 2 Autonomous AI Database-Instanzen mit jeweils 20 GB
- AMD und Arm Compute-VMs
- Insgesamt 200 GB Blockspeicher
- 10 GB Objektspeicher
- 10 TB ausgehende Datenübertragung pro Monat
- Mehr als 10 permanent kostenlose Services
- Kostenlose Credits im Wert von 300 US-Dollar, 30 Tage lang noch mehr
Mit schrittweiser Anleitung lernen
Erleben Sie eine breite Palette von OCI-Services in Tutorials und praktischen Übungen. Unabhängig davon, ob Sie ein Entwickler, Administrator oder Analyst sind, können wir Ihnen zeigen, wie OCI funktioniert. Viele Übungen werden auf dem Free Tier von Oracle Cloud oder einer von Oracle bereitgestellten freien Laborumgebung ausgeführt.
-
Erste Schritte mit zentralen OCI-Services
Die Übungen in diesem Workshop umfassen eine Einführung in zentrale Oracle Cloud Infrastructure-(OCI-)Services wie virtuelle Cloud-Netzwerke (VCN) sowie Compute- und Speicherservices.
Übungen zu den zentralen OCI-Services jetzt starten -
Autonomous AI Database – Schnellstart
In diesem Workshop vermitteln wir Ihnen die ersten Schritte, um Oracle Autonomous AI Database zu nutzen.
Jetzt mit der Übung für den Schnelleinstieg in Autonomous AI Database beginnen -
App aus einer Kalkulationstabelle erstellen
In dieser Übung laden Sie eine Tabelle in eine Oracle Database-Tabelle hoch und erstellen anschließend eine Anwendung auf Basis dieser neuen Tabelle.
Diese Übung jetzt starten
Entdecken Sie mehr als 150 Best Practice-Designs
Erfahren Sie, wie unsere Architekten und anderen Kunden eine Vielzahl von Workloads bereitstellen, von Unternehmensanwendungen bis hin zu HPC, von Microservices bis hin zu Data Lakes. Informieren Sie sich über Best Practice, hören Sie von anderen Kundenarchitekten in unserer Reihe „Built & Deploy“, und stellen Sie außerdem viele Workloads mit unserer Funktion „Click-to-Deployment“ oder selbst aus unserem GitHub-Repository bereit.
Beliebte Architekturen
- Apache Tomcat mit MySQL Database Service
- Oracle Weblogic auf Kubernetes mit Jenkins
- ML- und KI-Umgebungen
- Tomcat on Arm mit Oracle Autonomous AI Database
- Loganalyse mit ELK-Stack
- HPC mit OpenFOAM
Erfahren Sie, wie viel Sie bei OCI sparen können
Die Tarife für Oracle Cloud sind unkompliziert, mit weltweit konsequent niedrigen Tarifen und zahlreichen unterstützten Anwendungsfällen. Um den für Sie zutreffenden, niedrigen Tarif zu berechnen, gehen Sie zum Kostenrechner und konfigurieren Sie die Services entsprechend Ihrer Anforderungen.
Den Unterschied entdecken:
- 1/4 der Kosten für ausgehende Bandbreite
- 3-mal besseres Preis-Leistungs-Verhältnis
- Gleicher niedriger Preis in jeder Region
- Niedrige Tarife ohne langfristige Verpflichtungen
Vertrieb kontaktieren
Möchten Sie mehr über die Oracle Cloud Infrastructure erfahren? Einer unserer Experten wird Ihnen gerne helfen.
-
Sie können Fragen beantworten wie:
- Welche Workloads werden am besten auf OCI ausgeführt?
- Wie kann ich meine gesamten Oracle Investitionen optimal nutzen?
- Wie schlägt sich OCI verglichen mit anderen Cloud-Computing-Anbietern?
- Wie kann OCI Ihre IaaS- und PaaS-Ziele unterstützen?